
 Technologie-Peripheriegeräte
KI
Tsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne
Technologie-Peripheriegeräte
KI
Tsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne
Tsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne

Bei der Verarbeitung natürlicher Sprache werden viele Informationen tatsächlich wiederholt.
Wenn die Aufforderungswörter effektiv komprimiert werden können, entspricht dies einer gewissen Erweiterung der Länge des vom Modell unterstützten Kontexts.
Bestehende Informationsentropiemethoden reduzieren diese Redundanz, indem sie bestimmte Wörter oder Phrasen entfernen.
Die auf der Informationsentropie basierende Berechnung deckt jedoch nur den einseitigen Textkontext ab und ignoriert möglicherweise wichtige Informationen, die für die Komprimierung erforderlich sind. Darüber hinaus stimmt die Berechnungsmethode der Informationsentropie nicht vollständig mit dem tatsächlichen Zweck der Komprimierungsaufforderung überein Wörter.
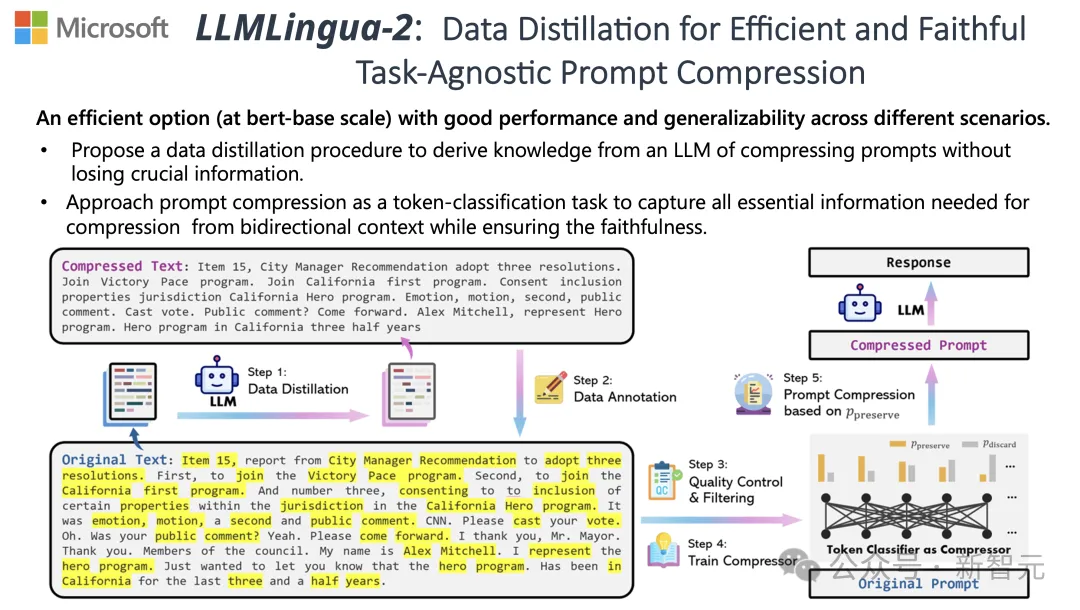
Um diesen Herausforderungen zu begegnen, haben Forscher der Tsinghua-Universität und Microsoft gemeinsam einen neuen Datenverarbeitungsprozess namens LLMLingua-2 vorgeschlagen. Ziel ist es, Wissen aus großen Sprachmodellen (LLM) zu extrahieren und eine Verfeinerung der Informationen durch die Komprimierung von Eingabeaufforderungen zu erreichen und gleichzeitig sicherzustellen, dass wichtige Informationen nicht verloren gehen.
Das Projekt hat 3,1.000 Sterne auf GitHub erhalten
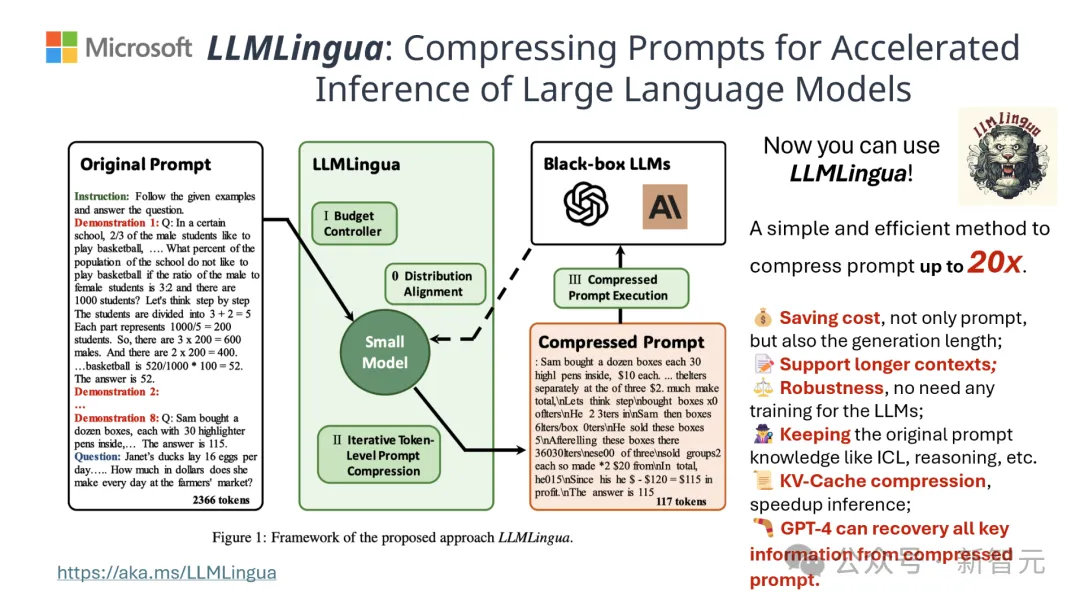
Die Ergebnisse zeigen, dass LLMLingua-2 die Textlänge erheblich auf die ursprünglichen 20 % reduzieren kann, wodurch Verarbeitungszeit und Kosten effektiv reduziert werden.
Darüber hinaus ist die Verarbeitungsgeschwindigkeit von LLMLingua 2 im Vergleich zur Vorgängerversion von LLMLingua und anderen ähnlichen Technologien um das Drei- bis Sechsfache erhöht.

Papieradresse: https://arxiv.org/abs/2403.12968
Bei diesem Prozess wird zunächst der Originaltext in das Modell eingegeben.
Das Modell bewertet die Wichtigkeit jedes Wortes und entscheidet, ob es beibehalten oder gelöscht werden soll, wobei auch die Beziehung zwischen Wörtern berücksichtigt wird.
Abschließend wählt das Modell die Wörter mit den höchsten Punktzahlen aus, um ein kürzeres Aufforderungswort zu bilden.
Das Team testete das LLMLingua-2-Modell an mehreren Datensätzen, darunter MeetingBank, LongBench, ZeroScrolls, GSM8K und BBH.
Obwohl dieses Modell klein ist, erzielte es in Benchmark-Tests deutliche Leistungsverbesserungen und hat seine Leistung in verschiedenen großen Sprachmodellen (von GPT-3.5 bis Mistral-7B) und Sprachen (von Englisch bis Chinesisch) unter Beweis gestellt ausgezeichnete Generalisierungsfähigkeit.
Systemaufforderung:
Als herausragender Linguist sind Sie gut darin, längere Absätze in kurze Ausdrücke zu komprimieren, indem Sie unwichtige Wörter entfernen und so viele Informationen wie möglich behalten.
Benutzertipps:
Bitte komprimieren Sie den angegebenen Text in einen kurzen Ausdruck, damit Sie (GPT-4) den Originaltext so genau wie möglich wiederherstellen können. Anders als bei der normalen Textkomprimierung müssen Sie die folgenden fünf Bedingungen befolgen:
1. Entfernen Sie nur diese unwichtigen Wörter.
2. Behalten Sie die Reihenfolge der ursprünglichen Wörter bei.
3. Behalten Sie den ursprünglichen Wortschatz bei.
4. Verwenden Sie keine Abkürzungen oder Emoticons.
5. Fügen Sie keine neuen Wörter oder Symbole hinzu.
Bitte komprimieren Sie den Originaltext so weit wie möglich und behalten Sie dabei so viele Informationen wie möglich bei. Wenn Sie es verstanden haben, komprimieren Sie bitte den folgenden Text: {Zu komprimierender Text}
Der komprimierte Text ist: [...]
Die Ergebnisse zeigen, dass in Fragen und Antworten, abstraktem Schreiben und logischem Denken In Bei einer Vielzahl von Sprachaufgaben übertrifft LLMLlingua-2 das ursprüngliche LLMLingua-Modell und andere selektive Kontextstrategien deutlich.
Es ist erwähnenswert, dass diese Komprimierungsmethode für verschiedene große Sprachmodelle (von GPT-3.5 bis Mistral-7B) und verschiedene Sprachen (von Englisch bis Chinesisch) gleichermaßen effektiv ist.
Darüber hinaus kann die Bereitstellung von LLMLingua-2 mit nur zwei Codezeilen erreicht werden.
Derzeit ist das Modell in die weit verbreiteten RAG-Frameworks LangChain und LlamaIndex integriert.
Implementierungsmethode
Um die Probleme bestehender auf Informationsentropie basierender Textkomprimierungsmethoden zu überwinden, wendet LLMLingua-2 eine innovative Datenextraktionsstrategie an.
Diese Strategie erreicht eine effiziente Textkomprimierung, ohne wichtige Inhalte zu verlieren und das Hinzufügen fehlerhafter Informationen zu vermeiden, indem wesentliche Informationen aus großen Sprachmodellen wie GPT-4 extrahiert werden.
Tipps Design
Um das Textkomprimierungspotenzial von GPT-4 voll auszuschöpfen, liegt der Schlüssel darin, genaue Komprimierungsanweisungen festzulegen.
Das heißt, wenn Sie Text komprimieren, weisen Sie GPT-4 an, nur die Wörter zu entfernen, die im Originaltext weniger wichtig sind, und dabei die Einführung neuer Wörter zu vermeiden.
Damit soll sichergestellt werden, dass der komprimierte Text die Authentizität und Integrität des Originaltextes so weit wie möglich beibehält.

Annotation und Filterung
Forscher haben einen neuartigen Datenannotationsalgorithmus entwickelt, der Wissen nutzt, das aus großen Sprachmodellen wie GPT-4 extrahiert wurde.
Dieser Algorithmus kann jedes Wort im Originaltext kennzeichnen und klar angeben, welche Wörter während des Komprimierungsprozesses beibehalten werden müssen.
Um die hohe Qualität des erstellten Datensatzes sicherzustellen, haben sie außerdem zwei Qualitätsüberwachungsmechanismen entwickelt, die speziell darauf abzielen, Datenproben mit schlechter Qualität zu identifizieren und zu eliminieren.

Kompressor
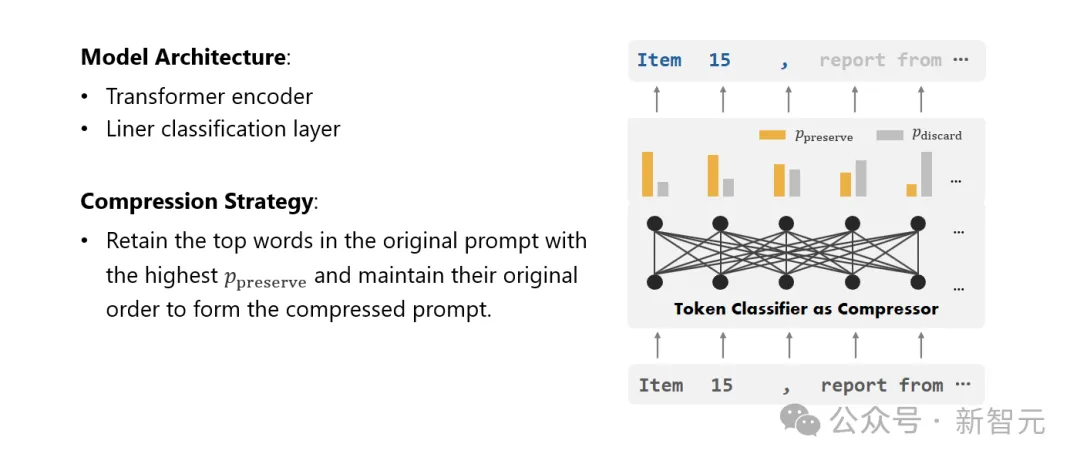
Schließlich wandelten die Forscher das Problem der Textkomprimierung in eine Aufgabe zur Klassifizierung jedes Vokabulars (Token) um und verwendeten einen leistungsstarken Transformer als Feature-Extraktor.
Dieses Tool versteht den Kontext von Text, um die Informationen, die für die Textkomprimierung entscheidend sind, genau zu erfassen.
Durch Training an einem sorgfältig erstellten Datensatz ist das Modell der Forscher in der Lage, einen Wahrscheinlichkeitswert basierend auf der Wichtigkeit jedes Wortes zu berechnen, um zu entscheiden, ob das Wort im endgültigen komprimierten Text beibehalten oder aufgegeben werden sollte.
Leistungsbewertung
Die Forscher testeten die Leistung von LLMLingua-2 bei einer Reihe von Aufgaben, darunter Kontextlernen, Textzusammenfassung, Dialoggenerierung, Fragen und Antworten für mehrere und einzelne Dokumente, Codegenerierung usw Syntheseaufgaben umfassen sowohl domäneninterne als auch domänenexterne Datensätze.
Testergebnisse zeigen, dass die Methode der Forscher minimale Leistungsverluste bei gleichzeitig hoher Leistung reduziert und unter den aufgabenunspezifischen Textkomprimierungsmethoden eine hervorragende Leistung erbringt.
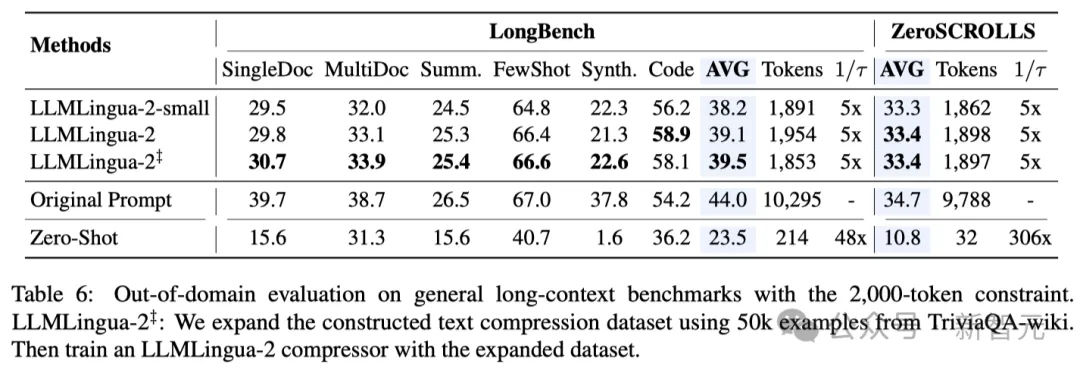
– In-Domain-Tests (MeetingBank)
Die Forscher verglichen die Leistung von LLMLingua-2 auf dem MeetingBank-Testsatz mit anderen leistungsstarken Basismethoden.
Obwohl ihre Modellgröße viel kleiner ist als die des LLaMa-2-7B, das in der Basislinie verwendet wurde, verbesserte die Methode der Forscher bei den Fragenbeantwortungs- und Textzusammenfassungsaufgaben nicht nur die Leistung deutlich, sondern schnitt auch fast genauso gut ab die Originaltextaufforderungen. ?? in der Verallgemeinerungsfähigkeit in verschiedenen Szenarien wie Langtext, logischem Denken und kontextbezogenem Lernen.
Es ist erwähnenswert, dass LLMLlingua-2 zwar nur an einem Datensatz trainiert wurde, seine Leistung jedoch bei Tests außerhalb der Domäne nicht nur mit den aktuellen aufgabenunspezifischen Komprimierungsmethoden auf dem neuesten Stand der Technik vergleichbar war, sondern sogar in manchen Fällen sogar noch schlimmer.
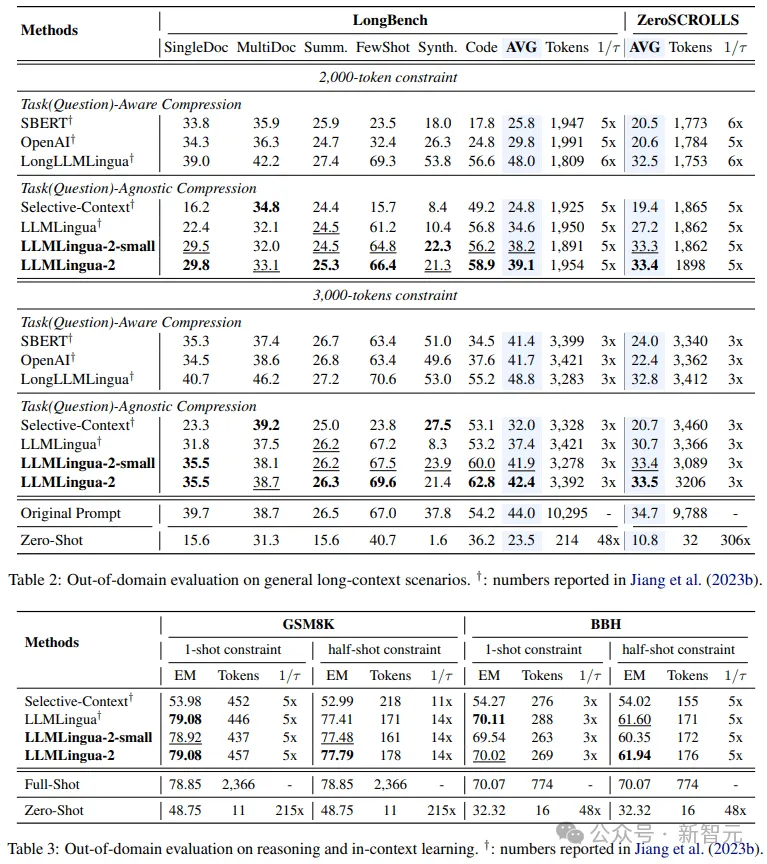
Sogar das kleinere Modell der Forscher (BERT-Basisgröße) konnte eine Leistung erzielen, die mit den ursprünglichen Hinweisen vergleichbar und in einigen Fällen sogar etwas besser war.
Obwohl der Ansatz der Forscher vielversprechende Ergebnisse erzielte, weist er im Vergleich zu anderen aufgabenbewussten Komprimierungsmethoden wie LongLLMlingua auf Longbench immer noch Mängel auf.
Die Forscher führen diese Leistungslücke auf die zusätzlichen Informationen zurück, die sie durch das Problem erhalten. Allerdings ist das Modell der Forscher aufgabenunabhängig, was es zu einer effizienten Option mit guter Generalisierbarkeit macht, wenn es in verschiedenen Szenarien eingesetzt wird.
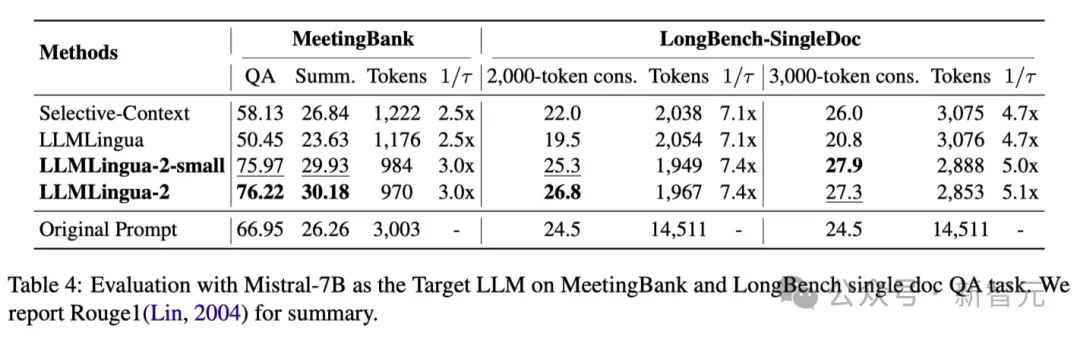
Tabelle 4 oben listet die Ergebnisse verschiedener Methoden unter Verwendung von Mistral-7Bv0.1 4 als Ziel-LLM auf.
Im Vergleich zu anderen Basismethoden weist die Methode der Forscher eine deutliche Leistungsverbesserung auf, was ihre gute Generalisierungsfähigkeit auf das Ziel-LLM demonstriert.
Es ist erwähnenswert, dass LLMLingua-2 sogar besser abschneidet als die ursprüngliche Eingabeaufforderung.
Forscher spekulieren, dass Mistral-7B bei der Verwaltung langer Kontexte möglicherweise nicht so gut ist wie GPT-3.5-Turbo.
Der Ansatz der Forscher verbessert effektiv die endgültige Inferenzleistung von Mistral7B, indem er kurze Hinweise mit höherer Informationsdichte liefert.
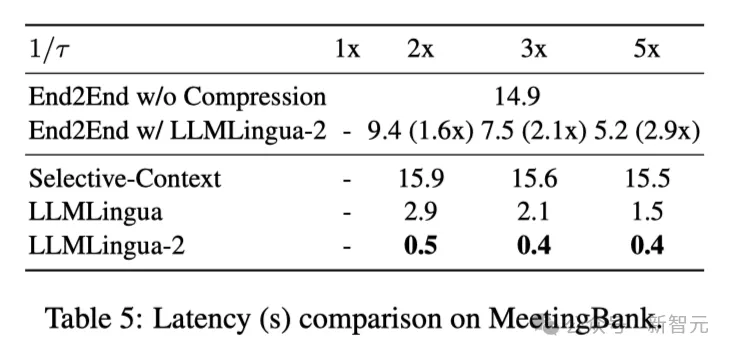
Tabelle 5 oben zeigt die Latenz verschiedener Systeme auf der V100-32G-GPU mit unterschiedlichen Komprimierungsverhältnissen.
Die Ergebnisse zeigen, dass LLMLingua2 im Vergleich zu anderen Komprimierungsmethoden viel weniger Rechenaufwand hat und eine End-to-End-Geschwindigkeitsverbesserung von 1,6x bis 2,9x erreichen kann.
Darüber hinaus kann die Methode der Forscher die GPU-Speicherkosten um das Achtfache senken und so den Bedarf an Hardware-Ressourcen reduzieren.
Kontextbewusste Beobachtung Die Forscher beobachteten, dass LLMLingua-2 mit zunehmender Komprimierungsrate die informativsten Wörter effektiv mit vollständigem Kontext beibehalten kann.
Dies ist der Einführung eines bidirektionalen kontextsensitiven Feature-Extraktors und einer Strategie zu verdanken, die explizit auf das Ziel einer zeitnahen Komprimierung hin optimiert.
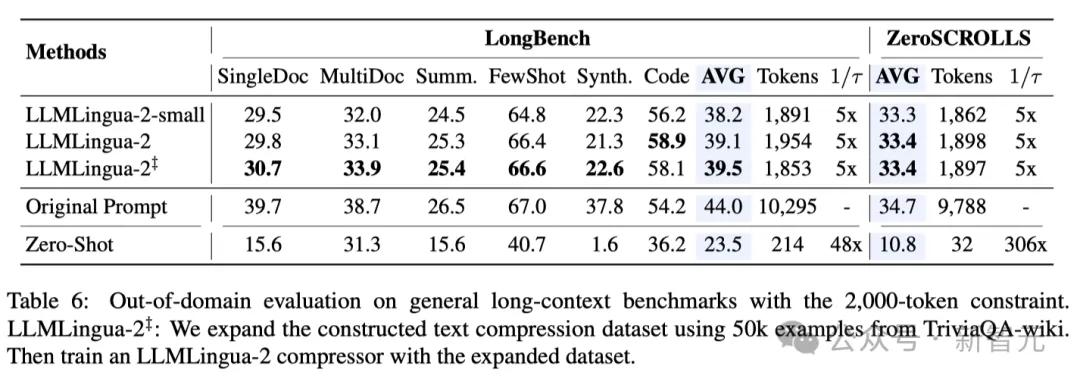
Die Forscher beobachteten, dass LLMLingua-2 mit zunehmendem Komprimierungsverhältnis effektiv die informativsten Wörter im Zusammenhang mit dem gesamten Kontext beibehalten kann.
Dies ist der Einführung eines bidirektionalen kontextsensitiven Feature-Extraktors und einer Strategie zu verdanken, die explizit auf das Ziel einer zeitnahen Komprimierung hin optimiert.
Schließlich baten die Forscher GPT-4, den Originalton aus dem LLMLlingua-2-Komprimierungshinweis zu rekonstruieren.
Die Ergebnisse zeigen, dass GPT-4 den ursprünglichen Tipp effektiv rekonstruieren kann, was darauf hinweist, dass während des LLMLlingua-2-Komprimierungsprozesses keine wesentlichen Informationen verloren gehen.
Das obige ist der detaillierte Inhalt vonTsinghua: Microsoft hat ein neues Komprimierungstool für Eingabeaufforderungsworte als Open-Source-Lösung bereitgestellt, dessen Länge um 80 % gesunken ist! GitHub erhält 3,1K Sterne. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Einstiegsadresse für die internationale Bing-Version von Microsoft (Einstieg in die Bing-Suchmaschine)
Mar 14, 2024 pm 01:37 PM
Bing ist eine von Microsoft eingeführte Online-Suchmaschine. Die Suchfunktion ist sehr leistungsfähig und verfügt über zwei Eingänge: die inländische Version und die internationale Version. Wo sind die Eingänge zu diesen beiden Versionen? Wie greife ich auf die internationale Version zu? Werfen wir einen Blick auf die Details unten. Zugang zur Website der chinesischen Version von Bing: https://cn.bing.com/ Zugang zur Website der internationalen Version von Bing: https://global.bing.com/ Wie greife ich auf die internationale Version von Bing zu? 1. Geben Sie zunächst die URL ein, um Bing zu öffnen: https://www.bing.com/ 2. Sie sehen, dass es Optionen für nationale und internationale Versionen gibt. Wir müssen nur die internationale Version auswählen und die Schlüsselwörter eingeben.
 Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Das Vollbild-Popup von Microsoft fordert Benutzer von Windows 10 auf, sich zu beeilen und auf Windows 11 zu aktualisieren
Jun 06, 2024 am 11:35 AM
Laut Nachrichten vom 3. Juni sendet Microsoft aktiv Vollbildbenachrichtigungen an alle Windows 10-Benutzer, um sie zu einem Upgrade auf das Betriebssystem Windows 11 zu ermutigen. Dabei handelt es sich um Geräte, deren Hardwarekonfigurationen das neue System nicht unterstützen. Seit 2015 hat Windows 10 fast 70 % des Marktanteils eingenommen und seine Dominanz als Windows-Betriebssystem fest etabliert. Der Marktanteil liegt jedoch weit über dem Marktanteil von 82 %, und der Marktanteil übersteigt den von Windows 11, das 2021 erscheinen wird, bei weitem. Obwohl Windows 11 seit fast drei Jahren auf dem Markt ist, ist die Marktdurchdringung immer noch langsam. Microsoft hat angekündigt, den technischen Support für Windows 10 nach dem 14. Oktober 2025 einzustellen, um sich stärker darauf zu konzentrieren
 Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Microsoft veröffentlicht das kumulative August-Update für Win11: Verbesserung der Sicherheit, Optimierung des Sperrbildschirms usw.
Aug 14, 2024 am 10:39 AM
Laut Nachrichten dieser Website vom 14. August veröffentlichte Microsoft während des heutigen August-Patch-Dienstags kumulative Updates für Windows 11-Systeme, darunter das Update KB5041585 für 22H2 und 23H2 sowie das Update KB5041592 für 21H2. Nachdem das oben genannte Gerät mit dem kumulativen Update vom August installiert wurde, sind die mit dieser Site verbundenen Versionsnummernänderungen wie folgt: Nach der Installation des 21H2-Geräts wurde die Versionsnummer auf Build22000.314722H2 erhöht. Die Versionsnummer wurde auf Build22621.403723H2 erhöht. Nach der Installation des Geräts wurde die Versionsnummer auf Build22631.4037 erhöht. Die Hauptinhalte des KB5041585-Updates für Windows 1121H2 sind wie folgt: Verbesserung: Verbessert
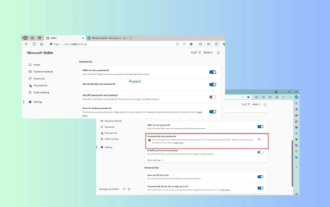 Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Microsoft Edge-Upgrade: Funktion zum automatischen Speichern von Passwörtern verboten? ! Die Benutzer waren schockiert!
Apr 19, 2024 am 08:13 AM
Neuigkeiten vom 18. April: Kürzlich berichteten einige Benutzer des Microsoft Edge-Browsers, die den Canary-Kanal nutzten, dass sie nach dem Upgrade auf die neueste Version festgestellt hätten, dass die Option zum automatischen Speichern von Passwörtern deaktiviert sei. Nach einer Untersuchung stellte sich heraus, dass es sich hierbei um eine geringfügige Anpassung nach dem Browser-Upgrade und nicht um eine Aufhebung der Funktionalität handelte. Vor der Verwendung des Edge-Browsers für den Zugriff auf eine Website berichteten Benutzer, dass der Browser ein Fenster öffnete, in dem sie gefragt wurden, ob sie das Anmeldekennwort für die Website speichern wollten. Nachdem Sie sich zum Speichern entschieden haben, gibt Edge bei der nächsten Anmeldung automatisch die gespeicherte Kontonummer und das gespeicherte Passwort ein, was den Benutzern großen Komfort bietet. Aber das neueste Update ähnelt einer Optimierung, bei der die Standardeinstellungen geändert werden. Benutzer müssen das Speichern des Passworts auswählen und dann in den Einstellungen das automatische Ausfüllen des gespeicherten Kontos und Passworts manuell aktivieren.
 Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Die Funktion von Microsoft Win11 zum Komprimieren von 7z- und TAR-Dateien wurde von den Versionen 24H2 auf 23H2/22H2 herabgestuft
Apr 28, 2024 am 09:19 AM
Laut Nachrichten dieser Website vom 27. April hat Microsoft Anfang dieses Monats das Vorschauversionsupdate für Windows 11 Build 26100 auf den Canary- und Dev-Kanälen veröffentlicht, das voraussichtlich eine mögliche RTM-Version des Windows 1124H2-Updates werden wird. Die wichtigsten Änderungen in der neuen Version sind der Datei-Explorer, die Integration von Copilot, die Bearbeitung von PNG-Dateimetadaten, die Erstellung von TAR- und 7z-komprimierten Dateien usw. @PhantomOfEarth hat herausgefunden, dass Microsoft einige Funktionen der 24H2-Version (Germanium) auf die 23H2/22H2-Version (Nickel) übertragen hat, beispielsweise die Erstellung von TAR- und 7z-komprimierten Dateien. Wie im Diagramm gezeigt, unterstützt Windows 11 die native Erstellung von TAR
 Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Microsoft Edge-Browser-Update: Funktion „Bild vergrößern' hinzugefügt, um die Benutzererfahrung zu verbessern
Mar 21, 2024 pm 01:40 PM
Einer Nachricht vom 21. März zufolge hat Microsoft kürzlich seinen Microsoft Edge-Browser aktualisiert und eine praktische „Bild vergrößern“-Funktion hinzugefügt. Wenn Benutzer den Edge-Browser verwenden, können Benutzer diese neue Funktion jetzt ganz einfach im Popup-Menü finden, indem sie einfach mit der rechten Maustaste auf das Bild klicken. Noch praktischer ist, dass Benutzer auch mit der Maus über das Bild fahren und dann die Strg-Taste doppelklicken können, um schnell die Funktion zum Vergrößern des Bildes aufzurufen. Nach Angaben des Herausgebers wurde der neueste veröffentlichte Microsoft Edge-Browser im kanarischen Kanal auf neue Funktionen getestet. Die stabile Version des Browsers hat außerdem offiziell die praktische Funktion „Bild vergrößern“ eingeführt, die Benutzern ein komfortableres Durchsuchen von Bildern ermöglicht. Darauf haben auch ausländische Wissenschafts- und Technologiemedien geachtet
 Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
Microsoft plant, NTLM in Windows 11 in der zweiten Jahreshälfte 2024 auslaufen zu lassen und vollständig auf Kerberos-Authentifizierung umzustellen
Jun 09, 2024 pm 04:17 PM
In der zweiten Hälfte des Jahres 2024 veröffentlichte der offizielle Microsoft-Sicherheitsblog eine Nachricht als Reaktion auf den Aufruf der Sicherheits-Community. Das Unternehmen plant, das in der zweiten Jahreshälfte 2024 veröffentlichte NTLAN Manager (NTLM)-Authentifizierungsprotokoll in Windows 11 zu eliminieren, um die Sicherheit zu verbessern. Nach bisherigen Erläuterungen hat Microsoft bereits zuvor ähnliche Schritte unternommen. Am 12. Oktober letzten Jahres schlug Microsoft in einer offiziellen Pressemitteilung einen Übergangsplan vor, der darauf abzielt, NTLM-Authentifizierungsmethoden auslaufen zu lassen und mehr Unternehmen und Benutzer dazu zu bewegen, auf Kerberos umzusteigen. Um Unternehmen zu helfen, die möglicherweise Probleme mit fest verdrahteten Anwendungen und Diensten haben, nachdem sie die NTLM-Authentifizierung deaktiviert haben, stellt Microsoft IAKerb und zur Verfügung
 Microsoft bringt neuen Windows 11 AI-PC auf den Markt: ausgestattet mit innovativer „Review'-Funktion
Jun 06, 2024 pm 01:52 PM
Microsoft bringt neuen Windows 11 AI-PC auf den Markt: ausgestattet mit innovativer „Review'-Funktion
Jun 06, 2024 pm 01:52 PM
Laut Nachrichten vom 21. Mai hat Microsoft der Öffentlichkeit heute auf einer großen Veranstaltung auf seinem neuen Campus ein neues Windows-PC-Produkt vorgestellt – den Windows 11 AI PC. Dieses neue Produkt ist speziell für das KI-Erlebnis konzipiert. Der Windows 11 AI PC ist mit hervorragender Leistung und intelligentem Design ausgestattet und zielt darauf ab, Benutzern ein intelligenteres und effizienteres Computererlebnis zu bieten. Dieses Produkt wird die Technologie der künstlichen Intelligenz nutzen, um eine humanere Interaktionsmethode zu erreichen und den Benutzern das ultimative Benutzererlebnis zu bieten. Gleichzeitig integriert Windows 11 AI PC auch viele intelligente Funktionen. Windows 11 AI kann PC-Benutzern ein großes Highlight bieten, nämlich seine einzigartige „Recall“-Funktion. Diese beispiellose „Erinnerung“
