
 Technologie-Peripheriegeräte
KI
StreamingT2V, ein Generator für lange Videos mit zwei Minuten und 1.200 Bildern, ist da, und der Code wird Open Source sein
Technologie-Peripheriegeräte
KI
StreamingT2V, ein Generator für lange Videos mit zwei Minuten und 1.200 Bildern, ist da, und der Code wird Open Source sein
StreamingT2V, ein Generator für lange Videos mit zwei Minuten und 1.200 Bildern, ist da, und der Code wird Open Source sein

Weitwinkelaufnahme des Schlachtfeldes, Sturmtruppen rennen...

prompt: Weitwinkelaufnahme des Schlachtfeldes, Sturmtruppen rennen...
Dieses 2-minütige Video mit 1200 Bildern ist ein aus Text (Text) generiertes Video -to-Video)-Modell. Obwohl die Spuren von KI immer noch deutlich zu erkennen sind, zeigen die Charaktere und Szenen eine recht gute Konsistenz.
Wie geht das? Sie sollten wissen, dass die Generierungsqualität und Textausrichtungsqualität der Vincent-Videotechnologie in den letzten Jahren zwar recht gut war, sich die meisten vorhandenen Methoden jedoch auf die Erstellung kurzer Videos (normalerweise 16 oder 24 Bilder lang) konzentrieren. Bestehende Methoden, die für kurze Videos funktionieren, funktionieren jedoch oft nicht bei langen Videos (≥ 64 Bilder).
Selbst das Generieren kurzer Sequenzen erfordert oft kostspielige Schulungen, wie z. B. Trainingsschritte von mehr als 260 KB und Stapelgrößen von mehr als 4500. Wenn Sie nicht an längeren Videos trainieren und einen Kurzvideogenerator verwenden, um lange Videos zu erstellen, sind die resultierenden langen Videos oft von schlechter Qualität. Die bestehende autoregressive Methode (Erzeugung eines neuen kurzen Videos unter Verwendung der letzten paar Bilder des kurzen Videos und anschließende Synthese des langen Videos) weist auch einige Probleme auf, wie z. B. einen inkonsistenten Szenenwechsel.
Um die Mängel bestehender Methoden auszugleichen, haben Picsart AI Research und andere Institutionen gemeinsam eine neue Vincent-Videomethode vorgeschlagen: StreamingT2V. Diese Methode nutzt autoregressive Technologie und kombiniert sie mit einem langen Kurzzeitgedächtnismodul, wodurch lange Videos mit starker zeitlicher Kohärenz generiert werden können.

- Papiertitel: StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
- Papieradresse: https://arxiv.org/abs/2403.14773
- Projektadresse: https ://streamingt2v.github.io/
Das Folgende ist ein 600-Frame-1-Minuten-Videogenerierungsergebnis. Sie können sehen, dass Bienen und Blumen eine hervorragende Konsistenz haben:
Daher hat das Team Folgendes vorgeschlagen Bedingungen Aufmerksamkeitsmodul (CAM). CAM nutzt seinen Aufmerksamkeitsmechanismus, um Informationen aus vorherigen Frames effektiv zu integrieren, um neue Frames zu generieren, und kann Bewegungen in neuen Frames frei verarbeiten, ohne durch die Struktur oder Form vorheriger Frames eingeschränkt zu sein.
Um das Problem der Erscheinungsänderungen von Personen und Objekten im generierten Video zu lösen, schlug das Team außerdem das Erscheinungserhaltungsmodul (APM) vor: Es kann die Erscheinungsinformationen von Objekten oder globalen Szenen aus einem Anfangsbild extrahieren ( Ankerrahmen) und verwenden Sie diese Informationen, um den Videogenerierungsprozess für alle Videoblöcke zu regulieren.
Um die Qualität und Auflösung der Generierung langer Videos weiter zu verbessern, verbesserte das Team ein Videoverbesserungsmodell für die Aufgabe der autoregressiven Generierung. Dazu wählte das Team ein hochauflösendes Vincent-Videomodell aus und verbesserte mit der SDEdit-Methode die Qualität von 24 aufeinanderfolgenden Videoblöcken (mit 8 überlappenden Bildern).
Um den Übergang zur Videoblockverbesserung reibungslos zu gestalten, haben sie außerdem eine Zufallsmischmethode entwickelt, die überlappende verbesserte Videoblöcke nahtlos miteinander verbindet.
Methode
Erstellen Sie zunächst ein 5-Sekunden-Video mit einer Auflösung von 256 × 256 (16 fps) und verbessern Sie es dann auf eine höhere Auflösung (720 × 720). Abbildung 2 zeigt den vollständigen Arbeitsablauf.
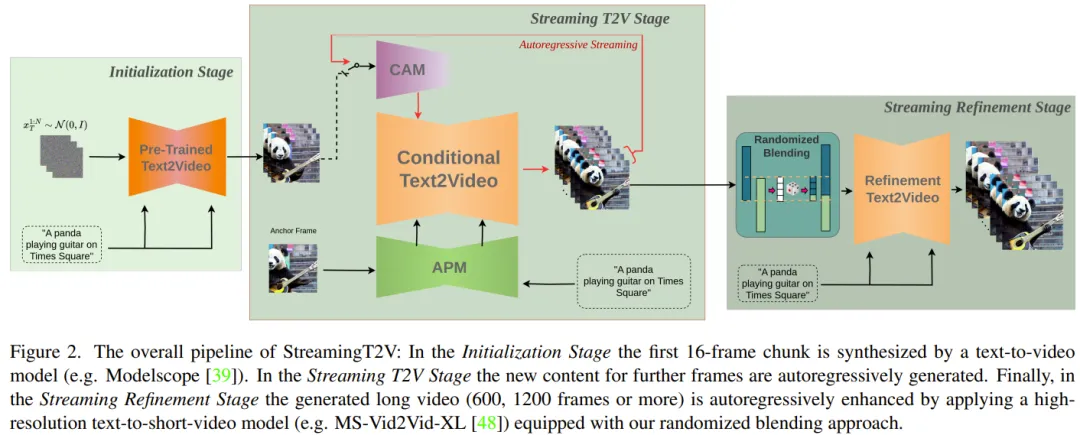
Der lange Videogenerierungsteil besteht aus der Initialisierungsphase und der Streaming-T2V-Phase.
Unter anderem verwendet die Initialisierungsphase ein vorab trainiertes Vincent-Videomodell (Sie können beispielsweise Modelscope verwenden), um den ersten 16-Frame-Videoblock zu generieren, während die Streaming-Vincent-Videophase nachfolgende Frames auf autoregressive Weise generiert . Neuer Inhalt.
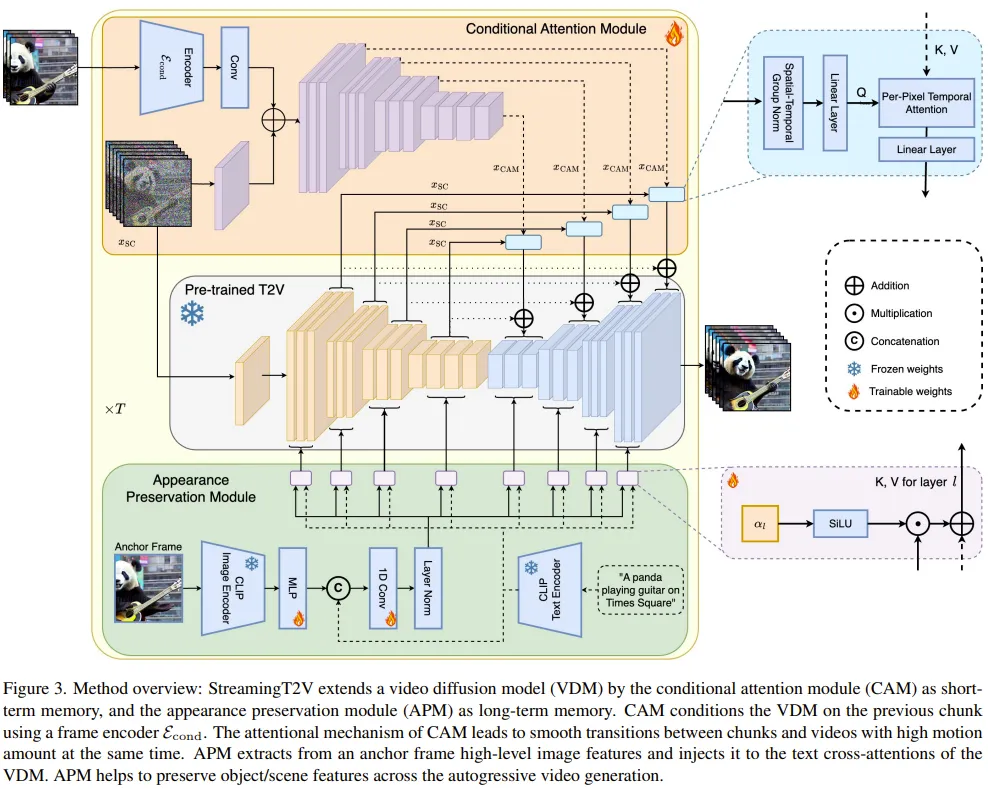
Für den autoregressiven Prozess (siehe Abbildung 3) kann das vom Team neu vorgeschlagene CAM die Kurzzeitinformationen der letzten 8 Bilder des vorherigen Videoblocks nutzen, um einen nahtlosen Wechsel zwischen Blöcken zu erreichen. Darüber hinaus werden sie das neu vorgeschlagene APM-Modul verwenden, um Langzeitinformationen eines festen Ankerrahmens zu extrahieren, sodass der autoregressive Prozess Änderungen an Dingen und Szenendetails während des Generierungsprozesses robust bewältigen kann.
Nachdem sie lange Videos (80, 240, 600, 1200 oder mehr Bilder) erstellt haben, verbessern sie dann die Videoqualität durch die Streaming Refinement Stage. Dieser Prozess verwendet ein hochauflösendes Vison-Kurzvideomodell (z. B. MS-Vid2Vid-XL) auf autoregressive Weise, gekoppelt mit einer neu vorgeschlagenen stochastischen Mischmethode für eine nahtlose Videoblockverarbeitung. Darüber hinaus erfordert der letzte Schritt kein zusätzliches Training, was diese Methode weniger rechenintensiv macht.
Modul für bedingte Aufmerksamkeit
Zuerst wird das verwendete vorab trainierte Vincent-Videomodell (kurz) als Video-LDM bezeichnet. Das Aufmerksamkeitsmodul (CAM) besteht aus einem Feature-Extraktor und einem Feature-Injektor, die in Video-LDM UNet eingespeist werden.
Der Feature-Extraktor verwendet einen Frame-by-Frame-Bildencoder, gefolgt von derselben Encoderschicht, die von Video-LDM UNet bis zur mittleren Schicht verwendet wird (und durch das Gewicht von UNet initialisiert wird).
Für die Feature-Injection besteht das Design hier darin, jede Sprungverbindung mit großer Reichweite in UNet durch Kreuzaufmerksamkeit auf die entsprechenden Features zu konzentrieren, die von CAM generiert werden.
Appearance Preservation Module
Das APM-Modul integriert das Langzeitgedächtnis in den Videogenerierungsprozess, indem es Informationen aus festen Ankerrahmen nutzt. Dies trägt dazu bei, Szenen- und Objekteigenschaften während der Video-Patch-Generierung beizubehalten.
Damit APM die Verarbeitung der durch Ankerrahmen und Textanweisungen bereitgestellten Führungsinformationen ausgleichen kann, hat das Team zwei Verbesserungen vorgenommen: (1) Mischen Sie das CLIP-Bild-Token des Ankerrahmens mit dem CLIP-Text-Token der Textanweisung ; (2) Für jede Queraufmerksamkeitsschicht wird ein Gewicht eingeführt, um Queraufmerksamkeit zu nutzen.
Autoregressive Videoverbesserung
Um die generierten Videoblöcke von 24 Frames autoregressiv zu verbessern, wird hier ein hochauflösender (1280x720) Refiner Video-LDM verwendet, siehe Bild 3). Dieser Prozess wird durchgeführt, indem zunächst eine große Menge Rauschen zum Eingabevideoblock hinzugefügt und dann dieses Vincent-Videodiffusionsmodell verwendet wird, um eine Entrauschungsverarbeitung durchzuführen.
Diese Methode reicht jedoch nicht aus, um das Problem der Übergangsinkongruenz zwischen Videoblöcken zu lösen.
Zu diesem Zweck ist die Lösung des Teams eine Zufallsmischmethode. Einzelheiten entnehmen Sie bitte dem Originalpapier.
Experiment
Im Experiment verwendet das Team folgende Bewertungsmetriken: SCuts-Score zur Bewertung der zeitlichen Konsistenz, Motion-Aware Twist Error (MAWE) zur Bewertung von Bewegungs- und Twist-Fehlern, CLIP-Text-Bild-Ähnlichkeits-Score (CLIP) und Ästhetik-Score (AE) zur Bewertung der Qualität der Textausrichtung.
Ablationsstudie
Um die Wirksamkeit verschiedener neuer Komponenten zu bewerten, führte das Team eine Ablationsstudie an 75 Stichproben durch, die zufällig aus dem Validierungssatz ausgewählt wurden.
CAM für bedingte Verarbeitung: CAM hilft dem Modell, konsistentere Videos zu generieren, wobei SCuts im Vergleich 88 % niedrigere Werte als andere Basismodelle erzielt.
Langzeitgedächtnis: Abbildung 6 zeigt, dass das Langzeitgedächtnis erheblich dazu beitragen kann, die Stabilität der Eigenschaften von Objekten und Szenen während des autoregressiven Generierungsprozesses aufrechtzuerhalten.

Bei einer quantitativen Bewertungsmetrik (Personen-Re-Identifikations-Score) erzielte APM eine Verbesserung um 20 %.
Zufälliges Mischen zur Videoverbesserung: Im Vergleich zu den beiden anderen Benchmarks kann das zufällige Mischen erhebliche Qualitätsverbesserungen bringen. Aus Abbildung 4 ist auch ersichtlich: StreamingT2V kann flüssigere Übergänge erzielen.

StreamingT2V im Vergleich zum Basismodell
Das Team verglich die Integration des oben genannten verbesserten StreamingT2V mit mehreren Modellen, einschließlich der Bild-zu-Video-Methode I2VGen unter Verwendung eines autoregressiven Ansatzes, durch quantitative und qualitative Auswertungen XL, SVD, DynamiCrafter-XL, SEINE, Video-to-Video-Methode SparseControl, Text-to-Long-Video-Methode FreeNoise.
Quantitative Bewertung: Wie aus Tabelle 8 hervorgeht, zeigt die quantitative Bewertung des Testsatzes, dass StreamingT2V hinsichtlich des nahtlosen Videoblockübergangs und der Bewegungskonsistenz am besten abschneidet. Auch der MAWE-Score der neuen Methode ist deutlich besser als alle anderen Methoden – sogar mehr als 50 % niedriger als der zweitbeste SEINE. Ein ähnliches Verhalten ist in den SCuts-Ergebnissen zu beobachten.
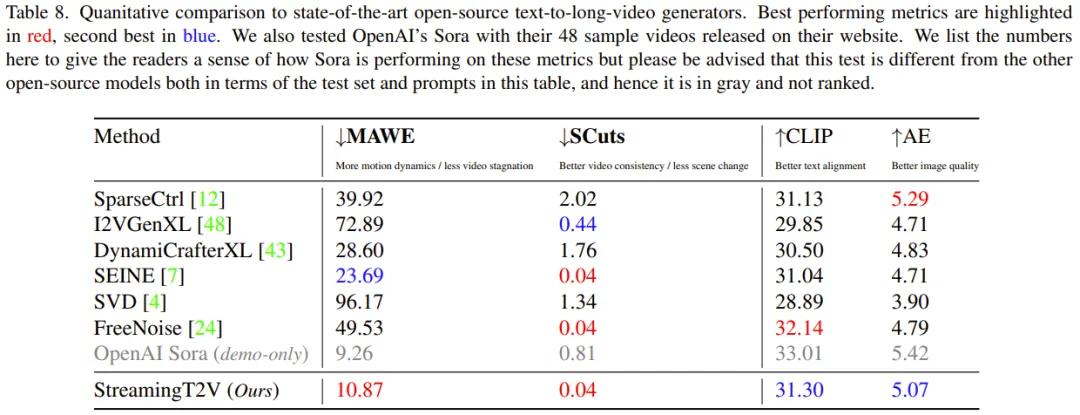
Außerdem ist StreamingT2V SparseCtrl hinsichtlich der Einzelbildqualität des generierten Videos nur geringfügig unterlegen. Dies zeigt, dass diese neue Methode in der Lage ist, qualitativ hochwertige lange Videos mit besserer zeitlicher Konsistenz und Bewegungsdynamik als andere Vergleichsmethoden zu generieren.
Qualitative Bewertung: Die folgende Abbildung zeigt den Vergleich der Auswirkungen von StreamingT2V mit anderen Methoden. Es ist ersichtlich, dass die neue Methode eine bessere Konsistenz beibehalten und gleichzeitig die dynamische Wirkung des Videos gewährleisten kann.

Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonStreamingT2V, ein Generator für lange Videos mit zwei Minuten und 1.200 Bildern, ist da, und der Code wird Open Source sein. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1653
1653
 14
1413
52
1305
25
1251
29
1224
24
14
1413
52
1305
25
1251
29
1224
24

 Was sind die zehn Top -Apps für virtuelle Währungshandel? Die neuesten Ranglisten für digitale Währung Exchange
Apr 28, 2025 pm 08:03 PM
Was sind die zehn Top -Apps für virtuelle Währungshandel? Die neuesten Ranglisten für digitale Währung Exchange
Apr 28, 2025 pm 08:03 PM
Die zehn Top -Börsen für digitale Währungen wie Binance, OKX, Gate.io haben ihre Systeme, effiziente diversifizierte Transaktionen und strenge Sicherheitsmaßnahmen verbessert.
 Welche der zehn besten Währungsplattformen der Welt sind die neueste Version der zehn besten Währungshandelsplattformen
Apr 28, 2025 pm 08:09 PM
Welche der zehn besten Währungsplattformen der Welt sind die neueste Version der zehn besten Währungshandelsplattformen
Apr 28, 2025 pm 08:09 PM
Zu den zehn Top -Kryptowährungs -Handelsplattformen der Welt gehören Binance, OKX, Gate.io, Coinbase, Kraken, Huobi Global, Bitfinex, Bittrex, Kucoin und Poloniex, die alle eine Vielzahl von Handelsmethoden und leistungsstarken Sicherheitsmaßnahmen bieten.
 Empfohlene zuverlässige Handelsplattformen für digitale Währung. Top 10 Digitalwährungsbörsen in der Welt. 2025
Apr 28, 2025 pm 04:30 PM
Empfohlene zuverlässige Handelsplattformen für digitale Währung. Top 10 Digitalwährungsbörsen in der Welt. 2025
Apr 28, 2025 pm 04:30 PM
Empfohlene zuverlässige Handelsplattformen für digitale Währung: 1. OKX, 2. Binance, 3. Coinbase, 4. Kraken, 5. Huobi, 6. Kucoin, 7. Bitfinex, 8. Gemini, 9. Bitstamp, 10. Poloniex, diese Plattformen sind für ihre Sicherheit, Benutzererfahrung und verschiedene Funziktionen, geeignet für Benutzer, geeignet für Benutzer, geeignet für Benutzer, geeignet für Benutzer, geeignet für Ufers, für Benutzer, geeignet für Ufersniveaus, in unterschiedlichen Digitalverkehrsniveaus, in unterschiedlichen Niveaus, bei Digitalwährung, für Nutzer, für Benutzer, in unterschiedliche Ebenen von Digitalwährung, für Benutzer, die für Nutzer, für Benutzer, in unterschiedlichen Digitalverkehrsniveaus, auf Digitalwährung, auf Digitalwährung, auf Digitalwährung, bei Digitalwährung, auf Digitalwährung bekannt
 Welche der zehn besten Währungshandelsplattformen der Welt gehören 2025 zu den zehn Top -Währungshandelsplattformen
Apr 28, 2025 pm 08:12 PM
Welche der zehn besten Währungshandelsplattformen der Welt gehören 2025 zu den zehn Top -Währungshandelsplattformen
Apr 28, 2025 pm 08:12 PM
Zu den zehn Top -Kryptowährungsbörsen der Welt im Jahr 2025 gehören Binance, OKX, Gate.io, Coinbase, Kraken, Huobi, Bitfinex, Kucoin, Bittrex und Poloniex, die alle für ihr hohes Handelsvolumen und ihre Sicherheit bekannt sind.
 Wie viel ist Bitcoin wert?
Apr 28, 2025 pm 07:42 PM
Wie viel ist Bitcoin wert?
Apr 28, 2025 pm 07:42 PM
Der Preis von Bitcoin liegt zwischen 20.000 und 30.000 US -Dollar. 1. Bitcoin's Preis hat seit 2009 dramatisch geschwankt und im Jahr 2017 fast 20.000 US -Dollar und im Jahr 2021 in Höhe von fast 60.000 USD erreicht. 2. Die Preise werden von Faktoren wie Marktnachfrage, Angebot und makroökonomischem Umfeld beeinflusst. 3. Erhalten Sie Echtzeitpreise über Börsen, mobile Apps und Websites. V. 5. Es hat eine gewisse Beziehung zu den traditionellen Finanzmärkten und ist von den globalen Aktienmärkten, der Stärke des US-Dollars usw. betroffen. 6. Der langfristige Trend ist optimistisch, aber Risiken müssen mit Vorsicht bewertet werden.
 Was sind die Top -Währungshandelsplattformen? Die Top 10 neuesten virtuellen Währungsbörsen
Apr 28, 2025 pm 08:06 PM
Was sind die Top -Währungshandelsplattformen? Die Top 10 neuesten virtuellen Währungsbörsen
Apr 28, 2025 pm 08:06 PM
Derzeit unter den zehn besten Börsen der virtuellen Währung eingestuft: 1. Binance, 2. OKX, 3. Gate.io, 4. Coin Library, 5. Siren, 6. Huobi Global Station, 7. Bybit, 8. Kucoin, 9. Bitcoin, 10. Bit Stamp.
 Decryption Gate.io Strategy Upgrade: Wie definieren Sie das Krypto -Asset -Management in Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Decryption Gate.io Strategy Upgrade: Wie definieren Sie das Krypto -Asset -Management in Memebox 2.0?
Apr 28, 2025 pm 03:33 PM
Memebox 2.0 definiert das Krypto -Asset -Management durch innovative Architektur- und Leistungsbrachdurchbrüche. 1) Es löst drei Hauptschmerzpunkte: Vermögenssetsilos, Einkommensverfall und Paradox der Sicherheit und Bequemlichkeit. 2) Durch intelligente Asset-Hubs werden dynamische Risikomanagement- und Renditeverstärkungsmotoren die Übertragungsgeschwindigkeit, die durchschnittliche Ertragsrate und die Reaktionsgeschwindigkeit für Sicherheitsvorfälle verbessert. 3) Nutzern die Integration von Asset Visualisierung, Richtlinienautomatisierung und Governance -Integration zur Verfügung stellen und die Rekonstruktion des Benutzerwerts realisieren. 4) Durch ökologische Zusammenarbeit und Compliance -Innovation wurde die Gesamtwirksamkeit der Plattform verbessert. 5) In Zukunft werden intelligente Vertragsversicherungspools, die Prognosemarktintegration und die KI-gesteuerte Vermögenszuweisung gestartet, um weiterhin die Entwicklung der Branche zu leiten.
 Wie misst ich die Thread -Leistung in C?
Apr 28, 2025 pm 10:21 PM
Wie misst ich die Thread -Leistung in C?
Apr 28, 2025 pm 10:21 PM
Durch die Messung der Thread -Leistung in C kann Timing -Tools, Leistungsanalyse -Tools und benutzerdefinierte Timer in der Standardbibliothek verwendet werden. 1. Verwenden Sie die Bibliothek, um die Ausführungszeit zu messen. 2. Verwenden Sie GPROF für die Leistungsanalyse. Zu den Schritten gehört das Hinzufügen der -PG -Option während der Kompilierung, das Ausführen des Programms, um eine Gmon.out -Datei zu generieren, und das Generieren eines Leistungsberichts. 3. Verwenden Sie das Callgrind -Modul von Valgrind, um eine detailliertere Analyse durchzuführen. Zu den Schritten gehört das Ausführen des Programms zum Generieren der Callgrind.out -Datei und das Anzeigen der Ergebnisse mit KCACHEGRIND. 4. Benutzerdefinierte Timer können die Ausführungszeit eines bestimmten Codesegments flexibel messen. Diese Methoden helfen dabei, die Thread -Leistung vollständig zu verstehen und den Code zu optimieren.
