

15 empfohlene kostenlose Open-Source-Bildanmerkungstools

Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Bildanmerkungen haben ein breites Anwendungsspektrum und decken viele Bereiche ab, wie z. B. Computer Vision, Verarbeitung natürlicher Sprache und Grafiken und Diagnose von Krankheiten durch medizinische Bildidentifikation.
In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesense.ai fc4c96329531345635a4baa9

2.Labelme
https://www.php.cn/link/fd8979ada2fd5bab05e9c5f035a5c4c7
 Labelme ist ein Python-basiertes Bildbeschriftungstool, das verschiedene Beschriftungstypen unterstützt und Benutzerdefiniert bereitstellt GUI anpassen. Datensätze in den Formaten VOC und COCO können zur Semantik- und Instanzsegmentierung exportiert werden.
Labelme ist ein Python-basiertes Bildbeschriftungstool, das verschiedene Beschriftungstypen unterstützt und Benutzerdefiniert bereitstellt GUI anpassen. Datensätze in den Formaten VOC und COCO können zur Semantik- und Instanzsegmentierung exportiert werden.
Funktionen:
Unterstützt Markierungsanmerkungen auf Polygon-, Rechteck-, Kreis-, Linien-, Punkt- und Bildebene.Verfügbar für Ubuntu, macOS und Windows.
Anmerkungsinformationen als JSON-Datei speichern.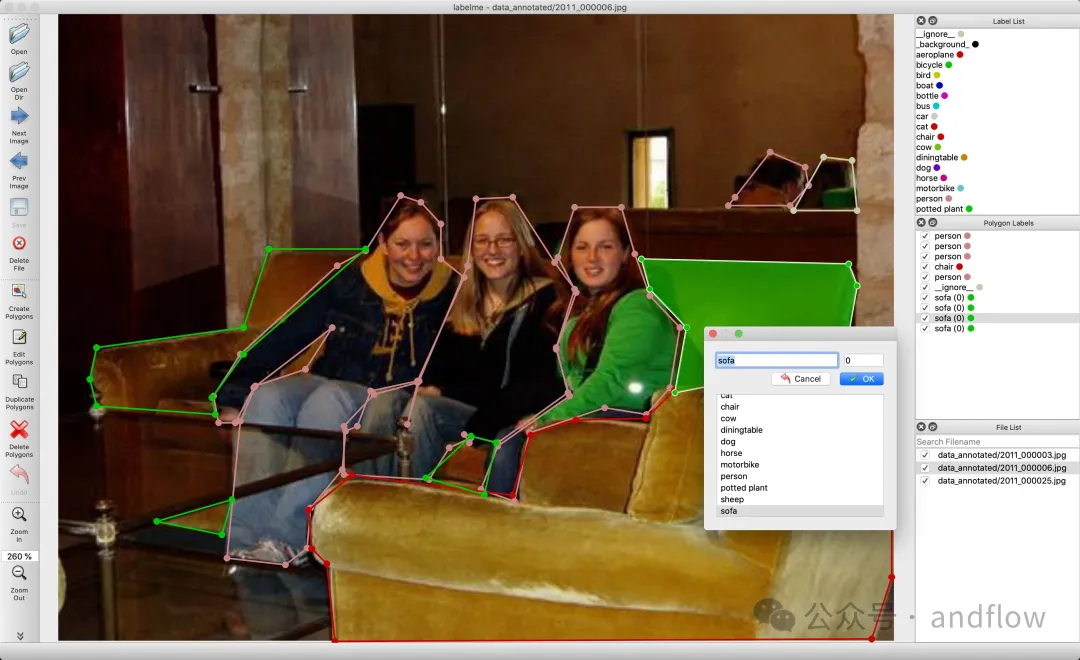 Erweitertes Anwendungsbeispiel.
Erweitertes Anwendungsbeispiel.
Markup zuweisen zu gesamtes Bild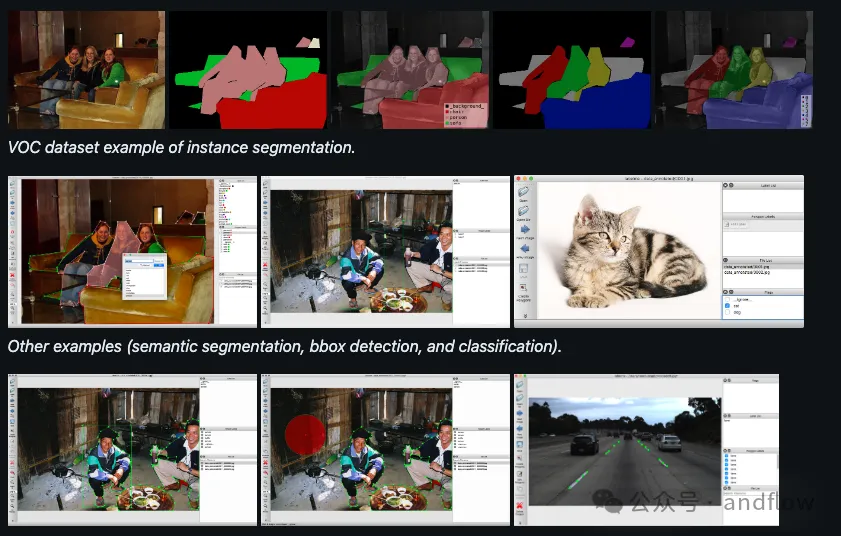
- Funktionen:
- Unterstützt Datenanmerkungen für Bilder, 3D-LiDAR und 2D/3D-Sensorfusionsdatensätze
- Eingebaute vorbeschriftete und interaktive Modelle unterstützen die Erkennung, Segmentierung und Klassifizierung von 2D/3D-Objekten
- Konfigurierbares Ontologiezentrum, z allgemeine Klassen (mit Hierarchien) und Attribute für das Modelltraining
- Datenmanagement und Qualitätsüberwachung
- Tools zum Finden und Beheben von Beschriftungsfehlern
Visualisierung von Modellergebnissen zur Unterstützung der Modellbewertung Für große Sprachmodelle RLHF (Betaversion)
Einfache Installation mit Docker oder aus der Quelle
4.Label Studio
- Label Studio ist ein Open-Source-Tools zur Kennzeichnung von Daten Typen wie Audio, Text, Bilder, Videos und Zeitreihen.
- Es verfügt über eine benutzerfreundliche Oberfläche, kann Daten in standardisierten Formaten exportieren, unterstützt integrierte Modelle für maschinelles Lernen und kann für bestimmte Projekte angepasst werden.
- Es basiert auf der Open-Source-Lizenz Apache-2.0.
- Benutzerdefinierte Annotationspipeline
- Erweiterbare Anwendung
- Einfache Verbindung zu externen Dateisystemen wie S3 Bucket oder Azure Blobstorage
- Visualisieren Sie den Annotationsprozess im Browser.
- Kann lokal oder auf dem Webserver konfiguriert werden.
- Unterstützt das Organisieren von Tag-Bäumen Erstellung von Anmerkungsvorschlägen
- Einzelbild-Anmerkungstool (SIA) zum Kommentieren von Bboxen, Polygonen, Punkten oder Linien
- Mehrbild-Anmerkungstool (MIA) zum Kommentieren ganzer Bildcluster
- Anmerkungsfunktionen exportieren
- Anmerkungsstatistiken basierend auf Einzelpersonen und Projekte
- Farbige Tag-Bäume für die Tag-Organisation
- Anmerkungsfunktionen anzeigen
- Pipeline-Projektimport und -Export
- Pipeline-Projektfreigabe
- Integration von Jupyter-Lab zur einfachen Entwicklung von Pipelines
- LDAP integriert
- E-Mail-Benachrichtigungen
- Skalierbares Design zur Verteilung intensive Rechenprozesse über mehrere Maschinen hinweg ) ist ein interaktives Tool für Video und Bildanmerkung, weit verbreitet in der Computer Vision. Es unterstützt einen datenzentrierten Ansatz für künstliche Intelligenz und ist kostenlos online oder mit Abonnement für zusätzliche Funktionen verfügbar. CVAT kann auch privat installiert werden und bietet Unternehmensunterstützung für erweiterte Funktionen.
- 7.Gromit-MPX
- https://www.php.cn/link/388ac20c845a327f97edece8acba6237
- Zeichnen Sie Begrenzungsrahmen und Polygone für die Objektanmerkung.
- Verwenden Sie Funktionen für Polygonoperationen, um Punkte zu bearbeiten, zu entfernen und hinzuzufügen.
- Unterstützt verschiedene Datensatzformate.
- Unterstützt die automatische Annotation mithilfe des „COCO-SSD“-Modells.
- Lokale Läufe zur Pflege Datenschutz
- Ermöglicht den Import und die Weiterverarbeitung bestehender Annotationsprojekte
- Kann zum Konvertieren von Datensätzen von einem Format in ein anderes verwendet werden
- Webbasiertes Tool
- Effiziente und vielseitige Bildbeschriftung
- Entwickelt für die Erstellung von Trainingsdaten zur Bildlokalisierung und Objekterkennung
- Segmentbeschriftung
- Objektinstanzverfolgung
- Beschriftung mit Unterbrechungen
- Speichern und exportieren Anmerkungen im COCO-Format
- Intuitive und anpassbare Benutzeroberfläche
- Ermöglicht Benutzern die manuelle Definition von Bereichen im Bild
- Erstellen von Textbeschreibungen
- über Begrenzungsrahmen, Maskierungswerkzeuge oder Markierungspunkte Objektmarkierungen
- Freiformkurven- oder Polygonanmerkungen
- Direkt Export in das COCO-Format
- Segmentierung von Objekten
- Möglichkeit zum Hinzufügen von Schlüsselpunkten
- Nützliche API-Endpunkte für die Datenanalyse
- Importieren von Datensätzen im COCO-Format
- Annotieren getrennter Objekte als einzelne Instanzen
- Beschriften von Bildfragmenten gleichzeitig mit einer beliebigen Anzahl von Beschriftungen
- Ermöglicht benutzerdefinierte Metadaten für jede Instanz oder jedes Objekt.
- Erweiterte Auswahltools wie DEXTR, MaskRCNN und Magic Wand.
- Verwenden Sie Anmerkungsbilder für halbe Trainingsmodelle.
- Verwenden Sie Google-Bilder, um Datensätze zu generieren
- https://www.php.cn/link/c4dc035d67bc669546c560622ac4bdd4
- Beschriften Sie Gesichter und Pixel mit dem Segment Anything-Modell.
- Automatisches Markieren mit Core-ML-Modellen.
- Automatische Texterkennung von Linien und Wörtern Beschriftungsorientierte Begrenzungsrahmen
- Schlüsselpunkte mit Skeletten markieren
- Pixel mit Pinseln und Superpixeln markieren
- Objekte, Eigenschaften, Hotkeys und Beschriftungen schnell einrichten
- In der Galerieansicht nach Objekten, Eigenschaften und Bildnamen suchen
- Als COCO exportieren , Labelme, COML, YOLO, DOTA und CSV-Formate
- Exportieren Sie indizierte Farbmaskenbilder und Graustufenmaskenbilder
- Videos in Bildrahmen, verbesserte Bilder und mehr. 13.OpenLabeling
- OpenLabeling ist ein Open-Source-Tool zum Beschriften von Bildern und Videos. Es unterstützt mehrere Formate wie PASCAL VOC und YOLO Darknet.
- Dieses Tool wurde verwendet für: Deep-Learning-Objekterkennungsmodelle, störungsbewusste siamesische Netzwerke für die visuelle Objektverfolgung, Begrenzungsrahmenverfolgung und den OpenCV-Tracker für die Videoobjektverfolgung.
- 14.bbox-visualizer
5. Lostthttps://www.php.cn/link/254b6cccc84A3B7E5C6967C9EF656E
LOST (Label Object and Save Time) ist ein webbasiertes Bildkollaborationstool. Es bietet vorgefertigte Annotationspipelines für die spontane Bildannotation ohne Programmierkenntnisse, ermöglicht Benutzern aber auch die Definition von Annotationspipelines.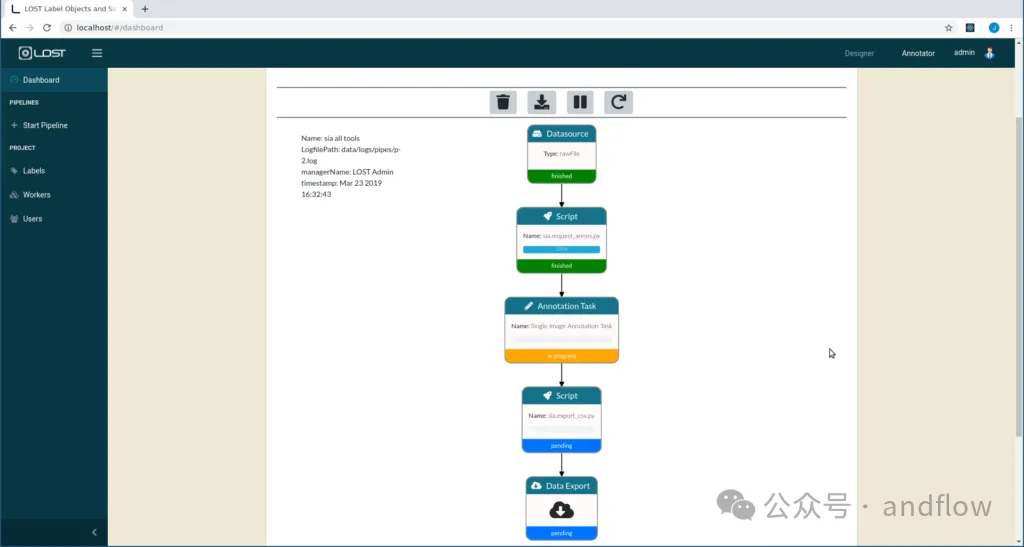 Die Anwendung ist erweiterbar und kann problemlos eine Verbindung zu externen Dateisystemen wie S3 Bucket oder Azure Blobstorage herstellen. Es kann lokal oder auf einem Webserver eingerichtet werden und unterstützt Organisationen beim Erstellen von Tag-Bäumen, der Überwachung des Tagging-Prozesses und des In-Browser-Taggings.
Die Anwendung ist erweiterbar und kann problemlos eine Verbindung zu externen Dateisystemen wie S3 Bucket oder Azure Blobstorage herstellen. Es kann lokal oder auf einem Webserver eingerichtet werden und unterstützt Organisationen beim Erstellen von Tag-Bäumen, der Überwachung des Tagging-Prozesses und des In-Browser-Taggings.
Hauptfunktionen:
Kollaboratives webbasiertes Bildannotations-Framework Vorgefertigte Annotationspipeline für sofortige Bildannotation8.MyVision MyVision ist ein kostenloses Online-Bildanmerkungstool zur Erstellung von Schulungen für maschinelles Lernen im Bereich Computer Vision Daten. Unterstützt das Zeichnen von Begrenzungsrahmen und Polygonen für Objektanmerkungen und Polygonoperationen sowie verschiedene Datensatzformate. Es unterstützt auch die automatische Annotation mithilfe des „COCO-SSD“-Modells, das lokal betrieben werden kann, um Datenschutz und Sicherheit zu gewährleisten.
Unterstützte Datenformate:Funktionsmerkmale: 
9. LabelImg
https://www. php.cn/link/112a8e92dcedcda4237de18e9126b2d 2
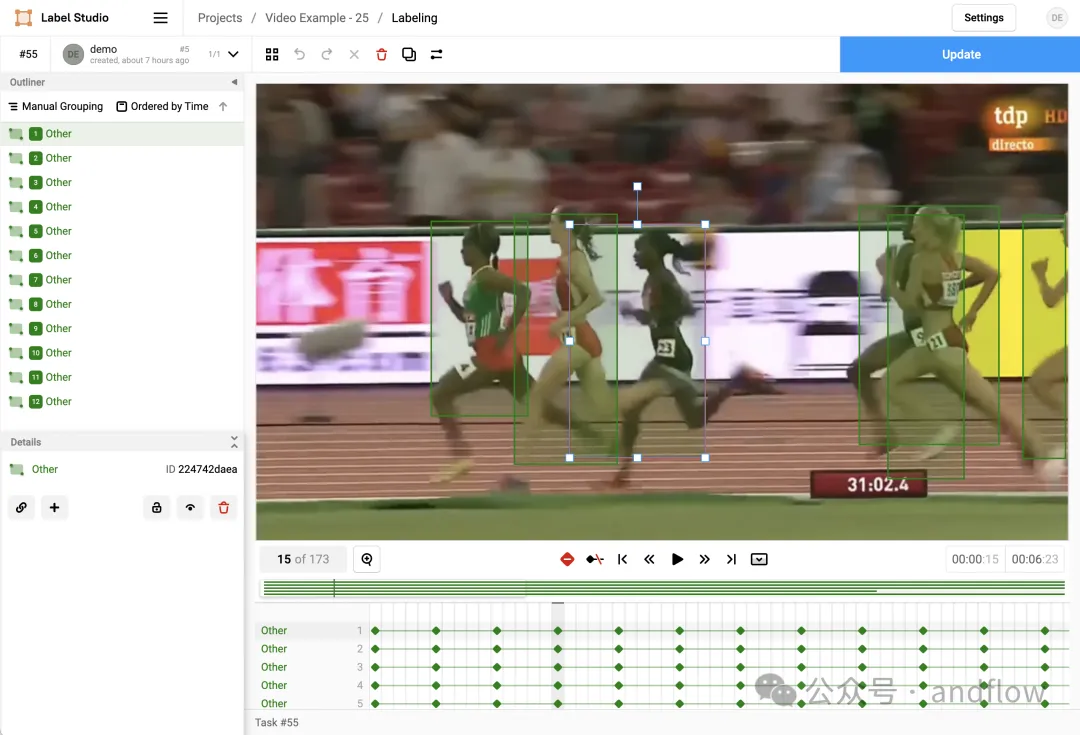
LabelImg ist ein beliebtes Bildanmerkungstool, das der Label Studio-Community beigetreten ist und nicht mehr aktiv weiterentwickelt wird. Label Studio ist ein flexibles Open-Source-Datenkennzeichnungstool für verschiedene Datentypen, darunter Bilder, Text, Audio-, Video- und Zeitreihendaten.
Die Anmerkungsinformationen in LabelImg werden im PASCAL VOC-Format gespeichert. Darüber hinaus werden auch die Formate YOLO und XML unterstützt.
10.Coco Annotator
https://www.php.cn/link/e3743b463beb38a2a24eebe5ecbad410

COCO Annotator ist ein webbasiertes, effizientes und vielseitiges Bildbeschriftungstool, das für das Training der Bildpositionierung und Objekterkennung entwickelt wurde Erstellen Sie einen Datensatz.
Zu den bereitgestellten Funktionen gehören Segmentmarkierung, Verfolgung von Objektinstanzen und Markierung von Objekten mit nicht verbundenen sichtbaren Teilen. Es speichert und exportiert Notizen im COCO-Format über eine intuitive und anpassbare Benutzeroberfläche.
Funktionen:
 Universal Data Tool ist eine vielseitige Anwendung zum Bearbeiten und Kommentieren von Datentypen wie Bildern, Text, Audio und Dokumenten. Es unterstützt Aufgaben wie Bildsegmentierung, Textklassifizierung und Audiotranskription. Das Tool ermöglicht die Zusammenarbeit in Echtzeit, läuft auf verschiedenen Plattformen und unterstützt mehrere Datenformate.
Universal Data Tool ist eine vielseitige Anwendung zum Bearbeiten und Kommentieren von Datentypen wie Bildern, Text, Audio und Dokumenten. Es unterstützt Aufgaben wie Bildsegmentierung, Textklassifizierung und Audiotranskription. Das Tool ermöglicht die Zusammenarbeit in Echtzeit, läuft auf verschiedenen Plattformen und unterstützt mehrere Datenformate.
12.RectLabel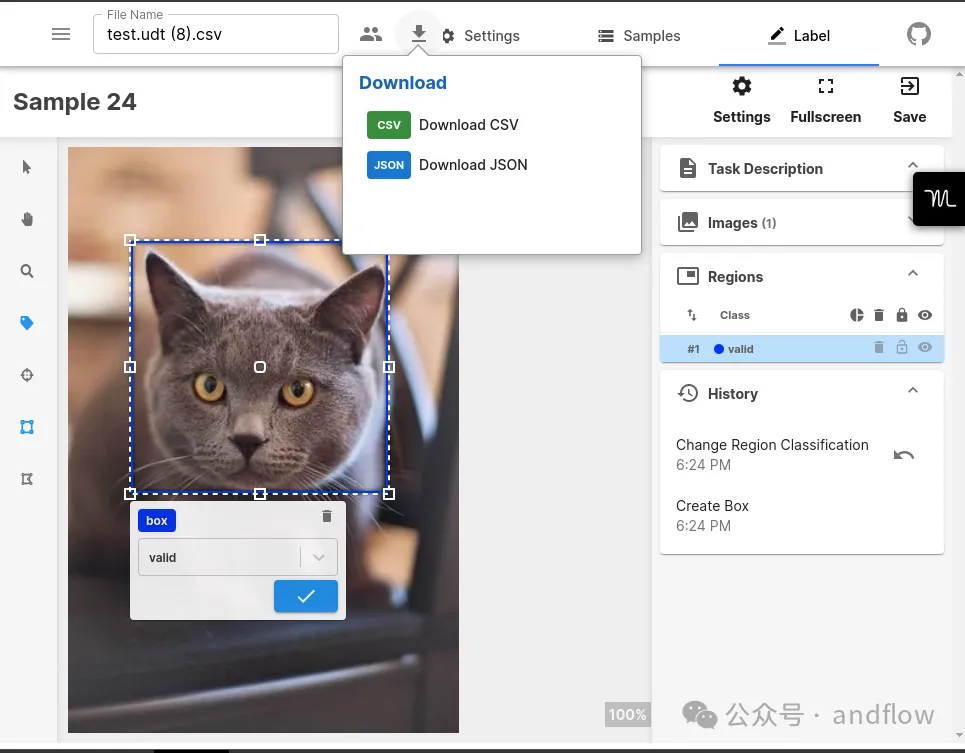
https://www.php.cn/link/1b31a4f23c784d5b162a3066fa9aaf4f
Label ist ein Offline-Bildanmerkungstool, das zur Objekterkennung und -segmentierung verwendet werden kann.
Hauptmerkmale: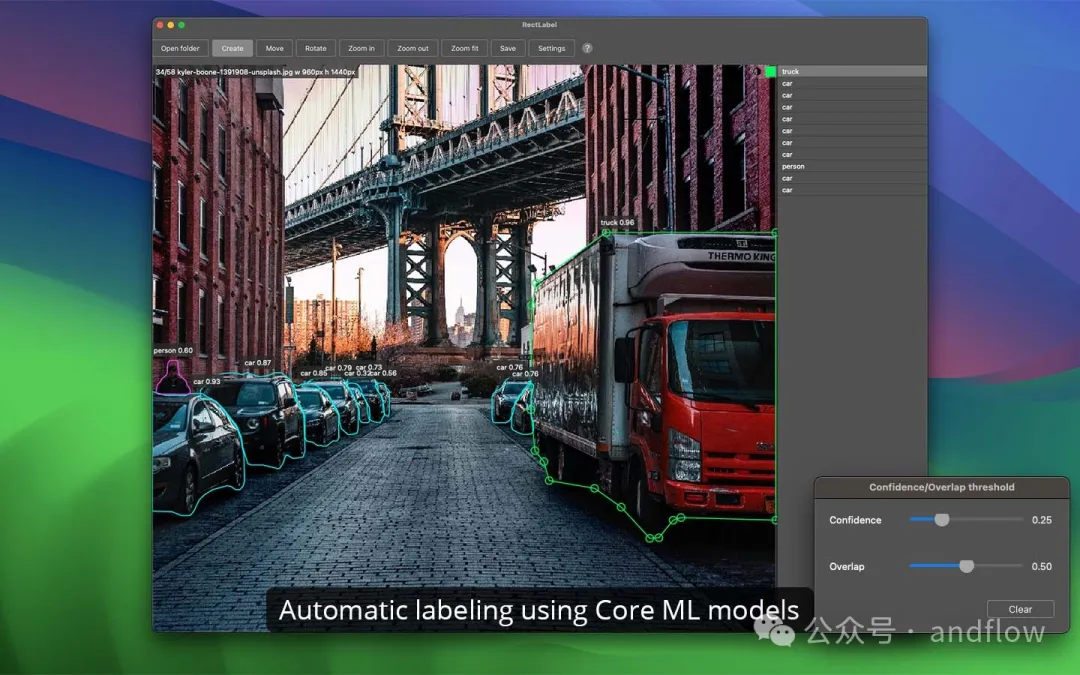
 bbox-visualizer kann Benutzern dabei helfen, Begrenzungsrahmen um Objekte zu zeichnen, wodurch die komplexe Mathematik für die Berechnung der Etikettenpositionierung entfällt . Es bietet verschiedene Visualisierungstypen zur Beschriftung von Objekten nach der Erkennung. Das Datenformat der Begrenzungsrahmenpunkte ist: (xmin, ymin, xmax, ymax).
bbox-visualizer kann Benutzern dabei helfen, Begrenzungsrahmen um Objekte zu zeichnen, wodurch die komplexe Mathematik für die Berechnung der Etikettenpositionierung entfällt . Es bietet verschiedene Visualisierungstypen zur Beschriftung von Objekten nach der Erkennung. Das Datenformat der Begrenzungsrahmenpunkte ist: (xmin, ymin, xmax, ymax).
15.PixelAnnotationTool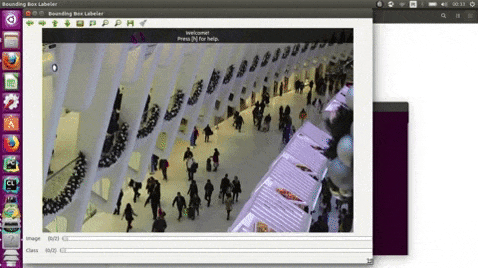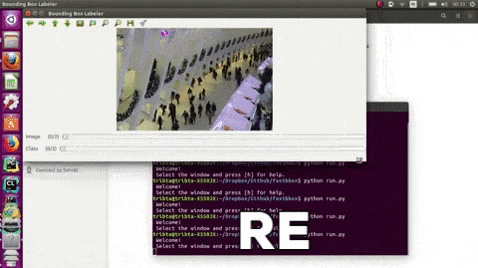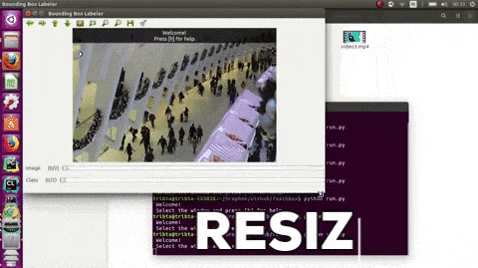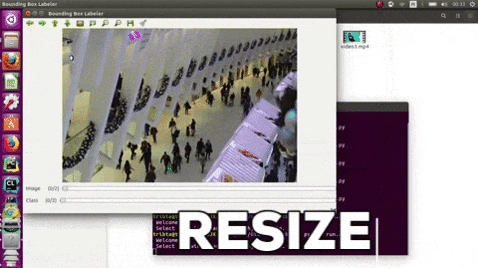
https://www.php.cn/link/2e3e809d4082093c8bbf499ae9966cfc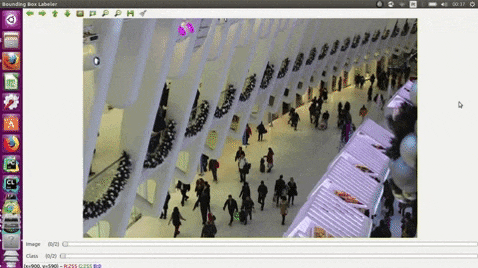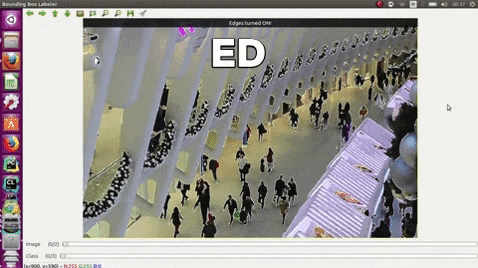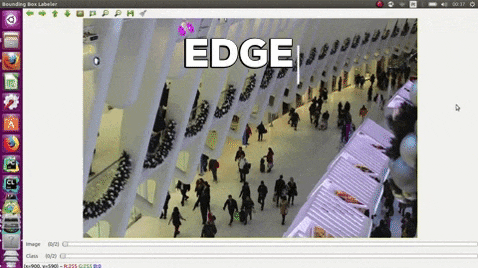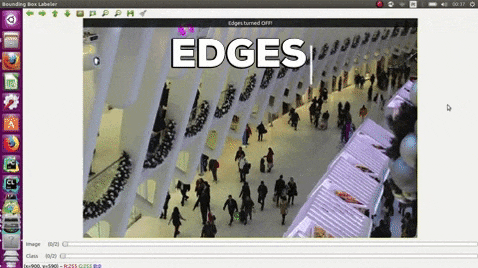
Das obige ist der detaillierte Inhalt von15 empfohlene kostenlose Open-Source-Bildanmerkungstools. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Apr 29, 2024 pm 04:55 PM
FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht länger das „Patent“ von H100! Lao Huang wollte, dass jeder INT8/INT4 nutzt, und das Microsoft DeepSpeed-Team begann, FP6 auf A100 ohne offizielle Unterstützung von NVIDIA auszuführen. Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 nahe an INT4 liegt oder gelegentlich schneller als diese ist und eine höhere Genauigkeit aufweist als letztere. Darüber hinaus gibt es eine durchgängige Unterstützung großer Modelle, die als Open-Source-Lösung bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde. Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – in diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten. eins
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
Ist Flash Attention stabil? Meta und Harvard stellten fest, dass die Gewichtsabweichungen ihrer Modelle um Größenordnungen schwankten
May 30, 2024 pm 01:24 PM
MetaFAIR hat sich mit Harvard zusammengetan, um einen neuen Forschungsrahmen zur Optimierung der Datenverzerrung bereitzustellen, die bei der Durchführung groß angelegten maschinellen Lernens entsteht. Es ist bekannt, dass das Training großer Sprachmodelle oft Monate dauert und Hunderte oder sogar Tausende von GPUs verwendet. Am Beispiel des Modells LLaMA270B erfordert das Training insgesamt 1.720.320 GPU-Stunden. Das Training großer Modelle stellt aufgrund des Umfangs und der Komplexität dieser Arbeitsbelastungen einzigartige systemische Herausforderungen dar. In letzter Zeit haben viele Institutionen über Instabilität im Trainingsprozess beim Training generativer SOTA-KI-Modelle berichtet. Diese treten normalerweise in Form von Verlustspitzen auf. Beim PaLM-Modell von Google kam es beispielsweise während des Trainingsprozesses zu Instabilitäten. Numerische Voreingenommenheit ist die Hauptursache für diese Trainingsungenauigkeit.
