
 Technologie-Peripheriegeräte
KI
DifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!
Technologie-Peripheriegeräte
KI
DifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!
DifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!

Originaltitel: DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
Papierlink: https://arxiv.org/pdf/2311.17456.pdf
Codelink: https://github. com/IRMVLab/DifFlow3D
Autorenzugehörigkeit: Shanghai Jiao Tong University Cambridge University Zhejiang University Intelligent Robot

Thesis-Idee:
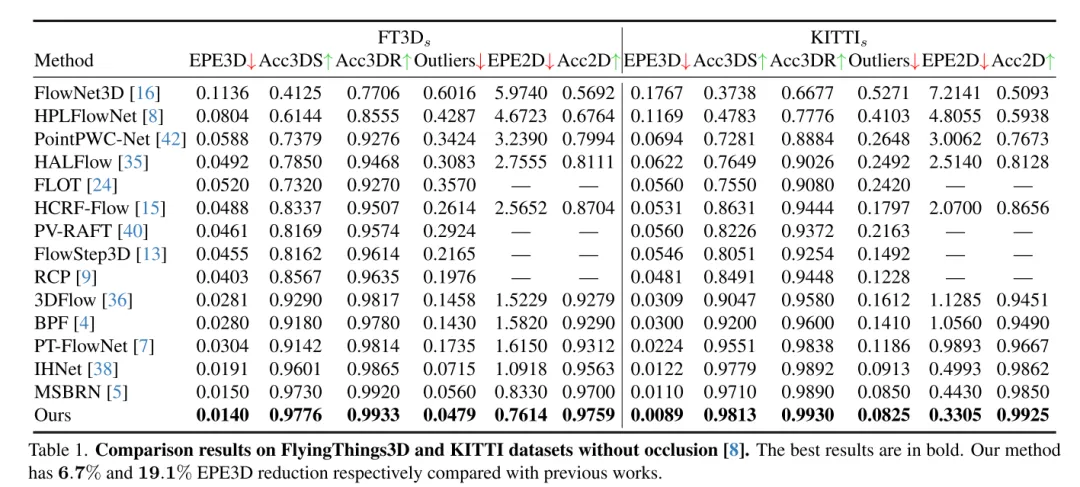
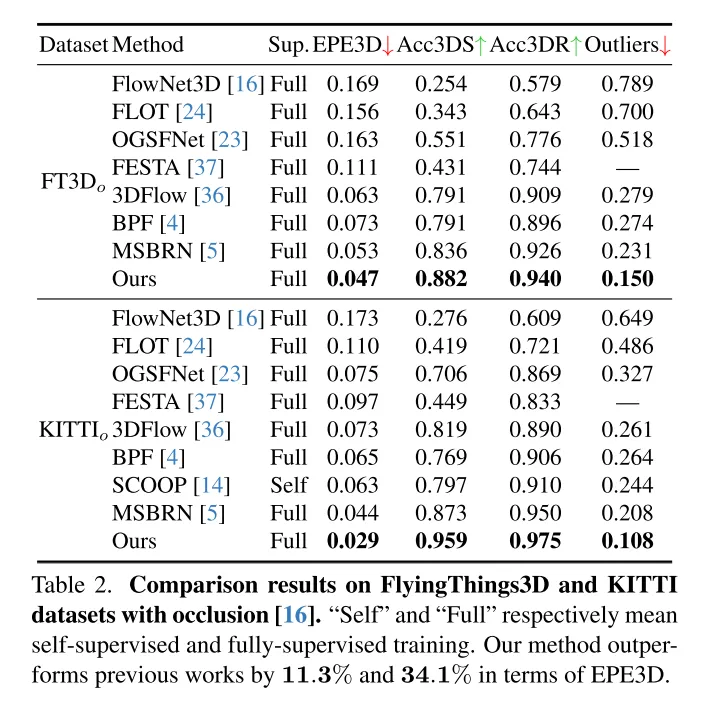
Szenenflussschätzung zielt darauf ab, die 3D-Verschiebungsänderung jedes Punktes in einer dynamischen Szene vorherzusagen. Es ist eine grundlegende Aufgabe im Bereich Computer Vision. Frühere Arbeiten leiden jedoch häufig unter unzuverlässigen Korrelationen, die durch lokal begrenzte Suchbereiche verursacht werden, und häufen Ungenauigkeiten in groben bis feinen Strukturen an. Um diese Probleme zu lindern, schlägt dieser Artikel ein neuartiges, unsicherheitsbewusstes Netzwerk zur Schätzung des Szenenflusses (DifFlow3D) vor, das ein Diffusions-Wahrscheinlichkeitsmodell verwendet. Die iterative diffusionsbasierte Verfeinerung soll die Robustheit der Korrelation verbessern und eine starke Anpassungsfähigkeit an schwierige Situationen (z. B. Dynamik, verrauschte Eingaben, wiederholte Muster usw.) bieten. Um die Vielfalt der Erzeugung zu begrenzen, werden in unserem Diffusionsmodell drei wichtige strömungsbezogene Merkmale als Bedingungen ausgenutzt. Darüber hinaus wird in diesem Artikel ein Unsicherheitsschätzungsmodul für die Diffusion entwickelt, um die Zuverlässigkeit des geschätzten Szenenflusses zu bewerten. DifFlow3D dieses Artikels erreicht eine Reduzierung der dreidimensionalen Endpunktfehler (EPE3D) um 6,7 % bzw. 19,1 % bei den Datensätzen FlyingThings3D und KITTI 2015 und erreicht eine beispiellose Genauigkeit auf Millimeterebene beim KITTI-Datensatz (0,0089 Meter für EPE3D). Darüber hinaus kann unser diffusionsbasiertes Verfeinerungsparadigma problemlos als Plug-and-Play-Modul in bestehende Szenenflussnetzwerke integriert werden, wodurch deren Schätzgenauigkeit erheblich verbessert wird.
Hauptbeiträge:
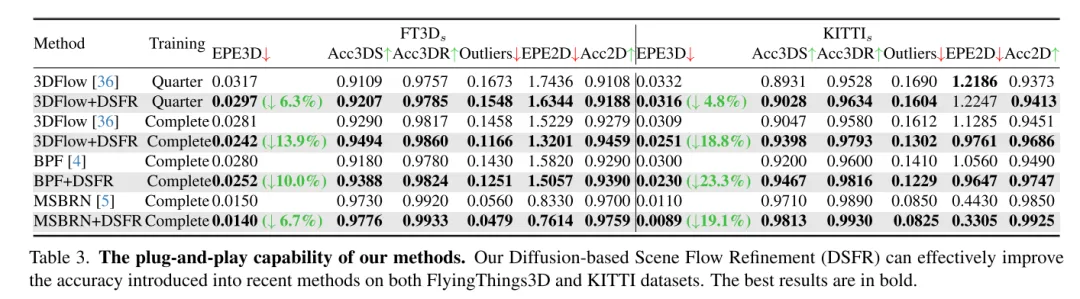
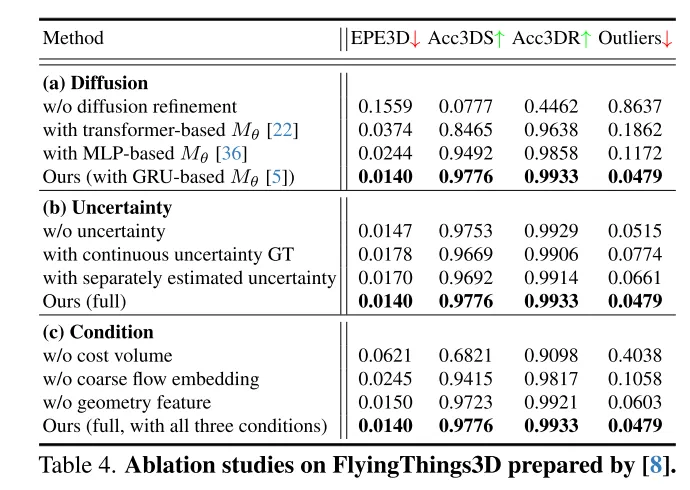
Um eine robuste Szenenflussschätzung zu erreichen, schlägt diese Studie einen neuen diffusionsbasierten Plug-and-Play-Verfeinerungsprozess vor. Nach unserem besten Wissen ist dies das erste Mal, dass ein Diffusions-Wahrscheinlichkeitsmodell in einer Szenenflussaufgabe eingesetzt wurde.
Der Autor kombiniert Techniken wie grobe Flusseinbettung, geometrische Kodierung und Cross-Frame-Kostenvolumina, um eine effektive bedingte Führungsmethode zur Steuerung der Vielfalt der generierten Ergebnisse zu entwerfen.
Um die Zuverlässigkeit der Flüsse in diesem Artikel zu bewerten und ungenaue Punktübereinstimmungen zu identifizieren, führen die Autoren auch Unsicherheitsschätzungen für jeden Punkt im Diffusionsmodell ein.
Die Forschungsergebnisse zeigen, dass die in diesem Artikel vorgeschlagene Methode bei den FlyingThings3D- und KITTI-Datensätzen eine gute Leistung erbringt und andere bestehende Methoden übertrifft. Insbesondere erreicht DifFlow3D zum ersten Mal einen Endpunktfehler auf Millimeterebene (EPE3D) im KITTI-Datensatz. Im Vergleich zu früheren Untersuchungen ist unsere Methode robuster im Umgang mit herausfordernden Situationen wie lauten Eingaben und dynamischen Änderungen.
Netzwerkdesign:
Als grundlegende Aufgabe in der Bildverarbeitung bezeichnet Szenenfluss die Schätzung eines dreidimensionalen Bewegungsfelds aus kontinuierlichen Bildern oder Punktwolken. Es liefert Informationen für die Wahrnehmung dynamischer Szenen auf niedriger Ebene und verfügt über verschiedene nachgelagerte Anwendungen, wie etwa autonomes Fahren [21], Posenschätzung [9] und Bewegungssegmentierung [1]. Frühe Arbeiten konzentrierten sich auf die Verwendung von Stereo- [12] oder RGB-D-Bildern [10] als Eingabe. Mit der zunehmenden Beliebtheit von 3D-Sensoren wie Lidar verwenden neuere Arbeiten häufig Punktwolken direkt als Eingabe.
Als Pionierarbeit verwendet FlowNet3D[16] PointNet++[25], um hierarchische Merkmale zu extrahieren, und führt dann eine iterative Regression des Szenenflusses durch. PointPWC [42] verbessert es weiter durch Pyramiden-, Verformungs- und Kostenvolumenstrukturen [31]. HALFlow [35] folgt ihnen und führt einen Aufmerksamkeitsmechanismus zur besseren Flusseinbettung ein. Diese regressionsbasierten Arbeiten leiden jedoch häufig unter unzuverlässigen Korrelationen und lokalen Optimaproblemen [17]. Dafür gibt es zwei Hauptgründe: (1) In ihrem Netzwerk werden K nächste Nachbarn (KNN) zur Suche nach Punktkorrespondenzen verwendet, wobei korrekte, aber entfernte Punktpaare nicht berücksichtigt werden, und es gibt auch Übereinstimmungsrauschen [7]. (2) Ein weiteres potenzielles Problem ergibt sich aus der in früheren Arbeiten weit verbreiteten Grob-Fein-Struktur [16, 35, 36, 42]. Grundsätzlich wird der anfängliche Fluss auf der gröbsten Schicht geschätzt und dann iterativ in höheren Auflösungen verfeinert. Die Leistung der Strömungsverfeinerung hängt jedoch stark von der Zuverlässigkeit der anfänglichen Grobströmung ab, da nachfolgende Verfeinerungen normalerweise auf eine kleine räumliche Ausdehnung um die Initialisierung herum beschränkt sind.
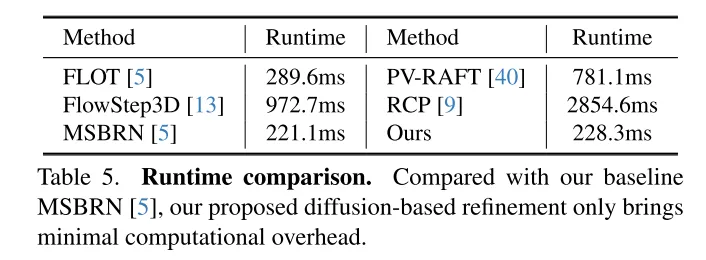
Um das Problem der Unzuverlässigkeit zu lösen, hat 3DFlow[36] ein All-to-All-Punkteerfassungsmodul entwickelt und eine umgekehrte Überprüfung hinzugefügt. In ähnlicher Weise schlagen Bi-PointFlowNet [4] und seine Erweiterung MSBRN [5] ein bidirektionales Netzwerk mit Vorwärts-Rückwärts-Korrelation vor. IHNet [38] nutzt ein wiederkehrendes Netzwerk mit einem hochauflösenden Bootstrapping- und Resampling-Schema. Allerdings leiden die meisten dieser Netzwerke aufgrund ihrer bidirektionalen Korrelationen oder Schleifeniterationen unter Rechenkosten. In diesem Artikel wird festgestellt, dass Diffusionsmodelle dank ihrer entrauschenden Natur (dargestellt in Abbildung 1) auch die Zuverlässigkeit von Korrelationen und die Widerstandsfähigkeit gegenüber Anpassungsrauschen verbessern können. Inspiriert von der Entdeckung in [30], dass die Injektion von zufälligem Rauschen dazu beiträgt, aus dem lokalen Optimum herauszuspringen, rekonstruiert dieser Artikel die deterministische Flussregressionsaufgabe mithilfe eines probabilistischen Diffusionsmodells, wie in Abbildung 2 dargestellt. Darüber hinaus kann unsere Methode als Plug-and-Play-Modul verwendet werden, um das vorherige Szenenflussnetzwerk zu bedienen, das allgemeiner ist und fast keine Rechenkosten verursacht (Abschnitt 4.5).
Allerdings ist die Nutzung generativer Modelle in der Aufgabe dieser Arbeit aufgrund der inhärenten generativen Vielfalt von Diffusionsmodellen eine ziemliche Herausforderung. Im Gegensatz zur Punktwolkengenerierungsaufgabe, die verschiedene Ausgabebeispiele erfordert, ist die Szenenflussvorhersage eine deterministische Aufgabe, die präzise Bewegungsvektoren pro Punkt berechnet. Um dieses Problem zu lösen, nutzt dieser Artikel starke bedingte Informationen, um die Diversität zu begrenzen und den erzeugten Fluss effektiv zu steuern. Insbesondere wird zunächst ein grober, spärlicher Szenenfluss initialisiert, und dann werden durch Diffusion iterativ Flussreste generiert. In jeder diffusionsbasierten Verfeinerungsschicht nutzen wir Grobströmungseinbettung, Kostenvolumen und geometrische Kodierung als Bedingungen. In diesem Fall wird Diffusion angewendet, um tatsächlich eine probabilistische Zuordnung von bedingten Eingaben zu Stream-Residuen zu lernen.
Darüber hinaus haben nur wenige frühere Arbeiten die Zuverlässigkeit und Zuverlässigkeit der Szenenflussschätzung untersucht. Wie in Abbildung 1 dargestellt, ist das Dense-Flow-Matching jedoch bei Vorhandensein von Rauschen, dynamischen Änderungen, kleinen Objekten und sich wiederholenden Mustern fehleranfällig. Daher ist es sehr wichtig zu wissen, ob jede geschätzte Punktkorrespondenz zuverlässig ist. Inspiriert durch den jüngsten Erfolg der Unsicherheitsschätzung bei optischen Flussaufgaben [33] schlagen wir eine punktweise Unsicherheit im Diffusionsmodell vor, um die Zuverlässigkeit unserer Szenenflussschätzung zu bewerten.
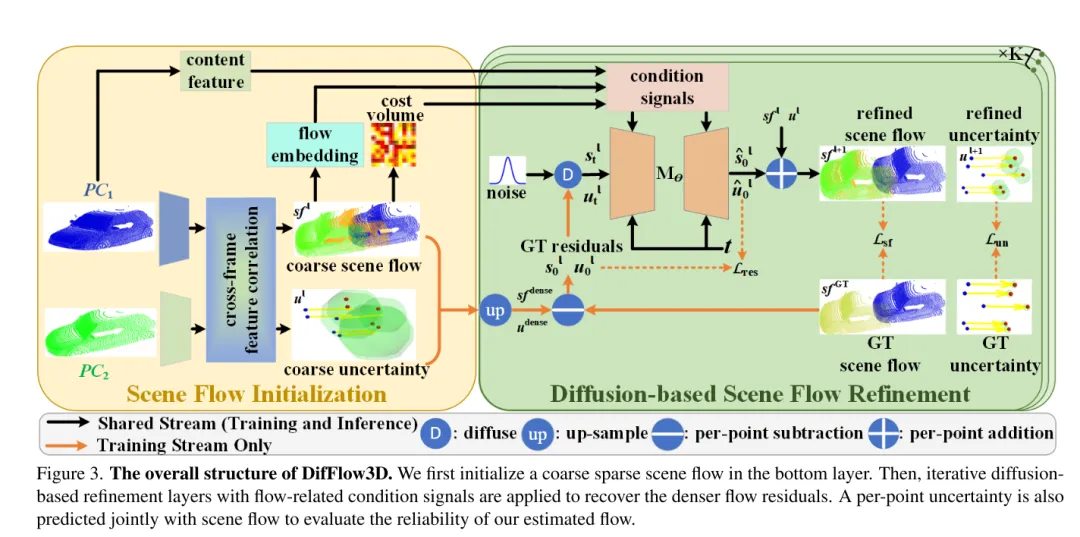
Bild 3. Die Gesamtstruktur von DifFlow3D. In diesem Artikel wird zunächst ein grober, spärlicher Szenenfluss in der unteren Ebene initialisiert. Anschließend werden iterative Diffusionsverfeinerungsschichten in Verbindung mit strömungsbezogenen bedingten Signalen verwendet, um dichtere Strömungsreste wiederherzustellen. Um die Zuverlässigkeit der in diesem Artikel geschätzten Flüsse zu bewerten, wird die Unsicherheit an jedem Punkt auch gemeinsam mit dem Szenenfluss vorhergesagt.
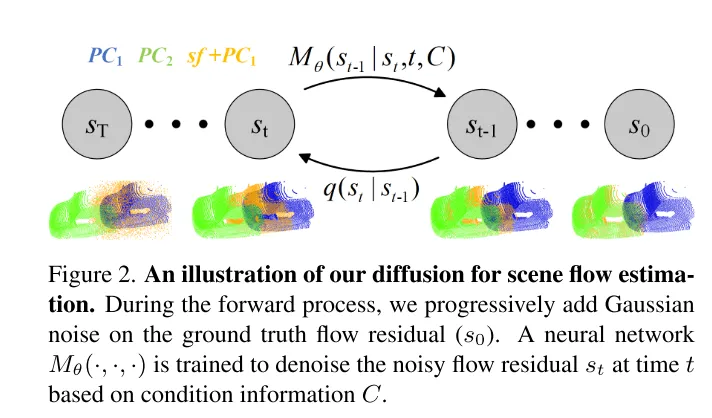
Bild 2. Schematische Darstellung des Diffusionsprozesses, der in diesem Artikel zur Szenenflussschätzung verwendet wird.
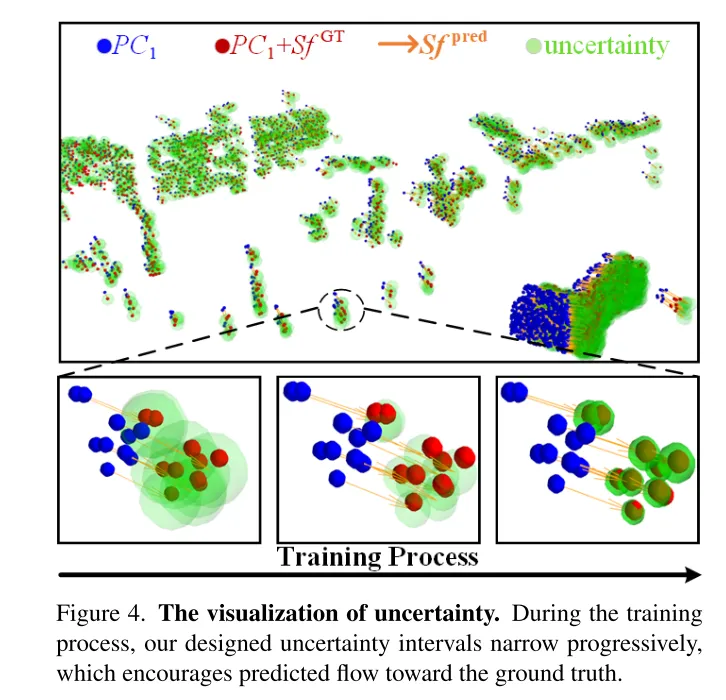
Bild 4. Unsicherheit visualisieren. Während des Trainingsprozesses schrumpft das in diesem Artikel entworfene Unsicherheitsintervall allmählich, was dazu führt, dass sich der vorhergesagte Fluss dem wahren Wert annähert.
Experimentelle Ergebnisse:
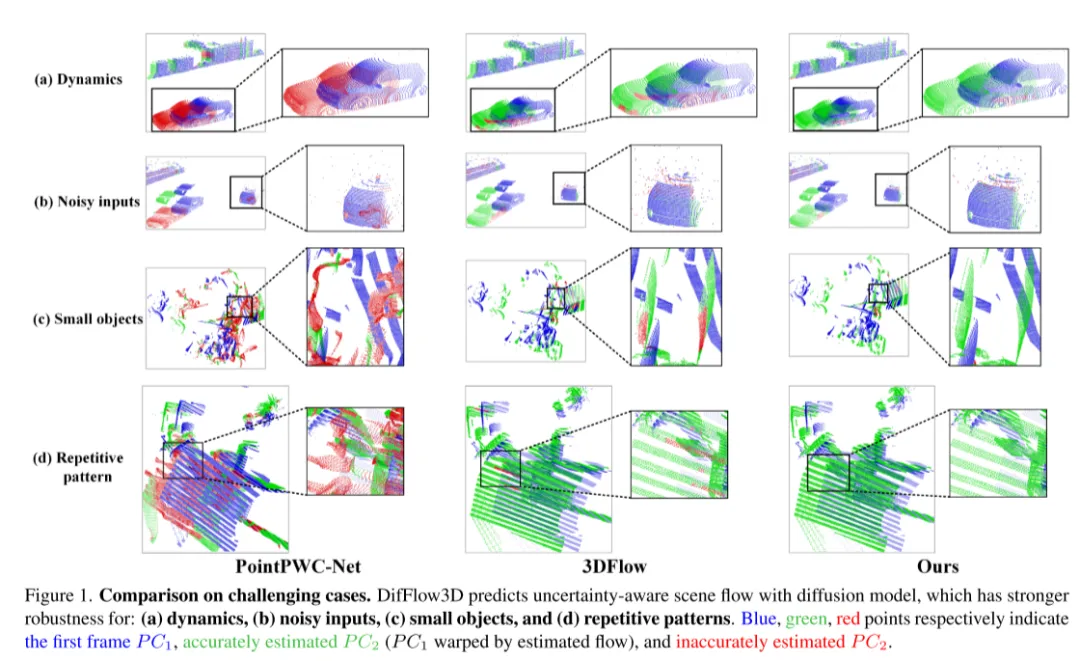
Abbildung 1. Vergleich in herausfordernden Situationen. DifFlow3D sagt einen unsicheren Szenenfluss mithilfe eines Diffusionsmodells voraus, das robuster ist gegenüber: (a) dynamischen Änderungen, (b) verrauschten Eingaben, (c) kleinen Objekten und (d)) sich wiederholenden Mustern.
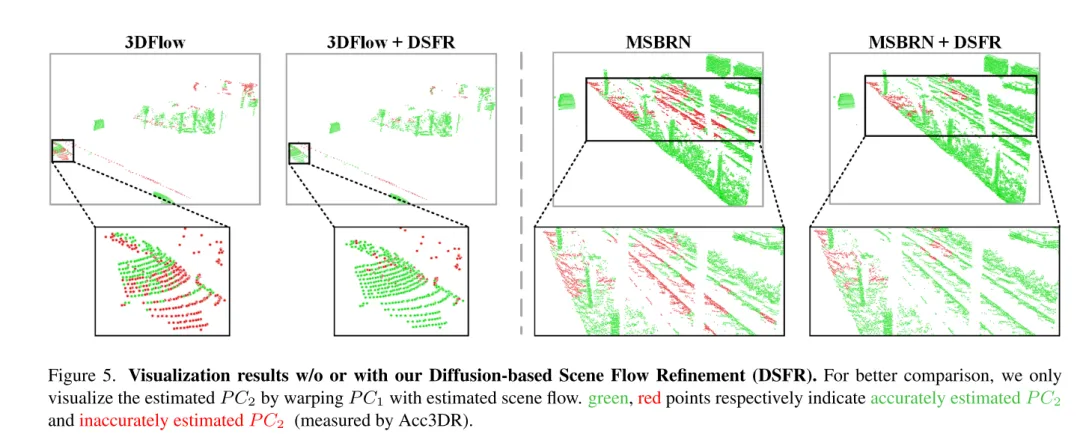
Abbildung 5. Visualisierungsergebnisse ohne oder mit diffusionsbasierter Szenenflussverfeinerung (DSFR).
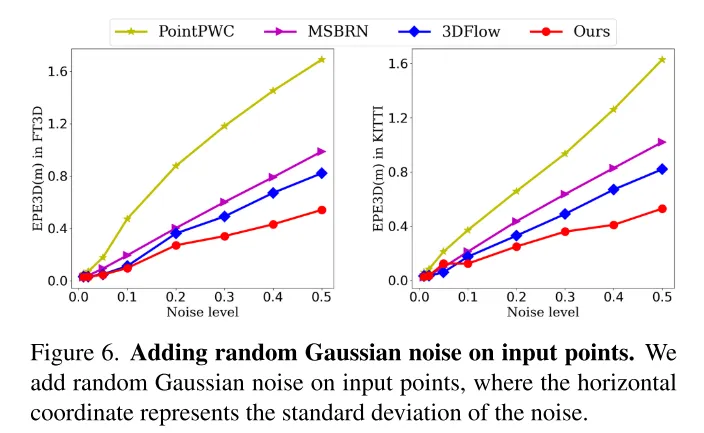
Bild 6. Fügen Sie den Eingabepunkten zufälliges Gaußsches Rauschen hinzu.
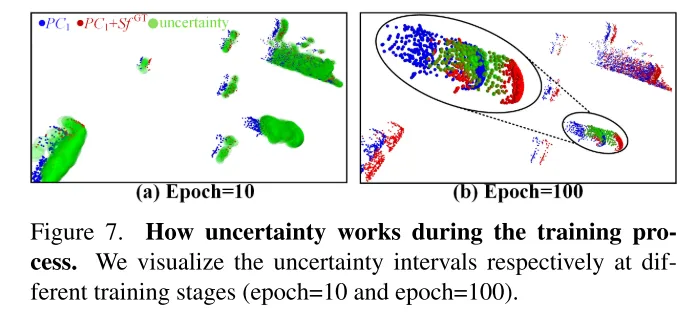
Bild 7. Die Rolle der Unsicherheit im Trainingsprozess. In diesem Artikel werden die Unsicherheitsintervalle in verschiedenen Trainingsstadien (10. Runde und 100. Runde) visualisiert.
Zusammenfassung:
Dieses Papier schlägt innovativ ein diffusionsbasiertes Szenenfluss-Verfeinerungsnetzwerk vor, das sich der Schätzungsunsicherheit bewusst ist. In diesem Artikel wird eine mehrskalige Diffusionsverfeinerung angewendet, um feinkörnige dichte Strömungsreste zu erzeugen. Um die Robustheit der Schätzung zu verbessern, führt dieser Artikel auch die punktuelle Unsicherheit ein, die gemeinsam mit dem Szenenfluss erzeugt wird. Umfangreiche Experimente belegen die Überlegenheit und Generalisierungsfähigkeit unseres DifFlow3D. Es ist erwähnenswert, dass die diffusionsbasierte Verfeinerung dieses Artikels als Plug-and-Play-Modul auf frühere Arbeiten angewendet werden kann und neue Implikationen für zukünftige Forschung liefert.
Zitat:
Liu J, Wang G, Ye W, et al. DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Diffusion Model[J].
Das obige ist der detaillierte Inhalt vonDifFlow3D: Neues SOTA zur Szenenflussschätzung, das Diffusionsmodell hat einen weiteren Erfolg!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
