
 Technologie-Peripheriegeräte
KI
Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Technologie-Peripheriegeräte
KI
Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!
Massenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!

Geschrieben vor
Einer der Algorithmen, mit denen das aktuelle autonome Fahrsystem seine Abhängigkeit von hochpräzisen Karten beseitigt, besteht darin, die Tatsache auszunutzen, dass die Wahrnehmungsleistung im Fernbereich immer noch schlecht ist. Zu diesem Zweck schlagen wir P-MapNet vor, wobei sich „P“ auf die Fusion von Kartenprioritäten konzentriert, um die Modellleistung zu verbessern. Konkret nutzen wir die Vorinformationen in SDMap und HDMap aus: Einerseits extrahieren wir schwach ausgerichtete SDMap-Daten aus OpenStreetMap und kodieren sie in unabhängige Begriffe, um die Eingabe zu unterstützen. Es gibt ein Problem der schwachen Ausrichtung zwischen streng modifizierter Eingabe und der tatsächlichen HD+Map. Unsere auf dem Cross-Attention-Mechanismus basierende Struktur kann sich andererseits adaptiv auf das SDMap-Skelett konzentrieren und erhebliche Leistungsverbesserungen bringen MAE Um das Refine-Modul der vorherigen HDMap-Verteilung zu erfassen, hilft dieses Modul dabei, eine Verteilung zu generieren, die konsistenter mit der tatsächlichen Karte ist, und trägt dazu bei, die Auswirkungen von Okklusion, Artefakten usw. zu reduzieren. Wir führen umfangreiche experimentelle Validierungen an nuScenes- und Argoverse2-Datensätzen durch.
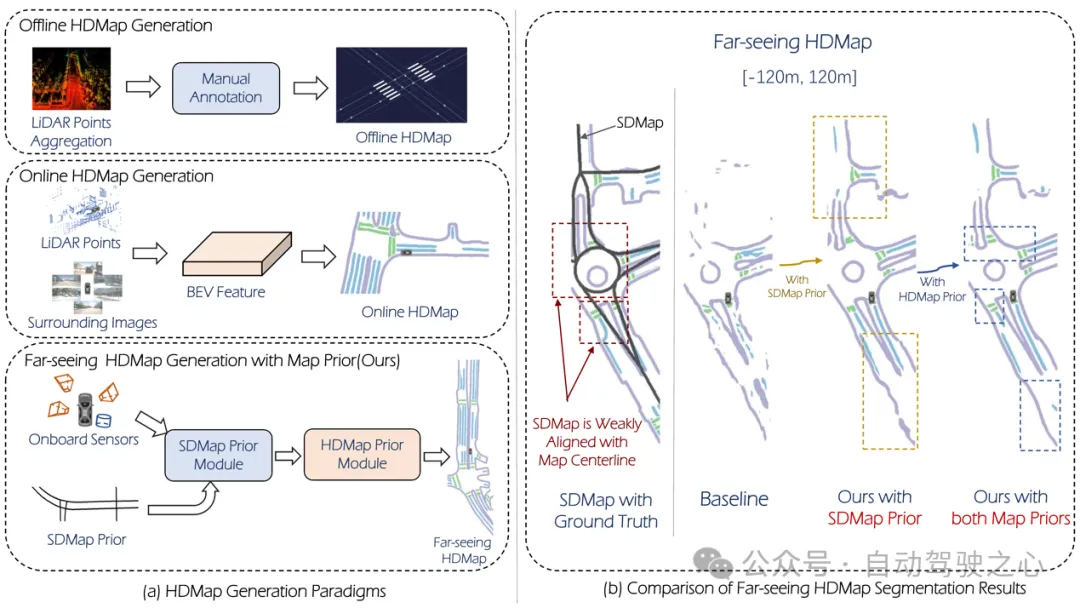 Abbildung 1
Abbildung 1
Zusammenfassend lauten unsere Beiträge wie folgt:
Unsere fortschrittliche SDMap kann die Leistung der Online-Kartengenerierung verbessern, einschließlich Rasterisierung (bis zu 18,73 mIoU) und Quantisierung (bis zu 8,50 mAP) Zwei Kartendarstellungen.
(2) Unser HDMap Prior kann den Kartenbekanntheitsindex um bis zu 6,34 % verbessern.
(3) P-MapNet kann in verschiedene Inferenzmodi wechseln, um Genauigkeit und Effizienz abzuwägen.
P-MapNet ist eine HD+-Kartengenerierungslösung für große Entfernungen, die eine größere Verbesserung der weiteren Erfassungsreichweite bewirken kann. Unser Code und unser Modell wurden unter https://jike5.github.io/P-MapNet/ öffentlich veröffentlicht.
Überprüfung verwandter Arbeiten
(1)Online-Kartenerstellung
HD+Die Kartenproduktion umfasst hauptsächlich SLAM-Mapping, automatische Beschriftung, manuelle Beschriftung und andere Schritte. Dies führt zu hohen Kosten und einer begrenzten Aktualität von HD+Map. Daher ist die Online-Kartenerstellung für autonome Fahrsysteme von entscheidender Bedeutung. HDMapNet drückt Kartenelemente durch Rasterung aus und verwendet pixelweise Vorhersage- und Nachbearbeitungsmethoden, um vektorisierte Vorhersageergebnisse zu erhalten. Einige neuere Methoden wie MapTR, PivotNet, Streammapnet usw. implementieren eine durchgängige vektorisierte Vorhersage basierend auf der Transformer-Architektur. Diese Methoden verwenden jedoch nur Sensoreingaben und ihre Leistung ist in komplexen Umgebungen wie Okklusion immer noch begrenzt und extremes Wetter.
(2)Kartenwahrnehmung über große Entfernungen
Um die durch Online-Karten generierten Ergebnisse besser von nachgelagerten Modulen nutzen zu können, wird in einigen Forschungsarbeiten versucht, den Umfang der Kartenwahrnehmung weiter zu erweitern. SuperFusion[7] erreicht eine Vorwärtsvorhersage über 90 m über große Entfernungen durch die Verbindung von Lidar und Kameras und die Verwendung einer tiefenabhängigen BEV-Transformation. NeuralMapPrior[8] verbessert die Qualität aktueller Online-Beobachtungen und erweitert den Wahrnehmungsbereich durch die Pflege und Aktualisierung globaler neuronaler Kartenprioritäten. [6] ermittelt BEV-Merkmale durch die Aggregation von Satellitenbildern und Fahrzeugsensordaten und prognostiziert diese weiter. MV-Map konzentriert sich auf die Offline-Erstellung von Fernkarten. Diese Methode optimiert BEV-Features durch die Aggregation aller zugehörigen Frame-Features und die Verwendung neuronaler Strahlungsfelder.
Übersicht über P-MapNet
Der Gesamtrahmen ist in Abbildung 2 dargestellt.
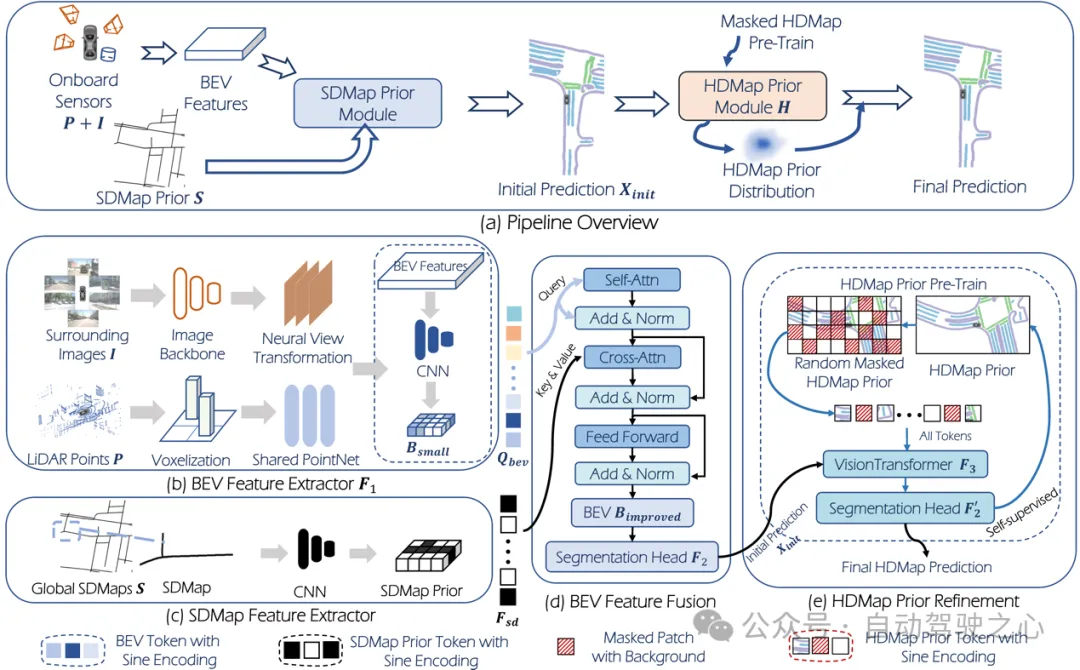 Abbildung 2
Abbildung 2
Eingabe: Die Systemeingabe ist Punktwolke: , Surround-Kamera:, wobei die Anzahl der Surround-Kameras ist. Eine gängige HDMap-Generierungsaufgabe (z. B. HDMapNet) kann wie folgt definiert werden:
wobei die Merkmalsextraktion darstellt, den Segmentierungskopf darstellt und das Vorhersageergebnis von HDMap ist.
Das von uns vorgeschlagene P-MapNet kombiniert SD-Map- und HD-Map-Prioritäten. Diese neue Aufgabe ( Einstellung) kann wie folgt ausgedrückt werden:
wobei die SDMap-Priorität darstellt, die in diesem Artikel vorgeschlagene Verfeinerung Modul. Das Modul lernt die HD-Kartenverteilung vorab durch Vorschulung. Wenn wir zuvor nur SDMap verwenden, erhalten wir ebenfalls die -nur-Einstellung:
Ausgabe: Für Kartengenerierungsaufgaben gibt es normalerweise zwei Kartendarstellungen: Rasterisierung und Vektorisierung. Bei der Recherche dieses Artikels konzentrieren wir uns hauptsächlich auf die gerasterte Darstellung, da die beiden in diesem Artikel entworfenen A-priori-Module besser für die gerasterte Ausgabe geeignet sind.
3.1 SDMap Vorheriges Modul
SDMap-Datengenerierung
Dieser Artikel führt Forschungen auf der Grundlage von nuScenes- und Argoverse2-Datensätzen durch, verwendet OpenStreetMap-Daten, um SD-Kartendaten für die entsprechenden Bereiche der oben genannten Datensätze zu generieren, und führt Koordinaten durch Systemtransformation durch Fahrzeug-GPS, um die SD-Karte des entsprechenden Gebiets zu erhalten.
BEV-Abfrage
Wie in Abbildung 2 gezeigt, führen wir zunächst eine Merkmalsextraktion und eine Perspektivkonvertierung der Bilddaten sowie eine Merkmalsextraktion der Punktwolke durch, um BEV-Merkmale zu erhalten. Anschließend werden die BEV-Merkmale durch das Faltungsnetzwerk heruntergetastet, um die neuen BEV-Merkmale zu erhalten, und die Feature-Map wird abgeflacht, um die BEV-Abfrage zu erhalten.
SD-Karte vor der Fusion
Für SD-Kartendaten werden nach der Merkmalsextraktion durch das Faltungsnetzwerk die erhaltenen Merkmale übergeben der Segmentierungskopf, um erste Vorhersagen von Kartenelementen zu erhalten.
3.2. Das HDMap-Prior-Modulverwendet direkt die gerasterte HD-Karte als Eingabe des ursprünglichen MAE. Das MAE wird durch MSE Loss trainiert, wodurch es nicht als Verfeinerungsmodul verwendet werden kann. Daher ersetzen wir in diesem Artikel die Ausgabe von MAE durch unseren Segmentierungskopf. Um sicherzustellen, dass die vorhergesagten Kartenelemente Kontinuität und Authentizität aufweisen (näher an der Verteilung der tatsächlichen HD-Karte), verwenden wir zur Verfeinerung ein vorab trainiertes MAE-Modul. Das Training dieses Moduls besteht aus zwei Schritten: Der erste Schritt besteht darin, das MAE-Modul mithilfe von selbstüberwachtem Lernen zu trainieren, um die Verteilung von HD Map zu lernen, und der zweite Schritt besteht darin, alle Module des Netzwerks mithilfe der erhaltenen Gewichte zu optimieren im ersten Schritt als Anfangsgewichte. Im ersten Schritt des Vortrainings wird die aus dem Datensatz erhaltene echte HD-Karte zufällig maskiert und als Netzwerkeingabe verwendet
, und das Trainingsziel besteht darin, die HD-Karte zu vervollständigen:
Im zweiten Schritt Schritt der Feinabstimmung,
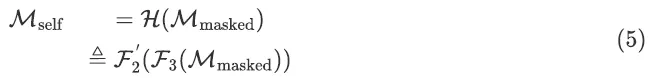 Der erste Schritt der Vortrainingsgewichte wird als Anfangsgewichte verwendet. Das vollständige Netzwerk ist:
Der erste Schritt der Vortrainingsgewichte wird als Anfangsgewichte verwendet. Das vollständige Netzwerk ist:
4. Experiment

Wir führen durch es auf zwei Mainstream-Datensätzen überprüft: nuScenes und Argoverse2. Um die Wirksamkeit unserer vorgeschlagenen Methode auf große Entfernungen nachzuweisen, stellen wir sie auf drei verschiedene Erkennungsentfernungen ein:
, . Unter ihnen beträgt die Auflösung des BEV Grid im Bereich
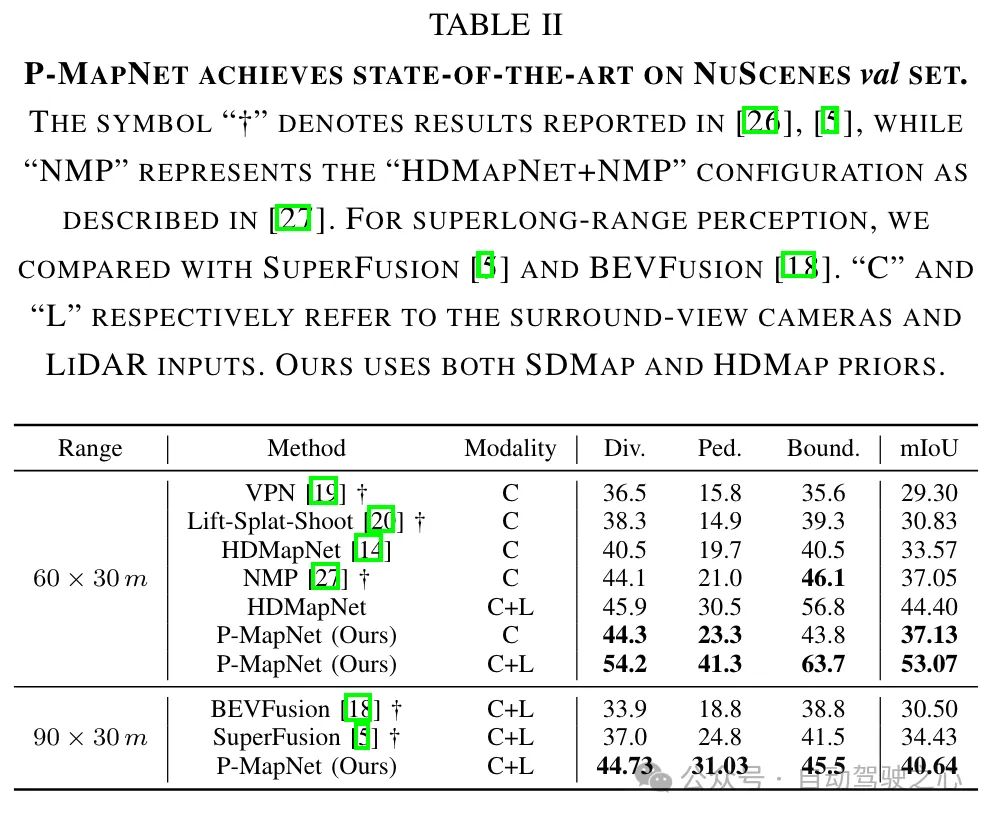
0,15 m und die Auflösung in den anderen beiden Bereichen beträgt 0,3 m. Wir verwenden die mIOU-Metrik, um gerasterte Vorhersageergebnisse auszuwerten, und mAP, um vektorisierte Vorhersageergebnisse auszuwerten. Um die Authentizität der Karte zu bewerten, verwenden wir auch die LPIPS-Metrik als Kartenbekanntheitsmetrik. 4.2 Ergebnisse Vergleich mit SOTA-Ergebnissen: Wir vergleichen die Kartenerstellungsergebnisse der vorgeschlagenen Methode und der aktuellen SOTA-Methode auf kurze Distanz (60 m × 30 m) und lange Distanz (90 m × 30 m). Wie in Tabelle II gezeigt, zeigt unsere Methode eine überlegene Leistung im Vergleich zu bestehenden Nur-Vision- und multimodalen (RGB+LiDAR)-Methoden.
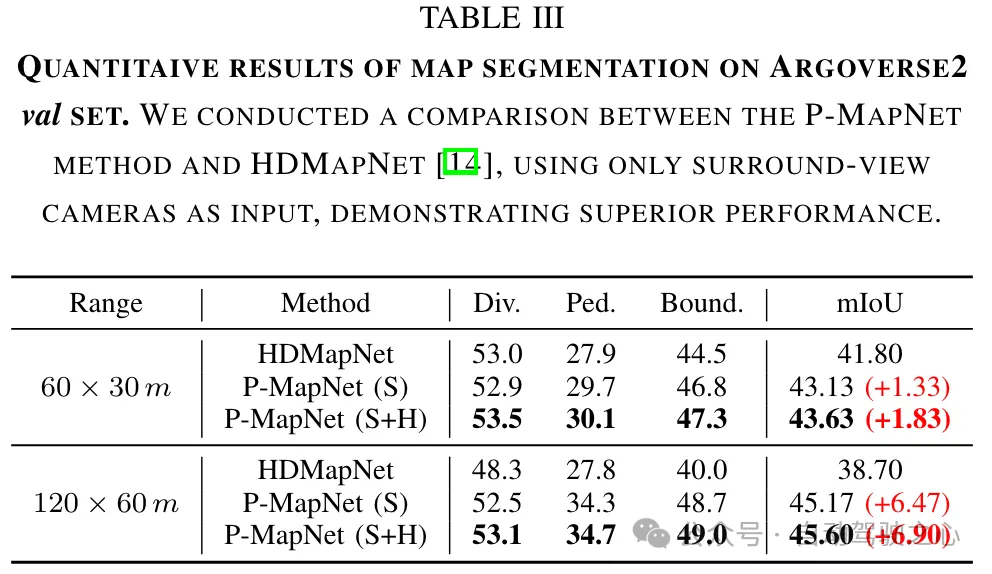
Wir haben einen Leistungsvergleich mit HDMapNet [14] bei verschiedenen Entfernungen und unter Verwendung verschiedener Sensormodi durchgeführt. Die Ergebnisse sind in Tabelle I und Tabelle III zusammengefasst. Unsere Methode erreicht eine Verbesserung von 13,4 % gegenüber mIOU bei einer Reichweite von 240 m × 60 m. Wenn der wahrgenommene Abstand den Erfassungsbereich des Sensors überschreitet oder sogar überschreitet, wird die Wirksamkeit des SDMap-Priori wichtiger, wodurch die Wirksamkeit des SDMap-Prior bestätigt wird. Schließlich nutzen wir die HD-Karte, um weitere Leistungsverbesserungen zu erzielen, indem wir die anfänglichen Vorhersageergebnisse verfeinern, um sie realistischer zu machen und falsche Ergebnisse zu eliminieren.
HDMap vorherige Wahrnehmungsmetrik. Das vorherige HDMap-Modul ordnet die anfänglichen Vorhersagen des Netzwerks der Verteilung der HD-Karte zu und macht sie so realistischer. Um die Authentizität der HDMap-Ausgabe des vorherigen Moduls zu bewerten, haben wir die Wahrnehmungsmetrik LPIPS (je niedriger der Wert, desto besser die Leistung) zur Bewertung verwendet. Wie in Tabelle IV gezeigt, ist die Verbesserung des LPIPS-Index in der Einstellung 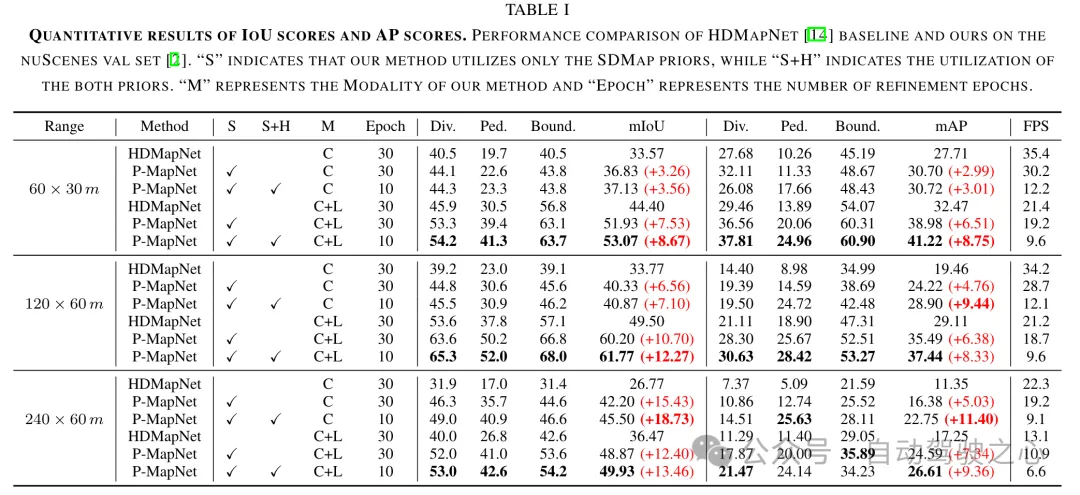
 .
.
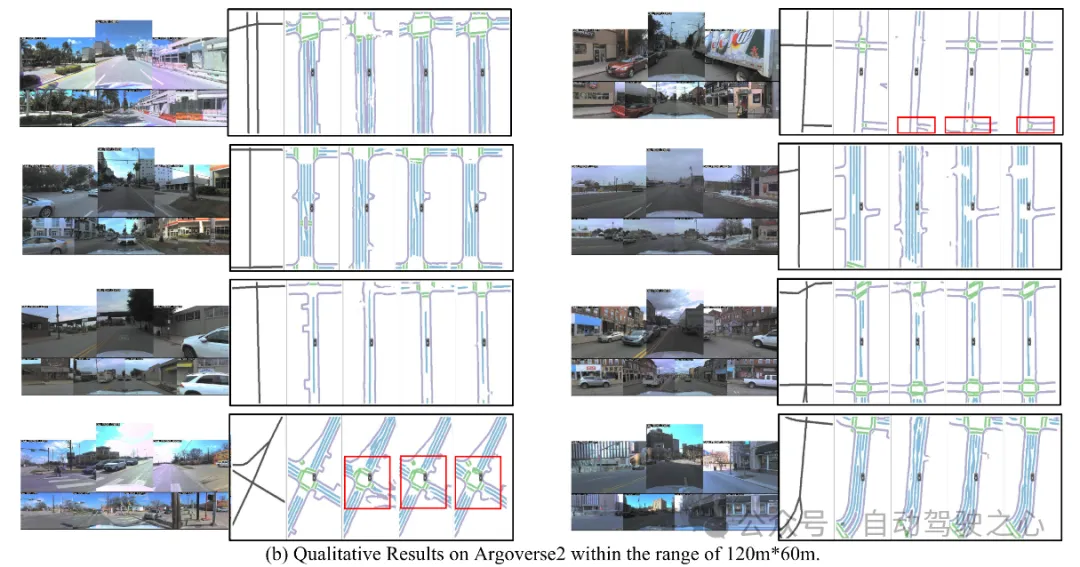
Visualisierung: 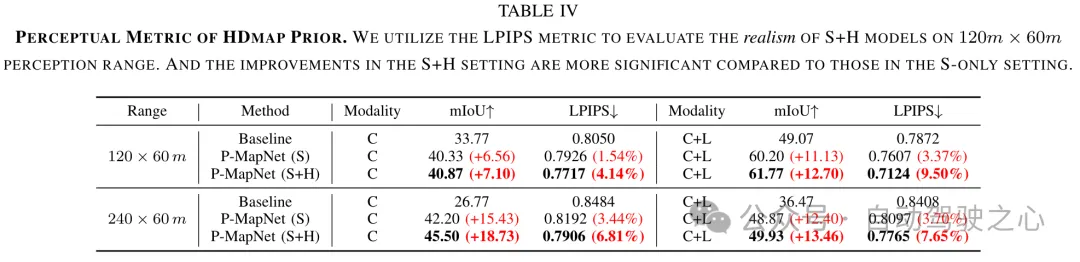

Das obige ist der detaillierte Inhalt vonMassenproduktionskiller! P-Mapnet: Durch die vorherige Verwendung der Karte SDMap mit niedriger Genauigkeit wird die Kartenleistung deutlich um fast 20 Punkte verbessert!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Beherrschen Sie die Koordinatensystemkonvertierung wirklich? Multisensorik-Themen, die für das autonome Fahren unverzichtbar sind
Oct 12, 2023 am 11:21 AM
Der erste Pilot- und Schlüsselartikel stellt hauptsächlich mehrere häufig verwendete Koordinatensysteme in der autonomen Fahrtechnologie vor und erläutert, wie die Korrelation und Konvertierung zwischen ihnen abgeschlossen und schließlich ein einheitliches Umgebungsmodell erstellt werden kann. Der Schwerpunkt liegt hier auf dem Verständnis der Umrechnung vom Fahrzeug in den starren Kamerakörper (externe Parameter), der Kamera-in-Bild-Konvertierung (interne Parameter) und der Bild-in-Pixel-Einheitenkonvertierung. Die Konvertierung von 3D in 2D führt zu entsprechenden Verzerrungen, Verschiebungen usw. Wichtige Punkte: Das Fahrzeugkoordinatensystem und das Kamerakörperkoordinatensystem müssen neu geschrieben werden: Das Ebenenkoordinatensystem und das Pixelkoordinatensystem. Schwierigkeit: Sowohl die Entzerrung als auch die Verzerrungsaddition müssen auf der Bildebene kompensiert werden. 2. Einführung Insgesamt gibt es vier visuelle Systeme Koordinatensystem: Pixelebenenkoordinatensystem (u, v), Bildkoordinatensystem (x, y), Kamerakoordinatensystem () und Weltkoordinatensystem (). Es gibt eine Beziehung zwischen jedem Koordinatensystem,
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
