
 Technologie-Peripheriegeräte
KI
Aus nur einem Bild lässt sich ein KI-Video generieren! Das neue Diffusionsmodell von Google bringt Charaktere in Bewegung
Technologie-Peripheriegeräte
KI
Aus nur einem Bild lässt sich ein KI-Video generieren! Das neue Diffusionsmodell von Google bringt Charaktere in Bewegung
Aus nur einem Bild lässt sich ein KI-Video generieren! Das neue Diffusionsmodell von Google bringt Charaktere in Bewegung

Sie benötigen lediglich ein Foto und einen Ton, um direkt ein Video des sprechenden Charakters zu erstellen!
Kürzlich haben Forscher von Google das multimodale Diffusionsmodell VLOGGER veröffentlicht, das uns dem virtuellen digitalen Menschen einen Schritt näher bringt.

Papieradresse: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger kann ein einzelnes Eingabebild sammeln und Text- oder Audiotreiber verwenden, um Videos menschlicher Sprache zu generieren, einschließlich oral Die Form, der Ausdruck, die Körperbewegungen usw. sind alle sehr natürlich.
Schauen wir uns zunächst ein paar Beispiele an:




Wenn Sie das Gefühl haben, dass die Verwendung der Stimmen anderer Personen im Video etwas inkonsistent ist, wenden Sie sich an den Herausgeber hilft Ihnen, den Ton auszuschalten:

Man erkennt, dass der gesamte erzeugte Effekt sehr elegant und natürlich ist.
VLOGGER baut auf dem jüngsten Erfolg generativer Diffusionsmodelle auf, einschließlich eines Modells, das Menschen in 3D-Bewegung übersetzt, und einer neuen diffusionsbasierten Architektur zur Verbesserung textgenerierter Bilder mit zeitlicher und räumlicher Kontrolle.

VLOGGER kann hochwertige Videos variabler Länge erzeugen, und diese Videos können mit erweiterten Darstellungen von Gesichtern und Körpern einfach gesteuert werden.

Zum Beispiel können wir die Personen im generierten Video bitten, den Mund zu halten:

oder die Augen zu schließen:

Im Vergleich zu früheren ähnlichen Modellen tut VLOGGER dies nicht erforderlich Es wird auf Einzelpersonen trainiert, basiert nicht auf Gesichtserkennung und Zuschneiden und umfasst Körperbewegungen, Oberkörper und Hintergründe – eine normale menschliche Leistung, die kommunizieren kann.
Die Stimme der KI, der Ausdruck der KI, die Aktion der KI, die Szene der KI, der Wert des Menschen liegt am Anfang darin, Daten bereitzustellen, aber könnten sie in Zukunft keinen Wert mehr haben?


In Bezug auf die Daten haben die Forscher einen neuen und vielfältigen Datensatz MENTOR gesammelt, der eine ganze Größenordnung größer ist als der vorherige ähnliche Datensatz. Der Trainingssatz umfasst 2.200 Stunden und 800.000 verschiedene Einzelpersonen, der Testsatz umfasst 120 Stunden und 4000 Personen mit unterschiedlichen Identitäten.

Die Forscher bewerteten VLOGGER anhand von drei verschiedenen Benchmarks und zeigten, dass das Modell hinsichtlich Bildqualität, Identitätserhaltung und zeitlicher Konsistenz eine Spitzenleistung erzielte.

VLOGGER
VLOGGERs Ziel ist es, ein realistisches Video variabler Länge zu erstellen, das den gesamten Sprechvorgang der Zielperson einschließlich Kopfbewegungen und Gesten darstellt.

Wie oben gezeigt, wird bei einem einzelnen Eingabebild in Spalte 1 und einem Beispiel-Audioeingang in der rechten Spalte eine Reihe zusammengesetzter Bilder angezeigt.
Einschließlich der Erzeugung von Kopfbewegungen, Blicken, Blinzeln, Lippenbewegungen und etwas, was frühere Modelle nicht konnten, nämlich der Erzeugung von Oberkörper und Gesten, was einen großen Fortschritt in der audiogesteuerten Synthese darstellt.
VLOGGER verwendet eine zweistufige Pipeline, die auf einem Zufallsdiffusionsmodell basiert, um eine Eins-zu-viele-Zuordnung von Sprache zu Video zu simulieren.
Das erste Netzwerk verwendet Audiowellenformen als Eingabe, um Körperbewegungssteuerungen zu generieren, die für Blick, Gesichtsausdrücke und Gesten über die Länge des Zielvideos verantwortlich sind.
Das zweite Netzwerk ist ein zeitliches Bild-zu-Bild-Übersetzungsmodell, das das Großbilddiffusionsmodell erweitert, um vorhergesagte Körpersteuerung zur Erzeugung entsprechender Frames zu nutzen. Um diesen Prozess auf eine bestimmte Identität auszurichten, erhält das Netzwerk ein Referenzbild der Zielperson.
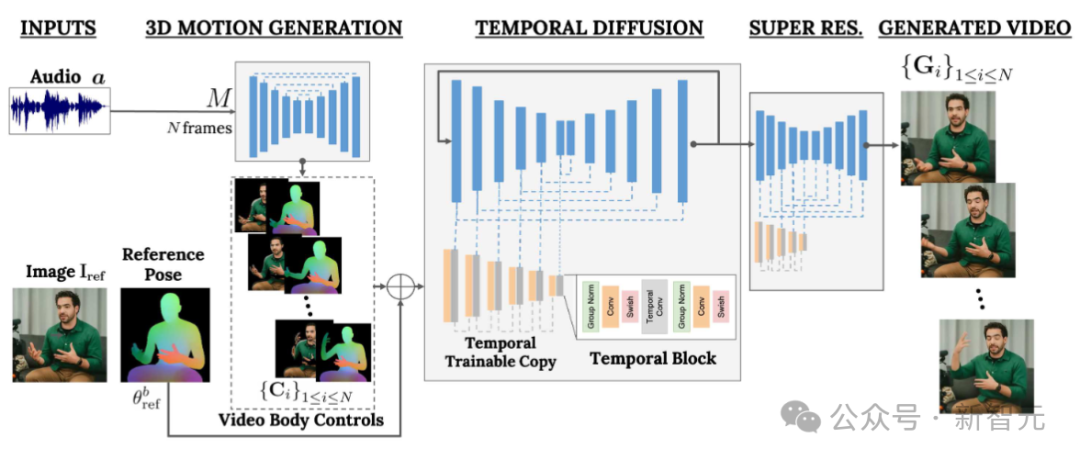
VLOGGER verwendet statistikbasierte 3D-Körpermodelle, um den Videogenerierungsprozess zu regulieren. Bei einem gegebenen Eingabebild kodieren die vorhergesagten Formparameter die geometrischen Eigenschaften der Zielidentität.
Zuerst nimmt das Netzwerk M die eingegebene Sprache und generiert eine Reihe von N Bildern mit 3D-Gesichtsausdrücken und Körperhaltungen.
Eine dichte Darstellung des sich bewegenden 3D-Körpers wird dann gerendert, um während der Videogenerierungsphase als 2D-Steuerung zu dienen. Diese Bilder dienen zusammen mit den Eingabebildern als Eingabe für das zeitliche Diffusionsmodell und die Superauflösungsmodule.
Audiogesteuerte Bewegungserzeugung
Das erste Netzwerk der Pipeline ist darauf ausgelegt, Bewegungen basierend auf eingegebener Sprache vorherzusagen. Darüber hinaus wird der Eingabetext durch ein Text-to-Speech-Modell in eine Wellenform umgewandelt und das generierte Audio wird als Standard-Mel-Spektrogramm dargestellt.
Die Pipeline basiert auf der Transformer-Architektur und verfügt über vier Multi-Head-Aufmerksamkeitsebenen in der Zeitdimension. Beinhaltet die Positionskodierung der Bildnummer und des Diffusionsschritts sowie die Einbettung von MLP für Eingangsaudio und Diffusionsschritt.
Verwenden Sie in jedem Frame eine kausale Maske, damit sich das Modell nur auf den vorherigen Frame konzentriert. Das Modell wird mithilfe von Videos variabler Länge (z. B. dem TalkingHead-1KH-Datensatz) trainiert, um sehr lange Sequenzen zu generieren.
Die Forscher nutzen statistisch basierte geschätzte Parameter eines 3D-Modells des menschlichen Körpers, um Zwischenkontrolldarstellungen für synthetische Videos zu generieren.
Das Modell berücksichtigt sowohl Mimik als auch Körperbewegungen, um ausdrucksstärkere und dynamischere Gesten zu erzeugen.
Darüber hinaus basieren frühere Arbeiten zur Gesichtsgenerierung normalerweise auf verzerrten Bildern, aber in diffusionsbasierten Architekturen wurde diese Methode ignoriert.
Die Autoren schlagen vor, verzerrte Bilder zu verwenden, um den Generierungsprozess zu leiten, was die Aufgabe des Netzwerks erleichtert und dabei hilft, die Subjektidentität der Charaktere zu bewahren.
Sprechende und sich bewegende Menschen generieren
Das nächste Ziel besteht darin, eine Bewegungsverarbeitung an einem Eingabebild einer Person durchzuführen, sodass es zuvor vorhergesagten Körper- und Gesichtsbewegungen folgt.
Inspiriert von ControlNet froren die Forscher das ursprünglich trainierte Modell ein und übernahmen Eingabezeitkontrollen, um eine nullinitialisierte, trainierbare Kopie der Codierungsschicht zu erstellen.
Der Autor verschachtelt eindimensionale Faltungsschichten im Zeitbereich. Das Netzwerk wird durch den Erhalt aufeinanderfolgender N Frames und Steuerelemente trainiert und generiert Aktionsvideos von Referenzzeichen basierend auf den Eingabesteuerelementen.
Das Modell wird mithilfe des vom Autor erstellten MENTOR-Datensatzes trainiert. Da das Netzwerk während des Trainingsprozesses eine Reihe aufeinanderfolgender Bilder und beliebige Referenzbilder erhält, kann theoretisch jedes Videobild als Referenz bezeichnet werden.
In der Praxis entscheiden sich die Autoren jedoch dafür, Referenzen weiter vom Zielclip entfernt zu sampeln, da nähere Beispiele weniger Verallgemeinerungspotenzial bieten.
Das Netzwerk wird in zwei Phasen trainiert: Zuerst wird eine neue Steuerungsschicht auf einem einzelnen Frame gelernt und dann wird das Video trainiert, indem eine zeitliche Komponente hinzugefügt wird. Dies ermöglicht die Verwendung großer Stapel in der ersten Phase und ein schnelleres Erlernen von Head-Replay-Aufgaben.
Die vom Autor verwendete Lernrate beträgt 5e-5, und das Bildmodell wird in beiden Phasen mit einer Schrittgröße von 400.000 und einer Stapelgröße von 128 trainiert.
Vielfalt
Die folgende Abbildung zeigt die vielfältige Verteilung von Zielvideos, die aus einem Eingabebild generiert wurden. Die Spalte ganz rechts zeigt die Pixelvielfalt, die sich aus den 80 generierten Videos ergibt.

Während der Hintergrund fest bleibt, bewegen sich Kopf und Körper der Person deutlich (Rot bedeutet eine größere Vielfalt an Pixelfarben), und trotz der Vielfalt sehen alle Videos gleich aus. Sehr realistisch. Eine der Anwendungen von
Videobearbeitung

ist die Bearbeitung vorhandener Videos. In diesem Fall nimmt VLOGGER ein Video auf und verändert den Gesichtsausdruck der Person, indem sie beispielsweise den Mund oder die Augen schließt.
In der Praxis nutzt der Autor die Flexibilität des Diffusionsmodells, um die Teile des Bildes zu reparieren, die geändert werden sollten, sodass die Videobearbeitung mit den ursprünglichen unveränderten Pixeln übereinstimmt.
Videoübersetzung
Eine der Hauptanwendungen des Modells ist die Videoübersetzung. In diesem Fall nimmt VLOGGER vorhandenes Video in einer bestimmten Sprache und bearbeitet die Lippen und Gesichtsbereiche, um sie an den neuen Ton anzupassen (z. B. Spanisch).
Das obige ist der detaillierte Inhalt vonAus nur einem Bild lässt sich ein KI-Video generieren! Das neue Diffusionsmodell von Google bringt Charaktere in Bewegung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So nehmen Sie Bildschirmvideos mit einem OPPO-Telefon auf (einfache Bedienung)
May 07, 2024 pm 06:22 PM
So nehmen Sie Bildschirmvideos mit einem OPPO-Telefon auf (einfache Bedienung)
May 07, 2024 pm 06:22 PM
Spielfähigkeiten oder Lehrdemonstrationen: Im täglichen Leben müssen wir häufig Mobiltelefone verwenden, um Bildschirmvideos aufzunehmen, um einige Bedienschritte zu zeigen. Die Funktion zum Aufzeichnen von Bildschirmvideos ist ebenfalls sehr gut und das OPPO-Mobiltelefon ist ein leistungsstarkes Smartphone. Damit Sie die Aufnahmeaufgabe einfach und schnell erledigen können, wird in diesem Artikel detailliert beschrieben, wie Sie OPPO-Mobiltelefone zum Aufzeichnen von Bildschirmvideos verwenden. Vorbereitung – Aufnahmeziele festlegen Bevor Sie beginnen, müssen Sie Ihre Aufnahmeziele klären. Möchten Sie ein Schritt-für-Schritt-Demonstrationsvideo aufnehmen? Oder möchten Sie einen wundervollen Moment eines Spiels festhalten? Oder möchten Sie ein Lehrvideo aufnehmen? Nur durch eine bessere Organisation des Aufnahmeprozesses und klare Ziele. Öffnen Sie die Bildschirmaufzeichnungsfunktion des OPPO-Mobiltelefons und finden Sie sie im Verknüpfungsfeld. Die Bildschirmaufzeichnungsfunktion befindet sich im Verknüpfungsfeld.
 Was ist der Unterschied zwischen Quad-Core- und Acht-Core-Computer-CPUs?
May 06, 2024 am 09:46 AM
Was ist der Unterschied zwischen Quad-Core- und Acht-Core-Computer-CPUs?
May 06, 2024 am 09:46 AM
Was ist der Unterschied zwischen Quad-Core- und Acht-Core-Computer-CPUs? Der Unterschied liegt in der Verarbeitungsgeschwindigkeit und Leistung. Eine Quad-Core-CPU verfügt über vier Prozessorkerne, während eine Acht-Core-CPU über acht Kerne verfügt. Dies bedeutet, dass ersterer vier Aufgaben gleichzeitig ausführen kann und letzterer acht Aufgaben gleichzeitig ausführen kann. Daher ist eine Octa-Core-CPU schneller als eine Quad-Core-CPU, wenn sie zur Verarbeitung großer Datenmengen oder zur Ausführung mehrerer Programme verwendet wird. Gleichzeitig eignen sich Achtkern-CPUs auch besser für Multimedia-Arbeiten wie Videobearbeitung oder Spiele, da diese Aufgaben höhere Verarbeitungsgeschwindigkeiten und bessere Grafikverarbeitungsfunktionen erfordern. Allerdings sind auch die Kosten für Achtkern-CPUs höher, daher ist es sehr wichtig, die richtige CPU basierend auf den tatsächlichen Anforderungen und dem Budget auszuwählen. Ist es besser, eine Dual-Core- oder Quad-Core-Computer-CPU zu haben? Ob Dual-Core oder Quad-Core besser ist, hängt von Ihren Nutzungsanforderungen ab.
 So wechseln Sie die Sprache in Adobe After Effects cs6 (Ae cs6) Detaillierte Schritte zum Wechseln zwischen Chinesisch und Englisch in Ae cs6 – ZOL-Download
May 09, 2024 pm 02:00 PM
So wechseln Sie die Sprache in Adobe After Effects cs6 (Ae cs6) Detaillierte Schritte zum Wechseln zwischen Chinesisch und Englisch in Ae cs6 – ZOL-Download
May 09, 2024 pm 02:00 PM
1. Suchen Sie zuerst den Ordner AMTLangagues. Wir haben einige Dokumentationen im AMTLangagues-Ordner gefunden. Wenn Sie vereinfachtes Chinesisch installieren, gibt es ein Textdokument zh_CN.txt (der Textinhalt ist: zh_CN). Wenn Sie es auf Englisch installiert haben, gibt es ein Textdokument en_US.txt (der Textinhalt ist: en_US). 3. Wenn wir also auf Chinesisch umsteigen möchten, müssen wir ein neues Textdokument von zh_CN.txt (der Textinhalt ist: zh_CN) unter dem Pfad AdobeAfterEffectsCCSupportFilesAMTLanguages erstellen. 4. Im Gegenteil, wenn wir auf Englisch umsteigen wollen,
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
 Wie drehe ich Videos auf TikTok? Wie schalte ich das Mikrofon für Videoaufnahmen ein?
May 09, 2024 pm 02:40 PM
Wie drehe ich Videos auf TikTok? Wie schalte ich das Mikrofon für Videoaufnahmen ein?
May 09, 2024 pm 02:40 PM
Als eine der beliebtesten Kurzvideoplattformen von heute wirken sich Qualität und Wirkung der Videos von Douyin direkt auf das Seherlebnis des Benutzers aus. Wie dreht man also hochwertige Videos auf TikTok? 1. Wie drehe ich Videos auf Douyin? 1. Öffnen Sie die Douyin-App und klicken Sie unten in der Mitte auf die Schaltfläche „+“, um die Videoaufnahmeseite aufzurufen. 2. Douyin bietet eine Vielzahl von Aufnahmemodi, darunter normale Aufnahme, Zeitlupe, Kurzvideo usw. Wählen Sie den passenden Aufnahmemodus entsprechend Ihren Anforderungen. 3. Klicken Sie auf der Aufnahmeseite unten auf dem Bildschirm auf die Schaltfläche „Filter“, um verschiedene Filtereffekte auszuwählen und das Video individueller zu gestalten. 4. Wenn Sie Parameter wie Belichtung und Kontrast anpassen müssen, können Sie zum Einstellen auf die Schaltfläche „Parameter“ in der unteren linken Ecke des Bildschirms klicken. 5. Während der Aufnahme können Sie auf die linke Seite des Bildschirms klicken
