
 Technologie-Peripheriegeräte
KI
Der erste Beitrag, seit der Chef gegangen ist! Stabilität, offizielles Codemodell, Stable Code Instruct 3B
Technologie-Peripheriegeräte
KI
Der erste Beitrag, seit der Chef gegangen ist! Stabilität, offizielles Codemodell, Stable Code Instruct 3B
Der erste Beitrag, seit der Chef gegangen ist! Stabilität, offizielles Codemodell, Stable Code Instruct 3B

Nachdem der Chef gegangen ist, ist das erste Modell da!
Erst heute hat Stability AI offiziell ein neues Codemodell angekündigt, Stable Code Instruct 3B.
 Bilder
Bilder
Stabilität ist sehr wichtig. Der Abgang des CEO hat bei Stable Diffusion einige Probleme verursacht, und es kann zu Problemen mit Ihrem eigenen Gehalt kommen.
Draußen vor dem Gebäude toben jedoch Wind und Regen, aber das Labor bleibt bewegungslos. Es sollten Untersuchungen durchgeführt, Diskussionen geführt und Modelle angepasst werden nichts.
Es weitet nicht nur seinen Stall aus, um sich auf einen umfassenden Krieg einzulassen, sondern jede Forschung macht auch kontinuierliche Fortschritte. Beispielsweise basiert der heutige Stable Code Instruct 3B auf dem vorherigen Stable Code 3B mit Befehlsoptimierung.
 Bilder
Bilder
Papieradresse: https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412edcd56f8e/1711392114564/Stable _C ode_TechReport_release.pdf
Mit Eingabeaufforderungen in natürlicher Sprache, Stable Code Instruct 3B kann verschiedene Aufgaben wie Codegenerierung, Mathematik und andere Fragen zur Softwareentwicklung bearbeiten.
 Bilder
Bilder
Unbesiegbar auf dem gleichen Level, starke Kills auf höheren Leveln
Stable Code Instruct 3B hat den aktuellen SOTA in einem Modell mit der gleichen Anzahl von Parametern erreicht, sogar besser als CodeLlama, das ist mehr als doppelt so groß wie 7B Instruct und andere Modelle und seine Leistung bei softwaretechnischen Aufgaben ist vergleichbar mit StarChat 15B.
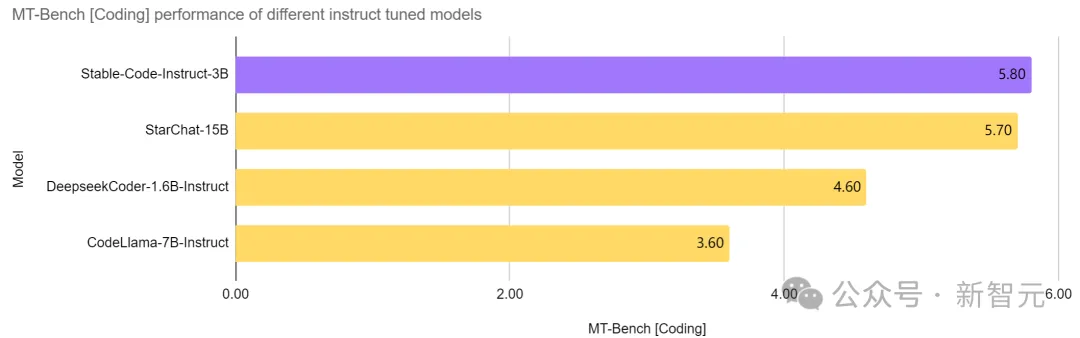 Bilder
Bilder
Wie Sie auf dem Bild oben sehen können, schneidet Stable Code Instruct 3B im Vergleich zu führenden Modellen wie Codellama 7B Instruct und DeepSeek-Coder Instruct 1.3B bei einer Reihe von Codierungsaufgaben gut ab.
Tests zeigen, dass Stable Code Instruct 3B in der Lage ist, mit der Konkurrenz in Bezug auf die Genauigkeit der Codevervollständigung, das Verständnis natürlichsprachlicher Anweisungen und die Vielseitigkeit in verschiedenen Programmiersprachen mitzuhalten oder diese zu übertreffen.
 Bilder
Bilder
Stable Code Instruct 3B basiert auf den Ergebnissen der Entwicklerumfrage Stack Overflow 2023 und konzentriert das Training auf Programmiersprachen wie Python, Javascript, Java, C, C++ und Gehen.
Die obige Grafik vergleicht die Stärke der Ausgabe, die von drei Modellen in verschiedenen Programmiersprachen mithilfe des Multi-PL-Benchmarks generiert wurde. Es kann festgestellt werden, dass Stable Code Instruct 3B in allen Sprachen deutlich besser ist als CodeLlama und die Anzahl der Parameter mehr als die Hälfte beträgt.
Zusätzlich zu den oben genannten beliebten Programmiersprachen umfasst Stable Code Instruct 3B auch Schulungen für andere Sprachen (wie SQL, PHP und Rust) und kann selbst in Sprachen leistungsstarke Schulungen anbieten Testleistung ohne Training (z. B. Lua).
Stable Code Instruct 3B beherrscht nicht nur die Codegenerierung, sondern auch FIM-Aufgaben (füllen Sie die Mitte aus), Datenbankabfragen, Codeübersetzung, -interpretation und -erstellung.
Durch die Optimierung von Anweisungen sind Modelle in der Lage, subtile Anweisungen zu verstehen und darauf zu reagieren, was eine breite Palette von Codierungsaufgaben erleichtert, die über die einfache Codevervollständigung hinausgehen, wie etwa mathematisches Verständnis, logisches Denken und den Umgang mit komplexen Techniken der Softwareentwicklung.
 Bilder
Bilder
Modell-Download: https://huggingface.co/stabilityai/stable-code-instruct-3b
Stable Code Instruct 3B ist jetzt für kommerzielle Zwecke mit Stability AI-Mitgliedschaft verfügbar. Für den nichtkommerziellen Gebrauch können Modellgewichte und Code auf Hugging Face heruntergeladen werden.
Technische Details
 Bilder
Bilder
Modellarchitektur
Stable Code basiert auf Stable LM 3B und ist eine Nur-Decoder-Transformerstruktur mit einem ähnlichen Design wie LLaMA. Die folgende Tabelle enthält einige wichtige Strukturinformationen:
 Bilder
Bilder
Die Hauptunterschiede zu LLaMA umfassen:
Positionelle Einbettung: Verwenden Sie eine gedrehte positionelle Einbettung in den ersten 25 % der Kopfeinbettung, um die nachfolgende zu verbessern Durchsatz.
Regularisierung: Verwenden Sie LayerNorm mit Learning-Bias-Term anstelle von RMSNorm.
Bias-Begriffe: Alle Bias-Begriffe im Feedforward-Netzwerk und in der Multi-Head-Selbstaufmerksamkeitsschicht werden gelöscht, mit Ausnahme von KQV.
Verwendet den gleichen Tokenizer (BPE) wie das Stable LM 3B-Modell mit einer Größe von 50.257; außerdem werden auch spezielle Tags von StarCoder referenziert, einschließlich der Anzahl der Sterne, die zur Angabe des Dateinamens, des Repositorys usw. verwendet werden. und Zwischenfüllung (FIM) warten.
Für langes Kontexttraining verwenden Sie spezielle Markierungen, um anzuzeigen, wann zwei verkettete Dateien zum selben Repository gehören.
Trainingsprozess
Trainingsdaten
Der Pre-Training-Datensatz sammelt eine Vielzahl öffentlich zugänglicher großer Datenquellen, einschließlich Code-Repositorys, technischer Dokumentation (z. B. readthedocs) und mathematikbasierter Konzentrieren Sie sich auf Text und große Webdatensätze.
Das Hauptziel der anfänglichen Vortrainingsphase besteht darin, umfangreiche interne Darstellungen zu erlernen, um die Fähigkeit des Modells zum mathematischen Verständnis, zum logischen Denken und zur Verarbeitung komplexer technischer Texte im Zusammenhang mit der Softwareentwicklung erheblich zu verbessern.
Darüber hinaus enthalten die Trainingsdaten auch einen gemeinsamen Textdatensatz, um dem Modell breitere Sprachkenntnisse und Kontext bereitzustellen, wodurch das Modell letztendlich in die Lage versetzt wird, ein breiteres Spektrum an Abfragen und Aufgaben auf konversationelle Weise zu bearbeiten.
Die folgende Tabelle zeigt die Datenquellen, Kategorien und Stichprobengewichte des Korpus vor dem Training, wobei das Verhältnis von Code- und natürlichsprachlichen Daten 80:20 beträgt.
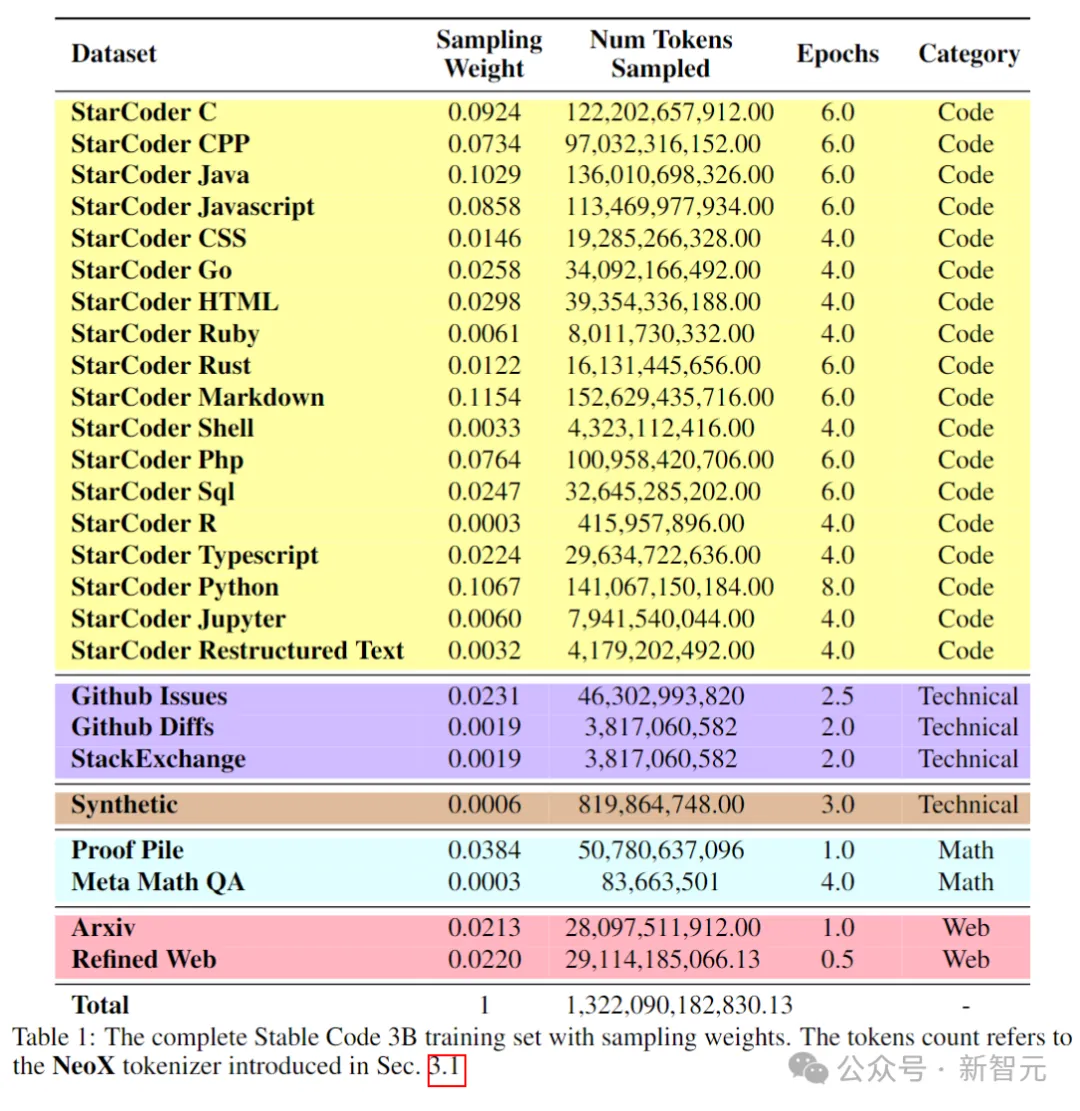 Bilder
Bilder
Darüber hinaus führten die Forscher auch einen kleinen synthetischen Datensatz ein. Die Daten wurden aus den Samenspitzen des CodeAlpaca-Datensatzes synthetisiert, der 174.000 Spitzen enthält.
Und folgen Sie der WizardLM-Methode, erhöhen Sie schrittweise die Komplexität der vorgegebenen Seed-Eingabeaufforderungen und erhalten Sie weitere 100.000 Eingabeaufforderungen.
Der Autor glaubt, dass die Einführung dieser synthetischen Daten zu Beginn der Vortrainingsphase dazu beiträgt, dass das Modell besser auf Text in natürlicher Sprache reagiert.
Langer Kontextdatensatz
Da mehrere Dateien in einem Repository häufig voneinander abhängen, ist die Kontextlänge für die Codierung von Modellen wichtig.
Die Forscher schätzten die mittlere und durchschnittliche Anzahl der Token im Software-Repository auf 12.000 bzw. 18.000, daher wurde 16.384 als Kontextlänge gewählt.
Der nächste Schritt bestand darin, einen langen Kontextdatensatz zu erstellen, der in gängigen Sprachen im Repository verfasst war, und sie miteinander zu kombinieren, wobei zwischen den einzelnen Dateien ein spezielles Tag eingefügt wurde, um die Trennung beizubehalten Inhaltsfluss.
Um mögliche Verzerrungen zu umgehen, die sich aus der festen Reihenfolge der Dateien ergeben könnten, haben die Autoren eine Randomisierungsstrategie gewählt. Für jedes Repository werden zwei unterschiedliche Sequenzen von Verbindungsdateien generiert.
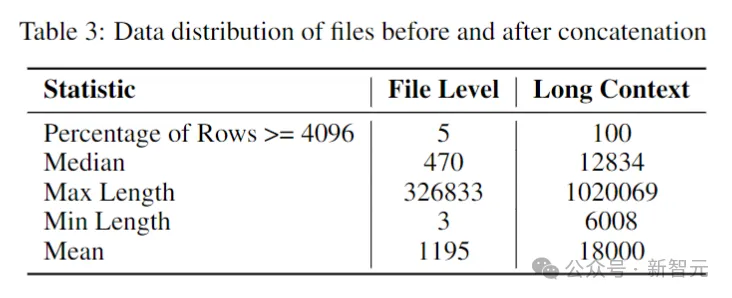 Bilder
Bilder
Phasenweises Training
Stable Code wird mit 32 Amazon P4d-Instanzen trainiert, die 256 NVIDIA A100 (40 GB HBM2) GPUs enthalten, und verwendet ZeRO für die verteilte Optimierung.
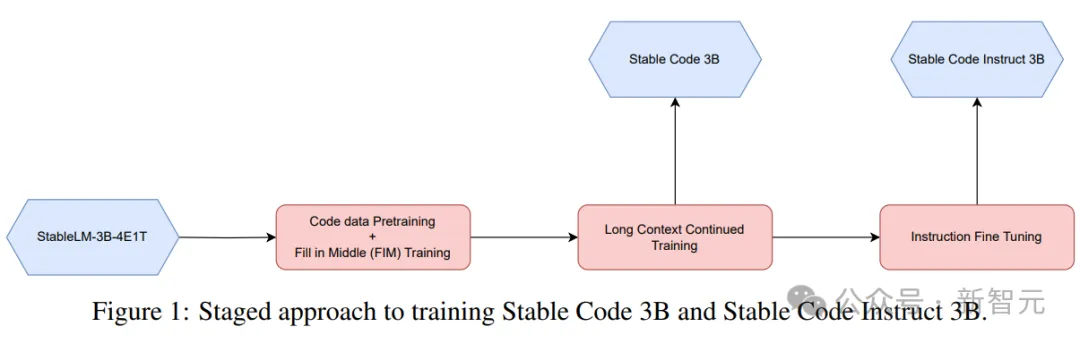 Bilder
Bilder
Hier kommt eine phasenweise Trainingsmethode zum Einsatz, wie im Bild oben dargestellt.
Das Training folgt der standardmäßigen autoregressiven Sequenzmodellierung, um den nächsten Token vorherzusagen. Das Modell wird mit dem Prüfpunkt von Stable LM 3B initialisiert. Die Kontextlänge der ersten Trainingsstufe beträgt 4096, und dann wird ein kontinuierliches Vortraining durchgeführt.
Das Training wird mit BFloat16 Mixed Precision durchgeführt und FP32 wird für die Gesamtreduzierung verwendet. Die Einstellungen des AdamW-Optimierers sind: β1=0,9, β2=0,95, ε=1e−6, λ (Gewichtsabfall)=0,1. Beginnen Sie mit der Lernrate = 3,2e-4, stellen Sie die minimale Lernrate auf 3,2e-5 ein und verwenden Sie den Kosinuszerfall.
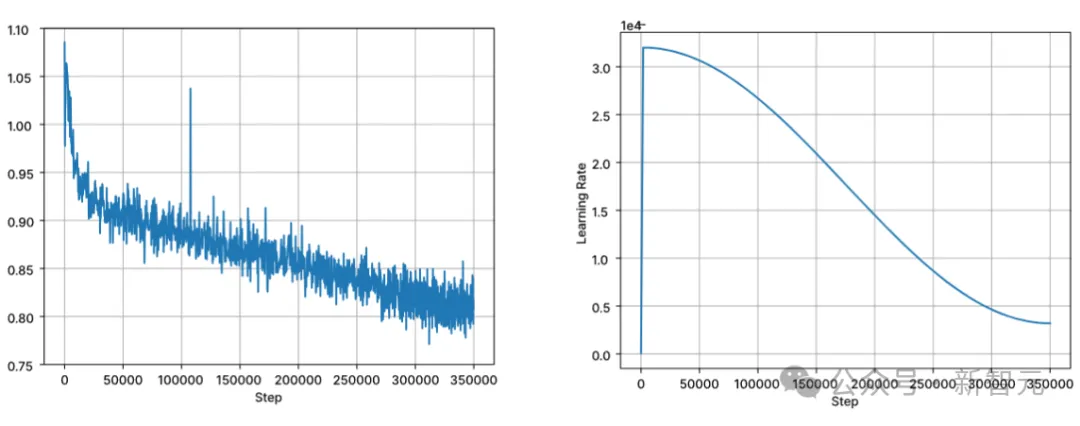 Bilder
Bilder
Eine der Kernannahmen des Modelltrainings in natürlicher Sprache ist die kausale Reihenfolge von links nach rechts. Für Code gilt diese Annahme jedoch nicht immer (z. B. Funktionsaufrufe und Funktion). Deklarationen können für viele Funktionen in beliebiger Reihenfolge vorliegen).
Um dieses Problem zu lösen, verwendeten Forscher FIM (Fill in the Middle). Teilen Sie das Dokument nach dem Zufallsprinzip in drei Segmente auf: Präfix, Mitte und Suffix, und verschieben Sie dann das mittlere Segment an das Ende des Dokuments. Nach der Neuordnung wird derselbe autoregressive Trainingsprozess durchgeführt.
Anweisungs-Feinabstimmung
Nach dem Vortraining verbessert der Autor die Dialogfähigkeiten des Modells durch eine Feinabstimmungsphase weiter, die überwachte Feinabstimmung (SFT) und direkte Präferenzoptimierung (DPO) umfasst.
Führen Sie zunächst die SFT-Feinabstimmung mithilfe öffentlich verfügbarer Datensätze auf Hugging Face durch: einschließlich OpenHermes, Code Feedback, CodeAlpaca.
Nach der Durchführung der exakten Match-Deduplizierung liefern die drei Datensätze insgesamt etwa 500.000 Trainingsbeispiele.
Verwenden Sie den Kosinus-Lernratenplaner, um den Trainingsprozess zu steuern, und legen Sie die globale Stapelgröße auf 512 fest, um die Eingabe in Sequenzen mit einer Länge von nicht mehr als 4096 zu packen.
Starten Sie nach SFT die DPO-Phase und verwenden Sie Daten von UltraFeedback, um einen Datensatz mit etwa 7.000 Proben zu kuratieren. Um die Sicherheit des Modells zu verbessern, hat der Autor außerdem den hilfreichen und harmlosen RLFH-Datensatz einbezogen.
Die Forscher übernahmen RMSProp als Optimierungsalgorithmus und erhöhten die Lernrate in der Anfangsphase des DPO-Trainings auf einen Spitzenwert von 5e-7.
Leistungstest
Im Folgenden wird die Leistung der Modelle bei Code-Vervollständigungsaufgaben verglichen, wobei der Multi-PL-Benchmark zur Bewertung der Modelle verwendet wird.
Stabile Codebasis
Die folgende Tabelle zeigt die Leistung verschiedener Codemodelle mit Parametern der Größe 3B und darunter auf Multi-PL.
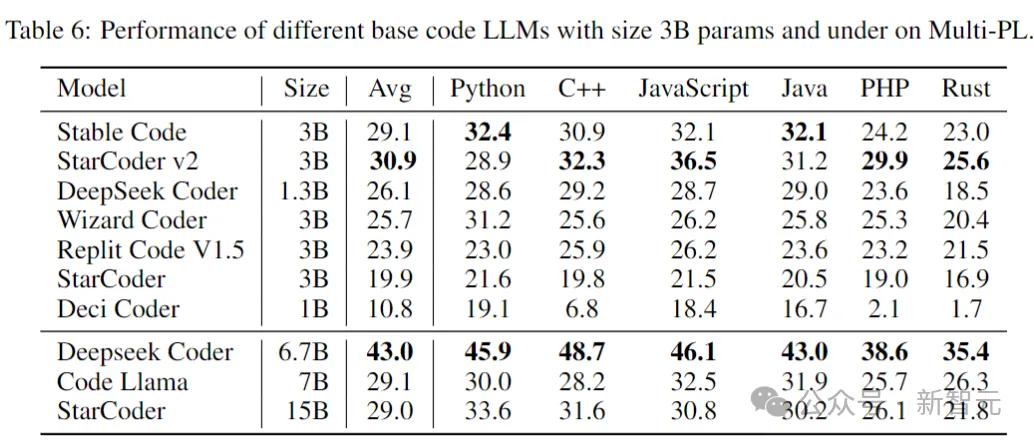 Bilder
Bilder
Obwohl die Anzahl der Parameter von Stable Code weniger als 40 % bzw. 20 % von Code Llama und StarCoder 15B beträgt, ist die durchschnittliche Leistung des Modells in verschiedenen Programmiersprachen gleichwertig ihnen.
Stable Code Instruct
In der folgenden Tabelle werden fein abgestimmte Instruct-Versionen mehrerer Modelle im Multi-PL-Benchmark bewertet.
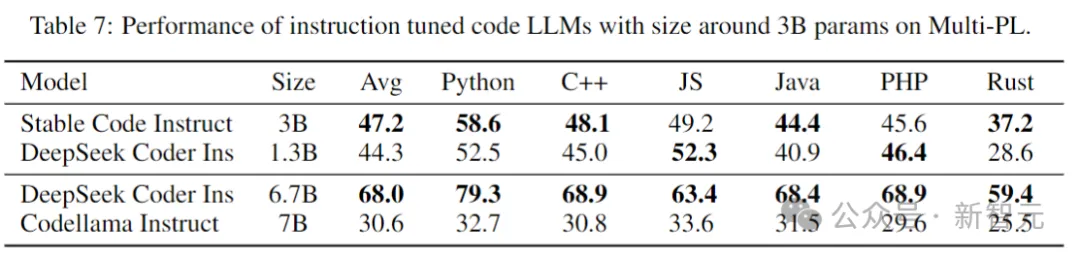 Bilder
Bilder
SQL-Leistung
Eine wichtige Anwendung des Code-Sprachmodells ist die Datenbankabfrageaufgabe. In diesem Bereich wird die Leistung von Stable Code Instruct mit anderen gängigen, auf Anweisungen abgestimmten Modellen und speziell für SQL trainierten Modellen verglichen. Benchmarks, die hier mit Defog AI erstellt wurden.
 Bilder
Bilder
Inferenzleistung
Die folgende Tabelle gibt den Durchsatz und den Stromverbrauch an, wenn stabiler Code auf Verbrauchergeräten und entsprechenden Systemumgebungen ausgeführt wird.
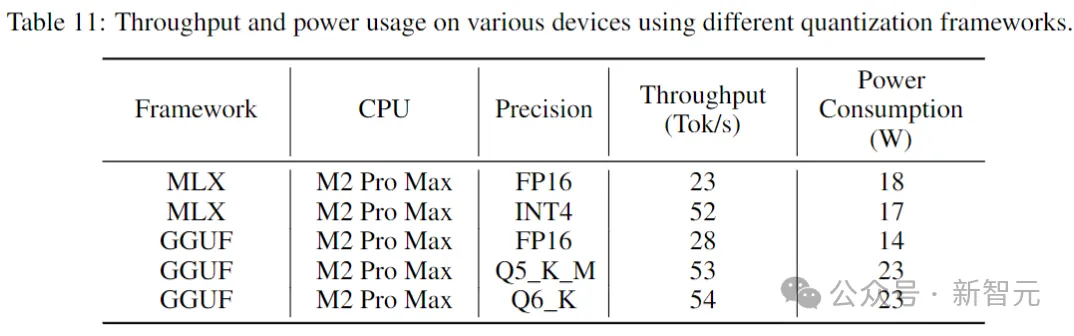 Bilder
Bilder
Die Ergebnisse zeigen, dass sich der Durchsatz bei Verwendung einer geringeren Präzision um fast das Doppelte erhöht. Es ist jedoch wichtig zu beachten, dass die Implementierung einer Quantisierung mit geringerer Präzision zu einer (möglicherweise erheblichen) Verschlechterung der Modellleistung führen kann.
Referenz: https://www.php.cn/link/8cb3522da182ff9ea5925bbd8975b203
Das obige ist der detaillierte Inhalt vonDer erste Beitrag, seit der Chef gegangen ist! Stabilität, offizielles Codemodell, Stable Code Instruct 3B. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie kann man adaptives Layout der Y-Achse-Position in Webanmerkungen implementieren?
Apr 04, 2025 pm 11:30 PM
Wie kann man adaptives Layout der Y-Achse-Position in Webanmerkungen implementieren?
Apr 04, 2025 pm 11:30 PM
Der ad-axis-Position adaptive Algorithmus für Webanmerkungen In diesem Artikel wird untersucht, wie Annotationsfunktionen ähnlich wie Word-Dokumente implementiert werden, insbesondere wie man mit dem Intervall zwischen Anmerkungen umgeht ...
 Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Die Methode zur Anpassung der Größe der Größe der Größe der Größe in CSS ist mit Hintergrundfarben einheitlich. In der täglichen Entwicklung begegnen wir häufig Situationen, in denen wir die Details der Benutzeroberfläche wie Anpassung anpassen müssen ...
 Wie verwendet ich das Clip-Pfad-Attribut von CSS, um den 45-Grad-Kurveneffekt des Segmenters zu erreichen?
Apr 04, 2025 pm 11:45 PM
Wie verwendet ich das Clip-Pfad-Attribut von CSS, um den 45-Grad-Kurveneffekt des Segmenters zu erreichen?
Apr 04, 2025 pm 11:45 PM
Wie kann man den 45-Grad-Kurveneffekt des Segmenters erreichen? Bei der Implementierung des Segmenters verwandeln Sie den rechten Rand in eine 45-Grad-Kurve, wenn Sie auf die linke Schaltfläche klicken, und der Punkt ...
 Wie kann ich die Höhe benachbarter Spalten in der Element -Benutzeroberfläche automatisch an den Inhalt anpassen?
Apr 05, 2025 am 06:12 AM
Wie kann ich die Höhe benachbarter Spalten in der Element -Benutzeroberfläche automatisch an den Inhalt anpassen?
Apr 05, 2025 am 06:12 AM
Wie kann ich die Höhe benachbarter Spalten derselben Zeile automatisch an den Inhalt anpassen? Im Webdesign stoßen wir oft auf dieses Problem: Wenn es viele in einer Tabelle oder einer Reihe gibt ...
 Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Das Problem der Containeröffnung aufgrund einer übermäßigen Auslassung von Text unter Flex -Layout und Lösungen werden verwendet ...
 Ist die H5-Seitenproduktion eine Front-End-Entwicklung?
Apr 05, 2025 pm 11:42 PM
Ist die H5-Seitenproduktion eine Front-End-Entwicklung?
Apr 05, 2025 pm 11:42 PM
Ja, die H5-Seitenproduktion ist eine wichtige Implementierungsmethode für die Front-End-Entwicklung, die Kerntechnologien wie HTML, CSS und JavaScript umfasst. Entwickler bauen dynamische und leistungsstarke H5 -Seiten auf, indem sie diese Technologien geschickt kombinieren, z. B. die Verwendung der & lt; canvas & gt; Tag, um Grafiken zu zeichnen oder JavaScript zu verwenden, um das Interaktionsverhalten zu steuern.
 Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Es gibt viele Möglichkeiten, Bootstrap -Bilder zu zentrieren, und Sie müssen keine Flexbox verwenden. Wenn Sie nur horizontal zentrieren müssen, reicht die Text-Center-Klasse aus. Wenn Sie vertikal oder mehrere Elemente zentrieren müssen, ist Flexbox oder Grid besser geeignet. Flexbox ist weniger kompatibel und kann die Komplexität erhöhen, während das Netz leistungsfähiger ist und höhere Lernkosten hat. Bei der Auswahl einer Methode sollten Sie die Vor- und Nachteile abwägen und die am besten geeignete Methode entsprechend Ihren Anforderungen und Vorlieben auswählen.
 Warum sind die Inline-Block-Elemente falsch ausgerichtet? Wie löst ich dieses Problem?
Apr 04, 2025 pm 10:39 PM
Warum sind die Inline-Block-Elemente falsch ausgerichtet? Wie löst ich dieses Problem?
Apr 04, 2025 pm 10:39 PM
In Bezug auf die Gründe und Lösungen für falsch ausgerichtete Darstellung von Inline-Block-Elementen. Beim Schreiben von Webseitenlayout stoßen wir oft auf einige scheinbar seltsame Anzeigenprobleme. Vergleichen...
