
 Technologie-Peripheriegeräte
KI
Aufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz
Technologie-Peripheriegeräte
KI
Aufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz
Aufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz

Mamba-Zeit ist gekommen?
Seit der Veröffentlichung der wegweisenden Forschungsarbeit „Attention is All You Need“ im Jahr 2017 dominiert die Transformer-Architektur das Feld der generativen künstlichen Intelligenz.
Allerdings hat die Transformer-Architektur tatsächlich zwei wesentliche Nachteile:
Der Speicherbedarf von Transformer variiert mit der Kontextlänge. Dies macht es schwierig, lange Kontextfenster oder umfangreiche Parallelverarbeitung ohne erhebliche Hardware-Ressourcen auszuführen, wodurch weitreichende Experimente und Bereitstellungen eingeschränkt werden. Der Speicherbedarf von Transformer-Modellen skaliert mit der Kontextlänge, wodurch es schwierig wird, lange Kontextfenster oder stark parallele Verarbeitung ohne nennenswerte Hardwareressourcen auszuführen, wodurch weitreichende Experimente und Bereitstellungen eingeschränkt werden.
Der Aufmerksamkeitsmechanismus im Transformer-Modell passt die Geschwindigkeit entsprechend der Zunahme der Kontextlänge an. Dieser Mechanismus erweitert die Sequenzlänge zufällig und reduziert den Rechenaufwand, da jedes Token von der gesamten Sequenz davor abhängt Reduzieren des Kontexts Wird außerhalb des Rahmens einer effizienten Produktion angewendet.
Transformer ist nicht der einzige Weg nach vorne für künstliche Intelligenz in der Produktion. Kürzlich haben AI21 Labs eine neue Methode namens „Jamba“ eingeführt und als Open-Source-Lösung bereitgestellt, die den Transformer in mehreren Benchmarks übertrifft.

Hugging Face-Adresse: https://huggingface.co/ai21labs/Jamba-v0.1
Mambas SSM-Architektur kann die Speicherressourcen und Kontextprobleme des Transformators gut lösen. Allerdings hat der Mamba-Ansatz Schwierigkeiten, das gleiche Leistungsniveau wie das Transformer-Modell zu liefern.
Jamba kombiniert das Mamba-Modell basierend auf dem Structured State Space Model (SSM) mit der Transformer-Architektur und zielt darauf ab, die besten Eigenschaften von SSM und Transformer zu kombinieren.

Jamba ist auch über den NVIDIA API-Katalog als NVIDIA NIM-Inferenz-Microservice zugänglich, den Entwickler von Unternehmensanwendungen mithilfe der NVIDIA AI Enterprise-Softwareplattform bereitstellen können.
Im Allgemeinen weist das Jamba-Modell die folgenden Merkmale auf:
Das erste auf Mamba basierende Modell auf Produktionsebene, das die neuartige SSM-Transformer-Hybridarchitektur verwendet.
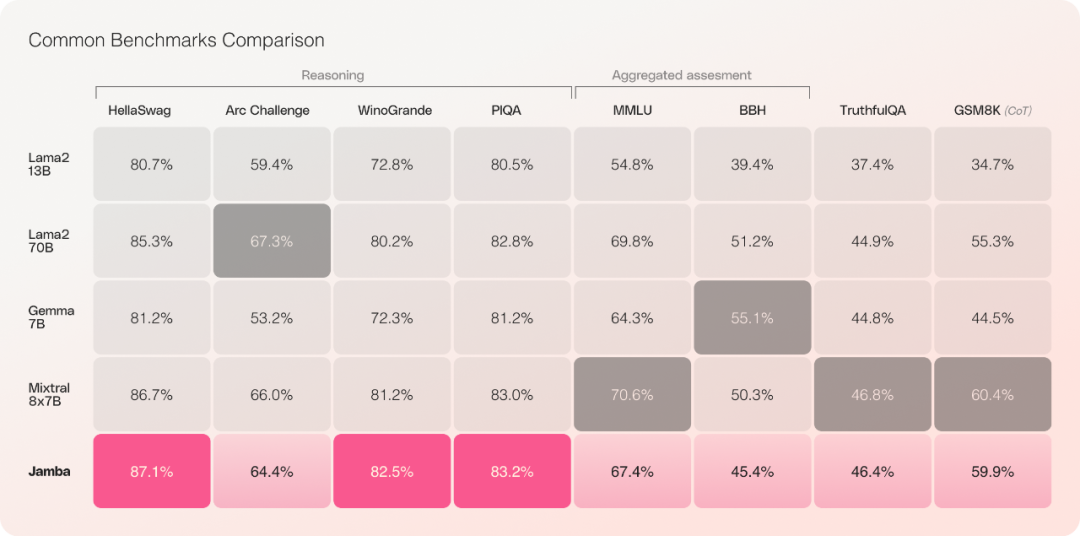
Im Vergleich zu Mixtral 8x7B beträgt der Durchsatz um das Dreifache erhöht;
bietet Zugriff auf 256.000 Kontextfenster;
Das einzige Modell mit der gleichen Parameterskala, das bis zu 140.000 Kontexte auf einer einzelnen GPU aufnehmen kann.
- Modellarchitektur
Wie in der Abbildung unten dargestellt, verfolgt Jambas Architektur einen Block-und-Schichten-Ansatz, der es Jamba ermöglicht, die beiden Architekturen zu integrieren. Jeder Jamba-Block besteht aus einer Aufmerksamkeitsschicht oder einer Mamba-Schicht, gefolgt von einem mehrschichtigen Perzeptron (MLP), das eine Transformatorschicht bildet.
Jamba nutzt MoE, um die Gesamtzahl der Modellparameter zu erhöhen und gleichzeitig die Anzahl der in der Inferenz verwendeten aktiven Parameter zu vereinfachen, was zu einer höheren Modellkapazität ohne entsprechende Erhöhung der Rechenanforderungen führt. Um die Modellqualität und den Durchsatz auf einer einzelnen 80-GB-GPU zu maximieren, optimierte das Forschungsteam die Anzahl der verwendeten MoE-Schichten und Experten und ließ so genügend Speicher für gängige Inferenz-Workloads übrig.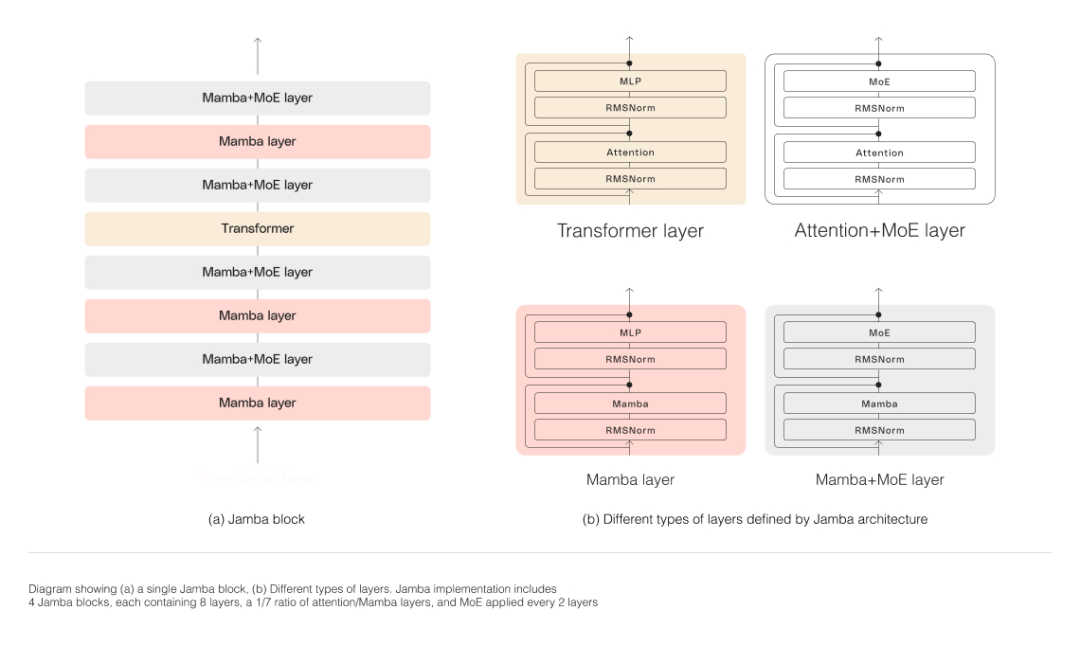 Jambas MoE-Schicht ermöglicht die Nutzung von nur 12B der verfügbaren 52B Parameter zur Inferenzzeit und seine Hybridarchitektur macht diese 12B aktiven Parameter effizienter als ein reines Transformatormodell derselben Größe.
Jambas MoE-Schicht ermöglicht die Nutzung von nur 12B der verfügbaren 52B Parameter zur Inferenzzeit und seine Hybridarchitektur macht diese 12B aktiven Parameter effizienter als ein reines Transformatormodell derselben Größe. Niemand hat Mamba bisher über die 3B-Parameter hinaus erweitert. Jamba ist die erste Hybridarchitektur ihrer Art, die den Produktionsmaßstab erreicht.
Durchsatz und EffizienzVorläufige Evaluierungsexperimente zeigen, dass Jamba bei wichtigen Kennzahlen wie Durchsatz und Effizienz gut abschneidet. In Bezug auf die Effizienz erreicht Jamba bei langen Kontexten den dreifachen Durchsatz von Mixtral 8x7B. Jamba ist effizienter als Transformer-basierte Modelle ähnlicher Größe wie Mixtral 8x7B.
Was die Kosten betrifft, kann Jamba 140.000 Kontexte auf einer einzigen GPU unterbringen. Jamba bietet mehr Bereitstellungs- und Experimentiermöglichkeiten als andere aktuelle Open-Source-Modelle ähnlicher Größe.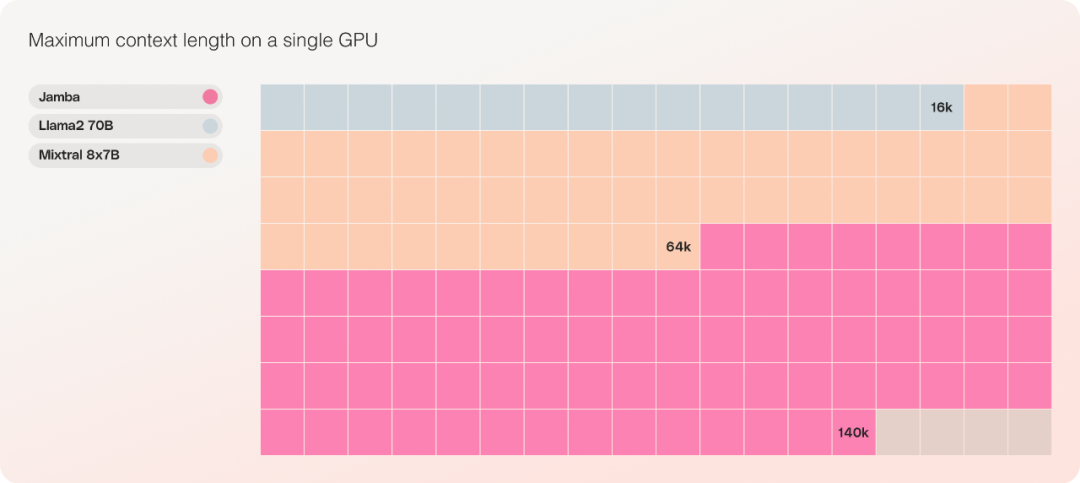
Es ist zu beachten, dass Jamba derzeit wahrscheinlich nicht die aktuellen Transformer-basierten Large Language Models (LLM) ersetzen wird, in einigen Bereichen jedoch möglicherweise eine Ergänzung darstellt.
Referenzlink:
https://www.ai21.com/blog/anncreasing-jamba
https://venturebeat.com/ai/ai21-labs-juices-up- gen-ai-transformers-with-jamba/
Das obige ist der detaillierte Inhalt vonAufmerksamkeit ist nicht alles, was Sie brauchen! Mamba-Hybrid-Großmodell Open Source: dreifacher Transformer-Durchsatz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1659
1659
 14
1415
52
1310
25
1258
29
1232
24
14
1415
52
1310
25
1258
29
1232
24

 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
 Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Distributed Artificial Intelligence Conference DAI 2024 Call for Papers: Agent Day, Richard Sutton, der Vater des Reinforcement Learning, wird teilnehmen! Yan Shuicheng, Sergey Levine und DeepMind-Wissenschaftler werden Grundsatzreden halten
Aug 22, 2024 pm 08:02 PM
Einleitung zur Konferenz Mit der rasanten Entwicklung von Wissenschaft und Technologie ist künstliche Intelligenz zu einer wichtigen Kraft bei der Förderung des sozialen Fortschritts geworden. In dieser Zeit haben wir das Glück, die Innovation und Anwendung der verteilten künstlichen Intelligenz (DAI) mitzuerleben und daran teilzuhaben. Verteilte Künstliche Intelligenz ist ein wichtiger Zweig des Gebiets der Künstlichen Intelligenz, der in den letzten Jahren immer mehr Aufmerksamkeit erregt hat. Durch die Kombination des leistungsstarken Sprachverständnisses und der Generierungsfähigkeiten großer Modelle sind plötzlich Agenten aufgetaucht, die auf natürlichen Sprachinteraktionen, Wissensbegründung, Aufgabenplanung usw. basieren. AIAgent übernimmt das große Sprachmodell und ist zu einem heißen Thema im aktuellen KI-Kreis geworden. Au
 KI im Einsatz |. Das verrückte KI-Spiel Amway des Microsoft-CEOs hat mich tausende Male gequält
Aug 14, 2024 am 12:00 AM
KI im Einsatz |. Das verrückte KI-Spiel Amway des Microsoft-CEOs hat mich tausende Male gequält
Aug 14, 2024 am 12:00 AM
Herausgeber des Machine Power Report: Yang Wen Die Welle der künstlichen Intelligenz, repräsentiert durch große Modelle und AIGC, hat unsere Art zu leben und zu arbeiten still und leise verändert, aber die meisten Menschen wissen immer noch nicht, wie sie sie nutzen sollen. Aus diesem Grund haben wir die Kolumne „KI im Einsatz“ ins Leben gerufen, um detailliert vorzustellen, wie KI durch intuitive, interessante und prägnante Anwendungsfälle für künstliche Intelligenz eingesetzt werden kann, und um das Denken aller anzuregen. Wir heißen Leser auch willkommen, innovative, praktische Anwendungsfälle einzureichen. Oh mein Gott, KI ist wirklich ein Genie geworden. In letzter Zeit ist es zu einem heißen Thema geworden, dass es schwierig ist, die Authentizität von KI-generierten Bildern zu erkennen. (Weitere Informationen finden Sie unter: KI im Einsatz | In drei Schritten zur KI-Schönheit werden und in einer Sekunde von der KI wieder in ihre ursprüngliche Form zurückgeprügelt werden) Neben der beliebten KI von Google Lady im Internet gibt es verschiedene FLUX-Generatoren entstanden auf sozialen Plattformen
