

Ein Foto + ein Video können das Foto zum Leben erwecken!
Vor kurzem ist Champ, ein kontrollierbares Werk zur Erzeugung menschlicher Sehkraft, das gemeinsam von Alibaba, der Fudan-Universität und der Nanjing-Universität veröffentlicht wurde, im gesamten Internet populär geworden. Dieses Modell ist erst seit 5 Tagen als Open Source verfügbar und hat auf GitHub 1.000 Sterne erhalten. Es erfreut sich großer Beliebtheit auf Twitter und lockt viele Blogger an, neue Projekte zu erstellen. Die Gesamtzahl der Aufrufe hat 300.000 erreicht.
Derzeit hat Champ den Inferenzcode und die Gewichte als Open Source bereitgestellt, und Benutzer können sie direkt von Github herunterladen und verwenden. Die offizielle Hugging Face-Demo wurde gestartet und gleichzeitig wird auch die gekapselte Champ-ComfyUI beworben. Die GitHub-Homepage zeigt, dass das Team den Trainingscode und die Datensätze in naher Zukunft als Open Source veröffentlichen wird. Interessierte Partner können weiterhin auf die Projektdynamik achten. 
Projekthomepage: https://fudan-generative-vision.github.io/champ/
Papierlink: https://arxiv.org/abs/2403.14781
Github-Link: https ://github.com/fudan-generative-vision/champ
Hugging Face Link: https://huggingface.co/fudan-generative-ai/champ
Champ-Videoeffekt auf Porträts aus der realen Welt, Dadurch können verschiedene Porträts dieselbe Aktion „kopieren“, indem sie das Aktionsvideo aus der oberen linken Ecke als Eingabe verwenden.

Obwohl Champ nur mit Videos von echten menschlichen Körpern trainiert wurde, hat es eine starke Verallgemeinerungsfähigkeit bei verschiedenen Bildtypen bewiesen:

Schwarz-Weiß-Fotos, Ölgemälde, Aquarelle und andere Effekte sind hervorragend, und das auch Funktioniert gut bei verschiedenen Bildtypen. Realistische Bilder, die durch Diagrammmodelle generiert werden, einschließlich virtueller Charaktere:

Technischer Überblick
Champ verwendet ein fortschrittliches menschliches Netzwiederherstellungsmodell, um den entsprechenden parametrisierten dreidimensionalen menschlichen Körper aus dem zu extrahieren Geben Sie ein menschliches Körpervideo ein. Die SMPL-Sequenz des Netzmodells (Skinned Multi-Person Linear Model) rendert außerdem die entsprechende Tiefenkarte, Normalkarte, menschliche Körperhaltung und menschliche semantische Karte, die als entsprechende Bewegungssteuerungsbedingungen zur Steuerung der Videogenerierung verwendet werden Durch die Übertragung von Aktionen auf die Eingabe auf das Referenzporträt kann die Qualität des Bewegungsvideos sowie die geometrische und Erscheinungsbildkonsistenz erheblich verbessert werden.
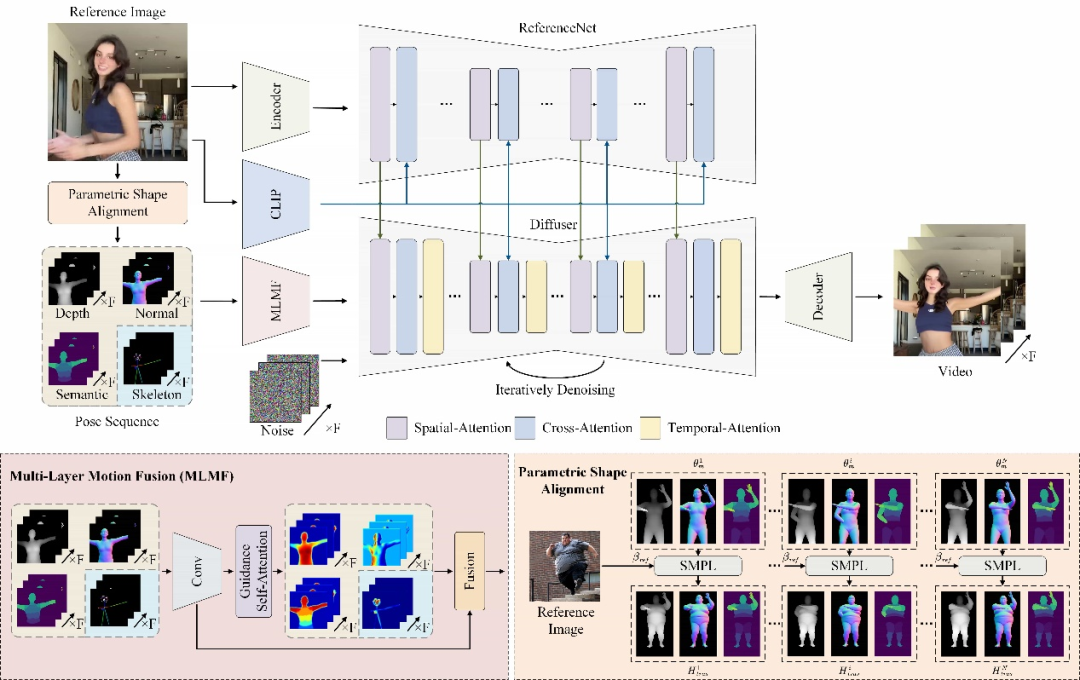
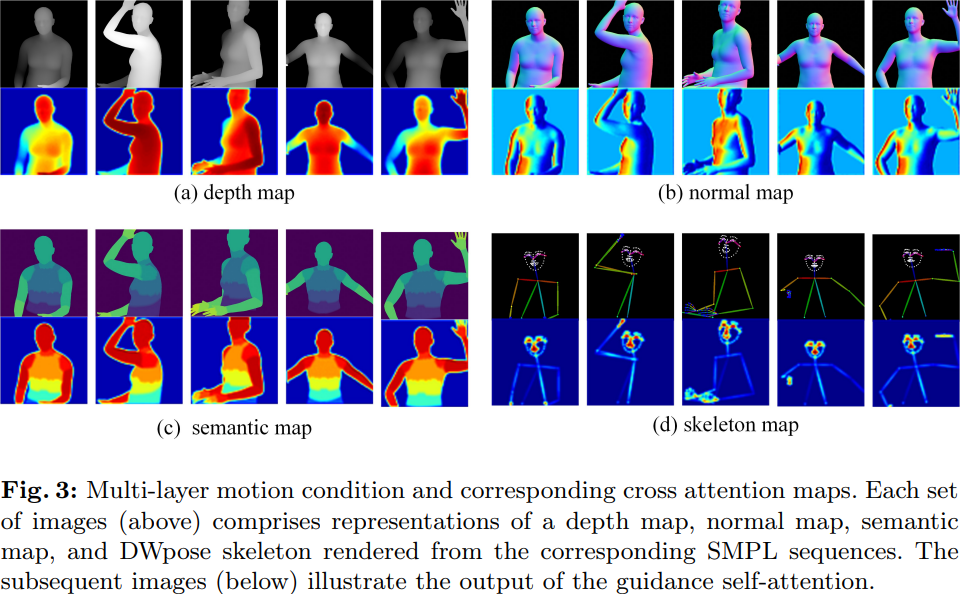
Für unterschiedliche Bewegungsbedingungen verwendet Champ ein mehrschichtiges Bewegungsfusionsmodul (MLMF), das den Selbstaufmerksamkeitsmechanismus nutzt, um die Eigenschaften zwischen verschiedenen Bedingungen vollständig zu integrieren und so eine verfeinerte Bewegungssteuerung zu erreichen. Die folgende Abbildung zeigt die Aufmerksamkeitsvisualisierungsergebnisse dieses Moduls unter verschiedenen Bedingungen: Die Tiefenkarte konzentriert sich auf die geometrischen Umrissinformationen der menschlichen Form, die Normalkarte zeigt die Ausrichtung des menschlichen Körpers an und die semantische Karte steuert die Erscheinungsbildkorrespondenz verschiedener Teile des menschlichen Körpers und des menschlichen Haltungsskeletts. Es konzentriert sich nur auf die wichtigsten Details des Gesichts und der Hände.
Andererseits entdeckte und löste Champ das Problem der Körperformmigration, das bei der Erstellung menschlicher Videos ignoriert wurde. Frühere Arbeiten basierten entweder auf dem menschlichen Skelettmodell oder auf anderen geometrischen Informationen, die aus dem Eingabevideo gewonnen wurden, um die Bewegung der menschlichen Figur zu steuern. Diese Methoden waren jedoch nicht in der Lage, die Bewegung von der menschlichen Körperform zu entkoppeln, was zu dem erzeugten Ergebnis führte Die Ergebnisse stimmen nicht mit dem menschlichen Körper im Referenzbild überein.
Angenommen als Referenzbild ist beispielsweise das Vergleichsergebnis in Abbildung 7 dargestellt:

Es ist ersichtlich, dass in den generierten Ergebnissen von Animate Everyone und MagicAnimate der dicke, dicke Bauch zu sehen ist geglättet, gleichmäßig Der Rahmen ist auch etwas geschrumpft. Champ verwendet die Körperformparameter in SMPL, um sie an der SMPL-Sequenz auszurichten, die das Video in einer parametrisierten Körperform steuert, wodurch die beste Konsistenz in Körperform und Aktion erreicht wird (mit PST im Bild).
Experimentelle Ergebnisse
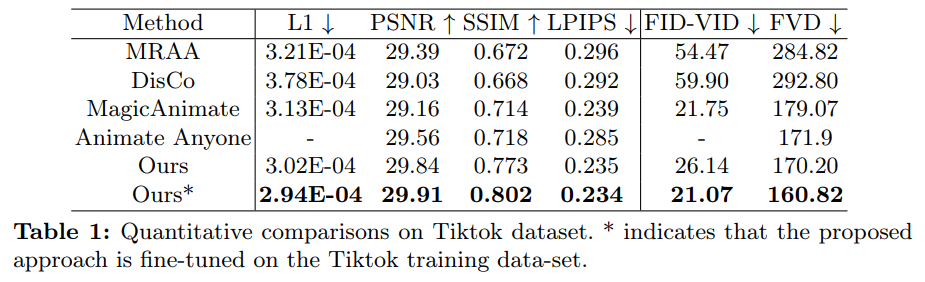
Wie in Tabelle 4 unten gezeigt, verfügt Champ im Vergleich zu anderen SOTA-Arbeiten über eine bessere Bewegungskontrolle und weniger Artefakte:

Gleichzeitig demonstriert Champ auch seine überlegene Generalisierungsleistung und Stabilität beim Aussehensabgleich:


Weitere technische Details und experimentelle Ergebnisse finden Sie im Originalpapier und Code von Champ. Sie können auch zu HuggingFace gehen oder den offiziellen Quellcode herunterladen, um praktische Erfahrungen zu sammeln.
Das obige ist der detaillierte Inhalt vonChamp ist das erste Open Source: Human Body Video generiert neues SOTA, hat in 5 Tagen 1.000 Sterne gewonnen und die Demo ist spielbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Methode zur Erstellung von Intouch-Berichten
Methode zur Erstellung von Intouch-Berichten
 Eigenschaften des Netzwerks
Eigenschaften des Netzwerks
 DSP-Anwendungsbereiche
DSP-Anwendungsbereiche
 So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
So lösen Sie das Problem, dass Teamviewer keine Verbindung herstellen kann
 So löschen Sie ein Verzeichnis unter LINUX
So löschen Sie ein Verzeichnis unter LINUX
 Der Unterschied zwischen zufällig und pseudozufällig
Der Unterschied zwischen zufällig und pseudozufällig
 So öffnen Sie JAR-Dateien
So öffnen Sie JAR-Dateien
 Welche Währung ist U-Coin?
Welche Währung ist U-Coin?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



