
 Technologie-Peripheriegeräte
KI
Das neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich
Technologie-Peripheriegeräte
KI
Das neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich
Das neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich

Die Langtextfunktion von CLIP ist freigeschaltet und die Leistung von Bildabrufaufgaben ist erheblich verbessert!
Einige wichtige Details können ebenfalls erfasst werden. Die Shanghai Jiao Tong University und das Shanghai AI Laboratory haben ein neues Framework Long-CLIP vorgeschlagen.
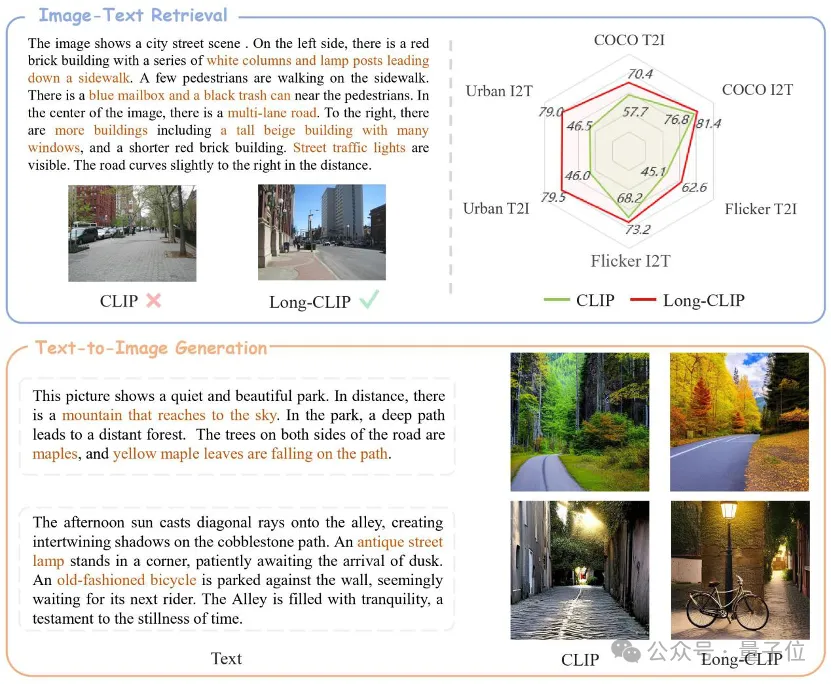
△Der braune Text ist das wichtigste Detail, das die beiden Bilder unterscheidet.
Long-CLIP basiert auf der Beibehaltung des ursprünglichen Funktionsraums von CLIP und lässt sich in nachgelagerte Aufgaben wie die Bildgenerierung integrieren, um eine gute Leistung zu erzielen -körnige Bilderzeugung von Langtexten.
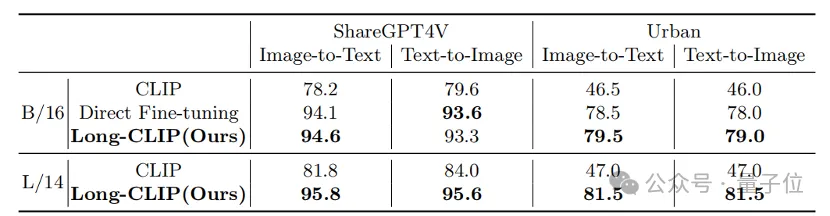
Der Abruf von langen Texten und Bildern stieg um 20 %, der Abruf von kurzen Texten und Bildern um 6 %.
Entsperren Sie die Langtextfunktionen von CLIP.
CLIP richtet visuelle und Textmodalitäten aus und verfügt über leistungsstarke Zero-Shot-Generalisierungsfunktionen. Daher wird CLIP häufig für verschiedene multimodale Aufgaben verwendet, z. B. für die Bildklassifizierung, das Abrufen von Textbildern, die Bildgenerierung usw.
Aber ein großer Nachteil von CLIP ist das Mangel an Langtextfunktionen.
Erstens ist die Texteingabelänge von CLIP aufgrund der Verwendung der absoluten Positionskodierung auf 677 Token begrenzt. Darüber hinaus haben Experimente gezeigt, dass die tatsächliche effektive Länge von CLIP sogar weniger als 20 Token beträgt, was bei weitem nicht ausreicht, um feinkörnige Informationen darzustellen. Um diese Einschränkung zu überwinden, haben Forscher jedoch eine Lösung vorgeschlagen. Durch die Einführung spezifischer Tags in die Texteingabe kann sich das Modell auf die wichtigen Teile konzentrieren. Die Position und Anzahl dieser Token in der Eingabe wird im Voraus festgelegt und wird 20 Token nicht überschreiten. Auf diese Weise ist CLIP in der Lage, Texteingaben zu verarbeiten. Das Fehlen von Langtext auf der Textseite schränkt auch die Möglichkeiten der visuellen Seite ein. Da es nur kurzen Text enthält, extrahiert der visuelle Encoder von CLIP nur die wichtigsten Komponenten eines Bildes und ignoriert verschiedene Details. Dies ist für feinkörnige Aufgaben wie den
Cross-modal Retrievalsehr schädlich. Gleichzeitig führt das Fehlen von Langtext dazu, dass CLIP eine einfache Modellierungsmethode ähnlich der Bag-of-Feature (BOF) verwendet, die nicht über komplexe Funktionen wie Kausalschlussfolgerungen verfügt.
Um dieses Problem anzugehen, schlugen Forscher das Long-CLIP-Modell vor.
Konkret wurden zwei Strategien vorgeschlagen: Wissenserhaltendes Dehnen der Positionseinbettung und eine Feinabstimmungsstrategie, die die Ausrichtung der Kernkomponenten hinzufügt (Primärkomponenten-Matching). 
Wissenserhaltende Erweiterung der Positionskodierung
Eine einfache Methode, die Eingabelänge zu erweitern und die Fähigkeit von Langtexten zu verbessern, besteht darin, die Positionskodierung zunächst mit einem festen Verhältnis λ
1zu interpolieren und sie dann über die Länge hinweg zu optimieren Text. Forscher fanden heraus, dass der Trainingsgrad verschiedener Positionskodierungen von CLIP unterschiedlich ist. Da es sich bei dem Trainingstext wahrscheinlich hauptsächlich um kurzen Text handelt, ist die niedrigere Positionscodierung vollständiger trainiert und kann die absolute Position genau darstellen, während die höhere Positionscodierung nur ihre ungefähre relative Position darstellen kann. Daher sind die Kosten für die Interpolation von Codes an verschiedenen Positionen unterschiedlich.
Basierend auf den obigen Beobachtungen behielt der Forscher die ersten 20 Positionscodes bei und interpolierte sie mit einem größeren Verhältnis λ
2. Die Berechnungsformel kann wie folgt ausgedrückt werden:
Experiment Es zeigt das Im Vergleich zur direkten Interpolation kann diese Strategie die Leistung bei verschiedenen Aufgaben erheblich verbessern und gleichzeitig eine längere Gesamtlänge unterstützen. 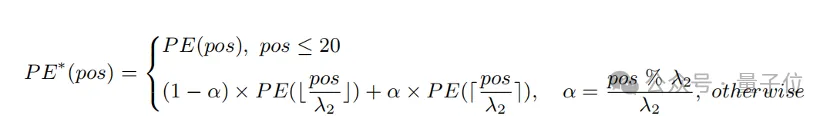
Fügen Sie eine Feinabstimmung der Kernattributausrichtung hinzu.
Nur die Einführung einer Feinabstimmung des Langtextes führt zu einem weiteren Missverständnis des Modells, das darin besteht, alle Details gleichermaßen einzubeziehen. Um dieses Problem anzugehen, führten Forscher bei der Feinabstimmung die Strategie der Ausrichtung von Kernattributen ein.
Konkret verwendeten die Forscher den Algorithmus der Hauptkomponentenanalyse (PCA), um Kernattribute aus feinkörnigen Bildmerkmalen zu extrahieren, die verbleibenden Attribute zu filtern, um grobkörnige Bildmerkmale zu rekonstruieren, und sie mit zusammengefassten Kurztexten zu vergleichen. Diese Strategie erfordert, dass das Modell nicht nur mehr Details enthält (feinkörnige Ausrichtung), sondern auch die wichtigsten Kernattribute identifiziert und modelliert (Kernkomponentenextraktion und grobkörnige Ausrichtung).
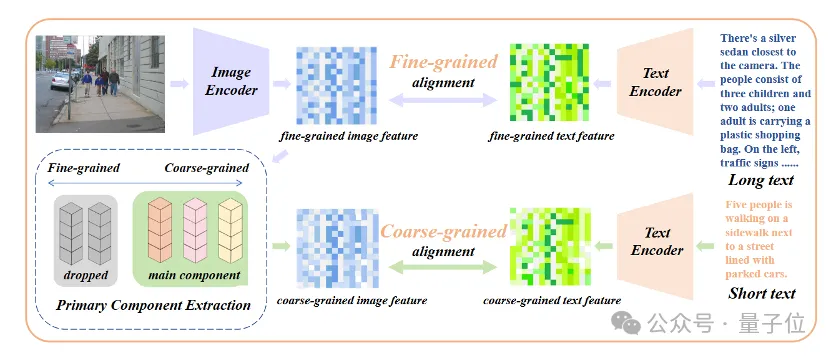 △Fügen Sie den Feinabstimmungsprozess der Kernattributausrichtung hinzu
△Fügen Sie den Feinabstimmungsprozess der Kernattributausrichtung hinzu
Plug-and-Play für verschiedene multimodale Aufgaben
In den Bereichen Bild- und Textabruf, Bildgenerierung und anderen Bereichen kann Long-CLIP Plug-and-Play-fähig sein abspielen, um CLIP zu ersetzen.
Beim Bild- und Textabruf kann Long-CLIP beispielsweise feinkörnigere Informationen im Bild- und Textmodus erfassen, wodurch die Fähigkeit zur Unterscheidung ähnlicher Bilder und Texte verbessert und die Leistung des Bild- und Textabrufs erheblich verbessert wird.
Ob es sich um herkömmliche Kurztext-Retrieval-Aufgaben (COCO, Flickr30k) oder Langtext-Retrieval-Aufgaben handelt, Long-CLIP hat die Erinnerungsrate deutlich verbessert. Experimentelle Ergebnisse zum Abrufen von kurzen Texten und Bildern Bilder
Darüber hinaus wird der Text-Encoder von CLIP häufig in Text-zu-Bild-Generierungsmodellen wie der Stable Diffusion-Serie usw. verwendet. Allerdings sind die Textbeschreibungen, die zur Generierung von Bildern verwendet werden, aufgrund fehlender Langtextfunktionen meist sehr kurz und können nicht mit verschiedenen Details angepasst werden. 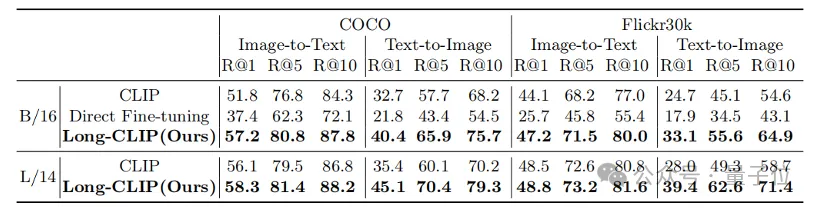
Papierlink:
Codelink:
https://github.com/beichenzbc/Long-CLIP
Das obige ist der detaillierte Inhalt vonDas neue Framework der Shanghai Jiao Tong University erschließt CLIP-Langtextfunktionen, erfasst die Details der multimodalen Generierung und verbessert die Bildabruffunktionen erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laravel eloquent orm bei bangla partieller Modellsuche)
Apr 08, 2025 pm 02:06 PM
Laraveleloquent-Modellab Abruf: Das Erhalten von Datenbankdaten Eloquentorm bietet eine prägnante und leicht verständliche Möglichkeit, die Datenbank zu bedienen. In diesem Artikel werden verschiedene eloquente Modellsuchtechniken im Detail eingeführt, um Daten aus der Datenbank effizient zu erhalten. 1. Holen Sie sich alle Aufzeichnungen. Verwenden Sie die Methode All (), um alle Datensätze in der Datenbanktabelle zu erhalten: UseApp \ Models \ post; $ posts = post :: all (); Dies wird eine Sammlung zurückgeben. Sie können mit der Foreach-Schleife oder anderen Sammelmethoden auf Daten zugreifen: foreach ($ postas $ post) {echo $ post->
