
 Technologie-Peripheriegeräte
KI
Detaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?
Technologie-Peripheriegeräte
KI
Detaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?
Detaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?

Seit der Veröffentlichung des Artikels „Attention Is All You Need“ im Jahr 2017 ist die Transformer-Architektur der Eckpfeiler des Bereichs Natural Language Processing (NLP). Sein Design ist seit Jahren weitgehend unverändert geblieben, wobei das Jahr 2022 mit der Einführung von Rotary Position Encoding (RoPE) eine große Entwicklung auf diesem Gebiet markiert.
Rotierte Positionseinbettung ist die fortschrittlichste NLP-Positionseinbettungstechnologie. Die meisten gängigen großen Sprachmodelle wie Llama, Llama2, PaLM und CodeGen verwenden es bereits. In diesem Artikel gehen wir näher darauf ein, was Rotationspositionskodierungen sind und wie sie die Vorteile absoluter und relativer Positionseinbettungen geschickt miteinander verbinden.
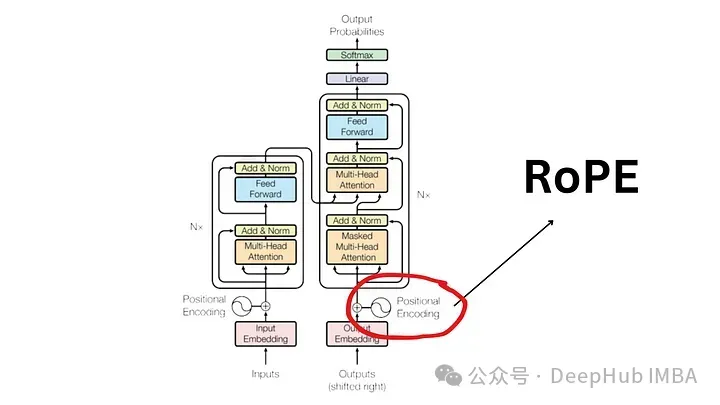
Die Notwendigkeit der Positionskodierung
Um die Bedeutung von RoPE zu verstehen, schauen wir uns zunächst an, warum die Positionskodierung entscheidend ist. Transformatormodelle berücksichtigen aufgrund ihres inhärenten Designs nicht die Reihenfolge der Eingabetokens.
Zum Beispiel gelten Ausdrücke wie „Der Hund jagt das Schwein“ und „Das Schwein jagt die Hunde“, obwohl sie unterschiedliche Bedeutungen haben, als nicht unterscheidbar, da sie als ungeordneter Satz von Token betrachtet werden. Um Sequenzinformationen und ihre Bedeutung aufrechtzuerhalten, ist eine Darstellung erforderlich, um Positionsinformationen in das Modell zu integrieren.
Absolute Positionskodierung
Um die Positionen in einem Satz zu kodieren, wird ein weiteres Werkzeug benötigt, das Vektoren mit den gleichen Abmessungen verwendet, wobei jeder Vektor eine Position im Satz darstellt. Geben Sie beispielsweise einen bestimmten Vektor für das zweite Wort in einem Satz an. Daher hat jede Satzposition ihren eindeutigen Vektor. Die Eingabe in die Transformer-Schicht wird dann durch Kombinieren der Worteinbettungen mit den Einbettungen ihrer entsprechenden Positionen gebildet.
Es gibt zwei Hauptmethoden, um diese Einbettungen zu generieren:
- Lernen aus Daten: Hier wird der Positionsvektor während des Trainings gelernt, genau wie andere Modellparameter. Wir lernen für jede Position einen eindeutigen Vektor (z. B. von 1 bis 512). Dies führt zu einer Einschränkung: Die maximale Sequenzlänge ist begrenzt. Wenn das Modell nur Position 512 lernt, kann es keine Sequenzen darstellen, die länger als diese Position sind.
- Sinusfunktion: Diese Methode beinhaltet die Verwendung einer Sinusfunktion, um eine eindeutige Einbettung für jede Position zu erstellen. Obwohl die Details dieser Konstruktion komplex sind, bietet sie im Wesentlichen eine eindeutige Positionseinbettung für jede Position in der Sequenz. Empirische Studien zeigen, dass das Erlernen und Verwenden von Sinusfunktionen aus Daten in realen Modellen eine vergleichbare Leistung erzielen kann.
Einschränkungen der absoluten Positionskodierung
Obwohl die absolute Positionseinbettung weit verbreitet ist, ist sie nicht ohne Nachteile:
- Begrenzte Sequenzlänge: Wie oben erwähnt, wenn das Modell bis zu einem bestimmten Punkt A lernt Positionsvektor, der von Natur aus keine Positionen jenseits dieser Grenze darstellen kann.
- Unabhängigkeit von Standorteinbettungen: Jede Standorteinbettung ist unabhängig von anderen Standorteinbettungen. Das bedeutet, dass aus Sicht des Modells die Differenz zwischen den Positionen 1 und 2 gleich der Differenz zwischen den Positionen 2 und 500 ist. Tatsächlich dürften die Positionen 1 und 2 jedoch enger miteinander verbunden sein als die deutlich weiter entfernte Position 500. Dieser Mangel an relativer Positionierung kann die Fähigkeit des Modells beeinträchtigen, die Nuancen der Sprachstruktur zu verstehen.
Relative Positionskodierung
Die relative Position konzentriert sich nicht auf die absolute Position von Noten im Satz, sondern auf den Abstand zwischen Notenpaaren. Bei dieser Methode werden Positionsvektoren nicht direkt zu den Wortvektoren hinzugefügt. Stattdessen wird der Aufmerksamkeitsmechanismus geändert, um relative Positionsinformationen einzubeziehen.
T5 (Text-to-Text Transfer Transformer) ist ein berühmtes Modell, das die relative Positionseinbettung nutzt. T5 führt eine subtile Art der Handhabung von Positionsinformationen ein:
- Bias für Positionsoffsets: T5 verwendet einen Bias (eine Gleitkommazahl), um jeden möglichen Positionsoffset darzustellen. Beispielsweise könnte Bias B1 den relativen Abstand zwischen zwei beliebigen Token darstellen, die eine Position voneinander entfernt sind, unabhängig von ihrer absoluten Position im Satz.
- Integration in die Selbstaufmerksamkeitsschicht: Diese relative Positions-Bias-Matrix wird zum Produkt aus der Abfragematrix und der Schlüsselmatrix in der Selbstaufmerksamkeitsschicht hinzugefügt. Dadurch wird sichergestellt, dass Markierungen im gleichen relativen Abstand unabhängig von ihrer Position in der Sequenz immer mit dem gleichen Bias dargestellt werden.
- Skalierbarkeit: Ein wesentlicher Vorteil dieses Ansatzes ist seine Skalierbarkeit. Es kann auf beliebig lange Sequenzen erweitert werden, was gegenüber der absoluten Positionseinbettung offensichtliche Vorteile hat.
Einschränkungen der relativen Positionskodierung
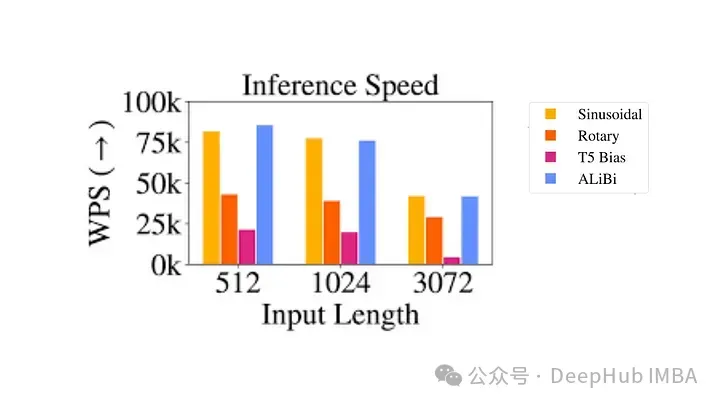
Obwohl sie theoretisch attraktiv sind, sind relative Positionskodierungen äußerst problematisch
- Rechnerisch ineffizient: Es müssen paarweise Positionskodierungsmatrizen erstellt und dann eine große Anzahl von Tensoroperationen durchgeführt werden, um die relative Positionskodierung jedes Zeitschritts zu erhalten. Vor allem bei längeren Sequenzen. Dies ist hauptsächlich auf den zusätzlichen Rechenschritt in der Selbstaufmerksamkeitsschicht zurückzuführen, wo die Positionsmatrix zur Abfrageschlüsselmatrix hinzugefügt wird.
- Komplexität der Schlüsselwert-Cache-Nutzung: Da jedes zusätzliche Token die Einbettung jedes anderen Tokens verändert, erschwert dies die effektive Nutzung des Schlüsselwert-Cache in Transformer. Eine Voraussetzung für die Verwendung des KV-Cache ist, dass sich die Positionskodierung bereits generierter Wörter bei der Generierung neuer Wörter nicht ändert (die absolute Positionskodierung bietet), sodass die relative Positionskodierung nicht für Inferenzen geeignet ist, da sich die Einbettung jedes Tokens mit jeder neuen Änderung ändert mit Zeitschritten.
Aufgrund dieser technischen Komplexität wurde die Positionscodierung nicht weit verbreitet, insbesondere in größeren Sprachmodellen.
Rotational Position Encoding (RoPE)?
RoPE stellt eine neue Art der Kodierung von Standortinformationen dar. Sowohl die absolute Methode als auch die relative Methode in herkömmlichen Methoden haben ihre Grenzen. Die absolute Positionskodierung weist jeder Position einen eindeutigen Vektor zu. Dies ist einfach, lässt sich aber nicht gut skalieren und kann relative Positionen nicht effektiv erfassen. Die relative Positionskodierung konzentriert sich auf den Abstand zwischen Markern, verbessert das Verständnis des Modells für Markerbeziehungen, macht die Modellarchitektur jedoch komplizierter .
RoPE vereint geschickt die Vorteile beider. Kodieren Sie Standortinformationen so, dass das Modell die absolute Position der Markierungen und ihre relative Entfernung verstehen kann. Dies wird durch einen Rotationsmechanismus erreicht, bei dem jede Position in der Sequenz durch eine Drehung im Einbettungsraum dargestellt wird. Die Eleganz von RoPE liegt in seiner Einfachheit und Effizienz, die es dem Modell ermöglicht, die Nuancen der Sprachsyntax und -semantik besser zu erfassen.
Die Rotationsmatrix wird aus den trigonometrischen Eigenschaften von Sinus und Cosinus abgeleitet, die wir in der High School gelernt haben. Die Verwendung einer 2D-Matrix sollte ausreichen, um die Theorie der Rotationsmatrix wie unten gezeigt zu erhalten!
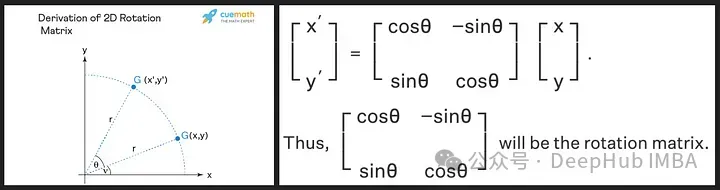
Wir sehen, dass die Rotationsmatrix die Größe (oder Länge) des ursprünglichen Vektors beibehält, wie durch „r“ im Bild oben gezeigt, das einzige, was sich ändert, ist der Winkel mit der x-Achse.
RoPE stellt ein neuartiges Konzept vor. Anstatt Positionsvektoren hinzuzufügen, werden die Wortvektoren gedreht. Der Drehwinkel (θ) ist proportional zur Position des Wortes im Satz. Der Vektor an der ersten Position wird um θ gedreht, der Vektor an der zweiten Position wird um 2θ gedreht und so weiter. Dieser Ansatz hat mehrere Vorteile:
- Stabilität von Vektoren: Das Hinzufügen von Markierungen am Ende eines Satzes hat keinen Einfluss auf den Vektor des Anfangsworts, was für ein effizientes Caching von Vorteil ist.
- Bewahrung der relativen Position: Wenn zwei Wörter in unterschiedlichen Kontexten den gleichen relativen Abstand beibehalten, werden ihre Vektoren um den gleichen Betrag gedreht. Dadurch wird sichergestellt, dass der Winkel sowie das Skalarprodukt zwischen diesen Vektoren konstant bleiben
Die Matrixformel von RoPE
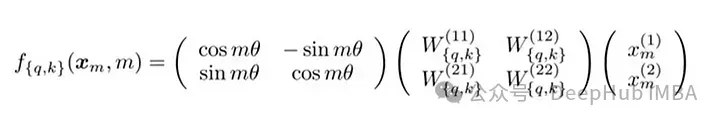
Die technische Umsetzung von RoPE beinhaltet eine Rotationsmatrix. Im 2D-Fall enthalten die Gleichungen in der Arbeit eine Rotationsmatrix, die den Vektor um Mθ Grad dreht, wobei M die absolute Position im Satz ist. Diese Rotation wird auf den Abfragevektor und den Schlüsselvektor im Selbstaufmerksamkeitsmechanismus des Transformers angewendet.
Für höhere Dimensionen werden die Vektoren in 2D-Blöcke aufgeteilt und jedes Paar wird unabhängig gedreht. Dies kann man sich als eine im Raum rotierende n-Dimension vorstellen. Es hört sich so an, als wäre die Implementierung dieser Methode kompliziert, aber das ist nicht der Fall. Sie kann in Bibliotheken wie PyTorch mit nur etwa zehn Codezeilen effizient implementiert werden.
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x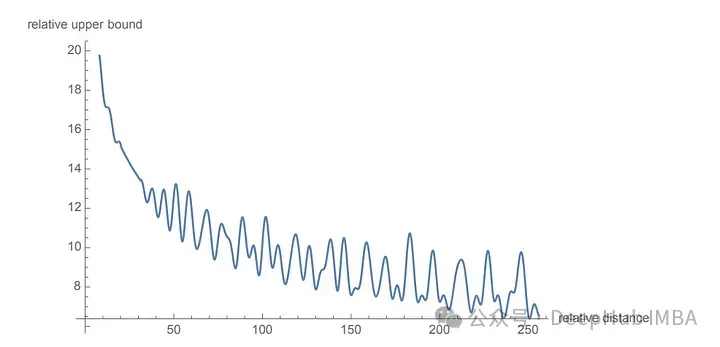
为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
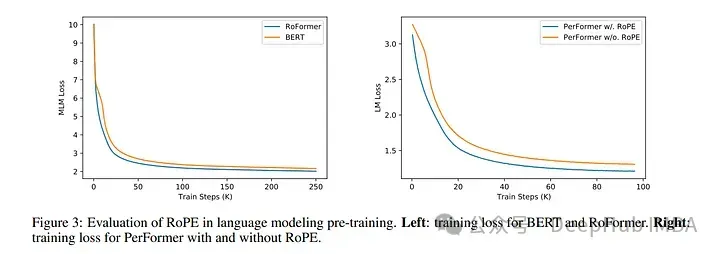
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
总结
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Rotationspositionskodierung RoPE, die häufig in großen Sprachmodellen verwendet wird: Warum ist sie besser als die absolute oder relative Positionskodierung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Apr 11, 2024 am 09:43 AM
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Apr 11, 2024 am 09:43 AM
Das Potenzial großer Sprachmodelle wird gefördert – eine hochpräzise Zeitreihenvorhersage kann ohne Training großer Sprachmodelle erreicht werden und übertrifft alle herkömmlichen Zeitreihenmodelle. Die Monash University, Ant und IBM Research haben gemeinsam ein allgemeines Framework entwickelt, das die Fähigkeit großer Sprachmodelle, Sequenzdaten über Modalitäten hinweg zu verarbeiten, erfolgreich förderte. Das Framework ist zu einer wichtigen technologischen Innovation geworden. Die Vorhersage von Zeitreihen ist für die Entscheidungsfindung in typischen komplexen Systemen wie Städten, Energie, Transport und Fernerkundung von Vorteil. Seitdem wird erwartet, dass große Modelle das Zeitreihen-/spatiotemporale Data-Mining revolutionieren werden. Das allgemeine Forschungsteam zum Reprogrammieren von Frameworks für große Sprachmodelle schlug ein allgemeines Framework vor, mit dem große Sprachmodelle einfach und ohne Schulung für die allgemeine Zeitreihenvorhersage verwendet werden können. Es werden hauptsächlich zwei Schlüsseltechnologien vorgeschlagen: Neuprogrammierung der Zeiteingabe; Zeit-
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Unterbricht die Sticky-Positionierung den Dokumentenfluss?
Feb 20, 2024 pm 05:24 PM
Unterbricht die Sticky-Positionierung den Dokumentenfluss?
Feb 20, 2024 pm 05:24 PM
Unterbricht die Sticky-Positionierung den Dokumentenfluss? In der Webentwicklung ist das Layout ein sehr wichtiges Thema. Unter diesen ist die Positionierung eine der am häufigsten verwendeten Layouttechniken. In CSS gibt es drei gängige Positionierungsmethoden: statische Positionierung, relative Positionierung und absolute Positionierung. Zusätzlich zu diesen drei Positionierungsmethoden gibt es noch eine speziellere Positionierungsmethode, nämlich die Sticky-Positionierung. Unterbricht die Sticky-Positionierung also den Dokumentenfluss? Lassen Sie uns dies im Folgenden ausführlich besprechen und einige Codebeispiele bereitstellen, um das Verständnis zu erleichtern. Zuerst müssen wir verstehen, was Dokumentenfluss ist
 Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
In diesem Artikel werden die Ergebnisse von „Local Deployment of Large Language Models in OpenHarmony“ auf der 2. OpenHarmony-Technologiekonferenz demonstriert. Open-Source-Adresse: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Die Implementierungsideen und -schritte bestehen darin, das leichtgewichtige LLM-Modellinferenz-Framework InferLLM auf das OpenHarmony-Standardsystem zu übertragen und ein Binärprodukt zu kompilieren, das auf OpenHarmony ausgeführt werden kann. InferLLM ist ein einfaches und effizientes L
 Verarbeitung natürlicher Sprache: Computer in die Lage versetzen, menschliche Sprache zu verstehen und zu verarbeiten
Sep 21, 2023 pm 03:53 PM
Verarbeitung natürlicher Sprache: Computer in die Lage versetzen, menschliche Sprache zu verstehen und zu verarbeiten
Sep 21, 2023 pm 03:53 PM
Natural Language Processing (NLP) ist eine wichtige und spannende Technologie im Bereich der künstlichen Intelligenz. Ihr Ziel ist es, Computer in die Lage zu versetzen, menschliche Sprache zu verstehen, zu analysieren und zu generieren. Die Entwicklung von NLP hat enorme Fortschritte gemacht und ermöglicht es Computern, besser mit Menschen zu interagieren und ein breiteres Anwendungsspektrum zu erreichen. In diesem Artikel werden die Konzepte, Technologien, Anwendungen und Zukunftsaussichten der Verarbeitung natürlicher Sprache untersucht. Das Konzept der Verarbeitung natürlicher Sprache ist eine Disziplin, die untersucht, wie Computer in die Lage versetzt werden, menschliche Sprache zu verstehen und zu verarbeiten. Die Komplexität und Mehrdeutigkeit der menschlichen Sprache stellt Computer vor große Herausforderungen beim Verstehen und Verarbeiten. Das Ziel von NLP ist die Entwicklung von Algorithmen und Modellen, die es Computern ermöglichen, Informationen aus Texten zu extrahieren
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Stimulieren Sie die räumliche Denkfähigkeit großer Sprachmodelle: Tipps zur Denkvisualisierung
Apr 11, 2024 pm 03:10 PM
Stimulieren Sie die räumliche Denkfähigkeit großer Sprachmodelle: Tipps zur Denkvisualisierung
Apr 11, 2024 pm 03:10 PM
Große Sprachmodelle (LLMs) zeigen beeindruckende Leistungen beim Sprachverständnis und bei verschiedenen Argumentationsaufgaben. Ihre Rolle beim räumlichen Denken, einem Schlüsselaspekt der menschlichen Wahrnehmung, ist jedoch noch wenig erforscht. Menschen haben die Fähigkeit, durch einen Prozess, der als „geistiges Auge“ bekannt ist, mentale Bilder von unsichtbaren Objekten und Handlungen zu erzeugen, die es ermöglichen, sich die unsichtbare Welt vorzustellen. Inspiriert von dieser kognitiven Fähigkeit schlugen Forscher die „Visualisierung des Denkens“ (VoT) vor. VoT zielt darauf ab, das räumliche Denken von LLMs durch die Visualisierung ihrer Argumentationszeichen zu steuern und so nachfolgende Argumentationsschritte zu steuern. Forscher wenden VoT auf Multi-Hop-Aufgaben zum räumlichen Denken an, einschließlich Navigation in natürlicher Sprache und Sehvermögen
