
 Technologie-Peripheriegeräte
KI
Die Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel
Technologie-Peripheriegeräte
KI
Die Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel
Die Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel

Punktwolken als Sammlung von Punkten sollen durch 3D-Rekonstruktion, industrielle Inspektion und Roboterbetrieb eine Veränderung bei der Erfassung und Generierung dreidimensionaler (3D) Oberflächeninformationen von Objekten bewirken. Der anspruchsvollste, aber wesentlichste Prozess ist die Punktwolkenregistrierung, d. h. das Erhalten einer räumlichen Transformation, die zwei in zwei verschiedenen Koordinaten erhaltene Punktwolken ausrichtet und abgleicht. In dieser Rezension werden ein Überblick und die Grundprinzipien der Punktwolkenregistrierung vorgestellt, verschiedene Methoden systematisch klassifiziert und verglichen und die technischen Probleme bei der Punktwolkenregistrierung gelöst. Dabei wird versucht, akademischen Forschern außerhalb des Fachgebiets und Ingenieuren Orientierung zu geben und Diskussionen über eine einheitliche Vision zu erleichtern zur Punktwolkenregistrierung.
Die allgemeine Methode zur Punktwolkenerfassung
ist in aktive und passive Methoden unterteilt. Die vom Sensor aktiv erfasste Punktwolke ist die aktive Methode, und die Methode durch Rekonstruktion in der späteren Phase ist die passive Methode.
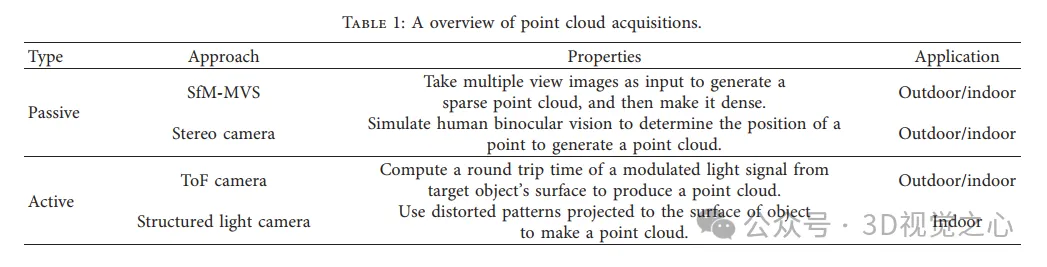
Dichte Rekonstruktion von SFM zu MVS. (a) SFM. (b) Beispiel einer von SfM generierten Punktwolke. (c) Flussdiagramm des PMVS-Algorithmus, ein Patch-basierter Multi-View-Stereo-Algorithmus. (d) Beispiel einer von PMVS erzeugten dichten Punktwolke.
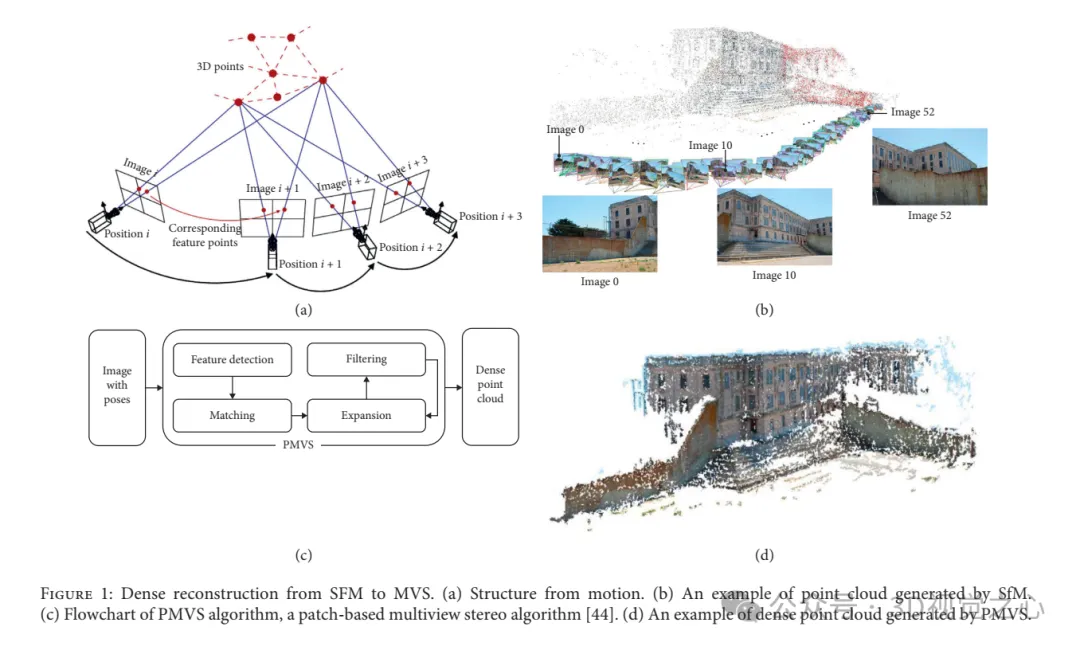
Strukturierte Lichtrekonstruktionsmethoden:
starre Registrierung und nicht starre Registrierung
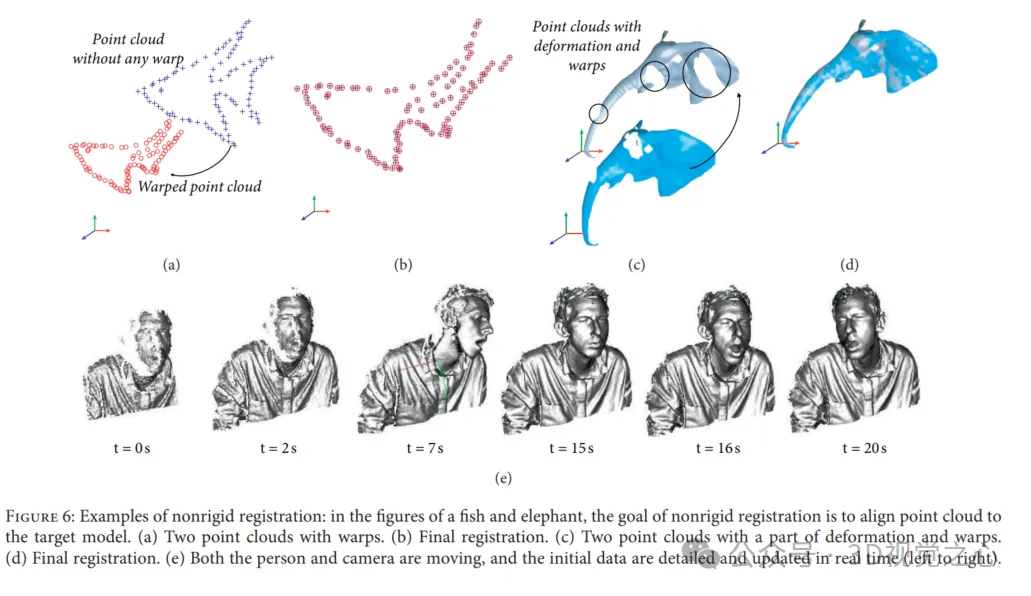
In einer Umgebung kann die Transformation in Rotation und Translation zerlegt werden. Nach entsprechender starrer Transformation wird eine Punktwolke abgebildet eine weitere Punktwolke unter Beibehaltung derselben Form und Größe.
Bei der nicht starren Registrierung wird eine nicht starre Transformation eingerichtet, um die Scandaten in die Zielpunktwolke einzubinden. Nicht starre Transformationen umfassen Spiegelungen, Drehungen, Skalierungen und Verschiebungen, im Gegensatz zu nur Verschiebungen und Drehungen bei starrer Registrierung. Die nicht starre Registrierung wird aus zwei Hauptgründen verwendet: (1) Nichtlinearitäten und Kalibrierungsfehler bei der Datenerfassung können niederfrequente Verzerrungen bei Scans starrer Objekte verursachen. (2) Die Registrierung wird an Szenen oder Objekten durchgeführt, die ihre Form ändern und sich darüber bewegen Zeit .
Beispiele für starre Registrierung: (a) zwei Punktwolken: Lesepunktwolke (grün) und Referenzpunktwolke (rot); ohne (b) und mit (c) Fall des starren Registrierungsalgorithmus werden die Punktwolken verschmolzen in ein gemeinsames Koordinatensystem.
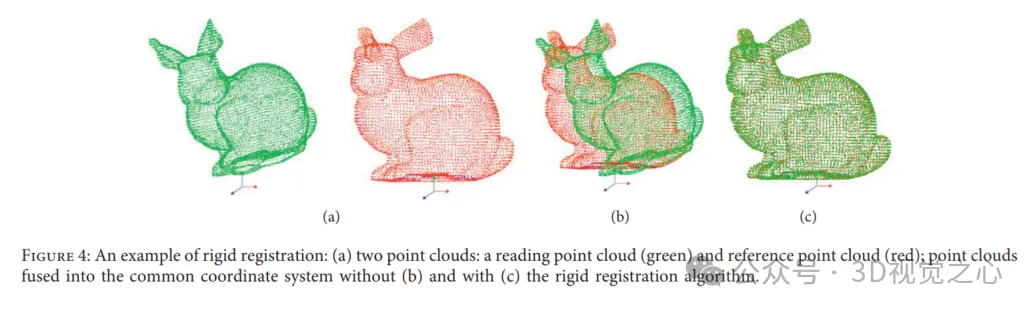

Die Leistung der Punktwolkenregistrierung wird jedoch durch Variantenüberlappung, Rauschen und Ausreißer, hohe Rechenkosten und verschiedene Indikatoren für den Registrierungserfolg begrenzt.
Welche Registrierungsmethoden gibt es?
In den letzten Jahrzehnten wurden immer mehr Methoden zur Punktwolkenregistrierung vorgeschlagen, von klassischen ICP-Algorithmen bis hin zu Lösungen in Kombination mit Deep-Learning-Technologie.
1) ICP-Schema
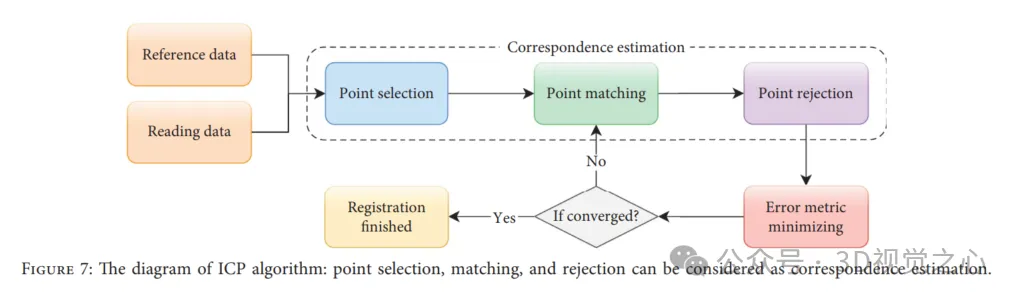
Der ICP-Algorithmus ist ein iterativer Algorithmus, der die Genauigkeit, Konvergenzgeschwindigkeit und Stabilität der Registrierung unter idealen Bedingungen gewährleisten kann. In gewissem Sinne kann ICP als ein Problem der Erwartungsmaximierung (EM) betrachtet werden, sodass es neue Transformationen basierend auf Korrespondenzen berechnet und aktualisiert, die dann auf die gelesenen Daten angewendet werden, bis die Fehlermetrik konvergiert. Dies garantiert jedoch nicht, dass ICP das globale Optimum erreicht. Der ICP-Algorithmus kann grob in vier Schritte unterteilt werden: Punktauswahl, Punktanpassung, Punktzurückweisung und Fehlermetrikminimierung, wie in der folgenden Abbildung dargestellt.

2) Merkmalsbasierte Methoden
Wie wir bei ICP-basierten Algorithmen gesehen haben, ist es entscheidend, vor der Transformationsschätzung eine Korrespondenz herzustellen. Das Endergebnis ist garantiert, wenn wir eine entsprechende Korrespondenz erhalten, die die korrekte Beziehung zwischen den beiden Punktwolken beschreibt. Daher können wir Orientierungspunkte auf dem gescannten Ziel einfügen oder in der Nachbearbeitung manuell äquivalente Punktpaare auswählen, um die Transformation der interessierenden Punkte (ausgewählte Punkte) zu berechnen, die letztendlich zum Lesen der Punktwolke angewendet werden kann. Wie in Abbildung 12(c) dargestellt, werden die Punktwolken in dasselbe Koordinatensystem geladen und in verschiedenen Farben gezeichnet. Die Abbildungen 12(a) und 12(b) zeigen zwei Punktwolken, die aus unterschiedlichen Blickwinkeln erfasst wurden, wobei Punktpaare aus den Referenzdaten bzw. Lesedaten ausgewählt wurden. Die Registrierungsergebnisse sind in Abbildung 12(d) dargestellt. Diese Methoden eignen sich jedoch weder für Messobjekte, an denen keine Orientierungspunkte angebracht werden können, noch können sie auf Anwendungen angewendet werden, die eine automatische Registrierung erfordern. Um den Suchraum von Korrespondenzen zu minimieren und die Annahme anfänglicher Transformationen in ICP-basierten Algorithmen zu vermeiden, wird gleichzeitig die merkmalsbasierte Registrierung eingeführt, bei der von den Forschern entworfene Schlüsselpunkte extrahiert werden. Normalerweise sind die Erkennung von Schlüsselpunkten und die Herstellung von Korrespondenzen die Hauptschritte dieser Methode.

Zu den gängigen Methoden zur Schlüsselpunktextraktion gehören PFH, SHOT usw. Es ist auch wichtig, einen Algorithmus zu entwerfen, um Ausreißer zu entfernen und die Transformation basierend auf Inliers effektiv zu schätzen.
3) Lernbasierte Ansätze
In Anwendungen, die Punktwolken als Eingabe verwenden, stützen sich herkömmliche Strategien zur Schätzung von Merkmalsdeskriptoren stark auf die einzigartigen geometrischen Eigenschaften der Objekte in der Punktwolke. Allerdings sind reale Daten oft zielspezifisch und können Ebenen, Ausreißer und Rauschen enthalten. Darüber hinaus enthalten die entfernten Fehlpaarungen oft nützliche Informationen, die zum Lernen genutzt werden können. Lernbasierte Techniken können zur Kodierung semantischer Informationen angepasst und auf bestimmte Aufgaben verallgemeinert werden. Die meisten in Techniken des maschinellen Lernens integrierten Registrierungsstrategien sind schneller und robuster als klassische Methoden und lassen sich flexibel auf andere Aufgaben wie die Schätzung der Objektposition und die Objektklassifizierung übertragen. Ebenso besteht eine zentrale Herausforderung bei der lernbasierten Punktwolkenregistrierung darin, Merkmale zu extrahieren, die gegenüber der räumlichen Variation der Punktwolke invariant und robuster gegenüber Rauschen und Ausreißern sind.
Vertreter lernbasierter Methoden sind: PointNet, PointNet++, PCRNet, Deep Global Registration, Deep Closest Point, Partial Registration Network, Robust Point Matching, PointNetLK, 3DRegNet.
4) Methode mit Wahrscheinlichkeitsdichtefunktion
Die Punktwolkenregistrierung basierend auf der Wahrscheinlichkeitsdichtefunktion (PDF) macht die Registrierung mithilfe statistischer Modelle zu einem gut untersuchten Problem. Die Schlüsselidee dieser Methode ist die Verwendung spezifischer Wahrscheinlichkeitsdichtefunktionen stellen die Daten dar, z. B. das Gaußsche Mischungsmodell (GMM) und die Normalverteilung (ND). Die Registrierungsaufgabe wird als Problem der Ausrichtung zweier entsprechender Verteilungen umformuliert, gefolgt von einer Zielfunktion, die den statistischen Unterschied zwischen ihnen misst und minimiert. Gleichzeitig kann die Punktwolke aufgrund der PDF-Darstellung als Verteilung und nicht als viele einzelne Punkte betrachtet werden, wodurch die Schätzung der Korrespondenz vermieden wird und eine gute Anti-Rausch-Leistung erzielt wird, sie ist jedoch im Allgemeinen langsamer als ICP-basiert Methoden.
5) Andere Methoden
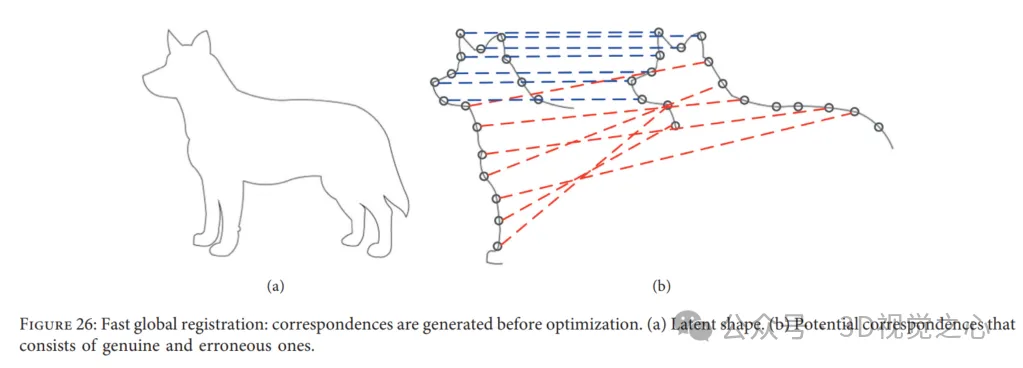
Schnelle globale Registrierung. Fast Global Registration (FGR) bietet eine schnelle Strategie zur Punktwolkenregistrierung, die keine Initialisierung erfordert. Insbesondere arbeitet FGR mit Kandidatenübereinstimmungen der abgedeckten Oberfläche und führt keine Korrespondenzaktualisierungen oder Abfragen nach nächstgelegenen Punkten durch. Das Besondere an diesem Ansatz ist, dass er direkt durch eine einzige Optimierung eines robusten Ziels erzeugt werden kann, das dicht auf der Oberfläche definiert ist Anmeldung. Bestehende Methoden zur Lösung der Punktwolkenregistrierung generieren jedoch normalerweise Kandidaten- oder Mehrfachkorrespondenzen zwischen zwei Punktwolken und berechnen und aktualisieren dann die globalen Ergebnisse. Darüber hinaus wird bei der schnellen globalen Registrierung die Übereinstimmung sofort in der Optimierung hergestellt und in den folgenden Schritten nicht erneut geschätzt. Daher wird eine teure Suche nach dem nächsten Nachbarn vermieden, um die Rechenkosten niedrig zu halten. Dadurch sind eine lineare Verarbeitung für jede Korrespondenz in iterativen Schritten und ein lineares System zur Posenschätzung effizient. FGR wird anhand mehrerer Datensätze bewertet, beispielsweise des UWA-Benchmarks und des Stanford Bunny, im Vergleich mit Punkt-zu-Punkt- und Punkt-Top-ICP sowie ICP-Varianten wie Go ICP. Experimente zeigen, dass FGR bei Lärm eine gute Leistung erbringt!
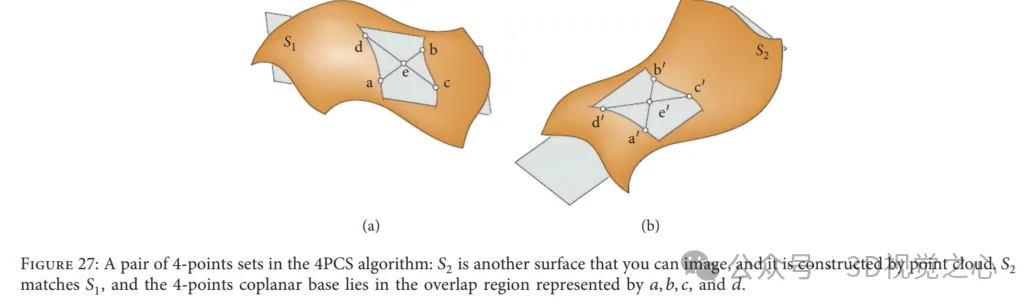
4-Punkte-Kongruenzmengen-Algorithmus: Die 4-Punkte-Kongruenzmenge (4PCS) bietet eine anfängliche Transformation zum Lesen von Daten ohne Startpositionsannahmen. Typischerweise kann eine starre Registrierungstransformation zwischen zwei Punktwolken eindeutig durch ein Paar von Tripeln definiert werden, eines aus den Referenzdaten und das andere aus den gelesenen Daten. Bei dieser Methode wird jedoch nach speziellen 4-Punkt-Basen gesucht, d. h. 4 koplanaren kongruenten Punkten in jeder Punktwolke, indem in einem kleinen Potentialsatz gesucht wird, wie in Abbildung 27 dargestellt. Lösung der optimalen starren Transformation im Problem der größten Menge gemeinsamer Punkte (LCP). Dieser Algorithmus erreicht eine ähnliche Leistung, wenn die Überlappung gepaarter Punktwolken gering ist und Ausreißer vorhanden sind. Um sich an unterschiedliche Anwendungen anzupassen, haben viele Forscher wichtigere Arbeiten im Zusammenhang mit der klassischen 4PCS-Lösung eingeführt.
Das obige ist der detaillierte Inhalt vonDie Registrierung von Punktwolken ist für die 3D-Vision unumgänglich! Verstehen Sie alle gängigen Lösungen und Herausforderungen in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Sie müssen bedenken, insbesondere wenn Sie Teams-Benutzer sind, dass Microsoft seiner arbeitsorientierten Videokonferenz-App eine neue Reihe von 3DFluent-Emojis hinzugefügt hat. Nachdem Microsoft letztes Jahr 3D-Emojis für Teams und Windows angekündigt hatte, wurden im Rahmen des Prozesses tatsächlich mehr als 1.800 bestehende Emojis für die Plattform aktualisiert. Diese große Idee und die Einführung des 3DFluent-Emoji-Updates für Teams wurden erstmals über einen offiziellen Blogbeitrag beworben. Das neueste Teams-Update bringt FluentEmojis in die App. Laut Microsoft werden uns die aktualisierten 1.800 Emojis täglich zur Verfügung stehen
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Als sich das Gerücht verbreitete, dass das neue Windows 11 in der Entwicklung sei, war jeder Microsoft-Nutzer neugierig, wie das neue Betriebssystem aussehen und was es bringen würde. Nach Spekulationen ist Windows 11 da. Das Betriebssystem kommt mit neuem Design und funktionalen Änderungen. Zusätzlich zu einigen Ergänzungen werden Funktionen eingestellt und entfernt. Eine der Funktionen, die es in Windows 11 nicht gibt, ist Paint3D. Während es immer noch klassisches Paint bietet, das sich gut für Zeichner, Kritzler und Kritzler eignet, verzichtet es auf Paint3D, das zusätzliche Funktionen bietet, die sich ideal für 3D-Ersteller eignen. Wenn Sie nach zusätzlichen Funktionen suchen, empfehlen wir Autodesk Maya als beste 3D-Designsoftware. wie
 Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
ChatGPT hat der KI-Branche eine Portion Hühnerblut injiziert, und alles, was einst undenkbar war, ist heute zur gängigen Praxis geworden. Text-to-3D, das immer weiter voranschreitet, gilt nach Diffusion (Bilder) und GPT (Text) als nächster Hotspot im AIGC-Bereich und hat beispiellose Aufmerksamkeit erhalten. Nein, ein Produkt namens ChatAvatar befindet sich in einer unauffälligen öffentlichen Betaphase, hat schnell über 700.000 Aufrufe und Aufmerksamkeit erregt und wurde auf Spacesoftheweek vorgestellt. △ChatAvatar wird auch die Imageto3D-Technologie unterstützen, die 3D-stilisierte Charaktere aus KI-generierten Einzel-/Mehrperspektive-Originalgemälden generiert. Das von der aktuellen Beta-Version generierte 3D-Modell hat große Beachtung gefunden.
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
