
 Technologie-Peripheriegeräte
KI
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Technologie-Peripheriegeräte
KI
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA
Das multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA

Multimodales DokumentenverständnisFähigkeit neues SOTA!
Das Alibaba mPLUG-Team hat das neueste Open-Source-Werk mPLUG-DocOwl 1.5 veröffentlicht, das eine Reihe von Lösungen für die vier großen Herausforderungen der hochauflösenden Bildtexterkennung, des universellen Verständnisses der Dokumentstruktur, der Befolgung von Anweisungen und der Einführung von externem Wissen vorschlägt .
Schauen wir uns ohne weitere Umschweife zunächst die Auswirkungen an.
Ein-Klick-Erkennung und Konvertierung von Diagrammen mit komplexen Strukturen in das Markdown-Format:
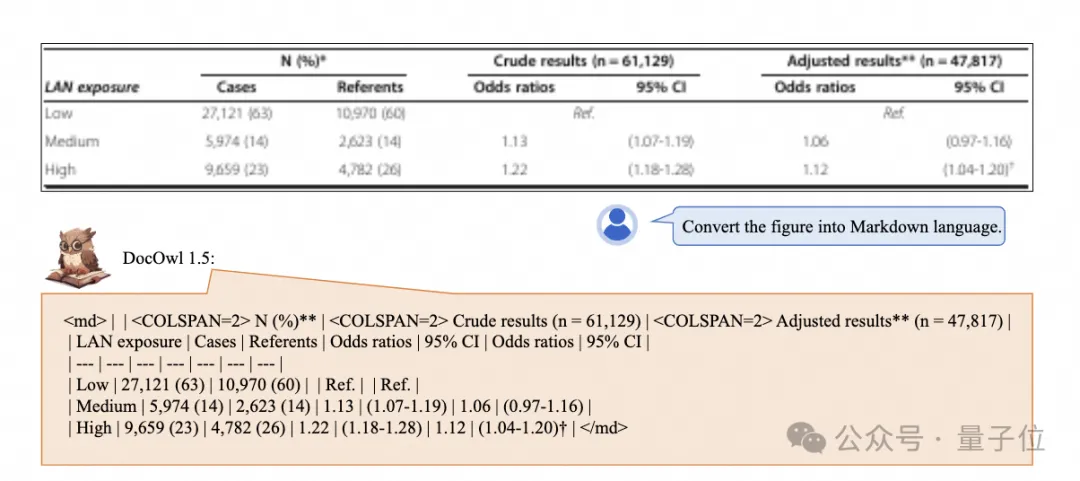
Es stehen Diagramme verschiedener Stile zur Verfügung:
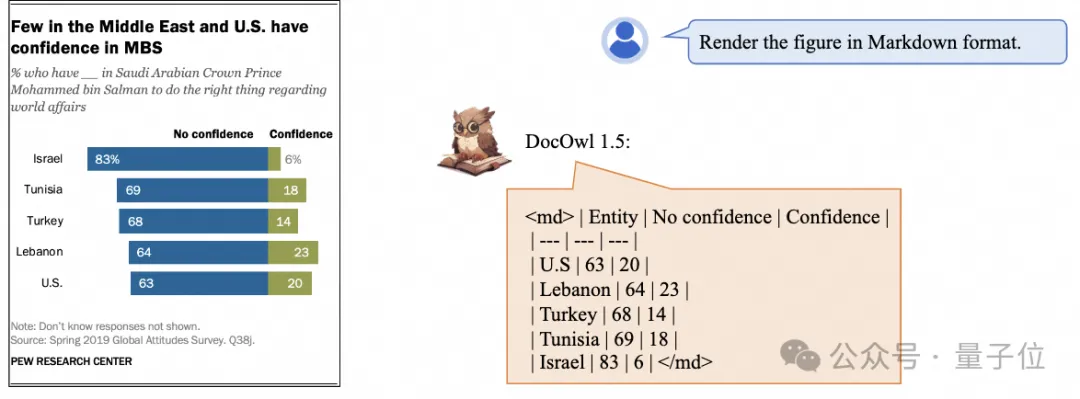
Eine detailliertere Texterkennung und -positionierung ist ebenfalls einfach zu handhaben:

Erläutern Sie außerdem ausführlich das Dokumentverständnis:

Sie müssen wissen, dass „Dokumentverständnis“ derzeit ein wichtiges Szenario für die Implementierung großer Sprachmodelle ist. Es gibt viele Produkte auf dem Markt, die das Lesen von Dokumenten unterstützen Verwenden Sie hauptsächlich OCR-Systeme zum Lesen von Text. Durch die Erkennung und das Textverständnis mit LLM können gute Fähigkeiten zum Verstehen von Dokumenten erzielt werden.
Aufgrund der unterschiedlichen Kategorien von Dokumentbildern, Rich Text und komplexem Layout ist es jedoch schwierig, ein universelles Verständnis von Bildern mit komplexen Strukturen wie Diagrammen, Infografiken und Webseiten zu erreichen.
Die derzeit beliebten multimodalen Großmodelle QwenVL-Max, Gemini, Claude3 und GPT4V verfügen alle über starke Fähigkeiten zum Verständnis von Dokumentenbildern, Open-Source-Modelle haben jedoch nur langsame Fortschritte in dieser Richtung gemacht.
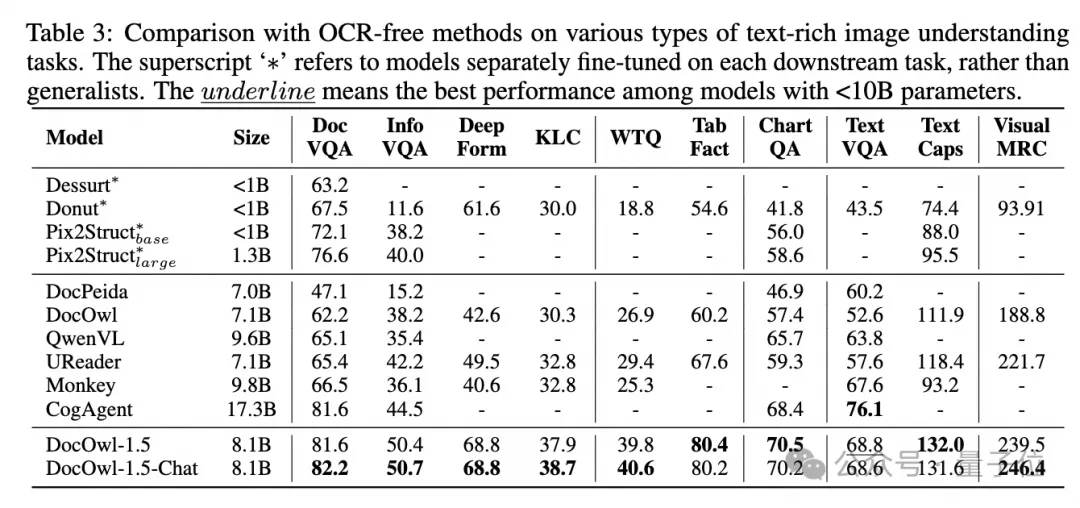
Alibabas neue Forschung mPLUG-DocOwl 1.5 gewann SOTA bei 10 Dokumentenverständnis-Benchmarks, verbesserte sich um mehr als 10 Punkte bei 5 Datensätzen, übertraf Wisdoms 17.3B CogAgent bei einigen Datensätzen und erreichte 82,2 beim DocVQA-Effekt.
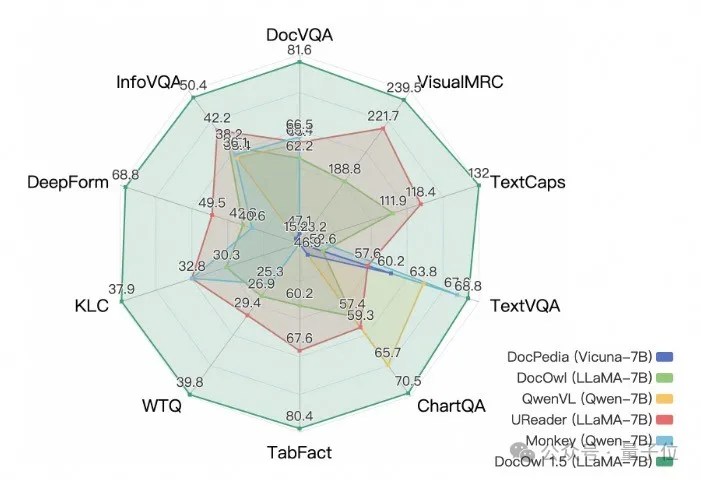
Neben der Fähigkeit, einfache Antworten auf den Benchmark zu geben, kann DocOwl 1.5-Chat durch eine kleine Menge „detaillierter Erklärung“ (Begründung) Feinabstimmung der Daten auch die Fähigkeit haben, zu erklären im Detail im Bereich multimodaler Dokumente, der ein großes Anwendungspotenzial hat.
Das Alibaba mPLUG-Team investiert seit Juli 2023 in die multimodale Dokumentverständnisforschung und hat nacheinander mPLUG-DocOwl, UReader, mPLUG-PaperOwl, mPLUG-DocOwl 1.5 veröffentlicht und eine Reihe großer Dokumentverständnismodelle und Open-Source-Modelle veröffentlicht Trainingsdaten.
Dieser Artikel beginnt mit der neuesten Arbeit mPLUG-DocOwl 1.5 und analysiert die wichtigsten Herausforderungen und wirksamen Lösungen im Bereich „multimodales Dokumentenverständnis“.
Herausforderung 1: Hochauflösende Bildtexterkennung
Im Gegensatz zu allgemeinen Bildern zeichnen sich Dokumentbilder durch unterschiedliche Formen und Größen aus, zu denen Dokumentbilder im A4-Format, kurze und breite Tabellenbilder sowie lange und schmale mobile Webseiten gehören können Screenshots, zufällige Szenenbilder usw. werden in einer Vielzahl von Auflösungen verteilt.
Wenn gängige multimodale große Modelle Bilder kodieren, skalieren sie die Bildgröße oft direkt. Beispielsweise skalieren mPLUG-Owl2 und QwenVL auf 448 x 448 und LLaVA 1.5 auf 336 x 336.
Eine einfache Skalierung des Dokumentbilds führt dazu, dass der Text im Bild unscharf und deformiert wird, sodass er nicht mehr erkennbar ist.
Um Dokumentbilder zu verarbeiten, setzt mPLUG-DocOwl 1.5 den Schnitt-Ansatz seines Vorgängers UReader fort. Die Modellstruktur ist in Abbildung 1 dargestellt:
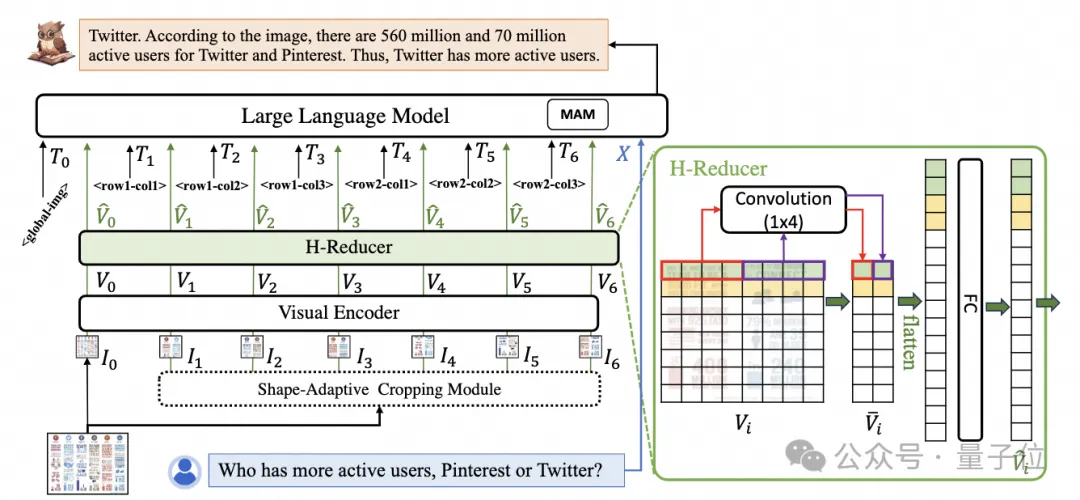
△Abbildung 1: DocOwl 1.5-Modellstrukturdiagramm
UReader Es wurde zunächst vorgeschlagen, eine Reihe von Teilbildern über das parameterfreie formadaptive Zuschneidemodul zu erhalten, das auf dem vorhandenen multimodalen großen Modell basiert. Jedes Teilbild wird von einem Encoder mit niedriger Auflösung codiert Semantik über Sprachmodelle zu steuern. Diese Grafikschneidestrategie kann die Fähigkeiten vorhandener allgemeiner visueller Encoder
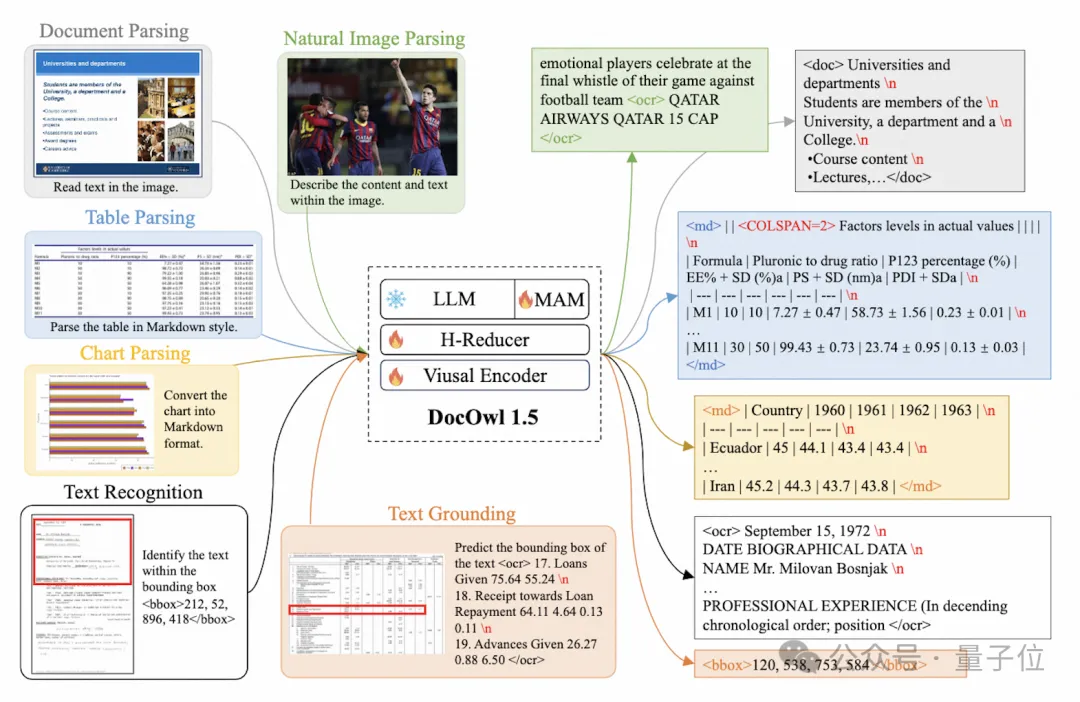
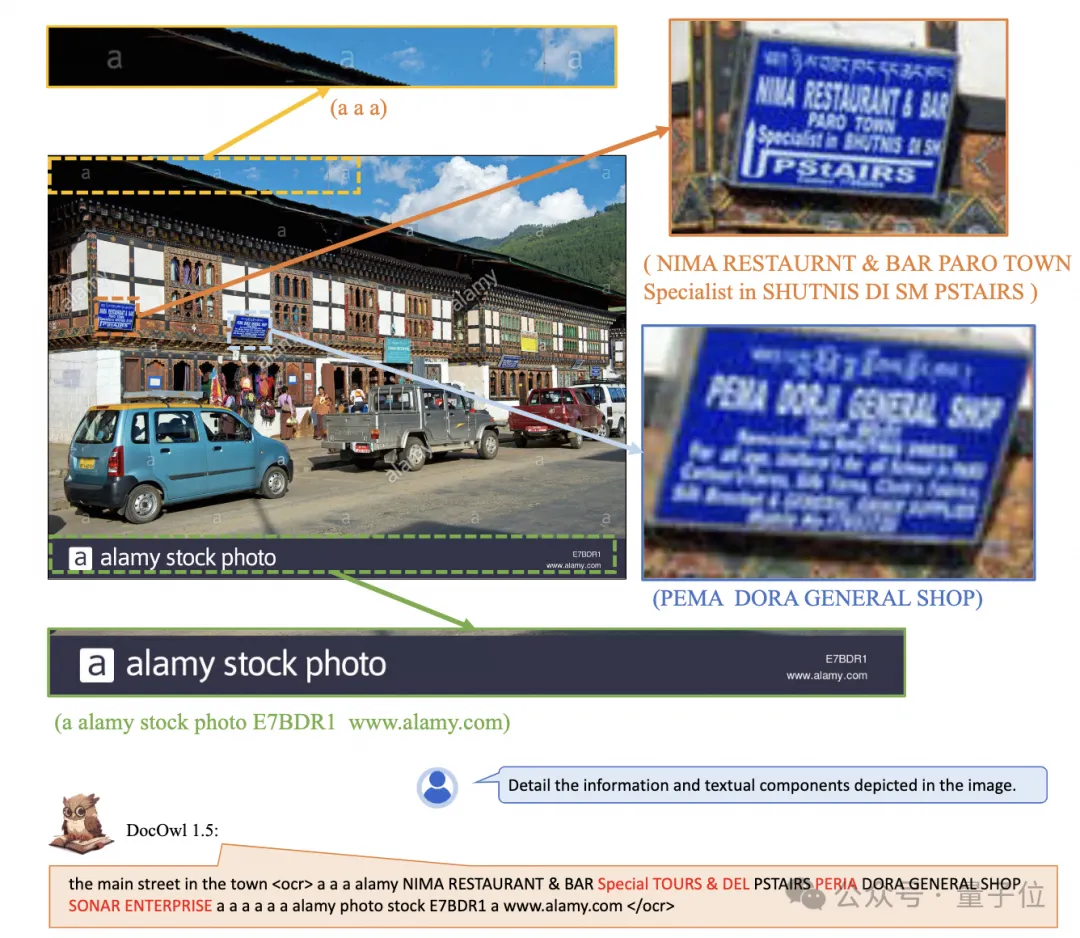
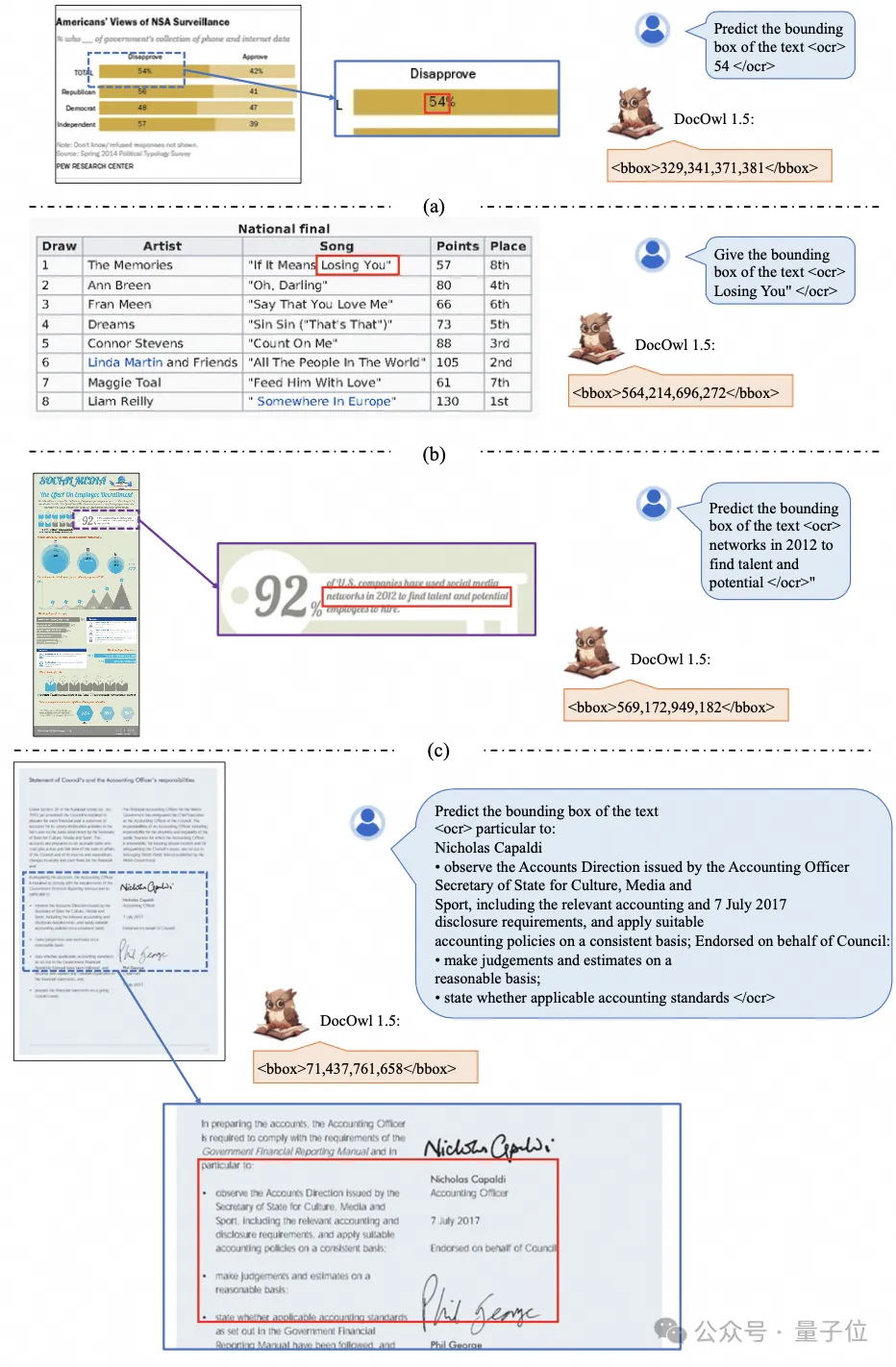
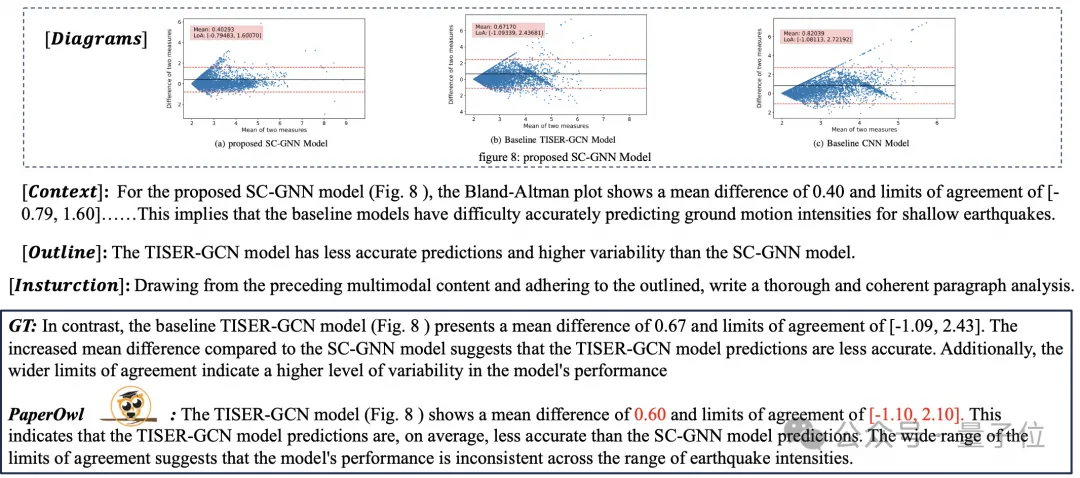
(z. B. CLIP ViT-14/L) für das Verständnis von Dokumenten maximal nutzen und die Kosten für die Umschulung hochauflösender visueller Encoder erheblich reduzieren. Das formangepasste Schneidmodul ist in Abbildung 2 dargestellt: Für das Verständnis von Dokumenten, die nicht auf OCR-Systemen beruhen, ist das Erkennen von Text eine grundlegende Fähigkeit. Es ist sehr wichtig, ein semantisches Verständnis und ein strukturelles Verständnis des Dokumentinhalts zu erreichen erfordert das Verständnis von Tabellenüberschriften und der Korrespondenz zwischen Zeilen und Spalten. Um Diagramme zu verstehen, müssen Sie verschiedene Strukturen wie Liniendiagramme, Balkendiagramme und Kreisdiagramme verstehen. mPLUG-DocOwl 1.5 konzentriert sich auf die Lösung struktureller Verständnisfähigkeiten wie allgemeiner Dokumente. Durch die Optimierung der Modellstruktur und die Verbesserung von Trainingsaufgaben wurden deutlich stärkere allgemeine Dokumentverständnisfähigkeiten erreicht. In Bezug auf die Struktur verzichtet mPLUG-DocOwl 1.5, wie in Abbildung 1 dargestellt, auf das visuelle Sprachverbindungsmodul von Abstractor in mPLUG-Owl/mPLUG-Owl2, verwendet H-Reducer basierend auf „Faltung + vollständig verbundener Schicht“ als Funktion Aggregation und Feature-Ausrichtung . Im Vergleich zu Abstractor, der auf lernbaren Abfragen basiert, behält H-Reducer die relative Positionsbeziehung zwischen visuellen Merkmalen bei und überträgt Dokumentstrukturinformationen besser an das Sprachmodell. Im Vergleich zu MLP, das die Länge der visuellen Sequenz beibehält, reduziert H-Reducer die Anzahl visueller Merkmale durch Faltung erheblich, sodass LLM hochauflösende Dokumentbilder effizienter verstehen kann. Angesichts der Tatsache, dass der Text in den meisten Dokumentenbildern zuerst horizontal angeordnet ist und die Textsemantik in horizontaler Richtung kohärent ist, verwendet der H-Reducer eine Faltungsform und Schrittgröße von 1x4. In der Arbeit bewies der Autor durch ausreichende Vergleichsexperimente die Überlegenheit von H-Reducer beim Strukturverständnis und dass 1x4 eine allgemeinere Aggregatform ist. In Bezug auf Trainingsaufgaben entwirft mPLUG-DocOwl 1.5 eine einheitliche Strukturlernaufgabe (Unified Structure Learning) für alle Arten von Bildern, wie in Abbildung 3 dargestellt. △Abbildung 3: Unified Structure Learning Unified Structure Learning umfasst nicht nur die globale Bildtextanalyse, sondern auch die Texterkennung und -positionierung mit mehreren Granularitäten. Bei der globalen Bildtextanalyse können für Dokumentbilder und Webseitenbilder am häufigsten Leerzeichen und Zeilenumbrüche verwendet werden, um die Textstruktur für Tabellen darzustellen. Der Autor führt Sonderzeichen ein, um mehrere Zeilen und Spalten basierend darauf darzustellen Die Markdown-Syntax berücksichtigt die Einfachheit und Vielseitigkeit der Tabellendarstellung. Da es sich bei Diagrammen um visuelle Darstellungen tabellarischer Daten handelt, verwendet der Autor auch Tabellen in Form von Markdown als Analyseziel für Diagramme Beschreibung und Szenentext sind gleichermaßen wichtig. Daher wird die mit Szenentext gespleißte Bildbeschreibungsform als Analyseziel verwendet. In der Aufgabe „Texterkennung und -positionierung“ hat der Autor die Texterkennung und -positionierung in vier Granularitäten von Wörtern, Phrasen, Zeilen und Blöcken entworfen, um das Verständnis von Dokumentbildern zu verbessern. Der Begrenzungsrahmen verwendet diskretisierte Ganzzahlen um den Bereich 0-999 darzustellen. Um das Lernen einheitlicher Strukturen zu unterstützen, hat der Autor ein umfassendes Trainingsset DocStruct4M erstellt, das verschiedene Arten von Bildern wie Dokumente/Webseiten, Tabellen, Diagramme, natürliche Bilder usw. abdeckt. Nach dem einheitlichen Strukturlernen ist DocOwl 1.5 in der Lage, Dokumente und Bilder in mehreren Feldern strukturell zu analysieren und zu positionieren. △Abbildung 4: Strukturiertes Textparsen Wie in Abbildung 4 und Abbildung 5 gezeigt: △Abbildung 5: Texterkennung und -positionierung mit mehreren Granularitäten „Anweisungen folgen“(Anweisungen folgen) erfordert, dass das Modell auf grundlegenden Fähigkeiten zum Verstehen von Dokumenten basiert und verschiedene Aufgaben gemäß den Anweisungen des Benutzers ausführt, z. B. Informationsextraktion, Fragen und Antworten, Bildbeschreibungen usw. In Fortführung der Praxis von mPLUG-DocOwl vereint DocOwl 1.5 mehrere nachgelagerte Aufgaben in Form von Befehlsfragen und -antworten. Nach dem einheitlichen Strukturlernen wird ein allgemeines Modell im Dokumentenbereich durch „gemeinsames Multitasking-Training“ (Generalist) erhalten. . Damit das Modell detailliert erklärt werden kann, hat mPLUG-DocOwl außerdem versucht, Klartextanweisungen zur Feinabstimmung der Daten für das gemeinsame Training einzuführen, was gewisse Auswirkungen hat, aber nicht ideal ist. (DocReason25K) Durch die Kombination von Dokument-Downstream-Aufgaben und DocReason25K für das Training kann DocOwl 1.5-Chat bessere Ergebnisse im Benchmark erzielen: △ Abbildung 6: Document Understanding Benchmark-Bewertung und detaillierte Erklärungen geben: △Abbildung 7: Ausführliche Erläuterung des Dokumentenverständnisses Dokumentenbild Aufgrund der Fülle an Informationen erfordert das Verständnis oft die Einführung von zusätzlichem Wissen, wie z. B. Fachbegriffen und deren Bedeutung in Spezialgebieten etc. Um zu untersuchen, wie externes Wissen für ein besseres Dokumentenverständnis eingeführt werden kann, begann das mPLUG-Team im Papierbereich und schlug mPLUG-PaperOwl vor, um einen hochwertigen Papierdiagramm-Analysedatensatz M-Paper zu erstellen, der 447K hochauflösendes Papier umfasst Diagramme. Diese Daten liefern den Kontext für die Diagramme im Papier als externe Wissensquelle und entwerfen „Schlüsselpunkte“ (Gliederung) als Steuersignale für die Diagrammanalyse, um dem Modell zu helfen, die Absicht des Benutzers besser zu erfassen. Basierend auf UReader hat der Autor mPLUG-PaperOwl auf M-Paper verfeinert, was vorläufige Funktionen zur Analyse von Papierdiagrammen demonstrierte, wie in Abbildung 8 dargestellt. △Abbildung 8: Papierdiagrammanalyse mPLUG-PaperOwl ist derzeit nur ein erster Versuch, externes Wissen in das Dokumentenverständnis einzubringen. Es bestehen noch Probleme wie Domänenbeschränkungen und einzelne Wissensquellen, die weiter gelöst werden müssen. Im Allgemeinen beginnt dieser Artikel mit dem kürzlich veröffentlichten 7B stärksten multimodalen Dokumentverständnis-Großmodell mPLUG-DocOwl 1.5 und fasst die vier wichtigsten Herausforderungen des multimodalen Dokumentverständnisses ohne Rückgriff auf OCR („Hochauflösender Bildtext“) zusammen Erkennung“, „Universelles Verständnis der Dokumentstruktur“, „Anweisungen befolgen“, „Einführung von externem Wissen“) und die Lösung des Alibaba mPLUG-Teams. Obwohl mPLUG-DocOwl 1.5 die Dokumentverständnisleistung des Open-Source-Modells erheblich verbessert hat, ist es immer noch weit vom Closed-Source-Großmodell entfernt und bietet noch Raum für Verbesserungen bei der Texterkennung, mathematischen Berechnungen und allgemeinen Zwecken. usw. in natürlichen Szenen. Das mPLUG-Team wird die Leistung von DocOwl weiter optimieren und es als Open Source veröffentlichen. Jeder ist herzlich eingeladen, weiterhin aufmerksam zu sein und freundliche Diskussionen zu führen! GitHub-Link: https://github.com/X-PLUG/mPLUG-DocOwl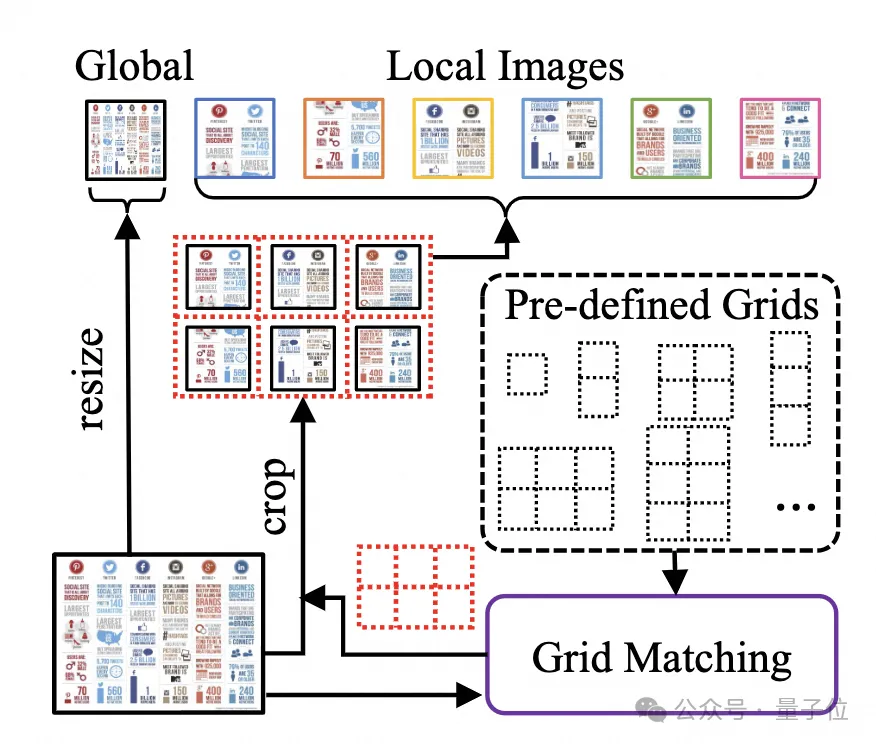
△Abbildung 2: Formadaptives Schneidmodul.
Herausforderung 2: Allgemeines Verständnis der Dokumentstruktur

Herausforderung 3: Anleitung

Herausforderung 4: Einführung von externem Wissen
Paper-Link: https://arxiv.org/abs/2403.12895
Das obige ist der detaillierte Inhalt vonDas multimodale Dokumentenverständnis-Großmodell Alibaba 7B gewinnt neue SOTA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
So fügen Sie eine neue Spalte in SQL hinzu
Apr 09, 2025 pm 02:09 PM
Fügen Sie einer vorhandenen Tabelle in SQL neue Spalten hinzu, indem Sie die Anweisung für die Änderung Tabelle verwenden. Zu den spezifischen Schritten gehören: Ermittlung des Tabellennamens und Spalteninformationen, Schreiben von Alter Tabellenanweisungen und Ausführungsanweisungen. Fügen Sie beispielsweise eine E -Mail -Spalte in die Tabelle der Kunden hinzu (VARCHAR (50)): Änderung der Tabelle Kunden addieren Sie E -Mail -Varchar (50).
 Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Was ist die Syntax zum Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:51 PM
Die Syntax zum Hinzufügen von Spalten in SQL ist Alter table table_name add column_name data_type [nicht null] [Standard default_value]; Wenn table_name der Tabellenname ist, ist Column_Name der neue Spaltenname, Data_Type ist der Datentyp, nicht null Gibt an, ob Nullwerte zulässig sind, und Standard Standard_Value gibt den Standardwert an.
 So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
So setzen Sie Standardwerte beim Hinzufügen von Spalten in SQL
Apr 09, 2025 pm 02:45 PM
Legen Sie den Standardwert für neu hinzugefügte Spalten fest, verwenden Sie die Anweisung für die Änderung der Tabelle: Hinzufügen von Spalten angeben und den Standardwert: Alter Table table_name hinzufügen column_name data_type Standard default_value; Verwenden Sie die Einschränkungsklausel, um den Standardwert anzugeben: Alter Table Table_Name add Column_Name Data_type Einschränkung default_constraint default default_value;
 SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
SQL Clear Tabelle: Tipps zur Leistungsoptimierung
Apr 09, 2025 pm 02:54 PM
Tipps zur Verbesserung der SQL -Tabellenlösungsleistung: Verwenden Sie die Truncate -Tabelle anstelle des Löschens, löschen Sie den Speicherplatz und setzen Sie die Identitätsspalte zurück. Deaktivieren Sie fremde Schlüsselbeschränkungen, um die Kaskadierung der Löschung zu verhindern. Verwenden Sie Transaktionskapselungsvorgänge, um die Datenkonsistenz sicherzustellen. Batch löschen Big Data und begrenzen Sie die Anzahl der Zeilen durch die Grenze. Bauen Sie den Index nach dem Löschen neu auf, um die Effizienz der Abfrage zu verbessern.
 Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Verwenden Sie die Löschanweisung, um SQL -Tabellen zu löschen
Apr 09, 2025 pm 03:00 PM
Ja, mit der Anweisung Löschen kann eine SQL -Tabelle gelöscht werden. TABLE_NAME ERSETZEN AUS DER NAME DER TABELLE, DIE DELDET.
 SQL Classic 50 Frage Antworten
Apr 09, 2025 pm 01:33 PM
SQL Classic 50 Frage Antworten
Apr 09, 2025 pm 01:33 PM
SQL (Structured Query Language) ist eine Programmiersprache, die zum Erstellen, Verwalten und Abfragen von Datenbanken verwendet wird. Zu den Hauptfunktionen gehören: Erstellen von Datenbanken und Tabellen, Einfügen, Aktualisierung und Löschen von Daten, Sortier- und Filterergebnissen, Aggregation von Funktionen, Verbindungstabellen, Unterabfragen, Operatoren, Funktionen, Funktionen, Keywords, Datenmanipulations-/Definitions-/Kontrollsprache, Verbindungstypen, Abfragetypen, Sicherheit, Trads, Ressourcen, Ressourcen, Ressourcen, Ressourcen, Ressourcen, Ausrüsten, Ausbreitung, Ausbreitung, Ausfallfehler, Ausfallfehlern, Ausbreitung, Ausbreitung, Ausfallfehlern, Ausrüsten, Ausbreitung, Ausfallfehlern, Ausrüsten, Ausbreitung, Ausfallfehlern, Ausbreitungsfehlern, Ausbreitung, Ausfallfehlern, Ausbreitung, Ausfallfehlern, Ausbreitung, Ausfallfehlern, Ausbreitung, Ausfallfehlern.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
