
 Technologie-Peripheriegeräte
KI
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Technologie-Peripheriegeräte
KI
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit
Erforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit

Einführung
Im Bereich Computer Vision ist die genaue Messung der Bildähnlichkeit eine entscheidende Aufgabe mit einer Vielzahl praktischer Anwendungen. Von Bildsuchmaschinen über Gesichtserkennungssysteme bis hin zu inhaltsbasierten Empfehlungssystemen ist die Fähigkeit, ähnliche Bilder effektiv zu vergleichen und zu finden, wichtig. Das siamesische Netzwerk bietet in Kombination mit Kontrastverlust einen leistungsstarken Rahmen für das datengesteuerte Erlernen der Bildähnlichkeit. In diesem Blogbeitrag werden wir uns mit den Details siamesischer Netzwerke befassen, das Konzept des Kontrastverlusts untersuchen und untersuchen, wie diese beiden Komponenten zusammenarbeiten, um ein effektives Bildähnlichkeitsmodell zu erstellen. Erstens besteht das siamesische Netzwerk aus zwei identischen Teilnetzwerken mit denselben Gewichten und Parametern. Jedes Subnetzwerk kodiert Eingabebilder in Merkmalsvektoren, die Schlüsselmerkmale des Bildes erfassen. Anschließend verwenden wir einen Kontrastverlust, um die Ähnlichkeit zwischen den beiden Eingabebildern zu messen. Der Kontrastverlust basiert auf der euklidischen Distanzmetrik und verwendet einen Restriktionsterm, um sicherzustellen, dass der Abstand zwischen Stichproben derselben Klasse kleiner ist als der Abstand zwischen Stichproben verschiedener Klassen. Durch Backpropagation und Optimierungsalgorithmen sind siamesische Netzwerke in der Lage, Merkmalsdarstellungen automatisch zu lernen, wodurch die Fähigkeit, Bildern zu ähneln, sehr wichtig ist. Die Innovation dieses Modells liegt in seiner Fähigkeit, relativ wenige Proben im Trainingssatz zu lernen und diese durch Transferlernen zu übertragen. Siamesische neuronale Netze sind eine Klasse neuronaler Netze, die die Ähnlichkeit zwischen Paaren von Eingangsproben vergleichen. Der Begriff „siamesisch“ leitet sich vom Konzept einer Netzwerkarchitektur ab, die aus zwei identisch strukturierten siamesischen neuronalen Netzwerken besteht, die die gleichen Gewichtungen aufweisen. Jedes Netzwerk verarbeitet eine der Stichproben aus der entsprechenden Eingabe und bestimmt die Ähnlichkeit oder Unähnlichkeit zwischen ihnen durch Vergleich ihrer Ausgaben. Jede Stichprobe im siamesischen Netzwerk befasst sich mit der Ähnlichkeit oder Unähnlichkeit zwischen Eingabeproben und entsprechenden Eingabeproben. Dieses Ähnlichkeitsmaß kann durch Vergleich ihrer Ausgaben bestimmt werden. Siamesische Netzwerke werden häufig für Erkennungs- und Verifizierungsaufgaben wie Gesichtserkennung, Fingerabdruckerkennung und Signaturüberprüfung verwendet. Es kann automatisch die Ähnlichkeiten zwischen Eingabeproben lernen und Entscheidungen auf der Grundlage von Trainingsdaten treffen. Bei einem siamesischen Netzwerk verarbeitet jedes Netzwerk eines der entsprechenden Eingabebeispiele und vergleicht seine Ausgaben, um zu bestimmen, wie ähnlich oder unähnlich sie sind.


- 共享网络:共享网络是Siamese架构的核心组件。它负责从输入样本中提取有意义的特征表示。共享网络包含神经单元的层,例如卷积层或全连接层,用于处理输入数据并生成固定长度的embedding向量。通过在孪生网络之间共享相同的权重,模型学会为相似的输入提取相似的特征,从而实现有效的比较。
- 相似性度:一旦输入由共享网络处理,就会使用相似性度量来比较生成的embedding,并测量两个输入之间的相似性或不相似性。相似度度量的选择取决于特定任务和输入数据的性质。常见的相似性度量包括欧氏距离、余弦相似度或相关系数。相似性度量量化了embedding之间的距离或相关性,并提供了输入样本之间相似性的度量。
- 对比损失函数:为了训练Siamese网络,采用了对比损失函数。对比损失函数鼓励网络为相似的输入生成距离更近的embedding,而为不相似的输入生成距离更远的embedding。当相似对之间的距离超过一定阈值或不相似对之间的距离低于另一个阈值时,对比损失函数对模型进行惩罚。对比损失函数的确切制定取决于所选的相似性度量和相似对与不相似对之间的期望边际。
在训练过程中,Siamese网络学会优化其参数以最小化对比损失,并生成能够有效捕捉输入数据的相似性结构的判别性embedding。
对比损失函数
对比损失是Siamese网络中常用于学习输入样本对之间相似性或不相似性的损失函数。它旨在以这样一种方式优化网络的参数,即相似的输入具有在特征空间中更接近的embedding,而不相似的输入则被推到更远的位置。通过最小化对比损失,网络学会生成能够有效捕捉输入数据的相似性结构的embedding。
为了详细了解对比损失函数,让我们将其分解为其关键组件和步骤:
- 输入对:对比损失函数作用于输入样本对,其中每对包含一个相似或正例和一个不相似或负例。这些对通常在训练过程中生成,其中正例对代表相似实例,而负例对代表不相似实例。
- embedding:Siamese网络通过共享网络处理每个输入样本,为配对中的两个样本生成embedding向量。这些embedding是固定长度的表示,捕捉输入样本的基本特征。
- 距离度量:使用距离度量,如欧氏距离或余弦相似度,来衡量生成的embedding之间的不相似性或相似性。距离度量的选择取决于输入数据的性质和任务的具体要求。
- 对比损失计算:对比损失函数计算每对embedding的损失,鼓励相似对具有更小的距离,而不相似对具有更大的距离。对比损失的一般公式如下:L = (1 — y) * D² + y * max(0, m — D)
其中:
- L:对于一对的对比损失。
- D:embedding之间的距离或不相似性。
- y:标签,指示配对是否相似(相似为0,不相似为1)。
- m:定义不相似性阈值的边际参数。
损失项 `(1 — y) * D²` 对相似对进行惩罚,如果它们的距离超过边际(m),则鼓励网络减小它们的距离。项 `y * max(0, m — D)²` 对不相似对进行惩罚,如果它们的距离低于边际,则推动网络增加它们的距离。
- 损失的汇总:为了获得整个输入对批次的整体对比损失,通常会对所有对之间的个体损失进行平均或求和。汇总方法的选择取决于特定的训练目标和优化策略。
通过通过梯度下降优化方法(例如反向传播和随机梯度下降)最小化对比损失,Siamese网络学会生成能够有效捕捉输入数据的相似性结构的判别性embedding。对比损失函数在训练Siamese网络中发挥着关键作用,使其能够学习可用于各种任务,如图像相似性、人脸验证和文本相似性的有意义表示。对比损失函数的具体制定和参数可以根据数据的特性和任务的要求进行调整。
在 PyTorch 中的孪生神经网络
1. 数据集创建
我们使用的数据集来自来自 :
http://vision.stanford.edu/aditya86/ImageNetDogs/
def copy_files(source_folder,files_list,des):for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.copy2(source_file,des_file)print(f"Copied {file} to {des}")return def move_files(source_folder,des):files_list=os.listdir(source_folder)for file in files_list:source_file=os.path.join(source_folder,file)des_file=os.path.join(des,file)shutil.move(source_file,des_file)print(f"Copied {file} to {des}")return def rename_file(file_path,new_name):directory=os.path.dirname(file_path)new_file_path=os.path.join(directory,new_name)os.rename(file_path,new_file_path)print(f"File renamed to {new_file_path}")returnfolder_path=r"C:\Users\sri.karan\Downloads\images1\Images\*"op_path_similar=r"C:\Users\sri.karan\Downloads\images1\Images\similar_all_images"tmp=r"C:\Users\sri.karan\Downloads\images1\Images\tmp"op_path_dissimilar=r"C:\Users\sri.karan\Downloads\images1\Images\dissimilar_all_images"folders_list=glob.glob(folder_path)folders_list=list(set(folders_list).difference(set(['C:\\Users\\sri.karan\\Downloads\\images1\\Images\\similar_all_images','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\tmp','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\dissimilar_all_images'])))l,g=0,0random.shuffle(folders_list)for i in glob.glob(folder_path):if i in ['C:\\Users\\sri.karan\\Downloads\\images1\\Images\\similar_all_images','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\tmp','C:\\Users\\sri.karan\\Downloads\\images1\\Images\\dissimilar_all_images']:continuefile_name=i.split('\\')[-1].split("-")[1]picked_files=pick_random_files(i,6)copy_files(i,picked_files,tmp)for m in range(3):rename_file(os.path.join(tmp,picked_files[m*2]),"similar_"+str(g)+"_first.jpg")rename_file(os.path.join(tmp,picked_files[m*2+1]),"similar_"+str(g)+"_second.jpg")g+=1move_files(tmp,op_path_similar)choice_one,choice_two=random.choice(range(len(folders_list))),random.choice(range(len(folders_list)))picked_dissimilar_one=pick_random_files(folders_list[choice_one],3)picked_dissimilar_two=pick_random_files(folders_list[choice_two],3)copy_files(folders_list[choice_one],picked_dissimilar_one,tmp)copy_files(folders_list[choice_two],picked_dissimilar_two,tmp)picked_files_dissimilar=picked_dissimilar_one+picked_dissimilar_twofor m in range(3):rename_file(os.path.join(tmp,picked_files_dissimilar[m]),"dissimilar_"+str(l)+"_first.jpg")rename_file(os.path.join(tmp,picked_files_dissimilar[m+3]),"dissimilar_"+str(l)+"_second.jpg")l+=1move_files(tmp,op_path_dissimilar)我们挑选了3对相似图像(狗品种)和3对不相似图像(狗品种)来微调模型,为了使负样本简单,对于给定的锚定图像(狗品种),任何除地面实况狗品种以外的其他狗品种都被视为负标签。
注意: “相似图像” 意味着来自相同狗品种的图像被视为正对,而“不相似图像” 意味着来自不同狗品种的图像被视为负对。
代码解释:
- 46行:从每个狗图像文件夹中随机挑选了6张图像。
- 47行:选择的图像被移动到一个名为 “tmp” 的文件夹中,并且由于它们来自同一狗品种文件夹,因此被重命名为 “similar_images”。
- 55行:完成所有这些后,它们被移动到 “similar_all_images” 文件夹中。
- 56、57行:类似地,为了获得不相似的图像对,从两个不同的狗品种文件夹中选择了3张图像。
- 然后重复上述流程,以获得不相似的图像对并将它们移动到 “dissimilar_all_images” 文件夹中。
完成所有这些后,我们可以继续创建数据集对象。
import torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import DataLoaderfrom PIL import Imageimport numpy as npimport randomfrom torch.utils.data import DataLoader, Datasetimport torchimport torch.nn as nnfrom torch import optimimport torch.nn.functional as Fclass ImagePairDataset(torch.utils.data.Dataset):def __init__(self, root_dir):self.root_dir = root_dirself.transform = T.Compose([# We first resize the input image to 256x256 and then we take center crop.transforms.Resize((256,256)), transforms.ToTensor()])self.image_pairs = self.load_image_pairs()def __len__(self):return len(self.image_pairs)def __getitem__(self, idx):image1_path, image2_path, label = self.image_pairs[idx]image1 = Image.open(image1_path).convert("RGB")image2 = Image.open(image2_path).convert("RGB")# Convert the tensor to a PIL image# image1 = functional.to_pil_image(image1)# image2 = functional.to_pil_image(image2)image1 = self.transform(image1)image2 = self.transform(image2)# image1 = torch.clamp(image1, 0, 1)# image2 = torch.clamp(image2, 0, 1)return image1, image2, labeldef load_image_pairs(self):image_pairs = []# Assume the directory structure is as follows:# root_dir# ├── similar# │ ├── similar_image1.jpg# │ ├── similar_image2.jpg# │ └── ...# └── dissimilar# ├── dissimilar_image1.jpg# ├── dissimilar_image2.jpg# └── ...similar_dir = os.path.join(self.root_dir, "similar_all_images")dissimilar_dir = os.path.join(self.root_dir, "dissimilar_all_images")# Load similar image pairs with label 1similar_images = os.listdir(similar_dir)for i in range(len(similar_images) // 2):image1_path = os.path.join(similar_dir, f"similar_{i}_first.jpg")image2_path = os.path.join(similar_dir, f"similar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 0))# Load dissimilar image pairs with label 0dissimilar_images = os.listdir(dissimilar_dir)for i in range(len(dissimilar_images) // 2):image1_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_first.jpg")image2_path = os.path.join(dissimilar_dir, f"dissimilar_{i}_second.jpg")image_pairs.append((image1_path, image2_path, 1))return image_pairsdataset = ImagePairDataset(r"/home/niq/hcsr2001/data/image_similarity")train_size = int(0.8 * len(dataset))test_size = len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])batch_size = 32train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)在上述代码的第8到10行:对图像进行预处理,包括将图像调整大小为256。我们使用批量大小为32,这取决于您的计算能力和 GPU。
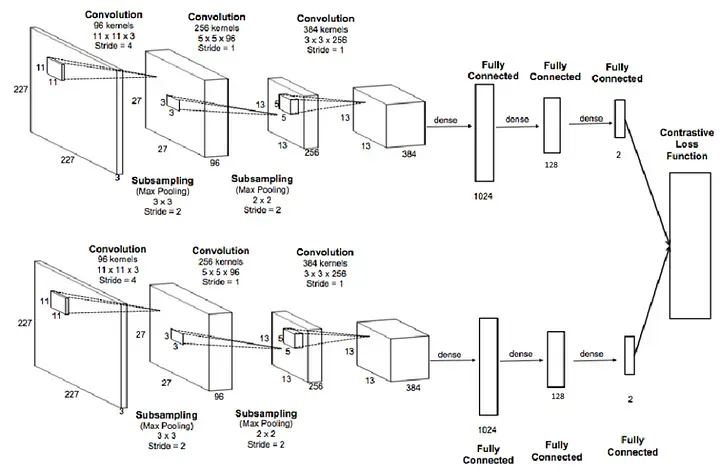
#create the Siamese Neural Networkclass SiameseNetwork(nn.Module):def __init__(self):super(SiameseNetwork, self).__init__()# Setting up the Sequential of CNN Layers# self.cnn1 = nn.Sequential(# nn.Conv2d(3, 256, kernel_size=11,stride=4),# nn.ReLU(inplace=True),# nn.MaxPool2d(3, stride=2),# nn.Conv2d(256, 256, kernel_size=5, stride=1),# nn.ReLU(inplace=True),# nn.MaxPool2d(2, stride=2),# nn.Conv2d(256, 384, kernel_size=3,stride=1),# nn.ReLU(inplace=True)# )self.cnn1=nn.Conv2d(3, 256, kernel_size=11,stride=4)self.relu = nn.ReLU()self.maxpool1=nn.MaxPool2d(3, stride=2)self.cnn2=nn.Conv2d(256, 256, kernel_size=5,stride=1)self.maxpool2=nn.MaxPool2d(2, stride=2)self.cnn3=nn.Conv2d(256, 384, kernel_size=3,stride=1)self.fc1 =nn.Linear(46464, 1024)self.fc2=nn.Linear(1024, 256)self.fc3=nn.Linear(256, 1)# Setting up the Fully Connected Layers# self.fc1 = nn.Sequential(# nn.Linear(384, 1024),# nn.ReLU(inplace=True),# nn.Linear(1024, 32*46464),# nn.ReLU(inplace=True),# nn.Linear(32*46464,1)# )def forward_once(self, x):# This function will be called for both images# Its output is used to determine the similiarity# output = self.cnn1(x)# print(output.view(output.size()[0], -1).shape)# output = output.view(output.size()[0], -1)# output = self.fc1(output)# print(x.shape)output= self.cnn1(x)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool1(output)# print(output.shape)output= self.cnn2(output)# print(output.shape)output=self.relu(output)# print(output.shape)output=self.maxpool2(output)# print(output.shape)output= self.cnn3(output)output=self.relu(output)# print(output.shape)output=output.view(output.size()[0], -1)# print(output.shape)output=self.fc1(output)# print(output.shape)output=self.fc2(output)# print(output.shape)output=self.fc3(output)return outputdef forward(self, input1, input2):# In this function we pass in both images and obtain both vectors# which are returnedoutput1 = self.forward_once(input1)output2 = self.forward_once(input2)return output1, output2
我们的网络称为 SiameseNetwork,我们可以看到它几乎与标准 CNN 相同。唯一可以注意到的区别是我们有两个前向函数(forward_once 和 forward)。为什么呢?
我们提到通过相同网络传递两个图像。forward_once 函数在 forward 函数中调用,它将一个图像作为输入传递到网络。输出存储在 output1 中,而来自第二个图像的输出存储在 output2 中,正如我们在 forward 函数中看到的那样。通过这种方式,我们设法输入了两个图像并从我们的模型获得了两个输出。
我们已经看到了损失函数应该是什么样子,现在让我们来编码它。我们创建了一个名为 ContrastiveLoss 的类,与模型类一样,我们将有一个 forward 函数。
class ContrastiveLoss(torch.nn.Module):def __init__(self, margin=2.0):super(ContrastiveLoss, self).__init__()self.margin = margindef forward(self, output1, output2, label):# Calculate the euclidean distance and calculate the contrastive losseuclidean_distance = F.pairwise_distance(output1, output2, keepdim = True)loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))return loss_contrastivenet = SiameseNetwork().cuda()criterion = ContrastiveLoss()optimizer = optim.Adam(net.parameters(), lr = 0.0005 )
按照顶部的流程图,我们可以开始创建训练循环。我们迭代100次并提取两个图像以及标签。我们将梯度归零,将两个图像传递到网络中,网络输出两个向量。然后,将两个向量和标签馈送到我们定义的 criterion(损失函数)中。我们进行反向传播和优化。出于一些可视化目的,并查看我们的模型在训练集上的性能,因此我们将每10批次打印一次损失。
counter = []loss_history = [] iteration_number= 0# Iterate throught the epochsfor epoch in range(100):# Iterate over batchesfor i, (img0, img1, label) in enumerate(train_loader, 0):# Send the images and labels to CUDAimg0, img1, label = img0.cuda(), img1.cuda(), label.cuda()# Zero the gradientsoptimizer.zero_grad()# Pass in the two images into the network and obtain two outputsoutput1, output2 = net(img0, img1)# Pass the outputs of the networks and label into the loss functionloss_contrastive = criterion(output1, output2, label)# Calculate the backpropagationloss_contrastive.backward()# Optimizeoptimizer.step()# Every 10 batches print out the lossif i % 10 == 0 :print(f"Epoch number {epoch}\n Current loss {loss_contrastive.item()}\n")iteration_number += 10counter.append(iteration_number)loss_history.append(loss_contrastive.item())show_plot(counter, loss_history)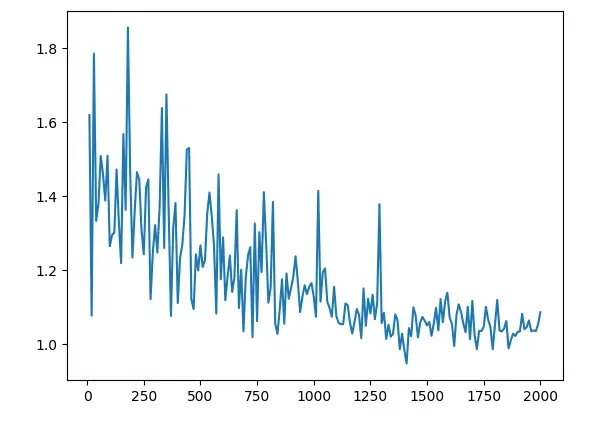
我们现在可以分析结果。我们能看到的第一件事是损失从1.6左右开始,并以接近1的数字结束。看到模型的实际运行情况将是有趣的。现在是我们在模型之前没见过的图像上测试我们的模型的部分。与之前一样,我们使用我们的自定义数据集类创建了一个 Siamese Network 数据集,但现在我们将其指向测试文件夹。
作为接下来的步骤,我们从第一批中提取第一张图像,并迭代5次以提取接下来5批中的5张图像,因为我们设置每批包含一张图像。然后,使用 torch.cat() 水平组合两个图像,我们可以清楚地可视化哪个图像与哪个图像进行了比较。
我们将两个图像传入模型并获得两个向量,然后将这两个向量传入 F.pairwise_distance() 函数,这将计算两个向量之间的欧氏距离。使用这个距离,我们可以作为衡量两张脸有多不相似的指标。
test_loader_one = DataLoader(test_dataset, batch_size=1, shuffle=False)dataiter = iter(test_loader_one)x0, _, _ = next(dataiter)for i in range(5):# Iterate over 5 images and test them with the first image (x0)_, x1, label2 = next(dataiter)# Concatenate the two images togetherconcatenated = torch.cat((x0, x1), 0)output1, output2 = net(x0.cuda(), x1.cuda())euclidean_distance = F.pairwise_distance(output1, output2)imshow(torchvision.utils.make_grid(concatenated), f'Dissimilarity: {euclidean_distance.item():.2f}')view raweval.py hosted with ❤ by GitHub
总结
Siamese 网络与对比损失结合,为学习图像相似性提供了一个强大而有效的框架。通过对相似和不相似图像进行训练,这些网络可以学会提取能够捕捉基本视觉特征的判别性embedding。对比损失函数通过优化embedding空间进一步增强
了模型准确测量图像相似性的能力。随着深度学习和计算机视觉的进步,Siamese 网络在各个领域都有着巨大的潜力,包括图像搜索、人脸验证和推荐系统。通过利用这些技术,我们可以为基于内容的图像检索、视觉理解以及视觉领域的智能决策开启令人兴奋的可能性。
Das obige ist der detaillierte Inhalt vonErforschung siamesischer Netzwerke unter Verwendung von Kontrastverlust zum Vergleich der Bildähnlichkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
