
 Technologie-Peripheriegeräte
KI
Lass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.
Technologie-Peripheriegeräte
KI
Lass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.
Lass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.

Geschrieben von Noah
Produziert |. 51CTO Technology Stack (WeChat ID: blog51cto)
Siri, die von Nutzern immer dafür kritisiert wird, „ein bisschen geistig zurückgeblieben“ zu sein, ist gerettet!
Siri gehört seit seiner Geburt zu den Vertretern auf dem Gebiet der intelligenten Sprachassistenten, allerdings ist seine Leistung schon lange unbefriedigend. Allerdings wird erwartet, dass die neuesten Forschungsergebnisse des Apple-Teams für künstliche Intelligenz den Status quo deutlich verändern werden. Diese Ergebnisse sind aufregend und wecken große Erwartungen für die Zukunft dieses Bereichs.
In entsprechenden Forschungsarbeiten beschreiben Apples KI-Experten ein System, bei dem Siri nicht nur den Inhalt in Bildern erkennen, sondern auch mehr tun kann und dadurch intelligenter und nützlicher wird. Dieses Funktionsmodell heißt ReALM, basiert auf dem GPT 4.0-Standard und verfügt über bessere Benchmark-Fähigkeiten als GPT 4.0. Diese Experten glauben, dass das von ihnen entwickelte Modell zur Implementierung einer von ihnen entwickelten Funktion verwendet wird, die Siri intelligenter, praktischer und für verschiedene Szenarien besser geeignet machen kann.
1. Motivation: Lösung der Referenzauflösung verschiedener Entitäten
Laut dem Forschungsteam von Apple: „Es ist sehr wichtig, den Konversationsassistenten in die Lage zu versetzen, den Kontext zu verstehen, einschließlich der zugehörigen Inhaltsverweisung.“ „Das Stellen von Fragen ist ein wichtiger Schritt, um ein sprachgesteuertes Erlebnis zu gewährleisten.“ Beispielsweise können Sie dem Sprachassistenten Anweisungen geben, eine Telefonnummer anrufen, zu einem bestimmten Ort auf einer Karte navigieren, eine bestimmte App oder Webseite öffnen und vieles mehr. Wenn der Konversationsassistent die Entitätsreferenz hinter den Anweisungen des Benutzers nicht verstehen kann, ist er nicht in der Lage, diese Befehle genau auszuführen.
Darüber hinaus ist das Phänomen der Fuzzy-Referenz in menschlichen Gesprächen weit verbreitet. Um eine natürliche Mensch-Computer-Interaktion zu erreichen und den Kontext genau zu verstehen, wenn Benutzer mit Sprachassistenten Anfragen zu Bildschirminhalten stellen, ist die Fähigkeit, Referenzen aufzulösen, von entscheidender Bedeutung.
Der Vorteil des von Apple in dem Artikel erwähnten Modells namens ReALM (Reference Resolution As Language Modeling) besteht darin, dass es den Inhalt auf dem Bildschirm des Benutzers und die laufende Aufgabe gleichzeitig berücksichtigen und große Sprachmodelle verwenden kann Lösen Sie verschiedene Probleme der Referenzauflösung von Typentitäten (einschließlich Konversationsentitäten und Nichtkonversationsentitäten).
Obwohl die herkömmliche Textmodalität für die Verarbeitung der auf dem Bildschirm angezeigten Entitäten unpraktisch ist, wandelt das ReALM-System die Referenzanalyse in ein Sprachmodellierungsproblem um und verwendet LLMs erfolgreich zur Verarbeitung der Referenz von Nicht-Konversationsentitäten auf dem Bildschirm äußerst effizient. Die Erde ermöglicht dieses Ziel. Auf diese Weise soll ein hochintelligentes und immersiveres Benutzererlebnis erreicht werden.
2. Rekonstruktion: Durchbrechen der Einschränkungen des traditionellen Textmodals
Das traditionelle Textmodal ist für die Verarbeitung von auf dem Bildschirm angezeigten Entitäten nicht geeignet, da Entitäten auf dem Bildschirm normalerweise umfangreiche visuelle Informationen und Layoutstrukturen enthalten, z Bilder, Symbole, Schaltflächen und deren relative Positionsbeziehungen usw. Es ist schwierig, diese Informationen vollständig in einer reinen Textbeschreibung auszudrücken.
Um dieser Herausforderung zu begegnen, schlägt das ReALM-System auf kreative Weise vor, den Bildschirm zu rekonstruieren, indem es Entitäten auf dem Bildschirm und ihre Positionsinformationen analysiert und eine reine Textdarstellung generiert, die den Bildschirminhalt visuell widerspiegeln kann.
Entitätsteile werden speziell markiert, damit das Sprachmodell versteht, wo die Entität erscheint und was der Text um sie herum ist, sodass es das „Sehen“ der Informationen auf dem Bildschirm simulieren und die Anweisungen auf dem Bildschirm verstehen und analysieren kann . Geben Sie die notwendigen Kontextinformationen an. Dieser Ansatz ist der erste Versuch, ein großes Sprachmodell zu verwenden, um Kontext aus Bildschirminhalten zu kodieren und so das Problem von Bildschirmeinheiten zu überwinden, die mit herkömmlichen Textmodalitäten schwer zu handhaben sind.
Damit das große Sprachmodell die auf dem Bildschirm angezeigten Entitäten „verstehen“ und verarbeiten kann, führt das ReALM-System insbesondere die folgenden Schritte aus:
Zuerst werden die Entitäten im Bildschirmtext mit extrahiert Mithilfe von Datendetektoren der oberen Ebene verfügen diese Entitäten über einen Typ, einen Begrenzungsrahmen und eine Liste von Nicht-Entitätstextelementen, die die Entität umgeben. Das bedeutet, dass das System für jede visuelle Einheit auf dem Bildschirm deren grundlegende Informationen und den Kontext, in dem sie existiert, erfasst.
Dann schlägt ReALM auf innovative Weise einen Algorithmus vor, um die Mittelpunkte der Begrenzungsrahmen von Entitäten und umgebenden Objekten in vertikaler (von oben nach unten) und horizontaler (von links nach rechts) Reihenfolge zu sortieren und die Anordnung zu stabilisieren. Wenn der Abstand zwischen den Elementen gering ist, werden sie als auf derselben Zeile liegend betrachtet und durch Tabulatoren getrennt. Wenn der Abstand den festgelegten Rand überschreitet, werden sie in der nächsten Zeile platziert. Auf diese Weise kann durch kontinuierliche Anwendung der oben genannten Methode der Bildschirminhalt von links nach rechts und von oben nach unten in ein Nur-Text-Format codiert werden, wodurch die relative räumliche Beziehung zwischen Entitäten effektiv beibehalten wird.
Auf diese Weise werden die visuellen Bildschirminformationen, die von LLM nur schwer direkt verarbeitet werden können, in eine für die Sprachmodelleingabe geeignete Textform umgewandelt, sodass LLM die spezifische Position und Position von Bildschirmentitäten bei der Verarbeitung vollständig berücksichtigen kann Sequenz-zu-Sequenz-Aufgaben, um eine korrekte Identifizierung und Referenzauflösung von Bildschirmeinheiten zu erreichen.
Dadurch leistet das ReALM-System nicht nur eine gute Leistung bei der Lösung des Referenzproblems von Konversationsentitäten, sondern zeigt auch eine deutliche Leistungsverbesserung beim Umgang mit Nichtkonversationsentitäten – also Entitäten auf dem Bildschirm.
3. Details: Aufgabendefinition und Datensatz
Vereinfacht ausgedrückt besteht die Aufgabe des ReALM-Systems darin, die Entitäten zu finden, die sich auf die aktuelle Benutzerabfrage in der angegebenen Entitätssammlung beziehen, basierend auf den Aufgaben, die der Benutzer ausführen möchte ausführen.
Diese Aufgabe ist als Multiple-Choice-Frage für ein großes Sprachmodell strukturiert und es wird erwartet, dass aus den auf dem Bildschirm des Benutzers angezeigten Entitäten eine oder mehrere Optionen als Antwort ausgewählt werden. Natürlich kann die Antwort in manchen Fällen auch „weder noch“ lauten.
Tatsächlich unterteilt das Forschungspapier die an der Aufgabe beteiligten Entitäten in drei Kategorien:
1 Bildschirmentitäten: bezieht sich auf Entitäten, die derzeit auf der Benutzeroberfläche sichtbar sind.
2. Dialogentitäten: Entitäten, die sich auf den Gesprächsinhalt beziehen und aus der letzten Rede des Benutzers stammen können (wenn der Benutzer beispielsweise „Mama anrufen“ erwähnt, ist der Eintrag „Mama“ in der Kontaktliste die relevante Entität), oder können von virtuellen Assistenten generiert werden, die in Gesprächen bereitgestellt werden (z. B. eine Liste von Orten, aus denen der Benutzer auswählen kann).
3. Hintergrundentitäten: Zugehörige Entitäten, die aus Hintergrundprozessen stammen und sich nicht unbedingt direkt in der Bildschirmanzeige des Benutzers oder in der Interaktion mit dem virtuellen Assistenten widerspiegeln, z. B. ein Wecker, der standardmäßig ertönt, oder Musik, die im Hintergrund abgespielt wird.
Der zum Trainieren und Testen von ReALM verwendete Datensatz besteht aus synthetischen Daten und manuell annotierten Daten, die ebenfalls in drei Kategorien unterteilt werden können:
Erstens der Dialogdatensatz: enthält die Interaktion zwischen die Benutzer- und Agentendatenpunkte für verbundene Entitäten. Diese Daten wurden gesammelt, indem Bewerter Screenshots mit Listen synthetischer Entitäten ansahen und sie gebeten wurden, Abfragen zu stellen, die explizit auf eine ausgewählte Entität in der Liste verwiesen.
Zweitens synthetischer Datensatz: Verwenden Sie die Methode zur Vorlagengenerierung, um Daten zu erhalten. Diese Methode ist besonders nützlich, wenn die Benutzerabfrage und der Entitätstyp ausreichen, um die Referenz zu bestimmen, ohne sich auf eine detaillierte Beschreibung verlassen zu müssen. Der synthetische Datensatz kann auch mehrere Entitäten enthalten, die derselben Abfrage entsprechen.
Dritter Bildschirmdatensatz: Er umfasst hauptsächlich die Daten von Entitäten, die derzeit auf dem Bildschirm des Benutzers angezeigt werden. Jedes Datenelement enthält eine Benutzerabfrage, eine Entitätsliste und die richtige Entität (oder Entitätssammlung), die der Abfrage entspricht. Zu den Informationen zu jeder Entität gehören der Entitätstyp und andere Eigenschaften wie der Name und andere mit der Entität verbundene Textdetails (z. B. die Bezeichnung und die Uhrzeit eines Weckers).
Für Datenpunkte, die bildschirmbezogenen Kontext enthalten, werden Kontextinformationen in Form des Begrenzungsrahmens der Entität und einer Liste anderer die Entität umgebender Objekte zusammen mit Attributinformationen wie Typ, Textinhalt und Position bereitgestellt dieser umgebenden Objekte. Die Größe des gesamten Datensatzes ist nach Kategorien in Trainingssätze und Testsätze unterteilt, und jeder hat eine bestimmte Größe.
4. Ergebnisse: Auch das kleinste Modell erzielte eine Leistungssteigerung von 5 %
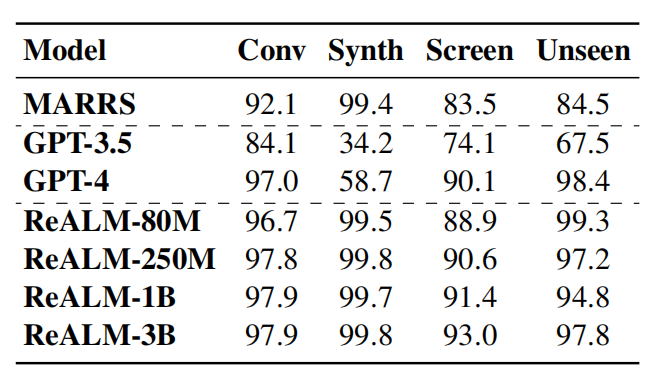
Im Benchmark-Test verglich Apple das eigene System mit GPT 3.5 und GPT 4.0. Das ReALM-Modell zeigt eine hervorragende Wettbewerbsfähigkeit bei der Lösung verschiedener Arten von referenziellen Parsing-Aufgaben.
 Bild
Bild
Dem Papier zufolge hat selbst die Version mit den wenigsten Parametern in ReALM eine Leistungsverbesserung von mehr als 5 % im Vergleich zum Basissystem erzielt. Bei der größeren Modellversion übertrifft ReALM GPT-4 deutlich. Insbesondere bei der Verarbeitung von auf dem Bildschirm angezeigten Entitäten wird die Leistungsverbesserung von ReALM auf dem Bildschirmdatensatz mit zunehmender Modellgröße immer bedeutender.
Darüber hinaus kommt die Leistung des ReALM-Modells in Zero-Shot-Lernszenarien in neuen Bereichen ziemlich nahe an GPT-4 heran. Bei der Verarbeitung von Abfragen in bestimmten Feldern ist das ReALM-Modell aufgrund der Feinabstimmung basierend auf Benutzeranforderungen genauer als GPT-4.
Bei einer Benutzeranfrage zum Anpassen der Helligkeit ordnet GPT-4 beispielsweise die Anfrage nur den Einstellungen zu und ignoriert dabei, dass die im Hintergrund vorhandenen Smart-Home-Geräte ebenfalls verwandte Einheiten sind, und ReALM wird domänenspezifisch trainiert Daten können die Referenzprobleme in solchen spezifischen Bereichen besser verstehen und richtig lösen.
„Wir zeigen, dass RealLM frühere Methoden übertrifft und vergleichbare Ergebnisse erzielt, selbst wenn es um Bildschirmreferenzen geht, die ausschließlich auf Textfeldern basieren, obwohl es weitaus weniger Parameter als das aktuelle LLM, GPT-4, hat . Darüber hinaus ist RealLM für Benutzeräußerungen in bestimmten Bereichen geeignet und kann lokal auf dem Gerät implementiert werden ist die bevorzugte Lösung für ein effizientes Referenzauflösungssystem. Darüber hinaus gaben die Forscher an, dass in praktischen Anwendungsszenarien Antworten mit geringer Latenz erforderlich sind oder eine mehrstufige Integration erforderlich ist, z. B. API-Aufrufe. Ein einziges groß angelegtes End-to-End-Endmodell ist oft nicht anwendbar.
In diesem Zusammenhang bietet das modular aufgebaute ReALM-System weitere Vorteile, da es einen einfachen Austausch und ein Upgrade des ursprünglichen Referenzauflösungsmoduls ohne Auswirkungen auf die Gesamtarchitektur ermöglicht und gleichzeitig ein besseres Optimierungspotenzial und eine bessere Interpretierbarkeit bietet.
Face à l'avenir, l'orientation de la recherche pointe vers des méthodes plus complexes, telles que la division de la zone d'écran en grilles et l'encodage des positions spatiales relatives sous forme de texte. Bien que cela soit assez difficile, il s'agit d'une voie prometteuse à explorer.
5. Écrit à la fin
Dans le domaine de l'intelligence artificielle, même si Apple a toujours été plus prudente, elle investit aussi discrètement. Qu'il s'agisse du grand modèle multimodal MM1, de l'outil de génération d'animation piloté par l'IA Keyframer ou encore du ReALM actuel, l'équipe de recherche d'Apple a continué à réaliser des percées technologiques.
Regardez des concurrents tels que Google, Microsoft et Amazon ajouter l'IA à la recherche, aux services cloud et aux logiciels de bureau, faisant jouer leurs muscles les uns après les autres. Apple essaie clairement de ne pas se laisser distancer. Alors que les résultats de la mise en œuvre de l’IA générative continuent d’émerger, Apple a accéléré son rythme de rattrapage. Des personnes proches du dossier ont révélé depuis longtemps qu'Apple se concentrerait sur le domaine de l'intelligence artificielle lors de la conférence mondiale des développeurs en juin, et que la nouvelle stratégie d'intelligence artificielle deviendra probablement le contenu principal de la mise à niveau iOS 18. D’ici là, cela pourrait vous réserver des surprises.
Lien de référence :
https://apple.slashdot.org/story/24/04/01/1959205/apple-ai-researchers-boast-useful-on-device-model-that-substantiellement-surperforme -gpt-4
https://arxiv.org/pdf/2403.20329.pdf
Das obige ist der detaillierte Inhalt vonLass Siri nicht länger geistig zurückgeblieben sein! Apple definiert ein neues geräteseitiges Modell, das „viel besser als GPT-4' ist. Es verzichtet auf Text und simuliert Bildschirminformationen immer noch 5 % besser als das Basissystem.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So passen Sie den Sesam offenen Austausch in Chinesisch an
Mar 04, 2025 pm 11:51 PM
So passen Sie den Sesam offenen Austausch in Chinesisch an
Mar 04, 2025 pm 11:51 PM
Wie kann ich den Sesam offenen Austausch an Chinesisch anpassen? Dieses Tutorial behandelt detaillierte Schritte zu Computern und Android -Mobiltelefonen, von der vorläufigen Vorbereitung bis hin zu operativen Prozessen und dann bis zur Lösung gemeinsamer Probleme, um die Sesam -Open Exchange -Schnittstelle auf Chinesisch zu wechseln und schnell mit der Handelsplattform zu beginnen.
 Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Muss ich Flexbox in der Mitte des Bootstrap -Bildes verwenden?
Apr 07, 2025 am 09:06 AM
Es gibt viele Möglichkeiten, Bootstrap -Bilder zu zentrieren, und Sie müssen keine Flexbox verwenden. Wenn Sie nur horizontal zentrieren müssen, reicht die Text-Center-Klasse aus. Wenn Sie vertikal oder mehrere Elemente zentrieren müssen, ist Flexbox oder Grid besser geeignet. Flexbox ist weniger kompatibel und kann die Komplexität erhöhen, während das Netz leistungsfähiger ist und höhere Lernkosten hat. Bei der Auswahl einer Methode sollten Sie die Vor- und Nachteile abwägen und die am besten geeignete Methode entsprechend Ihren Anforderungen und Vorlieben auswählen.
 Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top Ten Ten Virtual Currency Trading Platforms 2025: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Zu den zehn Top -Kryptowährungsplattformen gehören: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Eine sichere und zuverlässige Plattform für digitale Währung: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Die Berechnung von C35 ist im Wesentlichen kombinatorische Mathematik, die die Anzahl der aus 3 von 5 Elementen ausgewählten Kombinationen darstellt. Die Berechnungsformel lautet C53 = 5! / (3! * 2!), Was direkt durch Schleifen berechnet werden kann, um die Effizienz zu verbessern und Überlauf zu vermeiden. Darüber hinaus ist das Verständnis der Art von Kombinationen und Beherrschen effizienter Berechnungsmethoden von entscheidender Bedeutung, um viele Probleme in den Bereichen Wahrscheinlichkeitsstatistik, Kryptographie, Algorithmus -Design usw. zu lösen.
 Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene Safe Virtual Currency Software Apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Top 10 Apps Rankings von Virtual Currency Trading: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundenbetreuung sollten bei der Auswahl einer Plattform berücksichtigt werden.
