

Kuaishou-Verstärkungslernen und Multitasking-Empfehlung

1. Zweistufiger eingeschränkter Schauspieler-Kritiker für kurze Videoempfehlungen
Die erste Arbeit wurde von Kuaishou selbst entwickelt und zielte hauptsächlich auf eingeschränkte Multitasking-Szenarien ab.
1. Kurzes Video-Multitasking-Empfehlungsszenario

Diese Arbeit zielt hauptsächlich auf ein professionelleres Multitasking-Benutzerfeedback ab, das in die Betrachtungsdauer und Interaktion unterteilt ist, die häufiger vorkommen Einschließlich Likes, Collections, Follows und Kommentare hat jedes dieser Feedbacks seine eigenen Eigenschaften. Durch Online-Systembeobachtung haben wir festgestellt, dass das Dauersignal tatsächlich sehr spärlich ist und es schwierig ist, das Interesse des Benutzers genau zu messen, da es sich um einen kontinuierlichen Wert handelt. Im Gegensatz dazu sind interaktive Signale umfassender, einschließlich Likes, Favoriten, Follows und Kommentare. Diese Rückmeldungen können in zwei Kategorien unterteilt werden: Publikumspräferenzen und Verhaltensfeedback. Während des Optimierungsprozesses betrachten wir dieses Signal als Hauptziel und die Interaktion als Hilfsoptimierung. Wir versuchen sicherzustellen, dass das interaktive Signal nicht als Gesamtziel der Optimierung verloren geht. Im Gegensatz dazu sind die Interaktionszahlen spärlicher und da es keinen einheitlichen Standard gibt, ist es schwierig, das Nutzerinteresse genau zu messen. Um den Effekt zu verbessern, müssen wir bestimmte Optimierungen durchführen, damit er als Hauptziel in unserem System optimiert werden kann und gleichzeitig die Integrität der interaktiven Daten als Hilfsmittel für das Gesamtziel sichergestellt wird.

Auf diese Weise kann das Problem sehr intuitiv als eingeschränktes Optimierungsproblem beschrieben werden. Es gibt ein Hauptziel der Optimierung des Nutzens und das Hilfsziel besteht darin, eine Untergrenze zu erfüllen. Anders als bei herkömmlichen Pareto-Optimierungsproblemen müssen wir hier Prioritäten setzen.
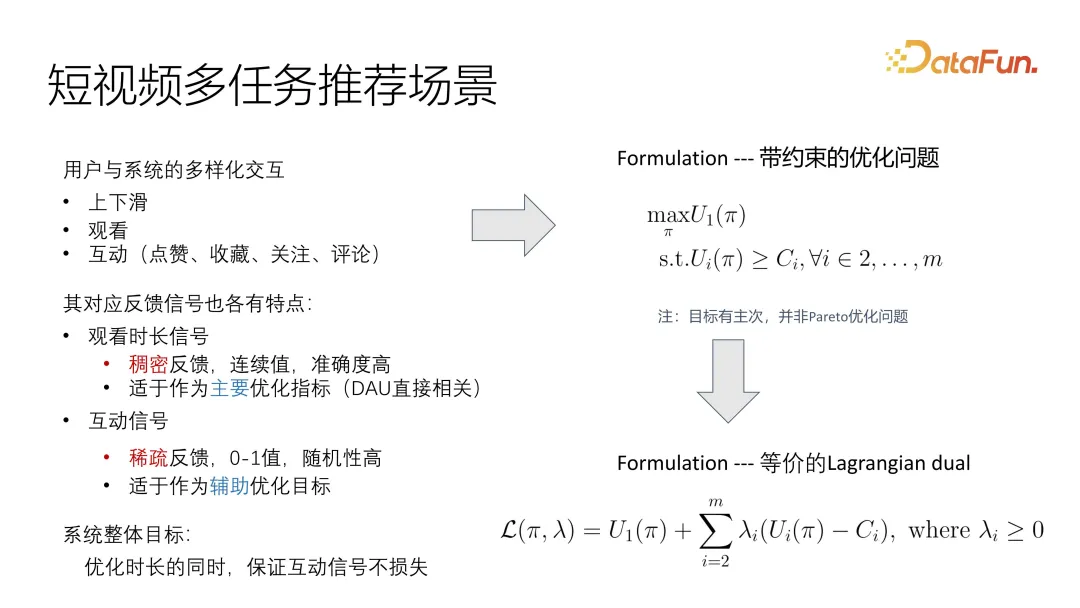
Eine übliche Methode zur Lösung dieses Problems besteht darin, es in ein Lagrange-Dualproblem umzuwandeln, sodass es direkt in eine optimierte Zielfunktion integriert werden kann. Unabhängig davon, ob es sich um eine Gesamtoptimierung oder eine alternierende Optimierung handelt, kann es optimiert werden ein Gesamtziel. Natürlich ist es notwendig, die Korrelation und Einflussfaktoren verschiedener Ziele zu kontrollieren.
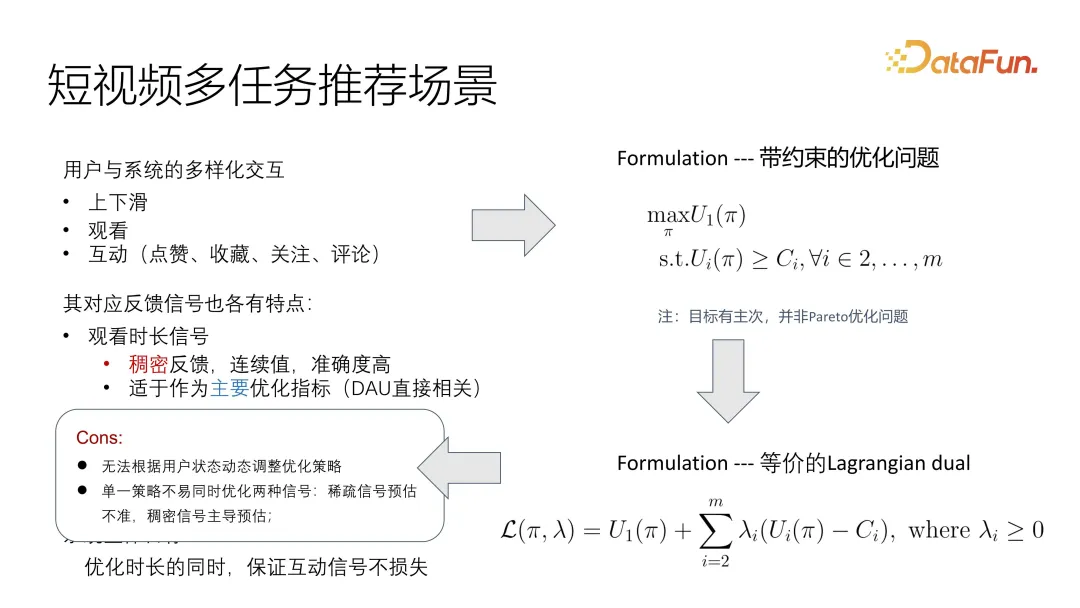
Bei der Formulierung dieser Beobachtung gibt es noch einige Probleme, da sich der Benutzerstatus dynamisch ändert und sich im Kurzvideoszenario sehr schnell ändert. Da die Signale nicht einheitlich sind und insbesondere die Hauptzieloptimierung und die Hilfszieloptimierung der Zyanose sehr inkonsistente Verteilungsprobleme aufweisen, ist es außerdem schwierig, mit vorhandenen Lösungen umzugehen. Wenn Sie es in einer Zielfunktion vereinheitlichen, kann eines der Signale ein anderes Signal dominieren.
2. Multi-Task Reinforcement Learning
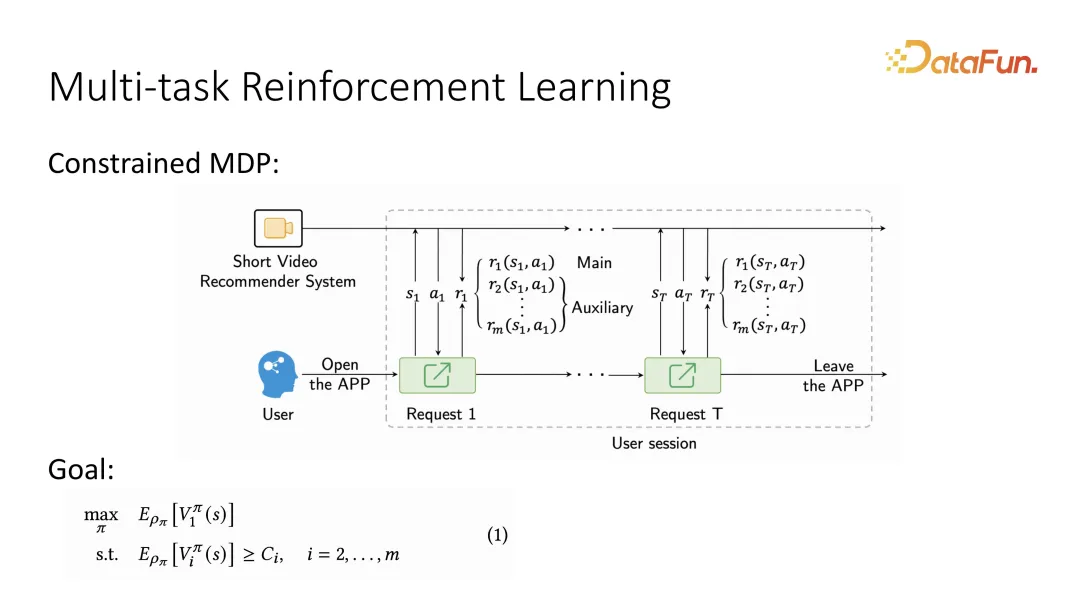
Basierend auf dem ersten Punkt wird das Problem unter Berücksichtigung der dynamischen Veränderungen von Benutzern oft als MDP beschrieben, was die Abfolge der abwechselnden Interaktion zwischen Benutzern und Benutzern darstellt System und diese Sequenz Nachdem sie als Markov-Entscheidungsprozess beschrieben wurde, kann sie mithilfe von Methoden des verstärkenden Lernens gelöst werden. Insbesondere muss nach der Beschreibung des Markov-Entscheidungsprozesses, da auch zwischen Hauptziel und Nebenziel unterschieden werden muss, eine zusätzliche Aussage gemacht werden, dass beim Geben von Benutzerfeedback zwei verschiedene Ziele unterschieden werden müssen Es können mehrere Hilfsziele sein. Wenn Verstärkungslernen das langfristige Optimierungsziel definiert, definiert es das zu optimierende Hauptziel als langfristige Wertfunktion, die als Wertfunktion bezeichnet wird. Ebenso gibt es für Hilfsziele auch entsprechende Wertfunktionen. Entsprechend dem Feedback jedes Benutzers wird es eine langfristige Wertbewertung geben. Im Vergleich zur vorherigen Nutzenfunktion ist sie nun zu einer langfristigen Wertfunktion geworden.
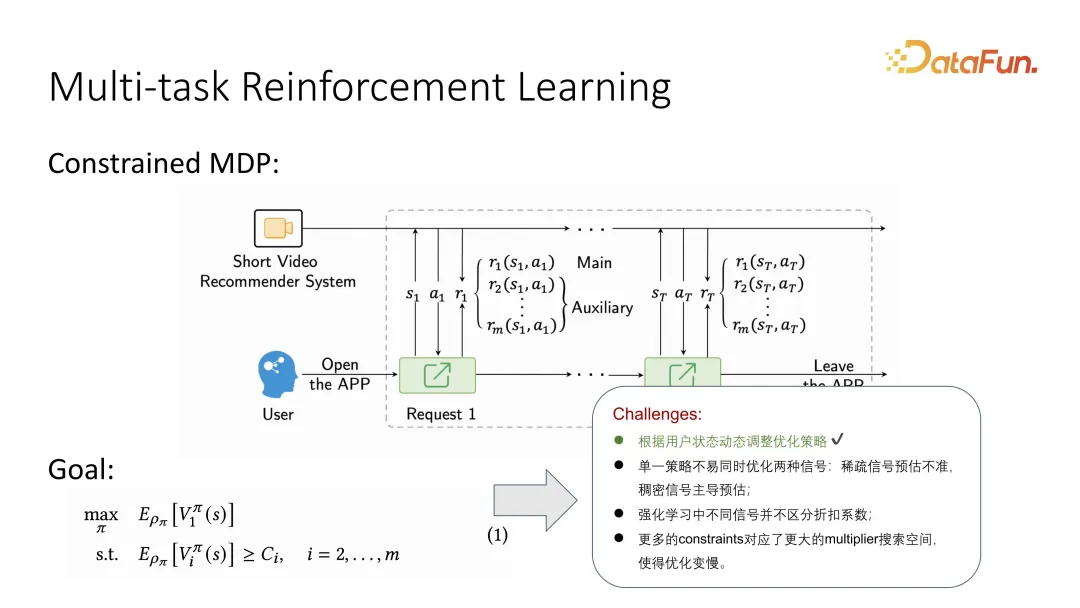
In ähnlicher Weise werden in Kombination mit Reinforcement Learning einige neue Probleme auftreten, beispielsweise wie Reinforcement Learning verschiedene Rabattkoeffizienten unterscheidet. Darüber hinaus wird mit der Einführung weiterer Einschränkungen der Suchraum für Parameter größer, was das verstärkende Lernen schwieriger macht.
3. Lösung: Zweistufige multikritische Optimierung

Die Lösung dieser Arbeit besteht darin, die gesamte Optimierung in zwei Phasen zu unterteilen. Die erste Phase optimiert die Hilfsziele und die zweite Phase optimiert die Hauptziele.
In der ersten Stufe der Hilfszieloptimierung wird eine typische Methode zur Optimierung von Akteurkritikern angewendet. Zur Optimierung von Hilfszielen wie Likes und Followern wird ein Kritiker optimiert, um die Qualität des aktuellen Zustands abzuschätzen. Nachdem die langfristige Wertschätzung korrekt ist, können Sie die Wertfunktion als Lernhilfe bei der Optimierung des Akteurs verwenden. Formel (2) ist die Optimierung des Kritikers und Formel (3) ist die Optimierung des Akteurs. Zur Optimierung des Kritikers werden während des Trainings der aktuelle Zustand, der nächste Zustand und die Stichprobe der aktuellen Aktion verwendet . Gemäß der Bellman-Gleichung kann die Aktion erhalten werden, und in Verbindung mit der Wertschätzung des zukünftigen Zustands sollte sie nahe an der Schätzung des aktuellen Zustands liegen. Auf diese Weise kann sich die Optimierung schrittweise der genauen langfristigen Wertschätzung nähern . Bei der Steuerung des Lernens von Akteuren, also der Empfehlung des Lernens von Richtlinien, wird eine Vorteilsfunktion verwendet. Die Vorteilsfunktion bezieht sich darauf, ob die Wirkung einer bestimmten Aktion stärker ist als die durchschnittliche Schätzung. Diese durchschnittliche Schätzung wird als Basislinie bezeichnet. Je größer der Vorteil, desto besser die Aktion und desto größer die Wahrscheinlichkeit, dass diese empfohlene Strategie übernommen wird. Dies ist die erste Stufe, die Optimierung von Hilfszielen.

Die zweite Stufe besteht darin, das Hauptziel zu optimieren, wir nutzen die Dauer. Das Hilfsziel verwendet eine ungefähre Strategie, wenn es das Hauptziel einschränkt. Wir hoffen, dass die vom Hauptziel ausgegebene Aktionsverteilung so nah wie möglich an den verschiedenen Hilfszielen liegt, solange wir uns dem Hilfsziel nähern Das Ziel sollte nicht allzu schlecht sein. Nach Erhalt der Näherungsformulierung kann eine geschlossene Lösung durch Vervollständigung des Quadrats, also auf gewichtete Weise, erhalten werden. Tatsächlich gibt es keinen großen Unterschied zwischen der Optimierungsmethode des Schauspielerkritikers des gesamten Hauptziels auf der Kritikerebene und der Wertfunktionsschätzungsebene. Aber im Fall von Schauspielern führen wir Gewichte ein, die aus der Lösung in geschlossener Form erhalten werden. Die Bedeutung dieses Gewichts besteht darin, dass je größer der Impact-Faktor ist, der einer bestimmten Hilfsstrategie I entspricht, desto größer ist ihr Einfluss auf das Gesamtgewicht. Wir hoffen, dass die Verteilung der Richtlinienausgabe so nah wie möglich am Durchschnitt aller Hilfszielrichtlinien liegt. Dieses Phänomen tritt auf, wenn das Verhalten der geschlossenen Lösung erhalten wird.
4. Experimente
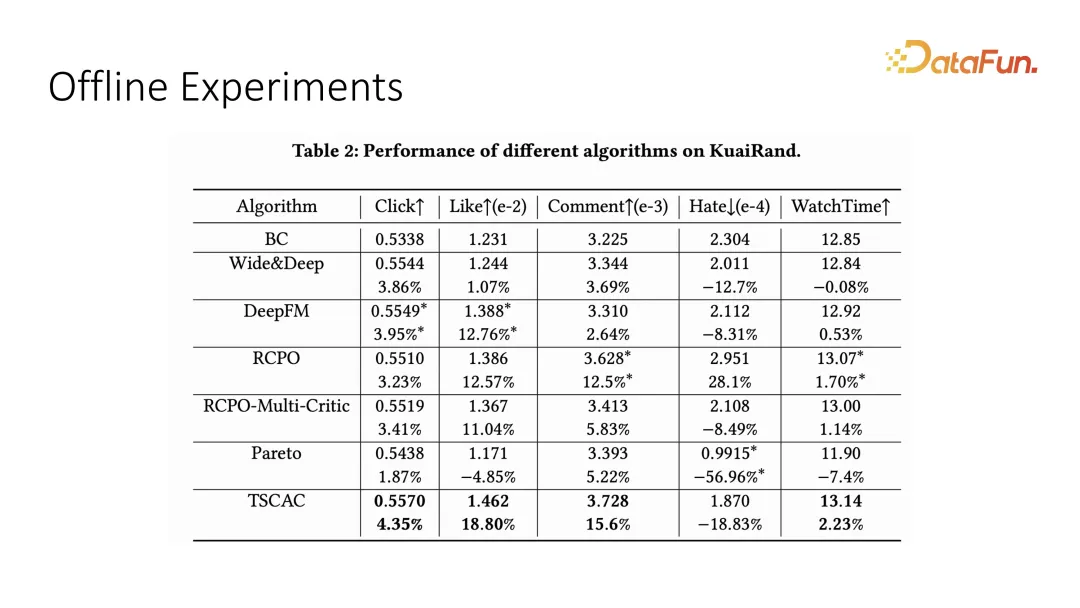
Das Hauptziel hier ist die Wiedergabezeit, also die Betrachtungszeit, und die Hilfsziele sind Klick, Liken, Kommentieren und Hassen sowie andere interaktive Indikatoren. Es ist ersichtlich, dass der von uns vorgeschlagene zweistufige Akteur-Kritiker optimale Ergebnisse erzielen kann.
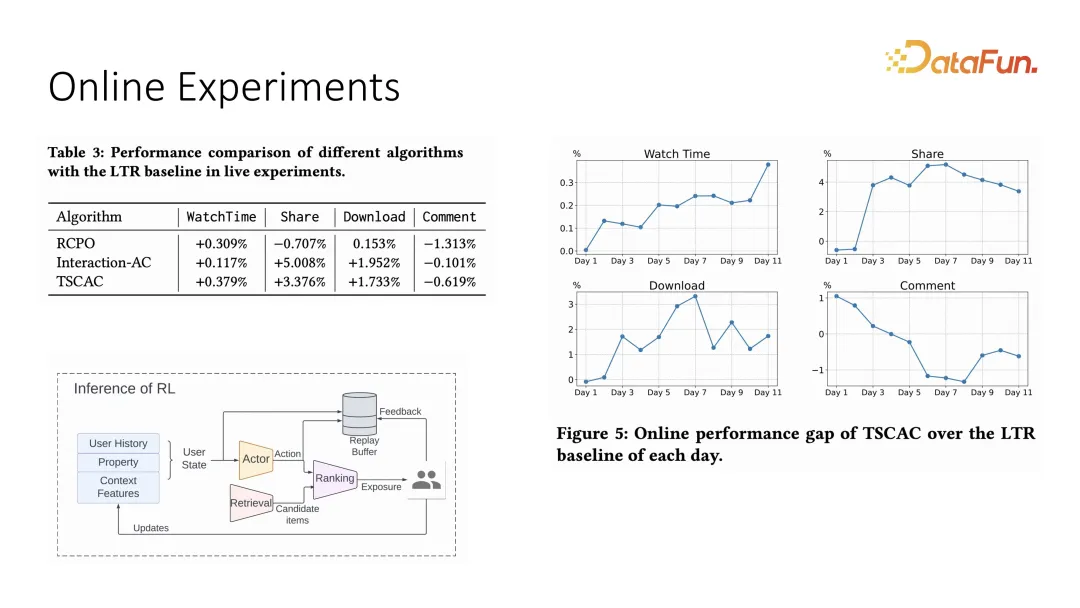
In ähnlicher Weise haben wir auch entsprechende Vergleichsexperimente im Online-System durchgeführt. Die Einstellung des Online-Systems übernimmt das Empfehlungsmodell des Schauspielers plus Ranking, und das endgültige Ranking wird von jedem bestimmt item und Das Ergebnis des inneren Produkts der Gewichte. Aus Online-Experimenten geht auch hervor, dass die Wiedergabezeit andere Interaktionen einschränken und gleichzeitig die Interaktionsindikatoren verbessern kann.
Das Obige ist eine Einführung in die erste Arbeit.
2. Multi-Task-Empfehlungen mit Reinforcement Learning
Die zweite Arbeit ist ebenfalls die Anwendung von Reinforcement Learning bei der Multi-Task-Optimierung, aber dies ist eine traditionellere Optimierung. Diese Arbeit ist ein Gemeinschaftsprojekt von Kuaishou und der City University of Hong Kong. Der Erstautor ist Liu Ziru.
1. Hintergrund und Motivation
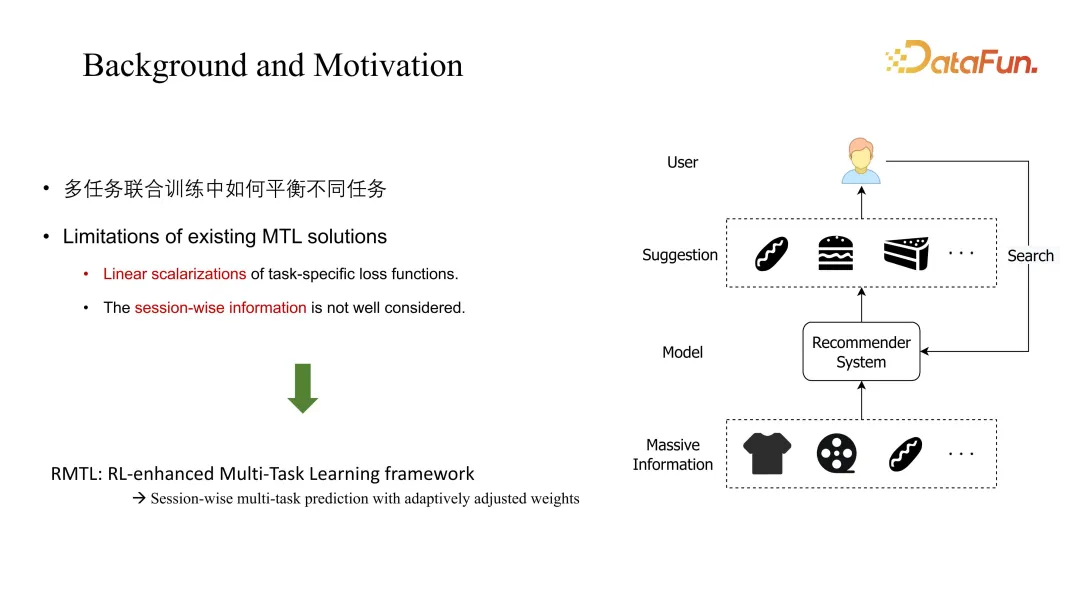
Das in dieser Arbeit diskutierte Hauptproblem besteht darin, die Koeffizienten zwischen verschiedenen Aufgaben auszugleichen. Die traditionelle MTL-Lösung ist im Allgemeinen eine lineare Kombination Methoden werden berücksichtigt und die Sitzungsdimension, also langfristige dynamische Änderungen, werden ignoriert. Der in dieser Arbeit vorgeschlagene RMTL ändert die Gewichtungsmethode durch langfristige Prognosen.
2. Problemformulierung
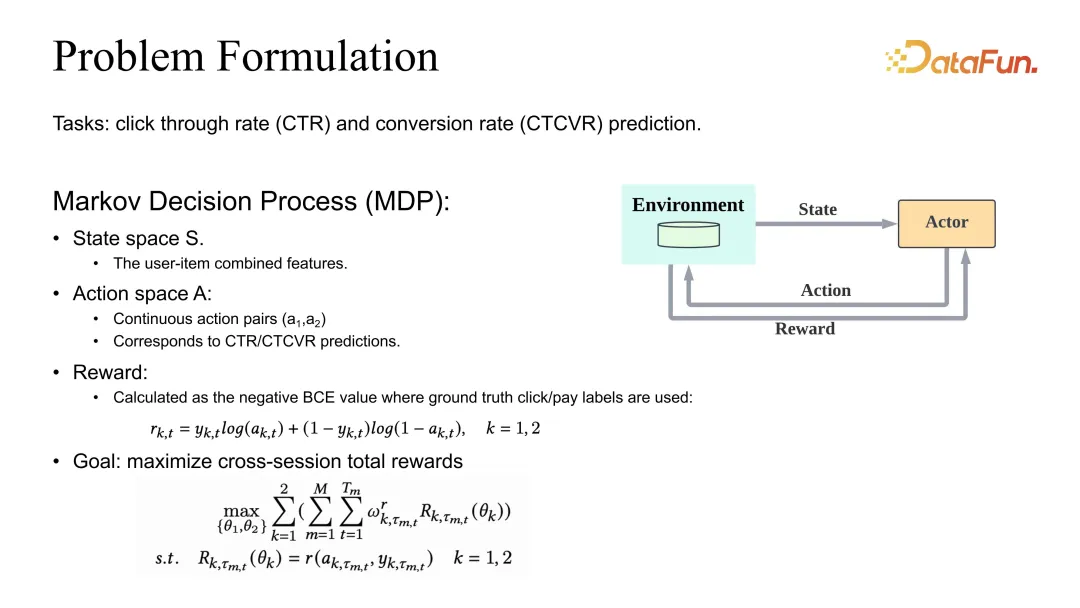
Die Problemstellung besteht darin, die gemeinsame Optimierung der Schätzungen von CTR und CVR zu definieren. Wir haben auch eine Definition von MDP (Markov Decision Process), aber hier handelt es sich bei der Aktion nicht mehr um eine Empfehlungsliste, sondern um die entsprechenden CTR- und CVR-Schätzungen. Wenn die Schätzung korrekt sein soll, sollte die Belohnung als BCE oder ein entsprechender angemessener Verlust definiert werden. Im Hinblick auf die Gesamtzieldefinition werden im Allgemeinen unterschiedliche Aufgabengewichte definiert und dann die gesamte Sitzung und alle Datenproben summiert.
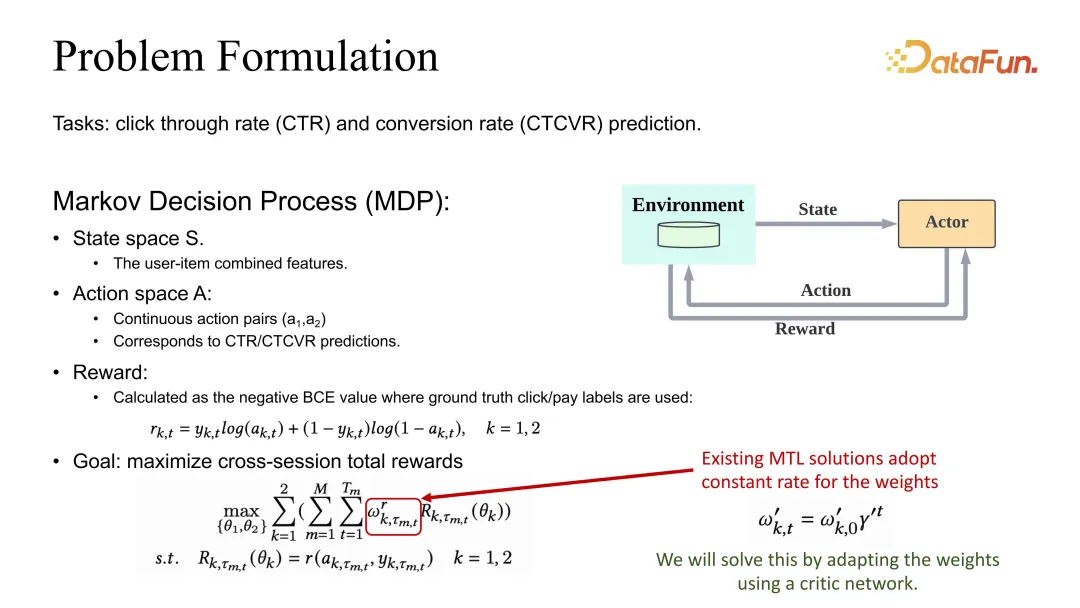
Sie können sehen, dass zusätzlich zum Rabatt von Gamma auch der Gewichtskoeffizient von einem Koeffizienten beeinflusst wird, der angepasst werden muss.
3. Lösungsrahmen
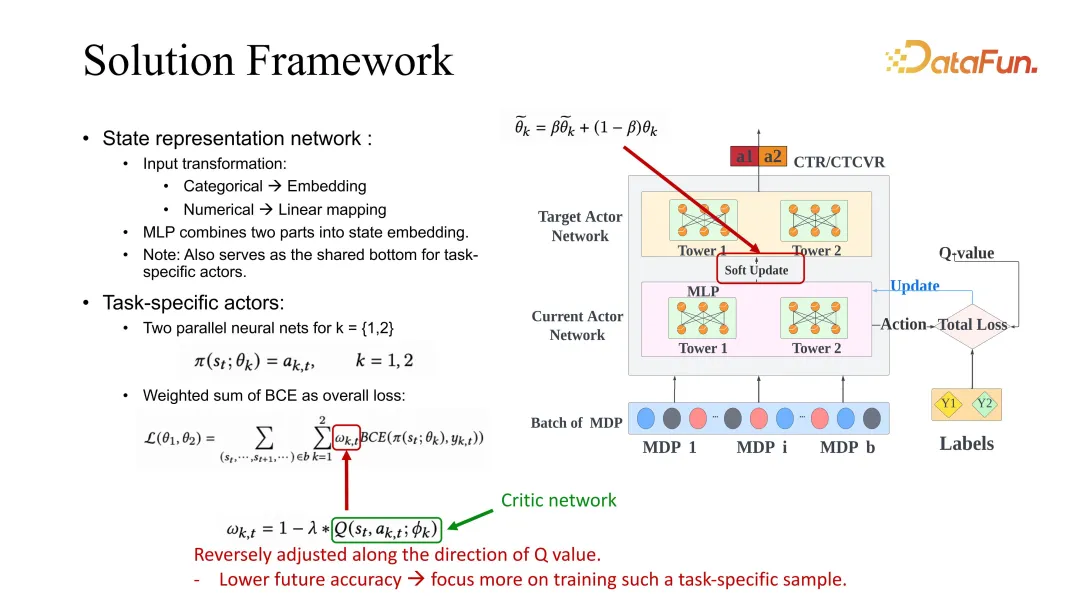
Unsere Lösung besteht darin, die Anpassung dieses Koeffizienten in Bezug auf die Schätzung der Sitzungsdimension vorzunehmen. Ein ESMM-Backbone ist hier gegeben. Natürlich ist auch die Verwendung anderer Baselines üblich und kann mit unserer Methode verbessert werden.
Lassen Sie uns ESMM im Detail vorstellen. Für jede Aufgabe wird ein Ziel und eine aktuelle Akteuroptimierung verwendet. Während des Optimierungsprozesses muss der BCE-Verlust das aufgabenspezifische Gewicht anpassen, wenn er das Lernen des Akteurs steuert. In unserer Lösung muss dieses Gewicht aufgrund zukünftiger Wertschätzungen entsprechend geändert werden. Die Bedeutung dieser Einstellung besteht darin, dass ein höherer zukünftiger Bewertungswert bedeutet, dass der aktuelle Status und die aktuelle Aktion genauer sind und das Lernen verlangsamt werden kann. Im Gegenteil, wenn die Vorhersage der Zukunft schlecht ist, bedeutet dies, dass das Modell hinsichtlich der Zukunft des Staates und Handelns nicht optimistisch ist und sein Lernen erhöht werden sollte. Das Gewicht wird auf diese Weise angepasst. Zukünftige Evaluationen nutzen hier auch das oben erwähnte Kritikernetzwerk zum Lernen.
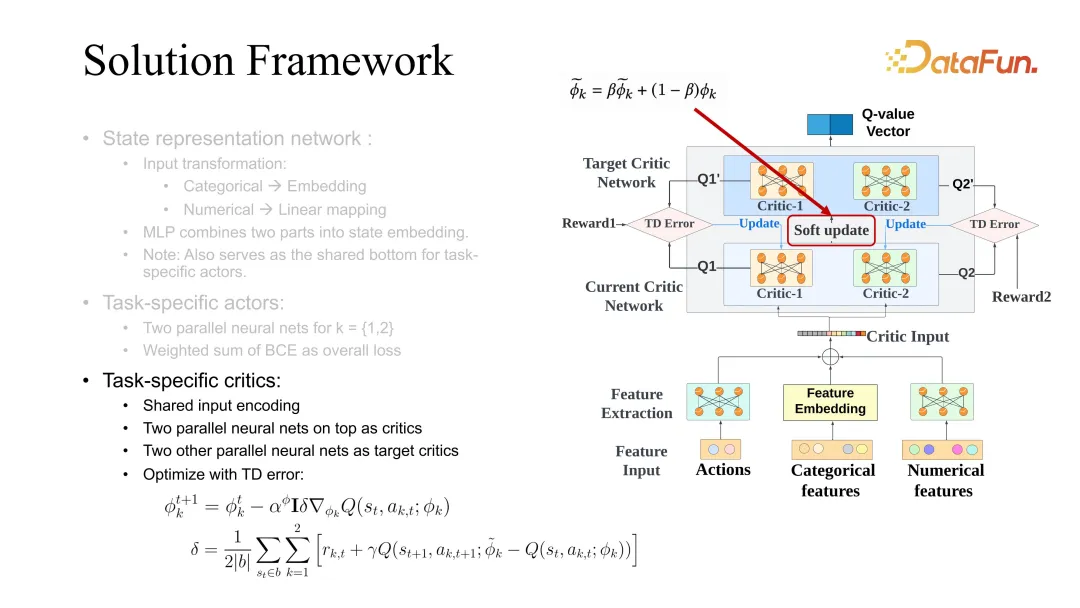
Der Kritiker verwendet auch die Differenz zwischen dem zukünftigen Zustand und dem aktuellen Zustand, unterscheidet sich jedoch von der Wertfunktion. Das Erlernen der Differenz verwendet hier die Q-Funktion, die eine gemeinsame Bewertung von Zustand und Aktion erfordert . Bei der Aktualisierung von Akteuren ist es auch erforderlich, das Lernen von Akteuren zu nutzen, die verschiedenen Aufgaben gleichzeitig entsprechen. Hier ist Soft Update ein allgemeiner Trick, der nützlicher ist, wenn die Stabilität des RL-Lernens erhöht wird. Normalerweise werden das Ziel und der aktuelle Kritiker gleichzeitig optimiert. 5. Experiment wurde verbessert.
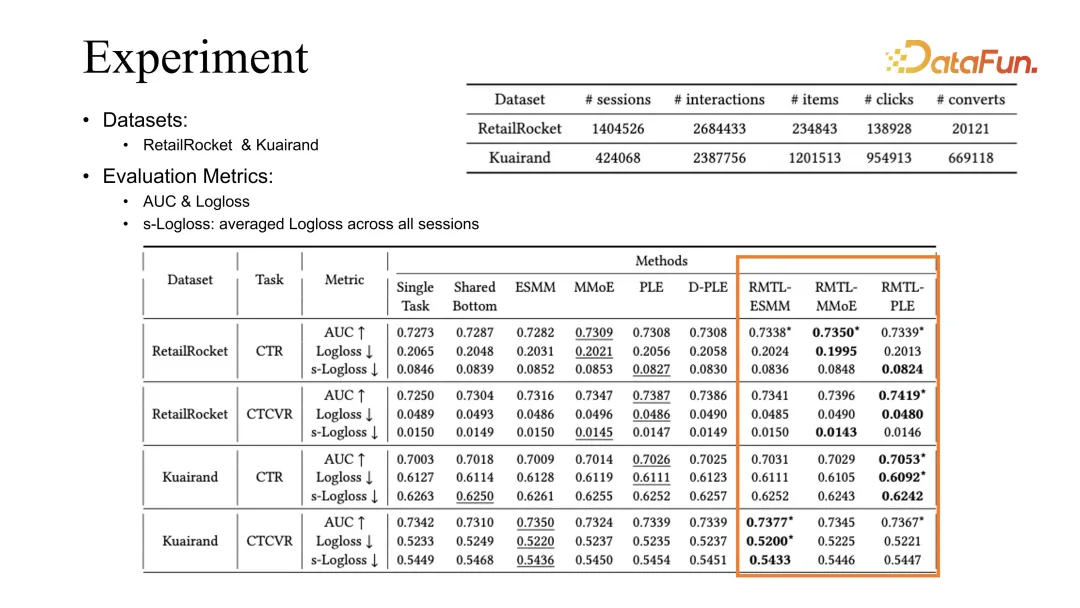
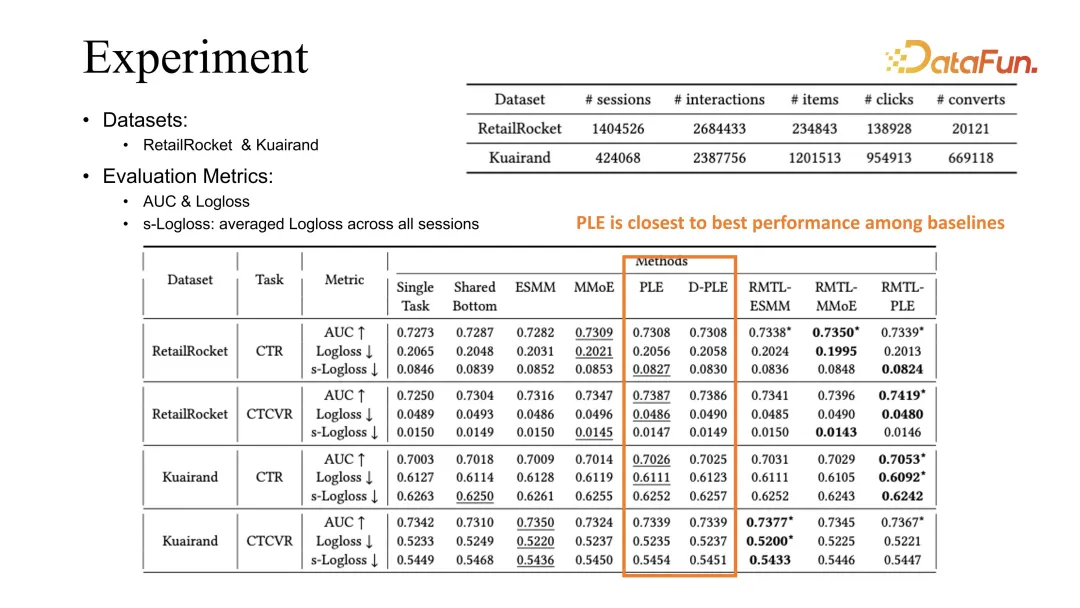
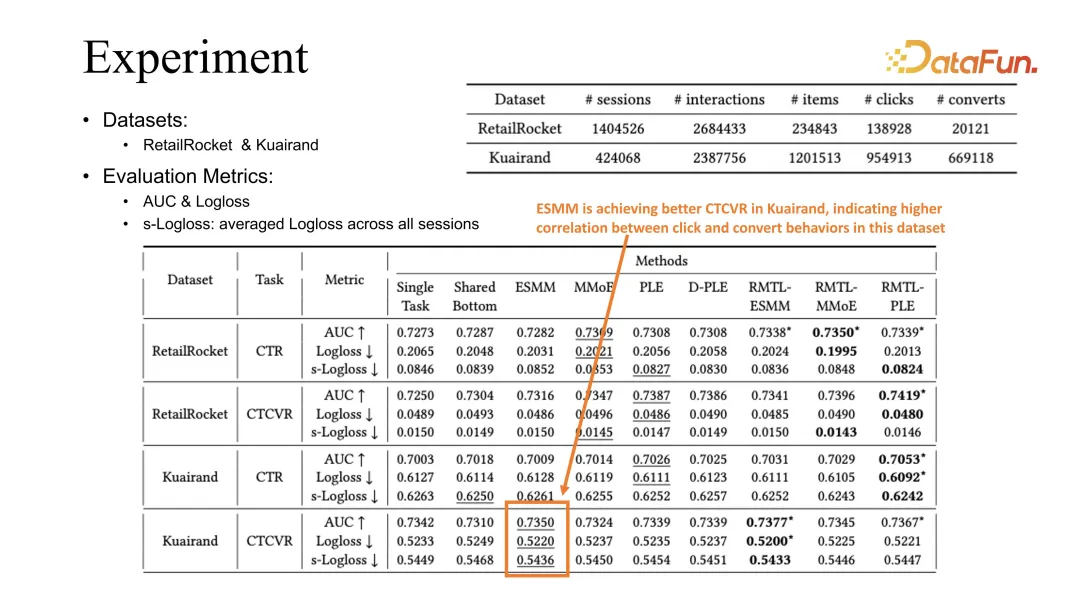
5. Übertragbarkeitsstudie
Darüber hinaus haben wir auch einen Übertragbarkeitstest durchgeführt, da unser Kritiker direkt auf andere Modelle übertragen werden kann. Sie können beispielsweise die Schauspielerkritik mithilfe der grundlegendsten RMTL erlernen und dann die Kritik verwenden, um die Leistung anderer Modelle direkt zu verbessern. Wir haben festgestellt, dass der Effekt während der Veredelung stabil verbessert werden kann.
6. Ablationsstudie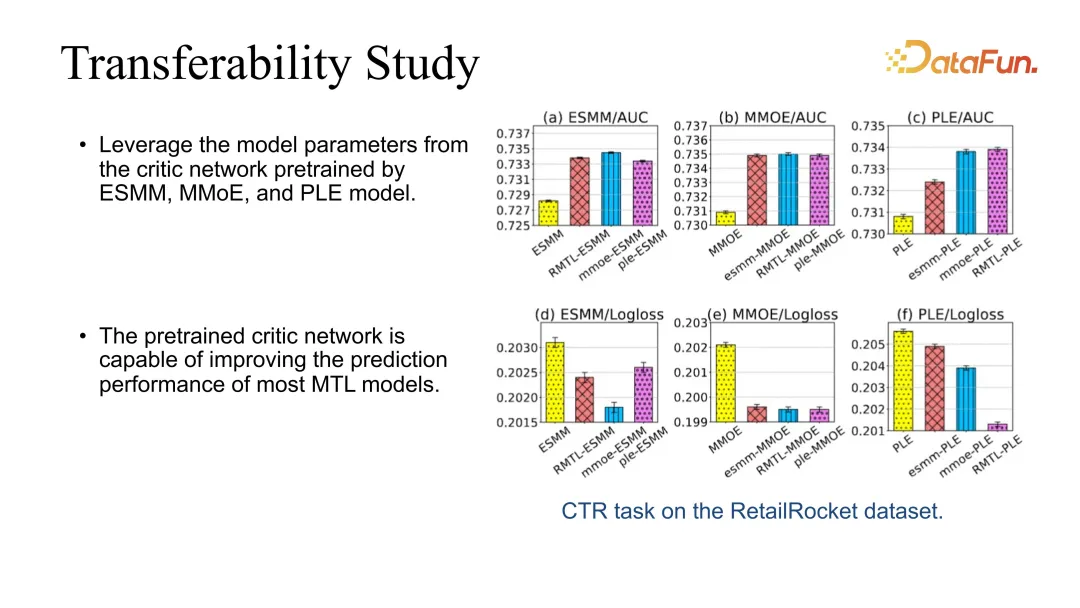
Abschließend haben wir eine Ablationsstudie durchgeführt, um verschiedene Gewichtungsmethoden zu vergleichen. Die besten Ergebnisse werden derzeit mit unserem RMTL erzielt. Lassen Sie uns abschließend einige Erfahrungen mit RL und MTL zusammenfassen. Wir haben festgestellt, dass die langfristige Optimierung des Empfehlungssystems, insbesondere die langfristige Optimierung komplexer Indikatoren, ein sehr typisches Szenario für verstärktes Lernen und Multitasking-Optimierung ist. Wenn es sich um eine gemeinsame Optimierung des Haupt- und Nebenziels handelt, kann eine sanfte Regularisierung verwendet werden, um das Lernen des Hauptziels einzuschränken. Wenn bei der Mehrziel-Gelenkoptimierung die dynamischen Änderungen verschiedener Ziele berücksichtigt werden, kann auch der Optimierungseffekt verbessert werden. Darüber hinaus gibt es auch einige Herausforderungen. Beispielsweise bringt die Kombination verschiedener Module des Reinforcement Learning viele Herausforderungen für die Stabilität des Systems mit sich. Wir haben die Erfahrung gemacht, dass die Kontrolle der Datenqualität, die Kontrolle der Etikettengenauigkeit und die Überwachung der Modellvorhersagegenauigkeit sehr wichtige Möglichkeiten sind. Da das Empfehlungssystem und der Benutzer außerdem direkt interagieren, können unterschiedliche Ziele die Benutzererfahrung nur teilweise widerspiegeln, sodass die resultierenden Empfehlungsstrategien sehr unterschiedlich sein werden. Wie man das Benutzererlebnis unter dem sich ständig ändernden Benutzerstatus gemeinsam optimieren und umfassend verbessern kann, wird in Zukunft ein sehr wichtiges Thema sein. F2: Welche Indikatoren können offline angezeigt werden, z. B. Regressionsindikatoren wie Dauerindikatoren? F3: Gibt es für spärliche Ziele wie die Weiterleitung eine Modellierungsmethode, die es genauer machen kann? F4: Wie führt Kuaishou diese Multi-Target-Fusion durch? Handelt es sich um die Anpassung der Verstärkungslernparameter? A5: Wir hatten in letzter Zeit einige Signale, bei denen die Arbeitsgespräche äußerst spärlich ausfielen und das Feedback nur wenige Tage in Anspruch nahm. Eines der typischsten Signale ist die Benutzerbindung, da Benutzer möglicherweise einige Tage lang weggehen, bevor sie wiederkommen. Wenn wir also das Signal erhalten, ist das Modell bereits mehrere Tage lang aktualisiert. Es gibt einige Kompromisse, um diese Probleme zu lösen. Eine Lösung besteht darin, zu analysieren, welche Echtzeit-Rückkopplungssignale eine gewisse Korrelation mit diesem äußerst spärlichen Signal haben. Durch die Optimierung dieser Echtzeitsignale wird eine Kombination von Methoden zur indirekten Optimierung von Langzeitsignalen eingesetzt. Am Beispiel der Retention haben wir in unserem System festgestellt, dass zwischen der Benutzerretention und der Echtzeit-Anzeigezeit des Benutzers eine sehr starke positive Korrelation besteht garantieren die Untergrenze der Benutzerbindung. Wenn wir die Kundenbindung optimieren, verwenden wir im Allgemeinen die Optimierungsdauer in Kombination mit einigen anderen zugehörigen Indikatoren, um die Kundenbindung zu optimieren. Solange unsere Analyse ergibt, dass ein gewisser Zusammenhang mit der Bindung besteht, können wir ihn einführen. A6: Schauspielerkritiker ist das Ergebnis, nachdem wir mehrere Male iteriert haben. Wir haben auch schon etwas intuitivere Methoden wie DQN und Reinforce ausprobiert. Einige davon sind in einigen Szenarien tatsächlich effektiv, aber derzeit ist der Schauspielerkritiker relativ stabil eins. Und eine gute Möglichkeit zum Debuggen. Beispielsweise erfordert die Verwendung von „Verstärkung“ die Verwendung von Langzeitsignalen, und das langfristige Flugbahnsignal ist relativ volatil, sodass es schwieriger wird, seine Stabilität zu verbessern. Einer der Vorteile von Actor Critical besteht jedoch darin, dass es auf der Grundlage von Einzelschrittsignalen optimieren kann, eine Funktion, die sehr gut mit Empfehlungssystemen übereinstimmt. Wir hoffen, dass das Feedback jedes Benutzers als Trainingsbeispiel zum Lernen verwendet werden kann und die entsprechenden Schauspielerkritiker- und DDPG-Methoden sehr gut mit den Einstellungen unseres Systems übereinstimmen. A7: Die Benutzer-ID ist eigentlich nicht schlecht, da unsere benutzerseitigen Funktionen immer noch verschiedene Funktionen verwenden. Zusätzlich zu den ID-Merkmalen verfügt der Benutzer auch über einige statistische Merkmale. Da sich RL in den von uns angewendeten Modulen wie Feinranking und Neuordnung in einem relativ späten Stadium befindet, werden außerdem in den vorherigen Phasen auch Schätzungen und Modellrankingsignale gegeben drin. Daher erhält Reinforcement Learning in empfohlenen Szenarien immer noch viele benutzerseitige Signale, und grundsätzlich wird es keine Situation geben, in der nur eine Benutzer-ID verwendet wird. A8: Ja, und wir haben festgestellt, dass die Auswirkung auf die Personalisierung ziemlich groß ist, wenn keine Benutzer-ID verwendet wird. Wenn Sie nur einige statistische Merkmale von Benutzern verwenden, ist der Verbesserungseffekt manchmal nicht so groß wie der einer Benutzer-ID. Zwar ist der Einfluss der Benutzer-ID relativ groß, aber wenn der Einfluss zu groß ist, kommt es zu Volatilitätsproblemen. A9: Dieses Problem ist auf den Benutzer-Kaltstart ausgerichtet. In Kaltstartszenarien werden empfohlene Links im Allgemeinen mit Vervollständigungs- oder Automatisierungsfunktionen gefüllt. Vorausgesetzt, es handelt sich um einen Standardbenutzer, kann dieses Problem bis zu einem gewissen Grad gelöst werden. Später, wenn der Benutzer weiterhin mit dem System interagiert und die Sitzung weiter bereichert wird, können wir tatsächlich ein gewisses Maß an Benutzerfeedback erhalten und das Training wird nach und nach immer genauer. Im Hinblick auf die Gewährleistung der Stabilität können Sie den Systemeffekt im Grunde immer noch verbessern, solange Sie eine gute Kontrolle haben und verhindern, dass eine Benutzer-ID das Training dominiert. A10: Diese Arbeit besteht darin, das Bucketing direkt durchzuführen und dann die Ankunftswahrscheinlichkeit jedes Buckets zu verwenden, um gemeinsam die Dauer zu bewerten, anstatt nach dem Bucketing eine Regression durchzuführen. Es verwendet nur die Wahrscheinlichkeit des Bucketings plus den Wert des Bucketings, um eine Gesamtwahrscheinlichkeitsbewertung vorzunehmen. Die Regression nach dem Bucketing sollte tatsächlich nicht mehr unvoreingenommen sein, schließlich hat jeder Bucket immer noch sein eigenes Verteilungsmuster. A11: Dies ist eigentlich keine Multi-Ziel-Optimierung mehr. Der CTR-Indikator kann sogar direkt als Input zur Optimierung der CPR verwendet werden, da die CTR kein Optimierungsziel mehr ist. Dies ist jedoch möglicherweise nicht gut für Benutzer, da die CTR des Benutzers in größerem Maße die Präferenz und Bindung des Systems widerspiegelt. Allerdings können sich verschiedene Systeme unterscheiden, je nachdem, ob das Empfehlungssystem hauptsächlich auf den Verkauf von Produkten oder auf den Verkehr ausgerichtet ist. Da Kuaishou-Kurzvideos verkehrsbasiert sind, ist die CTR des Benutzers ein intuitiverer und wichtigerer Indikator, und die CVR ist nur ein Effekt nach der Verkehrsumleitung. 3. Fazit

IV. Fragen und Antworten: Welcher Verlust wird im Allgemeinen für das Dauersignal und das Interaktionssignal verwendet? Welche Indikatoren werden im Allgemeinen für die Offline-Bewertung von Interaktionszielen und Anzeigezielen verwendet?
A1: Der Dauerindikator ist eine typische Regressionsaufgabe. Wir haben jedoch auch festgestellt, dass die Schätzung der Dauer stark von der Länge des Videos selbst abhängt. Beispielsweise ist die Verteilung von Kurzvideos und Langvideos sehr unterschiedlich. Bei der Schätzung wird daher zuerst klassifiziert und dann eine Regression vorgenommen Erledigt. . Kürzlich haben wir auch einen Artikel in KDD veröffentlicht, in dem es um die Methode der Aufteilungsdauersignalschätzung mithilfe der Baummethode geht. Wenn Sie interessiert sind, können Sie darauf achten. Die allgemeine Bedeutung ist, dass beispielsweise bei einer Aufteilung der Dauer in lange Videos und kurze Videos das lange Video eine geschätzte Reichweite hat und das kurze Video eine geschätzte Reichweite für das kurze Video hat. Für eine detailliertere Klassifizierung können Sie auch die Baummethode verwenden. Lange Videos können in mittlere Videos und lange Videos unterteilt werden, und kurze Videos können auch in ultrakurze Videos und kurze Videos unterteilt werden. Natürlich gibt es auch Methoden, die zur Lösung der Dauerschätzung ausschließlich Klassifizierungsmethoden verwenden, und wir haben auch Tests durchgeführt. In Bezug auf den Gesamteffekt liegt es immer noch im Rahmen der Klassifizierung. Wenn wir erneut eine Regression durchführen, wird der Effekt etwas besser sein. Die Schätzung anderer interaktiver Indikatoren ähnelt im Allgemeinen den bestehenden Schätzmethoden. Bei der Offline-Auswertung sind AUC und GAUC im Allgemeinen relativ starke Signale, und derzeit sind diese beiden Signale relativ genau.
A2: Unser System berücksichtigt hauptsächlich Online-Indikatoren und offline verwendet es im Allgemeinen MAE und RMSE. Wir sehen aber auch, dass es Unterschiede zwischen Offline- und Online-Bewertungen gibt. Wenn es bei der Offline-Bewertung keine offensichtliche Verbesserung gibt, kann es sein, dass der entsprechende Verbesserungseffekt nicht eine bestimmte Bedeutung erreicht Der Unterschied wird nicht groß sein.
A3: Die Analyse der Gründe, warum Benutzer erneut posten, und einige Beobachtungen können zu besseren Ergebnissen führen. Wenn wir derzeit eine Weiterleitungsschätzung durchführen, ist der Unterschied zwischen der Schätzmethode unter unserem Link und anderen interaktiven Zielen nicht allzu groß. Es gibt eine allgemeinere Vorstellung, dass die Definition der Bezeichnung, insbesondere die Definition des negativen Rückkopplungssignals, einen großen Einfluss auf die Genauigkeit des Modelltrainings hat. Darüber hinaus wirkt sich die Optimierung der Datenquellen auch auf die Vorhersagegenauigkeit aus, sodass sich ein Großteil unserer Arbeit auch auf die Verzerrung konzentriert. Denn im Empfehlungsszenario sind viele geschätzte Indikatoren tatsächlich indirekte Signale, die sich im nächsten Schritt auf den Empfehlungseffekt auswirken. Daher ist die Optimierung von Indikatoren auf Basis von Empfehlungseffekten unser Anwendungsszenario.
A4: Bei der Multiobjektivfusion gibt es zu Beginn einige heuristische Methoden und einige manuelle Parameterausgleichsmethoden. Später begann ich nach und nach, die Parameteranpassungsmethode zu verwenden und versuchte auch, Parameter für das verstärkte Lernen anzupassen. Die aktuelle Erfahrung zeigt, dass die automatische Referenzanpassung besser ist als die manuelle Anpassung und ihre Obergrenze etwas höher liegt.
F5: Wenn die Online-Daten oder ein bestimmtes anzupassendes Ziel besonders spärlich sind und die Parameteranpassung auf Online-Daten basiert, dauert der Feedback-Zyklus oder das Beobachtungsvertrauen lange, sodass die Effizienz der Parameteranpassung relativ ist niedrig. Was ist in diesem Fall die Lösung?
Frage 6: Haben Sie andere Methoden des verstärkenden Lernens ausprobiert? Was sind die Vorteile der Schauspielerkritik?
F7: Welche Benutzerfunktionen werden im Allgemeinen verwendet, wenn die Kuaishou-Mehrzielfusion Methoden des verstärkenden Lernens verwendet? Wie kann dieses Problem gelöst werden?
F8: Es wird also auch die Benutzer-ID verwendet, aber es gibt noch kein Konvergenzproblem, oder?
Frage 9: In einigen Unternehmen sind die Daten zum Benutzerverhalten möglicherweise relativ klein. Wird es auch schwierig sein, die Benutzer-ID zu konvergieren? Wenn Sie auf ähnliche Probleme stoßen?
F10: Wie bereits erwähnt, wird bei der Modellierung von Dauerzielen zuerst die Klassifizierung und dann die Regression durchgeführt. Konkret: Wird die Dauer zuerst in Buckets unterteilt und dann erfolgt die Regression nach der Bucketing? Ist diese Methode eine unvoreingenommene Schätzung?
F11: Der Lehrer hat gerade eine Frage gestellt. Für die beiden Ziele a und b ist unser Hauptziel a, und die Anforderung für b ist, dass es nicht sinkt. In unserem tatsächlichen Szenario kann es ein Szenario geben, in dem a das Hauptziel ist und es keine Einschränkung für b gibt. Beispielsweise wird das CTR-Ziel zusammen mit dem CVR-Ziel optimiert, aber das Modell selbst ist ein CVR-Modell. Es ist uns egal, ob sich der CTR-Effekt verschlechtert. Wir möchten lediglich, dass die CTR den CVR unterstützt so viel wie möglich. Gibt es in einem solchen Szenario eine Lösung, wenn Sie sie für ein gemeinsames Training zusammenstellen möchten?
Das obige ist der detaillierte Inhalt vonKuaishou-Verstärkungslernen und Multitasking-Empfehlung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So verwenden Sie die Go-Sprache und Redis zur Implementierung eines Empfehlungssystems. Das Empfehlungssystem ist ein wichtiger Bestandteil der modernen Internetplattform. Es hilft Benutzern, interessante Informationen zu finden und zu erhalten. Die Go-Sprache und Redis sind zwei sehr beliebte Tools, die bei der Implementierung von Empfehlungssystemen eine wichtige Rolle spielen können. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache und Redis ein einfaches Empfehlungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. Redis ist eine Open-Source-In-Memory-Datenbank, die eine Speicherschnittstelle für Schlüssel-Wert-Paare bereitstellt und eine Vielzahl von Daten unterstützt
 In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Internet-Technologie werden Empfehlungssysteme als wichtige Technologie zur Informationsfilterung immer häufiger eingesetzt und beachtet. Bei der Implementierung von Empfehlungssystemalgorithmen ist Java als schnelle und zuverlässige Programmiersprache weit verbreitet. In diesem Artikel werden die in Java implementierten Empfehlungssystemalgorithmen und -anwendungen vorgestellt und der Schwerpunkt auf drei gängige Empfehlungssystemalgorithmen gelegt: benutzerbasierter kollaborativer Filteralgorithmus, artikelbasierter kollaborativer Filteralgorithmus und inhaltsbasierter Empfehlungsalgorithmus. Der benutzerbasierte kollaborative Filteralgorithmus basiert auf benutzerbasierter kollaborativer Filterung
 Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Mit der Popularität von Internetanwendungen ist die Microservice-Architektur zu einer beliebten Architekturmethode geworden. Unter anderem besteht der Schlüssel zur Microservice-Architektur darin, die Anwendung in verschiedene Dienste aufzuteilen und über RPC zu kommunizieren, um eine lose gekoppelte Service-Architektur zu erreichen. In diesem Artikel stellen wir vor, wie man mit go-micro ein Microservice-Empfehlungssystem basierend auf tatsächlichen Fällen erstellt. 1. Was ist ein Microservice-Empfehlungssystem? Ein Microservice-Empfehlungssystem ist ein Empfehlungssystem, das auf einer Microservice-Architektur basiert. Es integriert verschiedene Module in das Empfehlungssystem (z. B. Feature-Engineering, Klassifizierung).
 Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
1. Einführung in das Szenario Zunächst stellen wir das in diesem Artikel beschriebene Szenario vor – das Szenario „Gute Waren sind verfügbar“. Seine Position befindet sich im Vierquadratraster auf der Homepage von Taobao, die in eine One-Hop-Auswahlseite und eine Two-Hop-Akzeptanzseite unterteilt ist. Es gibt zwei Hauptformen von Akzeptanzseiten: eine ist die Bild- und Text-Akzeptanzseite und die andere ist die kurze Video-Akzeptanzseite. Das Ziel dieses Szenarios besteht hauptsächlich darin, den Benutzern zufriedenstellende Waren bereitzustellen und das Wachstum des GMV voranzutreiben, wodurch das Angebot an Experten weiter genutzt wird. 2. Was ist ein Beliebtheitsbias und warum befassen wir uns als nächstes mit dem Beliebtheitsbias? Was ist ein Beliebtheitsbias? Warum kommt es zu einem Beliebtheitsbias? 1. Was ist Popularitätsbias? Es gibt viele Pseudonyme, wie zum Beispiel Matthew-Effekt und Informationskokonraum. Intuitiv gesehen ist es ein Karneval hochexplosiver Produkte. Je beliebter das Produkt ist, desto einfacher ist es. Dies wird dazu führen
 Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Cloud-Computing-Technologie werden Cloud-Such- und Empfehlungssysteme immer beliebter. Als Antwort auf diese Nachfrage bietet die Go-Sprache ebenfalls eine gute Lösung. In der Go-Sprache können wir die Funktionen zur gleichzeitigen Hochgeschwindigkeitsverarbeitung und die umfangreichen Standardbibliotheken nutzen, um ein effizientes Cloud-Such- und Empfehlungssystem zu implementieren. Im Folgenden wird vorgestellt, wie die Go-Sprache ein solches System implementiert. 1. Suche in der Cloud Zunächst müssen wir die Vorgehensweise und die Prinzipien der Suche verstehen. Die Suchposition bezieht sich auf die Suchmaschinen-Matching-Seiten basierend auf den vom Benutzer eingegebenen Schlüsselwörtern.
 Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
1. Problemhintergrund: Die Notwendigkeit und Bedeutung der Kaltstartmodellierung. Als Content-Plattform stellt Cloud Music täglich eine große Menge neuer Inhalte online. Obwohl die Menge an neuen Inhalten auf der Cloud-Musikplattform im Vergleich zu anderen Plattformen, wie etwa Kurzvideos, relativ gering ist, kann die tatsächliche Menge die Vorstellungskraft eines jeden bei weitem übersteigen. Gleichzeitig unterscheiden sich Musikinhalte deutlich von kurzen Videos, Nachrichten und Produktempfehlungen. Der Lebenszyklus von Musik erstreckt sich über extrem lange Zeiträume, oft gemessen in Jahren. Manche Songs können explodieren, nachdem sie monate- oder jahrelang inaktiv waren, und klassische Songs können auch nach mehr als zehn Jahren noch eine starke Vitalität haben. Daher ist es für das Empfehlungssystem von Musikplattformen wichtiger, unpopuläre und qualitativ hochwertige Long-Tail-Inhalte zu entdecken und sie den richtigen Nutzern zu empfehlen, als andere Kategorien zu empfehlen.
 Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
1. Hintergrund der Ursache-Wirkungs-Korrektur 1. Abweichungen treten im Empfehlungssystem auf. Das Empfehlungsmodell wird durch das Sammeln von Daten trainiert, um Benutzern geeignete Elemente zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen. 2. Häufige Vorurteile Es gibt drei Haupttypen häufiger Vorurteile in Empfehlungsmarketingsystemen: Selektive Voreingenommenheit: Sie ist auf die Herkunft des Benutzers zurückzuführen
 Empfehlungssystem und kollaborative Filtertechnologie in PHP
May 11, 2023 pm 12:21 PM
Empfehlungssystem und kollaborative Filtertechnologie in PHP
May 11, 2023 pm 12:21 PM
Mit der rasanten Entwicklung des Internets gewinnen Empfehlungssysteme immer mehr an Bedeutung. Ein Empfehlungssystem ist ein Algorithmus, der zur Vorhersage von Elementen verwendet wird, die für einen Benutzer von Interesse sind. In Internetanwendungen können Empfehlungssysteme personalisierte Vorschläge und Empfehlungen bereitstellen und so die Benutzerzufriedenheit und Konversionsraten verbessern. PHP ist eine in der Webentwicklung weit verbreitete Programmiersprache. In diesem Artikel werden Empfehlungssysteme und kollaborative Filtertechnologie in PHP untersucht. Prinzip des Empfehlungssystems Das Empfehlungssystem basiert auf maschinellen Lernalgorithmen und Datenanalysen. Es analysiert und prognostiziert das historische Verhalten des Benutzers.
