
 Technologie-Peripheriegeräte
KI
Praktische Leistungsbewertung für LLM-Abfragen mit extrem langem Kontext
Technologie-Peripheriegeräte
KI
Praktische Leistungsbewertung für LLM-Abfragen mit extrem langem Kontext
Praktische Leistungsbewertung für LLM-Abfragen mit extrem langem Kontext

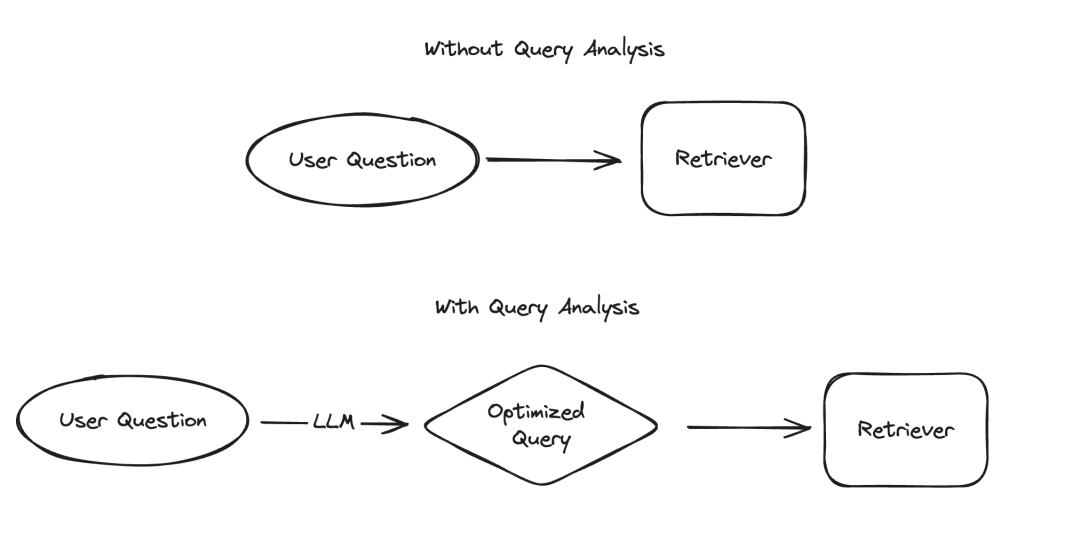
Bei der Anwendung großer Sprachmodelle (LLM) gibt es mehrere Szenarien, die eine strukturierte Darstellung von Daten erfordern, wobei Informationsextraktion und Abfrageanalyse zwei typische Beispiele sind. Wir haben kürzlich die Bedeutung der Informationsextraktion mit aktualisierter Dokumentation und einem speziellen Code-Repository hervorgehoben. Für die Abfrageanalyse haben wir auch die zugehörige Dokumentation aktualisiert. In diesen Szenarien können Datenfelder Zeichenfolgen, boolesche Werte, Ganzzahlen usw. enthalten. Unter diesen Typen ist der Umgang mit kategorialen Werten mit hoher Kardinalität (d. h. Aufzählungstypen) die größte Herausforderung.
 Bilder
Bilder
Die sogenannten „Gruppierungswerte mit hoher Kardinalität“ beziehen sich auf Werte, die aus begrenzten Optionen ausgewählt werden müssen. Diese Werte können nicht willkürlich angegeben werden, sondern müssen aus einem vordefinierten Satz stammen. In einer solchen Menge gibt es manchmal eine sehr große Anzahl gültiger Werte, die wir „Werte mit hoher Kardinalität“ nennen. Der Grund, warum der Umgang mit solchen Werten schwierig ist, liegt darin, dass LLM selbst nicht weiß, was diese realisierbaren Werte sind. Daher müssen wir LLM Informationen über diese realisierbaren Werte zur Verfügung stellen. Selbst wenn wir den Fall ignorieren, dass es nur wenige mögliche Werte gibt, können wir dieses Problem dennoch lösen, indem wir diese möglichen Werte im Hinweis explizit auflisten. Das Problem wird jedoch komplizierter, da es so viele mögliche Werte gibt.
Mit zunehmender Anzahl möglicher Werte steigt auch die Schwierigkeit, LLM-Werte auszuwählen. Wenn einerseits zu viele mögliche Werte vorhanden sind, passen diese möglicherweise nicht in das Kontextfenster des LLM. Selbst wenn andererseits alle möglichen Werte in den Kontext passen, führt die Einbeziehung aller Werte zu einer langsameren Verarbeitung, höheren Kosten und verringerten LLM-Argumentationsfähigkeiten beim Umgang mit großen Kontextmengen. „Mit zunehmender Anzahl möglicher Werte nimmt die Schwierigkeit bei der LLM-Auswahl von Werten zu.“ Wenn einerseits zu viele mögliche Werte vorhanden sind, passen diese möglicherweise nicht in das Kontextfenster des LLM. Selbst wenn andererseits alle möglichen Werte in den Kontext passen, führt die Einbeziehung aller Werte zu einer langsameren Verarbeitung, höheren Kosten und verringerten LLM-Argumentationsfähigkeiten beim Umgang mit großen Kontextmengen. ` (Hinweis: Der Originaltext scheint URL-codiert zu sein. Ich habe die Codierung korrigiert und den umgeschriebenen Text bereitgestellt.)
Kürzlich haben wir eine eingehende Untersuchung der Abfrageanalyse durchgeführt und bei der Überarbeitung der relevanten Dokumentation hinzugefügt Ein spezieller Abschnitt zum Umgang damit. Seiten mit hohen Kardinalitätswerten. In diesem Blog werden wir uns mit mehreren experimentellen Ansätzen befassen und deren Ergebnisse zum Leistungsbenchmark bereitstellen.
Eine Übersicht der Ergebnisse kann bei LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev eingesehen werden. Als nächstes stellen wir im Detail vor:
 Bilder
Bilder
Datensatzübersicht
Der detaillierte Datensatz kann hier eingesehen werden https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc -d7def170be76 /d?ref=blog.langchain.dev.
Um dieses Problem zu simulieren, gehen wir von einem Szenario aus: Wir möchten Bücher über Außerirdische von einem bestimmten Autor finden. In diesem Szenario handelt es sich beim Writer-Feld um eine kategoriale Variable mit hoher Kardinalität. Es gibt viele mögliche Werte, diese sollten jedoch bestimmte gültige Writer-Namen sein. Um dies zu testen, haben wir einen Datensatz erstellt, der Autorennamen und gängige Aliase enthält. „Harry Chase“ könnte beispielsweise ein Alias für „Harrison Chase“ sein. Wir wollen, dass intelligente Systeme mit dieser Art von Aliasing umgehen können. In diesem Datensatz haben wir einen Datensatz erstellt, der eine Liste der Namen und Aliase der Autoren enthält. Beachten Sie, dass 10.000 zufällige Namen nicht zu viel sind – bei Systemen auf Unternehmensebene müssen Sie möglicherweise mit Kardinalitäten in Millionenhöhe rechnen.
Anhand dieses Datensatzes stellen wir die Frage: „Was sind Harry Chases Bücher über Außerirdische?“ Unser Abfrageanalysesystem sollte in der Lage sein, diese Frage in ein strukturiertes Format zu analysieren, das zwei Felder enthält: Thema und Autor. In diesem Beispiel wäre die erwartete Ausgabe {"topic": "aliens", "author": "Harrison Chase"}. Wir gehen davon aus, dass das System erkennt, dass es keinen Autor namens Harry Chase gibt, der Benutzer meinte jedoch möglicherweise Harrison Chase.
Mit diesem Setup können wir den von uns erstellten Alias-Datensatz testen, um zu überprüfen, ob er korrekt mit echten Namen übereinstimmt. Gleichzeitig erfassen wir auch die Latenz und die Kosten der Abfrage. Diese Art von Abfrageanalysesystem wird normalerweise für die Suche verwendet, daher sind wir über diese beiden Indikatoren sehr besorgt. Aus diesem Grund beschränken wir auch alle Methoden auf nur einen LLM-Aufruf. Möglicherweise werden wir in einem zukünftigen Artikel Methoden mit mehreren LLM-Aufrufen vergleichen.
Als nächstes stellen wir verschiedene Methoden und deren Leistung vor.
 Bilder
Bilder
Die vollständigen Ergebnisse können in LangSmith eingesehen werden, und den Code zum Reproduzieren dieser Ergebnisse finden Sie hier.
Basistest
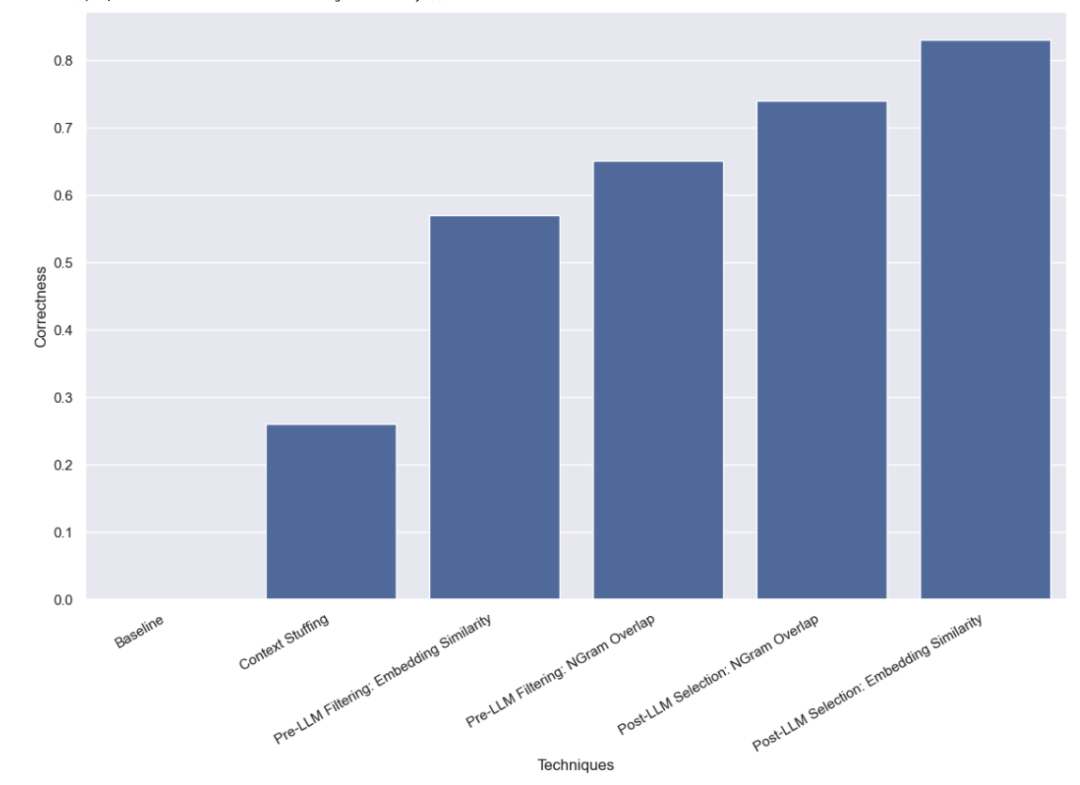
Zuerst führten wir einen Basistest für LLM durch, das heißt, wir forderten LLM direkt auf, eine Abfrageanalyse durchzuführen, ohne gültige Namensinformationen anzugeben. Wie erwartet wurde keine einzige Frage richtig beantwortet. Dies liegt daran, dass wir absichtlich einen Datensatz erstellt haben, der die Abfrage der Autoren nach Alias erfordert.
Kontextuelle Füllmethode
Bei dieser Methode geben wir alle 10.000 legalen Autorennamen in die Eingabeaufforderung ein und bitten LLM, sich bei der Abfrageanalyse daran zu erinnern, dass es sich um legale Autorennamen handelt. Einige Modelle (z. B. GPT-3.5) können diese Aufgabe aufgrund der Einschränkungen des Kontextfensters einfach nicht ausführen. Bei anderen Modellen mit längeren Kontextfenstern hatten sie ebenfalls Schwierigkeiten, den richtigen Namen genau auszuwählen. GPT-4 wählte nur in 26 % der Fälle den richtigen Namen. Der häufigste Fehler besteht darin, Namen zu extrahieren, sie aber nicht zu korrigieren. Diese Methode ist nicht nur langsam, sondern auch teuer: Sie dauert durchschnittlich 5 Sekunden und kostet insgesamt 8,44 US-Dollar.
Pre-LLM-Filtermethode
Die Methode, die wir als Nächstes getestet haben, besteht darin, die Liste möglicher Werte zu filtern, bevor sie an das LLM übergeben wird. Dies hat den Vorteil, dass nur eine Teilmenge der möglichen Namen an LLM übergeben wird, sodass LLM weitaus weniger Namen berücksichtigen muss, was hoffentlich eine schnellere, kostengünstigere und genauere Durchführung der Abfrageanalyse ermöglicht. Dies führt jedoch auch zu einem neuen potenziellen Fehlermodus: Was passiert, wenn die anfängliche Filterung schief geht?
Einbettungsbasierte Filterung
Die Filtermethode, die wir ursprünglich verwendet haben, war die Einbettungsmethode und wählte die 10 Namen aus, die der Abfrage am ähnlichsten sind. Beachten Sie, dass wir die gesamte Abfrage mit dem Namen vergleichen, was kein idealer Vergleich ist!
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 57 % der Fälle korrekt verarbeiten konnte. Diese Methode ist viel schneller und kostengünstiger als frühere Methoden und dauert durchschnittlich nur 0,76 Sekunden, wobei die Gesamtkosten nur 0,002 US-Dollar betragen.
Filtermethode basierend auf NGram-Ähnlichkeit
Die zweite Filtermethode, die wir verwenden, besteht darin, die 3-Gramm-Zeichenfolge aller gültigen Namen mit TF-IDF zu vektorisieren und die vektorisierten gültigen Namen mit der vektorisierten Kosinusähnlichkeit zwischen Benutzereingaben zu verwenden wird verwendet, um die relevantesten 10 gültigen Namen auszuwählen, die den Modelleingabeaufforderungen hinzugefügt werden sollen. Beachten Sie außerdem, dass wir die gesamte Abfrage mit dem Namen vergleichen, was kein idealer Vergleich ist!
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 65 % der Fälle korrekt bearbeiten konnte. Diese Methode ist außerdem viel schneller und kostengünstiger als frühere Methoden, da sie durchschnittlich nur 0,57 Sekunden in Anspruch nimmt und die Gesamtkosten nur 0,002 US-Dollar betragen.
LLM-Nachauswahlmethode
Die letzte von uns getestete Methode bestand darin, zu versuchen, etwaige Fehler zu korrigieren, nachdem LLM die vorläufige Abfrageanalyse abgeschlossen hatte. Wir haben zunächst eine Abfrageanalyse für Benutzereingaben durchgeführt, ohne in der Eingabeaufforderung Informationen zu gültigen Autorennamen anzugeben. Dies ist derselbe Basistest, den wir ursprünglich durchgeführt haben. Anschließend führten wir einen weiteren Schritt durch, bei dem wir die Namen im Feld „Autor“ verwendeten und den ähnlichsten gültigen Namen suchten.
Auswahlmethode basierend auf Einbettungsähnlichkeit
Zuerst führten wir eine Ähnlichkeitsprüfung mit der Einbettungsmethode durch.
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 83 % der Fälle korrekt bearbeiten konnte. Diese Methode ist viel schneller und kostengünstiger als frühere Methoden, sie dauert durchschnittlich nur 0,66 Sekunden und die Gesamtkosten betragen nur 0,001 $.
NGramm-Ähnlichkeitsbasierte Auswahlmethode
Abschließend versuchen wir, einen 3-Gramm-Vektorisierer zur Ähnlichkeitsprüfung zu verwenden.
Wir haben festgestellt, dass GPT-3.5 mit diesem Ansatz 74 % der Fälle korrekt bearbeiten konnte. Diese Methode ist außerdem viel schneller und kostengünstiger als frühere Methoden, da sie durchschnittlich nur 0,48 Sekunden in Anspruch nimmt und die Gesamtkosten nur 0,001 US-Dollar betragen.
Fazit
Wir haben mehrere Benchmarks zu Abfrageanalysemethoden für den Umgang mit kategorialen Werten mit hoher Kardinalität durchgeführt. Wir haben uns darauf beschränkt, nur einen LLM-Aufruf durchzuführen, um reale Latenzbeschränkungen zu simulieren. Wir haben festgestellt, dass die Einbettung ähnlichkeitsbasierter Auswahlmethoden nach der Verwendung von LLM am besten funktioniert.
Es gibt andere Methoden, die es wert sind, weiter getestet zu werden. Insbesondere gibt es viele verschiedene Möglichkeiten, den ähnlichsten kategorialen Wert vor oder nach dem LLM-Aufruf zu finden. Darüber hinaus ist die Kategoriebasis in diesem Datensatz nicht so hoch wie in vielen Unternehmenssystemen. Dieser Datensatz verfügt über etwa 10.000 Werte, während viele reale Systeme möglicherweise Kardinalitäten in Millionenhöhe verarbeiten müssen. Daher wäre ein Benchmarking anhand von Daten mit höherer Kardinalität sehr wertvoll.
Das obige ist der detaillierte Inhalt vonPraktische Leistungsbewertung für LLM-Abfragen mit extrem langem Kontext. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
Caltech-Chinesen nutzen KI, um mathematische Beweise zu untergraben! Beschleunigen Sie 5-mal schockiert Tao Zhexuan, 80 % der mathematischen Schritte sind vollständig automatisiert
Apr 23, 2024 pm 03:01 PM
LeanCopilot, dieses formale Mathematikwerkzeug, das von vielen Mathematikern wie Terence Tao gelobt wurde, hat sich erneut weiterentwickelt? Soeben gab Caltech-Professorin Anima Anandkumar bekannt, dass das Team eine erweiterte Version des LeanCopilot-Papiers veröffentlicht und die Codebasis aktualisiert hat. Adresse des Bildpapiers: https://arxiv.org/pdf/2404.12534.pdf Die neuesten Experimente zeigen, dass dieses Copilot-Tool mehr als 80 % der mathematischen Beweisschritte automatisieren kann! Dieser Rekord ist 2,3-mal besser als der vorherige Basiswert von Aesop. Und wie zuvor ist es Open Source unter der MIT-Lizenz. Auf dem Bild ist er Song Peiyang, ein chinesischer Junge
 Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud bringt den tragbaren NotePin AI-Recorder für 169 US-Dollar auf den Markt
Aug 29, 2024 pm 02:37 PM
Plaud, das Unternehmen hinter dem Plaud Note AI Voice Recorder (erhältlich bei Amazon für 159 US-Dollar), hat ein neues Produkt angekündigt. Das als NotePin bezeichnete Gerät wird als KI-Speicherkapsel beschrieben und ist wie der Humane AI Pin tragbar. Der NotePin ist
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) erfreut sich zunehmender Beliebtheit und hat sich zu einer leistungsstarken Ergänzung zu herkömmlichen Vektorsuchmethoden entwickelt. Diese Methode nutzt die strukturellen Merkmale von Graphdatenbanken, um Daten in Form von Knoten und Beziehungen zu organisieren und dadurch die Tiefe und kontextbezogene Relevanz der abgerufenen Informationen zu verbessern. Diagramme haben einen natürlichen Vorteil bei der Darstellung und Speicherung vielfältiger und miteinander verbundener Informationen und können problemlos komplexe Beziehungen und Eigenschaften zwischen verschiedenen Datentypen erfassen. Vektordatenbanken können diese Art von strukturierten Informationen nicht verarbeiten und konzentrieren sich mehr auf die Verarbeitung unstrukturierter Daten, die durch hochdimensionale Vektoren dargestellt werden. In RAG-Anwendungen können wir durch die Kombination strukturierter Diagrammdaten und unstrukturierter Textvektorsuche gleichzeitig die Vorteile beider nutzen, worauf in diesem Artikel eingegangen wird. Struktur
 Google AI kündigt Gemini 1.5 Pro und Gemma 2 für Entwickler an
Jul 01, 2024 am 07:22 AM
Google AI kündigt Gemini 1.5 Pro und Gemma 2 für Entwickler an
Jul 01, 2024 am 07:22 AM
Google AI hat damit begonnen, Entwicklern Zugriff auf erweiterte Kontextfenster und kostensparende Funktionen zu bieten, beginnend mit dem großen Sprachmodell Gemini 1.5 Pro (LLM). Bisher über eine Warteliste verfügbar, das vollständige 2-Millionen-Token-Kontextfenster
 PHP-Array-Schlüsselwertumdrehen: Vergleichende Leistungsanalyse verschiedener Methoden
May 03, 2024 pm 09:03 PM
PHP-Array-Schlüsselwertumdrehen: Vergleichende Leistungsanalyse verschiedener Methoden
May 03, 2024 pm 09:03 PM
Der Leistungsvergleich der PHP-Methoden zum Umdrehen von Array-Schlüsselwerten zeigt, dass die Funktion array_flip() in großen Arrays (mehr als 1 Million Elemente) eine bessere Leistung als die for-Schleife erbringt und weniger Zeit benötigt. Die for-Schleifenmethode zum manuellen Umdrehen von Schlüsselwerten dauert relativ lange.
 Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks: REST-API-Anforderungsverarbeitung: Vert.x ist am besten, mit einer Anforderungsrate von 2-mal SpringBoot und 3-mal Dropwizard. Datenbankabfrage: HibernateORM von SpringBoot ist besser als ORM von Vert.x und Dropwizard. Caching-Vorgänge: Der Hazelcast-Client von Vert.x ist den Caching-Mechanismen von SpringBoot und Dropwizard überlegen. Geeignetes Framework: Wählen Sie entsprechend den Anwendungsanforderungen. Vert.x eignet sich für leistungsstarke Webdienste, SpringBoot eignet sich für datenintensive Anwendungen und Dropwizard eignet sich für Microservice-Architekturen.
