

适宜做简单搜索的MySQL数据库全文索引_MySQL

全文索引在 MySQL 中是一个 FULLTEXT 类型索引。FULLTEXT 索引用于 MyISAM 表,可以在 CREATE TABLE 时或之后使用 ALTER TABLE 或 CREATE INDEX 在 CHAR、VARCHAR 或 TEXT 列上创建。对于大的数据库,将数据装载到一个没有 FULLTEXT 索引的表中,然后再使用 ALTER TABLE (或 CREATE INDEX) 创建索引,这将是非常快的。将数据装载到一个已经有 FULLTEXT 索引的表中,将是非常慢的。
全文搜索通过 MATCH() 函数完成:
mysql> CREATE TABLE articles (
-> id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> title VARCHAR(200),
-> body TEXT,
-> FULLTEXT (title,body)
-> );
Query OK, 0 rows affected (0.00 sec)
mysql> INSERT INTO articles VALUES
-> (NULL,'MySQL Tutorial', 'DBMS stands for DataBase ...'),
-> (NULL,'How To Use MySQL Efficiently', 'After you went through a ...'),
-> (NULL,'Optimising MySQL','In this tutorial we will show ...'),
-> (NULL,'1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
-> (NULL,'MySQL vs. YourSQL', 'In the following database comparison ...'),
-> (NULL,'MySQL Security', 'When configured properly, MySQL ...');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM articles
-> WHERE MATCH (title,body) AGAINST ('database');
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
+----+-------------------+------------------------------------------+
2 rows in set (0.00 sec)
函数 MATCH() 对照一个文本集(包含在一个 FULLTEXT 索引中的一个或多个列的列集)执行一个自然语言搜索一个字符串。搜索字符串做为 AGAINST() 的参数被给定。搜索以忽略字母大小写的方式执行。对于表中的每个记录行,MATCH() 返回一个相关性值。即,在搜索字符串与记录行在 MATCH() 列表中指定的列的文本之间的相似性尺度。
当 MATCH() 被使用在一个 WHERE 子句中时 (参看上面的例子),返回的记录行被自动地以相关性从高到底的次序排序。相关性值是非负的浮点数字。零相关性意味着不相似。相关性的计算是基于:词在记录行中的数目、在行中唯一词的数目、在集中词的全部数目和包含一个特殊词的文档(记录行)的数目。
它也可以执行一个逻辑模式的搜索。这在下面的章节中被描述。
前面的例子是函数 MATCH() 使用上的一些基本说明。记录行以相似性递减的顺序返回。 下一个示例显示如何检索一个明确的相似性值。如果即没有 WHERE 也没有 ORDER BY 子句,返回行是不排序的。
mysql> SELECT id,MATCH (title,body) AGAINST ('Tutorial') FROM articles;
+----+-----------------------------------------+
| id | MATCH (title,body) AGAINST ('Tutorial') |
+----+-----------------------------------------+
| 1 | 0.64840710366884 |
| 2 | 0 |
| 3 | 0.66266459031789 |
| 4 | 0 |
| 5 | 0 |
| 6 | 0 |
+----+-----------------------------------------+
6 rows in set (0.00 sec)
下面的示例更复杂一点。查询返回相似性并依然以相似度递减的次序返回记录行。为了完成这个结果,你应该指定 MATCH() 两次。这不会引起附加的开销,因为 MySQL 优化器会注意到两次同样的 MATCH() 调用,并只调用一次全文搜索代码。
mysql> SELECT id, body, MATCH (title,body) AGAINST
-> ('Security implications of running MySQL as root') AS score
-> FROM articles WHERE MATCH (title,body) AGAINST
-> ('Security implications of running MySQL as root');
+----+-------------------------------------+-----------------+
| id | body | score |
+----+-------------------------------------+-----------------+
| 4 | 1. Never run mysqld as root. 2. ... | 1.5055546709332 |
| 6 | When configured properly, MySQL ... | 1.31140957288 |
+----+-------------------------------------+-----------------+
2 rows in set (0.00 sec)
MySQL 使用一个非常简单的剖析器来将文本分隔成词。一个“词”是由文字、数据、“'” 和 “_” 组成的任何字符序列。任何在 stopword 列表上出现的,或太短的(3 个字符或更少的)的 “word” 将被忽略。
在集和查询中的每个合适的词根据其在集与查询中的重要性衡量。这样,一个出现在多个文档中的词将有较低的权重(可能甚至有一个零权重),因为在这个特定的集中,它有较低的语义值。否则,如果词是较少的,它将得到一个较高的权重。然后,词的权重将被结合用于计算记录行的相似性。
这样一个技术工作可很好地工作与大的集(实际上,它会小心地与之谐调)。 对于非常小的表,词分类不足以充份地反应它们的语义值,有时这个模式可能产生奇怪的结果。
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('MySQL');
Empty set (0.00 sec)
在上面的例子中,搜索词 MySQL 却没有得到任何结果,因为这个词在超过一半的记录行中出现。同样的,它被有效地处理为一个 stopword (即,一个零语义值的词)。这是最理想的行为 -- 一个自然语言的查询不应该从一个 1GB 的表中返回每个次行(second row)。
匹配表中一半记录行的词很少可能找到相关文档。实际上,它可能会发现许多不相关的文档。我们都知道,当我们在互联网上通过搜索引擎试图搜索某些东西时,这会经常发生。因为这个原因,在这个特殊的数据集中,这样的行被设置一个低的语义值。
到 4.0.1 时,MySQL 也可以使用 IN BOOLEAN MODE 修饰语来执行一个逻辑全文搜索。
mysql> SELECT * FROM articles WHERE MATCH (title,body)
-> AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);
+----+------------------------------+-------------------------------------+
| id | title | body |
+----+------------------------------+-------------------------------------+
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
| 2 | How To Use MySQL Efficiently | After you went through a ... |
| 3 | Optimising MySQL | In this tutorial we will show ... |
| 4 | 1001 MySQL Tricks | 1. Never run mysqld as root. 2. ... |
| 6 | MySQL Security | When configured properly, MySQL ... |
+----+------------------------------+-------------------------------------+
12 下一页

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Welche Software ist Bonjour und kann sie deinstalliert werden?
Feb 20, 2024 am 09:33 AM
Welche Software ist Bonjour und kann sie deinstalliert werden?
Feb 20, 2024 am 09:33 AM
Titel: Entdecken Sie die Bonjour-Software und wie Sie sie deinstallieren. Zusammenfassung: In diesem Artikel werden die Funktionen, der Nutzungsumfang und die Deinstallation der Bonjour-Software vorgestellt. Gleichzeitig wird auch erläutert, wie Bonjour durch andere Tools ersetzt werden kann, um den Anforderungen der Benutzer gerecht zu werden. Einleitung: Bonjour ist eine gängige Software im Bereich der Computer- und Netzwerktechnik. Obwohl dies für einige Benutzer möglicherweise ungewohnt ist, kann es in bestimmten Situationen sehr nützlich sein. Wenn Sie Bonjour-Software installiert haben, diese nun aber deinstallieren möchten, dann
 Mar 18, 2024 pm 02:58 PM
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark ist ein kleines HDD-Benchmark-Tool für Festplatten, das schnell sequentielle und zufällige Lese-/Schreibgeschwindigkeiten misst. Lassen Sie sich als Nächstes vom Redakteur CrystalDiskMark und die Verwendung von CrystalDiskMark vorstellen ). Zufällige I/O-Leistung. Es ist eine kostenlose Windows-Anwendung und bietet eine benutzerfreundliche Oberfläche und verschiedene Testmodi zur Bewertung verschiedener Aspekte der Festplattenleistung. Sie wird häufig in Hardware-Reviews verwendet
 Was tun, wenn WPS Office die PPT-Datei nicht öffnen kann - Was tun, wenn WPS Office die PPT-Datei nicht öffnen kann?
Mar 04, 2024 am 11:40 AM
Was tun, wenn WPS Office die PPT-Datei nicht öffnen kann - Was tun, wenn WPS Office die PPT-Datei nicht öffnen kann?
Mar 04, 2024 am 11:40 AM
Kürzlich haben mich viele Freunde gefragt, was zu tun ist, wenn WPSOffice keine PPT-Dateien öffnen kann. Lassen Sie uns als Nächstes lernen, wie wir das Problem lösen können, dass WPSOffice keine PPT-Dateien öffnen kann. 1. Öffnen Sie zunächst WPSOffice und rufen Sie die Homepage auf, wie in der Abbildung unten gezeigt. 2. Geben Sie dann das Schlüsselwort „Dokumentreparatur“ in die Suchleiste oben ein und klicken Sie dann, um das Dokumentreparaturtool zu öffnen, wie in der Abbildung unten gezeigt. 3. Importieren Sie dann die PPT-Datei zur Reparatur, wie in der Abbildung unten gezeigt.
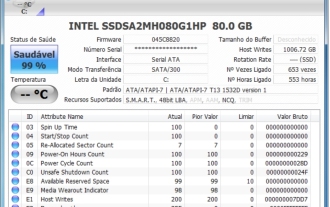 Mar 18, 2024 pm 04:50 PM
Mar 18, 2024 pm 04:50 PM
CrystalDiskInfo ist eine Software zur Überprüfung von Computerhardwaregeräten. Mit dieser Software können wir unsere eigene Computerhardware überprüfen, z. B. Lesegeschwindigkeit, Übertragungsmodus, Schnittstelle usw.! Wie verwende ich CrystalDiskInfo zusätzlich zu diesen Funktionen und was genau ist CrystalDiskInfo? 1. Der Ursprung von CrystalDiskInfo Als eine der drei Hauptkomponenten eines Computerhosts ist ein Solid-State-Laufwerk das Speichermedium eines Computers und für die Datenspeicherung des Computers verantwortlich. Ein gutes Solid-State-Laufwerk kann das Lesen von Dateien beschleunigen beeinflussen das Verbrauchererlebnis. Wenn Verbraucher neue Geräte erhalten, können sie dazu Software von Drittanbietern oder andere SSDs verwenden
 So legen Sie die Tastaturschrittweite in Adobe Illustrator CS6 fest - So legen Sie die Tastaturschrittweite in Adobe Illustrator CS6 fest
Mar 04, 2024 pm 06:04 PM
So legen Sie die Tastaturschrittweite in Adobe Illustrator CS6 fest - So legen Sie die Tastaturschrittweite in Adobe Illustrator CS6 fest
Mar 04, 2024 pm 06:04 PM
Viele Benutzer verwenden die Adobe Illustrator CS6-Software in ihren Büros. Wissen Sie also, wie Sie die Tastaturinkremente in Adobe Illustrator CS6 einstellen? Dann zeigt Ihnen der Editor, wie Sie die Tastaturinkremente in Adobe Illustrator CS6 festlegen können Werfen Sie einen Blick unten. Schritt 1: Starten Sie die Adobe Illustrator CS6-Software, wie in der Abbildung unten gezeigt. Schritt 2: Klicken Sie in der Menüleiste nacheinander auf den Befehl [Bearbeiten] → [Einstellungen] → [Allgemein]. Schritt 3: Das Dialogfeld [Tastaturschrittweite] wird angezeigt. Geben Sie die erforderliche Zahl in das Textfeld [Tastaturschrittweite] ein und klicken Sie abschließend auf die Schaltfläche [OK]. Schritt 4: Verwenden Sie die Tastenkombination [Strg]
 Welche Art von Software ist Bonjour?
Feb 22, 2024 pm 08:39 PM
Welche Art von Software ist Bonjour?
Feb 22, 2024 pm 08:39 PM
Bonjour ist ein von Apple eingeführtes Netzwerkprotokoll und eine Software zum Erkennen und Konfigurieren von Netzwerkdiensten in einem lokalen Netzwerk. Seine Hauptaufgabe besteht darin, Geräte, die im selben Netzwerk verbunden sind, automatisch zu erkennen und zwischen ihnen zu kommunizieren. Bonjour wurde erstmals 2002 in der MacOSX10.2-Version eingeführt und ist jetzt standardmäßig im Apple-Betriebssystem installiert und aktiviert. Seitdem hat Apple die Bonjour-Technologie für andere Hersteller geöffnet, sodass viele andere Betriebssysteme und Geräte Bonjour unterstützen können.
 So entfernen Sie Viren vollständig von Mobiltelefonen. Empfohlene Methoden zum Umgang mit Viren in Mobiltelefonen
Feb 29, 2024 am 10:52 AM
So entfernen Sie Viren vollständig von Mobiltelefonen. Empfohlene Methoden zum Umgang mit Viren in Mobiltelefonen
Feb 29, 2024 am 10:52 AM
Nachdem ein Mobiltelefon mit einem bestimmten Trojaner infiziert wurde, kann es von einer Antivirensoftware nicht erkannt und abgetötet werden. Dieses Prinzip ähnelt einem Computer, der mit einem hartnäckigen Virus infiziert ist. Der Virus kann nur durch Formatieren des Laufwerks C vollständig entfernt werden Nach der Neuinstallation des Systems erkläre ich Ihnen, wie Sie den Virus vollständig entfernen, nachdem das Mobiltelefon mit einem hartnäckigen Virus infiziert ist. Methode 1: Öffnen Sie das Telefon und klicken Sie auf „Einstellungen“ – „Andere Einstellungen“ – „Telefon wiederherstellen“, um das Telefon auf die Werkseinstellungen zurückzusetzen. Hinweis: Bevor Sie die Werkseinstellungen wiederherstellen, müssen Sie die wichtigen Daten im Telefon sichern zu denen des Computers. „Es ist dasselbe wie das Formatieren und Neuinstallieren des Systems.“ Methode 2 (1) Schalten Sie zuerst das Telefon aus und halten Sie dann die „Einschalttaste“ gedrückt „ + „Lautstärke +-Taste oder Lautstärke –-Taste“ am Telefon gleichzeitig drücken.
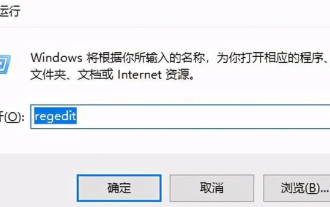 Wie kann ein Versuch, eine inkompatible Software mit Edge zu laden, behoben werden?
Mar 15, 2024 pm 01:34 PM
Wie kann ein Versuch, eine inkompatible Software mit Edge zu laden, behoben werden?
Mar 15, 2024 pm 01:34 PM
Wenn wir den Edge-Browser verwenden, wird manchmal versucht, inkompatible Software gleichzeitig zu laden. Was ist also los? Lassen Sie diese Website den Benutzern sorgfältig vorstellen, wie sie das Problem lösen können, das beim Versuch entsteht, inkompatible Software mit Edge zu laden. So lösen Sie das Problem, eine inkompatible Software mit Edge zu laden. Lösung 1: Suchen Sie im Startmenü nach IE und greifen Sie direkt über IE darauf zu. Lösung 2: Hinweis: Das Ändern der Registrierung kann zu Systemfehlern führen. Gehen Sie daher vorsichtig vor. Ändern Sie die Registrierungsparameter. 1. Geben Sie während des Betriebs regedit ein. 2. Suchen Sie den Pfad\HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Micros
