

Grouped Query Attention ist eine Multi-Query-Attention-Methode in großen Sprachmodellen. Ihr Ziel ist es, die Qualität von MHA zu erreichen und gleichzeitig die Geschwindigkeit von MQA beizubehalten. Grouped Query Attention gruppiert Abfragen so, dass Abfragen innerhalb jeder Gruppe das gleiche Aufmerksamkeitsgewicht haben, was dazu beiträgt, die Rechenkomplexität zu reduzieren und die Inferenzgeschwindigkeit zu erhöhen.
In diesem Artikel erklären wir die Idee der GQA und wie man sie in Code übersetzt.
GQA wurde im Artikel „GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints“ vorgeschlagen. Es handelt sich um eine ziemlich einfache und saubere Idee, die auf der Aufmerksamkeit mehrerer Köpfe basiert.
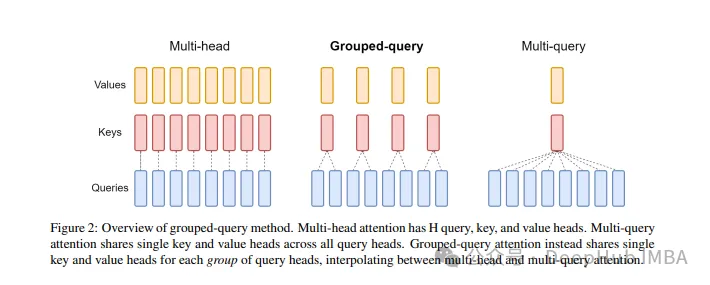
Der standardmäßige Multi-Head Attention Layer (MHA) besteht aus H-Abfrageheadern, Schlüsselheadern und Wertheadern. Jeder Kopf hat D-Maße. Der Pytorch-Code lautet wie folgt:
from torch.nn.functional import scaled_dot_product_attention # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 8, 64) value = torch.randn(1, 256, 8, 64) output = scaled_dot_product_attention(query, key, value) print(output.shape) # torch.Size([1, 256, 8, 64])
Für jeden Abfrageheader gibt es einen entsprechenden Schlüssel. Dieser Prozess ist in der folgenden Abbildung dargestellt:
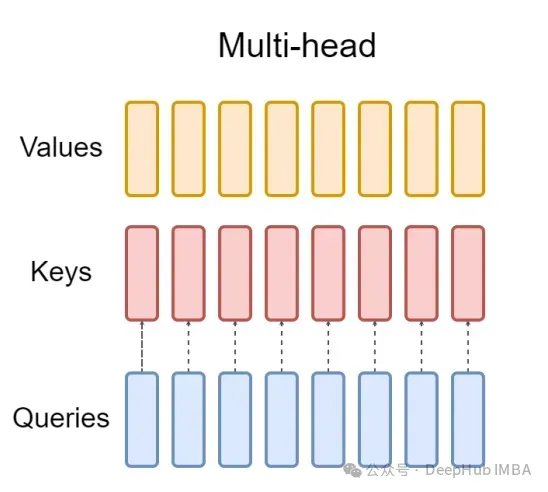
Und GQA unterteilt den Abfrageheader in G-Gruppen, jede Gruppe teilt einen Schlüssel und einen Wert. Es kann wie folgt ausgedrückt werden:
Anhand visueller Ausdrücke können Sie das Funktionsprinzip der GQA klar verstehen, genau wie wir oben gesagt haben. GQA ist eine ziemlich einfache und saubere Idee.
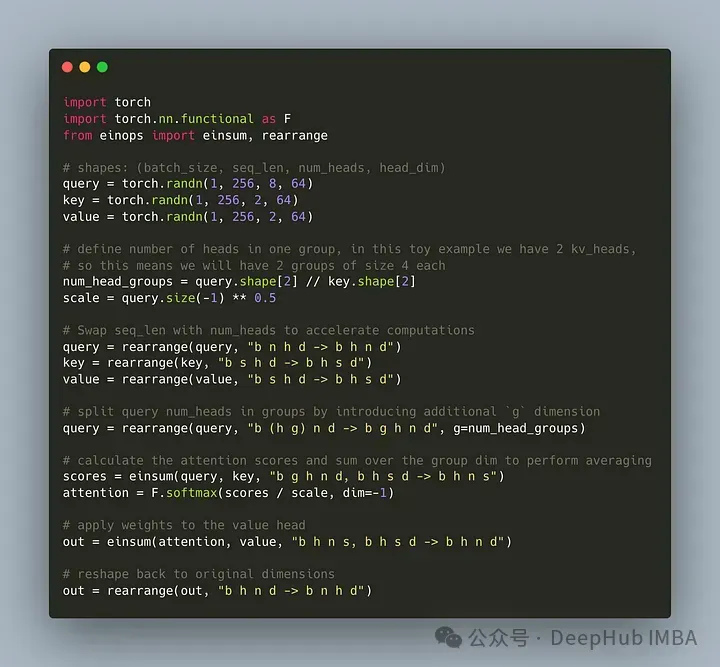
Schreiben wir den Code, um den Abfrageheader in G-Gruppen zu unterteilen, wobei jede Gruppe einen Schlüssel und einen Wert teilt. Wir können die einops-Bibliothek verwenden, um komplexe Operationen an Tensoren effizient durchzuführen.
Zuerst definieren Sie die Abfrage, Schlüssel und Werte. Legen Sie dann die Anzahl der Aufmerksamkeitsköpfe fest. Die Anzahl ist beliebig, es muss jedoch sichergestellt sein, dass num_heads_for_query % num_heads_for_key = 0 ist, was bedeutet, dass sie teilbar sein muss. Unsere Definition lautet wie folgt:
import torch # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 2, 64) value = torch.randn(1, 256, 2, 64) num_head_groups = query.shape[2] // key.shape[2] print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
Um die Effizienz zu verbessern, tauschen Sie die Dimensionen seq_len und num_heads aus. Einops können einfach wie folgt vervollständigt werden:
from einops import rearrange query = rearrange(query, "b n h d -> b h n d") key = rearrange(key, "b s h d -> b h s d") value = rearrange(value, "b s h d -> b h s d")
Dann müssen wir „Gruppierung“ einführen das Abfragematrixkonzept.
from einops import rearrange query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups) print(query.shape) # torch.Size([1, 4, 2, 256, 64])
Mit dem obigen Code formen wir 2D in 2D um: Für den von uns definierten Tensor wird die ursprüngliche Dimension 8 (die Anzahl der Köpfe in der Abfrage) jetzt in zwei Gruppen aufgeteilt (um mit den Köpfen in den Schlüsseln übereinzustimmen). und Werteanzahl), jede Gruppengröße beträgt 4.
Der letzte und schwierigste Teil ist die Berechnung des Aufmerksamkeitswerts. Tatsächlich kann dies jedoch in einer Zeile durch die Insum-Operation erfolgen. Der
from einops import einsum, rearrange # g stands for the number of groups # h stands for the hidden dim # n and s are equal and stands for sequence length scores = einsum(query, key, "b g h n d, b h s d -> b h n s") print(scores.shape) # torch.Size([1, 2, 256, 256])
Scores-Tensor hat die gleiche Form wie der Wertetensor oben. Mal sehen, wie es funktioniert
einsum erledigt zwei Dinge für uns:
1 Eine Abfrage und Matrixmultiplikation von Schlüsseln. In unserem Fall sind die Formen dieser Tensoren (1,4,2,256,64) und (1,2,256,64), sodass die Matrixmultiplikation entlang der letzten beiden Dimensionen (1,4,2,256,256) ergibt.
2. Summieren Sie die Elemente in der zweiten Dimension (Dimension g) – wenn die Dimension in der angegebenen Ausgabeform weggelassen wird, schließt einsum diese Arbeit automatisch ab und diese Summierung wird verwendet, um Schlüssel und die Anzahl der Köpfe abzugleichen der Wert.
Beachten Sie abschließend die Standardmultiplikation von Brüchen und Werten:
import torch.nn.functional as F scale = query.size(-1) ** 0.5 attention = F.softmax(similarity / scale, dim=-1) # here we do just a standard matrix multiplication out = einsum(attention, value, "b h n s, b h s d -> b h n d") # finally, just reshape back to the (batch_size, seq_len, num_kv_heads, hidden_dim) out = rearrange(out, "b h n d -> b n h d") print(out.shape) # torch.Size([1, 256, 2, 64])
Die einfachste GQA-Implementierung ist jetzt abgeschlossen und erfordert weniger als 16 Zeilen Python-Code:
Abschließend noch eine kurze Erwähnung von MQA: Multi-Query Attention (MQA) ist eine weitere beliebte Methode zur Vereinfachung von MHA. Alle Abfragen verwenden dieselben Schlüssel und Werte. Das schematische Diagramm sieht wie folgt aus:
Wie Sie sehen, können sowohl MQA als auch MHA aus GQA abgeleitet werden. GQA mit einem einzelnen Schlüssel und Wert entspricht MQA, während GQA mit Gruppen, die der Anzahl der Header entsprechen, MHA entspricht.
GQA ist ein guter Kompromiss zwischen bester Leistung (MQA) und bester Modellqualität (MHA).
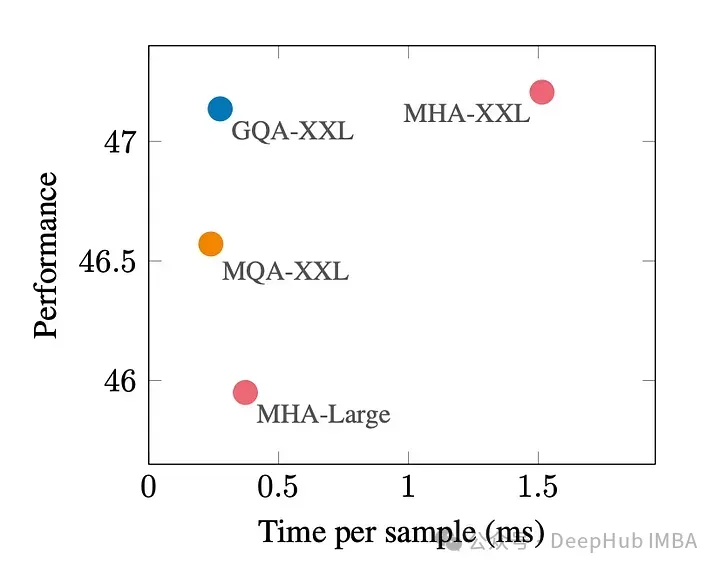
Die folgende Abbildung zeigt, dass Sie mit GQA fast die gleiche Modellqualität wie mit MHA erzielen und gleichzeitig die Verarbeitungszeit um das Dreifache verlängern können, wodurch Sie die Leistung von MQA erreichen. Dies kann für Hochlastsysteme unerlässlich sein.
Es gibt keine offizielle Implementierung von GQA in Pytorch. Also habe ich eine bessere inoffizielle Implementierung gefunden. Wenn Sie interessiert sind, können Sie es versuchen:
https://www.php.cn/link/5b52e27a9d5bf294f5b593c4c071500e
GQA-Papier:
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der GQA, des in großen Modellen häufig verwendeten Aufmerksamkeitsmechanismus und der Pytorch-Codeimplementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



