

Generative KI ist eine Technologie der menschlichen künstlichen Intelligenz, die verschiedene Arten von Inhalten generieren kann, darunter Text, Bilder, Audio und synthetische Daten. Was ist also künstliche Intelligenz? Was ist der Unterschied zwischen künstlicher Intelligenz und maschinellem Lernen? Was sind die technischen Merkmale?
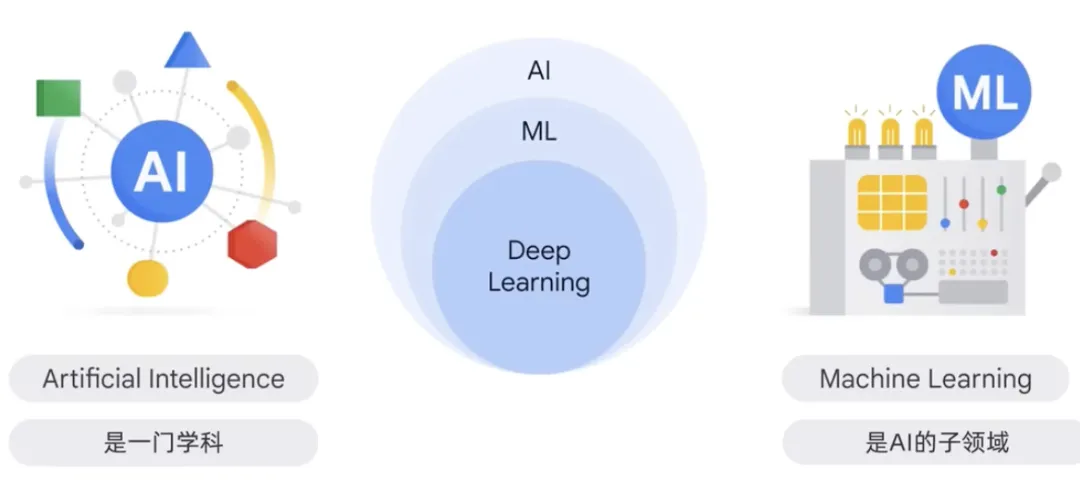
Künstliche Intelligenz ist eine Disziplin, ein Zweig der Informatik, der die Entwicklung intelligenter Agenten untersucht. Hierbei handelt es sich um Systeme, in denen intelligente Agenten autonom denken, lernen und handeln können. Das Studium intelligenter Agenten ist das Studium von Systemen, die autonom denken, lernen und handeln können.
Künstliche Intelligenz beschäftigt sich mit den Theorien und Methoden zum Bau von Maschinen, die wie Menschen denken und handeln. Innerhalb dieser Disziplin ist maschinelles Lernen ein Bereich der künstlichen Intelligenz. Es handelt sich um ein Programm oder System, das ein Modell auf der Grundlage von Eingabedaten trainiert. Das trainierte Modell kann aus neuen oder unbekannten Daten nützliche Vorhersagen treffen, die aus den einheitlichen Daten abgeleitet werden können, auf denen das Modell trainiert wurde. Durch das Training eines Modells anhand einheitlicher Daten aus seinem eigenen Trainingsmodell können diese Daten zur Vorhersage von Daten verwendet werden, die das Modell nicht gesehen hat. Diese Daten stammen aus den einheitlichen Daten, die zum Trainieren des Modells selbst verwendet werden, sodass nützliche Vorhersagen getroffen werden können. Diese Methode wird häufig bei Problemen in den Bereichen Bild, Spracherkennung, Verarbeitung natürlicher Sprache und anderen Bereichen eingesetzt.
Maschinelles Lernen gibt Computern die Möglichkeit, ohne explizite Programmierung zu lernen. Die beiden häufigsten Arten von Modellen für maschinelles Lernen sind unüberwachtes Lernen und überwachte ML-Modelle. Der Hauptunterschied zwischen den beiden besteht darin, dass wir für überwachte Modelle Beschriftungen haben, beschriftete Daten Daten mit Beschriftungen wie Name, Typ oder Nummer sind und unbeaufsichtigte Daten Daten ohne Beschriftungen sind.
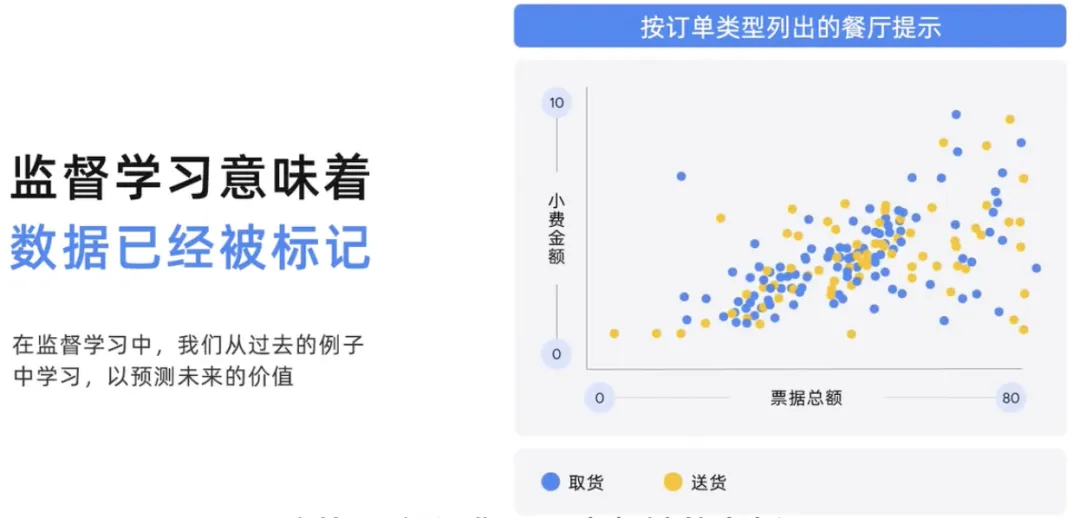
Diese Abbildung ist ein Beispiel für ein Problem, das ein überwachtes Modell zu lösen versuchen könnte.
Angenommen, Sie sind Restaurantbesitzer und verfügen über historische Daten zum Rechnungsbetrag, wie viel Trinkgeld je nach Bestellart an verschiedene Personen gegeben wurde und wie viele verschiedene Personen je nach Bestellart Trinkgeld erhalten haben, unabhängig davon, ob es sich um Abholung oder Lieferung handelte . Beim überwachten Lernen lernt ein Modell aus vergangenen Daten und sagt den zukünftigen Wert voraus. In diesem Modell wird also abhängig von der Bestellart der Gesamtrechnungsbetrag verwendet, um vorherzusagen, ob zukünftige Einkäufe zur Abholung oder Lieferung vorgesehen sind und wie hoch das Trinkgeld sein könnte. Von Prognosen auf der Grundlage früherer Modelle wird erwartet, dass sie die künftigen Verbrauchsmengen genau vorhersagen. Daher verwendet das Modell hier den Gesamtrechnungsbetrag, um zukünftige Ausgaben und Trinkgelder basierend auf der Bestellart vorherzusagen.
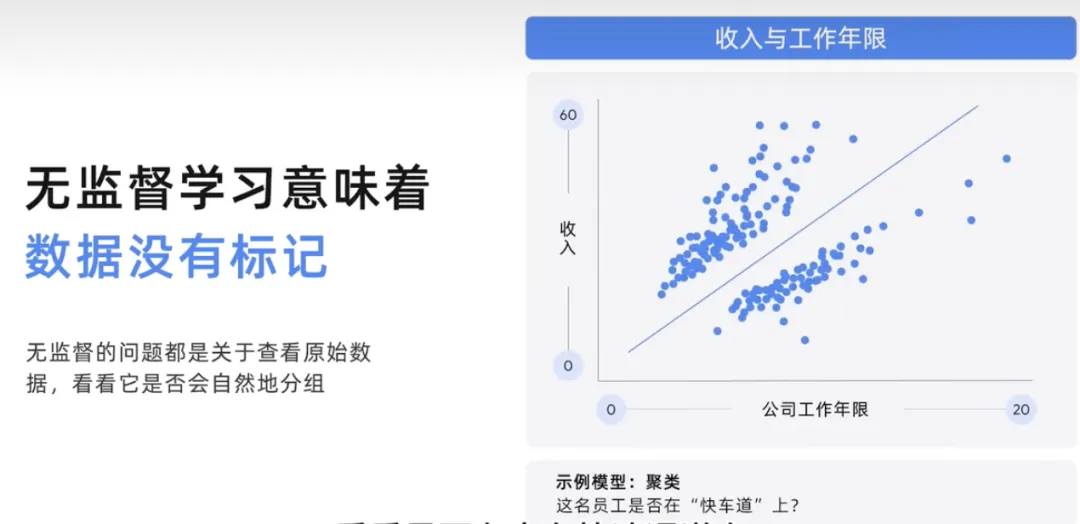
Dieses unbeaufsichtigte Modell kann bei Problembeispielen hilfreich sein, bei denen man sich die Betriebszugehörigkeit und das Einkommen ansehen und dann Mitarbeiter gruppieren muss, um Kohorten zu bilden, um zu sehen, ob jemand auf der Überholspur ist. Bei dem unbeaufsichtigten Problem geht es darum, die Rohdaten zu betrachten und zu sehen, ob sie sich auf natürliche Weise gruppieren. Gehen wir etwas tiefer und zeigen dies grafisch.
Die oben genannten Konzepte sind die Grundlage für das Verständnis generativer KI.

Beim überwachten Lernen werden Testdatenwerte in das Modell eingespeist, das Modell gibt eine Vorhersage aus und diese Vorhersage wird mit den Trainingsdaten verglichen, die zum Trainieren des Modells verwendet wurden.
Wenn der vorhergesagte Testdatenwert und der tatsächliche Trainingsdatenwert weit auseinander liegen, spricht man von einem Fehler und das Modell versucht, diesen Fehler zu reduzieren, bis der vorhergesagte und der tatsächliche Wert näher beieinander liegen.
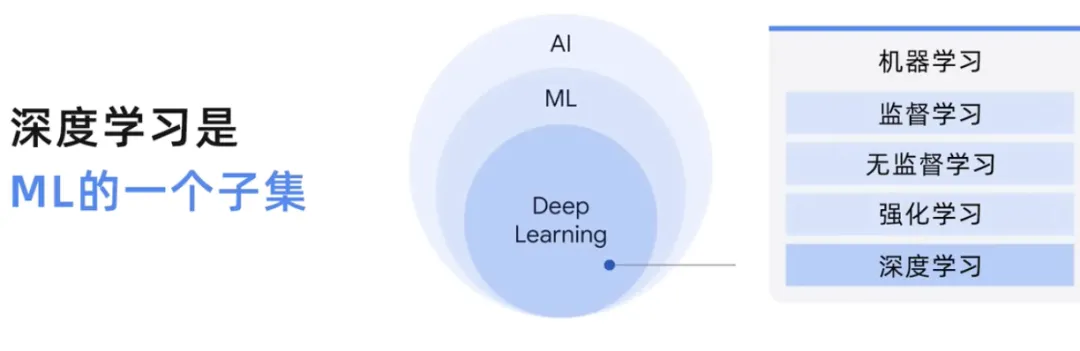
Wir haben den Unterschied zwischen künstlicher Intelligenz und maschinellem Lernen, überwachtem Lernen und unüberwachtem Lernen besprochen. Lassen Sie uns also kurz auf Deep Learning eingehen.
Während maschinelles Lernen ein weites Feld ist, das viele verschiedene Techniken umfasst, ist Deep Learning eine Art maschinelles Lernen, das künstliche neuronale Netze nutzt und es ihnen ermöglicht, komplexere Muster als maschinelles Lernen zu verarbeiten.
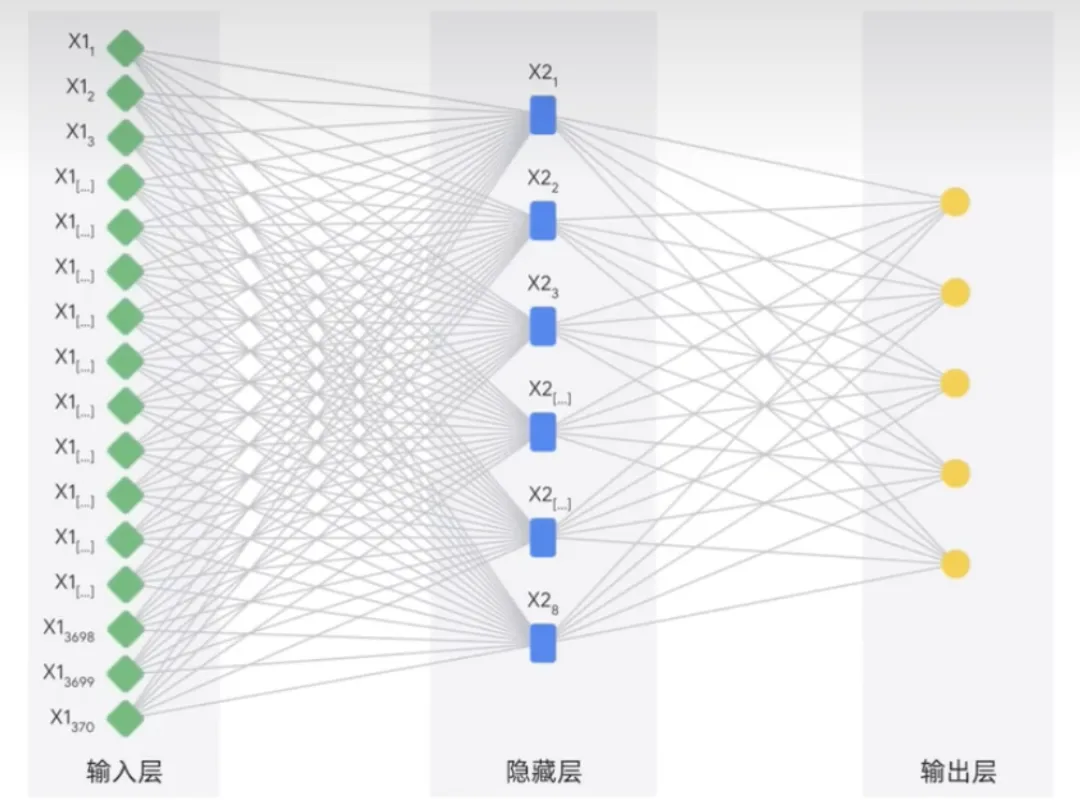
Künstliche neuronale Netze sind vom menschlichen Gehirn inspiriert. Sie bestehen aus vielen miteinander verbundenen Knoten oder Neuronen, die lernen können, Aufgaben auszuführen, indem sie Daten verarbeiten und Vorhersagen treffen.
Deep-Learning-Modelle verfügen normalerweise über mehrere Neuronenschichten. Dadurch können sie komplexere Muster lernen als herkömmliche Modelle des maschinellen Lernens. Neuronale Netze können sowohl mit gekennzeichneten als auch mit unbeschrifteten Daten arbeiten, was als halbüberwachtes Lernen bezeichnet wird. Beim halbüberwachten Lernen wird ein neuronales Netzwerk anhand einer kleinen Menge gekennzeichneter Daten und einer großen Menge unbeschrifteter Daten trainiert. Beschriftete Daten helfen dem neuronalen Netzwerk, die Grundkonzepte der Aufgabe zu erlernen. Und unbeschriftete Daten helfen neuronalen Netzen bei der Verallgemeinerung auf neue Beispiele.
Position in dieser Disziplin der künstlichen Intelligenz, was bedeutet, dass mithilfe künstlicher neuronaler Netze gekennzeichnete und unbeschriftete Daten in überwachten, unüberwachten und halbüberwachten Methoden verarbeitet werden können. Große Sprachmodelle sind auch eine Teilmenge von Deep Learning, Deep-Learning-Modellen oder Machine-Learning-Modellen im Allgemeinen.
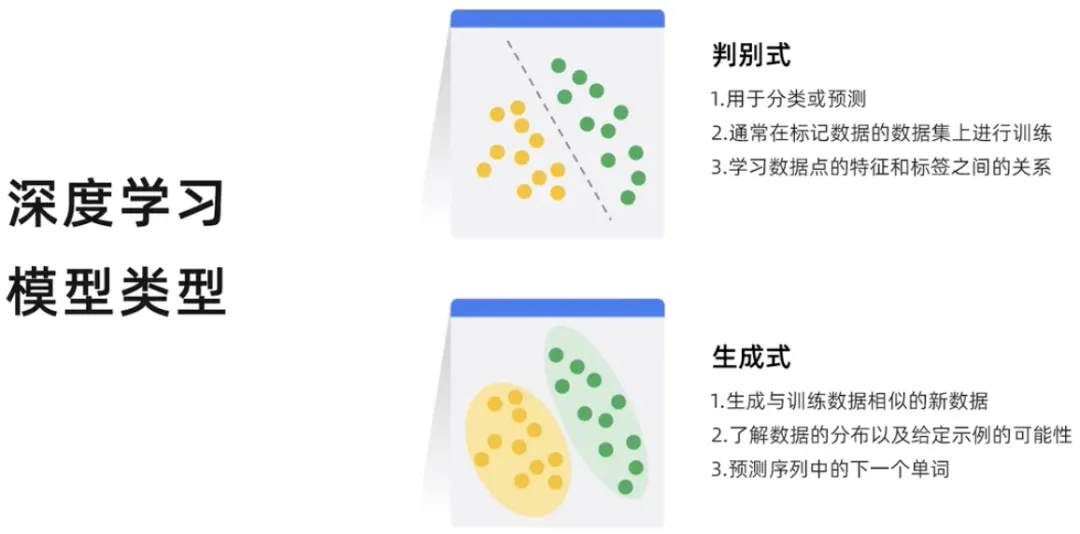
Deep Learning kann in zwei Typen unterteilt werden: diskriminativ und generativ. Ein diskriminatives Modell ist ein Modell, das zur Klassifizierung oder Vorhersage der Beschriftungen von Datenpunkten verwendet wird. Diskriminative Modelle werden typischerweise anhand von Datensätzen markierter Datenpunkte trainiert. Sie lernen die Beziehung zwischen den Merkmalen und Beschriftungen von Datenpunkten kennen und sobald das Unterscheidungsmodell trainiert ist, kann es zur Vorhersage der Beschriftungen neuer Datenpunkte verwendet werden. Das generative Modell generiert neue Dateninstanzen basierend auf der erlernten Wahrscheinlichkeitsverteilung bestehender Daten, sodass das generative Modell neue Inhalte produziert.
Das generative Modell kann neue Dateninstanzen ausgeben, während das diskriminative Modell verschiedene Arten von Dateninstanzen unterscheiden kann.
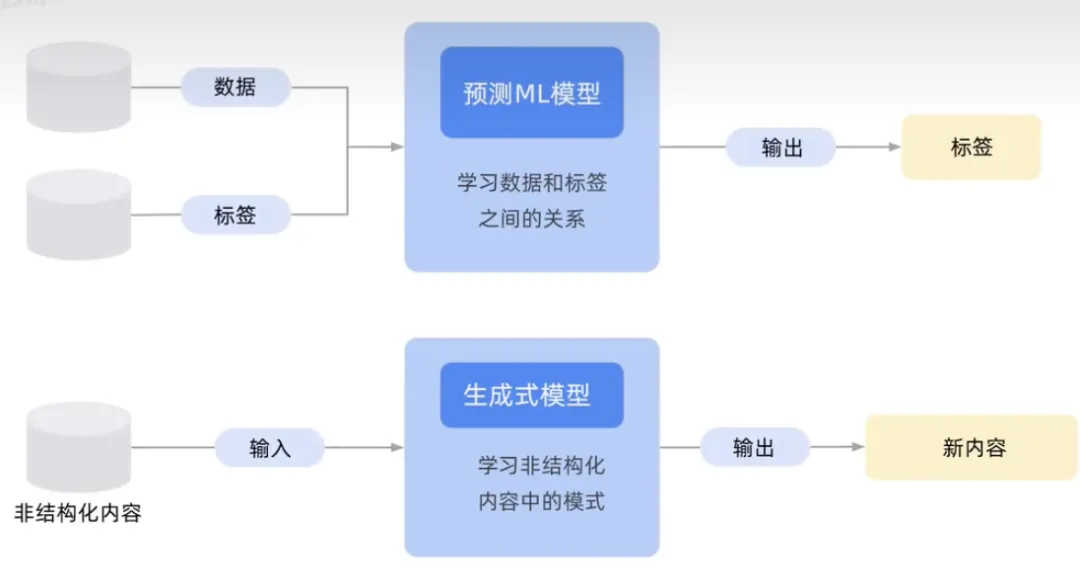
Dieses Diagramm zeigt ein traditionelles Modell für maschinelles Lernen. Der Unterschied besteht in der Beziehung zwischen den Daten und den Beschriftungen oder in dem, was Sie vorhersagen möchten. Das untere Bild zeigt ein generatives KI-Modell, das versucht, Inhaltsmuster zu lernen, um neue Inhalte zu generieren und auszugeben.
Wenn die äußere Ausgabebezeichnung eine Zahl oder Wahrscheinlichkeit ist, handelt es sich um nicht generative KI, z. B. Spam oder Nicht-Spam. Wenn es sich bei der Ausgabe um natürliche Sprache handelt, handelt es sich um generative KI, beispielsweise Sprache, Text, Bilder und Videos.
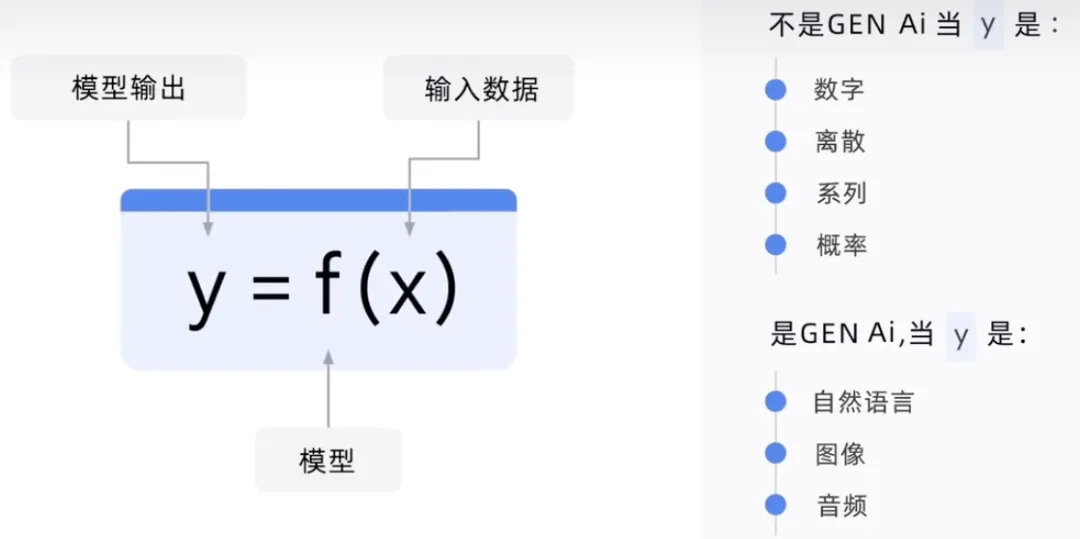
Die Modellausgabe ist eine Funktion aller Eingaben. Wenn Y eine Zahl ist, wie z. B. prognostizierte Verkäufe, dann handelt es sich nicht um GenAI. Wenn Y ein Satz ist, ist das so, als würde man Verkäufe definieren. Es ist insofern generativ, als Fragen Textantworten hervorrufen. Seine Antworten basieren auf all den riesigen Mengen an Big Data, auf denen das Modell trainiert wurde.
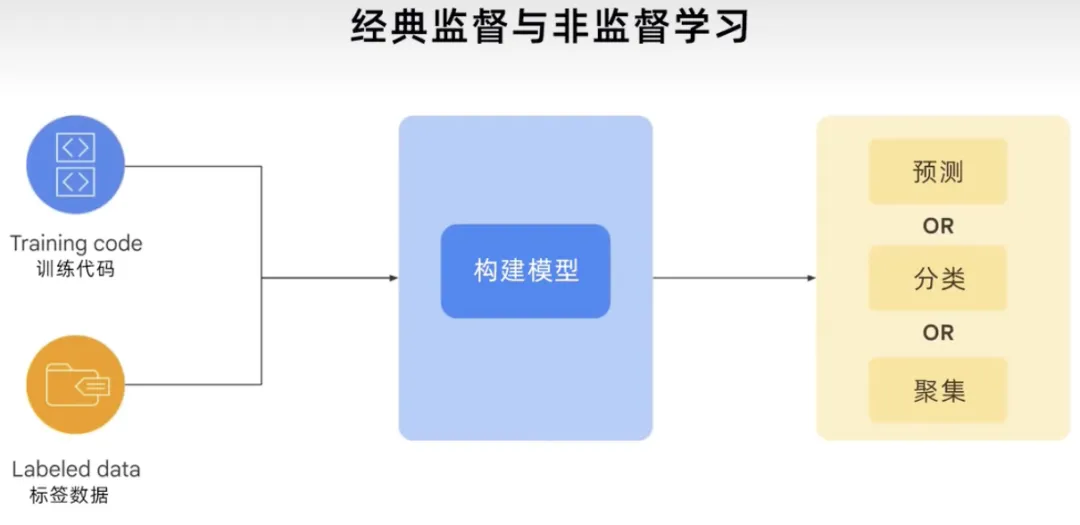
Zusammenfassend lässt sich sagen, dass der traditionelle, klassische überwachte und unbeaufsichtigte Lernprozess Trainingscode und gekennzeichnete Daten zum Aufbau des Modells verwendet. Je nach Anwendungsfall oder Problem kann Ihnen das Modell Vorhersagen geben, es kann etwas klassifizieren oder gruppieren und diese Kraft nutzen, um zu zeigen, wie robust der Prozess ist, der es generiert hat.
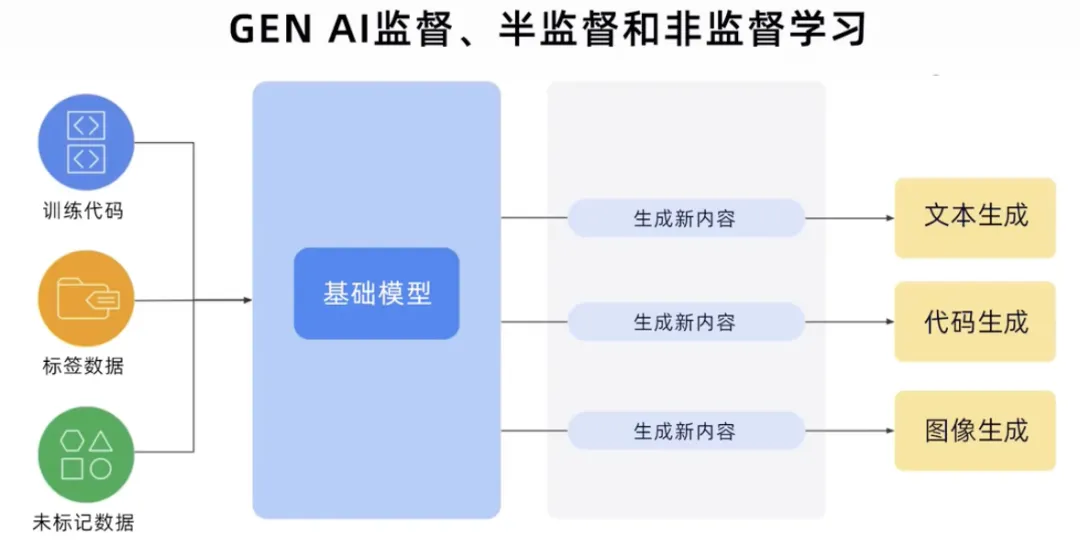
Der GenAI-Prozess kann Trainingscode, beschriftete Daten und unbeschriftete Daten aller Datentypen abrufen, ein Basismodell erstellen und dann kann das Basismodell neue Inhalte generieren. Wie Text, Code, Bilder, Audio, Video usw.
Von der traditionellen Programmierung über neuronale Netze bis hin zu generativen Modellen haben wir einen langen Weg zurückgelegt. In der traditionellen Programmierung mussten wir früher Regeln zur Unterscheidung von Katzen codieren. Der Typ ist ein Tier mit 4 Beinen, 2 Ohren, Fell usw.
In der Welle neuronaler Netze können wir die Netzwerkbilder von Katzen und Hunden füttern. und fragte, ob es eine Katze sei. Er wird eine Katze vorhersagen. In der generativen KI-Welle können wir als Nutzer unsere eigenen Inhalte generieren.

Ob es sich um Text, Bild, Audio, Video usw. handelt, wie zum Beispiel das Python-Sprachmodell oder das Sprachmodell für Konversationsanwendungen und andere Modelle. Erhalten Sie sehr große Datenmengen aus mehreren Quellen im Internet. Erstellen Sie grundlegende Sprachmodelle, die einfach durch das Stellen von Fragen verwendet werden können. Wenn Sie ihn also fragen, was eine Katze ist, kann er Ihnen alles sagen, was er über Katzen weiß.
GenAI Generative KI ist eine Technologie der künstlichen Intelligenz, die auf der Grundlage von Erkenntnissen aus vorhandenen Inhalten neue Inhalte erstellt. Der Prozess des Lernens aus vorhandenen Inhalten wird als Training bezeichnet. Und erstellen Sie ein statistisches Modell, wenn eine Aufforderung gegeben wird, verwenden Sie dieses Modell, um die erwartete Reaktion vorherzusagen, und generieren Sie neue Inhalte.
Im Wesentlichen lernt es den zugrunde liegenden Strukturinhalt der Daten und kann dann neue Stichproben generieren, die den Trainingsdaten ähneln. Wie bereits erwähnt, kann ein generatives Sprachmodell das, was es aus den gezeigten Beispielen gelernt hat, nutzen und auf der Grundlage dieser Informationen etwas völlig Neues erstellen.
Groß angelegte Sprachmodelle sind eine Art generative künstliche Intelligenz, da sie neuartige Textkombinationen in Form natürlich klingender Sprache generieren, Bildmodelle generieren, ein Bild als Eingabe verwenden und Text, ein anderes Bild usw. ausgeben können ein Video. Beispielsweise können Sie unter „Ausgabetext“ visuelle Fragen und Antworten erhalten, während Sie unter „Ausgabebild“ eine Bildvervollständigung generieren und unter „Ausgabevideo“ eine Animation generieren.
Generieren Sie ein Sprachmodell, das Text als Eingabe verwendet und mehr Text, Bilder, Audio oder Entscheidungen ausgeben kann. Generieren Sie beispielsweise eine Frage und Antwort unter dem Ausgabetext und ein Video unter dem Ausgabebild.

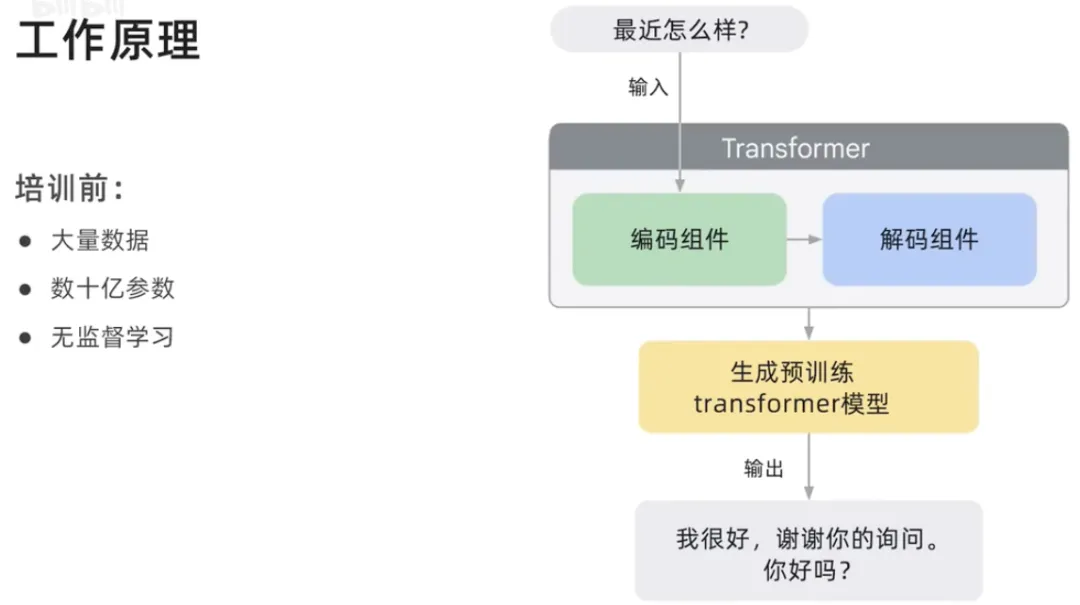
Wir haben gesagt, dass generative Sprachmodelle durch Trainingsdaten etwas über Muster und Sprache lernen und dann anhand eines Textes vorhersagen, was als nächstes passieren wird.
Generative Sprachmodelle sind Mustervergleichssysteme, sie lernen Muster basierend auf den Daten, die Sie ihnen zur Verfügung stellen. Basierend auf dem, was er aus den Trainingsdaten gelernt hat, liefert er eine Vorhersage, wie der Satz zu vervollständigen ist. Es wurde auf große Mengen an Textdaten trainiert und war in der Lage, auf eine Vielzahl von Aufforderungen und Fragen zu kommunizieren und menschenähnlichen Text zu generieren.
In einem Transformer ist ein Halluzin ein vom Modell generiertes Wort oder eine Phrase, die normalerweise Unsinn oder grammatikalisch falsch ist. Halluzinationen können durch eine Vielzahl von Faktoren verursacht werden, darunter, dass das Modell nicht mit ausreichend Daten trainiert wurde, oder dass das Modell mit verrauschten oder schmutzigen Daten trainiert wurde, oder dass dem Modell nicht genügend Kontext gegeben wurde oder dass dem Modell nicht genügend Einschränkungen gegeben wurden.

Sie können auch die Wahrscheinlichkeit erhöhen, dass das Modell falsche oder irreführende Informationen generiert, wie z. B. „Miscellaneous TPT3.5“, das manchmal Informationen generiert, die nicht unbedingt korrekt sind. Ein Aufforderungswort ist ein kleiner Textabschnitt, der als Eingabe für ein großes Sprachmodell bereitgestellt wird. Und es kann verwendet werden, um die Ausgabe des Modells auf verschiedene Arten zu steuern.
Hip Design ist der Prozess der Erstellung von Hinweisen, die den gewünschten Ausgabeinhalt aus einem großen Sprachmodell erzeugen. Wie bereits erwähnt, hängt LLM stark von den von Ihnen eingegebenen Trainingsdaten ab. Es lernt, indem es die Muster und die Struktur der Eingabedaten analysiert. Durch den Zugriff auf browserbasierte Eingabeaufforderungen können Benutzer jedoch ihre eigenen Inhalte generieren.

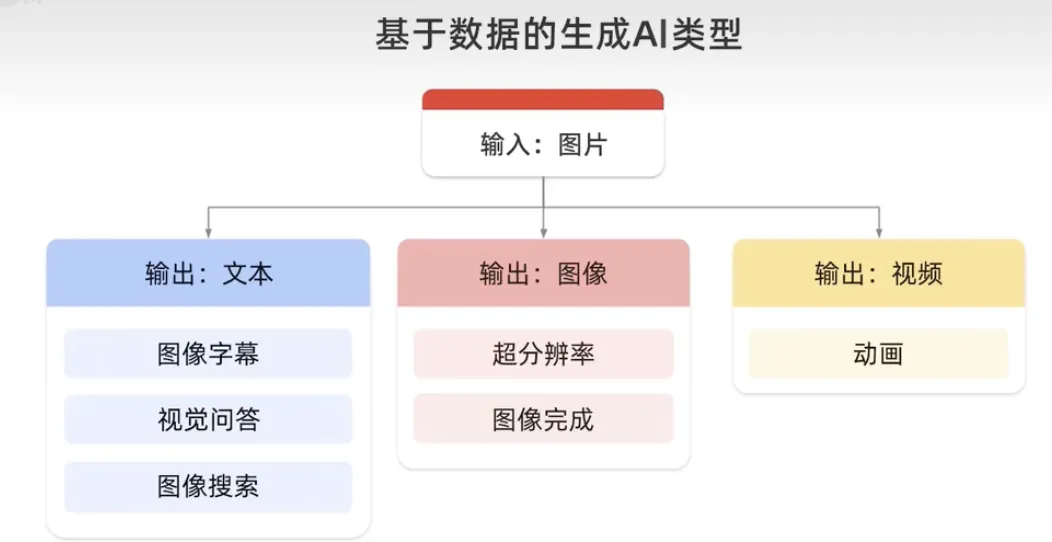
Wir haben eine Roadmap für datenbasierte Eingabetypen gezeigt, hier sind die relevanten Modelltypen.
Text-zu-Text-Modell. Nimmt Eingaben in natürlicher Sprache entgegen und generiert eine Textausgabe. Diese Modelle werden darauf trainiert, Zuordnungen zwischen Texten zu lernen. Zum Beispiel die Übersetzung von einer Sprache in eine andere.
Text-zu-Bild-Modell. Weil Text-zu-Bild-Modelle an einer großen Anzahl von Bildern trainiert werden. Zu jedem Bild gibt es eine kurze Textbeschreibung. Diffusion ist eine Methode, um dies zu erreichen.

Text zu Video und Text zu 3D. Text-zu-Video-Modelle generieren Videoinhalte nur aus Texteingaben, die von einem einzelnen Satz bis hin zu einem vollständigen Skript reichen können. Die Ausgabe ist videoähnlicher Text, der dem Eingabetext in ein 3D-Modell entspricht, das dreidimensionale Objekte generiert, die der Textbeschreibung des Benutzers entsprechen. Dies könnte beispielsweise für Spiele oder andere 3D-Welten genutzt werden.
Text-to-Task-Modell. Sobald es trainiert ist, kann es definierte Aufgaben oder Aktionen basierend auf Texteingaben ausführen. Diese Aufgabe kann umfangreich sein. Beantworten Sie beispielsweise eine Frage, führen Sie eine Suche durch, treffen Sie eine Vorhersage oder ergreifen Sie eine Aktion. Text-zu-Aufgaben-Modelle können auch trainiert werden, um Abfragen zu leiten oder Änderungen an Dokumenten vorzunehmen.
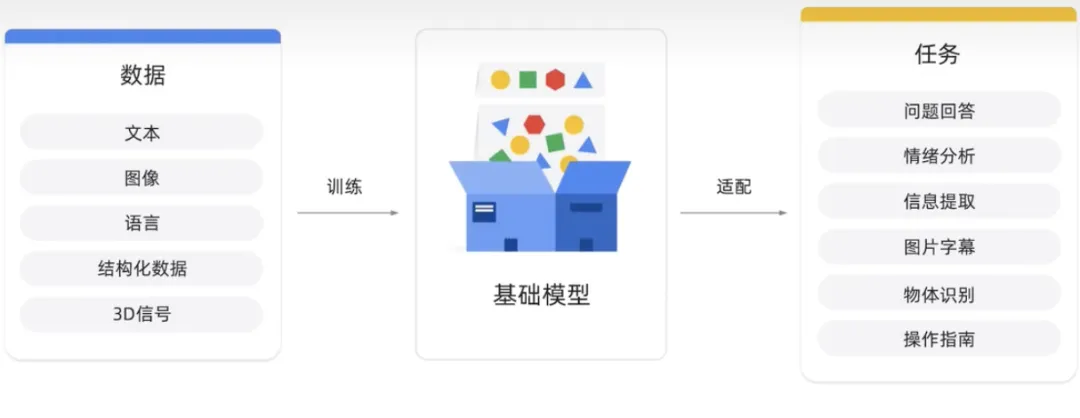
Das Basismodell ist ein großes KI-Modell, das auf einer großen Datenmenge vorab trainiert wurde. Ziel ist die Anpassung oder Feinabstimmung verschiedener nachgelagerter Aufgaben wie Sentimentanalyse, Bild-, Bildunterschriften- und Objekterkennung.
Zugrunde liegende Modelle haben das Potenzial, viele Branchen zu revolutionieren, darunter das Gesundheitswesen, das Finanzwesen und den Kundenservice, wo sie zur Erkennung von Vorhersagen und zur Bereitstellung personalisierter Kundenbetreuung eingesetzt werden können. OpenAI bietet eine grundlegende Modellquellsprache, einschließlich derjenigen für Chat und Text.

Das grundlegende Visionsmodell umfasst eine stabile Diffusion, mit der aus Textbeschreibungen effektiv Bilder in Paketqualität generiert werden können. Nehmen wir an, Sie haben einen Fall, in dem Sie Informationen darüber sammeln müssen, wie Kunden über Ihr Produkt oder Ihre Dienstleistung denken.

Generative AI Studio ermöglicht Ihnen aus Entwicklersicht das einfache Entwerfen und Erstellen von Anwendungen, ohne Code schreiben zu müssen. Es verfügt über einen visuellen Editor, der das Erstellen und Bearbeiten von Anwendungsinhalten erleichtert. Es gibt auch eine integrierte Suchmaschine, die es Benutzern ermöglicht, innerhalb der App nach Informationen zu suchen.
Es gibt auch eine Konversations-Engine für künstliche Intelligenz, die Benutzern hilft, mit der Anwendung in natürlicher Sprache zu interagieren. Sie können Ihren eigenen digitalen Assistenten, eine benutzerdefinierte Suchmaschine, eine Wissensdatenbank, eine Schulungs-App und mehr erstellen.

Modellbereitstellungstools unterstützen Entwickler bei der Bereitstellung von Modellen in Produktionsumgebungen mithilfe einer Reihe verschiedener Bereitstellungsoptionen. Und Modellüberwachungstools helfen Entwicklern, die Leistung von ML-Modellen in der Produktion mithilfe von Dashboards und vielen verschiedenen Metriken zu überwachen.
Wenn Sie sich die Entwicklung generativer KI-Anwendungen als das Zusammensetzen eines komplexen Puzzles vorstellen, sind alle dafür erforderlichen technischen Fähigkeiten, wie Datenwissenschaft, maschinelles Lernen und Programmierung, jedem Teil des Puzzles gleichwertig.
Für Unternehmen ohne technische Ausstattung ist es bereits schwierig, diese Puzzleteile zu verstehen, und das Zusammenfügen wird zu einer noch schwierigeren Aufgabe. Aber wenn es Dienste gibt, die diesen traditionellen Unternehmen mit schwachen technischen Fähigkeiten einige vorgefertigte Puzzleteile zur Verfügung stellen können, können diese traditionellen Unternehmen das gesamte Puzzle einfacher und schneller lösen.
Gemessen an der tatsächlichen Situation auf dem heimischen Markt ist die Entwicklung generativer KI weder so optimistisch, wie von den dem Trend nachjagenden Praktikern vorhergesagt, noch so pessimistisch, wie von Kritikern beschrieben.
Unternehmensbenutzer streben nach der Robustheit, Wirtschaftlichkeit, Sicherheit und Benutzerfreundlichkeit von Anwendungen, was ein völlig anderer Weg ist als generative KI wie große Sprachmodelle, die während des Trainingsprozesses hohe Rechenleistungskosten aufwenden, um höhere Fähigkeiten zu erreichen.
Ein Kernproblem dahinter ist, dass es im Bereich der generativen KI auf Unternehmensebene mit größerer Fantasie nicht darauf ankommt, wie leistungsfähig das große Modell ist, sondern wie es sich von einem Basismodell zu spezifischen Anwendungen in verschiedenen Bereichen weiterentwickeln kann . Dadurch wird die Entwicklung der gesamten Wirtschaft und Gesellschaft gefördert.
Das obige ist der detaillierte Inhalt vonWas ist generative KI? Welche Feature-Typen gibt es?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



