
 Technologie-Peripheriegeräte
KI
ICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe
Technologie-Peripheriegeräte
KI
ICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe
ICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe

Federated Learning nutzt mehrere Parteien zum Trainieren von Modellen, während der Datenschutz geschützt ist. Da der Server jedoch den von den Teilnehmern lokal durchgeführten Schulungsprozess nicht überwachen kann, können Teilnehmer das lokale Schulungsmodell manipulieren, was Sicherheitsrisiken für das gesamte föderierte Lernmodell mit sich bringt, beispielsweise durch Hintertürangriffe.
Dieser Artikel konzentriert sich darauf, wie man Hintertürangriffe auf föderiertes Lernen unter einem defensiv geschützten Trainingsrahmen startet. In diesem Artikel wird festgestellt, dass die Implementierung von Backdoor-Angriffen enger mit einigen neuronalen Netzwerkschichten zusammenhängt, und diese Schichten werden als Schlüsselschichten für Backdoor-Angriffe bezeichnet. Beim föderierten Lernen werden die am Training teilnehmenden Clients auf verschiedene Geräte verteilt. Sie trainieren jeweils ihre eigenen Modelle und laden dann die aktualisierten Modellparameter zur Aggregation auf den Server hoch. Da der an der Schulung teilnehmende Client nicht vertrauenswürdig ist und ein gewisses Risiko besteht, wird der Server
Basierend auf der Entdeckung der Schlüsselschicht der Hintertür wird in diesem Artikel vorgeschlagen, die Erkennung des Verteidigungsalgorithmus durch einen Angriff auf die Schlüsselschicht der Hintertür zu umgehen , so dass eine kleine Anzahl von Teilnehmern kontrolliert werden kann, um effiziente Backdoor-Angriffe durchzuführen.

Papiertitel: Backdoor Federated Learning By Poisoning Backdoor-Critical Layers
Papierlink: https://openreview.net/pdf?id=AJBGSVSTT2
Codelink: https://github.com/zhmzm/ Poisoning_Backdoor-critical_Layers_Attack
Methode
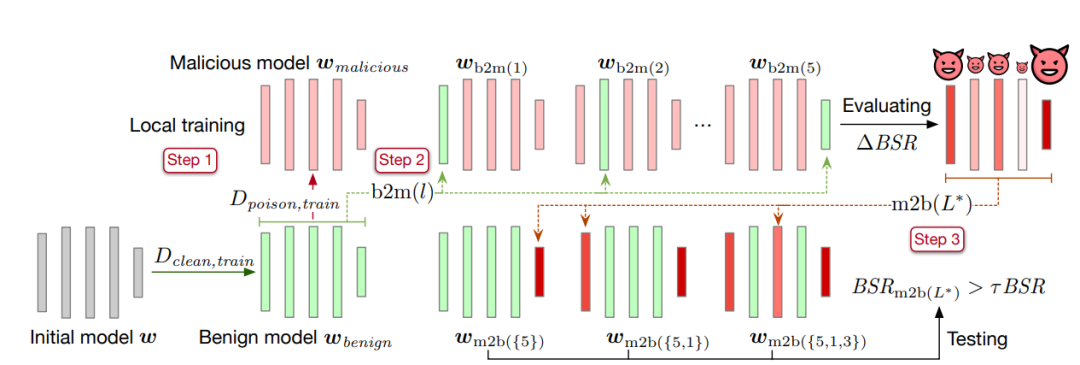
Dieser Artikel schlägt eine Methode zum Ersetzen von Schichten vor, um kritische Schichten für die Hintertür zu identifizieren. Die spezifische Methode ist wie folgt:
Der erste Schritt besteht darin, das Modell auf einem sauberen Datensatz bis zur Konvergenz zu trainieren und die Modellparameter als harmloses Modell zu speichern
 . Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf.
. Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf. - Der zweite Schritt besteht darin, eine Parameterschicht im harmlosen Modell durch das bösartige Modell zu ersetzen, das die Hintertür enthält, und die Erfolgsrate des Hintertürangriffs des resultierenden Modells zu berechnen
. Die Differenz zwischen der erhaltenen Erfolgsrate des Backdoor-Angriffs und der Backdoor-Angriffs-Erfolgsrate BSR des Schadmodells beträgt ΔBSR, mit der die Auswirkung dieser Schicht auf Backdoor-Angriffe ermittelt werden kann. Mit der gleichen Methode für jede Schicht im neuronalen Netzwerk können Sie eine Liste der Auswirkungen aller Schichten auf Backdoor-Angriffe erhalten.
- Der dritte Schritt besteht darin, alle Ebenen nach ihrer Auswirkung auf Backdoor-Angriffe zu sortieren. Nehmen Sie die Ebene mit der größten Auswirkung aus der Liste und fügen Sie sie dem kritischen Ebenensatz für Hintertürangriffe hinzu
und betten Sie die kritischen Ebenenparameter für Hintertürangriffe (Ebenen im Satz
) aus dem bösartigen Modell in das harmlose Modell ein. Berechnen Sie die Erfolgsquote des Backdoor-Angriffs des erhaltenen Modells. Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells , wird der Algorithmus gestoppt. Wenn dies nicht der Fall ist, fügen Sie weiterhin die größte Schicht unter den verbleibenden Schichten in der Liste zur Schlüsselschicht für Backdoor-Angriffe hinzu, bis die Bedingungen erfüllt sind.
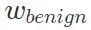 . Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf.
. Kopieren Sie dann das harmlose Modell und trainieren Sie es anhand des Datensatzes, der die Hintertür enthält. Speichern Sie nach der Konvergenz die Modellparameter und zeichnen Sie es als bösartiges Modell auf. 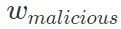
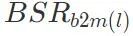
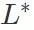 ) aus dem bösartigen Modell in das harmlose Modell ein. Berechnen Sie die Erfolgsquote des Backdoor-Angriffs des erhaltenen Modells
) aus dem bösartigen Modell in das harmlose Modell ein. Berechnen Sie die Erfolgsquote des Backdoor-Angriffs des erhaltenen Modells . Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells
. Wenn die Erfolgsrate des Backdoor-Angriffs größer ist als der festgelegte Schwellenwert τ multipliziert mit der Erfolgsrate des Backdoor-Angriffs des bösartigen Modells 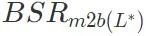 , wird der Algorithmus gestoppt. Wenn dies nicht der Fall ist, fügen Sie weiterhin die größte Schicht unter den verbleibenden Schichten in der Liste zur Schlüsselschicht für Backdoor-Angriffe hinzu
, wird der Algorithmus gestoppt. Wenn dies nicht der Fall ist, fügen Sie weiterhin die größte Schicht unter den verbleibenden Schichten in der Liste zur Schlüsselschicht für Backdoor-Angriffe hinzu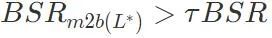 , bis die Bedingungen erfüllt sind.
, bis die Bedingungen erfüllt sind. Experimentelle Ergebnisse
Dieser Artikel überprüft die Wirksamkeit von Backdoor-Key-Layer-Angriffen auf mehrere Verteidigungsmethoden auf die CIFAR-10- und MNIST-Datensätze. Das Experiment wird die Erfolgsrate des Backdoor-Angriffs BSR und die Akzeptanzrate bösartiger Modelle MAR (Benign Model Acceptance Rate BAR) als Indikatoren verwenden, um die Wirksamkeit des Angriffs zu messen.
Zuallererst kann der schichtbasierte LP-Angriff böswilligen Clients eine hohe Auswahlrate ermöglichen. Wie in der folgenden Tabelle gezeigt, erreichte LP Attack eine Empfangsrate von 90 % beim CIFAR-10-Datensatz, was viel höher ist als die 34 % der harmlosen Benutzer.
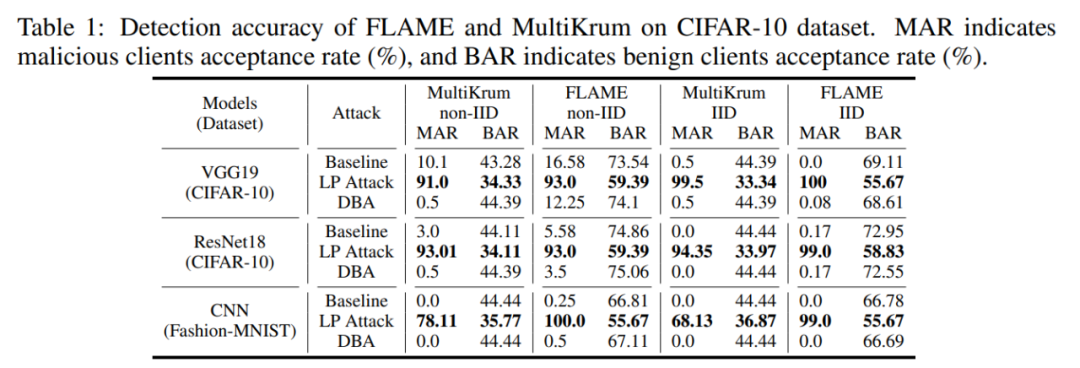
Dann kann LP Attack eine hohe Erfolgsquote bei Backdoor-Angriffen erzielen, selbst in einer Umgebung mit nur 10 % böswilligen Clients. Wie in der folgenden Tabelle gezeigt, kann LP Attack unter dem Schutz verschiedener Datensätze und verschiedener Verteidigungsmethoden eine hohe Erfolgsquote bei Backdoor-Angriffen (BSR) erzielen.
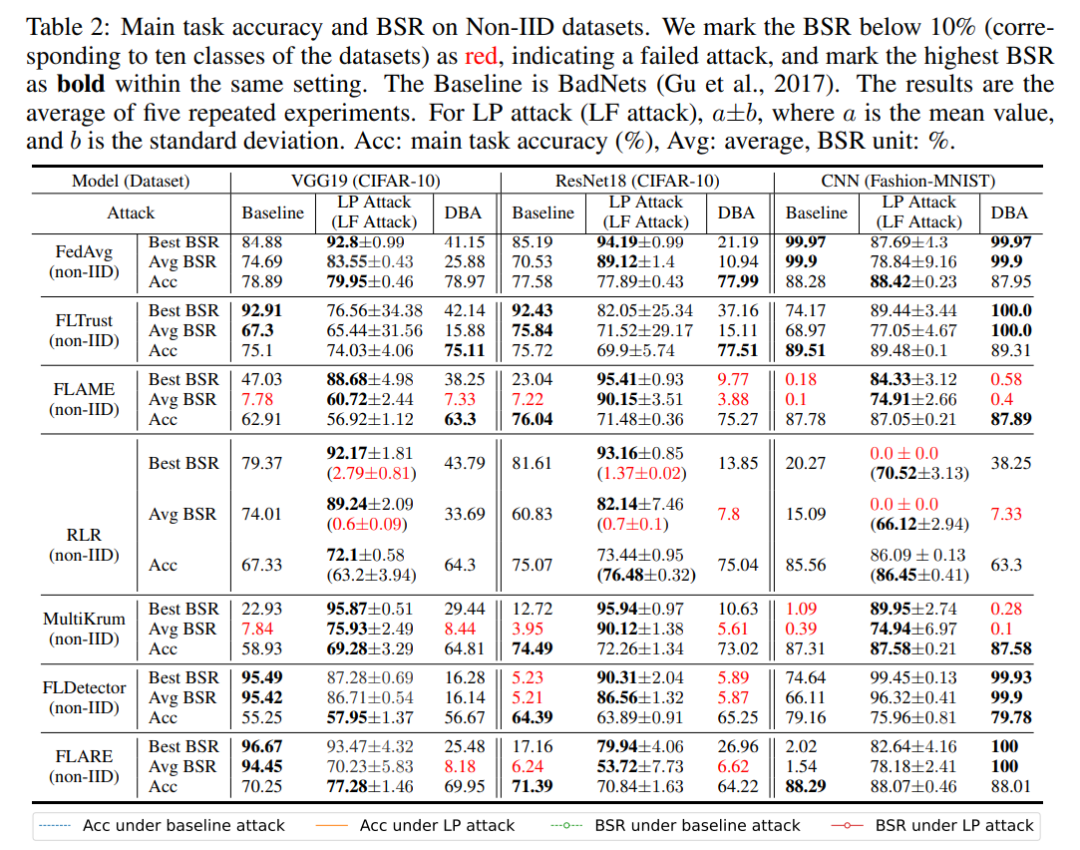
Im Ablationsexperiment hat dieser Artikel die Hintertür-Schlüsselschicht bzw. die Nicht-Hintertür-Schlüsselschicht vergiftet und die Erfolgsrate der Hintertür-Angriffe der beiden Experimente gemessen. Wie in der Abbildung unten gezeigt, ist die Erfolgsrate bei der Vergiftung von Nicht-Hintertür-Schlüsselschichten viel geringer als bei der Vergiftung von Hintertür-Schlüsselschichten. Dies zeigt, dass der Algorithmus in diesem Artikel einen wirksamen Hintertür-Angriffsschlüssel auswählen kann Lagen.
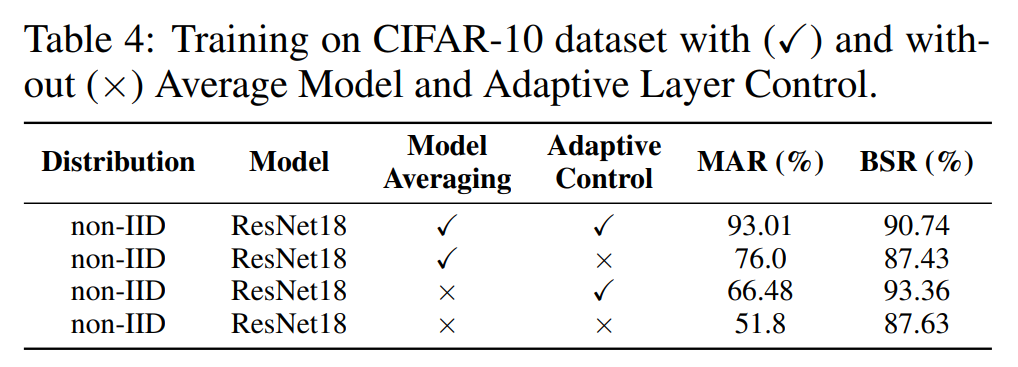
Darüber hinaus führen wir Ablationsexperimente zum Modellaggregationsmodul Model Averaging und zum adaptiven Steuerungsmodul Adaptive Control durch. Wie in der folgenden Tabelle gezeigt, verbessern beide Module die Auswahlrate und die Erfolgsquote von Backdoor-Angriffen, was die Wirksamkeit dieser beiden Module beweist.
Zusammenfassung
In diesem Artikel wurde festgestellt, dass Backdoor-Angriffe eng mit einigen Ebenen verbunden sind, und es wurde ein Algorithmus zur Suche nach Schlüsselebenen von Backdoor-Angriffen vorgeschlagen. In diesem Artikel wird ein schichtweiser Angriff auf den Schutzalgorithmus beim föderierten Lernen vorgeschlagen, bei dem Hintertüren zum Angriff auf Schlüsselschichten verwendet werden. Der vorgeschlagene Angriff deckt die Schwachstellen der aktuellen drei Arten von Verteidigungsmethoden auf, was darauf hindeutet, dass in Zukunft ausgefeiltere Verteidigungsalgorithmen erforderlich sein werden, um die Sicherheit des föderierten Lernens zu schützen.
Vorstellung des Autors
Zhuang Haomin hat einen Bachelor-Abschluss von der South China University of Technology. Er arbeitete als wissenschaftlicher Mitarbeiter im IntelliSys Laboratory der Louisiana State University und studiert derzeit an der University of Notre Dame. Die Hauptforschungsrichtungen sind Backdoor-Angriffe und gegnerische Musterangriffe.
Das obige ist der detaillierte Inhalt vonICLR 2024 |. Modellieren Sie kritische Schichten für föderierte Lern-Backdoor-Angriffe. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die ersten Drohnen des Landes, die Zulassungsbescheide für Hochschulaufnahmeprüfungen liefern, machen die Studienanfänger 2024 der South China University of Technology „glücklich vom Himmel'
Jul 17, 2024 am 03:15 AM
Die ersten Drohnen des Landes, die Zulassungsbescheide für Hochschulaufnahmeprüfungen liefern, machen die Studienanfänger 2024 der South China University of Technology „glücklich vom Himmel'
Jul 17, 2024 am 03:15 AM
Diese Website berichtete am 16. Juli, dass nach offiziellen Angaben der South China University of Technology die Guangzhou Post und die South China University of Technology gemeinsam den Einsatz von Drohnen untersucht haben, um Bewerbern Zulassungsbescheide für Hochschulaufnahmeprüfungen zuzustellen Vier, auf die wir warteten, kamen per Direktflug von der South China University of Technology. Am Morgen des 15. Juli trafen sich Tu Sulan, ein Kandidat, der zum Hauptfach Chemie der South China University of Technology (Strong Foundation Program Class) zugelassen wurde, und die Studenten Zhong Mingcheng, Wang Yunyi und Li Jinquan, die zum Sporttraining zugelassen wurden Hauptfach, „aufgeschaut“ in der Vanke Mountain View City, Bezirk Huangpu, Guangzhou. Ich freue mich darauf“, denn ihre Zulassungsbescheide werden „mit Freude vom Himmel kommen“. Berichten zufolge erfordert der gesamte Lieferprozess keine manuelle Steuerung durch professionelle Piloten, sondern die Systemroute wird über die Flugkontrollzentrale im Hintergrund der Drohne festgelegt. Um 11 Uhr übergab das Zulassungspersonal den versiegelten Bescheid an die Post
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
