
 Technologie-Peripheriegeräte
KI
Ein kostengünstiger Algorithmus verbessert die Robustheit der visuellen Klassifizierung erheblich! Chinesisches Team der Universität Sydney veröffentlicht neue EdgeNet-Methode
Technologie-Peripheriegeräte
KI
Ein kostengünstiger Algorithmus verbessert die Robustheit der visuellen Klassifizierung erheblich! Chinesisches Team der Universität Sydney veröffentlicht neue EdgeNet-Methode
Ein kostengünstiger Algorithmus verbessert die Robustheit der visuellen Klassifizierung erheblich! Chinesisches Team der Universität Sydney veröffentlicht neue EdgeNet-Methode

Zeigte eine hervorragende Genauigkeit in tiefen neuronalen Netzen (DNNs). Allerdings sind sie anfällig für zusätzlichen Lärm, also gegnerische Angriffe. Frühere Untersuchungen gingen davon aus, dass diese Schwachstelle auf die übermäßige Abhängigkeit hochpräziser DNNs von unbedeutenden und uneingeschränkten Merkmalen wie Textur und Hintergrund zurückzuführen sein könnte. Neue Untersuchungen zeigen jedoch, dass diese Schwachstelle nichts mit den spezifischen Eigenschaften hochpräziser DNNs zu tun hat, die irrelevanten Faktoren wie Gewichtung und Kontext übermäßig vertrauen.
Auf der jüngsten akademischen Konferenz AAAI 2024 enthüllten Forscher der Universität Sydney, dass „aus Bildern extrahierte Kanteninformationen hochrelevante und robuste Merkmale in Bezug auf Form und Hintergrund liefern können“.

Link zum Papier: https://ojs.aaai.org/index.php/AAAI/article/view/28110
Diese Funktionen helfen dem vorab trainierten tiefen Netzwerk, seine gegnerische Robustheit zu verbessern. , ohne die Genauigkeit bei klaren Bildern zu beeinträchtigen.
Forscher schlagen ein leichtes und anpassungsfähiges EdgeNet vor, das nahtlos in bestehende vorab trainierte tiefe Netzwerke integriert werden kann, einschließlich Vision Transformers (ViTs), der neuesten Generation fortschrittlicher Modelle für die visuelle Klassifizierungsfamilie.
EdgeNet ist eine Kantenextraktionstechnik, die Kanten verarbeitet, die aus sauberen natürlichen Bildern oder verrauschten gegnerischen Bildern extrahiert wurden, und in die mittlere Schicht eines vorab trainierten und eingefrorenen Backbone-Tiefennetzwerks eingefügt werden kann. Dieses tiefe Netzwerk verfügt über hervorragende Backbone-Robustheitsfunktionen und kann Funktionen mit umfangreichen semantischen Informationen extrahieren. Durch die Einbindung von EdgeNet in ein solches Netzwerk kann man die Vorteile seines hochwertigen Backbone-Deep-Netzwerks nutzen
Es ist zu beachten, dass dieser Ansatz nur minimale zusätzliche Kosten mit sich bringt: Die Verwendung herkömmlicher Kantenerkennungsalgorithmen wie der im Artikel erwähnte Die Kosten für den Erwerb dieser Kanten (Canny Edge Detector) sind im Vergleich zu den Kosten für die Inferenz für tiefe Netzwerke winzig, während die Kosten für das Training von EdgeNet mit den Kosten für die Feinabstimmung des Backbone-Netzwerks mithilfe von Techniken wie Adaptern vergleichbar sind.
EdgeNet-Architektur
Um Kanteninformationen in Bildern in das vorab trainierte Backbone-Netzwerk einzufügen, stellt der Autor ein Seitenzweignetzwerk namens EdgeNet vor. Dieses leichte Plug-and-Play-Sicherheitennetzwerk kann nahtlos in bestehende vorab trainierte tiefe Netzwerke integriert werden, einschließlich hochmoderner Modelle wie ViTs.
Anhand der aus dem Eingabebild extrahierten Kanteninformationen kann EdgeNet+ eine Reihe robuster Funktionen generieren. Dieser Prozess erzeugt ein robustes Merkmal, das selektiv in das vorab trainierte tiefe Backbone-Netzwerk eingefügt werden kann, um es in den Zwischenschichten des tiefen Netzwerks einzufrieren.
Durch die Integration dieser robusten Funktionen kann die Fähigkeit des Netzwerks, sich gegen gegnerische Störungen zu verteidigen, verbessert werden. Da das Backbone-Netzwerk eingefroren ist und die Injektion neuer Funktionen selektiv erfolgt, kann gleichzeitig die Genauigkeit des vorab trainierten Netzwerks bei der Identifizierung ungestörter klarer Bilder aufrechterhalten werden.
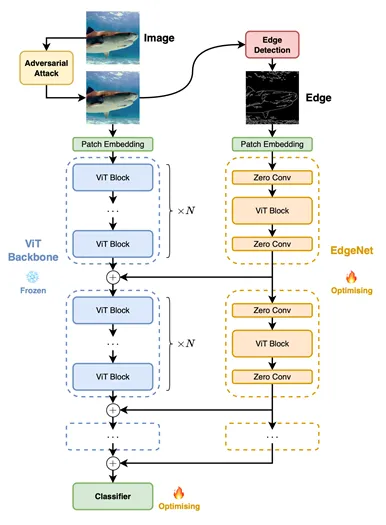
Wie in der Abbildung gezeigt, fügt der Autor basierend auf den ursprünglichen Bausteinen 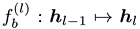 in einem bestimmten Intervall N neue EdgeNet-Bausteine
in einem bestimmten Intervall N neue EdgeNet-Bausteine 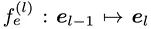 ein. Die Ausgabe der neuen Zwischenschicht kann durch die folgende Formel dargestellt werden:
ein. Die Ausgabe der neuen Zwischenschicht kann durch die folgende Formel dargestellt werden:
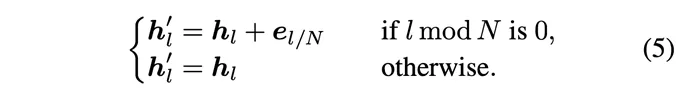
EdgeNet-Bausteine
Um eine selektive Merkmalsextraktion und selektive Merkmalinjektion zu erreichen, nehmen diese EdgeNet-Bausteine eine „Sandwich“-Struktur an: Jede Nullfaltung ( Nullfaltung) wird vor und nach dem Block hinzugefügt, um die Eingabe und Ausgabe zu steuern. Zwischen diesen beiden Nullfaltungen befindet sich ein ViT-Block mit zufälliger Initialisierung und derselben Architektur wie das Backbone-Netzwerk
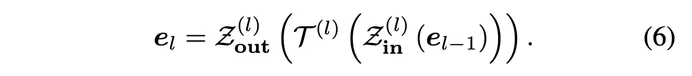
Bei Null-Input fungiert 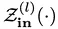 als Filter, um für das Optimierungsziel relevante Informationen zu extrahieren; bei Null-Output fungiert es als Filter, um die Informationen zu bestimmen, die in das Backbone integriert werden sollen. Darüber hinaus wird durch die Nullinitialisierung sichergestellt, dass der Informationsfluss innerhalb des Backbones unbeeinträchtigt bleibt. Dadurch wird die anschließende Feinabstimmung von EdgeNet effizienter.
als Filter, um für das Optimierungsziel relevante Informationen zu extrahieren; bei Null-Output fungiert es als Filter, um die Informationen zu bestimmen, die in das Backbone integriert werden sollen. Darüber hinaus wird durch die Nullinitialisierung sichergestellt, dass der Informationsfluss innerhalb des Backbones unbeeinträchtigt bleibt. Dadurch wird die anschließende Feinabstimmung von EdgeNet effizienter.
Trainingsziel
Während des Trainings von EdgeNet ist das vorab trainierte ViT-Backbone-Netzwerk mit Ausnahme des Klassifizierungskopfes eingefroren und wird nicht aktualisiert. Das Optimierungsziel konzentriert sich nur auf das für Edge-Features eingeführte EdgeNet-Netzwerk und die Klassifizierungsköpfe innerhalb des Backbone-Netzwerks. Hier verwendet der Autor ein sehr vereinfachtes gemeinsames Optimierungsziel, um die Effizienz des Trainings sicherzustellen:
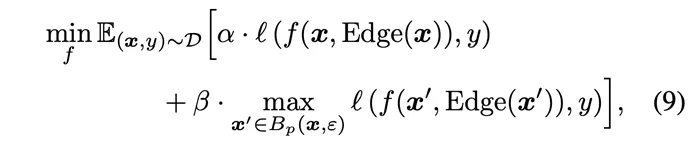
In Formel 9 ist α das Gewicht der Genauigkeitsverlustfunktion und β das Gewicht der Robustheitsverlustfunktion. Durch Anpassen der Größe von α und β kann die Ausgewogenheit der EdgeNet-Trainingsziele fein abgestimmt werden, um die Robustheit zu verbessern, ohne die Genauigkeit wesentlich zu verlieren.
Experimentelle Ergebnisse
Die Autoren testeten die Robustheit von zwei Hauptkategorien im ImageNet-Datensatz.
Die erste Kategorie ist die Robustheit gegenüber gegnerischen Angriffen, einschließlich White-Box-Angriffen und Black-Box-Angriffen;
Die zweite Kategorie ist die Robustheit gegenüber einigen häufigen Störungen, einschließlich der natürlichen Störungen in ImageNet-A Natural Adversarial Beispiele, Daten außerhalb der Verteilung in ImageNet-R und häufige Beschädigungen in ImageNet-C.
Der Autor visualisierte auch die unter verschiedenen Störungen extrahierten Kanteninformationen.

Netzwerkskalen- und Leistungstests
Im experimentellen Teil testete der Autor zunächst die Klassifizierungsleistung und den Rechenaufwand von EdgeNet in verschiedenen Maßstäben (Tabelle 1). Nach umfassender Betrachtung der Klassifizierungsleistung und des Rechenaufwands stellten sie fest, dass die Konfiguration von #Intervals = 3 die optimale Einstellung war.
In dieser Konfiguration erreicht EdgeNet im Vergleich zu Basismodellen erhebliche Genauigkeits- und Robustheitsverbesserungen. Es erreicht einen ausgewogenen Kompromiss zwischen Klassifizierungsleistung, Rechenanforderungen und Robustheit.
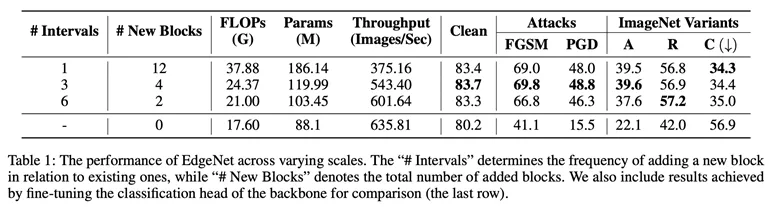
Diese Konfiguration erzielt erhebliche Fortschritte bei der Klarheit, Genauigkeit und Robustheit und behält gleichzeitig eine angemessene Recheneffizienz bei.
Vergleich von Genauigkeit und Robustheit
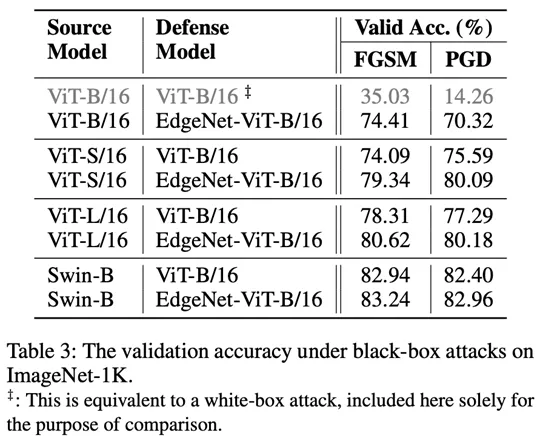
Die Autoren verglichen ihr vorgeschlagenes EdgeNet mit 5 verschiedenen Kategorien von SOTA-Methoden (Tabelle 2). Zu diesen Methoden gehören CNNs, die auf natürlichen Bildern trainiert wurden, robuste CNNs, auf natürlichen Bildern trainierte ViTs, robuste ViTs und robuste, fein abgestimmte ViTs.
Zu den berücksichtigten Metriken gehören die Genauigkeit bei gegnerischen Angriffen (FGSM und PGD), die Genauigkeit bei ImageNet-A und die Genauigkeit bei ImageNet-R.
Zusätzlich wird auch der mittlere Fehler (mCE) von ImageNet-C gemeldet, wobei niedrigere Werte auf eine bessere Leistung hinweisen. Experimentelle Ergebnisse zeigen, dass EdgeNet angesichts von FGSM- und PGD-Angriffen eine überlegene Leistung zeigt und gleichzeitig mit früheren SOTA-Methoden für den sauberen ImageNet-1K-Datensatz und seine Varianten gleichwertig ist.
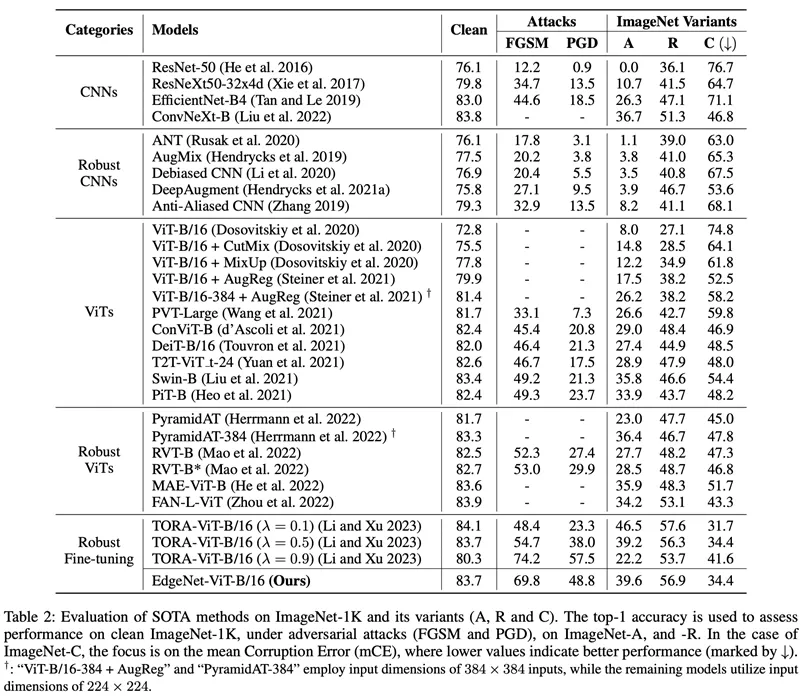
Darüber hinaus führte der Autor auch Black-Box-Angriffsexperimente durch (Tabelle 3). Experimentelle Ergebnisse zeigen, dass EdgeNet auch Black-Box-Angriffen sehr effektiv widerstehen kann.
Fazit
In dieser Arbeit schlug der Autor eine neue Methode namens EdgeNet vor, die die Robustheit tiefer neuronaler Netze (insbesondere ViTs) verbessern kann, indem sie Kanteninformationen nutzt, die aus Sexbildern extrahiert werden.
Dies ist ein leichtes Modul, das nahtlos in bestehende Netzwerke integriert werden kann und die Widerstandsfähigkeit gegen Gegner effektiv verbessern kann. Experimente haben gezeigt, dass EdgeNet effizient ist – es bringt nur minimalen zusätzlichen Rechenaufwand mit sich.
Darüber hinaus verfügt EdgeNet über eine breite Anwendbarkeit auf verschiedene robuste Benchmarks. Dies macht es zu einer bemerkenswerten Entwicklung auf diesem Gebiet.
Darüber hinaus bestätigen experimentelle Ergebnisse, dass EdgeNet gegnerischen Angriffen wirksam widerstehen und die Genauigkeit sauberer Bilder aufrechterhalten kann, was das Potenzial von Kanteninformationen als robustes und relevantes Merkmal bei visuellen Klassifizierungsaufgaben unterstreicht.
Es ist erwähnenswert, dass die Robustheit von EdgeNet nicht auf gegnerische Angriffe beschränkt ist, sondern auch Angriffe abdeckt, die natürliche gegnerische Beispiele (ImageNet-A), Daten außerhalb der Verteilung (ImageNet-R) und allgemeine Zerstörung (ImageNet-C) umfassen .
Diese umfassendere Anwendung unterstreicht die Vielseitigkeit von EdgeNet und zeigt sein Potenzial als umfassende Lösung für die vielfältigen Herausforderungen bei visuellen Klassifizierungsaufgaben.
Das obige ist der detaillierte Inhalt vonEin kostengünstiger Algorithmus verbessert die Robustheit der visuellen Klassifizierung erheblich! Chinesisches Team der Universität Sydney veröffentlicht neue EdgeNet-Methode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
