
 Technologie-Peripheriegeräte
KI
Brechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen
Technologie-Peripheriegeräte
KI
Brechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen
Brechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen

Der „Umkehrfluch“ des großen Sprachmodells wurde gelöst!
Dieser Fluch wurde erstmals im September letzten Jahres entdeckt, was sofort für Aufschrei bei LeCun, Karpathy, Marcus und anderen großen Kerlen sorgte.

Denn das beispiellose und arrogante große Modell hat tatsächlich eine „Achillesferse“: Ein auf „A ist B“ trainiertes Sprachmodell kann nicht richtig mit „Ist B A“ antworten.
Zum Beispiel das folgende Beispiel: LLM weiß eindeutig, dass „Tom Cruises Mutter Mary Lee Pfeiffer ist“, kann aber nicht antworten: „Mary Lee Pfeiffers Kind ist Tom Cruise“.

——Dies war zu dieser Zeit das fortschrittlichste GPT-4. Daher konnten selbst Kinder über normales logisches Denken verfügen, LLM jedoch nicht.
Basierend auf umfangreichen Daten hat er ein Wissen gespeichert, das fast allen Menschen überlegen ist, und verhält sich dennoch so langweilig. Er hat das Feuer der Weisheit erlangt, ist aber für immer in diesem Fluch gefangen.

Papieradresse: https://arxiv.org/pdf/2309.12288v1.pdf
Sobald dieser Vorfall bekannt wurde, war das gesamte Netzwerk in Aufruhr.
Einerseits sagten Internetnutzer, dass das große Modell wirklich dumm sei, wirklich. Da ich nur „A ist B“ wusste, aber nicht wusste, „B ist A“, behielt ich schließlich meine Würde als Mensch.
Andererseits haben auch Forscher begonnen, dies zu untersuchen und arbeiten hart daran, diese große Herausforderung zu lösen.
Kürzlich haben Forscher von Meta FAIR eine Reverse-Training-Methode eingeführt, um den „Umkehrfluch“ von LLM auf einen Schlag zu lösen.
Papieradresse: https://arxiv.org/pdf/2403.13799.pdf
Die Forscher beobachteten zunächst, dass LLMs autoregressiv von links nach rechts trainiert werden – das ist möglich, das ist die Ursache die Umkehrung des Fluches.
Wenn Sie also LLM (Reverse Training) in der Rechts-nach-Links-Richtung trainieren, ist es für das Modell möglich, die Fakten in umgekehrter Richtung zu sehen.
Umgekehrter Text kann als Zweitsprache behandelt werden, indem mehrere verschiedene Quellen durch Multitasking oder sprachübergreifendes Vortraining genutzt werden.
Die Forscher betrachteten 4 Inversionstypen: Token-Inversion, Wortinversion, entitätserhaltende Inversion und zufällige Segmentinversion.
Token- und Wortumkehr, indem die Sequenz in Token bzw. Wörter aufgeteilt und deren Reihenfolge umgekehrt wird, um eine neue Sequenz zu bilden.
Entity Preserving Reverse findet Entitätsnamen in einer Sequenz und behält die Wortreihenfolge von links nach rechts darin bei, während die Wortumkehr durchgeführt wird.
Zufällige Segmentinversion teilt die tokenisierte Sequenz in Blöcke zufälliger Länge auf und behält dann die Reihenfolge von links nach rechts innerhalb jedes Blocks bei.
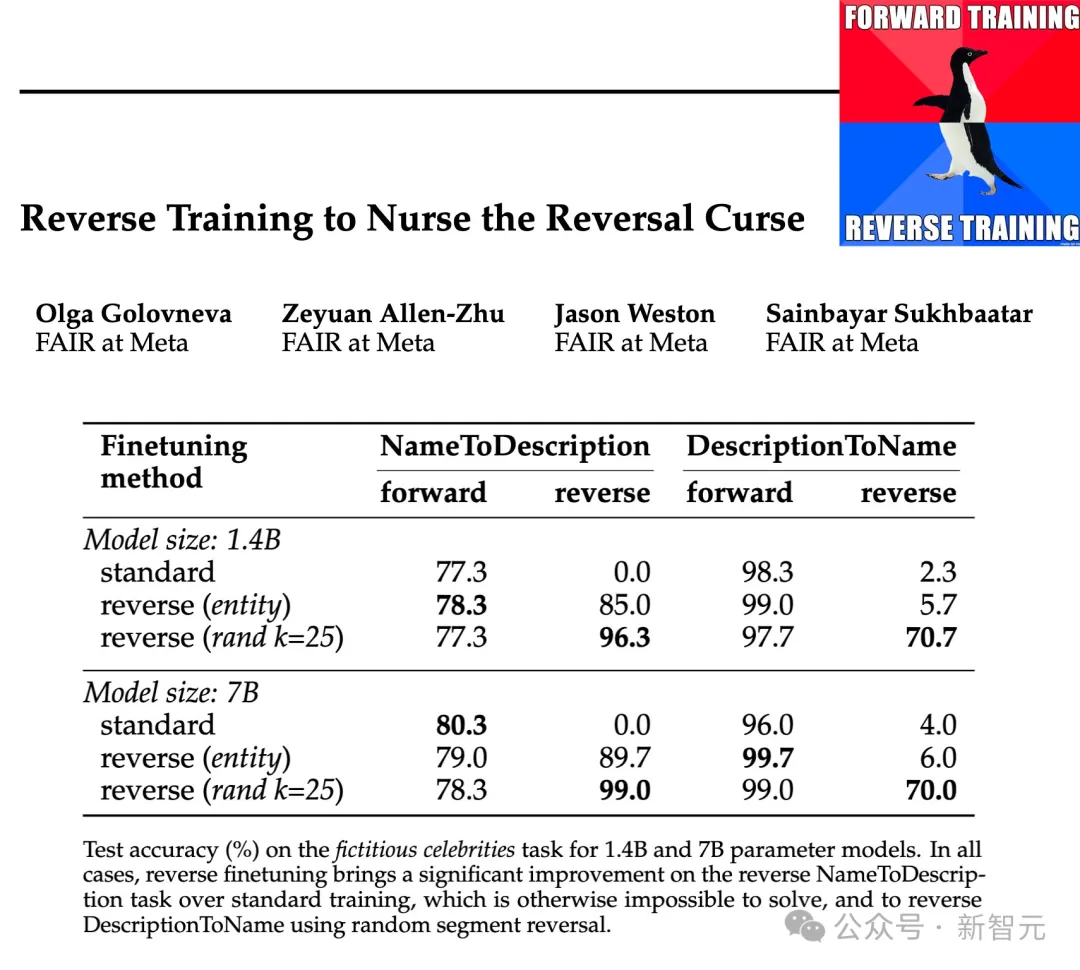
Die Forscher testeten die Wirksamkeit dieser Inversionstypen auf Parameterskalen von 1,4B und 7B, und die Ergebnisse zeigten, dass entitätserhaltendes und randomisiertes stückweises Inversionstraining den Inversionsfluch abschwächen, in manchen Fällen sogar vollständig beseitigen kann.
Darüber hinaus fanden die Forscher auch heraus, dass die Umkehrung vor dem Training die Leistung des Modells im Vergleich zum Standardtraining von links nach rechts verbesserte – sodass das Umkehrtraining als allgemeine Trainingsmethode verwendet werden kann.
Reverse-Trainingsmethode
Reverse-Training umfasst das Erhalten eines Trainingsdatensatzes mit N Stichproben und die Erstellung eines umgekehrten Stichprobensatzes REVERSE (x).
Die Funktion REVERSE ist wie folgt für die Umkehrung einer bestimmten Zeichenfolge verantwortlich:
Wortumkehr: Jedes Beispiel wird zuerst in Wörter aufgeteilt, und dann wird die Zeichenfolge auf Wortebene umgekehrt, wobei Leerzeichen miteinander verbunden werden.
Entitätserhaltende Inversion: Führen Sie einen Entitätsdetektor für ein bestimmtes Trainingsbeispiel aus und teilen Sie dabei auch Nicht-Entitäten in Wörter auf. Dann werden die Wörter, die keine Entitäten sind, umgekehrt, während die Wörter, die Entitäten darstellen, ihre ursprüngliche Wortreihenfolge beibehalten.
Zufällige Segmentumkehr: Anstatt einen Entitätsdetektor zu verwenden, versuchen wir, eine einheitliche Stichprobe zu verwenden, um die Sequenz zufällig in Segmente mit Größen zwischen 1 und k Token aufzuteilen, und kehren diese Segmente dann um, behalten aber die Wortreihenfolge innerhalb von a bei Anschließend werden die Segmente mit dem speziellen Token [REV] verbunden.
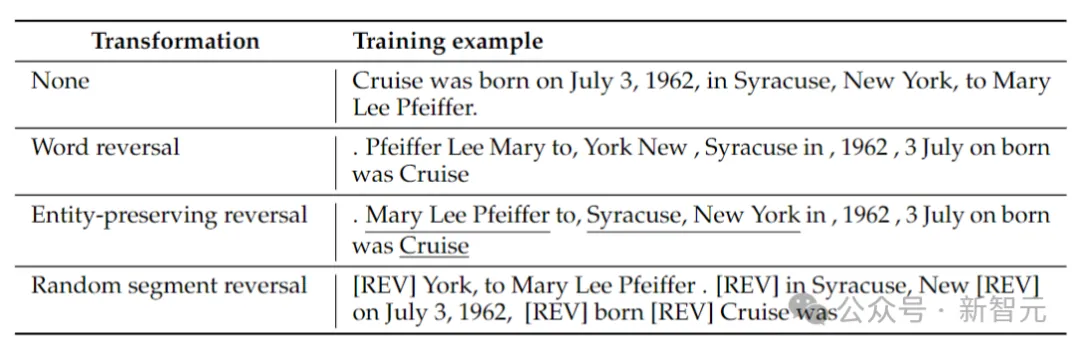
Die obige Tabelle enthält Beispiele für verschiedene Arten der Inversion einer bestimmten Zeichenfolge.
Zu diesem Zeitpunkt wird das Sprachmodell noch von links nach rechts trainiert. Bei der Wortumkehr entspricht dies der Vorhersage von Sätzen von rechts nach links.
Inverses Training umfasst das Training an Standard- und Reverse-Beispielen, sodass die Anzahl der Trainingstokens verdoppelt wird, während sowohl Vorwärts- als auch Reverse-Trainingsbeispiele gemischt werden.
Die Umkehrtransformation kann als zweite Sprache angesehen werden, die das Modell lernen muss. Während der Umkehrung bleibt die Beziehung zwischen den Fakten unverändert und das Modell kann anhand der Grammatik beurteilen, ob es sich um eine Vorwärts- oder Rückwärtssprache handelt Vorhersagemodell.
Eine andere Perspektive des inversen Trainings kann durch die Informationstheorie erklärt werden: Das Ziel der Sprachmodellierung besteht darin, die Wahrscheinlichkeitsverteilung natürlicher Sprache zu lernen
Erstellen Sie zunächst einen einfachen symbolbasierten Datensatz, um den Inversionsfluch in einer kontrollierten Umgebung zu untersuchen.
Paaren Sie die Entitäten a und b zufällig eins zu eins. Die Trainingsdaten enthalten alle (a→b)-Zuordnungspaare, aber nur die Hälfte der (b→a)-Zuordnungen, und die andere Hälfte dient als Testdaten. Das Modell muss die Regel a→b ⇔ b→a aus den Trainingsdaten ableiten und diese dann auf die Paare in den Testdaten verallgemeinern.
Die obige Tabelle zeigt die Testgenauigkeit (%) der Vorzeichenumkehraufgabe. Trotz der Einfachheit der Aufgabe scheitert das Standard-Sprachmodelltraining vollständig, was darauf hindeutet, dass Skalierung allein das Problem wahrscheinlich nicht lösen kann.
Im Gegensatz dazu kann das umgekehrte Training das Problem von zwei Wortentitäten fast lösen, aber seine Leistung lässt schnell nach, wenn die Entitäten länger werden.
Wortumkehr funktioniert gut für kürzere Entitäten, aber für Entitäten mit mehr Wörtern ist eine entitätserhaltende Umkehrung erforderlich. Die zufällige Segmentumkehr funktioniert gut, wenn die maximale Segmentlänge k mindestens so lang wie die Entität ist. 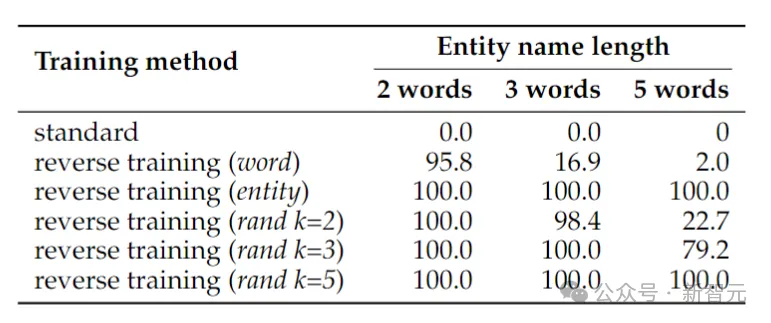
Wiederherstellen der Namen von Personen
Die obige Tabelle zeigt die Umkehraufgabe zur Bestimmung des vollständigen Namens einer Person, wenn zur Bestimmung des Namens einer Person nur das Geburtsdatum angegeben wird Der vollständige Name liegt immer noch nahe bei Null. Dies liegt daran, dass in der in diesem Artikel verwendeten Entitätserkennungsmethode Datumsangaben als drei Entitäten behandelt werden, sodass ihre Reihenfolge bei der Umkehrung nicht erhalten bleibt. Wenn sich die Umkehraufgabe nur auf die Bestimmung des Nachnamens einer Person beschränkt, reicht die Umkehrung auf Wortebene aus.
Ein weiteres Phänomen, das überraschen könnte, ist, dass die Entity-Retention-Methode den vollständigen Namen der Person ermitteln kann, nicht jedoch den Nachnamen der Person. 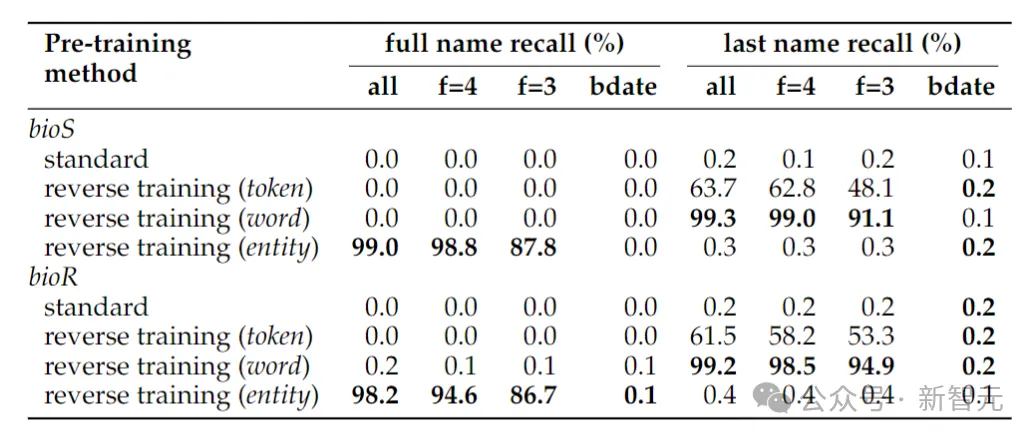
Dies ist ein bekanntes Phänomen: Sprachmodelle sind möglicherweise überhaupt nicht in der Lage, späte Token von Wissensfragmenten (z. B. Nachnamen) abzurufen.
Fakten aus der realen Welt
Hier trainierte der Autor ein Llama-2-Modell mit 1,4 Milliarden Parametern und trainierte ein Basismodell von 2 Billionen Token in der Richtung von links nach rechts.
Im Gegensatz dazu verwendet das inverse Training nur 1 Billion Token, verwendet jedoch dieselbe Datenteilmenge, um in zwei Richtungen zu trainieren, von links nach rechts und von rechts nach links – die beiden Richtungen zusammen ergeben 2 Billionen Token, was Fairness und Gerechtigkeit in Bezug auf die Bedingungen gewährleistet der Rechenressourcen. Um die Umkehrung realer Fakten zu testen, verwendeten die Forscher eine Promi-Aufgabe, die Fragen wie „Wer ist die Mutter einer Berühmtheit?“ sowie anspruchsvollere Umkehrfragen umfasste, zum Beispiel „Wer sind die Kinder einer bestimmten Person?“ Eltern der Berühmtheit?“ Die Ergebnisse sind in der Tabelle oben aufgeführt. Die Forscher untersuchten die Modelle mehrmals für jede Frage und betrachteten es als Erfolg, wenn eines davon die richtige Antwort enthielt. Im Allgemeinen ist die Genauigkeit normalerweise relativ gering, da das Modell hinsichtlich der Anzahl der Parameter klein ist, nur über begrenztes Vortraining verfügt und es an Feinabstimmung mangelt. Das umgekehrte Training schnitt jedoch noch besser ab. 1988 veröffentlichten Fodor und Pylyshyn in der Zeitschrift „Cognition“ einen Artikel über die Systematik des Denkens. Wenn Sie diese Welt wirklich verstehen, sollten Sie in der Lage sein, die Beziehung zwischen a und b und die Beziehung zwischen b und a zu verstehen. Auch nonverbale kognitive Wesen sollten dazu in der Lage sein. 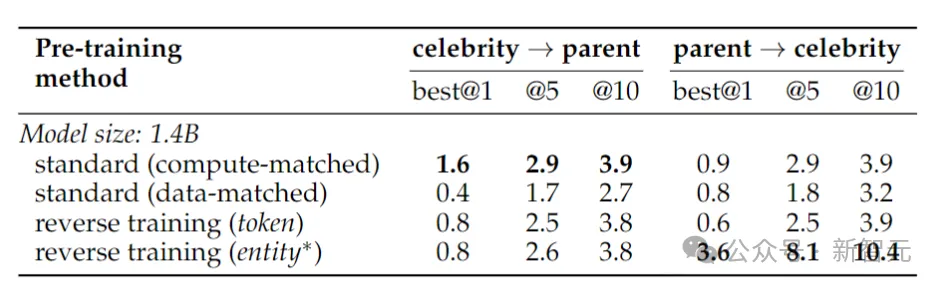
Prophezeiung vor 36 Jahren

Das obige ist der detaillierte Inhalt vonBrechen Sie den Fluch vor 36 Jahren! Meta führt eine Reverse-Training-Methode ein, um den „Umkehrfluch' großer Modelle zu beseitigen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
CentOS Shutdown -Befehlszeile
Apr 14, 2025 pm 09:12 PM
Der Befehl centOS stilldown wird heruntergefahren und die Syntax wird von [Optionen] ausgeführt [Informationen]. Zu den Optionen gehören: -h das System sofort stoppen; -P schalten Sie die Leistung nach dem Herunterfahren aus; -r neu starten; -t Wartezeit. Zeiten können als unmittelbar (jetzt), Minuten (Minuten) oder als bestimmte Zeit (HH: MM) angegeben werden. Hinzugefügten Informationen können in Systemmeldungen angezeigt werden.
 So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
So überprüfen Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:21 PM
Vollständige Anleitung zur Überprüfung der HDFS -Konfiguration in CentOS -Systemen In diesem Artikel wird die Konfiguration und den laufenden Status von HDFS auf CentOS -Systemen effektiv überprüft. Die folgenden Schritte helfen Ihnen dabei, das Setup und den Betrieb von HDFs vollständig zu verstehen. Überprüfen Sie die Hadoop -Umgebungsvariable: Stellen Sie zunächst sicher, dass die Hadoop -Umgebungsvariable korrekt eingestellt ist. Führen Sie im Terminal den folgenden Befehl aus, um zu überprüfen, ob Hadoop ordnungsgemäß installiert und konfiguriert ist: Hadoopsion-Check HDFS-Konfigurationsdatei: Die Kernkonfigurationsdatei von HDFS befindet sich im/etc/hadoop/conf/verzeichnis, wobei core-site.xml und hdfs-site.xml von entscheidender Bedeutung sind. verwenden
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
So sehen Sie sich Gitlab -Protokolle unter CentOS
Apr 14, 2025 pm 06:18 PM
Eine vollständige Anleitung zum Anzeigen von GitLab -Protokollen unter CentOS -System In diesem Artikel wird in diesem Artikel verschiedene GitLab -Protokolle im CentOS -System angezeigt, einschließlich Hauptprotokolle, Ausnahmebodi und anderen zugehörigen Protokollen. Bitte beachten Sie, dass der Log -Dateipfad je nach GitLab -Version und Installationsmethode variieren kann. Wenn der folgende Pfad nicht vorhanden ist, überprüfen Sie bitte das GitLab -Installationsverzeichnis und die Konfigurationsdateien. 1. Zeigen Sie das Hauptprotokoll an. Verwenden Sie den folgenden Befehl, um die Hauptprotokolldatei der GitLabRails-Anwendung anzuzeigen: Befehl: Sudocat/var/log/gitlab/gitlab-rails/production.log Dieser Befehl zeigt das Produkt an
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
