
 Technologie-Peripheriegeräte
KI
CVPR 2024 |. Hat die Segmentierung aller Modelle eine schlechte Generalisierungsfähigkeit von SAM? Strategie zur Domänenanpassung gelöst
Technologie-Peripheriegeräte
KI
CVPR 2024 |. Hat die Segmentierung aller Modelle eine schlechte Generalisierungsfähigkeit von SAM? Strategie zur Domänenanpassung gelöst
CVPR 2024 |. Hat die Segmentierung aller Modelle eine schlechte Generalisierungsfähigkeit von SAM? Strategie zur Domänenanpassung gelöst

Die erste Domain-Anpassungsstrategie für das große Modell „Segment Anything“ ist da! Verwandte Beiträge wurden vom CVPR 2024 angenommen. Der Erfolg großer Sprachmodelle (LLMs) hat das Gebiet der Computer Vision dazu inspiriert, grundlegende Modelle für die Segmentierung zu erforschen. Diese grundlegenden Segmentierungsmodelle werden normalerweise für die Null-/Wenige-Bildsegmentierung durch Prompt Engineer verwendet. Unter diesen ist das Segment Anything Model (SAM) das fortschrittlichste Grundmodell für die Bildsegmentierung.个 Picture SAM hat bei mehreren Downstream-Aufgaben eine schlechte Leistung erbracht, aber neuere Untersuchungen zeigen, dass SAM bei vielen Downstream-Aufgaben nicht sehr leistungsfähig und verallgemeinert ist, wie z. B. schlechte Leistung bei medizinischen Bildern, getarnten Objekten, natürlichen Bildern mit zusätzlichen Interferenzen usw. Dies kann auf die große „Domänenverschiebung“ zwischen dem Trainingsdatensatz und dem Downstream-Testdatensatz zurückzuführen sein. Daher ist eine sehr wichtige Frage: Wie kann ein Domänenanpassungsschema entworfen werden, um SAM robuster gegenüber der realen Welt und verschiedenen nachgelagerten Aufgaben zu machen?
Die Anpassung von vorab trainiertem SAM an nachgelagerte Aufgaben steht hauptsächlich vor drei Herausforderungen:
Quelldatensatz und Zieldatensatz, da der Datenschutz und die Rechenkosten geringer sind machbar.
Zweitens ist bei der Domänenanpassung die Aktualisierung aller Gewichtungen in der Regel leistungsstärker, wird aber auch durch  teure Speicherkosten
teure Speicherkosten
Robustheit und Recheneffizienz
Gewichtungszerlegung mit niedrigem Rang
Um den Effekt der passiven Domänenanpassung weiter zu verbessern, führen wir in der Zieldomäne eine schwache Überwachung ein, z. B. Annotationen mit geringer Punktdichte, um gleichzeitig stärkere Domänenanpassungsinformationen bereitzustellen Eine Art schwache Überwachung ist natürlich mit dem Cue-Encoder in SAM kompatibel. Mit schwacher Aufsicht als Prompt erhalten wir mehr lokale und explizite selbst trainierte Pseudo-Labels. Das abgestimmte Modell zeigt eine stärkere Generalisierungsfähigkeit bei mehreren nachgelagerten Aufgaben. Wir fassen die Beiträge dieser Arbeit wie folgt zusammen:
 2. Wir verwenden schwache Überwachung, einschließlich Box-, Punkt- und anderen Etiketten, um den adaptiven Effekt zu verbessern. Diese schwach überwachten Etiketten sind vollständig kompatibel mit dem Prompt-Encoder von SAM.
2. Wir verwenden schwache Überwachung, einschließlich Box-, Punkt- und anderen Etiketten, um den adaptiven Effekt zu verbessern. Diese schwach überwachten Etiketten sind vollständig kompatibel mit dem Prompt-Encoder von SAM.
Papieradresse: https://arxiv.org/pdf/2312.03502.pdf Projektadresse: https://github.com/Zhang-Haojie/WeSAM Papiertitel: Improving the Generalization of Segmentierungsgrundmodell unter Verteilungsverschiebung durch schwach überwachte Anpassung
-
Segment Anything Model Basierend auf Selbsttraining Wie das adaptive Framework schwache Aufsicht dabei hilft, ein effektives Selbsttraining zu erreichen -
Low-Rank-Gewichtsaktualisierung
Schüler-Lehrer-Architektur zur Selbstausbildung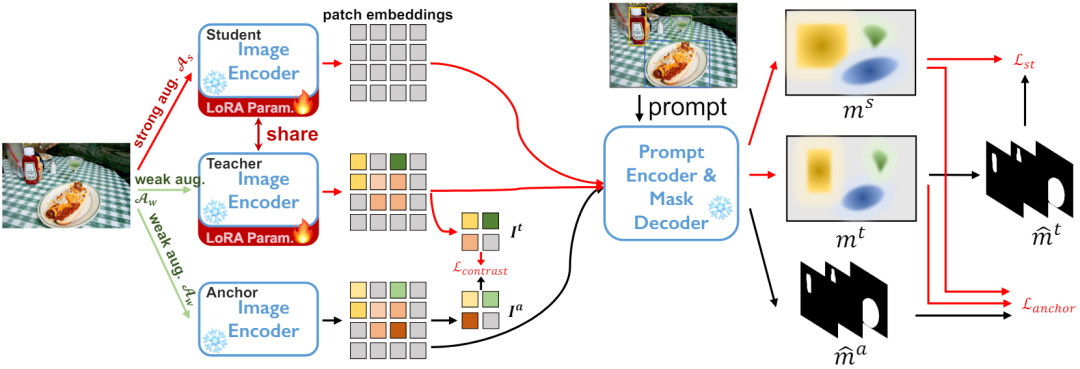 . Wie in Abbildung 2 dargestellt, unterhalten wir drei Encodernetzwerke, nämlich Ankermodell, Schülermodell und Lehrermodell, wobei die Schüler- und Lehrermodelle die gleiche Gewichtung haben.
. Wie in Abbildung 2 dargestellt, unterhalten wir drei Encodernetzwerke, nämlich Ankermodell, Schülermodell und Lehrermodell, wobei die Schüler- und Lehrermodelle die gleiche Gewichtung haben.
Wir führen eine Regularisierung durch Ankerverlust durch, wie in Gleichung 3 gezeigt, 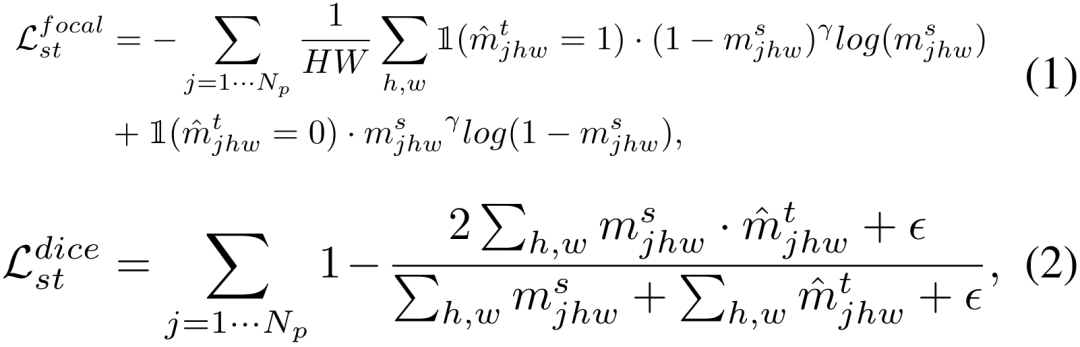 minimiert den Würfelverlust
minimiert den Würfelverlust
下 Vergleichsverlust der beiden Zweige in Abbildung 3
Die beiden oben genannten Trainingsziele werden im Ausgaberaum des Decoders ausgeführt. Der experimentelle Teil zeigt, dass die Aktualisierung des Encoder-Netzwerks die effizienteste Methode zur Anpassung von SAM ist. Daher ist es notwendig, die Regularisierung direkt auf die vom
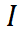
der Temperaturkoeffizient ist. 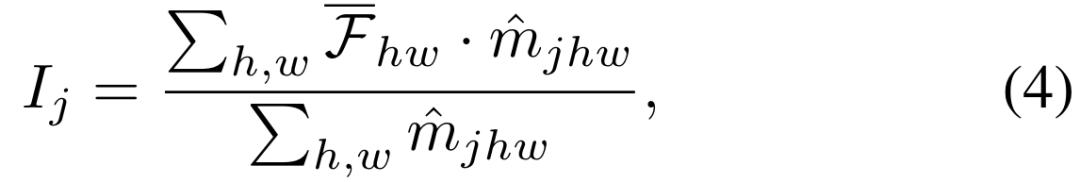
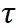
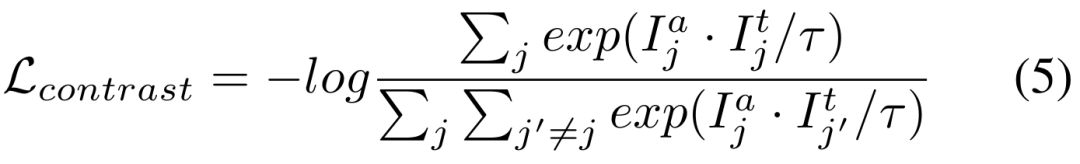
Segment-Anything-Modell: Aufgrund von Speicherbeschränkungen verwenden wir ViT-B als Encoder-Netzwerk. Verwenden Sie den Standard-Hinweis-Encoder und den Masken-Decoder. 
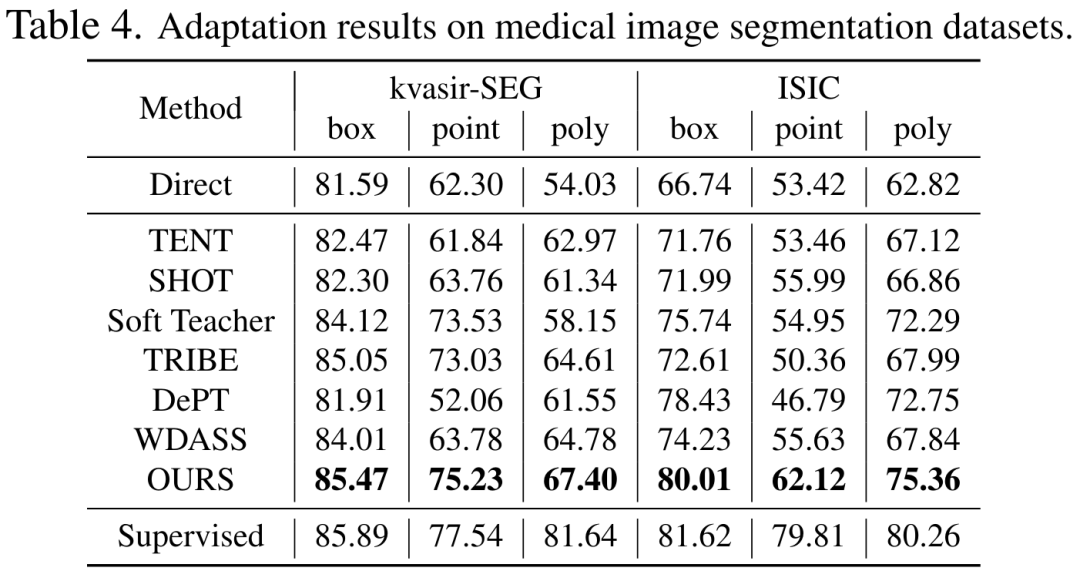

Wir haben den Leistungsunterschied zwischen Training und Tests anhand verschiedener Kategorien von Eingabeaufforderungen analysiert, wie in Tabelle 8 dargestellt. Experimente zeigen, dass unser Schema unter Cross-Prompt-Bedingungen immer noch gut funktioniert. 
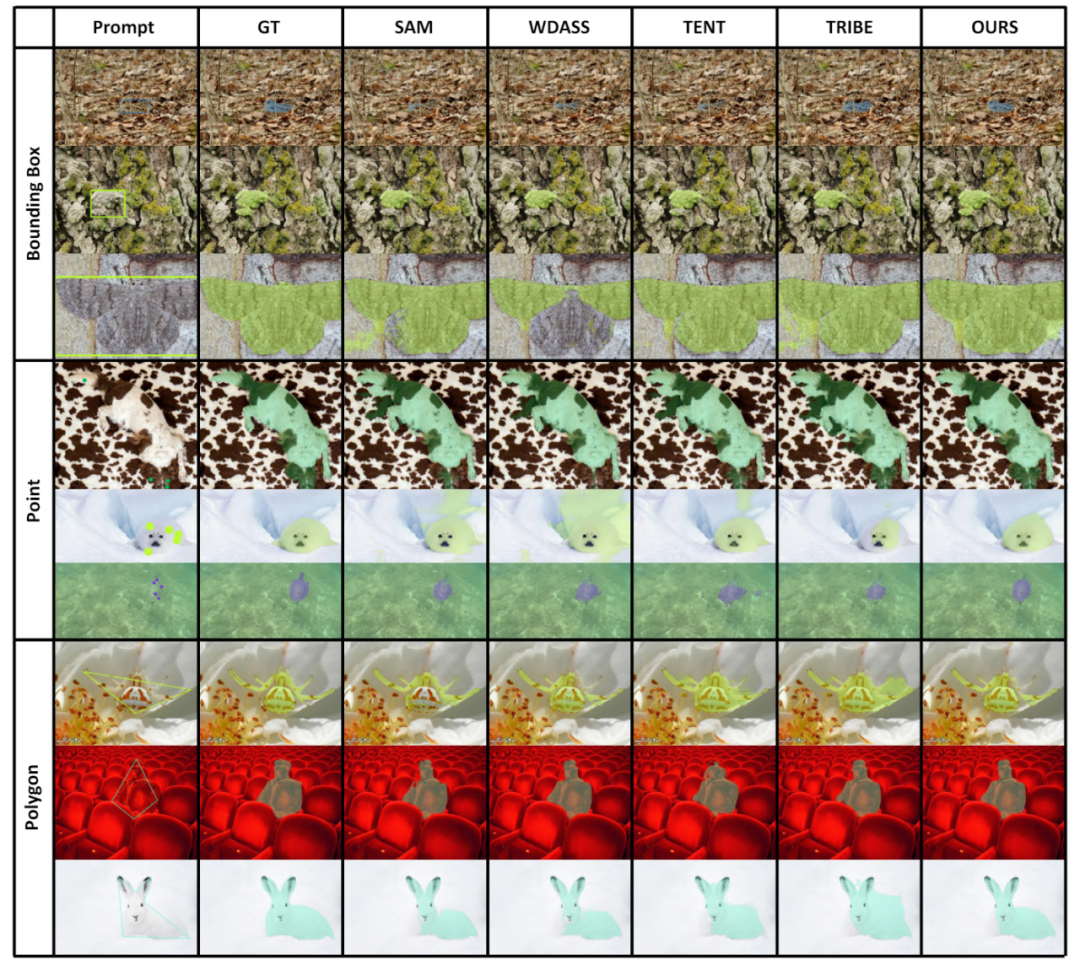
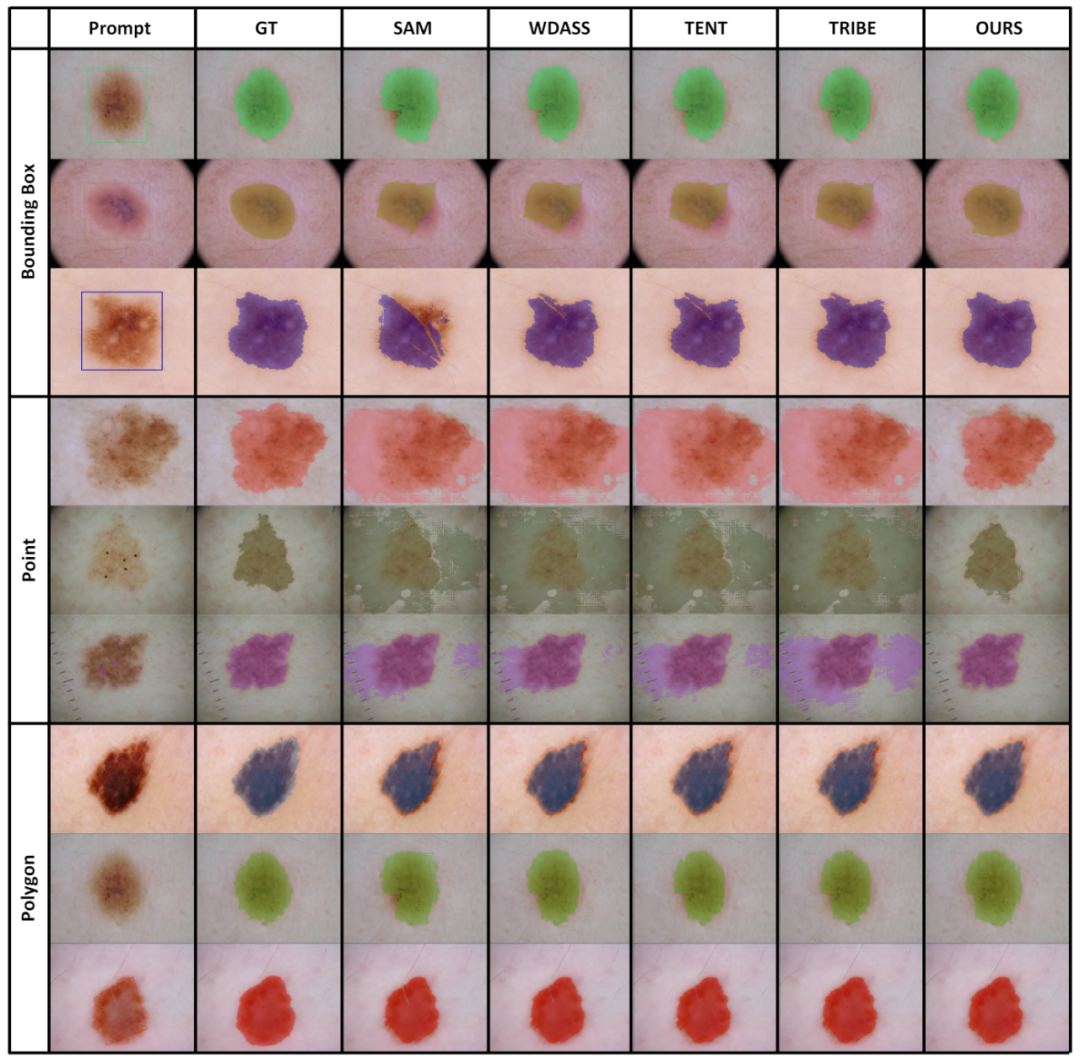
Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Hat die Segmentierung aller Modelle eine schlechte Generalisierungsfähigkeit von SAM? Strategie zur Domänenanpassung gelöst. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
Befolgen Sie die folgenden Schritte, um ein Git -Repository zu löschen: Bestätigen Sie das Repository, das Sie löschen möchten. Lokale Löschen des Repositorys: Verwenden Sie den Befehl rm -RF, um seinen Ordner zu löschen. Löschen Sie ein Lager aus der Ferne: Navigieren Sie zu den Lagereinstellungen, suchen Sie die Option "Lager löschen" und bestätigen Sie den Betrieb.
 Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Git Commit ist ein Befehl, mit dem Dateien Änderungen an einem Git -Repository aufgezeichnet werden, um einen Momentaufnahme des aktuellen Status des Projekts zu speichern. So verwenden Sie dies wie folgt: Fügen Sie Änderungen in den temporären Speicherbereich hinzu, schreiben Sie eine prägnante und informative Einreichungsnachricht, um die Einreichungsnachricht zu speichern und zu beenden, um die Einreichung optional abzuschließen: Fügen Sie eine Signatur für die Einreichungs -Git -Protokoll zum Anzeigen des Einreichungsinhalts hinzu.
 Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Auflösung: Wenn die Git -Download -Geschwindigkeit langsam ist, können Sie die folgenden Schritte ausführen: Überprüfen Sie die Netzwerkverbindung und versuchen Sie, die Verbindungsmethode zu wechseln. Optimieren Sie die GIT-Konfiguration: Erhöhen Sie die Post-Puffer-Größe (GIT-Konfiguration --global http.postbuffer 524288000) und verringern Sie die Niedriggeschwindigkeitsbegrenzung (GIT-Konfiguration --global http.lowSpeedLimit 1000). Verwenden Sie einen GIT-Proxy (wie Git-Proxy oder Git-LFS-Proxy). Versuchen Sie, einen anderen Git -Client (z. B. Sourcetree oder Github Desktop) zu verwenden. Überprüfen Sie den Brandschutz
 So stellen Sie eine Verbindung zum öffentlichen Netzwerk von Git Server her
Apr 17, 2025 pm 02:27 PM
So stellen Sie eine Verbindung zum öffentlichen Netzwerk von Git Server her
Apr 17, 2025 pm 02:27 PM
Das Verbinden eines Git -Servers mit dem öffentlichen Netzwerk enthält fünf Schritte: 1. Einrichten der öffentlichen IP -Adresse; 2. Öffnen Sie den Firewall -Port (22, 9418, 80/443); 3. Konfigurieren Sie den SSH -Zugriff (Generieren Sie Schlüsselpaare, erstellen Benutzer). 4. Konfigurieren Sie HTTP/HTTPS -Zugriff (installieren Server, Konfigurieren Sie Berechtigungen); 5. Testen Sie die Verbindung (mit SSH -Client- oder Git -Befehlen).
 Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Der Code -Konflikt bezieht sich auf einen Konflikt, der auftritt, wenn mehrere Entwickler denselben Code -Stück ändern und GIT veranlassen, sich zu verschmelzen, ohne automatisch Änderungen auszuwählen. Zu den Auflösungsschritten gehören: Öffnen Sie die widersprüchliche Datei und finden Sie den widersprüchlichen Code. Führen Sie den Code manuell zusammen und kopieren Sie die Änderungen, die Sie in den Konfliktmarker halten möchten. Löschen Sie die Konfliktmarke. Änderungen speichern und einreichen.
 So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
Um Projekte lokal über Git herunterzuladen, befolgen Sie die folgenden Schritte: Installieren Sie Git. Navigieren Sie zum Projektverzeichnis. Klonen des Remote-Repositorys mit dem folgenden Befehl: Git Clone https://github.com/username/repository-name.git.git
 Wie man nach der GIT -Einreichung zurückkehrt
Apr 17, 2025 pm 01:06 PM
Wie man nach der GIT -Einreichung zurückkehrt
Apr 17, 2025 pm 01:06 PM
Um ein Git -Commit zurückzufallen, können Sie den Befehl git reset -harter Head ~ n verwenden, wobei N die Anzahl der Commits zu Fallback darstellt. Zu den detaillierten Schritten gehören: Bestimmen Sie die Anzahl der zu rolvierten Commits. Verwenden Sie die Option -HART, um einen Fallback zu erzwingen. Führen Sie den Befehl aus, um auf das angegebene Commit zurückzufallen.
 So generieren Sie SSH -Schlüssel in Git
Apr 17, 2025 pm 01:36 PM
So generieren Sie SSH -Schlüssel in Git
Apr 17, 2025 pm 01:36 PM
Um sich sicher eine Verbindung zu einem Remote -Git -Server herzustellen, muss ein SSH -Schlüssel mit öffentlichen und privaten Schlüssel generiert werden. Die Schritte zur Generierung eines SSH -Schlüssels sind wie folgt: Öffnen Sie das Terminal und geben Sie den Befehl SSH -Keygen -t RSA -B 4096 ein. Wählen Sie den Schlüsselspeicherort aus. Geben Sie einen Kennwortphrase ein, um den privaten Schlüssel zu schützen. Kopieren Sie den öffentlichen Schlüssel auf den Remote -Server. Speichern Sie den privaten Schlüssel ordnungsgemäß, da dies die Anmeldeinformationen für den Zugriff auf das Konto sind.
