
 Technologie-Peripheriegeräte
KI
Mehr als 13-mal schneller als manuelle Arbeit entdeckt „Roboter + KI' den besten Elektrolyten für Batterien und beschleunigt die Materialforschung
Technologie-Peripheriegeräte
KI
Mehr als 13-mal schneller als manuelle Arbeit entdeckt „Roboter + KI' den besten Elektrolyten für Batterien und beschleunigt die Materialforschung
Mehr als 13-mal schneller als manuelle Arbeit entdeckt „Roboter + KI' den besten Elektrolyten für Batterien und beschleunigt die Materialforschung

 Herausgeber |. Ziluo
Herausgeber |. Ziluo
Das traditionelle Materialforschungs- und -entwicklungsmodell basiert hauptsächlich auf experimentellen „Versuch-und-Irrtum“-Methoden oder zufälligen Entdeckungen, und sein Forschungs- und Entwicklungsprozess dauert normalerweise 10–20 Jahre.
Datengesteuerte Methoden basierend auf maschinellem Lernen (ML) können das Design neuer Materialien für saubere Energietechnologien beschleunigen. Allerdings ist seine praktische Anwendung in der Materialforschung aufgrund des Mangels an umfangreichen experimentellen Datenbanken mit hoher Wiedergabetreue noch begrenzt.
Kürzlich hat das Forschungsteam des Pacific Northwest National Laboratory und des Argonne National Laboratory in den Vereinigten Staaten einen hochautomatisierten Arbeitsablauf entwickelt, der eine Hochdurchsatz-Experimentalplattform mit dem fortschrittlichsten aktiven Lernalgorithmus kombiniert, um Anoden effektiv zu screenen. Der Elektrolyt ist ein Binärsystem organisches Lösungsmittel mit optimaler Löslichkeit. Ziel dieser Forschung ist es, die Leistung und Stabilität von Energiespeichersystemen zu verbessern, um den breiten Einsatz erneuerbarer Energien zu fördern. Traditionell erfordert die Forschung mit Anolyten in der Regel viele Versuch-und-Irrtum-Experimente, was zeit- und arbeitsintensiv ist. Und mithilfe dieses automatisierten Workflows können Forscher geeignete Binärdateien schneller aussortieren.
Zusätzlich zu einem effizienten Workflow zur Entwicklung leistungsstarker Redox-Flow-Batterien bietet diese durch maschinelles Lernen gesteuerte Roboterplattform mit hohem Durchsatz einen leistungsstarken und vielseitigen Ansatz die Entdeckung funktioneller Materialien beschleunigen.
Der Gutachter kommentierte: „Diese Studie zeigt, dass eine KI-gesteuerte Roboterplattform effektiv nicht-intuitive Kombinationen von Lösungsmitteln und Elektrolyten in Energieanwendungen finden kann. Diese Arbeit hat wichtige Implikationen für die Batteriegemeinschaft
Die Studie trägt den Titel „ „Eine integrierte Hochdurchsatz-Roboterplattform und ein aktiver Lernansatz zur beschleunigten Entdeckung optimaler Elektrolytformulierungen“ wurde am 29. März 2024 auf „Nature Communications“ veröffentlicht.

Link zum Papier: https://www.nature.com/articles/s41467-024-47070-5
Um die Entwicklung sauberer Energietechnologieanwendungen sicherzustellen und eine tiefgreifende Dekarbonisierung der Elektrizität zu erreichen, ist es von entscheidender Bedeutung , die Designmaterialien mit gezielten funktionalen Eigenschaften für Werkzeuge sind entscheidend für die Entwicklung sauberer Energietechnologieanwendungen und die Erreichung einer umfassenden Dekarbonisierung der Elektrizität. Herkömmliche Trial-and-Error-Methoden sind teuer und zeitaufwändig, daher sind Entwurfstools von Natur aus teuer und zeitsparend.
Die Löslichkeit redoxaktiver Moleküle ist ein wichtiger Faktor bei der Bestimmung der Energiedichte von Redox-Flow-Batterien (RFB). Die Entdeckung von Elektrolytmaterialien ist jedoch durch das Fehlen experimenteller Löslichkeitsdatensätze begrenzt, die für die Nutzung datengesteuerter Ansätze von entscheidender Bedeutung sind.
Dennoch bleibt die Entwicklung hochlöslicher redoxaktiver organischer Moleküle (ROMs) für nichtwässrige RFBs (NRFBs) aufgrund der fehlenden Standardisierung organischer Lösungsmittelsysteme und anwendungsrelevanter experimenteller Löslichkeitsdaten eine schwierige Aufgabe.
Durch die Nutzung der Plattform für automatisierte Hochdurchsatzexperimente (HTE) können die Zuverlässigkeit und Effizienz der Methode zur Messung der Löslichkeit „überschüssiger gelöster Stoffe“ verbessert und die Löslichkeitsdatenbank von NRFB erstellt werden. Doch selbst bei HTE-Systemen macht die Vielfalt möglicher Lösungsmittelmischungen den Screening-Prozess zeitaufwändiger und teurer.
Aktives Lernen (AL) und insbesondere die Bayes'sche Optimierung (BO) haben sich als zuverlässige Methode erwiesen, um die Suche nach Elektrolyten zu beschleunigen, die für Energiespeicheranwendungen benötigt werden. Daher kann ein von BO geleiteter experimenteller Arbeitsablauf mit geschlossenem Regelkreis verwendet werden, um die HTE-Ausführung zu minimieren.
ML-gesteuerte experimentelle Roboterplattform mit hohem Durchsatz
Hier verwenden Forscher 2,1,3-Benzothiadiazol (BTZ), einen Hochleistungsanolyten mit einem hohen Grad an delokalisierter Ladungsdichte und guter chemischer Stabilität ein Modell-ROM. Der Schwerpunkt liegt auf der Untersuchung seiner Löslichkeit in verschiedenen organischen Lösungsmitteln, um das Potenzial einer durch maschinelles Lernen gesteuerten Roboterplattform für Hochdurchsatzexperimente (HTE) zur Beschleunigung der Entdeckung von NRFB-Elektrolyten zu demonstrieren.
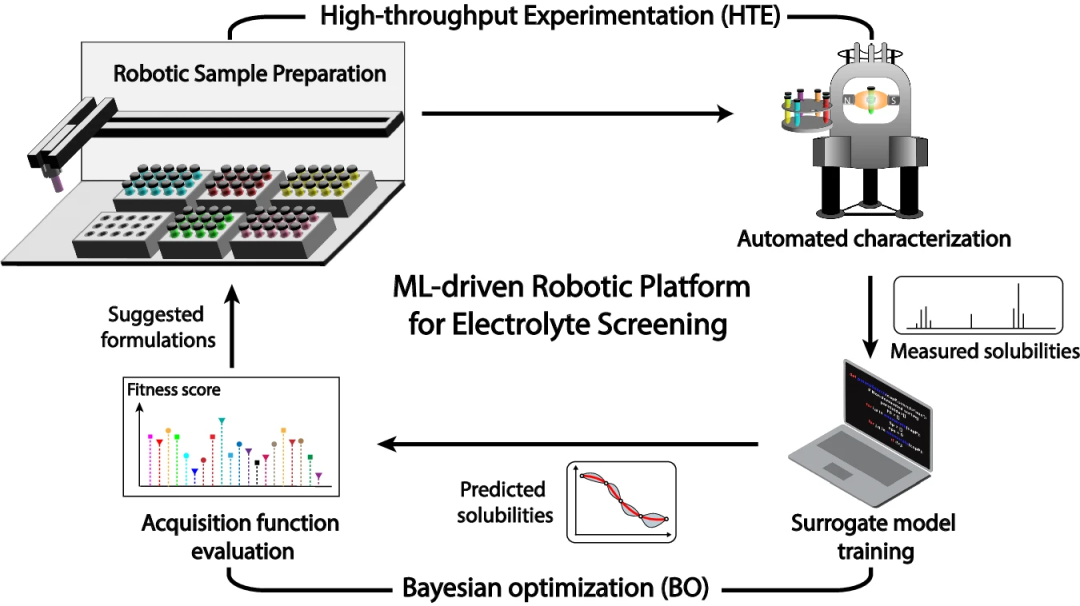
Abbildung: Schematische Darstellung des Elektrolyt-Screening-Prozesses mit geschlossenem Kreislauf basierend auf einer durch maschinelles Lernen (ML) gesteuerten Hochdurchsatz-Versuchsplattform. (Quelle: Papier)
Konkret entwarfen die Forscher einen Lösungsmittel-Screening-Workflow mit geschlossenem Kreislauf, der aus zwei miteinander verbundenen Modulen besteht, nämlich HTE und BO. Das HTE-Modul führt Probenvorbereitung und Löslichkeitsmessungen über eine Roboterplattform mit hohem Durchsatz durch. Die BO-Komponente besteht aus einem Ersatzmodell und einer Erfassungsfunktion, die zusammen als Orakel fungieren, Löslichkeitsvorhersagen treffen und neue Lösungsmittel zur Bewertung vorschlagen.
Der Arbeitsablauf ist in der Abbildung unten dargestellt, die spezifischen Schritte sind:
- Bereiten Sie zunächst die gesättigte ROM-Lösung vor und analysieren Sie die Probe über die HTE-Plattform. Als nächstes wurden Kernspinresonanzspektren (NMR) dieser Proben aufgenommen und die Spektraldaten zur Berechnung der Löslichkeit von ROM verwendet.
- Dieser Datensatz wird dann verwendet, um ein Ersatzmodell zu trainieren, das im Rahmen des BO-Prozesses zur Vorhersage der Löslichkeit ungetesteter Proben innerhalb des Suchraums verwendet wird.
- Die Erfassungsfunktion wird dann innerhalb des BO-Frameworks angewendet, um die Auswahl neuer Proben zu steuern und die Bewertung auf der Grundlage eines Gleichgewichts aus vorhergesagten Löslichkeitswerten und damit verbundenen Unsicherheiten (d. h. Fitness-Scores) zu leiten, wodurch die Entdeckung und Analyse des Potenzials vereinfacht wird Lösungsmittel.
Mehr als 13-mal schneller als die manuelle Probenverarbeitung
Die automatisierte Plattform kann mit minimalem manuellen Eingriff gesättigte Lösungen mit gelösten Stoffüberschüssen und quantitative Kernspinresonanzproben (qNMR) vorbereiten.
Mit dem automatisierten HTE-Workflow betrug die gesamte experimentelle Zeit zur Durchführung der Löslichkeitsmessungen von 42 Proben etwa 27 Stunden (~39 Minuten/Probe, weniger Zeit pro Probe, wenn mehr Proben durchgeführt werden). Dies ist mehr als 13-mal schneller als die manuelle Probenverarbeitung mit der Methode „überschüssiger gelöster Stoff“ (ca. 525 Minuten pro Probe).
Neben der durch das HTE-System bereitgestellten Geschwindigkeitssteigerung legte die Forschung auch großen Wert auf die Kontrolle der Versuchsbedingungen wie Temperatur (20 °C) und Stabilisierungszeit (8 Stunden), um eine genaue Messung der BTZ-Löslichkeit in verschiedenen zu gewährleisten organische Lösungsmittel.
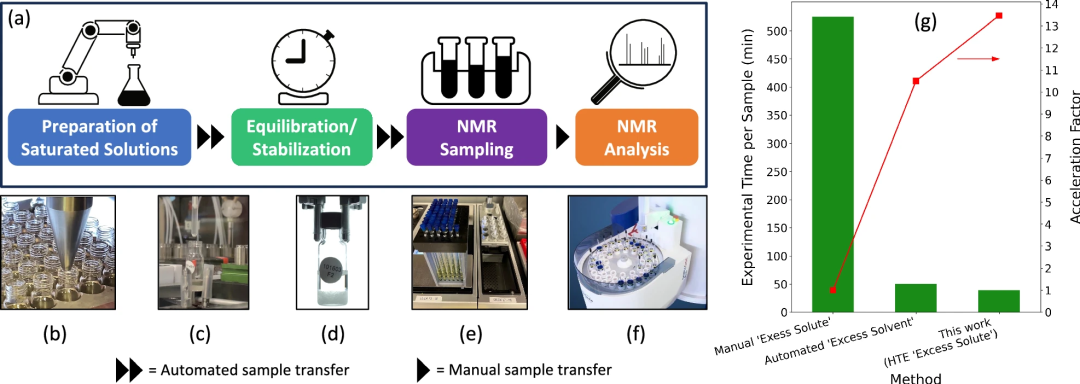
Abbildung: Übersicht über die Plattform für automatisierte Hochdurchsatzexperimente (HTE). (Quelle: Papier)
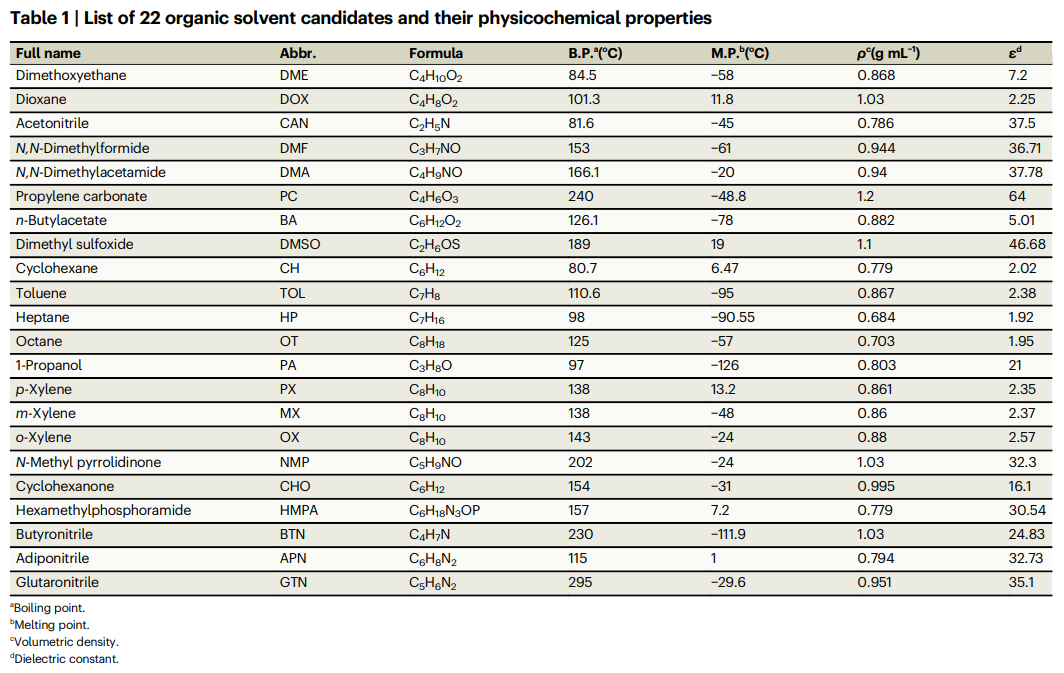
Basierend auf einer Literaturrecherche und der Betrachtung der Lösungsmitteleigenschaften listeten die Forscher 22 potenzielle Lösungsmittelkandidaten für BTZ auf. Anschließend wurden weitere 2079 binäre Lösungsmittel gezählt, indem diese 22 einzelnen Lösungsmittel paarweise mit jeweils 9 verschiedenen Volumenanteilen kombiniert wurden.
Tabelle: Liste der 22 möglichen organischen Lösungsmittel und ihrer physikalischen und chemischen Eigenschaften. (Quelle: Papier)
Die Plattform identifizierte mehrere Lösungsmittel aus einer umfassenden Bibliothek von mehr als 2000 potenziellen Lösungsmitteln mit einer Löslichkeitsschwelle, die das redoxaktive Prototypmolekül 2,1,3-Benzothiadiazol 6,20 M übersteigt. Insbesondere erforderte die umfassende Strategie eine Löslichkeitsbewertung für weniger als 10 % der Arzneimittelkandidaten, was die Effizienz des neuen Ansatzes unterstreicht.
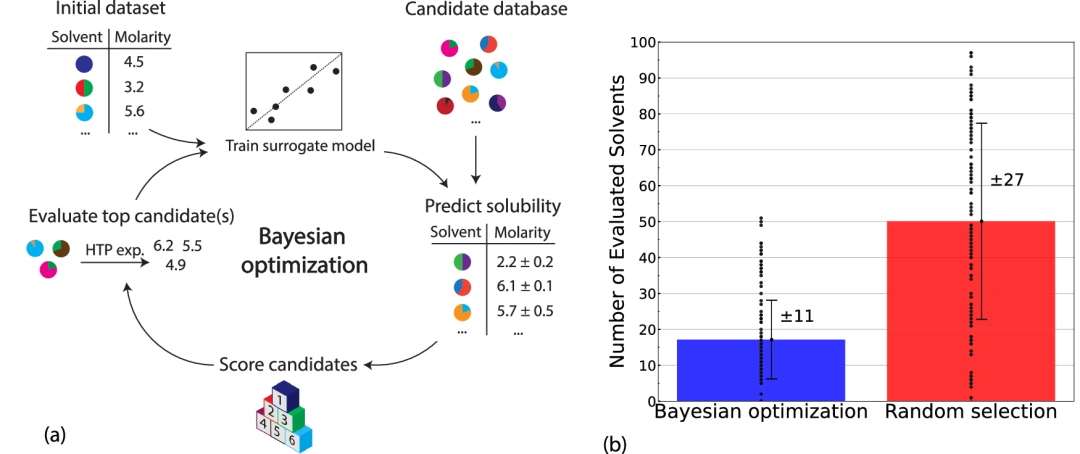
Abbildung: Identifizierung benötigter Elektrolyte mittels Bayes'scher Optimierung (BO). (Quelle: Paper)
Forschungsergebnisse zeigen auch, dass binäre Lösungsmittelmischungen, insbesondere solche, die 1,4-Dioxan (1,4-Dioxan) enthalten, zur Verbesserung der Löslichkeit von BTZ beitragen.
Zusammenfassend demonstriert die Studie eine ML-gesteuerte HTE-Plattform für das Elektrolyt-Screening, bei der ML-Vorhersagen und automatisierte Experimente zusammenarbeiten, um binäre organische Lösungsmittel mit optimaler Löslichkeit für BTZ effektiv zu screenen.
Diese Forschung trägt nicht nur dazu bei, die Bereiche Datenwissenschaft und traditionelle experimentelle Wissenschaft zu verbinden, sondern legt auch den Grundstein für die zukünftige Entwicklung einer autonomen Plattform, die sich dem Batterieelektrolyt-Screening widmet.
Das obige ist der detaillierte Inhalt vonMehr als 13-mal schneller als manuelle Arbeit entdeckt „Roboter + KI' den besten Elektrolyten für Batterien und beschleunigt die Materialforschung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird der Status von Transformer als Mainstream-Architektur großer KI-Modelle durch den multimodalen Trend erschüttert? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Können Large Vision Models (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen sein? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus Week50 2023
 Die Genauigkeitsrate erreicht 60,8 %. Das auf Transformer basierende Modell zur Vorhersage der chemischen Retrosynthese wurde in der Unterzeitschrift „Nature' veröffentlicht
Aug 06, 2024 pm 07:34 PM
Die Genauigkeitsrate erreicht 60,8 %. Das auf Transformer basierende Modell zur Vorhersage der chemischen Retrosynthese wurde in der Unterzeitschrift „Nature' veröffentlicht
Aug 06, 2024 pm 07:34 PM
Herausgeber | KX-Retrosynthese ist eine entscheidende Aufgabe in der Arzneimittelforschung und organischen Synthese, und KI wird zunehmend eingesetzt, um den Prozess zu beschleunigen. Bestehende KI-Methoden weisen eine unbefriedigende Leistung und eine begrenzte Vielfalt auf. In der Praxis verursachen chemische Reaktionen häufig lokale molekulare Veränderungen mit erheblichen Überschneidungen zwischen Reaktanten und Produkten. Davon inspiriert schlug das Team von Hou Tingjun an der Zhejiang-Universität vor, die einstufige retrosynthetische Vorhersage als eine Aufgabe zur Bearbeitung molekularer Ketten neu zu definieren und dabei die Zielmolekülkette iterativ zu verfeinern, um Vorläuferverbindungen zu erzeugen. Außerdem wird ein bearbeitungsbasiertes retrosynthetisches Modell EditRetro vorgeschlagen, mit dem qualitativ hochwertige und vielfältige Vorhersagen erzielt werden können. Umfangreiche Experimente zeigen, dass das Modell beim Standard-Benchmark-Datensatz USPTO-50 K eine hervorragende Leistung mit einer Top-1-Genauigkeit von 60,8 % erzielt.
