
 Technologie-Peripheriegeräte
KI
Ist die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?
Technologie-Peripheriegeräte
KI
Ist die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?
Ist die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?

Wie viel menschliches Wissen kann ein LLM-Sprachmodell im Maßstab 7B speichern? Wie lässt sich dieser Wert quantifizieren? Wie wirken sich Unterschiede in der Trainingszeit und der Modellarchitektur auf diesen Wert aus? Welche Auswirkungen werden Gleitkommakomprimierungsquantisierung, MoE mit gemischten Expertenmodellen und Unterschiede in der Datenqualität (Enzyklopädiewissen vs. Internetmüll) auf die Wissenskapazität von LLM haben?
Die neueste Forschung „Language Model Physics Part 3.3: Scaling Laws of Knowledge“ von Zhu Zeyuan (Meta AI) und Li Yuanzhi (MBZUAI) nutzte umfangreiche Experimente (50.000 Aufgaben, insgesamt 4.200.000 GPU-Stunden), um 12 Gesetze zusammenzufassen Die Wissenskapazität von LLM unter verschiedenen Dateien bietet eine genauere Messmethode.

Der Autor wies zunächst darauf hin, dass es unrealistisch sei, das Skalierungsgesetz von LLM anhand der Leistung des Open-Source-Modells im Benchmark-Datensatz (Benchmark) zu messen. Beispielsweise schneidet LLaMA-70B beim Wissensdatensatz 30 % besser ab als LLaMA-7B. Dies bedeutet nicht, dass eine Erweiterung des Modells um das Zehnfache die Kapazität nur um 30 % erhöhen kann. Wenn ein Modell mithilfe von Netzwerkdaten trainiert wird, ist es außerdem schwierig, die darin enthaltene Gesamtmenge an Wissen abzuschätzen.
Ein weiteres Beispiel: Wenn wir die Qualität der Mistral- und Llama-Modelle vergleichen: Liegt der Unterschied an deren unterschiedlichen Modellarchitekturen oder an der unterschiedlichen Vorbereitung ihrer Trainingsdaten?
Basierend auf den obigen Überlegungen übernimmt der Autor die Kernidee seiner Aufsatzreihe „Language Model Physics“, die darin besteht, künstlich synthetisierte Daten zu erstellen und die Wissensbits in den Daten durch Kontrolle der Menge und streng zu kontrollieren Art des Wissens in den Daten). Gleichzeitig verwendet der Autor LLMs unterschiedlicher Größe und Architektur, um auf synthetischen Daten zu trainieren, und gibt mathematische Definitionen an, um genau zu berechnen, wie viele Wissensbits das trainierte Modell aus den Daten gelernt hat. ??
 Für diese Studie sagten einige Leute, dass diese Richtung vernünftig erscheint. Wir können das Skalierungsgesetz auf sehr wissenschaftliche Weise analysieren.
Für diese Studie sagten einige Leute, dass diese Richtung vernünftig erscheint. Wir können das Skalierungsgesetz auf sehr wissenschaftliche Weise analysieren.
- Manche Leute glauben auch, dass diese Forschung das Skalierungsgesetz auf eine andere Ebene hebt. Auf jeden Fall ein Pflichtlektüre für Praktiker.
- Forschungsüberblick
Die Autoren untersuchten drei Arten synthetischer Daten: bioS, bioR, bioD. bioS ist eine Biografie, die mit englischen Vorlagen geschrieben wurde, bioR ist eine Biografie, die mit Hilfe des LlaMA2-Modells geschrieben wurde (insgesamt 22 GB), bioD ist eine Art virtuelle Wissensdaten, die die Details weiter steuern können (z. B. die Länge des Wissens usw.). Der Wortschatz kann kontrolliert werden. Warten Sie auf Details). Der Autor
konzentriert sich auf die Sprachmodellarchitektur basierend auf GPT2, LlaMA und Mistral, wobei GPT2 die aktualisierte Rotary Position Embedding (RoPE)-Technologie verwendet. 
Das Bild links zeigt Skalierungsgesetze mit ausreichender Trainingszeit, und das Bild rechts zeigt Skalierungsgesetze mit unzureichender Trainingszeit
Abbildung 1 oben skizziert kurz die ersten 5 vom Autor vorgeschlagenen Gesetze , wobei links/rechts jeweils „Training“ entsprechen. Die beiden Situationen „ausreichende Zeit“ und „unzureichende Trainingszeit“ entsprechen jeweils allgemeinem Wissen (zum Beispiel ist Peking die Hauptstadt Chinas) und weniger allgemeinem Wissen (zum Beispiel Die Abteilung für Physik der Tsinghua-Universität wurde 1926 gegründet.
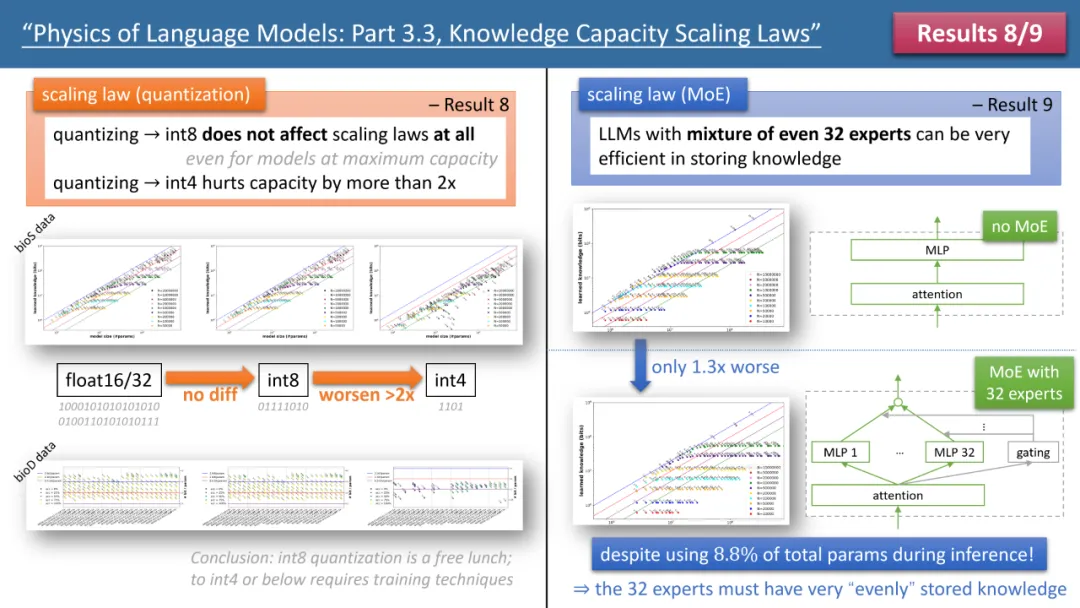
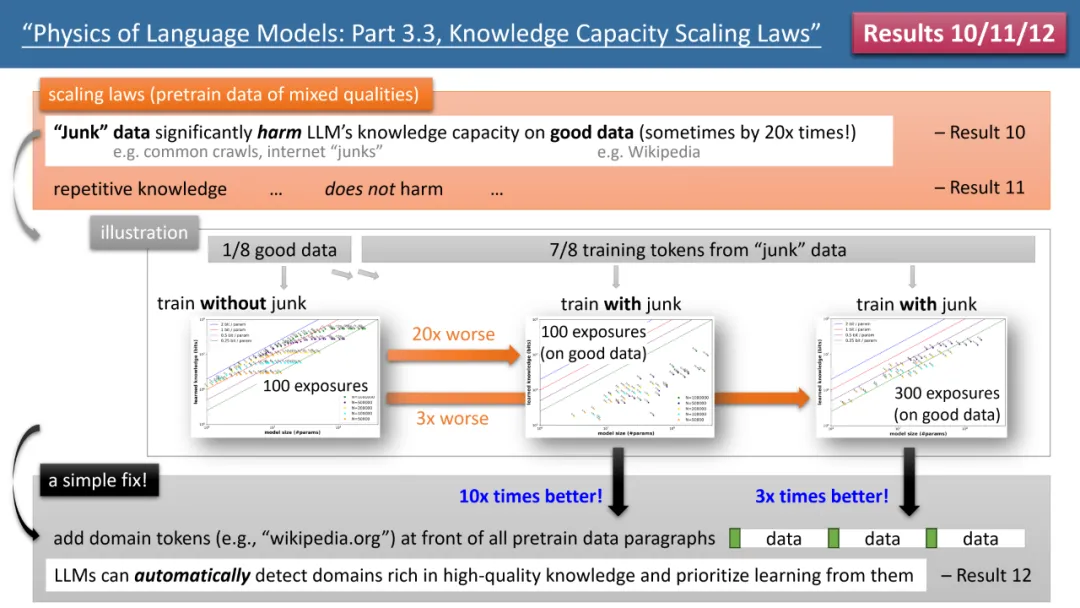
Wenn die Trainingszeit ausreicht, stellte der Autor fest, dass unabhängig von der verwendeten Modellarchitektur, GPT2 oder LlaMA/Mistral, die Speichereffizienz des Modells 2 Bit/Param erreichen kann – das heißt, jeder Modellparameter kann 2 speichern im Durchschnitt nur wenige Informationen. Dies hat nichts mit der Modelltiefe zu tun, sondern nur mit der Modellgröße. Mit anderen Worten: Ein 7B-Modell kann bei entsprechender Schulung 14 Milliarden Bits an Wissen speichern, was mehr ist als das menschliche Wissen in Wikipedia und allen englischen Lehrbüchern zusammen! Was noch überraschender ist, ist, dass die Forschung des Autors diese Ansicht widerlegt, obwohl die traditionelle Theorie besagt, dass das Wissen im Transformatormodell hauptsächlich in der MLP-Schicht gespeichert ist. Sie fanden heraus, dass das Modell dies auch dann noch tun kann, wenn alle MLP-Schichten entfernt werden Erreichen Sie 2 Bit/ Speichereffizienz der Parameter. Abbildung 2: Skalierungsgesetze bei unzureichender Trainingszeit Betrachten wir jedoch den Fall unzureichender Trainingszeit, werden die Unterschiede zwischen den Modellen deutlich. Wie in Abbildung 2 oben dargestellt, kann das GPT2-Modell in diesem Fall mehr als 30 % mehr Wissen speichern als LlaMA/Mistral, was bedeutet, dass das Modell von vor einigen Jahren das heutige Modell in einigen Aspekten übertrifft. Warum passiert das? Der Autor nahm architektonische Anpassungen am LlaMA-Modell vor, indem er jeden Unterschied zwischen dem Modell und GPT2 addierte oder subtrahierte, und stellte schließlich fest, dass GatedMLP den Verlust von 30 % verursachte. Um es zu betonen: GatedMLP führt nicht zu einer Änderung der „endgültigen“ Speicherrate des Modells – denn Abbildung 1 sagt uns, dass sie sich bei ausreichendem Training nicht unterscheiden werden. GatedMLP führt jedoch zu einem instabilen Training, sodass dasselbe Wissen eine längere Trainingszeit erfordert. Mit anderen Worten: Bei Wissen, das selten im Trainingssatz vorkommt, verringert sich die Speichereffizienz des Modells. Abbildung 3: Der Einfluss von Quantisierung und MoE auf Modellskalierungsgesetze Die Gesetze 8 und 9 des Autors untersuchen jeweils den Einfluss von Quantisierung und MoE auf Modellskalierungsgesetze. Die Schlussfolgerung ist in Abbildung dargestellt 3 oben. Ein Ergebnis ist, dass die Komprimierung des trainierten Modells von float32/16 auf int8 keine Auswirkungen auf die Wissensspeicherung hat, selbst für Modelle, die die Speichergrenze von 2 Bit/Parameter erreicht haben. Das bedeutet, dass LLM 1/4 der „Grenze der Informationstheorie“ erreichen kann – denn der int8-Parameter beträgt nur 8 Bit, aber im Durchschnitt kann jeder Parameter 2 Bit Wissen speichern. Der Autor weist darauf hin, dass dies ein universelles Gesetz ist und nichts mit der Form des Wissensausdrucks zu tun hat. Die auffälligsten Ergebnisse stammen aus den Gesetzen 10-12 der Autoren (siehe Abbildung 4). Wenn unsere (Vor-)Trainingsdaten stammen, stammen 1/8 aus hochwertigen Wissensdatenbanken (z. B. der Baidu-Enzyklopädie) und 7/8 aus Daten geringer Qualität (z. B. allgemeine Crawl- oder Forumsgespräche oder sogar völlig zufälliger Müll). Daten). Wird sich also minderwertige Daten auf die Aufnahme von qualitativ hochwertigem Wissen durch LLM auswirken? Die Ergebnisse sind überraschend. Selbst wenn die Trainingszeit für qualitativ hochwertige Daten konstant bleibt, kann die „Existenz“ von Daten mit geringer Qualität die Speicherung von qualitativ hochwertigem Wissen durch das Modell um das Zwanzigfache reduzieren! Selbst wenn die Schulungszeit für hochwertige Daten um das Dreifache verlängert wird, wird die Wissensreserve immer noch um das Dreifache reduziert. Das ist, als würde man Gold in den Sand werfen, und hochwertige Daten werden verschwendet. Der Autor schlug ein einfaches Experiment zur Überprüfung vor: Wenn hochwertige Daten mit einem speziellen Token hinzugefügt werden (jeder spezielle Token reicht aus, das Modell muss nicht im Voraus wissen, um welchen Token es sich handelt), dann ist das Wissen des Modells wichtig Der Speicher kann sich sofort um das Zehnfache erhöhen, ist das nicht erstaunlich? Daher ist das Hinzufügen von Domänennamen-Tokens zu Vortrainingsdaten ein äußerst wichtiger Datenvorbereitungsvorgang. Abbildung 4: Skalierungsgesetze, Modellfehler und wie man sie repariert, wenn Daten vor dem Training eine „ungleichmäßige Wissensqualität“ aufweisen Fazit Der Autor glaubt, dass durch synthetische Daten die Berechnung Das Modell wird trainiert. Die dabei gewonnene Methode des Gesamtwissens kann ein systematisches und genaues Bewertungssystem für die „Bewertung der Modellarchitektur, Trainingsmethoden und Datenaufbereitung“ bereitstellen. Dies unterscheidet sich grundlegend von herkömmlichen Benchmark-Vergleichen und ist zuverlässiger. Sie hoffen, dass dies den Designern zukünftiger LLMs helfen wird, fundiertere Entscheidungen zu treffen. 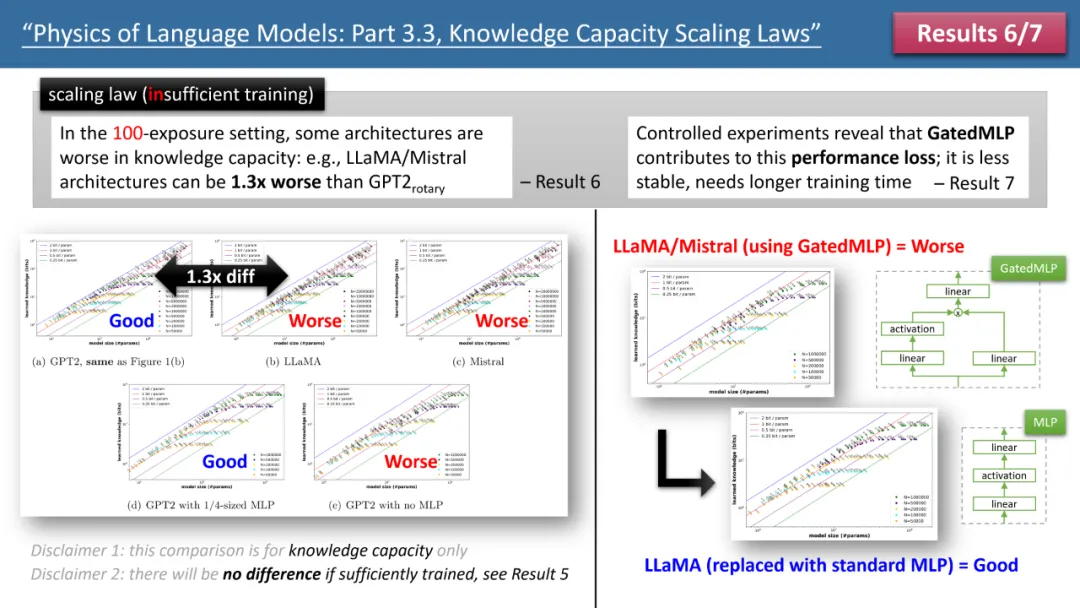
Das obige ist der detaillierte Inhalt vonIst die Llama-Architektur GPT2 unterlegen? Magischer Token erhöht den Speicher um das Zehnfache?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1663
1663
 14
1419
52
1313
25
1264
29
1237
24
14
1419
52
1313
25
1264
29
1237
24

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
