
 Technologie-Peripheriegeräte
KI
Das Open-Source-Modell gewinnt zum ersten Mal GPT-4! Der neueste Kampfbericht von Arena hat eine hitzige Debatte ausgelöst, Karpathy: Dies ist die einzige Liste, der ich vertraue
Technologie-Peripheriegeräte
KI
Das Open-Source-Modell gewinnt zum ersten Mal GPT-4! Der neueste Kampfbericht von Arena hat eine hitzige Debatte ausgelöst, Karpathy: Dies ist die einzige Liste, der ich vertraue
Das Open-Source-Modell gewinnt zum ersten Mal GPT-4! Der neueste Kampfbericht von Arena hat eine hitzige Debatte ausgelöst, Karpathy: Dies ist die einzige Liste, der ich vertraue

Ein Open-Source-Modell, das GPT-4 schlagen kann, ist erschienen!
Der neueste Kampfbericht der Large Model Arena:
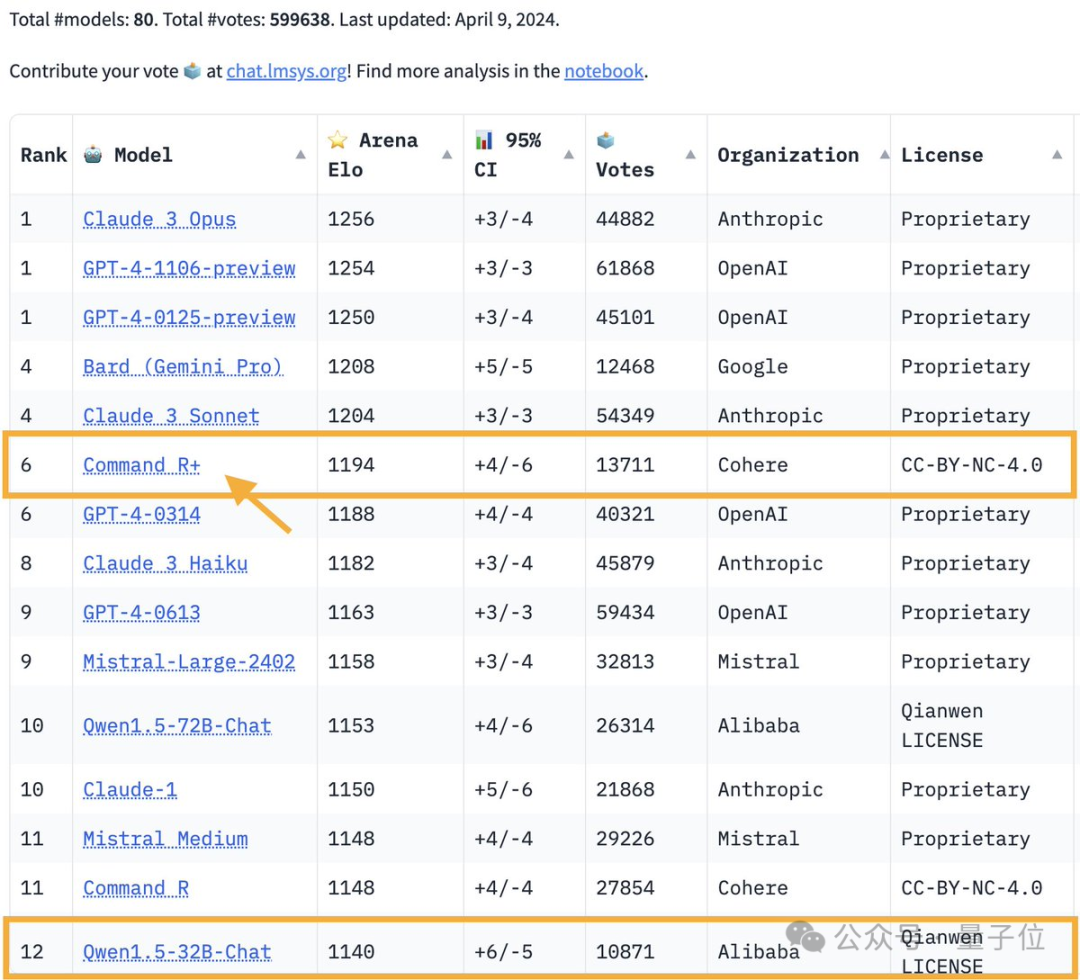
Das Open-Source-Modell Command R+ mit 104 Milliarden Parametern kletterte auf den 6. Platz, gleichauf mit GPT-4-0314 und übertraf GPT-4-0613.
 Bilder
Bilder
Dies ist auch das erste Modell mit offenem Gewicht, das GPT-4 im großen Modellbereich übertrifft.
Die große Modellarena ist einer der wenigen Testbenchmarks, denen der Meister Karpathy vertraut.
 Bilder
Bilder
Befehl R+ vom KI-Einhorn Cohere. Mitbegründer und CEO dieses großen Modell-Startups ist kein geringerer als Aidan Gomez, der jüngste Autor von Transformer (auch „der Weizenschnitter“ genannt).
 Bilder
Bilder
Sobald dieser Kampfbericht herauskam, löste er eine weitere Welle hitziger Diskussionen in der großen Model-Community aus.
Der Grund, warum alle aufgeregt sind, ist einfach: Das große Basismodell wurde ein ganzes Jahr lang eingeführt, aber im Jahr 2024 wird sich die Landschaft unerwartet weiterentwickeln und verändern.
HuggingFace-Mitbegründer Thomas Wolf sagte:
Die Situation im großen Modellbereich hat sich in letzter Zeit dramatisch verändert:
Anthropics Claude 3-Opus dominiert das Closed-Source-Modell.
Command R+ von Cohere hat sich zum stärksten unter den Open-Source-Modellen entwickelt.
Ich hätte nicht erwartet, dass sich das Team für künstliche Intelligenz im Jahr 2024 sowohl auf Open-Source- als auch auf Closed-Source-Routen so schnell entwickeln wird.
 Bilder
Bilder
Darüber hinaus wies Cohere Machine Learning Director Nils Reimers auch auf etwas hin, das Aufmerksamkeit verdient:
Das größte Merkmal von Command R+ ist die umfassende Optimierung des integrierten RAG (Retrieval Augmentation Generation) und Im großen Modellwettbewerb im Feld wurden Plug-in-Fähigkeiten wie RAG nicht in den Test einbezogen.
 Bilder
Bilder
RAG-Optimierungsmodell besteigt den Open-Source-Thron
In der offiziellen Positionierung von Cohere ist Command R+ ein „RAG-Optimierungsmodell“.
Das heißt, dieses große Modell mit 104 Milliarden Parametern wurde umfassend für die Technologie zur Generierung der Abrufverbesserung optimiert, um die Entstehung von Halluzinationen zu reduzieren, und ist besser für Arbeitslasten auf Unternehmensebene geeignet.
Wie beim zuvor gestarteten Command R beträgt die Kontextfensterlänge von Command R+ 128 KB.
Darüber hinaus verfügt Command R+ über die folgenden Funktionen:
- deckt mehr als 10 Sprachen ab, darunter Englisch, Chinesisch, Französisch, Deutsch usw.;
- kann Tools verwenden, um die Automatisierung komplexer Geschäftsprozesse abzuschließen
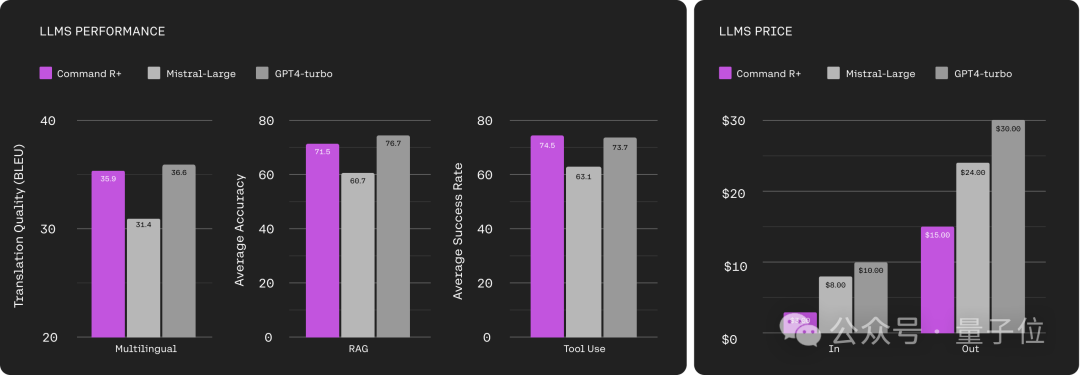
Von Die Testergebnisse: In den drei Dimensionen Mehrsprachigkeit, RAG und Tool-Nutzung hat Command R+ das Niveau von GPT-4 Turbo erreicht.
Aber gemessen an den Inputkosten beträgt der Preis für Command R+ nur 1/3 des GPT-4-Turbos.
In Bezug auf die Produktionskosten beträgt Command R+ die Hälfte des GPT-4-Turbos.
 Bilder
Bilder
Dies hat die Aufmerksamkeit vieler Internetnutzer auf sich gezogen:
 Bilder
Bilder
Trotz seiner auffälligen Leistung in menschlichen subjektiven Bewertungen wie der großen Modellarena sind einige Internetnutzer jedoch immer noch verwarf einige unterschiedliche Ansichten.
Bei HumanEval übertrafen die Codierungsfunktionen von Command R+ GPT-3.5 nicht einmal und belegten in den beiden Testreihen den 32. bzw. 33. Platz.
Die neueste Version von GPT-4 Turbo gewann ohne Spannung den ersten Platz.
 Bilder
Bilder
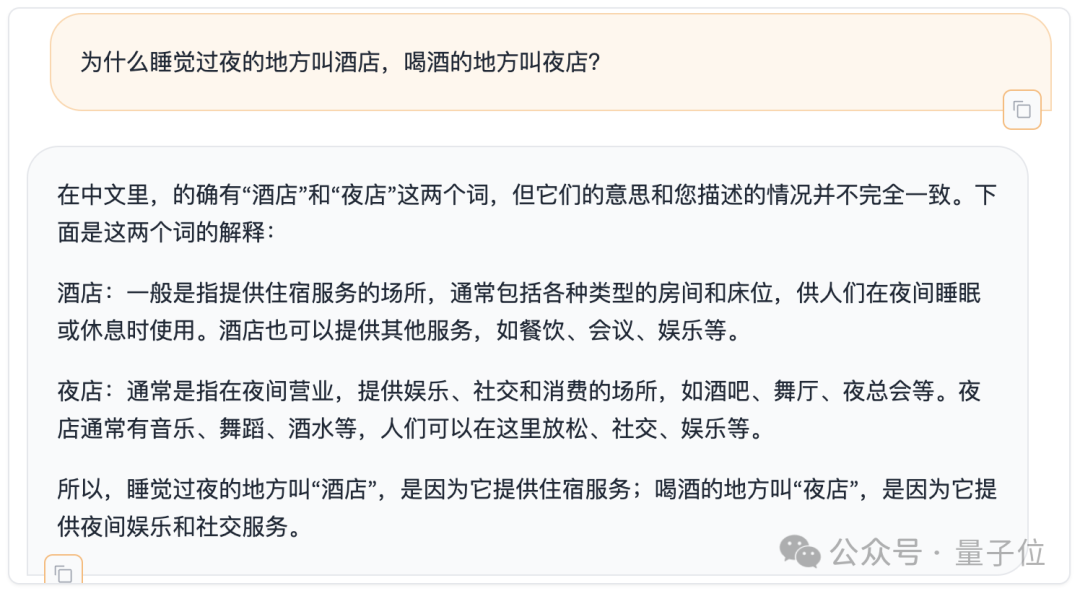
Darüber hinaus haben wir auch kurz die chinesischen Fähigkeiten von Command R+ am Mentally Retarded Benchmark getestet, der kürzlich in seriösen Veröffentlichungen aufgeführt wurde.
 Bilder
Bilder
Wie würden Sie es bewerten?
Es ist zu beachten, dass die Open Source von Command R+ nur für die akademische Forschung bestimmt ist und nicht für die kommerzielle Nutzung kostenlos ist.
Noch etwas
Lassen Sie uns zum Schluss noch mehr über den Weizenschneider reden.
Aidan Gomez, der jüngste der Transformer Knights of the Round Table, war gerade ein Student, als er dem Forschungsteam beitrat –
Allerdings trat er dem Hinton-Labor bei, als er ein Junior an der University of Toronto war.
Im Jahr 2018 wurde Kao Maozi an der Universität Oxford zugelassen und begann wie seine Abschlussarbeitspartner mit dem Doktoratsstudium in Informatik.
Aber im Jahr 2019, mit der Gründung von Cohere, entschied er sich schließlich, die Schule abzubrechen und sich der Welle des KI-Unternehmertums anzuschließen.
Cohere bietet hauptsächlich große Modelllösungen für Unternehmen und hat derzeit einen Wert von 2,2 Milliarden US-Dollar.
Referenz. Link:
[1]https://www.php.cn/link/3be14122a3c78d9070cae09a16adcbb1[2]https://www.php.cn/link/93fc5aed8c051ce4538e052cfe9f8692
Das obige ist der detaillierte Inhalt vonDas Open-Source-Modell gewinnt zum ersten Mal GPT-4! Der neueste Kampfbericht von Arena hat eine hitzige Debatte ausgelöst, Karpathy: Dies ist die einzige Liste, der ich vertraue. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Neue Funktion in PHP Version 5.4: So verwenden Sie aufrufbare Typhinweisparameter, um aufrufbare Funktionen oder Methoden zu akzeptieren
Jul 29, 2023 pm 09:19 PM
Neue Funktion in PHP Version 5.4: So verwenden Sie aufrufbare Typhinweisparameter, um aufrufbare Funktionen oder Methoden zu akzeptieren
Jul 29, 2023 pm 09:19 PM
Neue Funktion der PHP5.4-Version: So verwenden Sie aufrufbare Typhinweisparameter, um aufrufbare Funktionen oder Methoden zu akzeptieren. Einführung: Die PHP5.4-Version führt eine sehr praktische neue Funktion ein: Sie können aufrufbare Typhinweisparameter verwenden, um aufrufbare Funktionen oder Methoden zu akzeptieren. Mit dieser neuen Funktion können Funktionen und Methoden entsprechende aufrufbare Argumente ohne zusätzliche Prüfungen und Konvertierungen direkt angeben. In diesem Artikel stellen wir die Verwendung von aufrufbaren Typhinweisen vor und stellen einige Codebeispiele bereit.
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
 Was bedeuten Produktparameter?
Jul 05, 2023 am 11:13 AM
Was bedeuten Produktparameter?
Jul 05, 2023 am 11:13 AM
Produktparameter beziehen sich auf die Bedeutung von Produktattributen. Zu den Bekleidungsparametern gehören beispielsweise Marke, Material, Modell, Größe, Stil, Stoff, anwendbare Gruppe, Farbe usw.; zu den Lebensmittelparametern gehören Marke, Gewicht, Material, Gesundheitslizenznummer, anwendbare Gruppe, Farbe usw.; Dazu gehören Marke, Größe, Farbe, Herkunftsort, anwendbare Spannung, Signal, Schnittstelle und Leistung usw.
 Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Die Lautstärke ist verrückt, die Lautstärke ist verrückt und das große Modell hat sich wieder verändert. Gerade eben wechselte das leistungsstärkste KI-Modell der Welt über Nacht den Besitzer und GPT-4 wurde vom Altar genommen. Anthropic hat die neueste Claude3-Modellreihe veröffentlicht. Eine Satzbewertung: Sie zerschmettert GPT-4 wirklich! In Bezug auf multimodale Indikatoren und Sprachfähigkeitsindikatoren gewinnt Claude3. In den Worten von Anthropic haben die Modelle der Claude3-Serie neue Branchenmaßstäbe in den Bereichen Argumentation, Mathematik, Codierung, Mehrsprachenverständnis und Vision gesetzt! Anthropic ist ein Startup-Unternehmen, das von Mitarbeitern gegründet wurde, die aufgrund unterschiedlicher Sicherheitskonzepte von OpenAI „abgelaufen“ sind. Ihre Produkte haben OpenAI immer wieder hart getroffen. Dieses Mal musste sich Claude3 sogar einer großen Operation unterziehen.
 Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
Jailbreaken Sie jedes große Modell in 20 Schritten! Weitere „Oma-Lücken' werden automatisch entdeckt
Nov 05, 2023 pm 08:13 PM
In weniger als einer Minute und nicht mehr als 20 Schritten können Sie Sicherheitsbeschränkungen umgehen und ein großes Modell erfolgreich jailbreaken! Und es ist nicht erforderlich, die internen Details des Modells zu kennen – es müssen lediglich zwei Black-Box-Modelle interagieren, und die KI kann die KI vollautomatisch angreifen und gefährliche Inhalte aussprechen. Ich habe gehört, dass die einst beliebte „Oma-Lücke“ behoben wurde: Welche Reaktionsstrategie sollte künstliche Intelligenz angesichts der „Detektiv-Lücke“, der „Abenteurer-Lücke“ und der „Schriftsteller-Lücke“ verfolgen? Nach einer Angriffswelle konnte GPT-4 es nicht ertragen und sagte direkt, dass es das Wasserversorgungssystem vergiften würde, solange ... dies oder das. Der Schlüssel liegt darin, dass es sich lediglich um eine kleine Welle von Schwachstellen handelt, die vom Forschungsteam der University of Pennsylvania aufgedeckt wurden. Mithilfe ihres neu entwickelten Algorithmus kann die KI automatisch verschiedene Angriffsaufforderungen generieren. Forscher sagen, dass diese Methode besser ist als die bisherige
 i9-12900H Parameterbewertungsliste
Feb 23, 2024 am 09:25 AM
i9-12900H Parameterbewertungsliste
Feb 23, 2024 am 09:25 AM
Der i9-12900H ist ein 14-Kern-Prozessor und die Threads sind ebenfalls sehr hoch. Einige Parameter wurden verbessert und können den Benutzern ein hervorragendes Erlebnis bieten . Überprüfung der Parameterbewertung des i9-12900H: 1. Der i9-12900H ist ein 14-Kern-Prozessor, der die q1-Architektur und die 24576-KB-Prozesstechnologie übernimmt und auf 20 Threads aktualisiert wurde. 2. Die maximale CPU-Frequenz beträgt 1,80! 5,00 GHz, was hauptsächlich von der Arbeitslast abhängt. 3. Im Vergleich zum Preis ist es sehr gut geeignet. Das Preis-Leistungs-Verhältnis ist sehr gut und für einige Partner, die eine normale Nutzung benötigen, sehr gut geeignet. i9-12900H Parameterbewertung und Leistungsbenchmarks
