

JSP入门教程(2)_MySQL

欢迎使用JavaServer Pages(以下简称JSP)技术―制作动态内容网页的方法。
如果你希望学习这篇教程的话,我想你一定是这项技术的新手。你可能想成为一名利用JSP技术开发网络应用程序的程序员或者网页设计师。本教程中包含了一系列JSP的技巧和一些简单的代码的写法,每一步都举了一组例子来讲述原理。
我建议你在学习本教程之前先去看一看FAQ,了解如果配置你的服务器好让他能支持并运行JSP。那样你就可以跳过前边的内容直接看你感兴趣的内容了。
OK,费话少说,Let’s go!
第一课:真正的开始
现在开始做我们的第一个JSP页面。图1-1展示了一个最简单的JSP页面,接下来是两段代码。
[dukebanner.html]

|
helloworld.jsp
Hello, World! |
页面说明:
在很多JSP文件中你都要写上这样的说明。在helloword.jsp中:
傻瓜也看得出来,这句话没什么大用,只是简要的说明一下这段代码的作用。
你可以在JSP文件中的任何地方写这种代码,但是好的习惯是把他写在最前面,还有,因为他是JSP标签,记住一定要放在前面,呵
include说明:
include用来在主JSP文件中调用本地的一个其他文件,通常是一些版权信息啦,脚本语言啦等其他任何你想在其他文件中重复使用的代码。在这个例子中就是调用了一个图片其实。大家明白这个意思就得了。
随便说两句:
在JSP中对写法非常敏感,不可以有一点错误。举个例子,把
代码写好了,如何试验一下呢?
我这里写的UNIX下的方法,如果你用Windows,那么换一下路径就可以了

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion kann nicht nur besser imitieren, sondern auch „erschaffen“. Das Diffusionsmodell (DiffusionModel) ist ein Bilderzeugungsmodell. Im Vergleich zu bekannten Algorithmen wie GAN und VAE im Bereich der KI verfolgt das Diffusionsmodell einen anderen Ansatz. Seine Hauptidee besteht darin, dem Bild zunächst Rauschen hinzuzufügen und es dann schrittweise zu entrauschen. Das Entrauschen und Wiederherstellen des Originalbilds ist der Kernbestandteil des Algorithmus. Der endgültige Algorithmus ist in der Lage, aus einem zufälligen verrauschten Bild ein Bild zu erzeugen. In den letzten Jahren hat das phänomenale Wachstum der generativen KI viele spannende Anwendungen in der Text-zu-Bild-Generierung, Videogenerierung und mehr ermöglicht. Das Grundprinzip dieser generativen Werkzeuge ist das Konzept der Diffusion, ein spezieller Sampling-Mechanismus, der die Einschränkungen bisheriger Methoden überwindet.
 Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Kimi: In nur einem Satz, in nur zehn Sekunden ist ein PPT fertig. PPT ist so nervig! Um ein Meeting abzuhalten, benötigen Sie einen PPT; um einen wöchentlichen Bericht zu schreiben, müssen Sie einen PPT vorlegen, auch wenn Sie jemanden des Betrugs beschuldigen PPT. Das College ähnelt eher dem Studium eines PPT-Hauptfachs. Man schaut sich PPT im Unterricht an und macht PPT nach dem Unterricht. Als Dennis Austin vor 37 Jahren PPT erfand, hatte er vielleicht nicht damit gerechnet, dass PPT eines Tages so weit verbreitet sein würde. Wenn wir über unsere harte Erfahrung bei der Erstellung von PPT sprechen, treiben uns Tränen in die Augen. „Es dauerte drei Monate, ein PPT mit mehr als 20 Seiten zu erstellen, und ich habe es Dutzende Male überarbeitet. Als ich das PPT sah, musste ich mich übergeben.“ war PPT.“ Wenn Sie ein spontanes Meeting haben, sollten Sie es tun
 Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Alle CVPR 2024-Auszeichnungen bekannt gegeben! Fast 10.000 Menschen nahmen offline an der Konferenz teil und ein chinesischer Forscher von Google gewann den Preis für den besten Beitrag
Jun 20, 2024 pm 05:43 PM
Am frühen Morgen des 20. Juni (Pekinger Zeit) gab CVPR2024, die wichtigste internationale Computer-Vision-Konferenz in Seattle, offiziell die besten Beiträge und andere Auszeichnungen bekannt. In diesem Jahr wurden insgesamt 10 Arbeiten ausgezeichnet, darunter zwei beste Arbeiten und zwei beste studentische Arbeiten. Darüber hinaus gab es zwei Nominierungen für die beste Arbeit und vier Nominierungen für die beste studentische Arbeit. Die Top-Konferenz im Bereich Computer Vision (CV) ist die CVPR, die jedes Jahr zahlreiche Forschungseinrichtungen und Universitäten anzieht. Laut Statistik wurden in diesem Jahr insgesamt 11.532 Arbeiten eingereicht, von denen 2.719 angenommen wurden, was einer Annahmequote von 23,6 % entspricht. Laut der statistischen Analyse der CVPR2024-Daten des Georgia Institute of Technology befassen sich die meisten Arbeiten aus Sicht der Forschungsthemen mit der Bild- und Videosynthese und -generierung (Imageandvideosyn
 Im Sommer müssen Sie unbedingt versuchen, einen Regenbogen zu schießen
Jul 21, 2024 pm 05:16 PM
Im Sommer müssen Sie unbedingt versuchen, einen Regenbogen zu schießen
Jul 21, 2024 pm 05:16 PM
Nach dem Regen im Sommer können Sie oft ein wunderschönes und magisches besonderes Wetterbild sehen – den Regenbogen. Dies ist auch eine seltene Szene, die man in der Fotografie antreffen kann, und sie ist sehr fotogen. Für das Erscheinen eines Regenbogens gibt es mehrere Bedingungen: Erstens sind genügend Wassertröpfchen in der Luft und zweitens scheint die Sonne in einem niedrigeren Winkel. Daher ist es am einfachsten, einen Regenbogen am Nachmittag zu sehen, nachdem der Regen nachgelassen hat. Allerdings wird die Bildung eines Regenbogens stark von Wetter, Licht und anderen Bedingungen beeinflusst, sodass sie im Allgemeinen nur von kurzer Dauer ist und die beste Betrachtungs- und Aufnahmezeit sogar noch kürzer ist. Wenn Sie also auf einen Regenbogen stoßen, wie können Sie ihn dann richtig aufzeichnen und qualitativ hochwertige Fotos machen? 1. Suchen Sie nach Regenbögen. Zusätzlich zu den oben genannten Bedingungen erscheinen Regenbögen normalerweise in Richtung des Sonnenlichts, das heißt, wenn die Sonne von Westen nach Osten scheint, ist es wahrscheinlicher, dass Regenbögen im Osten erscheinen.
 Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Wir wissen, dass LLM auf großen Computerclustern unter Verwendung umfangreicher Daten trainiert wird. Auf dieser Website wurden viele Methoden und Technologien vorgestellt, die den LLM-Trainingsprozess unterstützen und verbessern. Was wir heute teilen möchten, ist ein Artikel, der tief in die zugrunde liegende Technologie eintaucht und vorstellt, wie man einen Haufen „Bare-Metals“ ohne Betriebssystem in einen Computercluster für das LLM-Training verwandelt. Dieser Artikel stammt von Imbue, einem KI-Startup, das allgemeine Intelligenz durch das Verständnis der Denkweise von Maschinen erreichen möchte. Natürlich ist es kein einfacher Prozess, einen Haufen „Bare Metal“ ohne Betriebssystem in einen Computercluster für das Training von LLM zu verwandeln, aber Imbue hat schließlich erfolgreich ein LLM mit 70 Milliarden Parametern trainiert der Prozess akkumuliert
 Der leitende NVIDIA-Architekt zählt die 12 Schwachstellen von RAG auf und vermittelt Lösungen
Jul 11, 2024 pm 01:53 PM
Der leitende NVIDIA-Architekt zählt die 12 Schwachstellen von RAG auf und vermittelt Lösungen
Jul 11, 2024 pm 01:53 PM
Retrieval-Augmented Generation (RAG) ist eine Technik, die Retrieval nutzt, um Sprachmodelle zu verbessern. Bevor ein Sprachmodell eine Antwort generiert, ruft es insbesondere relevante Informationen aus einer umfangreichen Dokumentendatenbank ab und verwendet diese Informationen dann zur Steuerung des Generierungsprozesses. Diese Technologie kann die Genauigkeit und Relevanz von Inhalten erheblich verbessern, das Problem der Halluzinationen wirksam lindern, die Geschwindigkeit der Wissensaktualisierung erhöhen und die Nachverfolgbarkeit der Inhaltsgenerierung verbessern. RAG ist zweifellos einer der spannendsten Bereiche der Forschung im Bereich der künstlichen Intelligenz. Weitere Informationen zu RAG finden Sie im Kolumnenartikel auf dieser Website „Was sind die neuen Entwicklungen bei RAG, das sich darauf spezialisiert hat, die Mängel großer Modelle auszugleichen?“ Diese Rezension erklärt es deutlich. Aber RAG ist nicht perfekt und Benutzer stoßen bei der Verwendung oft auf einige „Problempunkte“. Kürzlich die fortschrittliche generative KI-Lösung von NVIDIA
 KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
Herausgeber des Machine Power Report: Yang Wen Die Welle der künstlichen Intelligenz, repräsentiert durch große Modelle und AIGC, hat unsere Lebens- und Arbeitsweise still und leise verändert, aber die meisten Menschen wissen immer noch nicht, wie sie sie nutzen sollen. Aus diesem Grund haben wir die Kolumne „KI im Einsatz“ ins Leben gerufen, um detailliert vorzustellen, wie KI durch intuitive, interessante und prägnante Anwendungsfälle für künstliche Intelligenz genutzt werden kann, und um das Denken aller anzuregen. Wir heißen Leser auch willkommen, innovative, praktische Anwendungsfälle einzureichen. Videolink: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Vor kurzem wurde der Lebens-Vlog eines allein lebenden Mädchens auf Xiaohongshu populär. Eine Animation im Illustrationsstil, gepaart mit ein paar heilenden Worten, kann in nur wenigen Tagen leicht erlernt werden.
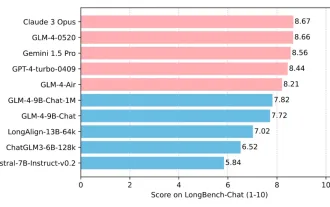 Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Seit der Einführung von ChatGLM-6B am 14. März 2023 haben die Modelle der GLM-Serie große Aufmerksamkeit und Anerkennung erhalten. Insbesondere nachdem ChatGLM3-6B als Open Source verfügbar war, sind die Entwickler voller Erwartungen an das von Zhipu AI eingeführte Modell der vierten Generation. Diese Erwartung wurde mit der Veröffentlichung von GLM-4-9B endlich vollständig erfüllt. Die Geburt von GLM-4-9B Um kleinen Modellen (10B und darunter) leistungsfähigere Fähigkeiten zu verleihen, hat das GLM-Technikteam nach fast einem halben Jahr dieses neue Open-Source-Modell der GLM-Serie der vierten Generation auf den Markt gebracht: GLM-4-9B Erkundung. Dieses Modell komprimiert die Modellgröße erheblich und stellt gleichzeitig Genauigkeit sicher. Es verfügt über eine schnellere Inferenzgeschwindigkeit und eine höhere Effizienz. Die Untersuchungen des GLM-Technikteams haben dies nicht getan
