
 Technologie-Peripheriegeräte
KI
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Technologie-Peripheriegeräte
KI
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus
Große Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus

Das Potenzial großer Sprachmodelle wird gefördert –
Eine hochpräzise Zeitreihenvorhersage kann ohne Training großer Sprachmodelle erreicht werden und übertrifft alle herkömmlichen Zeitreihenmodelle.
Monash University, Ant und IBM Research haben gemeinsam ein allgemeines Framework entwickelt, das die Fähigkeit großer Sprachmodelle, Sequenzdaten über Modalitäten hinweg zu verarbeiten, erfolgreich förderte. Das Framework ist zu einer wichtigen technologischen Innovation geworden.

Die Vorhersage von Zeitreihen ist für die Entscheidungsfindung in typischen komplexen Systemen wie Städten, Energie, Transport, Fernerkundung usw. von Vorteil.
Seitdem wird erwartet, dass große Modelle Zeitreihen-/spatiotemporale Data-Mining-Methoden revolutionieren werden.
Universeller Rahmen für die Neuprogrammierung großer Sprachmodelle
Das Forschungsteam schlug einen allgemeinen Rahmen vor, um große Sprachmodelle einfach und ohne Schulung für die allgemeine Zeitreihenvorhersage zu verwenden.
Es werden hauptsächlich zwei Schlüsseltechnologien vorgeschlagen: Neuprogrammierung der Zeiteingabe;
Time-LLM verwendet zunächst Textprototypen (Textprototypen), um die eingegebenen Zeitdaten neu zu programmieren, und verwendet die Darstellung in natürlicher Sprache, um die semantischen Informationen der Zeitdaten darzustellen, wodurch zwei unterschiedliche Datenmodalitäten ausgerichtet werden, sodass keine großen Sprachmodelle erforderlich sind Jede Änderung, um die Informationen hinter einer anderen Datenmodalität zu verstehen. Gleichzeitig erfordert das große Sprachmodell keinen spezifischen Trainingsdatensatz, um die Informationen hinter verschiedenen Datenmodalitäten zu verstehen. Diese Methode verbessert nicht nur die Genauigkeit des Modells, sondern vereinfacht auch den Datenvorverarbeitungsprozess.
Um die eingegebenen Zeitreihendaten und die Analyse der entsprechenden Aufgaben besser handhaben zu können, schlug der Autor das Prompt-as-Prefix (PaP)-Paradigma vor. Dieses Paradigma aktiviert die Verarbeitungsfähigkeiten von LLM für zeitliche Aufgaben vollständig, indem vor der Darstellung zeitlicher Daten zusätzliche Kontextinformationen und Aufgabenanweisungen hinzugefügt werden. Diese Methode kann eine verfeinerte Analyse von Timing-Aufgaben ermöglichen und die Verarbeitungsfähigkeiten von LLM für Timing-Aufgaben vollständig aktivieren, indem zusätzliche Kontextinformationen und Aufgabenanweisungen vor der Timing-Datentabelle hinzugefügt werden.
Zu den Hauptbeiträgen gehören:
- Vorschlag für ein neues Konzept zur Neuprogrammierung großer Sprachmodelle für die Zeitanalyse ohne Änderung des Backbone-Sprachmodells.
- Schlagen Sie Time-LLM vor, ein allgemeines Framework zur Neuprogrammierung von Sprachmodellen, das darin besteht, zeitliche Eingabedaten in eine natürlichere Textprototypdarstellung umzuprogrammieren und den Eingabekontext mit deklarativen Hinweisen wie Domänenexpertenwissen und Aufgabenbeschreibungen zu erweitern, um LLM anzuleiten für effektives domänenübergreifendes Denken.

- Die Leistung bei Mainstream-Vorhersageaufgaben übertrifft durchweg die Leistung der besten vorhandenen Modelle, insbesondere in Szenarien mit wenigen und null Stichproben. Darüber hinaus ist Time-LLM in der Lage, eine höhere Leistung zu erzielen und gleichzeitig eine hervorragende Effizienz bei der Neuprogrammierung des Modells beizubehalten. Erschließen Sie das ungenutzte Potenzial von LLM für Zeitreihen und andere sequentielle Daten.
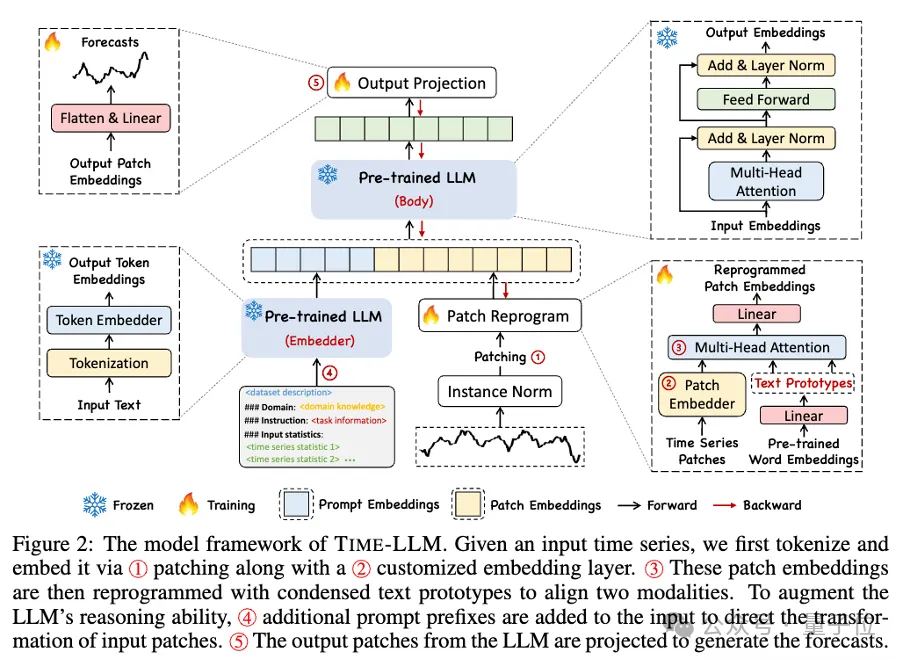
Wenn man sich dieses Framework genauer ansieht, werden zunächst die eingegebenen Zeitreihendaten zunächst durch RevIN normalisiert und dann in verschiedene Patches unterteilt und dem latenten Raum zugeordnet.
Es gibt erhebliche Unterschiede in den Ausdrucksmethoden zwischen Zeitreihendaten und Textdaten und sie gehören zu unterschiedlichen Modalitäten.
Zeitreihen können weder direkt bearbeitet noch verlustfrei in natürlicher Sprache beschrieben werden. Daher müssen wir zeitliche Eingabemerkmale an der Textdomäne natürlicher Sprache ausrichten.

Eine gängige Methode zur Ausrichtung verschiedener Modalitäten ist die Kreuzaufmerksamkeit, aber der inhärente Wortschatz von LLM ist sehr groß, so dass es unmöglich ist, zeitliche Merkmale direkt effektiv allen Wörtern zuzuordnen, und nicht alle Wörter stehen in Zusammenhang mit der Zeit. Sequenzen haben ausgerichtete semantische Beziehungen.
Um dieses Problem zu lösen, führt diese Arbeit eine lineare Kombination von Vokabeln durch, um Textprototypen zu erhalten. Die Anzahl der Textprototypen ist viel kleiner als die des ursprünglichen Vokabulars und die Kombination kann verwendet werden, um die sich ändernden Eigenschaften von Zeitreihendaten darzustellen .
Um die Fähigkeit von LLM bei bestimmten Timing-Aufgaben vollständig zu aktivieren, schlägt diese Arbeit ein Prompt-Prefixing-Paradigma vor.
Um es einfach auszudrücken: Einige Vorinformationen des Zeitreihendatensatzes werden in Form einer natürlichen Sprache als Präfix-Eingabeaufforderung an LLM weitergeleitet und die ausgerichteten Zeitreihenmerkmale werden an LLM gespleißt. Kann dies den Vorhersageeffekt verbessern? ?
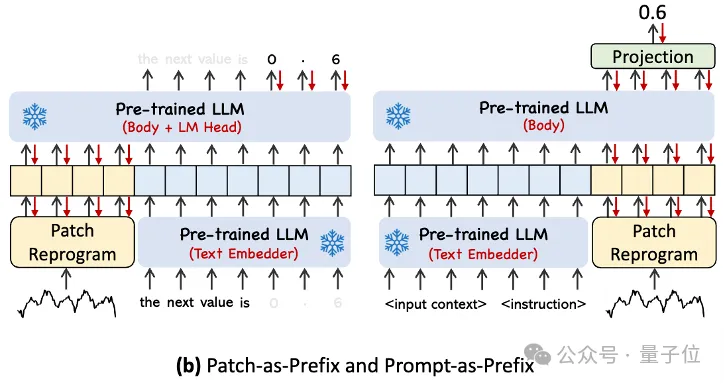
In der Praxis identifizierten die Autoren drei Schlüsselkomponenten für die Erstellung effektiver Eingabeaufforderungen:
Datensatzkontext; (2) Aufgabenanweisungen, die es LLM ermöglichen, sich an verschiedene nachgelagerte Aufgaben anzupassen, wie z. B. Trends, Verzögerungen; usw., wodurch LLM die Eigenschaften von Zeitreihendaten besser verstehen kann.

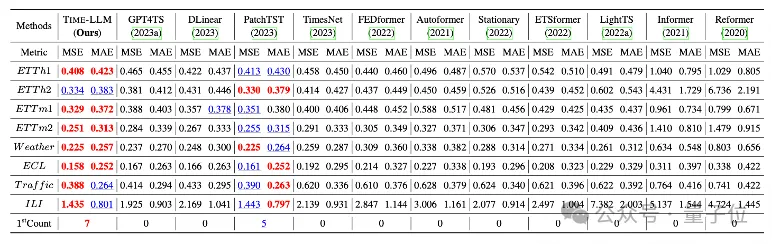
Das Team führte umfassende Tests an 8 klassischen öffentlichen Datensätzen für langfristige Vorhersagen durch.
Das Ergebnis ist, dass Time-LLM im Benchmark-Vergleich die bisherigen besten Ergebnisse auf diesem Gebiet deutlich übertrifft. Im Vergleich zu GPT4TS, das GPT-2 direkt verwendet, weist Time-LLM beispielsweise eine deutliche Verbesserung auf, was auf die Wirksamkeit dieser Methode hinweist .
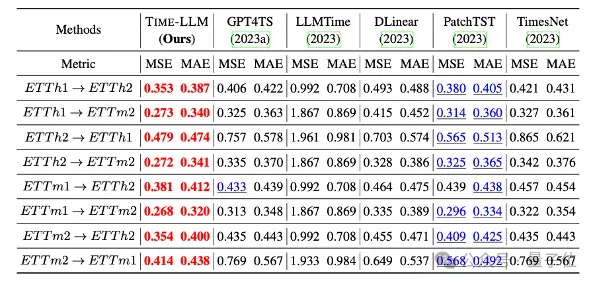
Darüber hinaus zeigt es auch eine starke Vorhersagefähigkeit in Zero-Shot-Szenarien.
Dieses Projekt wird von NextEvo unterstützt, der Forschungs- und Entwicklungsabteilung für KI-Innovation der Intelligent Engine Division der Ant Group.
Interessierte Freunde können auf den Link unten klicken, um mehr über das Papier zu erfahren~
Papier-Linkhttps://arxiv.org/abs/2310.01728.
Das obige ist der detaillierte Inhalt vonGroße Modelle sind auch bei der Vorhersage von Zeitreihen sehr leistungsstark! Das chinesische Team aktiviert neue LLM-Funktionen und erreicht SOTA über traditionelle Modelle hinaus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
So konfigurieren Sie das Debian Apache -Protokollformat
Apr 12, 2025 pm 11:30 PM
In diesem Artikel wird beschrieben, wie das Protokollformat von Apache auf Debian -Systemen angepasst wird. Die folgenden Schritte führen Sie durch den Konfigurationsprozess: Schritt 1: Greifen Sie auf die Apache -Konfigurationsdatei zu. Die Haupt -Apache -Konfigurationsdatei des Debian -Systems befindet sich normalerweise in /etc/apache2/apache2.conf oder /etc/apache2/httpd.conf. Öffnen Sie die Konfigurationsdatei mit Root -Berechtigungen mit dem folgenden Befehl: Sudonano/etc/apache2/apache2.conf oder sudonano/etc/apache2/httpd.conf Schritt 2: Definieren Sie benutzerdefinierte Protokollformate, um zu finden oder zu finden oder
 Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Wie Tomcat -Protokolle bei der Fehlerbehebung bei Speicherlecks helfen
Apr 12, 2025 pm 11:42 PM
Tomcat -Protokolle sind der Schlüssel zur Diagnose von Speicherleckproblemen. Durch die Analyse von Tomcat -Protokollen können Sie Einblicke in das Verhalten des Speicherverbrauchs und des Müllsammlung (GC) erhalten und Speicherlecks effektiv lokalisieren und auflösen. Hier erfahren Sie, wie Sie Speicherlecks mit Tomcat -Protokollen beheben: 1. GC -Protokollanalyse zuerst aktivieren Sie eine detaillierte GC -Protokollierung. Fügen Sie den Tomcat-Startparametern die folgenden JVM-Optionen hinzu: -xx: printgCDetails-xx: printgCDatESTAMPS-XLOGGC: GC.Log Diese Parameter generieren ein detailliertes GC-Protokoll (GC.Log), einschließlich Informationen wie GC-Typ, Recycling-Objektgröße und Zeit. Analyse gc.log
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
Wie man Debian Syslog lernt
Apr 13, 2025 am 11:51 AM
In diesem Leitfaden werden Sie erfahren, wie Sie Syslog in Debian -Systemen verwenden. Syslog ist ein Schlüsseldienst in Linux -Systemen für Protokollierungssysteme und Anwendungsprotokollnachrichten. Es hilft den Administratoren, die Systemaktivitäten zu überwachen und zu analysieren, um Probleme schnell zu identifizieren und zu lösen. 1. Grundkenntnisse über syslog Die Kernfunktionen von Syslog umfassen: zentrales Sammeln und Verwalten von Protokollnachrichten; Unterstützung mehrerer Protokoll -Ausgabesformate und Zielorte (z. B. Dateien oder Netzwerke); Bereitstellung von Echtzeit-Protokoll- und Filterfunktionen. 2. Installieren und Konfigurieren von Syslog (mit Rsyslog) Das Debian -System verwendet standardmäßig Rsyslog. Sie können es mit dem folgenden Befehl installieren: sudoaptupdatesud
 So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
So konfigurieren Sie Firewall -Regeln für Debian Syslog
Apr 13, 2025 am 06:51 AM
In diesem Artikel wird beschrieben, wie Sie Firewall -Regeln mit Iptables oder UFW in Debian -Systemen konfigurieren und Syslog verwenden, um Firewall -Aktivitäten aufzuzeichnen. Methode 1: Verwenden Sie IptableSiptables ist ein leistungsstarkes Befehlszeilen -Firewall -Tool im Debian -System. Vorhandene Regeln anzeigen: Verwenden Sie den folgenden Befehl, um die aktuellen IPTables-Regeln anzuzeigen: Sudoiptables-L-N-V Ermöglicht spezifische IP-Zugriff: ZBELTE IP-Adresse 192.168.1.100 Zugriff auf Port 80: sudoiptables-ainput-ptcp--dort80-s192.16
 Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Wo ist der Debian Nginx Log Path
Apr 12, 2025 pm 11:33 PM
Im Debian -System sind die Standardspeicherorte des Zugriffsprotokolls von NGINX wie folgt wie folgt: Zugriffsprotokoll (AccessLog):/var/log/nginx/access.log Fehlerprotokoll (FehlerLog):/var/log/nginx/fehler Wenn Sie den Speicherort der Protokolldatei während des Installationsprozesses geändert haben, überprüfen Sie bitte Ihre Nginx-Konfigurationsdatei (normalerweise in /etc/nginx/nginx.conf oder/etc/nginx/seiten-AVailable/Verzeichnis). In der Konfigurationsdatei
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
