


In den letzten Jahren haben große Sprachmodelle (LLMs) bei verschiedenen sprachbezogenen Aufgaben bemerkenswerte Leistungen erbracht. Trotz ihrer Erfolge beim mathematischen Denken, beim Denken mit gesundem Menschenverstand und bei anderen Denkaufgaben wie dem symbolischen oder logischen Denken sind ihre Fähigkeiten im räumlichen Denken noch immer wenig erforscht.Große Sprachmodelle (LLMs) zeigen beeindruckende Leistungen beim Sprachverständnis und bei verschiedenen Argumentationsaufgaben. Allerdings sind sie in Bezug auf einen Schlüsselaspekt der menschlichen Kognition nach wie vor wenig erforscht: das räumliche Denken. Menschen haben die Fähigkeit, durch einen Prozess, der als „Mind's Eye“ bekannt ist, mentale Bilder von unsichtbaren Objekten und Handlungen zu erzeugen, wodurch es möglich wird, sich die unsichtbare Welt vorzustellen. Inspiriert von dieser kognitiven Fähigkeit schlugen Forscher die Visualisierung des Denkens (VoT) vor. VoT zielt darauf ab, das räumliche Denken von LLMs durch die Visualisierung ihrer Argumentationszeichen zu steuern und so nachfolgende Argumentationsschritte zu steuern. Die Forscher wandten VoT auf Multi-Hop-Aufgaben zum räumlichen Denken an, darunter Navigation in natürlicher Sprache, visuelle Navigation und visuelles Pflastern in einer zweidimensionalen Gitterwelt. Experimentelle Ergebnisse zeigen, dass VoT die räumlichen Denkfähigkeiten von LLMs erheblich verbessert. Insbesondere übertrifft VoT bei diesen Aufgaben bestehende multimodale große Sprachmodelle (MLLMs) . Einführung
Das räumliche Denken ist eine grundlegende Funktion der menschlichen Wahrnehmung
und ermöglicht uns die Interaktion mit unserer Umwelt. Es erleichtert Aufgaben, die Verständnis und Überlegungen zu räumlichen Beziehungen zwischen Objekten und ihrer Bewegung erfordern. Das räumliche Denken von Sprachmodellen stützt sich in hohem Maße auf die Sprache, um über räumliche Informationen nachzudenken, und die kognitiven Fähigkeiten des Menschen übertreffen das sprachliche Denken bei weitem. Menschen können nicht nur aus visueller Wahrnehmung aufgabenrelevante abstrakte Darstellungen erstellen, sondern sich auch unsichtbare Szenen durch das geistige Auge vorstellen. Dies ist ein Forschungsthema, das als „mentale Bilder“ in den Bereichen Neurowissenschaften, Philosophie des Geistes und Kognitionswissenschaft bekannt ist. Aufbauend auf dieser kognitiven Funktion erleichtert der Mensch das räumliche Denken durch die Manipulation mentaler Bilder wie Navigation, mentale Rotation, mentales Papierfalten und mentale Simulation. Abbildung 1 veranschaulicht die menschlichen Prozesse, die an Navigationsaufgaben beteiligt sind. Menschen verbessern ihr räumliches Bewusstsein und leiten ihre Entscheidungen, indem sie sich mentale Bilder von Wegen erstellen und dabei verschiedene sensorische Eingaben wie Navigationsanweisungen oder Kartenbilder nutzen. Anschließend simulierten sie die Wegplanung vor dem geistigen Auge.Abbildung 1: Menschen können ihr räumliches Bewusstsein verbessern und die Entscheidungsfindung leiten, indem sie beim räumlichen Denken mentale Bilder erzeugen. Ebenso können große Sprachmodelle (LLMs) interne mentale Bilder aufbauen. Die Forscher schlugen VoT vor, um das „geistige Auge“ von LLMs anzuregen, indem ihr Denken bei jedem Zwischenschritt visualisiert und so das räumliche Denken gefördert wird.
Inspiriert durch diesen kognitiven Mechanismus spekulieren Forscher, dass LLMs die Fähigkeit haben, mentale Bilder im geistigen Auge zu erzeugen und zu manipulieren, um räumliches Denken zu ermöglichen. Wie in Abbildung 1 dargestellt, können LLMs möglicherweise räumliche Informationen in verschiedenen Formaten verarbeiten und verstehen. Sie sind möglicherweise in der Lage, innere Zustände zu visualisieren und diese mentalen Bilder durch das geistige Auge zu manipulieren, um nachfolgende Denkschritte zu steuern und so das räumliche Denken zu verbessern. Daher schlugen Forscher Eingabeaufforderungen zur 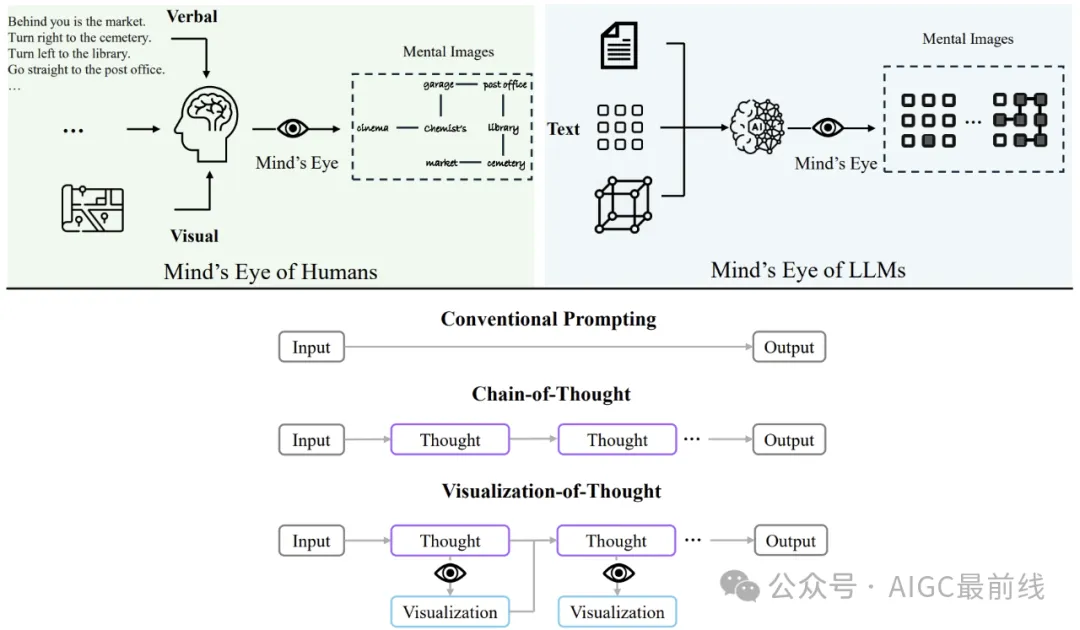 Visualisierung des Denkens (VoT)
Visualisierung des Denkens (VoT)
Navigation in natürlicher Sprache, visuelle Navigation und visuelles Pflastern. Für diese Aufgaben ist das Verständnis räumlicher, richtungsbezogener und geometrischer Formschlüsse erforderlich. Um die menschenähnliche multisensorische Wahrnehmung zu simulieren, entwarfen die Forscher 2D-Gitterwelten, die Sonderzeichen als reichhaltige Eingabeformate für die visuelle Navigation und die visuellen Legeaufgaben von LLMs verwenden. Bei diesen drei Aufgaben wurden verschiedene Modelle (GPT-4, GPT-4V) und Aufforderungstechniken verglichen. Forschungsergebnisse zeigen, dass VoT-Eingabeaufforderungen LLMs regelmäßig dazu auffordern, ihre Argumentationsschritte zu visualisieren und nachfolgende Schritte anzuleiten
. Daher erzielt diese Methode erhebliche Leistungsverbesserungen bei den entsprechenden Aufgaben.Abbildung 2: Beispiele für Navigationskarten in verschiedenen Umgebungen, wobei ein Haus-Emoji den Startpunkt und ein Büro-Emoji das Ziel darstellt.
Räumliches Denken bezieht sich auf die Fähigkeit, die räumlichen Beziehungen zwischen Objekten, ihre Bewegungen und Interaktionen zu verstehen und darüber nachzudenken. Diese Fähigkeit ist für eine Vielzahl realer Anwendungen wichtig, beispielsweise für Navigation, Robotik und autonomes Fahren. Diese Bereiche erfordern eine Handlungsplanung, die auf visueller Wahrnehmung und einem detaillierten Verständnis räumlicher Dimensionen basiert. Obwohl mehrere Aufgaben und Datensätze entwickelt wurden, um die in Texten eingebettete räumliche Semantik zu untersuchen, konzentrierten sich die Forschungsanstrengungen im Allgemeinen auf die sprachliche Struktur räumlicher Begriffe. In jüngster Zeit wurden bei diesen Benchmarks durch die Umwandlung räumlicher Begriffe in logische Formen und den Einsatz logischer Programmierung bedeutende Erfolge und beeindruckende Ergebnisse erzielt. Das bedeutet, dass eine gute Leistung bei diesen Aufgaben nicht unbedingt bedeutet, dass große Sprachmodelle (LLMs) räumliche Informationen wirklich verstehen, noch dass sie ein genaues Maß für ihr räumliches Bewusstsein liefern. Zur räumlichen Wahrnehmung gehört das Verständnis räumlicher Beziehungen, Richtungen, Entfernungen und Geometrie, die für die Planung von Handlungen in der physischen Welt unerlässlich sind. Um das räumliche Bewusstsein und die räumlichen Denkfähigkeiten von LLMs zu beurteilen, wählten die Forscher eine Reihe von Aufgaben aus, die Navigation und geometrische Denkfähigkeiten testen, darunter Navigation in natürlicher Sprache, visuelle Navigation und visuelles Pflastern.
Navigation in natürlicher Sprache beinhaltet das Durchsuchen der zugrunde liegenden räumlichen Struktur durch einen zufälligen Spaziergang mit dem Ziel, zuvor besuchte Orte zu identifizieren. Das Konzept wurde von früheren Forschungen zur menschlichen Kognition inspiriert und verwendete einen Ansatz, der einem zufälligen Spaziergang entlang einer Diagrammstruktur ähnelt. Dieser Prozess erfordert ein Verständnis des Schleifenschlusses, der für die räumliche Navigation von entscheidender Bedeutung ist.



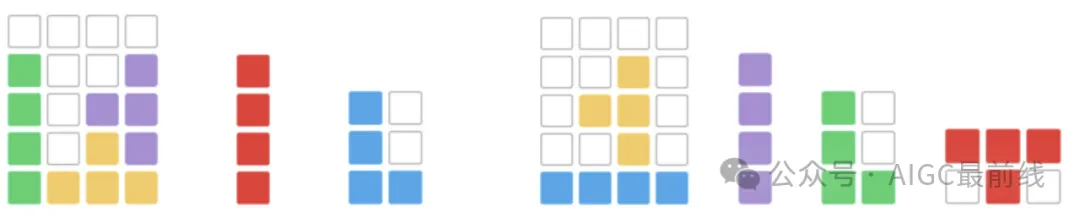
Abbildung 3: Beispiel einer visuellen Verlegung mit maskierten Dominosteinen. Das Bild zeigt nicht die gedrehten und gespiegelten Varianten der Dominosteine.
Denken
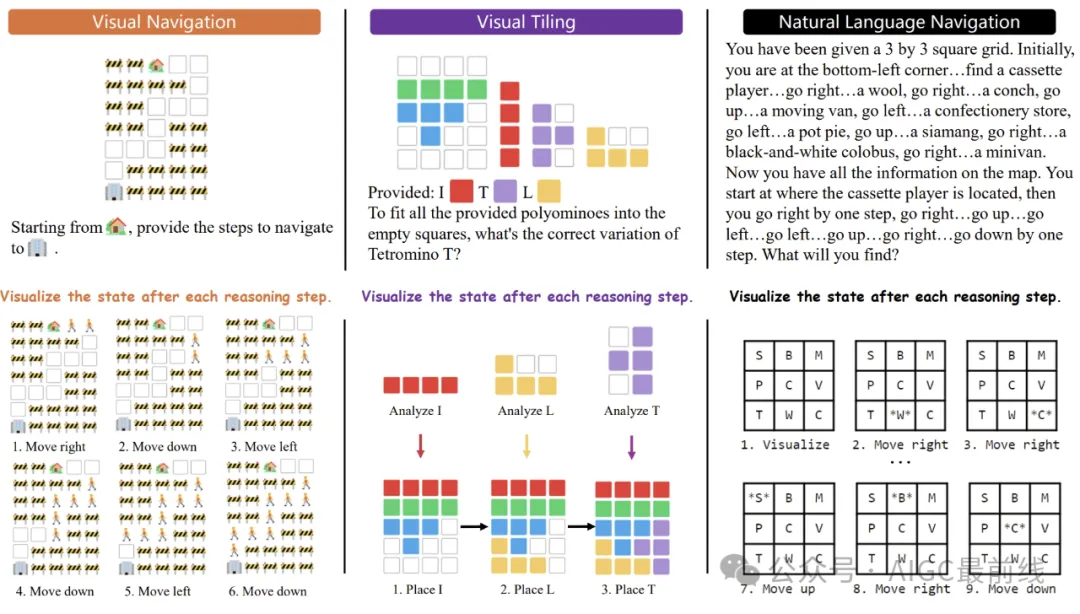
Abbildung 4: Beispiele für VoT-Eingabeaufforderungen in drei Aufgaben, bei denen LLM Inferenzzeichen und Visualisierungen in verschachtelter Weise generiert, um sich ändernde Zustände im Laufe der Zeit zu verfolgen.

Papier: https://arxiv.org/pdf/2404.03622.pdf
Das obige ist der detaillierte Inhalt vonStimulieren Sie die räumliche Denkfähigkeit großer Sprachmodelle: Tipps zur Denkvisualisierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



