
 Technologie-Peripheriegeräte
KI
Effizienz um das 16-fache erhöht! VRSO: 3D-Annotation von rein visuellen statischen Objekten, wodurch der geschlossene Datenkreislauf geöffnet wird!
Technologie-Peripheriegeräte
KI
Effizienz um das 16-fache erhöht! VRSO: 3D-Annotation von rein visuellen statischen Objekten, wodurch der geschlossene Datenkreislauf geöffnet wird!
Effizienz um das 16-fache erhöht! VRSO: 3D-Annotation von rein visuellen statischen Objekten, wodurch der geschlossene Datenkreislauf geöffnet wird!

Death of Labeling
Statische Objekterkennung (SOD), einschließlich Ampeln, Leitschilder und Verkehrskegel, die meisten Algorithmen sind datengesteuerte tiefe neuronale Netze und erfordern eine große Menge an Trainingsdaten. Die aktuelle Praxis umfasst typischerweise die manuelle Annotation einer großen Anzahl von Trainingsbeispielen auf LiDAR-gescannten Punktwolkendaten, um Long-Tail-Fälle zu beheben.

Manuelle Annotation ist schwierig, die Variabilität und Komplexität realer Szenen zu erfassen, und berücksichtigt häufig Verdeckungen, unterschiedliche Lichtverhältnisse und unterschiedliche Betrachtungswinkel nicht (gelbe Pfeile in Abbildung 1). Der gesamte Prozess hat lange Verknüpfungen, ist äußerst zeitaufwändig, fehleranfällig und kostspielig (Abbildung 2). Daher sind Unternehmen derzeit auf der Suche nach automatischen Etikettierungslösungen, insbesondere basierend auf reiner Sicht. Schließlich verfügt nicht jedes Auto über Lidar.
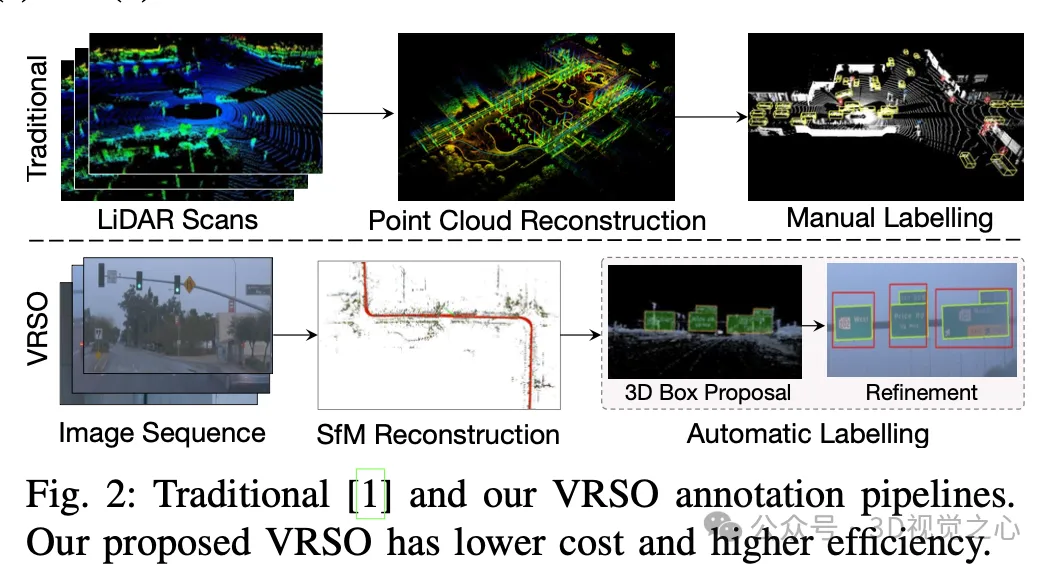
VRSO+ ist ein visionsbasiertes Annotationssystem für statische Objektannotationen. Es nutzt hauptsächlich Informationen aus SFM, 2D-Objekterkennung und Instanzsegmentierungsergebnissen. Der Gesamteffekt ist:
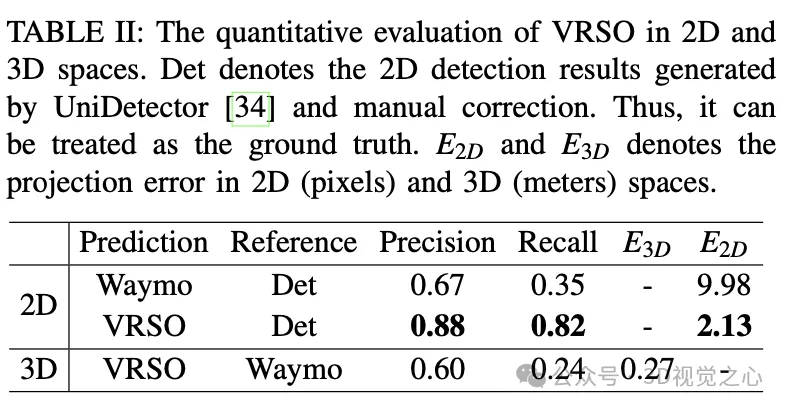
- Der durchschnittliche Projektionsfehler der Annotation beträgt ist 2,6 Pixel, etwa ein Viertel der Waymo-Annotation (10,6 Pixel)
- Im Vergleich zur manuellen Annotation wird die Geschwindigkeit um etwa das 16-fache erhöht
Bei statischen Objekten extrahiert VRSO Schlüsselpunkte durch Instanzsegmentierung und Konturen, um die Herausforderung zu lösen Die Integration und Deduplizierung statischer Objekte aus verschiedenen Blickwinkeln sowie die Schwierigkeit einer Unterbeobachtung aufgrund von Okklusionsproblemen verbessert die Anmerkungsgenauigkeit. Aus Abbildung 1 geht hervor, dass VRSO im Vergleich zu den manuellen Annotationsergebnissen des Waymo Open-Datensatzes eine höhere Robustheit und geometrische Genauigkeit zeigt.
(Sie haben das alle gesehen. Wischen Sie doch mit dem Daumen nach oben und klicken Sie auf die Karte oben, um mir zu folgen. Der gesamte Vorgang dauert nur 1,328 Sekunden und Sie erhalten dann alle nützlichen Informationen die Zukunft, falls es nützlich ist~)
Wie man die Situation durchbricht
Das VRSO-System ist hauptsächlich in zwei Teile unterteilt: Szenenrekonstruktion und Statische Objektanmerkung.
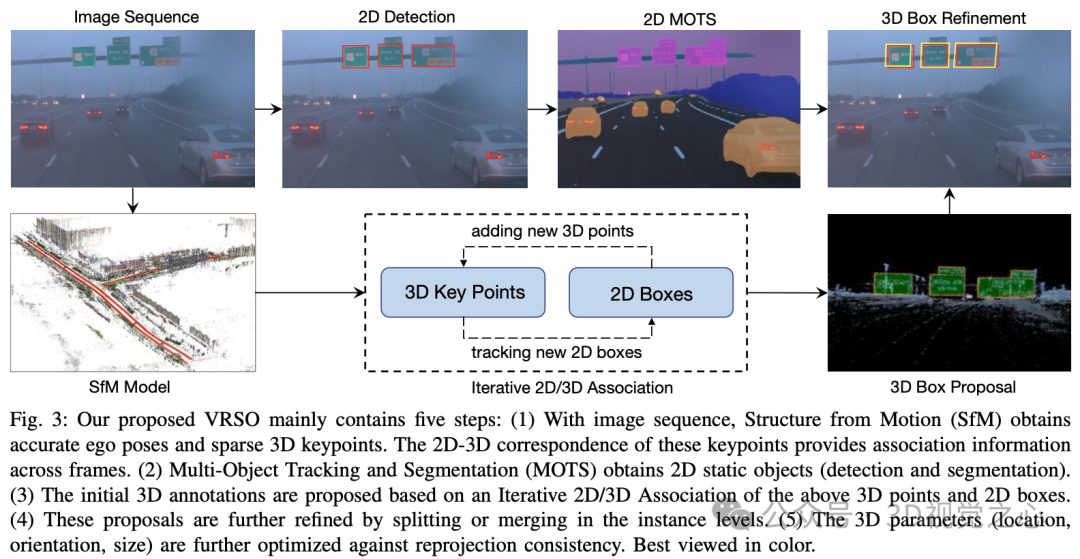
Der Rekonstruktionsteil steht nicht im Mittelpunkt, er basiert auf dem SFM-Algorithmus, um die Bildhaltung und spärliche 3D-Schlüsselpunkte wiederherzustellen.
Statischer Objektannotationsalgorithmus, kombiniert mit Pseudocode, der allgemeine Prozess ist (im Folgenden wird Schritt für Schritt detailliert beschrieben):
- Verwendung vorgefertigter 2D-Objekterkennungs- und Segmentierungsalgorithmen zur Generierung von Kandidaten
- Verwendung von 3D-2D Schlüsselpunktkorrespondenz im SFM-Modell Beziehungen zur Verfolgung von 2D-Instanzen über Frames hinweg
- Einführung der Reprojektionskonsistenz zur Optimierung der 3D-Anmerkungsparameter statischer Objekte

1. Verfolgung von Beziehungen
- Schritt 1: Extrahieren Sie 3D-Grenzen basierend auf Schlüsselpunkte des SFM-Modells 3D-Punkte innerhalb der Box.
- Schritt 2: Berechnen Sie die Koordinaten jedes 3D-Punkts auf der 2D-Karte basierend auf der 2D-3D-Übereinstimmungsbeziehung.
- Schritt 3: Bestimmen Sie die entsprechende Instanz des 3D-Punkts auf der aktuellen 2D-Karte basierend auf den 2D-Kartenkoordinaten und den Eckpunkten der Instanzsegmentierung.
- Schritt 4: Bestimmen Sie die Entsprechung zwischen 2D-Beobachtungen und 3D-Begrenzungsrahmen für jedes 2D-Bild.
2.proposal generiert
, um die 3D-Box-Parameter (Position, Richtung, Größe) des statischen Objekts für den gesamten Videoclip zu initialisieren. Jeder Schlüsselpunkt von SFM verfügt über eine genaue 3D-Position und ein entsprechendes 2D-Bild. Für jede 2D-Instanz werden Merkmalspunkte innerhalb der 2D-Instanzmaske extrahiert. Dann kann ein Satz entsprechender 3D-Schlüsselpunkte als Kandidaten für 3D-Begrenzungsrahmen betrachtet werden.
Ein Straßenschild wird als Rechteck mit einer Ausrichtung im Raum dargestellt, das 6 Freiheitsgrade hat, einschließlich Translation (,,), Ausrichtung (θ) und Größe (Breite und Höhe). Aufgrund ihrer Tiefe verfügt eine Ampel über 7 Freiheitsgrade. Verkehrskegel werden ähnlich wie Ampeln dargestellt.
3.Vorschlag verfeinern
- Schritt 1: Extrahieren Sie den Umriss jedes statischen Objekts aus der 2D-Instanzsegmentierung.
- Schritt 2: Passen Sie den minimal orientierten Begrenzungsrahmen (OBB) für die Konturkontur an.
- Schritt 3: Extrahieren Sie die Eckpunkte des minimalen Begrenzungsrahmens.
- Schritt 4: Berechnen Sie die Richtung basierend auf den Scheitelpunkten und Mittelpunkten und bestimmen Sie die Scheitelpunktreihenfolge.
- Schritt 5: Der Segmentierungs- und Zusammenführungsprozess wird basierend auf den Ergebnissen der 2D-Erkennung und der Instanzsegmentierung durchgeführt.
- Schritt 6: Beobachtungen mit Verdeckungen erkennen und verwerfen. Das Extrahieren von Eckpunkten aus der 2D-Instanzsegmentierungsmaske erfordert, dass alle vier Ecken jedes Zeichens sichtbar sind. Bei Verdeckungen werden achsenausgerichtete Begrenzungsrahmen (AABBs) aus der Instanzsegmentierung extrahiert und das Flächenverhältnis zwischen AABBs und 2D-Erkennungsrahmen berechnet. Wenn keine Verdeckungen vorhanden sind, sollten diese beiden Flächenberechnungsmethoden nahe beieinander liegen.
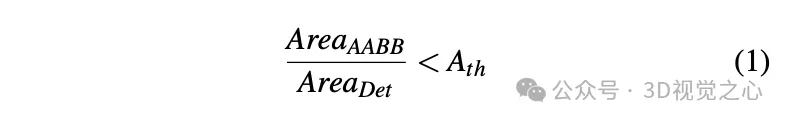
4. Triangulation
Erhalten Sie den anfänglichen Scheitelpunktwert des statischen Objekts unter 3D-Bedingungen durch Triangulation.
Durch die Überprüfung der Anzahl der Schlüsselpunkte in den 3D-Begrenzungsrahmen, die durch SFM und Instanzsegmentierung während der Szenenrekonstruktion erhalten wurden, gelten nur Instanzen, deren Anzahl der Schlüsselpunkte den Schwellenwert überschreitet, als stabile und gültige Beobachtungen. In diesen Fällen wird der entsprechende 2D-Begrenzungsrahmen als gültige Beobachtung betrachtet. Durch die 2D-Beobachtung mehrerer Bilder werden die Eckpunkte des 2D-Begrenzungsrahmens trianguliert, um die Koordinaten des Begrenzungsrahmens zu erhalten.
Bei kreisförmigen Schildern, die die Scheitelpunkte „unten links, oben links, oben rechts, oben rechts und unten rechts“ auf der Maske nicht unterscheiden, müssen diese kreisförmigen Schilder identifiziert werden. Unter Verwendung von 2D-Erkennungsergebnissen als Beobachtungen kreisförmiger Objekte werden 2D-Instanzsegmentierungsmasken zur Konturextraktion verwendet. Der Mittelpunkt und der Radius werden durch einen Anpassungsalgorithmus der kleinsten Quadrate berechnet. Zu den Parametern des Kreiszeichens gehören der Mittelpunkt (,,), die Richtung (θ) und der Radius ().
5. Tracking-Verfeinerung
Tracking-Feature-Punkt-Zuordnung basierend auf SFM. Bestimmen Sie, ob diese getrennten Instanzen basierend auf dem euklidischen Abstand der Eckpunkte des 3D-Begrenzungsrahmens und der IoU der 2D-Begrenzungsrahmenprojektion zusammengeführt werden sollen. Sobald die Zusammenführung abgeschlossen ist, können 3D-Feature-Punkte innerhalb einer Instanz gruppiert werden, um weitere 2D-Feature-Punkte zuzuordnen. Es wird eine iterative 2D-3D-Assoziation durchgeführt, bis keine 2D-Feature-Punkte mehr hinzugefügt werden können.
6. Endgültige Parameteroptimierung
Am Beispiel des rechteckigen Zeichens umfassen die Parameter, die optimiert werden können, Position (,,), Richtung (θ) und Größe (,) mit insgesamt sechs Grad der Freiheit. Die Hauptschritte umfassen:
- Konvertieren Sie sechs Freiheitsgrade in vier 3D-Punkte und berechnen Sie die Rotationsmatrix.
- Projizieren Sie die konvertierten vier 3D-Punkte auf das 2D-Bild.
- Berechnen Sie den Rest zwischen dem Projektionsergebnis und dem durch Instanzsegmentierung erhaltenen Eckpunktergebnis.
- Verwendung von Huber zur Optimierung und Aktualisierung der Begrenzungsrahmenparameter
Anmerkungseffekte


Es gibt auch einige herausfordernde Long-Tail-Fälle, wie z. B. extrem niedrige Auflösung und unzureichende Beleuchtung.

Zusammenfassend
Das VRSO-Framework ermöglicht eine hochpräzise und konsistente 3D-Annotation statischer Objekte, integriert Erkennungs-, Segmentierungs- und SFM-Algorithmen eng, eliminiert manuelle Eingriffe bei der intelligenten Fahrannotation und liefert vergleichbare LiDAR-basierte Ergebnisse zur manuellen Anmerkung. Qualitative und quantitative Auswertungen wurden mit dem weithin anerkannten Waymo Open Dataset durchgeführt: Im Vergleich zur manuellen Annotation wird die Geschwindigkeit um etwa das 16-fache erhöht, bei gleichzeitig bester Konsistenz und Genauigkeit.
Das obige ist der detaillierte Inhalt vonEffizienz um das 16-fache erhöht! VRSO: 3D-Annotation von rein visuellen statischen Objekten, wodurch der geschlossene Datenkreislauf geöffnet wird!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Jagdanzug-Design, neue smarte Luxus-Flaggschiff-Limousine: DENZA Z9GT ein echter Schuss
Apr 22, 2024 pm 02:10 PM
Jagdanzug-Design, neue smarte Luxus-Flaggschiff-Limousine: DENZA Z9GT ein echter Schuss
Apr 22, 2024 pm 02:10 PM
Laut Nachrichten vom 22. April feierte Denzas neues Flaggschiffmodell Z9GT heute Morgen sein Debüt. Jetzt möchte ich einige Bilder aus dem wirklichen Leben mit Ihnen teilen. Der offiziellen Vorstellung zufolge ist das neue Auto als smarte Luxus-Flaggschiff-Limousine positioniert, mit einer Länge von 5180 mm, die das Niveau einer D-Klasse-Luxuslimousine erreicht. Wolfgang Egger, globaler Designdirektor von BYD, leitete die Bemühungen, das Erscheinungsbild zu schaffen Ausgestattet mit „e³“-Schwarz-Technologie, mehreren Lidar- und anderen Konfigurationen, mit fast tausend PS. In puncto Design vereint der Denza Z9GT perfekt östliche und westliche Ästhetik mit einer auffälligen Vorderseite. An der Seite der Karosserie ist die „Z“-förmige Zierlinie exquisit und glatt, und der Schwerpunkt der Karosserie liegt relativ weit hinten, wodurch eine nach hinten geneigte Haltung entsteht, die sehr sportlich ist. Das Heck des Fahrzeugs ist rund und voll, und die Rücklichter erstrecken sich von der Mitte zu beiden Seiten und spiegeln die elektrischen Heckflügel wider, was dem gesamten Fahrzeug einen hohen Wiedererkennungswert verleiht. Wert
 Der Tank 300Hi4-T gibt ein starkes Debüt: die perfekte Kombination aus Geländegängigkeit und Intelligenz
Apr 23, 2024 pm 06:16 PM
Der Tank 300Hi4-T gibt ein starkes Debüt: die perfekte Kombination aus Geländegängigkeit und Intelligenz
Apr 23, 2024 pm 06:16 PM
Laut Nachrichten vom 23. April ist der mit Spannung erwartete Great Wall Tank 300Hi4-T kürzlich endlich offiziell auf den Markt gekommen. Dieses Modell hat aufgrund seiner einzigartigen Konfiguration und begrenzten Knappheit große Aufmerksamkeit erregt. Es wird berichtet, dass dieses Mal nur eine Konfiguration des Tank 300Hi4-T mit einem empfohlenen Verkaufspreis von 269.800 Yuan auf den Markt kommt und nur 3.000 Einheiten zum Verkauf stehen. Aus gestalterischer Sicht vermittelt der Tank 300Hi4-T eine starke Offroad-Atmosphäre. Es verfügt über ein professionelles Offroad-Chassis mit nicht tragender Karosserie, was zeigt, dass die Stabilität und die Offroad-Fähigkeiten des Fahrzeugs verbessert werden. Im vorderen Teil des Fahrzeugs ergänzt das ikonische runde Leuchtenset den horizontalen Kühlergrill mit drei Rahmen, und der silberverchromte Frontgrill lässt das Fahrzeug robuster und kraftvoller aussehen. Die Radhäuser und Außenspiegel in der gleichen Farbe wie die Karosserie unterstreichen das Erscheinungsbild dieses Fahrzeugs
 Xiangjie S9 debütiert auf der Beijing Auto Show, Huawei und BAIC Blue Valleys erste reine Elektrolimousine steht kurz vor der Premiere
Apr 23, 2024 pm 01:13 PM
Xiangjie S9 debütiert auf der Beijing Auto Show, Huawei und BAIC Blue Valleys erste reine Elektrolimousine steht kurz vor der Premiere
Apr 23, 2024 pm 01:13 PM
Neuigkeiten vom 23. April: Neuesten Berichten zufolge wird die mit Spannung erwartete reine Elektrolimousine Enjoy S9 auf der kommenden Beijing Auto Show erstmals der Öffentlichkeit vorgestellt. Dieses Auto ist ein Meisterwerk, das BAIC Blue Valley und Huawei gemeinsam für die beiden Branchenriesen geschaffen haben. Es ist im mittleren und großen Limousinenmarkt positioniert und wird voraussichtlich für nicht weniger als 500.000 Yuan verkauft. S9 hat kürzlich das entsprechende Antragsverfahren beim Ministerium für Industrie und Informationstechnologie abgeschlossen, was darauf hindeutet, dass der offizielle Start näher rückt. Den offengelegten Informationen nach zu urteilen, verfügt das neue Auto über ein markantes Außendesign mit einer modernen durchgehenden LED-Lichtgruppe und drei Sätzen von Lichtquellen, die sorgfältig in der Scheinwerfergruppe verteilt sind. Sein geschlossener Frontgrill und das auffällige Design der Wärmeableitungsöffnungen an der Vorderseite sorgen gemeinsam für ein stabiles und dennoch modisches Temperament. Der Datenredakteur versteht und genießt die eleganten Seitenlinien der S9-Karosserie.
 Die neue Generation des Great Wall Haval H6 und H9 wird auf der Beijing Auto Show 2024 vorgestellt
Apr 25, 2024 pm 07:07 PM
Die neue Generation des Great Wall Haval H6 und H9 wird auf der Beijing Auto Show 2024 vorgestellt
Apr 25, 2024 pm 07:07 PM
Am 25. April 2024 hatte Great Wall Haval mit seinem Haval H6 der neuen Generation, dem Haval H9 der neuen Generation, dem 2024 Haval Raptor und anderen Starmodellen einen großen Auftritt auf der 18. Internationalen Automobilausstellung in Peking. China Haval genießt weltweites Vertrauen, und die Marke Haval beschleunigt ihre Erschließung des globalen Marktes. Auf dieser Automesse nahm Great Wall Haval das Thema „China Haval, Global Trust“ auf und interpretierte damit das starke Engagement der Marke Haval gegenüber den Nutzern voll und ganz „Globaler SUV-Experte“. Great Wall Haval engagiert sich seit 13 Jahren intensiv im SUV-Bereich, angetrieben von technologischer Innovation und nutzt Kernproduktkompetenzen und zuverlässige Dienstleistungen, um Verbrauchern hochwertige SUV-Produkte anzubieten. Von der Führungsspitze Chinas zur Globalisierung schafft Great Wall Haval weiterhin hervorragende SUV-Produkterlebnisse, reagiert auf die Erwartungen und das Vertrauen von immer mehr Nutzern und prägt die Globalisierung chinesischer Marken
 Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Das Neueste von der Universität Oxford! Mickey: 2D-Bildabgleich in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Projektlink vorne geschrieben: https://nianticlabs.github.io/mickey/ Anhand zweier Bilder kann die Kameraposition zwischen ihnen geschätzt werden, indem die Korrespondenz zwischen den Bildern hergestellt wird. Normalerweise handelt es sich bei diesen Entsprechungen um 2D-zu-2D-Entsprechungen, und unsere geschätzten Posen sind maßstabsunabhängig. Einige Anwendungen, wie z. B. Instant Augmented Reality jederzeit und überall, erfordern eine Posenschätzung von Skalenmetriken und sind daher auf externe Tiefenschätzer angewiesen, um die Skalierung wiederherzustellen. In diesem Artikel wird MicKey vorgeschlagen, ein Keypoint-Matching-Prozess, mit dem metrische Korrespondenzen im 3D-Kameraraum vorhergesagt werden können. Durch das Erlernen des 3D-Koordinatenabgleichs zwischen Bildern können wir auf metrische Relativwerte schließen
 Denza Z9GT wird auf der Beijing Auto Show 2024 debütieren und sein Überseepreis könnte eine Million Yuan übersteigen
Apr 25, 2024 pm 07:52 PM
Denza Z9GT wird auf der Beijing Auto Show 2024 debütieren und sein Überseepreis könnte eine Million Yuan übersteigen
Apr 25, 2024 pm 07:52 PM
Am 25. April startete die 18. Internationale Automobilausstellung in Peking offiziell mit einem beeindruckenden Auftritt in Halle W4. Der Stand war voller Menschen und war damit der beliebteste Check-in-Punkt auf dieser Beijing Auto Show! Unter ihnen feiert der Denza Z9GT seine Weltpremiere. Er ist ein weiteres Spitzenwerk von Wolfgang Egger, dem Designdirektor der BYD Group. Er ist auch der erste, der die weltweit führende disruptive Technologieplattform nutzt Yi Sanfang, der den Weg weist. Der neue Trend der Elektrifizierung von Luxusautos. Unter der Leitung von Iger und ausgestattet mit bahnbrechender Technologie steht der Denza Z9GT im Mittelpunkt der diesjährigen Automobilausstellung. Als erstes Modell von Denzas neuem Designkonzept „Elegance in Motion“ steht das Erscheinungsbild des Denza Z9GT unter der Leitung von Eger und ist perfekt gestaltet .
 Die Blue Mountain Smart Driving Edition der Marke Great Wall Wei unterstützt NOA für unbekannte Städte und wird voraussichtlich im Juni offiziell veröffentlicht
May 09, 2024 pm 09:10 PM
Die Blue Mountain Smart Driving Edition der Marke Great Wall Wei unterstützt NOA für unbekannte Städte und wird voraussichtlich im Juni offiziell veröffentlicht
May 09, 2024 pm 09:10 PM
Berichten vom 9. Mai 2024 zufolge stellte Wei Brand, eine Tochtergesellschaft von Great Wall Motors, auf der diesjährigen Beijing International Auto Show ein neues Modell vor – die Blue Mountain Smart Driving Edition, das die Aufmerksamkeit vieler Besucher auf sich zog. Laut „Knowing Car Emperor's Vision“ wird dieses mit Spannung erwartete neue Auto voraussichtlich im Juni dieses Jahres offiziell auf den Markt kommen. Das Design der Blue Mountain Smart Driving Edition orientiert sich weiterhin am klassischen Erscheinungsbild des zum Verkauf stehenden Blue Mountain DHT-PHEV, wurde jedoch hinsichtlich des intelligenten Fahrgefühls deutlich aufgewertet. Das Auffälligste ist, dass auf dem Dach ein Lidar im Wachturmstil installiert ist. Gleichzeitig ist das Fahrzeug mit 3-Millimeter-Wellenradargeräten und 12 Ultraschallradargeräten sowie 11 hochauflösenden visuellen Wahrnehmungskameras ausgestattet. Insgesamt 27 Fahrassistenzsensoren verbessern die Umweltwahrnehmung des Fahrzeugs erheblich. entsprechend
 Wenjie M9 treibt 6,65-GB-System-Upgrade voran, mehrere Funktionen optimiert
Apr 21, 2024 pm 06:40 PM
Wenjie M9 treibt 6,65-GB-System-Upgrade voran, mehrere Funktionen optimiert
Apr 21, 2024 pm 06:40 PM
Laut Nachrichten vom 21. April 2021 hat die Q&A-Community des M9-Modells kürzlich das Versionsupdate V4.2.1.4 an Benutzer weitergegeben. Die Größe des aktualisierten Softwarepakets erreicht 6,65 GB. Es fügt nicht nur neue Funktionen hinzu, sondern optimiert auch einige bestehende Funktionen. Es wird berichtet, dass dieses Update eine Reihe auffälliger neuer Funktionen zu Q&A M9 bringt. Dazu gehört die intelligente interaktive Matrix-Scheinwerfer-Szenenlicht-Sprachfunktion, die dem Fahrer ein umfassenderes interaktives Erlebnis bietet. Gleichzeitig ermöglicht die neu hinzugefügte ADS-Dual-3D-Ansichtsfunktion dem Fahrer, die ADS-3D-Ansicht gleichzeitig auf dem Instrument und dem zentralen Steuerbildschirm anzuzeigen, was den Fahrkomfort und die Sicherheit erhöht. Darüber hinaus sind eine Rückfahrkamera-Reinigungsfunktion sowie intelligente Fahrassistenzfunktionen wie die aktive Vermeidung von Hindernissen auf der Fahrspur und die Erinnerung an eine falsche Gaspedalbetätigung enthalten.
