
 Technologie-Peripheriegeräte
KI
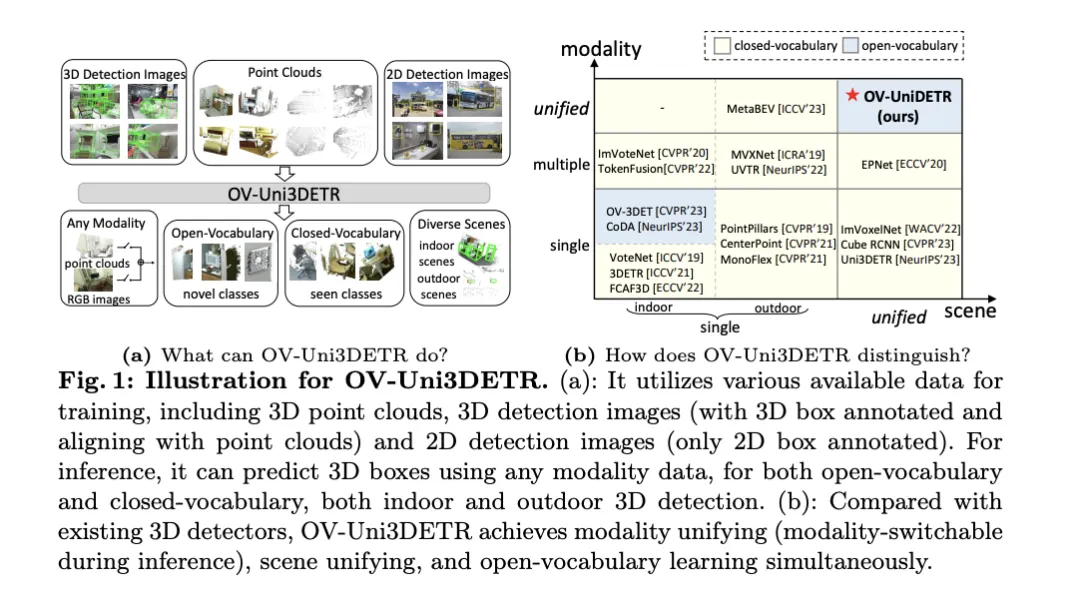
Mehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU)
Technologie-Peripheriegeräte
KI
Mehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU)
Mehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU)

In diesem Artikel wird der Bereich der 3D-Objekterkennung erörtert, insbesondere die 3D-Objekterkennung für Open-Vocabulary. Bei herkömmlichen 3D-Objekterkennungsaufgaben müssen Systeme die Position von Objekten in realen Szenen, 3D-Begrenzungsrahmen und semantische Kategoriebezeichnungen vorhersagen, was normalerweise auf Punktwolken oder RGB-Bildern beruht. Obwohl die 2D-Objekterkennungstechnologie aufgrund ihrer Allgegenwärtigkeit und Geschwindigkeit gute Leistungen erbringt, zeigen einschlägige Untersuchungen, dass die Entwicklung der universellen 3D-Erkennung im Vergleich zurückbleibt. Derzeit basieren die meisten 3D-Objekterkennungsmethoden immer noch auf vollständig überwachtem Lernen und sind durch vollständig kommentierte Daten in bestimmten Eingabemodi eingeschränkt. Sie können nur Kategorien erkennen, die während des Trainings entstehen, sei es in Innen- oder Außenszenen.
In diesem Artikel wird darauf hingewiesen, dass die Herausforderungen für die universelle 3D-Objekterkennung hauptsächlich darin bestehen, dass bestehende 3D-Detektoren nur mit geschlossener Vokabularaggregation arbeiten und daher nur Kategorien erkennen können, die bereits gesehen wurden. Die 3D-Objekterkennung von Open-Vocabulary wird dringend benötigt, um neue Klassenobjektinstanzen zu identifizieren und zu lokalisieren, die während des Trainings nicht erfasst wurden. Bestehende 3D-Erkennungsdatensätze sind im Vergleich zu 2D-Datensätzen in Größe und Kategorie begrenzt, was die Generalisierungsfähigkeit bei der Lokalisierung neuer Objekte einschränkt. Darüber hinaus verschärft der Mangel an vorab trainierten Bild-Text-Modellen im 3D-Bereich die Herausforderungen der Open-Vocabulary-3D-Erkennung noch weiter. Gleichzeitig fehlt eine einheitliche Architektur für die multimodale 3D-Erkennung, und bestehende 3D-Detektoren sind meist für bestimmte Eingabemodalitäten (Punktwolken, RGB-Bilder oder beides) konzipiert, was die effektive Nutzung der Daten behindert verschiedene Modalitäten und Szenen (drinnen oder draußen), wodurch die Generalisierungsfähigkeit auf neue Ziele eingeschränkt wird.
Um die oben genannten Probleme zu lösen, schlägt das Papier einen einheitlichen multimodalen 3D-Detektor namens OV-Uni3DETR vor. Der Detektor ist in der Lage, während des Trainings multimodale und aus mehreren Quellen stammende Daten zu nutzen, darunter Punktwolken, Punktwolken mit präzisen 3D-Box-Anmerkungen und an Punktwolken ausgerichteten 3D-Erkennungsbildern sowie 2D-Erkennungsbilder, die nur 2D-Box-Anmerkungen enthalten. Durch diese multimodale Lernmethode ist OV-Uni3DETR in der Lage, Daten jeder Modalität während der Inferenz zu verarbeiten, einen Modalwechsel während des Testens zu erreichen und gute Leistungen bei der Erkennung grundlegender und neuer Kategorien zu erbringen. Die einheitliche Struktur ermöglicht es OV-Uni3DETR darüber hinaus, Innen- und Außenszenen mit Open-Vocabulary-Funktionen zu erkennen, wodurch die Universalität des 3D-Detektors über Kategorien, Szenen und Modalitäten hinweg deutlich verbessert wird.
Zusätzlich zielt das Papier auf das Problem ab, wie der Detektor verallgemeinert werden kann, um neue Kategorien zu identifizieren, und wie man aus einer großen Anzahl von 2D-Erkennungsbildern ohne 3D-Boxanmerkungen lernen kann, und schlägt eine Methode vor, die als periodische Modenausbreitung bezeichnet wird Bei diesem Ansatz wird Wissen zwischen 2D- und 3D-Modalitäten weitergegeben, um beiden Herausforderungen zu begegnen. Auf diese Weise kann das umfangreiche semantische Wissen des 2D-Detektors auf die 3D-Domäne übertragen werden, um die Entdeckung neuer Boxen zu unterstützen, und das geometrische Wissen des 3D-Detektors kann verwendet werden, um Objekte im 2D-Erkennungsbild zu lokalisieren und die Klassifizierungsbezeichnungen abzugleichen durch Matching.
Zu den Hauptbeiträgen des Artikels gehört der Vorschlag eines einheitlichen Open-Vocabulary-3D-Detektors OV-Uni3DETR, der jede Kategorie von Zielen in verschiedenen Modalitäten und verschiedenen Szenen erkennen kann; der Vorschlag eines einheitlichen multimodalen Detektors für die Architektur von Innen- und Außenszenen; Es wird das Konzept einer Wissensverbreitungsschleife zwischen 2D- und 3D-Modalitäten vorgeschlagen. Mit diesen Innovationen erreicht OV-Uni3DETR eine hochmoderne Leistung bei mehreren 3D-Erkennungsaufgaben und übertrifft frühere Methoden im Open-Vocabulary-Umfeld deutlich. Diese Ergebnisse zeigen, dass OV-Uni3DETR einen wichtigen Schritt für die zukünftige Entwicklung von 3D-Basismodellen gemacht hat.
Detaillierte Erläuterung der OV-Uni3DETR-Methode
Multimodales Lernen
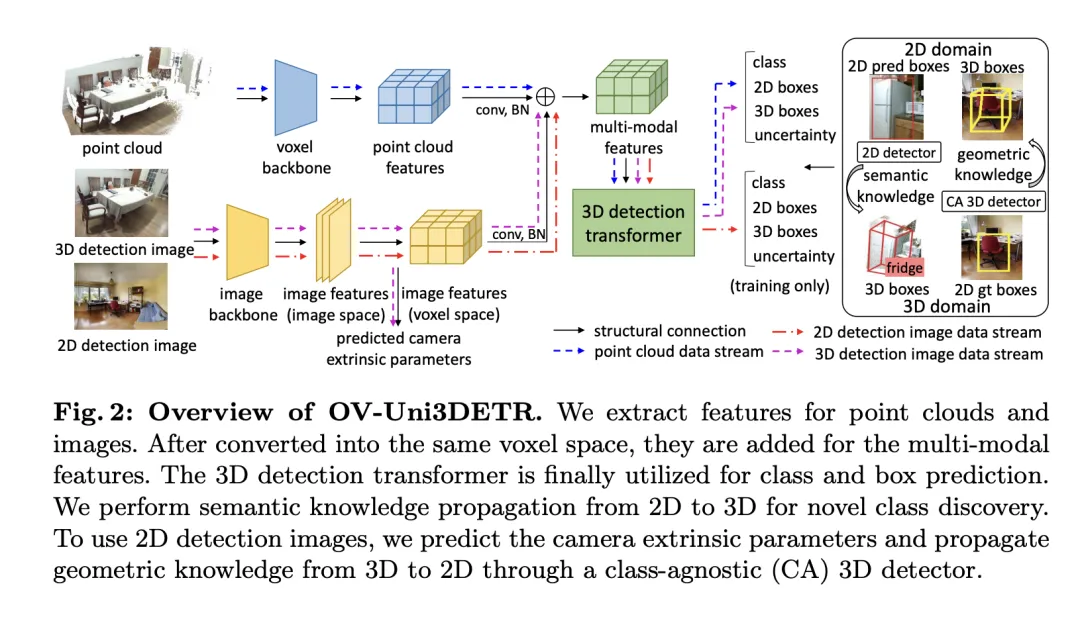
In diesem Artikel wird ein multimodales Lernframework speziell für 3D-Zielerkennungsaufgaben durch die Integration von Cloud- und Bilddaten vorgestellt. Verbessern Sie die Erkennungsleistung. Dieses Framework kann bestimmte Sensormodalitäten verarbeiten, die während der Inferenz möglicherweise fehlen, d. h. es verfügt auch über die Möglichkeit, den Modus während des Tests zu wechseln. Merkmale aus zwei verschiedenen Modalitäten, einschließlich 3D-Punktwolkenmerkmalen und 2D-Bildmerkmalen, werden über eine spezifische Netzwerkstruktur extrahiert und integriert. Nach der Elementarverarbeitung und Kameraparameterzuordnung werden diese Merkmale für nachfolgende Zielerkennungsaufgaben zusammengeführt.
Zu den wichtigsten technischen Punkten gehört die Verwendung von 3D-Faltung und Stapelnormalisierung zur Normalisierung und Integration von Funktionen verschiedener Modi, um zu verhindern, dass Inkonsistenzen auf Funktionsebene dazu führen, dass ein bestimmter Modus ignoriert wird. Darüber hinaus stellt die Trainingsstrategie des zufälligen Wechselns der Modi sicher, dass das Modell Daten aus nur einem einzigen Modus flexibel verarbeiten kann, wodurch die Robustheit und Anpassungsfähigkeit des Modells verbessert wird.
Letztendlich nutzt die Architektur eine zusammengesetzte Verlustfunktion, die Verluste aus Klassenvorhersage, 2D- und 3D-Bounding-Box-Regression und eine Unsicherheitsvorhersage für einen gewichteten Regressionsverlust kombiniert, um den gesamten Erkennungsprozess zu optimieren. Diese multimodale Lernmethode verbessert nicht nur die Erkennungsleistung bestehender Kategorien, sondern verbessert auch die Generalisierungsfähigkeit auf neue Kategorien durch die Fusion verschiedener Datentypen. Die multimodale Architektur sagt letztendlich Klassenbezeichnungen, 4D-2D-Boxen und 7D-3D-Boxen für die 2D- und 3D-Objekterkennung voraus. Für die 3D-Box-Regression werden L1-Verlust und entkoppelter IoU-Verlust verwendet; für die 2D-Box-Regression werden L1-Verlust und GIoU-Verlust verwendet. In der Open-Vocabulary-Einstellung gibt es neue Kategoriebeispiele, was den Schwierigkeitsgrad von Trainingsbeispielen erhöht. Daher wird die Unsicherheitsvorhersage 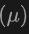 eingeführt und zur Gewichtung des L1-Regressionsverlusts verwendet. Der Verlust des Objekterkennungslernens ist:
eingeführt und zur Gewichtung des L1-Regressionsverlusts verwendet. Der Verlust des Objekterkennungslernens ist:
Bei einigen 3D-Szenen gibt es möglicherweise Bilder mit mehreren Ansichten anstelle eines einzelnen monokularen Bildes. Für jeden von ihnen werden Bildmerkmale extrahiert und mithilfe der jeweiligen Projektionsmatrix in den Voxelraum projiziert. Mehrere Bildmerkmale im Voxelraum werden summiert, um multimodale Merkmale zu erhalten. Dieser Ansatz verbessert die Generalisierungsfähigkeit des Modells auf neue Kategorien und erhöht die Anpassungsfähigkeit unter verschiedenen Eingabebedingungen durch die Kombination von Informationen aus verschiedenen Modalitäten.
Wissensweitergabe: 2D – 3D
Basierend auf dem eingeführten multimodalen Lernen wird eine Methode namens „Wissensweitergabe:  “ zur 3D-Erkennung von offenem Vokabular implementiert. Das Kernproblem des Open-Vocabulary-Lernens besteht darin, neue Kategorien zu identifizieren, die während des Trainingsprozesses nicht manuell annotiert wurden. Aufgrund der Schwierigkeit, Punktwolkendaten zu erhalten, wurden im Punktwolkenbereich noch keine vorab trainierten visuellen Sprachmodelle entwickelt. Die modalen Unterschiede zwischen Punktwolkendaten und RGB-Bildern schränken die Leistung dieser Modelle bei der 3D-Erkennung ein.
“ zur 3D-Erkennung von offenem Vokabular implementiert. Das Kernproblem des Open-Vocabulary-Lernens besteht darin, neue Kategorien zu identifizieren, die während des Trainingsprozesses nicht manuell annotiert wurden. Aufgrund der Schwierigkeit, Punktwolkendaten zu erhalten, wurden im Punktwolkenbereich noch keine vorab trainierten visuellen Sprachmodelle entwickelt. Die modalen Unterschiede zwischen Punktwolkendaten und RGB-Bildern schränken die Leistung dieser Modelle bei der 3D-Erkennung ein.

Um dieses Problem zu lösen, wird vorgeschlagen, das semantische Wissen des vorab trainierten 2D-Open-Vocabulary-Detektors zu nutzen und entsprechende 3D-Begrenzungsrahmen für neue Kategorien zu generieren. Diese generierten 3D-Boxen ergänzen die begrenzten 3D-Ground-Truth-Labels, die während des Trainings verfügbar sind.
Generieren Sie insbesondere zunächst einen 2D-Begrenzungsrahmen oder eine Instanzmaske mit dem 2DOpen-Vocabulary-Detektor. Da die im 2D-Bereich verfügbaren Daten und Anmerkungen umfangreicher sind, können diese generierten 2D-Boxen eine höhere Positionierungsgenauigkeit erreichen und ein breiteres Spektrum an Kategorien abdecken. Anschließend werden diese 2D-Boxen über 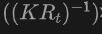 in den 3D-Raum projiziert, um die entsprechenden 3D-Boxen zu erhalten. Die spezifische Operation besteht darin,
in den 3D-Raum projiziert, um die entsprechenden 3D-Boxen zu erhalten. Die spezifische Operation besteht darin, 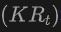
zu verwenden, um 3D-Punkte in den 2D-Raum zu projizieren, die Punkte innerhalb der 2D-Box zu finden und diese Punkte dann innerhalb der 2D-Box zu gruppieren, um Ausreißer zu eliminieren und die entsprechende 3D-Box zu erhalten. Aufgrund des Vorhandenseins vorab trainierter 2D-Detektoren können im generierten 3D-Boxset neue unbeschriftete Objekte entdeckt werden. Auf diese Weise wird die 3DOpen-Vocabulary-Erkennung durch umfangreiches semantisches Wissen, das von der 2D-Domäne an die generierten 3D-Boxen weitergegeben wird, erheblich erleichtert. Für Mehrfachansichtsbilder werden 3D-Boxen separat generiert und zur endgültigen Verwendung zusammengefügt.
Wenn während der Inferenz sowohl Punktwolken als auch Bilder verfügbar sind, können 3D-Boxen auf ähnliche Weise extrahiert werden. Diese generierten 3D-Boxen können auch als eine Form der 3DOpen-Vocabulary-Erkennungsergebnisse betrachtet werden. Diese 3D-Boxen werden zu den Vorhersagen des multimodalen 3D-Transformators hinzugefügt, um mögliche fehlende Objekte zu ergänzen und überlappende Begrenzungsboxen mittels 3D-Nicht-Maximum-Unterdrückung (NMS) zu filtern. Die von den vorab trainierten 2D-Detektoren zugewiesenen Konfidenzwerte werden systematisch durch eine vorgegebene Konstante dividiert und dann in die Konfidenzwerte der entsprechenden 3D-Boxen uminterpretiert.
Experiment
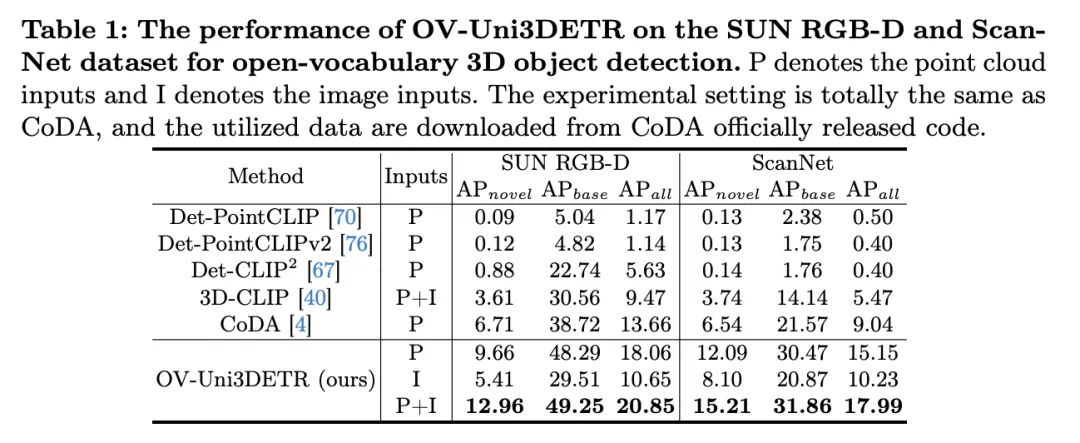
Die Tabelle zeigt die Leistung von OV-Uni3DETR für die Open-Vocabulary3D-Objekterkennung in SUN RGB-D- und ScanNet-Datensätzen. Die experimentellen Einstellungen sind genau die gleichen wie bei CoDA, und die verwendeten Daten stammen aus dem offiziell veröffentlichten Code von CoDA. Zu den Leistungsmetriken gehören die durchschnittliche Genauigkeit der neuen Klasse 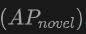 , die durchschnittliche Genauigkeit der Basisklasse
, die durchschnittliche Genauigkeit der Basisklasse 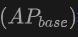 und die durchschnittliche Genauigkeit aller Klassen
und die durchschnittliche Genauigkeit aller Klassen 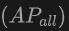 . Zu den Eingabetypen gehören Punktwolken (P), Bilder (I) und deren Kombinationen (P+I).
. Zu den Eingabetypen gehören Punktwolken (P), Bilder (I) und deren Kombinationen (P+I).
Bei der Analyse dieser Ergebnisse können wir folgende Punkte beobachten:
-
Vorteile der multimodalen Eingabe: Bei Verwendung einer Kombination aus Punktwolken und Bildern als Eingabe schneidet OV-Uni3DETR bei allen Bewertungsmetriken der beiden Datensätze gut ab Es erzielte in allen Aspekten die höchste Punktzahl, insbesondere die Verbesserung der durchschnittlichen Genauigkeit neuer Kategorien
 ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann.
ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann. - Vergleich mit anderen Methoden: Im Vergleich zu anderen punktwolkenbasierten Methoden (wie Det-PointCLIP, Det-PointCLIPv2, Det-CLIP, 3D-CLIP und CoDA) weist OV-Uni3DETR bei allen Auswertungen eine überlegene Leistung auf Kennzahlen Hervorragende Leistung. Dies zeigt die Wirksamkeit von OV-Uni3DETR bei der Bewältigung von Open-Vocabulary3D-Objekterkennungsaufgaben, insbesondere bei der Nutzung multimodaler Lern- und Wissensverbreitungsstrategien.
- Vergleich von Bild- und Punktwolkeneingabe: Obwohl die Leistung von OV-Uni3DETR, bei der nur Bild (I) als Eingabe verwendet wird, geringer ist als die bei Verwendung von Punktwolke (P) als Eingabe, zeigt es dennoch gute Erkennungsfähigkeiten. Dies beweist die Flexibilität und Anpassungsfähigkeit der OV-Uni3DETR-Architektur an einzelne Modaldaten und unterstreicht auch die Bedeutung der Fusion mehrerer Modaldaten zur Verbesserung der Erkennungsleistung.
-
Leistung bei neuen Kategorien: Besonders hervorzuheben ist die Leistung von OV-Uni3DETR bei der durchschnittlichen Genauigkeit neuer Kategorien, was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe.
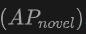 ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann.
ist am bedeutendsten. Dies zeigt, dass die Kombination von Punktwolken und Bildern die Fähigkeit des Modells, unsichtbare Klassen zu erkennen, sowie die Gesamterkennungsleistung erheblich verbessern kann. 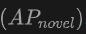 , was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte
, was besonders wichtig für die Erkennung offener Vokabeln ist. Beim SUN RGB-D-Datensatz erreichte 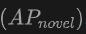 bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe.
bei Verwendung von Punktwolken- und Bildeingabe 12,96 % und beim ScanNet-Datensatz 15,21 %, was deutlich höher ist als bei anderen Methoden, was zeigt, dass es den Erkennungstrainingsprozess nicht verbessert Funktionen in der Kategorie, die ich gesehen habe. Im Allgemeinen zeigt OV-Uni3DETR durch seine einheitliche multimodale Lernarchitektur eine hervorragende Leistung bei Open-Vocabulary3D-Objekterkennungsaufgaben, insbesondere bei der Kombination von Punktwolken- und Bilddaten, und kann die Erkennungsgenauigkeit neuer Objekte effektiv verbessern Kategorien beweisen die Wirksamkeit und Bedeutung multimodaler Input- und Wissensverbreitungsstrategien.
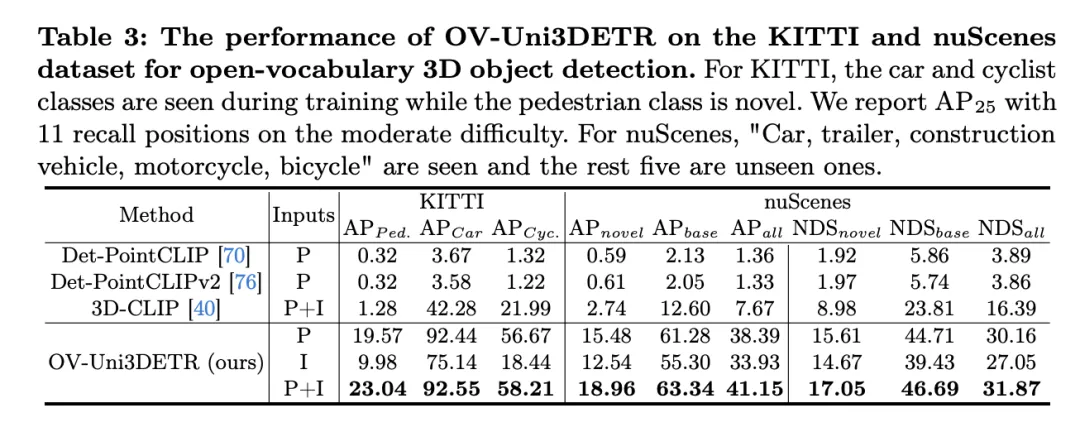
Diese Tabelle zeigt die Leistung von OV-Uni3DETR für die Open-Vocabulary3D-Objekterkennung in KITTI- und nuScenes-Datensätzen und deckt Kategorien ab, die während des Trainingsprozesses gesehen (Basis) und unsichtbar (Roman) wurden. Für den KITTI-Datensatz wurden die Kategorien „Auto“ und „Radfahrer“ während des Trainings gesehen, während die Kategorie „Fußgänger“ neu ist. Die Leistung wird anhand der 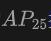
-Metrik bei mittlerem Schwierigkeitsgrad und unter Verwendung von 11 Rückrufpositionen gemessen. Für den nuScenes-Datensatz ist „Auto, Anhänger, Baufahrzeug, Motorrad, Fahrrad“ eine sichtbare Kategorie und die restlichen fünf sind unsichtbare Kategorien. Zusätzlich zu den AP-Indikatoren wird auch NDS (NuScenes Detection Score) zur umfassenden Bewertung der Erkennungsleistung berichtet.
Die Analyse dieser Ergebnisse führt zu folgenden Schlussfolgerungen:
- Wesentliche Vorteile der multimodalen Eingabe: Verglichen mit dem Fall, dass nur Punktwolke (P) oder Bild (I) als Eingabe verwendet werden, wenn sowohl Punktwolke als auch Bild (P+I) als Eingabe verwendet werden, OV – Uni3DETR erhielt bei allen Bewertungskriterien die höchste Punktzahl. Dieses Ergebnis unterstreicht die erheblichen Vorteile des multimodalen Lernens bei der Verbesserung der Erkennungsfähigkeiten für unsichtbare Kategorien und der gesamten Erkennungsleistung.
- Effektivität der Erkennung offener Vokabeln: OV-Uni3DETR zeigt eine hervorragende Leistung bei der Handhabung unsichtbarer Kategorien, insbesondere in der Kategorie „Fußgänger“ des KITTI-Datensatzes und der Kategorie „Roman“ des nuScenes-Datensatzes. Dies zeigt, dass das Modell über eine starke Verallgemeinerungsfähigkeit für neuartige Kategorien verfügt und eine effektive Lösung zur Erkennung von offenem Vokabular darstellt.
- Vergleich mit anderen Methoden: Im Vergleich zu anderen punktwolkenbasierten Methoden (wie Det-PointCLIP, Det-PointCLIPv2 und 3D-CLIP) zeigt OV-Uni3DETR erhebliche Leistungsverbesserungen, sowohl bei der Erkennung sichtbarer als auch unsichtbarer Kategorien. Dies zeigt seinen Fortschritt bei der Handhabung von Open-Vocabulary3D-Objekterkennungsaufgaben.
- Vergleich von Bildeingabe und Punktwolkeneingabe: Obwohl die Leistung der Bildeingabe etwas geringer ist als die der Punktwolkeneingabe, kann die Bildeingabe immer noch eine relativ hohe Erkennungsgenauigkeit bieten, was die Anpassungsfähigkeit des OV-Uni3DETR zeigt Architektur und Flexibilität.
- Umfassender Bewertungsindex: Aus den Ergebnissen des NDS-Bewertungsindex geht hervor, dass OV-Uni3DETR nicht nur bei der Erkennungsgenauigkeit gut abschneidet, sondern auch bei der Gesamterkennungsqualität hohe Werte erzielt, insbesondere in Kombination mit Punktwolken und Bildern Daten.
OV-Uni3DETR zeigt eine hervorragende Leistung bei der Open-Vocabulary3D-Objekterkennung, insbesondere bei der Verarbeitung unsichtbarer Kategorien und multimodaler Daten. Diese Ergebnisse bestätigen die Wirksamkeit der multimodalen Eingabe- und Wissensverbreitungsstrategie sowie das Potenzial von OV-Uni3DETR zur Verbesserung der Generalisierungsfähigkeit von 3D-Objekterkennungsaufgaben.
Diskussion

Dieses Papier bringt erhebliche Fortschritte auf dem Gebiet der 3D-Objekterkennung mit offenem Vokabular, indem es OV-Uni3DETR vorschlägt, einen einheitlichen multimodalen 3D-Detektor. Diese Methode nutzt multimodale Daten (Punktwolken und Bilder), um die Erkennungsleistung zu verbessern, und erweitert effektiv die Erkennungsfähigkeiten des Modells für unsichtbare Kategorien durch eine 2D-zu-3D-Wissensverbreitungsstrategie. Experimentelle Ergebnisse an mehreren öffentlichen Datensätzen zeigen die hervorragende Leistung von OV-Uni3DETR bei neuen Kategorien und Basiskategorien, insbesondere bei der Kombination von Punktwolken- und Bildeingaben, wodurch die Erkennungsfähigkeiten neuer Kategorien erheblich verbessert werden können, während gleichzeitig die Gesamterkennungsleistung ebenfalls erreicht wurde eine neue Höhe.
In Bezug auf die Vorteile demonstriert OV-Uni3DETR zunächst das Potenzial des multimodalen Lernens zur Verbesserung der 3D-Zielerkennungsleistung. Durch die Integration von Punktwolken- und Bilddaten ist das Modell in der Lage, ergänzende Merkmale jeder Modalität zu erlernen und so eine genauere Erkennung komplexer Szenen und verschiedener Zielkategorien zu ermöglichen. Zweitens ist OV-Uni3DETR durch die Einführung eines 2D-zu-3D-Wissensverbreitungsmechanismus in der Lage, umfangreiche 2D-Bilddaten und vorab trainierte 2D-Erkennungsmodelle zu nutzen, um neue Kategorien zu identifizieren und zu lokalisieren, die während des Trainingsprozesses nicht gesehen wurden, was die Generalisierbarkeit des Modells erheblich verbessert. isierungsfähigkeit. Darüber hinaus zeigt diese Methode leistungsstarke Fähigkeiten bei der Handhabung der Open-Vocabulary-Erkennung und eröffnet neue Forschungsrichtungen und potenzielle Anwendungen im Bereich der 3D-Erkennung.
Obwohl OV-Uni3DETR seine Vorteile in vielen Aspekten unter Beweis gestellt hat, gibt es auch einige potenzielle Einschränkungen. Erstens kann multimodales Lernen zwar die Leistung verbessern, es erhöht jedoch auch die Komplexität der Datenerfassung und -verarbeitung. Insbesondere in praktischen Anwendungen kann die Synchronisierung und Registrierung verschiedener modaler Daten eine Herausforderung darstellen. Zweitens kann die Wissensverbreitungsstrategie zwar effektiv 2D-Daten zur Unterstützung der 3D-Erkennung nutzen, diese Methode basiert jedoch möglicherweise auf hochwertigen 2D-Erkennungsmodellen und einer genauen 3D-2D-Ausrichtungstechnologie, was in einigen komplexen Umgebungen möglicherweise schwierig zu gewährleisten ist. Darüber hinaus kann bei einigen äußerst seltenen Kategorien sogar die Erkennung offener Vokabeln mit Herausforderungen bei der Erkennungsgenauigkeit konfrontiert sein, deren Lösung weitere Forschung erfordert.
OV-Uni3DETR hat durch seine innovative multimodale Lern- und Wissensverbreitungsstrategie erhebliche Fortschritte bei der Open-Vocabulary3D-Objekterkennung gemacht. Obwohl es einige potenzielle Einschränkungen gibt, zeigen seine Vorteile das große Potenzial dieser Methode bei der Förderung der Entwicklung und Anwendungserweiterung der 3D-Inspektionstechnologie. Zukünftige Forschungen können weiter untersuchen, wie diese Einschränkungen überwunden werden können und wie diese Strategien auf ein breiteres Spektrum von 3D-Wahrnehmungsaufgaben angewendet werden können.
Fazit
In diesem Artikel haben wir hauptsächlich OV-Uni3DETR vorgeschlagen, einen einheitlichen multimodalen 3D-Detektor mit offenem Vokabular. Mit Hilfe des multimodalen Lernens und der zyklischen modalen Wissensverbreitung kann unser OV-Uni3DETR neue Klassen gut identifizieren und lokalisieren und so eine modale Vereinheitlichung und Szenenvereinheitlichung erreichen. Experimente zeigen seine starken Fähigkeiten sowohl in Umgebungen mit offenem als auch geschlossenem Vokabular, sowohl in Innen- als auch in Außenszenen und bei jeder modalen Dateneingabe. Wir sind davon überzeugt, dass unsere Studie, die auf eine einheitliche 3D-Erkennung mit offenem Vokabular in multimodalen Umgebungen abzielt, die nachfolgende Forschung in die vielversprechende, aber herausfordernde Richtung der allgemeinen 3D-Computervision vorantreiben wird.
Das obige ist der detaillierte Inhalt vonMehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Erfahren Sie mehr über 3D Fluent-Emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Sie müssen bedenken, insbesondere wenn Sie Teams-Benutzer sind, dass Microsoft seiner arbeitsorientierten Videokonferenz-App eine neue Reihe von 3DFluent-Emojis hinzugefügt hat. Nachdem Microsoft letztes Jahr 3D-Emojis für Teams und Windows angekündigt hatte, wurden im Rahmen des Prozesses tatsächlich mehr als 1.800 bestehende Emojis für die Plattform aktualisiert. Diese große Idee und die Einführung des 3DFluent-Emoji-Updates für Teams wurden erstmals über einen offiziellen Blogbeitrag beworben. Das neueste Teams-Update bringt FluentEmojis in die App. Laut Microsoft werden uns die aktualisierten 1.800 Emojis täglich zur Verfügung stehen
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
1. Einleitung Derzeit sind die führenden Objektdetektoren zweistufige oder einstufige Netzwerke, die auf dem umfunktionierten Backbone-Klassifizierungsnetzwerk von Deep CNN basieren. YOLOv3 ist ein solcher bekannter hochmoderner einstufiger Detektor, der ein Eingabebild empfängt und es in eine gleich große Gittermatrix aufteilt. Für die Erkennung spezifischer Ziele sind Gitterzellen mit Zielzentren zuständig. Was ich heute vorstelle, ist eine neue mathematische Methode, die jedem Ziel mehrere Gitter zuordnet, um eine genaue Vorhersage des Begrenzungsrahmens zu erreichen. Die Forscher schlugen außerdem eine effektive Offline-Datenverbesserung durch Kopieren und Einfügen für die Zielerkennung vor. Die neu vorgeschlagene Methode übertrifft einige aktuelle Objektdetektoren auf dem neuesten Stand der Technik deutlich und verspricht eine bessere Leistung. 2. Das Hintergrundzielerkennungsnetzwerk ist für die Verwendung konzipiert
 Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Im Bereich der Zielerkennung macht YOLOv9 weiterhin Fortschritte im Implementierungsprozess. Durch die Einführung neuer Architekturen und Methoden wird die Parameternutzung der herkömmlichen Faltung effektiv verbessert, wodurch die Leistung den Produkten der vorherigen Generation weit überlegen ist. Mehr als ein Jahr nach der offiziellen Veröffentlichung von YOLOv8 im Januar 2023 ist YOLOv9 endlich da! Seit Joseph Redmon, Ali Farhadi und andere im Jahr 2015 das YOLO-Modell der ersten Generation vorgeschlagen haben, haben Forscher auf dem Gebiet der Zielerkennung es viele Male aktualisiert und iteriert. YOLO ist ein Vorhersagesystem, das auf globalen Bildinformationen basiert und dessen Modellleistung kontinuierlich verbessert wird. Durch die kontinuierliche Verbesserung von Algorithmen und Technologien haben Forscher bemerkenswerte Ergebnisse erzielt, die YOLO bei Zielerkennungsaufgaben immer leistungsfähiger machen.
 Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download-, Installations- und Nutzungshandbuch
Apr 26, 2023 am 11:28 AM
Als sich das Gerücht verbreitete, dass das neue Windows 11 in der Entwicklung sei, war jeder Microsoft-Nutzer neugierig, wie das neue Betriebssystem aussehen und was es bringen würde. Nach Spekulationen ist Windows 11 da. Das Betriebssystem kommt mit neuem Design und funktionalen Änderungen. Zusätzlich zu einigen Ergänzungen werden Funktionen eingestellt und entfernt. Eine der Funktionen, die es in Windows 11 nicht gibt, ist Paint3D. Während es immer noch klassisches Paint bietet, das sich gut für Zeichner, Kritzler und Kritzler eignet, verzichtet es auf Paint3D, das zusätzliche Funktionen bietet, die sich ideal für 3D-Ersteller eignen. Wenn Sie nach zusätzlichen Funktionen suchen, empfehlen wir Autodesk Maya als beste 3D-Designsoftware. wie
 Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
Holen Sie sich mit einer einzigen Karte in 30 Sekunden eine virtuelle 3D-Frau! Text to 3D generiert einen hochpräzisen digitalen Menschen mit klaren Porendetails und lässt sich nahtlos mit Maya, Unity und anderen Produktionstools verbinden
May 23, 2023 pm 02:34 PM
ChatGPT hat der KI-Branche eine Portion Hühnerblut injiziert, und alles, was einst undenkbar war, ist heute zur gängigen Praxis geworden. Text-to-3D, das immer weiter voranschreitet, gilt nach Diffusion (Bilder) und GPT (Text) als nächster Hotspot im AIGC-Bereich und hat beispiellose Aufmerksamkeit erhalten. Nein, ein Produkt namens ChatAvatar befindet sich in einer unauffälligen öffentlichen Betaphase, hat schnell über 700.000 Aufrufe und Aufmerksamkeit erregt und wurde auf Spacesoftheweek vorgestellt. △ChatAvatar wird auch die Imageto3D-Technologie unterstützen, die 3D-stilisierte Charaktere aus KI-generierten Einzel-/Mehrperspektive-Originalgemälden generiert. Das von der aktuellen Beta-Version generierte 3D-Modell hat große Beachtung gefunden.
