
 Technologie-Peripheriegeräte
KI
Langer Text kann RAG nicht töten: SQL+-Vektor steuert große Modelle und das neue Paradigma von Big Data, die MyScale AI-Datenbank ist offiziell Open Source
Technologie-Peripheriegeräte
KI
Langer Text kann RAG nicht töten: SQL+-Vektor steuert große Modelle und das neue Paradigma von Big Data, die MyScale AI-Datenbank ist offiziell Open Source
Langer Text kann RAG nicht töten: SQL+-Vektor steuert große Modelle und das neue Paradigma von Big Data, die MyScale AI-Datenbank ist offiziell Open Source

Die Kombination aus großen Modellen und KI-Datenbanken ist zu einer Erfolgsformel geworden, um die Kosten zu senken, die Effizienz großer Modelle zu steigern und Big Data wirklich intelligent zu machen.

Spezialisierte Vektordatenbanken, vertreten durch Pinecone/Weaviate/Milvus, sind von Anfang an für die Vektorabfrage konzipiert und gebaut, aber die allgemeine Datenverwaltungsfunktion ist schwach. Die von Elasticsearch/OpenSearch repräsentierten Schlüsselwort- und Vektor-Retrieval-Systeme werden aufgrund ihrer vollständigen Schlüsselwort-Retrieval-Funktionen häufig in der Produktion eingesetzt. Sie beanspruchen jedoch viele Systemressourcen und die gemeinsame Abfragegenauigkeit und Leistung von Schlüsselwörtern und Vektoren sind nicht zufriedenstellend . Die Leute bekommen, was sie wollen. SQL-Vektordatenbanken, dargestellt durch pgvector (Vektorsuch-Plug-in für PostgreSQL) und MyScale AI-Datenbank, basieren auf SQL und verfügen über leistungsstarke Datenverwaltungsfunktionen. Aufgrund der Nachteile der PostgreSQL-Zeilenspeicherung und der Einschränkungen von Vektoralgorithmen weist pgvector jedoch eine geringe Genauigkeit bei komplexen Vektorabfragen auf.
Dank der langfristigen Politur der SQL-Datenbank in Szenarios mit massiven strukturierten Daten unterstützt MyScaleDB
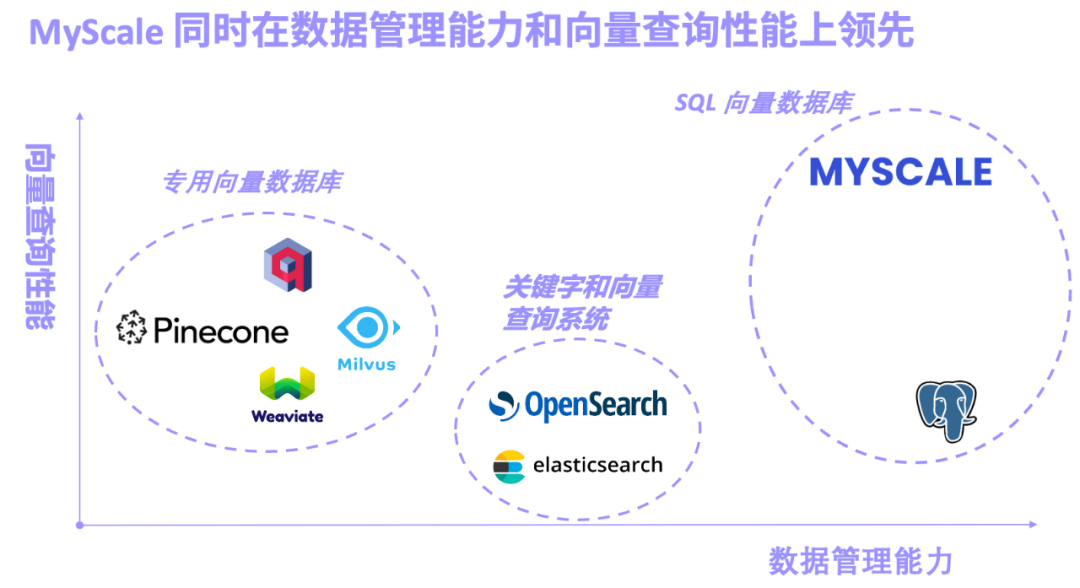
In tatsächlichen komplexen KI-Anwendungsszenarien kann die Kombination von SQL und Vektoren die Flexibilität der Datenmodellierung erheblich erhöhen und den Entwicklungsprozess vereinfachen. Im Science Navigator-Projekt, das zwischen dem MyScale-Team und dem Beijing Institute of Scientific Intelligence kooperiert, wird MyScaleDB beispielsweise verwendet, um umfangreiche wissenschaftliche Literaturdaten abzurufen und intelligente Fragen zu beantworten. Es gibt mehr als 10 Haupt-SQL-Tabellenstrukturen, von denen viele etabliert sind Vektoren und invertierter Tabellenindex, und verwenden Sie den Primärschlüssel und den Fremdschlüssel, um die Zuordnung herzustellen. Bei tatsächlichen Abfragen umfasst das System auch gemeinsame Abfragen von strukturierten Daten, Vektor- und Schlüsselwortdaten sowie zugehörige Abfragen mehrerer Tabellen. Diese Modellierung und Korrelationen sind in einer dedizierten Vektordatenbank schwer zu erreichen, was auch zu einer langsamen Iteration des endgültigen Systems, ineffizienten Abfragen und schwieriger Wartung führt.
Schematische Darstellung der Haupttabellenstruktur von NScience Navigator (Spalten mit fett gedruckten Körpern erstellen Vektorindizes oder invertierte Indizes) Genauigkeit und Wirkung des Abrufs sind die größten Engpässe, die seine Umsetzung einschränken. Dies erfordert, dass die KI-Datenbank gemeinsame Abfragen von Struktur-, Vektor- und Schlüsselwortdaten effizient unterstützt, um die Abrufgenauigkeit umfassend zu verbessern.
und kann
. Das MyScale-Team hat bereits die Implementierung dieser Lösung in der wissenschaftlichen Forschung, im Finanzwesen, in der Industrie, in der Medizin und in anderen Bereichen untersucht.
Das obige ist der detaillierte Inhalt vonLanger Text kann RAG nicht töten: SQL+-Vektor steuert große Modelle und das neue Paradigma von Big Data, die MyScale AI-Datenbank ist offiziell Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Frage Beschreibung: Wie erhalten Sie die Daten der Versandregion der Überseeversion? Gibt es bereitgestellte Ressourcen? Werden Sie im grenzüberschreitenden E-Commerce oder im globalisierten Geschäft genau ...
