
 Technologie-Peripheriegeräte
KI
Empfehlungssysteme basierend auf kausalen Schlussfolgerungen: Überprüfung und Aussichten
Technologie-Peripheriegeräte
KI
Empfehlungssysteme basierend auf kausalen Schlussfolgerungen: Überprüfung und Aussichten
Empfehlungssysteme basierend auf kausalen Schlussfolgerungen: Überprüfung und Aussichten

Das Thema dieses Austauschs sind Empfehlungssysteme, die auf kausalen Schlussfolgerungen basieren. Wir überprüfen vergangene verwandte Arbeiten und schlagen Zukunftsaussichten in diese Richtung vor.
Warum müssen wir kausale Inferenztechnologie in Empfehlungssystemen verwenden? Bestehende Forschungsarbeiten nutzen kausale Schlussfolgerungen, um drei Arten von Problemen zu lösen (siehe das TOIS 2023-Papier Causal Inference in Recommender Systems: A Survey and Future Directions von Gao et al.):
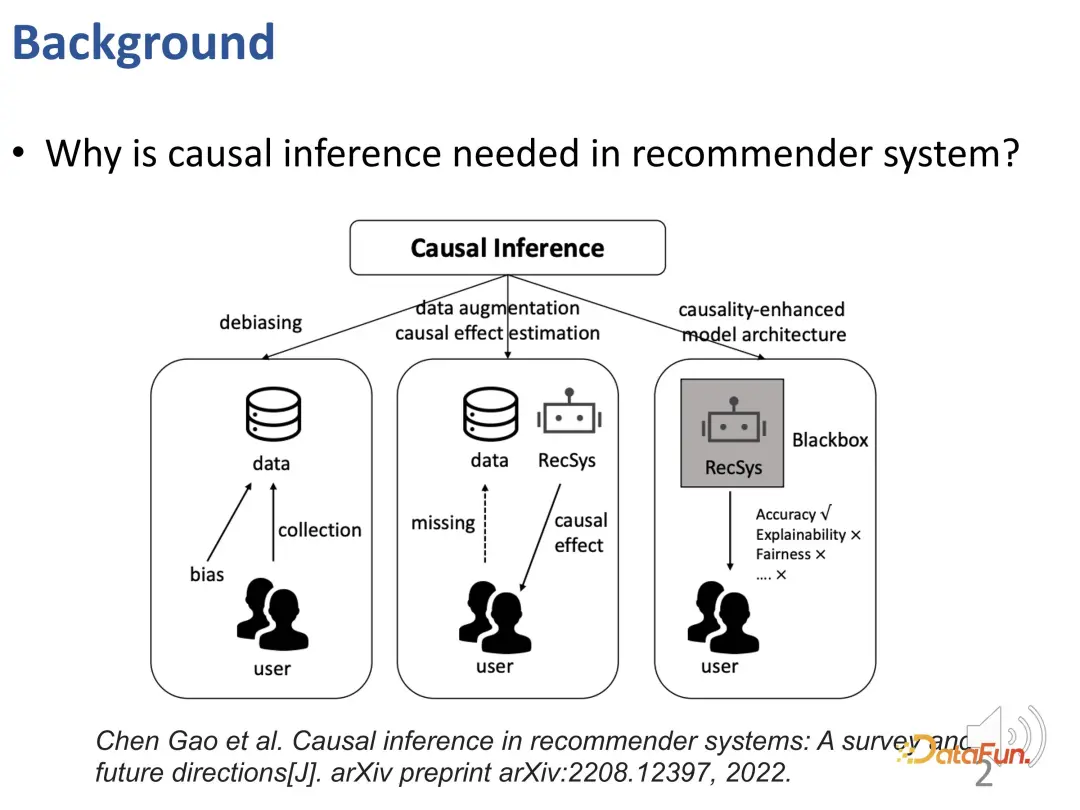
Erstens im Empfehlungssystem, Da es verschiedene Vorurteile (BIAS) gibt, ist die kausale Schlussfolgerung ein wirksames Instrument, um diese Vorurteile zu beseitigen.
Um die Probleme der Datenknappheit und der Unfähigkeit, kausale Auswirkungen genau abzuschätzen, anzugehen, stehen Empfehlungssysteme möglicherweise vor Herausforderungen. Um dieses Problem zu lösen, können Datenverbesserungs- oder Kausaleffekt-Schätzmethoden auf der Grundlage kausaler Schlussfolgerungen eingesetzt werden, um die Probleme der Datenknappheit und der Schwierigkeit bei der Schätzung kausaler Effekte wirksam zu lösen.
Schließlich können Empfehlungsmodelle besser konstruiert werden, indem kausales Wissen oder kausales Vorwissen als Leitfaden für die Gestaltung des Empfehlungssystems genutzt wird. Mit dieser Methode kann das Empfehlungsmodell das traditionelle Black-Box-Modell übertreffen und nicht nur die Genauigkeit verbessern, sondern auch die Interpretierbarkeit und Fairness erheblich verbessern.
Ausgehend von diesen drei Ideen stellt dieser Austausch die folgenden drei Teile der Arbeit vor:
- Entflechtung von Benutzerinteresse und Konformität für Empfehlungen (Y. Zheng, Chen Gao, et al. Entwirrung von Benutzerinteresse und Konformität für Empfehlungen mit kausaler Einbettung [C]//Proceedings of the Web Conference 2021. 2021: 2980-2991.)
- Entflechtungslernen von langfristigem und kurzfristigem Interesse (Y. Zheng, Chen Gao*, et al. Begriffsinteressen für Empfehlung[C]//Proceedings of the ACM Web Conference 2022. 2022: 2256-2267.)
- Entzerrung von Kurzvideoempfehlungen (Y. Zheng, Chen Gao*, et al. DVR: Mikrovideo Empfehlung zur Optimierung des Wiedergabezeitgewinns unter Dauerverzerrung[C]//Proceedings of the 30th ACM International Conference on Multimedia 2022: 334-345 Lernen Sie zunächst entsprechende Darstellungen für Benutzerinteressen und Konformitätsdiskriminierung durch kausale Inferenzmethoden. Dies gehört zum dritten Teil des oben genannten Klassifizierungsrahmens, der das Modell besser interpretierbar machen soll, wenn Vorkenntnisse über Ursache und Wirkung vorliegen.
Warum müssen wir entwirrte Darstellungen lernen? Lassen Sie uns hier eine ausführlichere Erklärung geben. Die entwirrte Darstellung kann dabei helfen, das Problem der inkonsistenten Verteilung (OOD) von Offline-Trainingsdaten und Online-Versuchsdaten zu überwinden. Wenn in einem echten Empfehlungssystem ein Offline-Empfehlungssystemmodell unter einer bestimmten Datenverteilung trainiert wird, muss berücksichtigt werden, dass sich die Datenverteilung bei der Online-Bereitstellung ändern kann. Das endgültige Verhalten des Benutzers wird durch die gemeinsame Aktion von Konformität und Interesse erzeugt. Die relative Bedeutung dieser beiden Teile ist zwischen Online- und Offline-Umgebungen unterschiedlich, was dazu führen kann, dass sich die Datenverteilung ändert, und es gibt keine Garantie dafür Das Interesse am Lernen bleibt bestehen. Es handelt sich hierbei um ein Cross-Distribution-Problem. Das Bild unten kann dieses Problem visuell veranschaulichen. In dieser Abbildung gibt es einen Verteilungsunterschied zwischen den Trainings- und Testdatensätzen: die gleiche Form, aber ihre Größe und Farbe haben sich geändert. Für die Formvorhersage können herkömmliche Modelle anhand der Größe und Farbe des Trainingsdatensatzes auf Formen schließen. Beispielsweise sind Rechtecke blau und am größten, aber die Schlussfolgerung gilt nicht für den Testdatensatz.
Wenn Sie diese Schwierigkeit besser überwinden möchten, müssen Sie effektiv sicherstellen, dass die Darstellung jedes Teils durch den entsprechenden Faktor bestimmt wird. Dies ist eine Motivation für das Erlernen entwirrter Darstellungen. Modelle, die latente Faktoren entwirren können, können in Kreuzverteilungssituationen ähnlich der obigen Abbildung bessere Ergebnisse erzielen: Beispielsweise lernt die Entwirrung Faktoren wie Kontur, Farbe und Größe und verwendet bevorzugt Konturen, um Formen vorherzusagen.
Der traditionelle Ansatz besteht darin, die IPS-Methode zu verwenden, um die Beliebtheit von Produkten auszugleichen. Diese Methode bestraft übermäßig beliebte Elemente (diese Elemente haben hinsichtlich der Konformität ein größeres Gewicht) während des Lernprozesses des Empfehlungssystemmodells. Aber dieser Ansatz bündelt Interesse und Konformität, ohne sie effektiv zu trennen.

Es gibt einige frühe Arbeiten zum Erlernen der kausalen Darstellung (kausale Einbettung) durch kausale Schlussfolgerung. Der Nachteil dieser Art von Arbeit besteht darin, dass sie sich auf einige unvoreingenommene Datensätze stützen muss und den Lernprozess voreingenommener Datensätze durch unvoreingenommene Datensätze einschränkt. Obwohl nicht viel benötigt wird, ist dennoch eine kleine Menge unverzerrter Daten erforderlich, um entwirrte Darstellungen zu lernen. Daher ist seine Anwendbarkeit in realen Systemen relativ begrenzt.

- Variable Konformität: Konformität ist eigentlich ein allgemeineres oder häufigeres Konzept, das einen Beliebtheitsbias beinhaltet. Die Konformität wird sowohl vom Benutzer als auch vom Artikel bestimmt. Die Konformität eines Benutzers kann bei verschiedenen Artikeln unterschiedlich sein und umgekehrt.
- Schwierigkeit der Entflechtung: Es ist eine ziemliche Herausforderung, eine entwirrte Darstellung direkt zu lernen. Es können nur Beobachtungsdaten (ein Verhalten, das sowohl von Interesse als auch von Konformität beeinflusst wird) erhalten werden, aber es gibt keine grundlegende Wahrheit über das Interesse des Benutzers, das heißt, es gibt keine explizite Bezeichnung für Interesse und Konformität selbst.
- Multikausale Natur des Benutzerverhaltens: Eine bestimmte Benutzerinteraktion kann aus der Wirkung eines einzelnen Faktors oder der Kombination zweier Faktoren resultieren. Das Empfehlungssystem erfordert eine sorgfältige Gestaltung, um die beiden Faktoren effektiv zu integrieren.
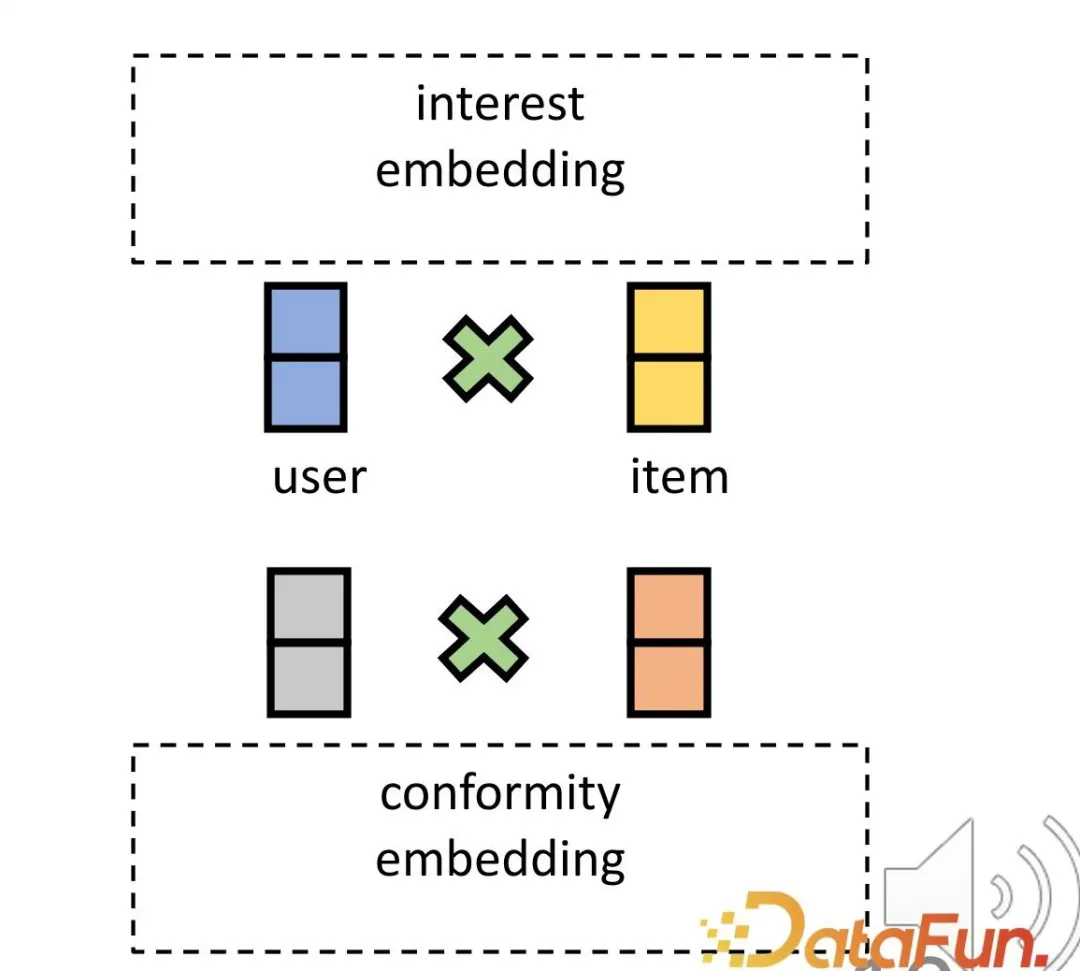
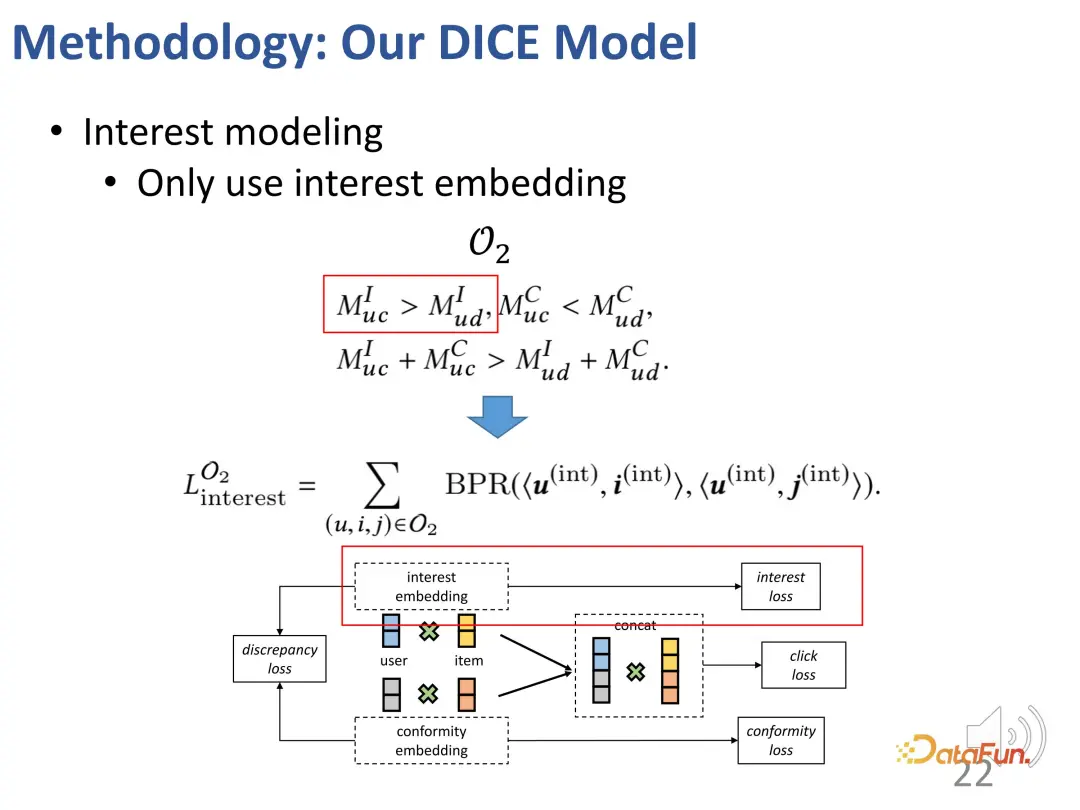
- Um die erste Herausforderung zu lösen, werden entsprechende Darstellungen für Benutzer und Produkte hinsichtlich Interesse und Konformität festgelegt. Erstens kann die Einbettung der Interaktion zwischen Benutzern und Produkten im hochdimensionalen Raum effektiv vielfältige Konformität zum Ausdruck bringen. Zweitens kann diese Methode Interesse und Konformität im hochdimensionalen Raum effektiv direkt entwirren, anstatt sich auf eine gemeinsame Darstellung zu verlassen, wodurch die Unabhängigkeit der beiden erreicht wird.
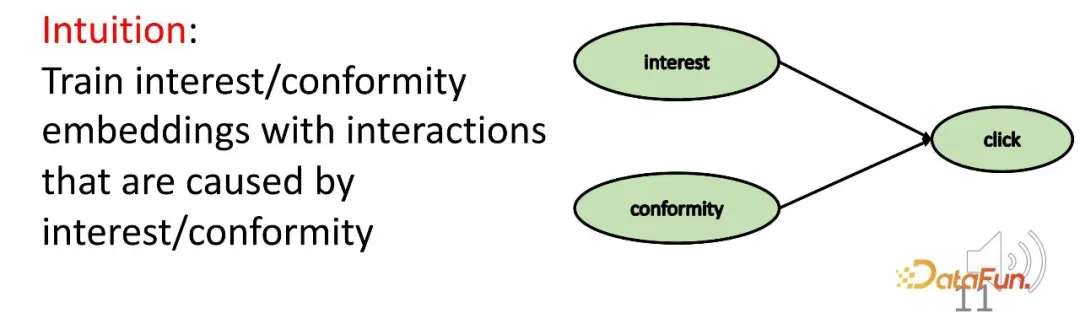
- Um die zweite Herausforderung zu lösen, wird die Kollisionsbeziehung im Kausalschluss genutzt. Interesse und Konformität führen gemeinsam zu Verhalten, und es besteht eine Kollisionsbeziehung. Diese Beziehung wird verwendet, um spezifische kausale Daten zu erhalten und entsprechende Darstellungen für die beiden Teile zu lernen.
- Um die Multi-Faktor-Herausforderung des Benutzerverhaltens zu lösen, wird eine Multi-Task-Progressive-Learning-Methode (CL) verwendet, um diese beiden Faktoren effektiv zu kombinieren und so die endgültige Empfehlung zu erreichen.
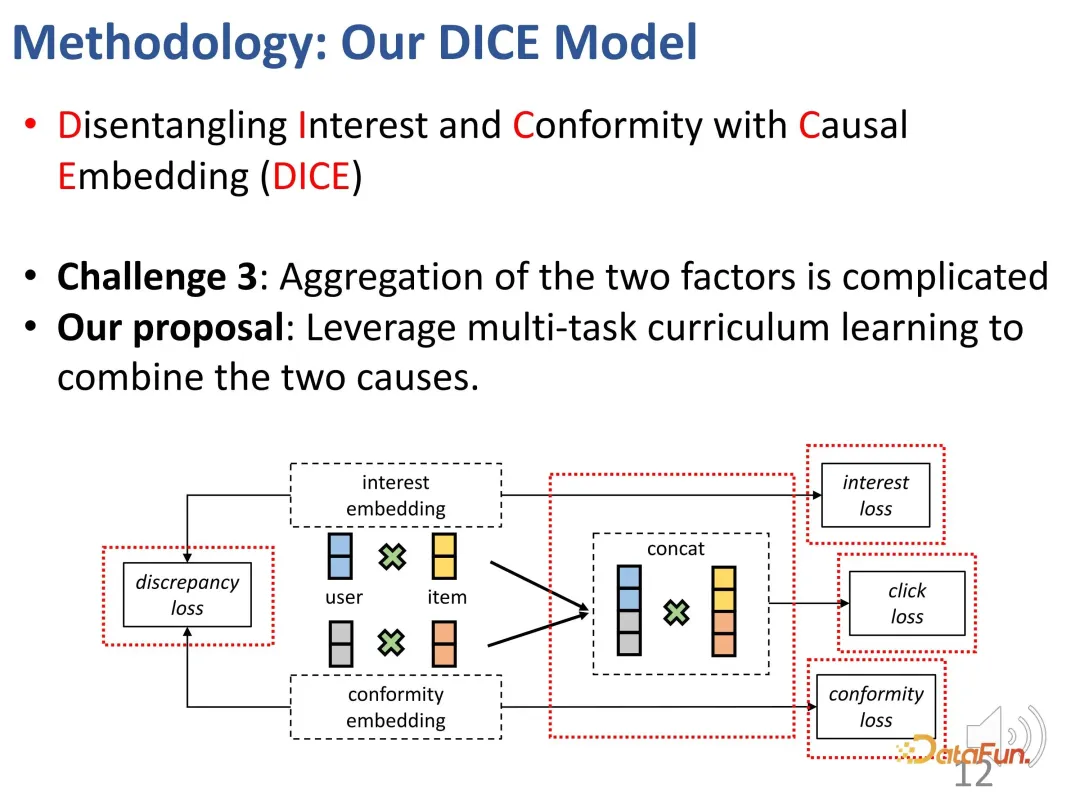
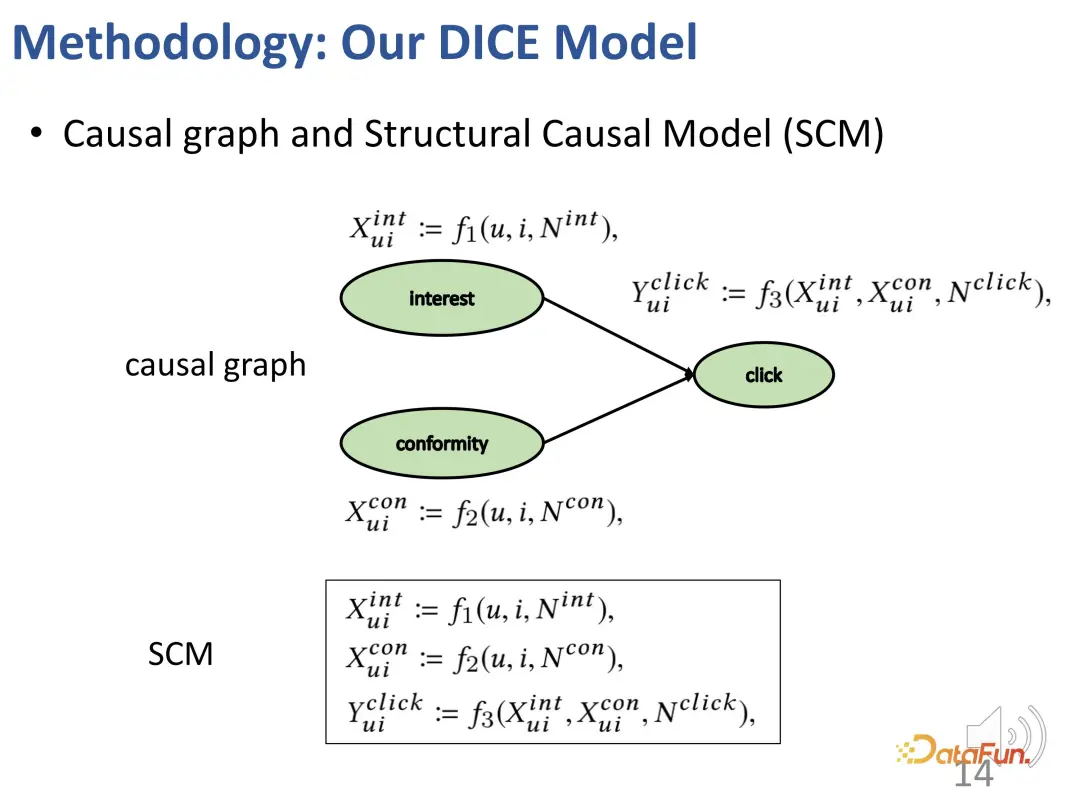
1. Kausale Einbettung
Erstellen Sie zunächst ein strukturelles Kausalmodell, einschließlich Interesse und Hüteverhalten.
2. Lernen der Entflechtungsdarstellung
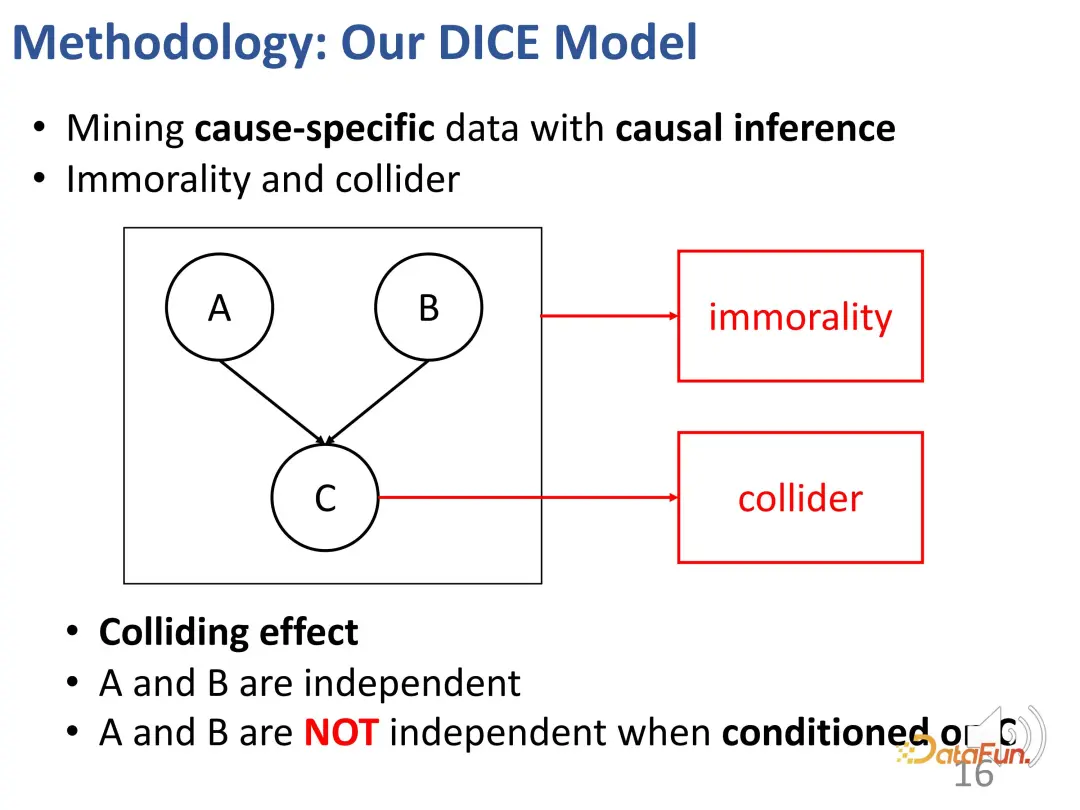
Bei einer solchen Kollisionsstruktur wie oben sind a und b tatsächlich nicht unabhängig, wenn die Bedingung c festgelegt ist. Geben Sie ein Beispiel, um diesen Effekt zu erklären: Beispielsweise steht a für das Talent eines Schülers, b für seinen Fleiß und c für die Fähigkeit des Schülers, eine Prüfung zu bestehen. Wenn dieser Student die Prüfung besteht und keine besonders ausgeprägte Begabung besitzt, muss er sehr hart gearbeitet haben. Ein anderer Schüler hat die Prüfung nicht bestanden, ist aber sehr talentiert, dann arbeitet dieser Klassenkamerad möglicherweise nicht hart genug.
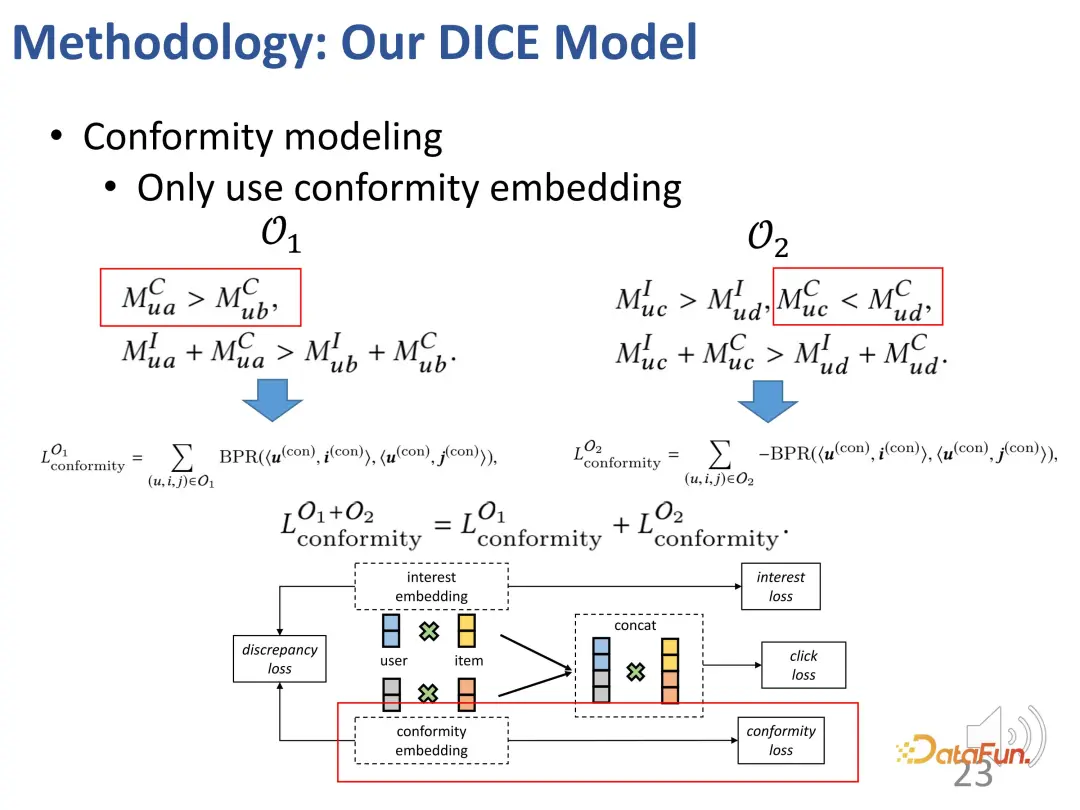
Basierend auf dieser Idee ist die Methode so konzipiert, dass sie die Interessenübereinstimmung und die Konformitätsübereinstimmung aufteilt und die Beliebtheit des Produkts als Indikator für die Konformität verwendet.
Der erste Fall: Wenn ein Benutzer auf ein beliebteres Element a klickt, aber nicht auf ein anderes weniger beliebtes Element b klickt, ähnlich wie im Beispiel gerade, besteht eine Interessenbeziehung wie unten gezeigt: a zu a Benutzer Die Konformität von a ist größer als die von b (weil a beliebter ist als b), und die allgemeine Attraktivität von a für Benutzer (Interesse + Konformität) ist größer als die von b (weil der Benutzer auf a geklickt hat, aber nicht geklickt hat). B).
Zweiter Fall: Ein Benutzer hat auf ein unpopuläres Element c geklickt, aber nicht auf ein beliebtes Element d geklickt, was zu der folgenden Beziehung führt: Die Konformität von c mit den Benutzern ist geringer als d (weil d beliebter ist als c), aber die allgemeine Attraktivität von c für den Benutzer (Interesse + Konformität) ist größer als d (weil der Benutzer auf c, aber nicht auf d geklickt hat), sodass das Interesse des Benutzers an c größer als d ist (aufgrund der Kollisionsbeziehung, wie oben erwähnt). .
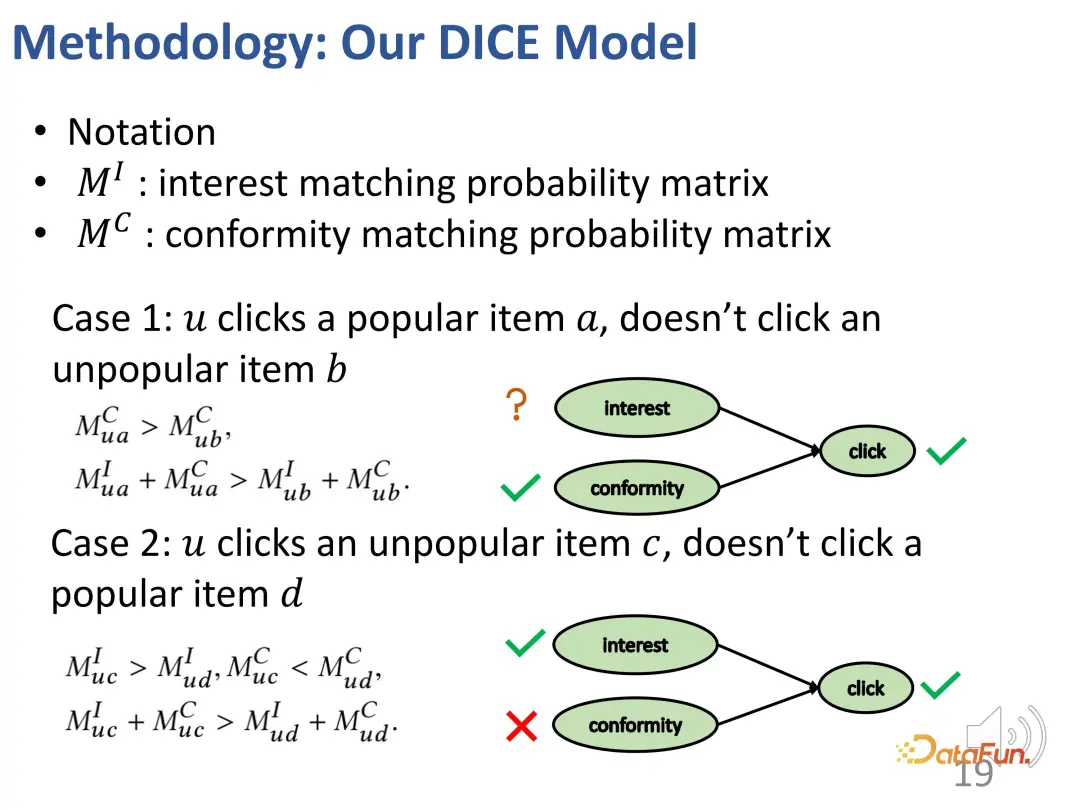
Im Allgemeinen werden mit der oben genannten Methode zwei Sätze erstellt: Einer sind die negativen Proben, die weniger beliebt sind als positive Proben (die gegensätzliche Beziehung zwischen dem Interesse des Benutzers an positiven und negativen Proben ist unbekannt), und der andere Andere sind solche, die weniger beliebt sind als positive Proben. Negative Proben, bei denen die Probe beliebter ist (Benutzer sind mehr an positiven Proben als an negativen Proben interessiert). Auf diesen beiden Teilen kann die Beziehung des kontrastiven Lernens konstruiert werden, um die Repräsentationsvektoren der beiden Teile gezielt zu trainieren.
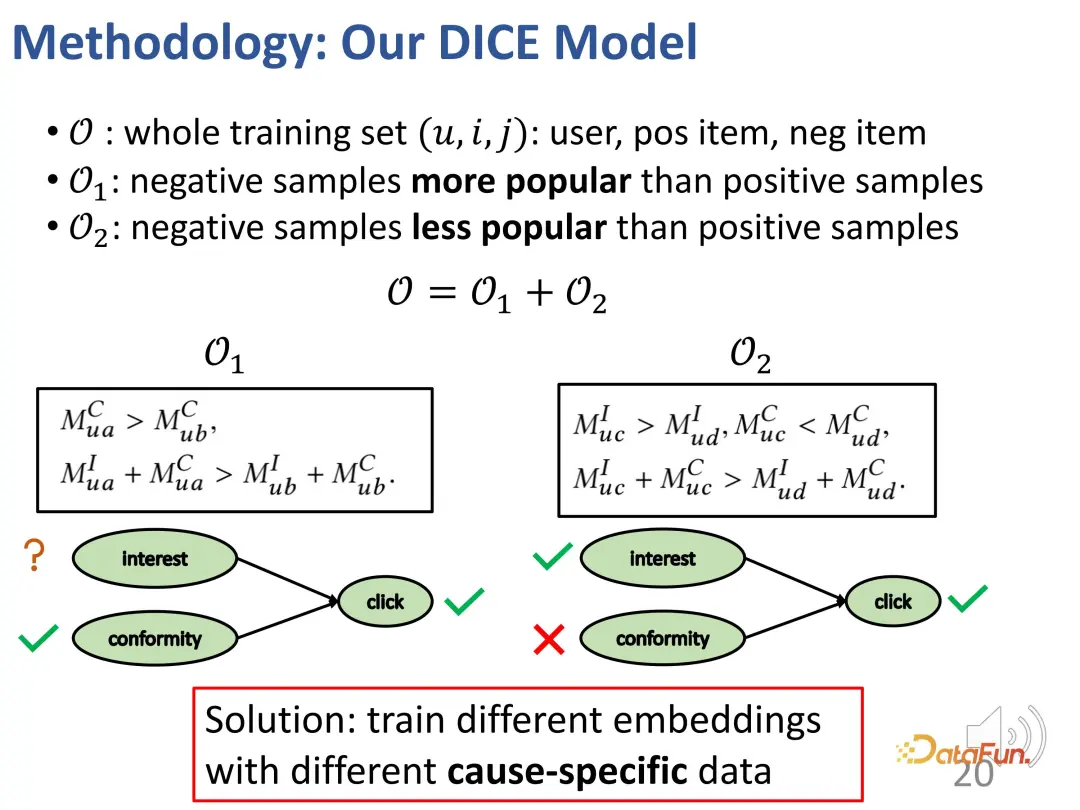
Im eigentlichen Trainingsprozess geht es natürlich immer noch darum, das beobachtete Interaktionsverhalten anzupassen. Wie bei den meisten Empfehlungssystemen wird der BPR-Verlust zur Vorhersage des Klickverhaltens verwendet. (u: Benutzer, i: positives Probenprodukt, j: negatives Probenprodukt).
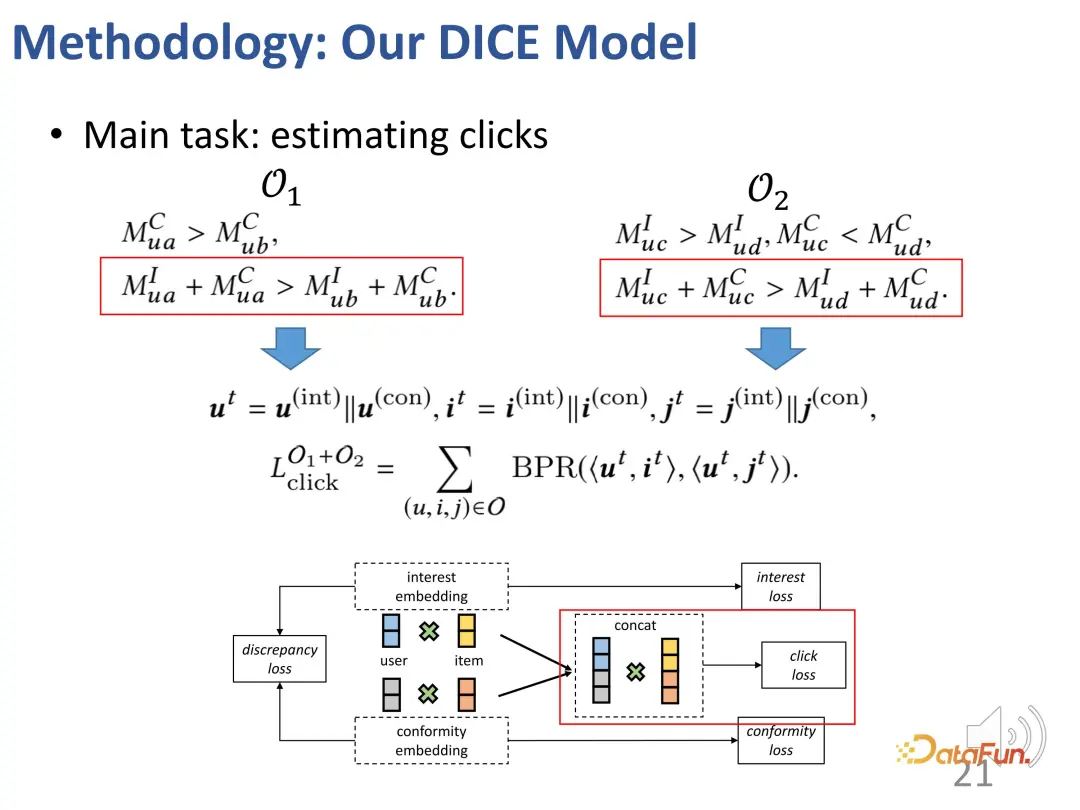
Darüber hinaus haben wir basierend auf den oben genannten Ideen auch zwei Teile kontrastiver Lernmethoden entworfen, die Verlustfunktion des kontrastiven Lernens eingeführt und zusätzlich die Einschränkungen der beiden Teile von Darstellungsvektoren eingeführt, um die beiden zu optimieren Teile der Darstellungsvektoren
Darüber hinaus müssen die Darstellungsvektoren dieser beiden Teile so weit wie möglich voneinander entfernt sein. Dies liegt daran, dass sie ihre Unterscheidungskraft verlieren können, wenn sie zu nahe beieinander liegen. Daher wird eine zusätzliche Verlustfunktion eingeführt, um den Abstand zwischen den beiden Teildarstellungsvektoren einzuschränken.
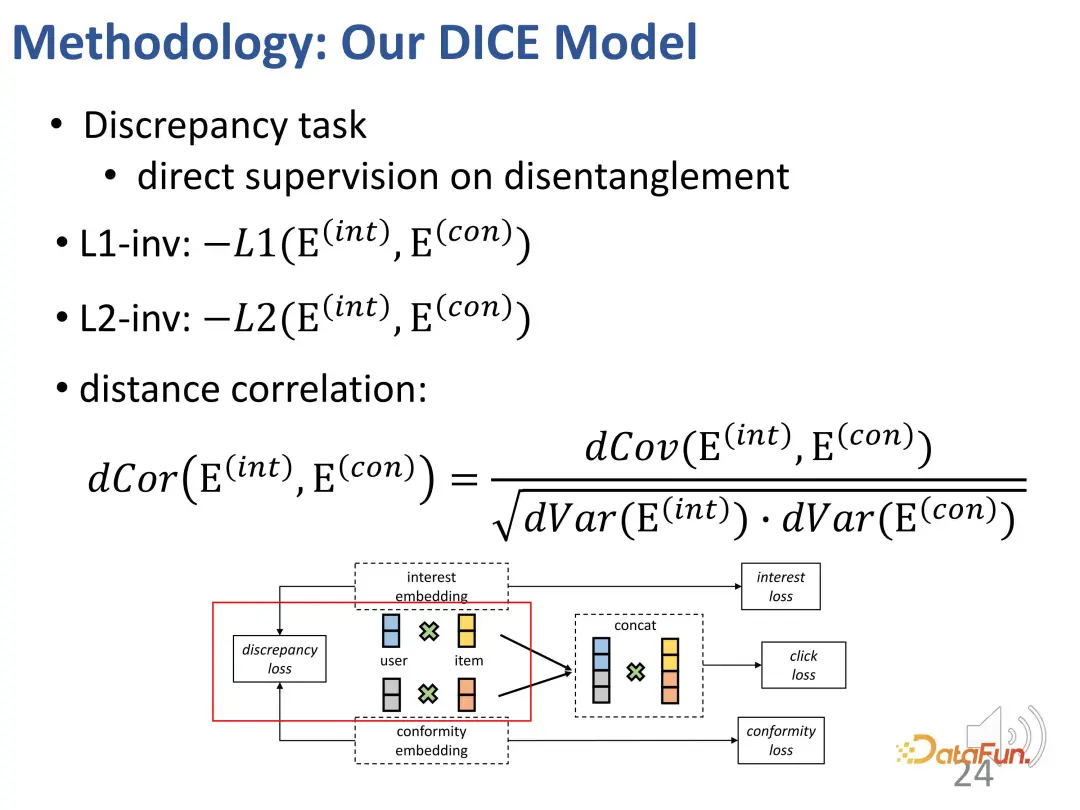
3. Multitasking-Kurslernen
Letztendlich werden beim Multitasking-Lernen mehrere Ziele miteinander verknüpft. Während dieses Prozesses wurde eine Strategie entwickelt, um einen schrittweisen Übergang von leicht zu schwer in Bezug auf die Lernschwierigkeit sicherzustellen. Zu Beginn des Trainings werden Proben mit geringerer Unterscheidungskraft verwendet, um die zu optimierenden Modellparameter in die richtige allgemeine Richtung zu lenken, und dann werden nach und nach schwierige Proben zum Lernen gefunden, um die Modellparameter weiter zu verfeinern. (Negative Proben mit einem großen Unterschied in der Beliebtheit gegenüber positiven Proben werden als einfache Proben betrachtet, und solche mit einem kleinen Unterschied werden als schwierige Proben betrachtet.)

4. Methodeneffekt
wurde an gängigen Datensätzen getestet, um die Leistung der Methode anhand der wichtigsten Ranking-Indikatoren zu untersuchen. Da es sich bei DICE um ein allgemeines Framework handelt, das nicht von einem bestimmten Empfehlungsmodell abhängt, können verschiedene Modelle als Rückgrat betrachtet und DICE als Plug-and-Play-Framework verwendet werden.

Zuallererst der Protagonist DICE. Es ist ersichtlich, dass die Verbesserung von DICE auf verschiedenen Backbones relativ stabil ist, sodass es als allgemeiner Rahmen betrachtet werden kann, der eine Leistungsverbesserung bewirken kann.
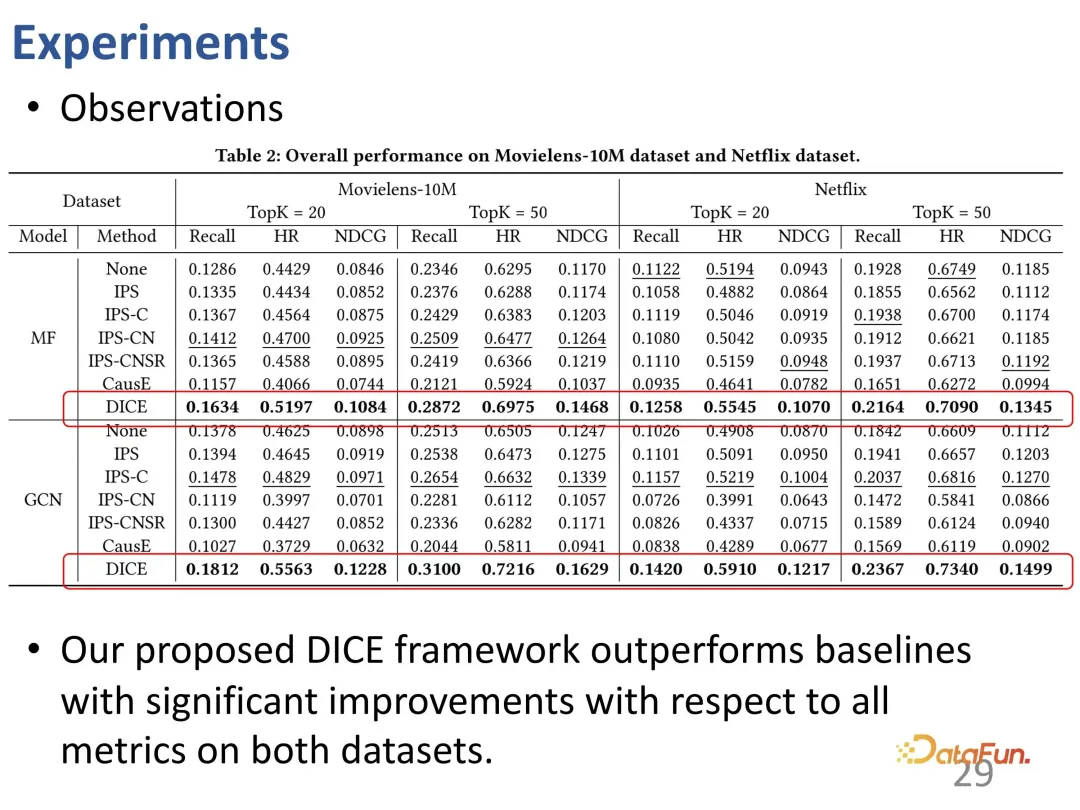
Die von DICE gelernte Darstellung ist interpretierbar. Nachdem die Darstellungen für Interesse und Konformität separat gelernt wurden, enthält der Vektor des Konformitätsteils die Popularität des Produkts. Durch Visualisierung wird festgestellt, dass es tatsächlich mit der Beliebtheit zusammenhängt (die Darstellung unterschiedlicher Beliebtheit zeigt eine offensichtliche Schichtung: grüne, orange und gelbe Punkte).
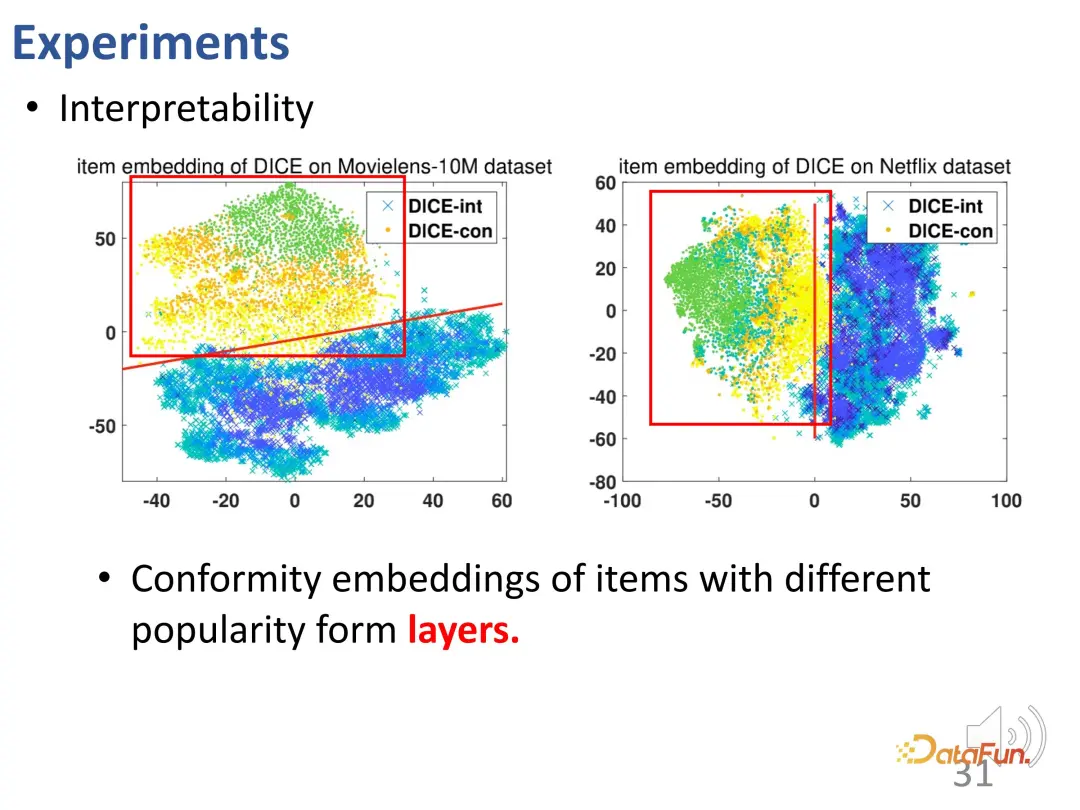
Darüber hinaus sind die Interessenvektordarstellungen von Elementen mit unterschiedlicher Beliebtheit gleichmäßig im Raum verteilt (Cyaninkreuz). Die Konformitätsvektordarstellung und die Interessenvektordarstellung nehmen ebenfalls unterschiedliche Räume ein und sind durch Entflechtung getrennt. Diese Visualisierung bestätigt, dass die von DICE gelernten Darstellungen tatsächlich sinnvoll sind.
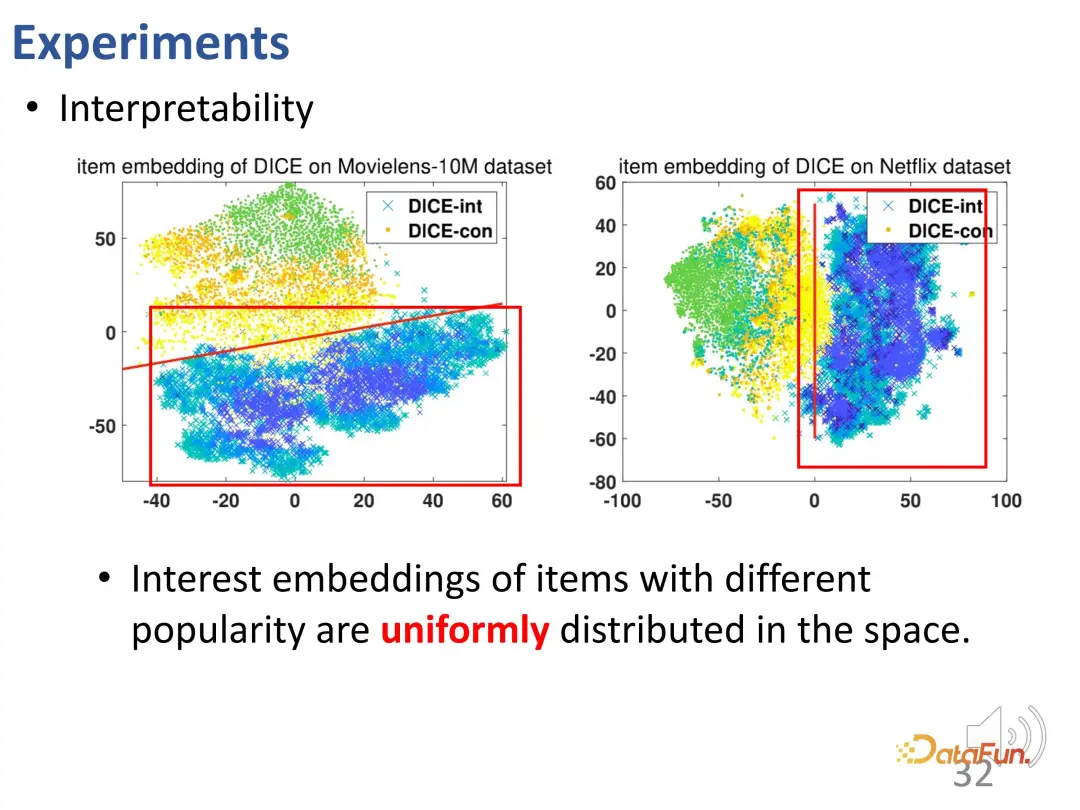
DICE hat die beabsichtigte Wirkung des Designs erreicht. Weitere Tests wurden an Daten mit unterschiedlichen Interventionsintensitäten durchgeführt und die Ergebnisse zeigten, dass die Leistung von DICE in verschiedenen Versuchsgruppen besser war als die IPS-Methode.
Zusammenfassend lässt sich sagen, dass DICE kausale Inferenzwerkzeuge verwendet, um entsprechende Darstellungsvektoren für Interesse bzw. Konformität zu lernen, was eine gute Robustheit und Interpretierbarkeit in Nicht-IID-Situationen bietet.

2. Entflechtungslernen von langfristigem und kurzfristigem Interesse
Die zweite Arbeit löst hauptsächlich das Entflechtungsproblem von langfristigem Interesse und kurzfristigem Interesse Sequenzempfehlungen, insbesondere Benutzerinteressen, sind komplex und werden als langfristige Interessen bezeichnet, während andere Interessen plötzlich auftreten und als kurzfristige Interessen bezeichnet werden. Im folgenden Beispiel interessiert sich der Nutzer langfristig für elektronische Produkte, möchte aber kurzfristig etwas Kleidung kaufen. Wenn diese Interessen gut identifiziert werden können, können die Gründe für jedes Verhalten besser erklärt und die Leistung des gesamten Empfehlungssystems verbessert werden.

Ein solches Problem kann als Modellierung langfristiger und kurzfristiger Interessen bezeichnet werden, das heißt, es kann adaptiv langfristige Interessen bzw. kurzfristige Interessen modellieren und weiter ableiten, welcher Teil davon ist Das aktuelle Verhalten des Benutzers wird hauptsächlich bestimmt. Wenn Sie die Interessen identifizieren können, die derzeit das Verhalten bestimmen, können Sie basierend auf aktuellen Interessen bessere Empfehlungen aussprechen. Wenn der Benutzer beispielsweise in einem kurzen Zeitraum dieselbe Kategorie durchsucht, kann dies ein kurzfristiges Interesse sein Interessen statt auf das aktuelle Interesse beschränkt zu sein. Im Allgemeinen sind langfristige und kurzfristige Interessen unterschiedlicher Natur und langfristige Bedürfnisse und kurzfristige Bedürfnisse müssen gut voneinander getrennt werden.

Generell kann davon ausgegangen werden, dass die kollaborative Filterung tatsächlich eine Methode zur Erfassung langfristiger Interessen ist, da sie die dynamischen Änderungen der Interessen ignoriert, während sich bestehende Sequenzempfehlungen eher auf die Modellierung kurzfristiger Interessen konzentrieren. Dies führt dazu, dass langfristige Interessen vergessen werden, und selbst wenn langfristige Interessen berücksichtigt werden, stützt es sich bei der Modellierung immer noch hauptsächlich auf kurzfristige Interessen. Daher sind bestehende Methoden immer noch nicht in der Lage, diese beiden Lerninteressen zu vereinen.
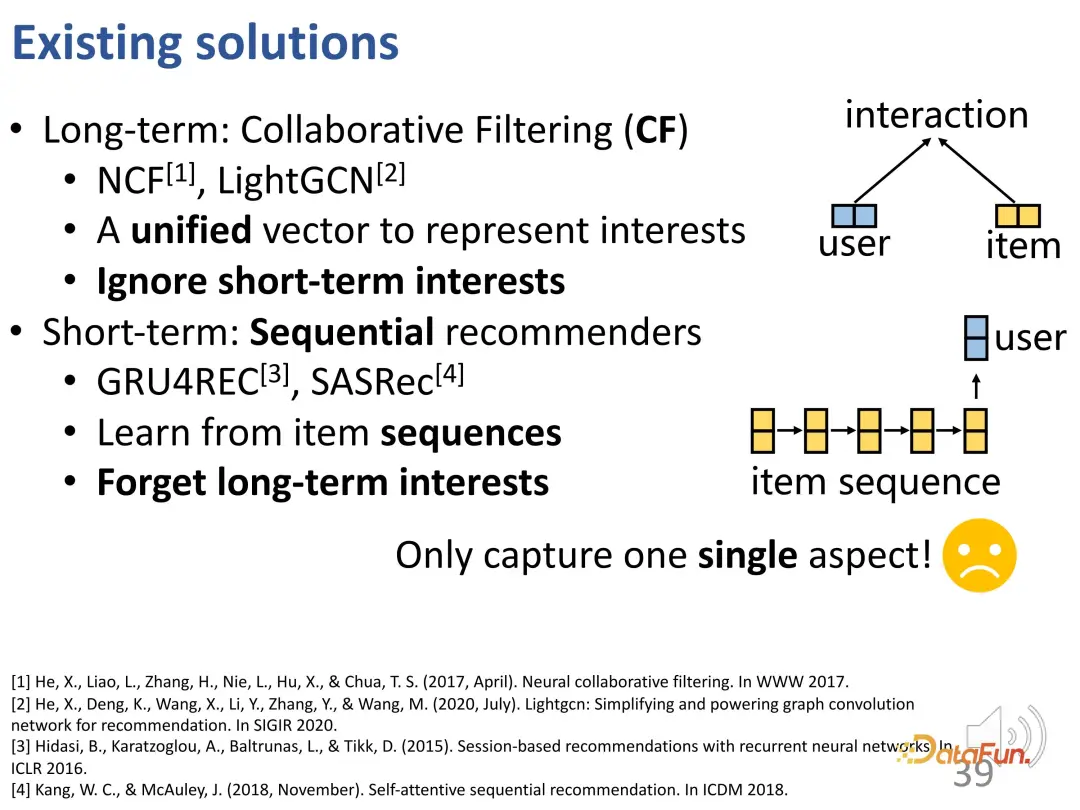
Einige neuere Arbeiten haben damit begonnen, die Modellierung langfristiger und kurzfristiger Interessen zu berücksichtigen, kurzfristige Module und langfristige Module getrennt zu entwerfen und sie dann direkt miteinander zu kombinieren. Unter diesen Methoden gibt es jedoch letztendlich nur einen erlernten Benutzervektor, der sowohl kurzfristige als auch langfristige Signale enthält. Die beiden sind immer noch miteinander verflochten und müssen weiter verbessert werden.
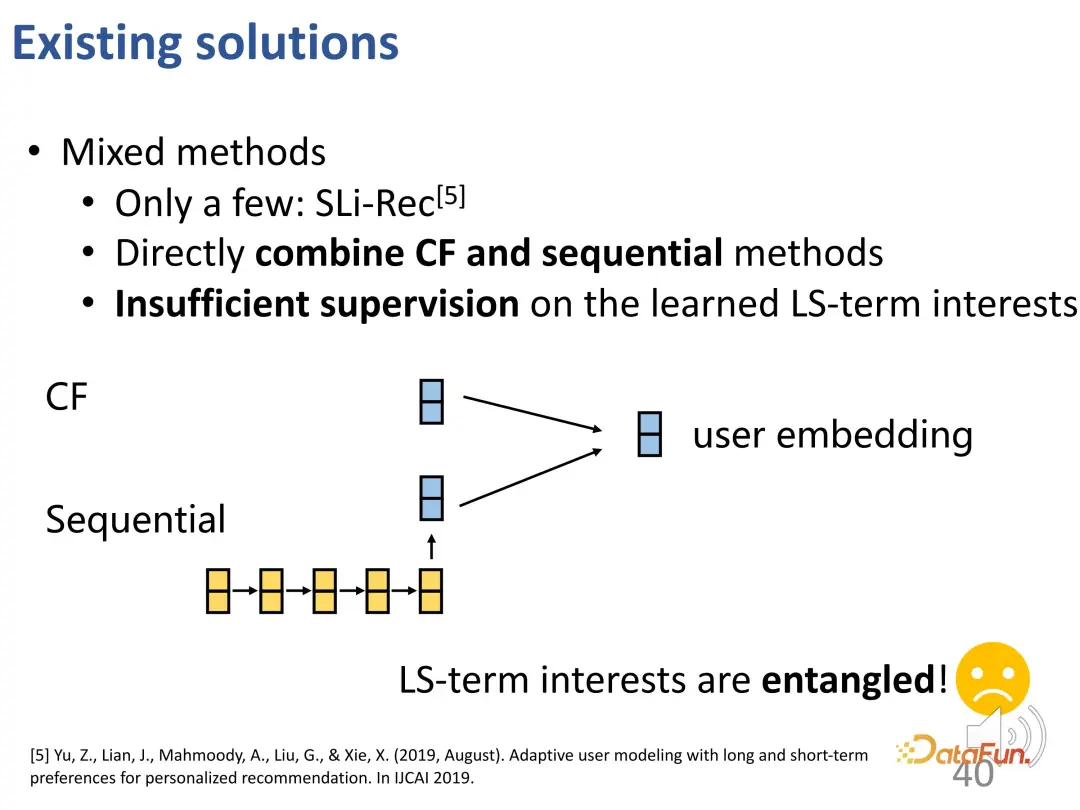
Die Entkopplung lang- und kurzfristiger Interessen ist jedoch immer noch eine Herausforderung:
- Erstens spiegeln langfristige und kurzfristige Interessen tatsächlich Unterschiede in den Präferenzen wider, die zwischen den Benutzern sehr unterschiedlich sein können, und auch ihre Eigenschaften sind unterschiedlich. Das langfristige Interesse ist ein relativ stabiles Allgemeininteresse, während das kurzfristige Interesse dynamisch ist und sich schnell entwickeln kann.
- Zweitens gibt es keine expliziten Bezeichnungen für Long- und Short-Interessen. Bei den meisten der gesammelten endgültigen Daten handelt es sich tatsächlich um das endgültige Verhalten, und es gibt keine grundlegende Wahrheit darüber, zu welcher Art von Interesse es gehört.
- Schließlich ist auch ungewiss, welcher Teil der langfristigen und kurzfristigen Interessen das aktuelle Verhalten bestimmt und welcher Teil wichtiger ist.
Als Reaktion auf dieses Problem wird eine vergleichende Lernmethode vorgeschlagen, um langfristige und kurzfristige Interessen gleichzeitig zu modellieren. (Kontrastiver Lernrahmen für langfristige und kurzfristige Interessen zur Empfehlung (CLSR))
1 Trennung von langfristigen und kurzfristigen Interessen
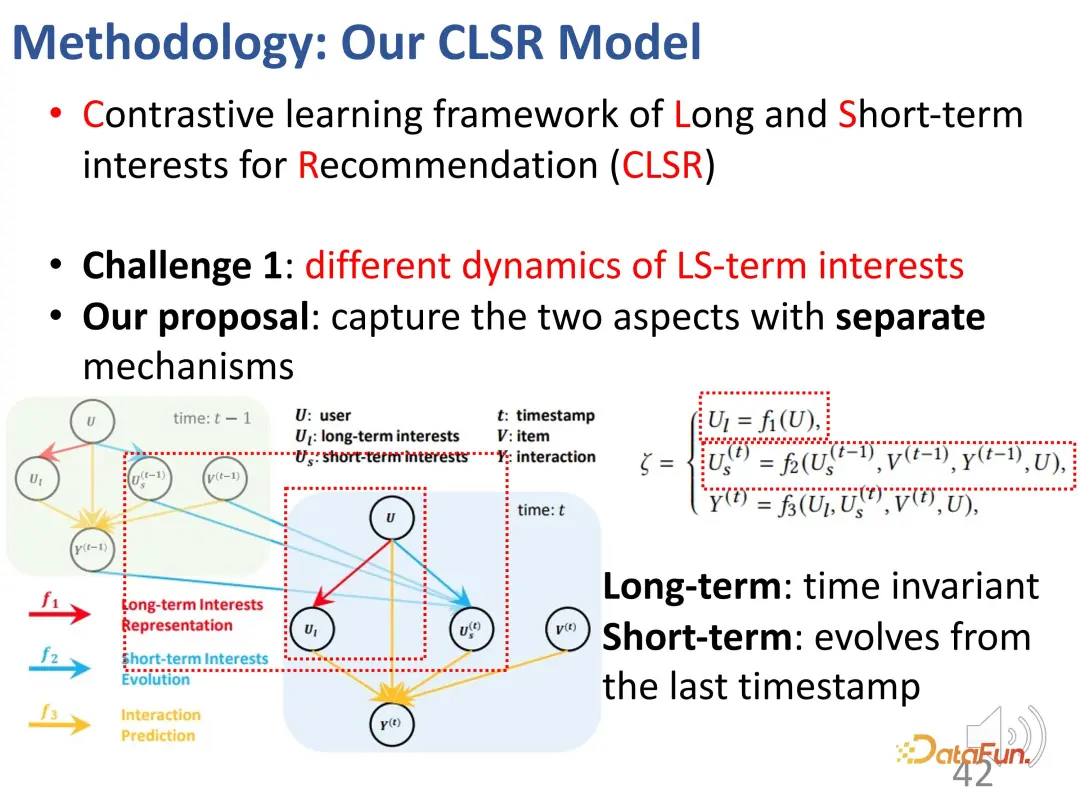
Für die erste Herausforderung – die Trennung von langfristigen und kurzfristigen Interessen Langfristige Interessen, wir trennen langfristige und kurzfristige Interessen. Wir sind daran interessiert, entsprechende evolutionäre Mechanismen zu etablieren. Im strukturellen Kausalmodell wird das langfristige Interesse unabhängig von der Zeit festgelegt, und das kurzfristige Interesse wird durch das kurzfristige Interesse zum vorherigen Zeitpunkt und das allgemeine langfristige Interesse bestimmt. Das heißt, während des Modellierungsprozesses ist das langfristige Interesse relativ stabil, während sich das kurzfristige Interesse in Echtzeit ändert.
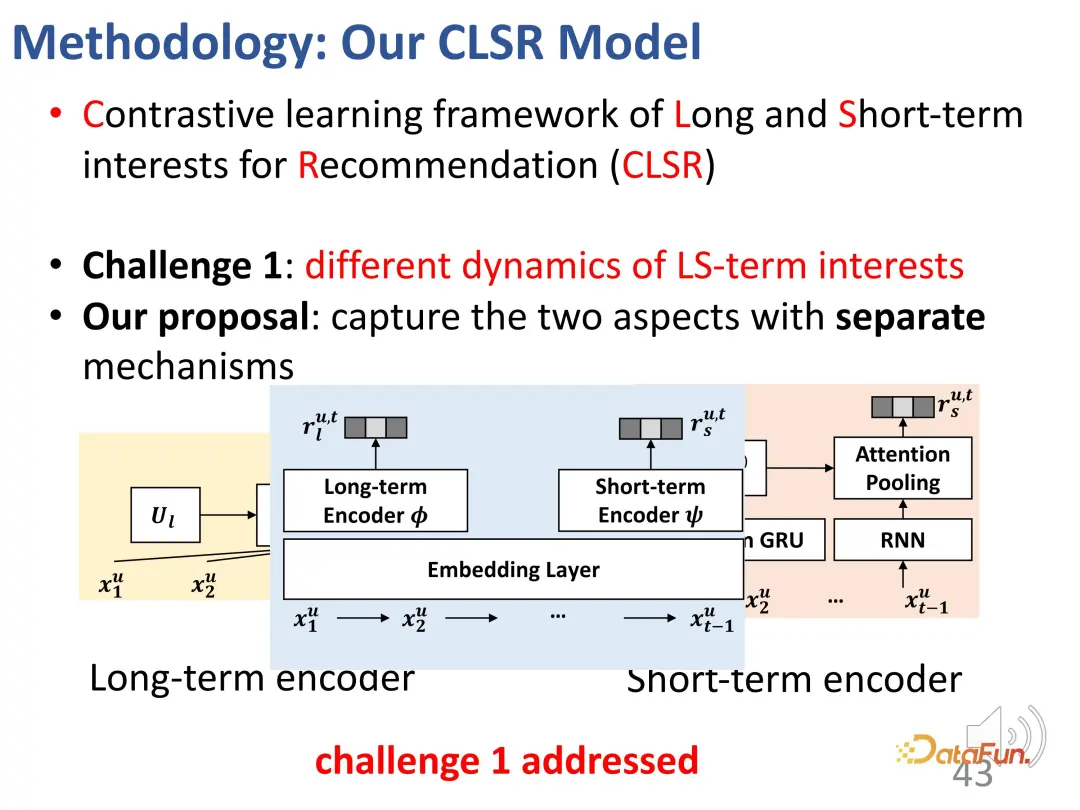
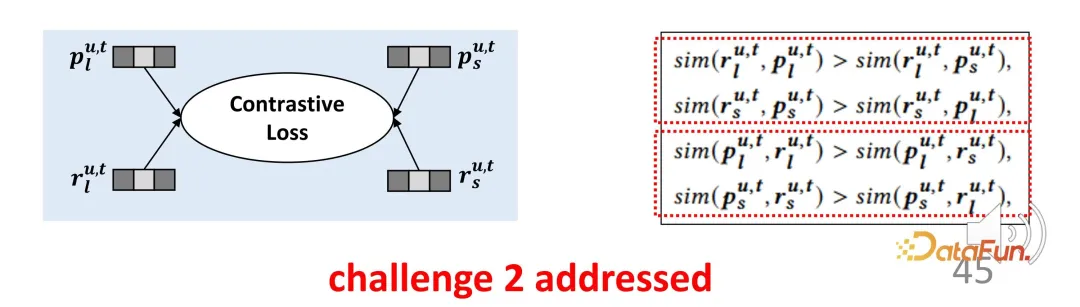
2. Kontrastives Lernen löst das Fehlen expliziter Supervisionssignale
Die zweite Herausforderung ist das Fehlen expliziter Supervisionssignale für die beiden Teile des Interesses. Um dieses Problem zu lösen, werden kontrastive Lernmethoden zur Überwachung eingeführt und Proxy-Labels konstruiert, um explizite Labels zu ersetzen.
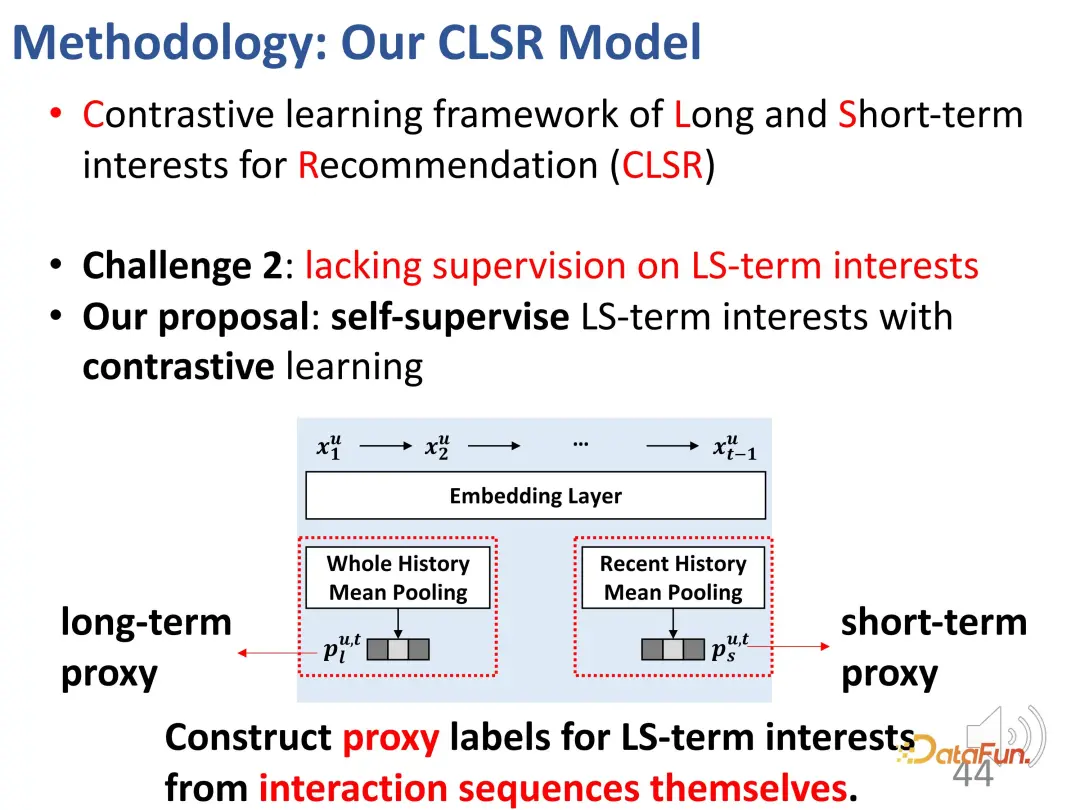
Das Agentenlabel ist in zwei Teile gegliedert, einer für Agenten mit langfristigen Interessen und der andere für Agenten mit kurzfristigen Interessen.
Verwenden Sie die gesamte Geschichte des Poolings als Proxy-Label für langfristiges Interesse, damit die vom Encoder gelernte Darstellung beim Lernen von langfristigem Interesse stärker in diese Richtung optimiert wird.
Ähnlich ist es auch für kurzfristige Interessen. Die durchschnittliche Zusammenfassung der letzten verschiedenen Verhaltensweisen des Benutzers wird ebenfalls als kurzfristiger Proxy verwendet, obwohl sie nicht direkt die Interessen des Benutzers darstellt Im Lernprozess ist es möglich, die kurzfristigen Interessen des Benutzers in diese Richtung zu optimieren. Obwohl Agentendarstellungen wie
nicht unbedingt Interessen darstellen, stellen sie eine Optimierungsrichtung dar. Für die langfristige Interessenrepräsentation und die kurzfristige Interessenrepräsentation werden sie der entsprechenden Repräsentation so nahe wie möglich kommen und sich von der Repräsentation in die andere Richtung fernhalten, wodurch eine Einschränkungsfunktion für kontrastives Lernen aufgebaut wird. Da die Proxy-Darstellung so nah wie möglich am tatsächlichen Encoder-Ausgang sein sollte, handelt es sich auf die gleiche Weise um eine symmetrische zweiteilige Verlustfunktion. Dieses Design gleicht den gerade erwähnten Mangel an Überwachungssignalen effektiv aus.
3. Unterscheidung zwischen langfristigen und kurzfristigen Zinsgewichten
Die dritte Herausforderung besteht darin, die Bedeutung zweier Interessenanteile für ein bestimmtes Verhalten zu beurteilen. Die Lösung besteht darin, die beiden Interessenanteile adaptiv zu verschmelzen. Das Design dieses Teils ist relativ einfach und unkompliziert, da es bereits zwei Teile von Darstellungsvektoren gibt und es nicht schwierig ist, sie miteinander zu mischen. Insbesondere muss ein Gewicht α berechnet werden, um die Interessen der beiden Teile auszugleichen. Wenn α relativ groß ist, wird das aktuelle Interesse hauptsächlich vom langfristigen Interesse dominiert. Abschließend wird eine Schätzung des Interaktionsverhaltens erhalten.
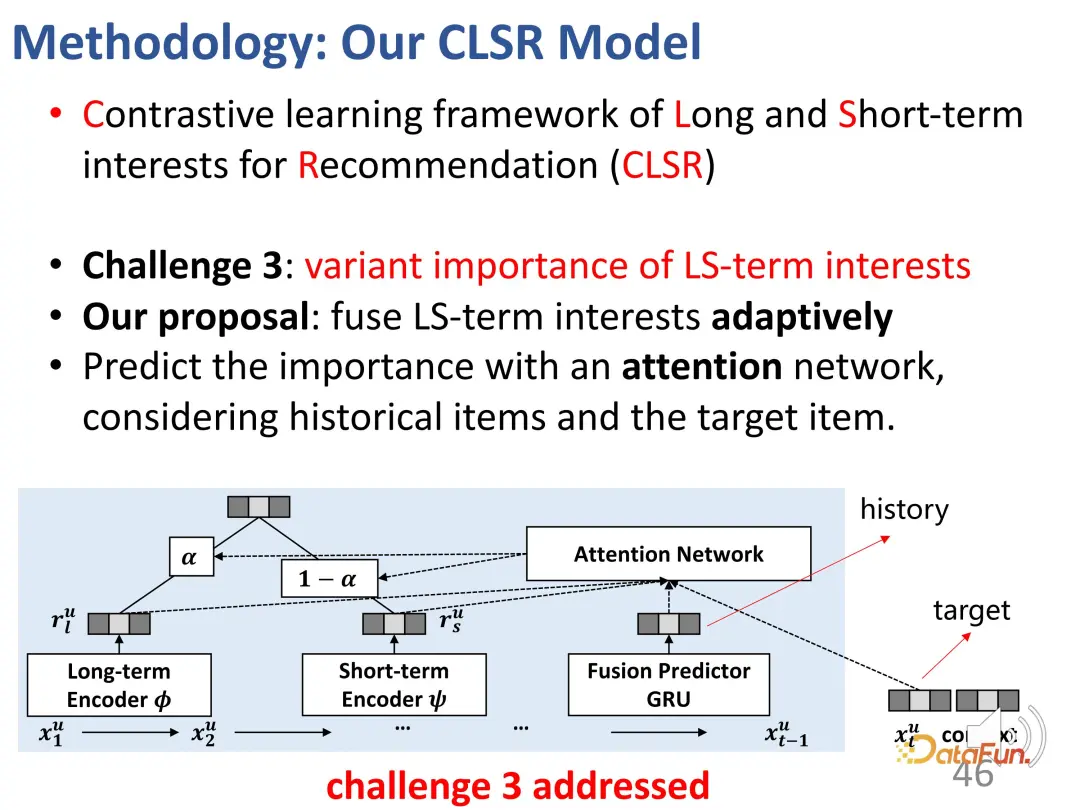
Bei der Vorhersage handelt es sich einerseits um den oben erwähnten Verlust des allgemeinen Empfehlungssystems, andererseits kommt in gewichteter Form noch die Verlustfunktion des kontrastiven Lernens hinzu.

Das Folgende ist das Gesamtblockdiagramm:
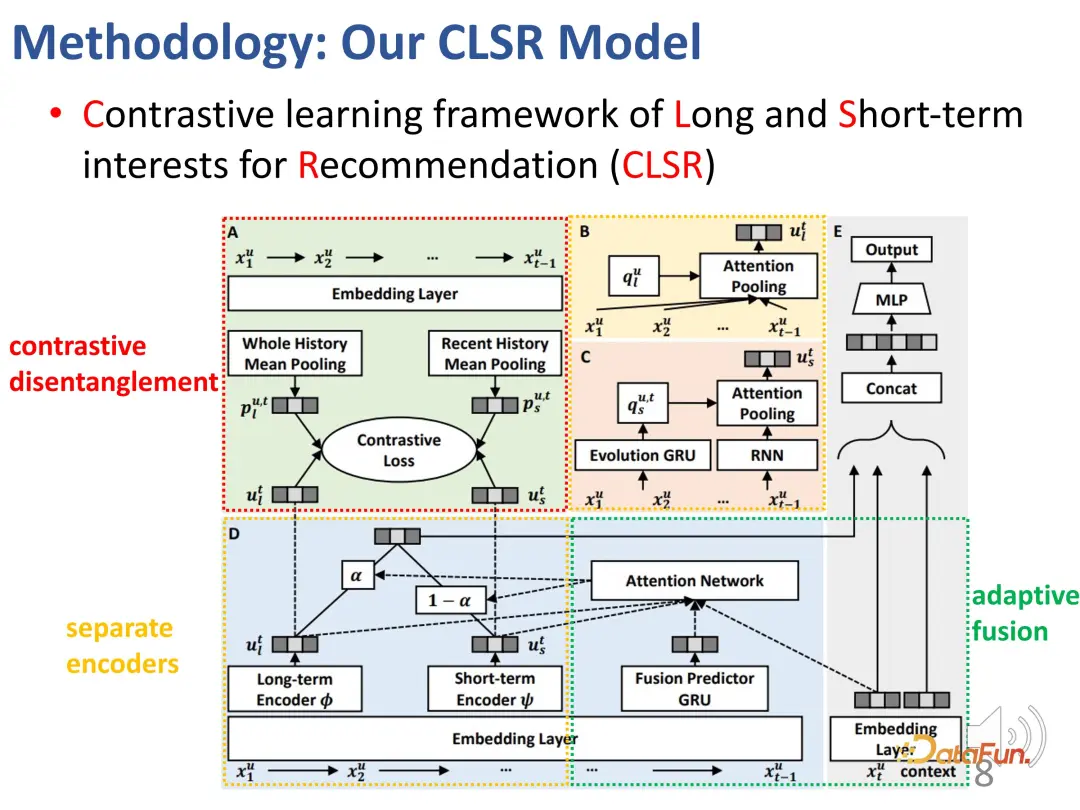
Es gibt zwei separate Encoder (BCD), die entsprechende Agentendarstellung und das Ziel des kontrastiven Lernens (A) und das Automatisch Verschmelzen Sie die Interessen beider Teile adaptiv.
In dieser Arbeit wurden Sequenzempfehlungsdatensätze verwendet, darunter der E-Commerce-Datensatz von Taobao und der kurze Videodatensatz von Kuaishou. Die Methoden werden in drei Typen unterteilt: langfristig, kurzfristig und eine Kombination aus langfristig und kurzfristig.
4. Experimentelle Ergebnisse

Anhand der gesamten experimentellen Ergebnisse können wir erkennen, dass Modelle, die nur kurzfristige Interessen berücksichtigen, besser abschneiden als Modelle, die nur langfristige Interessen berücksichtigen. Sequenzempfehlungsmodelle sind normalerweise besser als reine Modelle. Statische kollaborative Filtermodelle sind besser. Dies ist sinnvoll, da mit der kurzfristigen Interessenmodellierung einige der jüngsten Interessen, die den größten Einfluss auf das aktuelle Verhalten haben, besser identifiziert werden können.
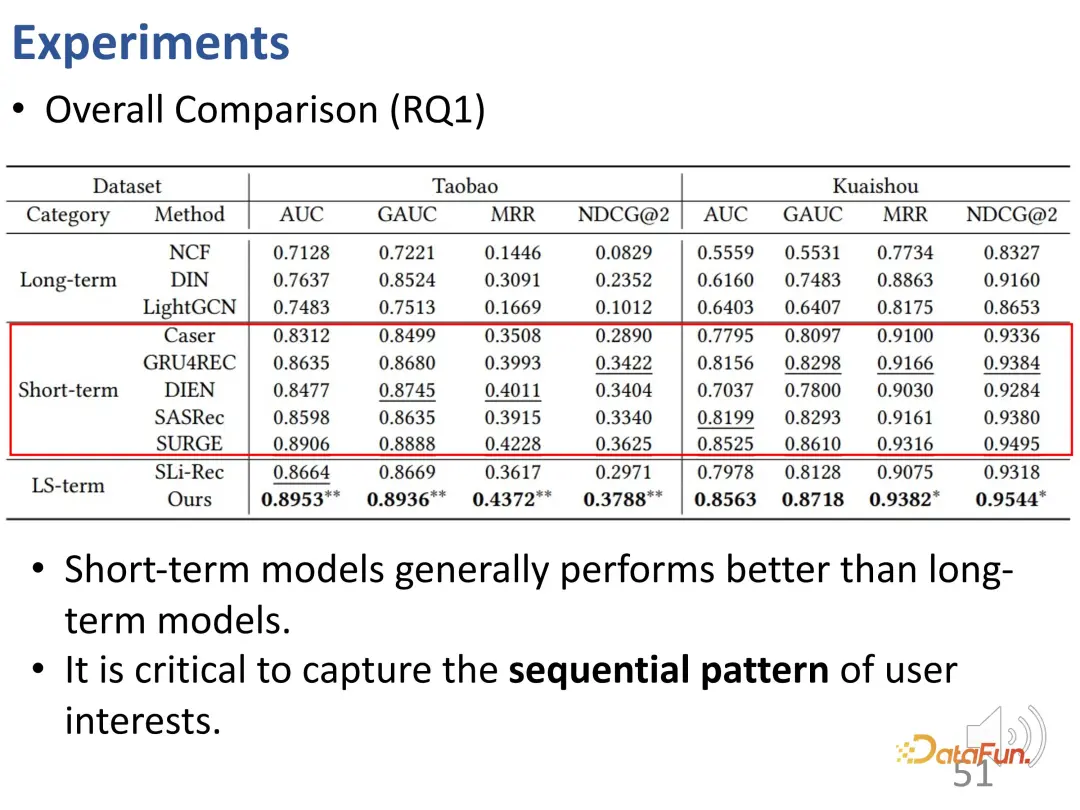
Die zweite Schlussfolgerung ist, dass das SLi-Rec-Modell, das sowohl langfristige als auch kurzfristige Interessen modelliert, nicht unbedingt besser ist als das traditionelle Sequenzempfehlungsmodell. Dies verdeutlicht die Mängel bestehender Arbeiten. Der Grund dafür ist, dass das einfache Mischen der beiden Modelle zu Verzerrungen oder Rauschen führen kann. Wie hier zu sehen ist, ist die beste Basislinie tatsächlich ein sequentielles kurzfristiges Zinsmodell.
Die von uns vorgeschlagene Methode zur Entkopplung von langfristigen und kurzfristigen Zinsen löst das Problem der Entflechtungsmodellierung zwischen langfristigen und kurzfristigen Interessen und kann stabile beste Ergebnisse für zwei Datensätze und vier Indikatoren erzielen.
Um diesen Entflechtungseffekt weiter zu untersuchen, wurden Experimente für zweiteilige Darstellungen durchgeführt, die langfristigen und kurzfristigen Interessen entsprechen. Vergleichen Sie das langfristige Interesse, das kurzfristige Interesse des CLSR-Lernens und die beiden Interessen des Sli-Rec-Lernens. Experimentelle Ergebnisse zeigen, dass unsere Arbeit (CLSR) in der Lage ist, in jedem Teil durchweg bessere Ergebnisse zu erzielen, und beweist auch die Notwendigkeit, langfristige Zinsmodellierung und kurzfristige Zinsmodellierung zu verschmelzen, da beide verwendet werden. Das beste Ergebnis ist die Integration von Interessen .
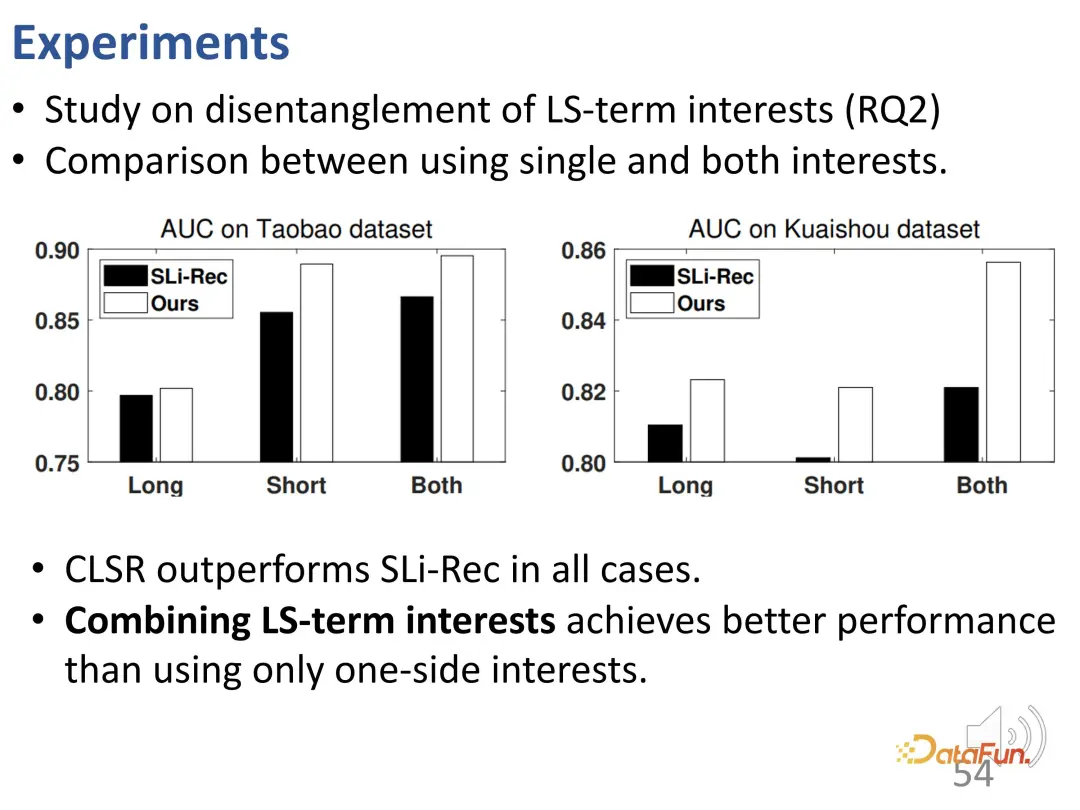
Verwenden Sie außerdem das Kaufverhalten und das Like-Verhalten für vergleichende Untersuchungen, da die Kosten für diese Verhaltensweisen höher sind als für Klicks: Einkäufe kosten Geld und Likes erfordern bestimmte Betriebskosten, sodass diese Interessen tatsächlich eine stärkere Präferenz widerspiegeln für stabile langfristige Interessen. Erstens erzielt CLSR im Leistungsvergleich bessere Ergebnisse. Darüber hinaus ist die Gewichtung der beiden Aspekte der Modellierung sinnvoller. CLSR ist in der Lage, Verhaltensweisen, die stärker auf langfristige Interessen ausgerichtet sind, größere Gewichtungen zuzuweisen als das SLi-Rec-Modell, was mit der vorherigen Motivation übereinstimmt.

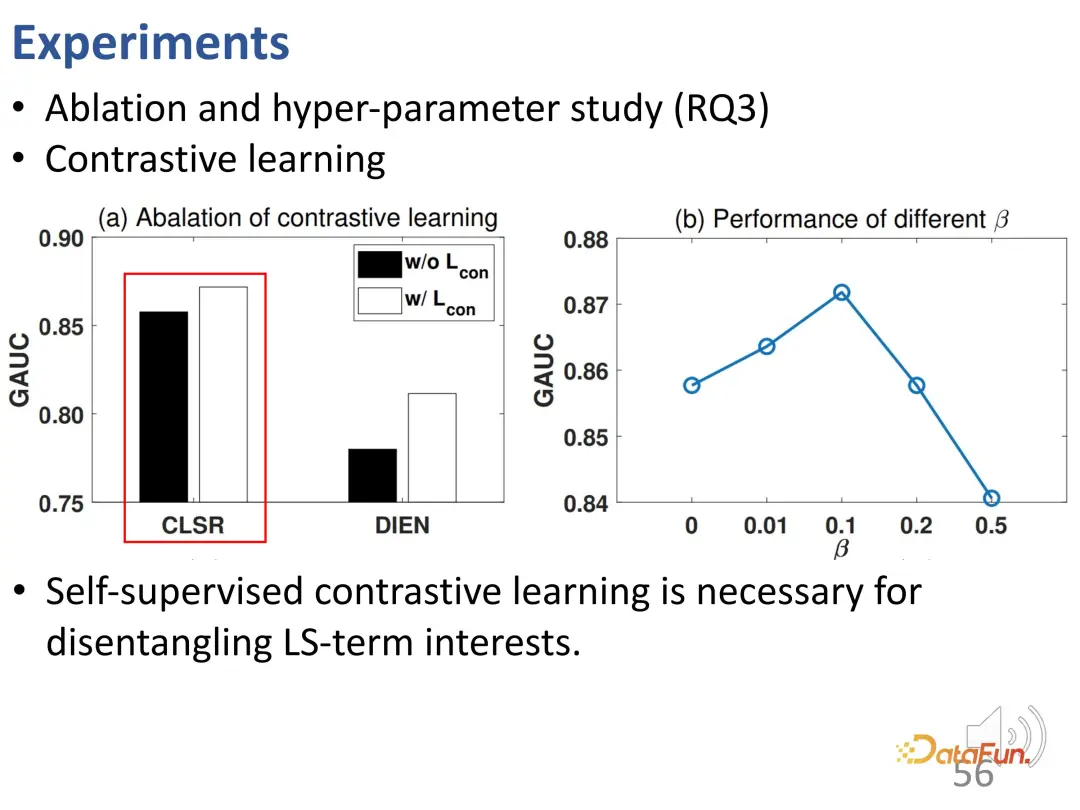
Weitere Ablationsexperimente und Hyperparameterexperimente wurden durchgeführt. Erstens wurde die Verlustfunktion des kontrastiven Lernens entfernt und es wurde festgestellt, dass die Leistung abnahm, was darauf hinweist, dass kontrastives Lernen sehr wichtig ist, um langfristige Interessen und kurzfristige Interessen zu entwirren. Dieses Experiment beweist weiter, dass CLSR ein besserer allgemeiner Rahmen ist, da es auch auf bestehenden Methoden aufbaut (selbstüberwachtes kontrastives Lernen kann die Leistung von DIEN verbessern) und eine Plug-and-Play-Methode ist. Untersuchungen zu β ergaben, dass ein angemessener Wert 0,1 ist.
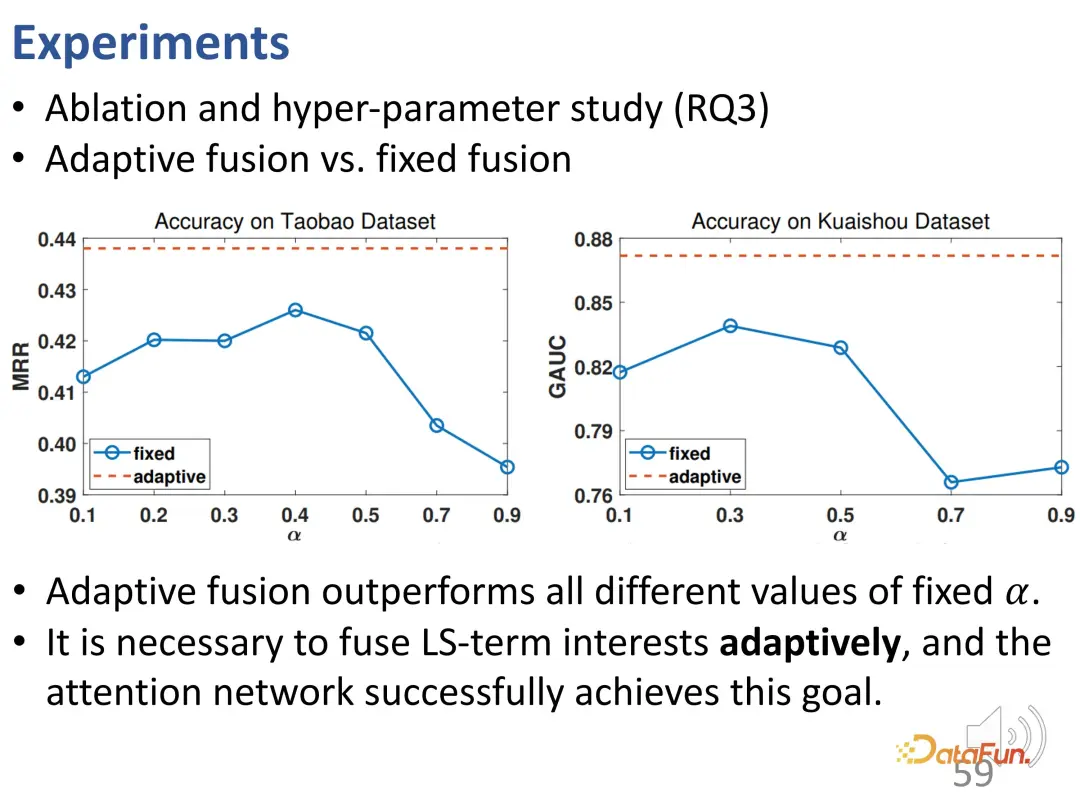
Als nächstes werden wir die Beziehung zwischen adaptiver Fusion und einfacher Fusion weiter untersuchen. Die adaptive Gewichtsfusion ist bei allen unterschiedlichen α-Werten stabiler und besser als die Fusion mit festen Gewichten. Dies bestätigt, dass jedes Interaktionsverhalten durch Gewichte unterschiedlicher Größe bestimmt werden kann, und bestätigt, dass die Interessenfusion durch adaptive Fusion und die Notwendigkeit einer endgültigen Verhaltensvorhersage erreicht wird .
Diese Arbeit schlägt eine kontrastive Lernmethode vor, um das langfristige Interesse und das kurzfristige Interesse an Sequenzinteressen zu modellieren, die entsprechenden Darstellungsvektoren zu lernen und eine Entflechtung zu erreichen. Experimentelle Ergebnisse belegen die Wirksamkeit dieser Methode.

3. Entzerrung kurzer Videoempfehlungen
Die beiden zuvor vorgestellten Aufgaben konzentrieren sich auf die Entflechtung von Interessen. Die dritte Arbeit konzentriert sich auf die Verhaltenskorrektur des Interessenlernens.
Kurze Videoempfehlungen sind zu einem sehr wichtigen Bestandteil des Empfehlungssystems geworden. Bestehende Kurzvideo-Empfehlungssysteme folgen jedoch immer noch dem bisherigen Paradigma der Langvideo-Empfehlung, und es können einige Probleme auftreten.
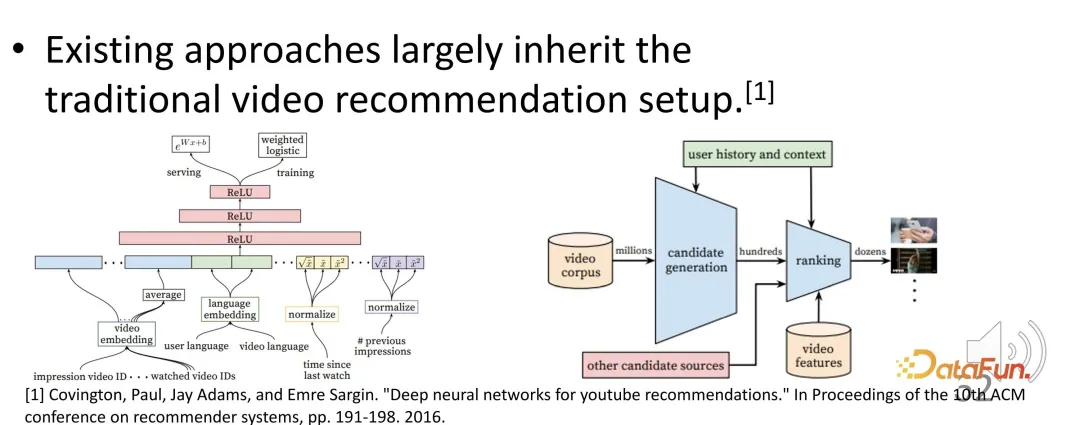
Wie bewertet man beispielsweise die Benutzerzufriedenheit und -aktivität in kurzen Videoempfehlungen? Was ist das Optimierungsziel? Gängige Optimierungsziele sind Wiedergabezeit oder Wiedergabefortschritt. Kurze Videos, bei denen schätzungsweise höhere Abschlussraten und Wiedergabezeiten erzielt werden, werden vom Empfehlungssystem möglicherweise höher eingestuft. Es kann auf Grundlage der Betrachtungszeit während des Trainings optimiert und auf Grundlage der geschätzten Betrachtungszeit während des Gottesdienstes sortiert werden. Es werden Videos mit einer längeren Betrachtungszeit empfohlen.
Ein Problem bei der Empfehlung von Kurzvideos besteht jedoch darin, dass eine längere Betrachtungszeit nicht unbedingt bedeutet, dass der Benutzer sehr an dem Kurzvideo interessiert ist, d. h. die Länge des Kurzvideos selbst ist eine sehr wichtige Abweichung. In Empfehlungssystemen, die die oben genannten Optimierungsziele (Sehdauer oder Sehfortschritt) nutzen, haben längere Videos einen natürlichen Vorteil. Das Empfehlen zu vieler langer Videos dieser Art entspricht möglicherweise nicht den Interessen des Benutzers. Aufgrund der Betriebskosten, die durch das Überspringen von Videos entstehen, ist die Bewertung durch tatsächliche Online-Tests oder Offline-Schulungen jedoch sehr hoch. Daher reicht es nicht aus, sich ausschließlich auf die Wiedergabezeit zu verlassen.
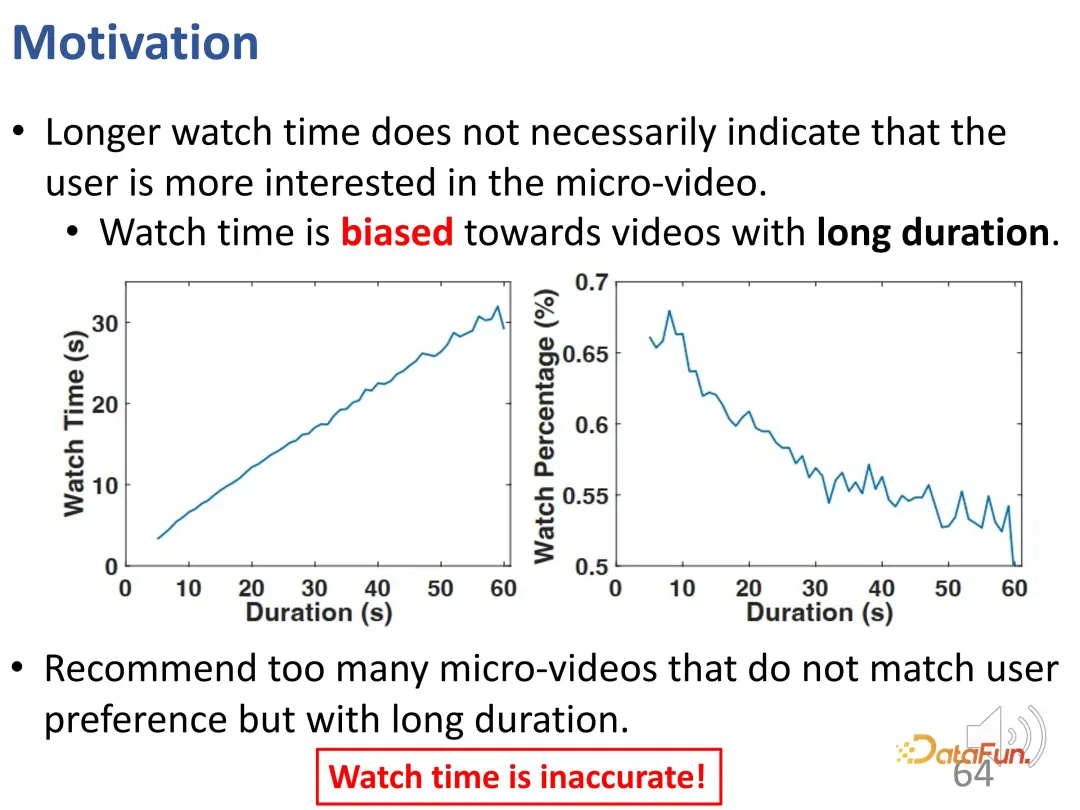
Wie Sie sehen können, gibt es in dem kurzen Video zwei Formen. Bei dem einen handelt es sich um längere Videos wie Vlogs, beim anderen um kürzere Unterhaltungsvideos. Nach der Analyse des realen Traffics haben wir herausgefunden, dass Nutzer, die lange Videos veröffentlichen, grundsätzlich mehr empfohlenen Traffic erhalten, und dieses Verhältnis ist sehr unterschiedlich. Die alleinige Nutzung der Wiedergabezeit zur Bewertung entspricht nicht nur den Interessen der Nutzer, sondern kann auch unfair sein.
Mit dieser Arbeit hoffen wir, zwei Probleme zu lösen:
- Wie man die Benutzerzufriedenheit besser und unvoreingenommen bewerten kann.
- Wie man dieses unvoreingenommene Nutzerinteresse lernt, um gute Empfehlungen zu geben.
Tatsächlich besteht die zentrale Herausforderung darin, dass kurze Videos unterschiedlicher Länge nicht direkt verglichen werden können. Da dieses Problem in verschiedenen Empfehlungssystemen natürlich und allgegenwärtig ist und die Strukturen verschiedener Empfehlungssysteme stark variieren, muss die entworfene Methode modellunabhängig sein.
Zunächst wurden mehrere repräsentative Methoden ausgewählt und anhand der Betrachtungsdauer ein simuliertes Training durchgeführt.

Sie können der Kurve entnehmen, dass die Dauerabweichung zunimmt: Im Vergleich zur Ground-Truth-Kurve liegt das Empfehlungsmodell bei den Vorhersageergebnissen für lange Videowiedergabezeiten deutlich höher. In Vorhersagemodellen ist eine Überempfehlung für lange Videos problematisch.
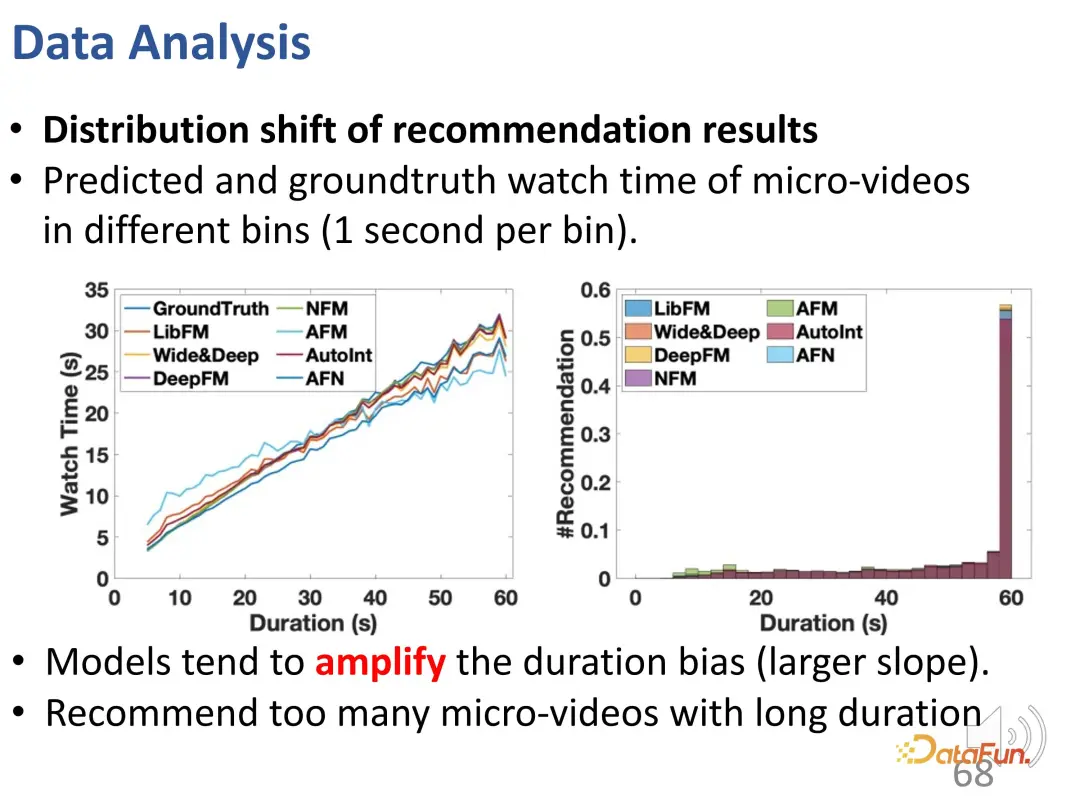
Darüber hinaus wurde auch festgestellt, dass es in den Empfehlungsergebnissen (#BC) viele ungenaue Empfehlungen gab.
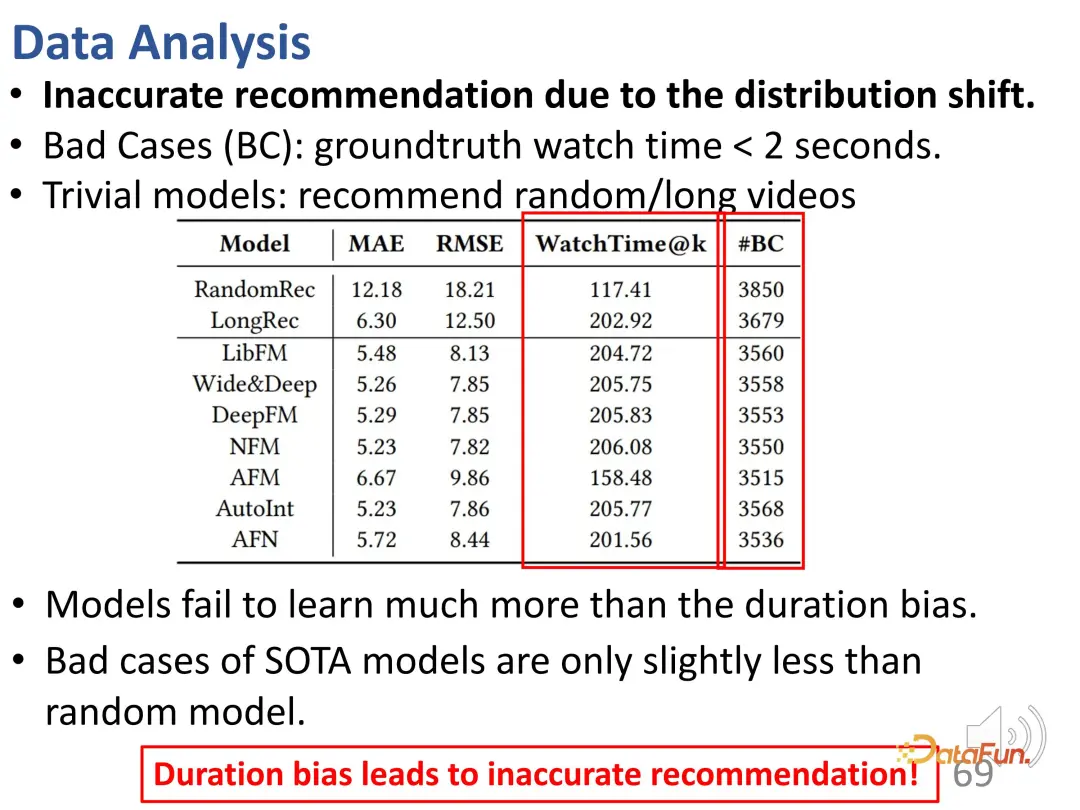
Wir können einige schlimme Fälle sehen, das heißt Videos, die weniger als 2 Sekunden angeschaut werden und von den Benutzern nicht gemocht werden. Aufgrund des Einflusses der Voreingenommenheit werden diese Videos jedoch fälschlicherweise empfohlen. Mit anderen Worten: Das Modell lernte nur den Unterschied in der Dauer der empfohlenen Videos und konnte im Grunde nur die Länge der Videos unterscheiden. Denn das gewünschte Vorhersageergebnis besteht darin, längere Videos zu empfehlen, um die Betrachtungszeit des Nutzers zu erhöhen. Daher wählt das Modell lange Videos anstelle von Videos aus, die dem Benutzer gefallen. Es ist ersichtlich, dass diese Modelle sogar die gleiche Anzahl schlechter Fälle aufweisen wie zufällige Empfehlungen, sodass diese Verzerrung zu sehr ungenauen Empfehlungen führt.
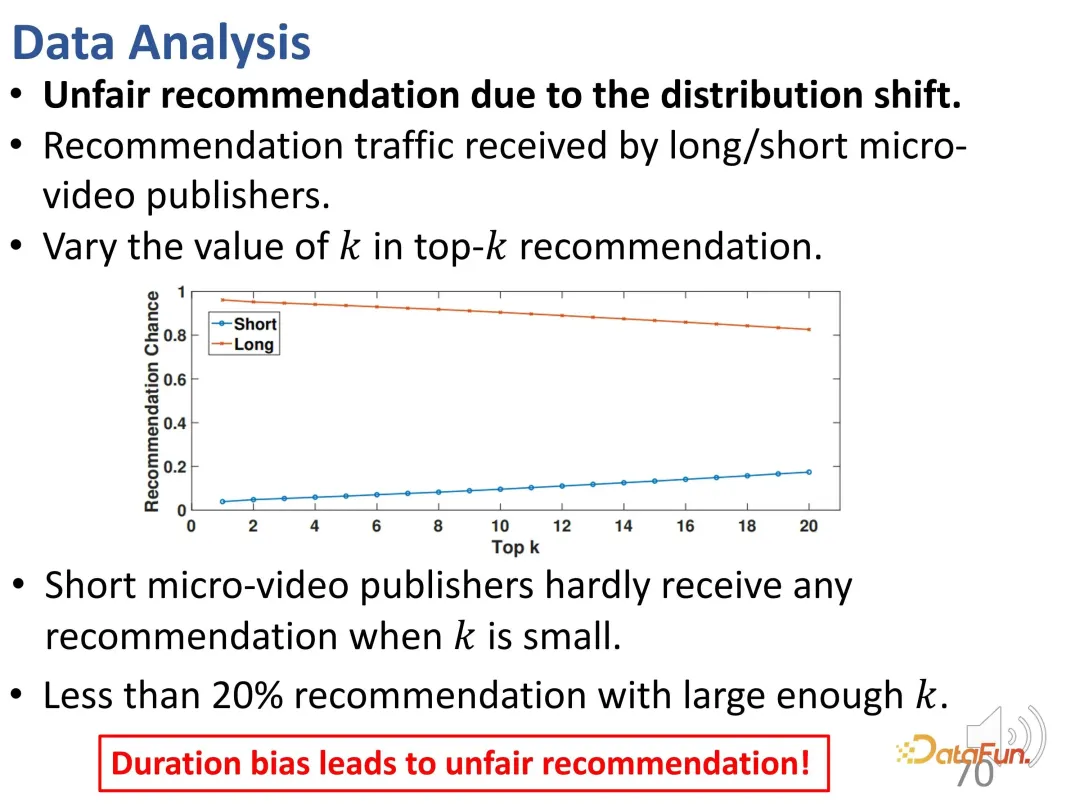
Außerdem besteht hier ein Problem der Ungerechtigkeit. Wenn der Kontroll-Top-K-Wert klein ist, ist es schwierig, kürzere Video-Publisher zu empfehlen; selbst wenn der K-Wert groß genug ist, beträgt der Anteil solcher Empfehlungen weniger als 20 %.
1. WTG-Indikator
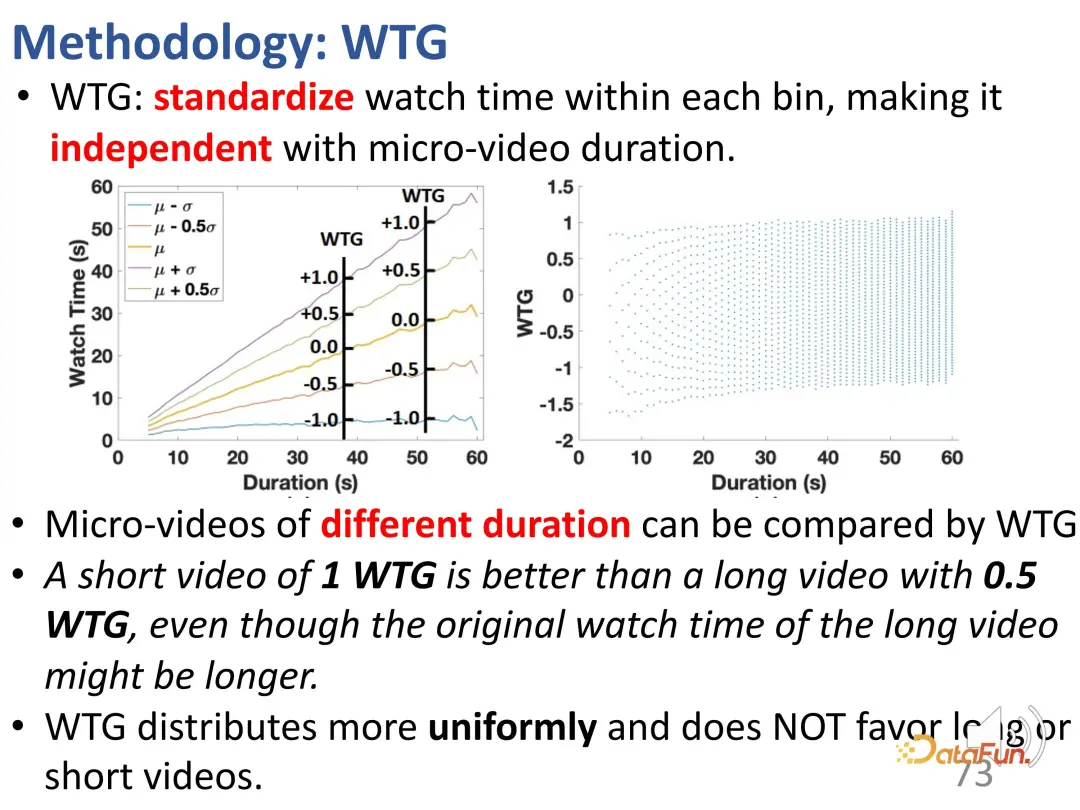
Um dieses Problem zu lösen, haben wir zunächst einen neuen Indikator namens WTG (Watch Time Gain) vorgeschlagen, der die Betrachtungszeit berücksichtigt, um eine unvoreingenommene Erzielung zu erreichen. Beispielsweise hat ein Benutzer ein 60-Sekunden-Video 50 Sekunden lang angesehen; ein anderes Video war ebenfalls 60 Sekunden lang, sah es sich jedoch nur 5 Sekunden lang an. Wenn Sie ein 60-Sekunden-Video kontrollieren, ist der Unterschied im Interesse zwischen den beiden Videos offensichtlich. Dies ist eine einfache, aber effektive Idee. Die Wiedergabedauer ist nur dann sinnvoll, wenn andere Videodaten eine ähnliche Dauer haben.
Teilen Sie zunächst alle Videos in gleichen Abständen in verschiedene Dauergruppen ein und vergleichen Sie dann die Interessenintensität des Benutzers in jeder Dauergruppe. In der Gruppe mit fester Dauer können die Interessen des Benutzers durch die Dauer dargestellt werden. Nach der Einführung von WTG wird WTG tatsächlich direkt verwendet, um die Intensität des Benutzerinteresses auszudrücken, ohne auf die ursprüngliche Dauer zu achten. Unter WTG-Bewertungen ist die Verteilung gleichmäßiger.

Basierend auf WTG wird die Bedeutung der Sortierposition weiter berücksichtigt. Da WTG nur einen Indikator (einen einzelnen Punkt) berücksichtigt, wird dieser kumulative Effekt zusätzlich berücksichtigt. Das heißt, bei der Berechnung des Index jedes Elements in der sortierten Liste muss auch die relative Position jedes Datenpunkts berücksichtigt werden. Diese Idee ähnelt NDCG. Daher wurde auf dieser Grundlage DCWTG definiert.

2. Empfohlene Methode zur Eliminierung von Verzerrungen
Wir haben zuvor Indikatoren definiert, die Benutzerinteressen unabhängig von der Dauer widerspiegeln können, nämlich WTG und NDWTG. Als nächstes entwerfen Sie eine Empfehlungsmethode, die Verzerrungen beseitigen kann, unabhängig vom spezifischen Modell ist und auf verschiedene Backbones anwendbar ist. Die Kernidee der DVR-Methode (Debiased Video Recommendation) besteht darin, dass im Empfehlungsmodell die dauerbezogenen Merkmale entfernt werden können, auch wenn die Eingabemerkmale komplex sind und möglicherweise dauerbezogene Informationen enthalten kann während des Lernprozesses verwendet werden. Wenn die Ausgabe des Modells diese Dauermerkmale ignoriert, kann sie als unvoreingenommen betrachtet werden, was bedeutet, dass das Modell dauerbezogene Merkmale herausfiltern kann, um unvoreingenommene Empfehlungen zu erhalten. Dies beinhaltet eine konfrontative Idee, die ein anderes Modell erfordert, um die Dauer basierend auf der Ausgabe des Empfehlungsmodells vorherzusagen. Wenn die Dauer nicht genau vorhergesagt werden kann, wird davon ausgegangen, dass die Ausgabe des vorherigen Modells keine Dauermerkmale enthält. Daher wird eine kontradiktorische Lernmethode verwendet, um dem Empfehlungsmodell eine Regressionsschicht hinzuzufügen, die die ursprüngliche Dauer basierend auf der vorhergesagten WTG vorhersagt. Wenn das Backbone-Modell tatsächlich unvoreingenommene Ergebnisse erzielen kann, ist die Regressionsschicht nicht in der Lage, die ursprüngliche Dauer erneut vorherzusagen und wiederherzustellen.
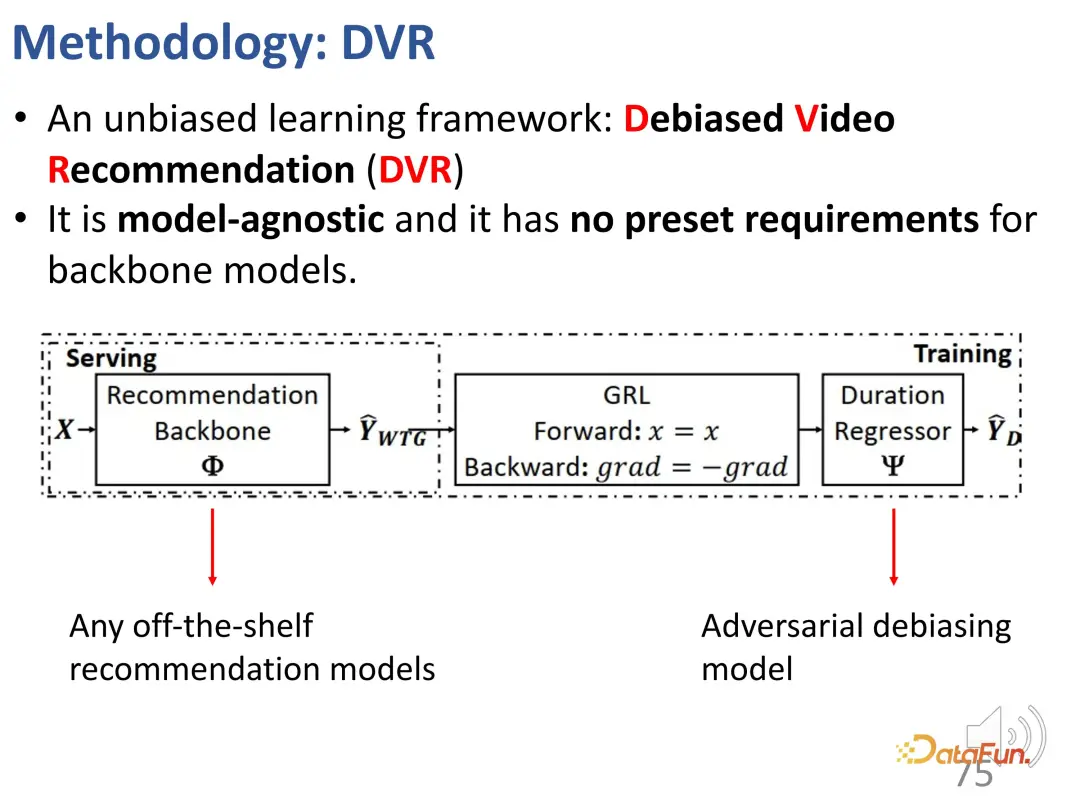

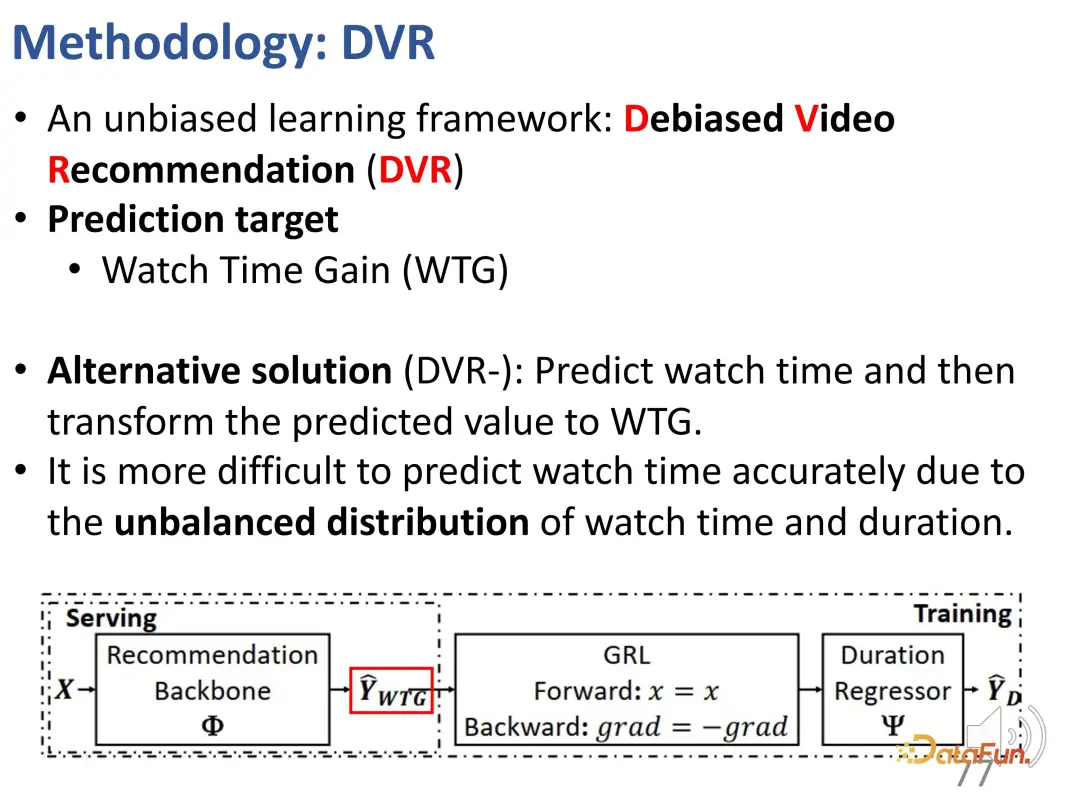

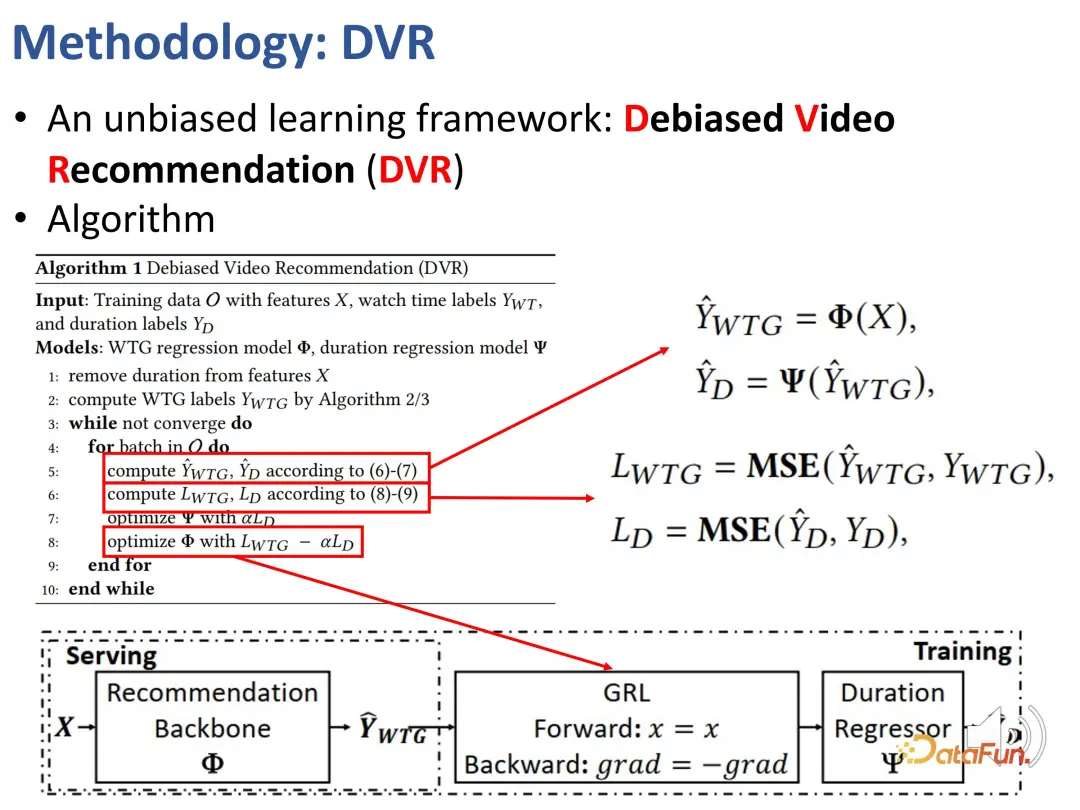
Das Obige sind die Details der Methode, die zur Implementierung von kontradiktorischem Lernen verwendet wird.
3. Experimentelle Ergebnisse
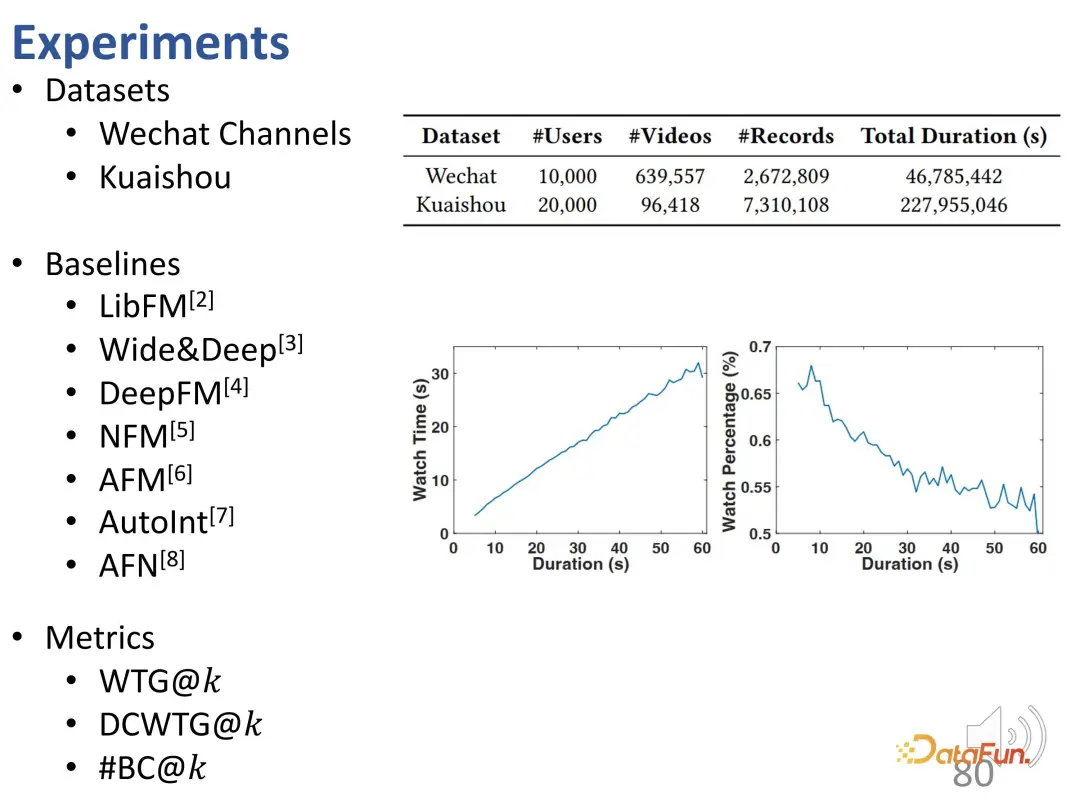
Experimente wurden mit zwei Datensätzen von WeChat und Kuaishou durchgeführt. Das erste ist WTG im Vergleich zur Wiedergabezeit. Es ist zu erkennen, dass die beiden Optimierungsziele separat verwendet und mit der Betrachtungsdauer in der Ground Truth verglichen werden. Nach der Verwendung von WTG als Ziel ist der Empfehlungseffekt des Modells sowohl bei kurzen als auch bei langen Videos besser und die WTG-Kurve liegt stabil über der Betrachtungszeitkurve.
Darüber hinaus führt die Verwendung von WTG als Ziel zu einem ausgeglicheneren Empfehlungsverkehr für lange und kurze Videos (der Empfehlungsanteil langer Videos ist im traditionellen Modell offensichtlich höher).

Die vorgeschlagene DVR-Methode ist für verschiedene Backbone-Modelle geeignet: 7 gängige Backbone-Modelle wurden getestet, und die Ergebnisse zeigten, dass die Leistung der Debiasing-Methode schlecht war, während DVR bei allen Backbone-Modellen und allen Indikatoren eine bessere Leistung erbrachte . Es hat eine gewisse Verbesserung gegeben.

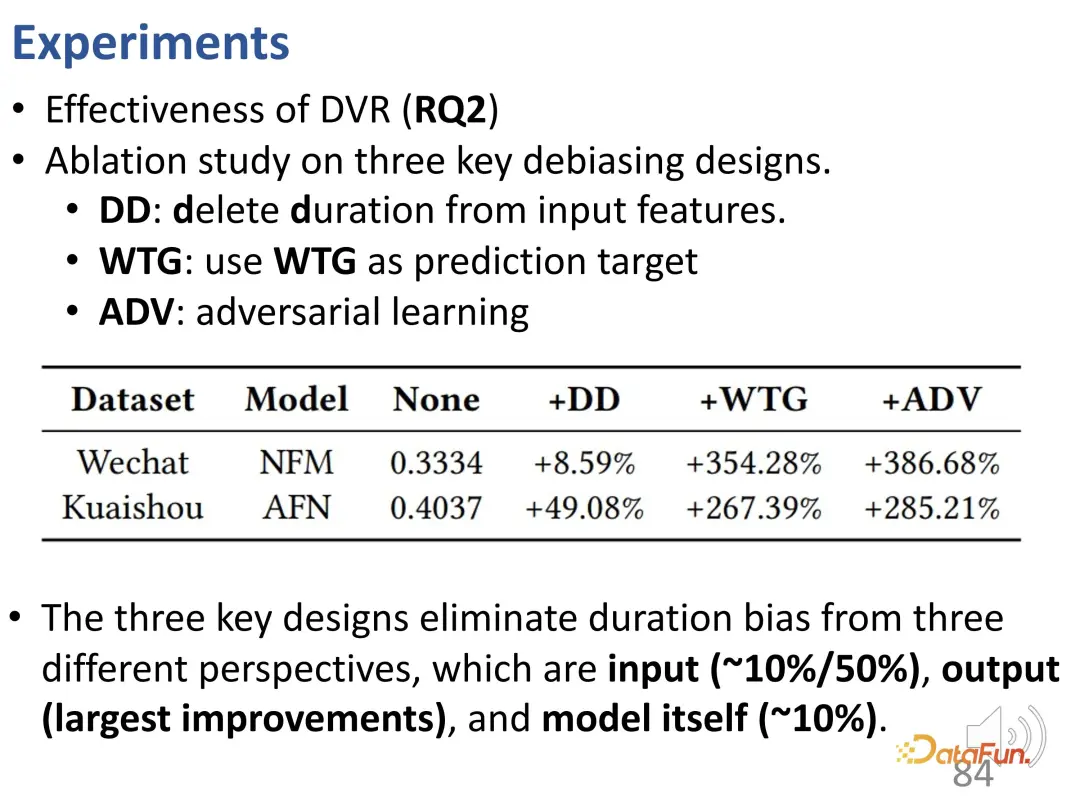
Außerdem wurden einige Ablationsexperimente durchgeführt. Wie im vorherigen Artikel erwähnt, besteht diese Methode aus drei Teilen des Designs, und diese drei Teile wurden jeweils entfernt. Die erste besteht darin, die Dauer als Eingabemerkmal zu entfernen, die zweite darin, WTG als Vorhersageziel zu entfernen und die dritte darin, die kontradiktorische Lernmethode zu entfernen. Sie sehen, dass das Entfernen jedes einzelnen Teils zu Leistungseinbußen führt. Daher sind alle drei Designs von entscheidender Bedeutung.
Um unsere Arbeit zusammenzufassen: Studieren Sie kurze Videoempfehlungen unter dem Gesichtspunkt der Reduzierung von Abweichungen und achten Sie auf Dauerabweichungen. Zunächst wird ein neuer Indikator vorgeschlagen: WTG. Es leistet gute Arbeit bei der Beseitigung von Verzerrungen im tatsächlichen Verhalten (Benutzerinteressen und -dauer). Zweitens wird eine allgemeine Methode vorgeschlagen, damit das Modell nicht mehr von der Videodauer beeinflusst wird und so unvoreingenommene Empfehlungen erstellt werden.

Fass diese Mitteilung abschließend zusammen. Verstehen Sie zunächst das Verschränkungslernen in Bezug auf Benutzerinteressen und Konformität. Als nächstes wird die Entflechtung von langfristigen und kurzfristigen Interessen im Hinblick auf eine sequentielle Verhaltensmodellierung untersucht. Abschließend wird eine Debiasing-Lernmethode vorgeschlagen, um das Problem der Optimierung der Betrachtungsdauer bei kurzen Videoempfehlungen zu lösen.
Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Vielen Dank an alle.
Verwandte Literatur:
[1] Causal Inference in Recommender Systems: A Survey and Future Directions, TOIS 2024
[2] Zheng et al , WWW 2021.
[3] Zheng et al. DVR: Micro-Video Recommendation Optimizing Watch-Time-Gain under Duration Bias, MM 2022
[4] Zheng et al. Interests for Recommendation, WWW 2022 .
Das obige ist der detaillierte Inhalt vonEmpfehlungssysteme basierend auf kausalen Schlussfolgerungen: Überprüfung und Aussichten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So verwenden Sie die Go-Sprache und Redis zur Implementierung eines Empfehlungssystems. Das Empfehlungssystem ist ein wichtiger Bestandteil der modernen Internetplattform. Es hilft Benutzern, interessante Informationen zu finden und zu erhalten. Die Go-Sprache und Redis sind zwei sehr beliebte Tools, die bei der Implementierung von Empfehlungssystemen eine wichtige Rolle spielen können. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache und Redis ein einfaches Empfehlungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. Redis ist eine Open-Source-In-Memory-Datenbank, die eine Speicherschnittstelle für Schlüssel-Wert-Paare bereitstellt und eine Vielzahl von Daten unterstützt
 In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Internet-Technologie werden Empfehlungssysteme als wichtige Technologie zur Informationsfilterung immer häufiger eingesetzt und beachtet. Bei der Implementierung von Empfehlungssystemalgorithmen ist Java als schnelle und zuverlässige Programmiersprache weit verbreitet. In diesem Artikel werden die in Java implementierten Empfehlungssystemalgorithmen und -anwendungen vorgestellt und der Schwerpunkt auf drei gängige Empfehlungssystemalgorithmen gelegt: benutzerbasierter kollaborativer Filteralgorithmus, artikelbasierter kollaborativer Filteralgorithmus und inhaltsbasierter Empfehlungsalgorithmus. Der benutzerbasierte kollaborative Filteralgorithmus basiert auf benutzerbasierter kollaborativer Filterung
 Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Mit der Popularität von Internetanwendungen ist die Microservice-Architektur zu einer beliebten Architekturmethode geworden. Unter anderem besteht der Schlüssel zur Microservice-Architektur darin, die Anwendung in verschiedene Dienste aufzuteilen und über RPC zu kommunizieren, um eine lose gekoppelte Service-Architektur zu erreichen. In diesem Artikel stellen wir vor, wie man mit go-micro ein Microservice-Empfehlungssystem basierend auf tatsächlichen Fällen erstellt. 1. Was ist ein Microservice-Empfehlungssystem? Ein Microservice-Empfehlungssystem ist ein Empfehlungssystem, das auf einer Microservice-Architektur basiert. Es integriert verschiedene Module in das Empfehlungssystem (z. B. Feature-Engineering, Klassifizierung).
 Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
1. Einführung in das Szenario Zunächst stellen wir das in diesem Artikel beschriebene Szenario vor – das Szenario „Gute Waren sind verfügbar“. Seine Position befindet sich im Vierquadratraster auf der Homepage von Taobao, die in eine One-Hop-Auswahlseite und eine Two-Hop-Akzeptanzseite unterteilt ist. Es gibt zwei Hauptformen von Akzeptanzseiten: eine ist die Bild- und Text-Akzeptanzseite und die andere ist die kurze Video-Akzeptanzseite. Das Ziel dieses Szenarios besteht hauptsächlich darin, den Benutzern zufriedenstellende Waren bereitzustellen und das Wachstum des GMV voranzutreiben, wodurch das Angebot an Experten weiter genutzt wird. 2. Was ist ein Beliebtheitsbias und warum befassen wir uns als nächstes mit dem Beliebtheitsbias? Was ist ein Beliebtheitsbias? Warum kommt es zu einem Beliebtheitsbias? 1. Was ist Popularitätsbias? Es gibt viele Pseudonyme, wie zum Beispiel Matthew-Effekt und Informationskokonraum. Intuitiv gesehen ist es ein Karneval hochexplosiver Produkte. Je beliebter das Produkt ist, desto einfacher ist es. Dies wird dazu führen
 Zusammenfassung der wichtigsten technischen Ideen und Methoden der kausalen Schlussfolgerung
Apr 12, 2023 am 08:10 AM
Zusammenfassung der wichtigsten technischen Ideen und Methoden der kausalen Schlussfolgerung
Apr 12, 2023 am 08:10 AM
Einleitung: Kausalinferenz ist ein wichtiger Zweig der Datenwissenschaft. Sie spielt eine wichtige Rolle bei der Produktiteration, Algorithmen- und Anreizstrategiebewertung im Internet und in der Industrie. Sie kombiniert Daten, Experimente oder statistische ökonometrische Modelle Leistungen sind die Grundlage für die Entscheidungsfindung. Der Kausalschluss ist jedoch keine einfache Angelegenheit. Erstens verwechseln Menschen im täglichen Leben oft Korrelation mit Kausalität. Korrelation bedeutet oft, dass zwei Variablen die Tendenz haben, gleichzeitig zuzunehmen oder zu sinken, aber Kausalität bedeutet, dass wir wissen wollen, was passiert, wenn wir eine Variable ändern, oder dass wir ein kontrafaktisches Ergebnis erwarten, wenn wir es in der Zeit getan haben Vergangenheit Wenn wir unterschiedliche Maßnahmen ergreifen, wird es in Zukunft Veränderungen geben? Die Schwierigkeit besteht jedoch darin, dass es sich häufig um kontrafaktische Daten handelt
 Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Cloud-Computing-Technologie werden Cloud-Such- und Empfehlungssysteme immer beliebter. Als Antwort auf diese Nachfrage bietet die Go-Sprache ebenfalls eine gute Lösung. In der Go-Sprache können wir die Funktionen zur gleichzeitigen Hochgeschwindigkeitsverarbeitung und die umfangreichen Standardbibliotheken nutzen, um ein effizientes Cloud-Such- und Empfehlungssystem zu implementieren. Im Folgenden wird vorgestellt, wie die Go-Sprache ein solches System implementiert. 1. Suche in der Cloud Zunächst müssen wir die Vorgehensweise und die Prinzipien der Suche verstehen. Die Suchposition bezieht sich auf die Suchmaschinen-Matching-Seiten basierend auf den vom Benutzer eingegebenen Schlüsselwörtern.
 Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
1. Problemhintergrund: Die Notwendigkeit und Bedeutung der Kaltstartmodellierung. Als Content-Plattform stellt Cloud Music täglich eine große Menge neuer Inhalte online. Obwohl die Menge an neuen Inhalten auf der Cloud-Musikplattform im Vergleich zu anderen Plattformen, wie etwa Kurzvideos, relativ gering ist, kann die tatsächliche Menge die Vorstellungskraft eines jeden bei weitem übersteigen. Gleichzeitig unterscheiden sich Musikinhalte deutlich von kurzen Videos, Nachrichten und Produktempfehlungen. Der Lebenszyklus von Musik erstreckt sich über extrem lange Zeiträume, oft gemessen in Jahren. Manche Songs können explodieren, nachdem sie monate- oder jahrelang inaktiv waren, und klassische Songs können auch nach mehr als zehn Jahren noch eine starke Vitalität haben. Daher ist es für das Empfehlungssystem von Musikplattformen wichtiger, unpopuläre und qualitativ hochwertige Long-Tail-Inhalte zu entdecken und sie den richtigen Nutzern zu empfehlen, als andere Kategorien zu empfehlen.
 Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
1. Hintergrund der Ursache-Wirkungs-Korrektur 1. Abweichungen treten im Empfehlungssystem auf. Das Empfehlungsmodell wird durch das Sammeln von Daten trainiert, um Benutzern geeignete Elemente zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen. 2. Häufige Vorurteile Es gibt drei Haupttypen häufiger Vorurteile in Empfehlungsmarketingsystemen: Selektive Voreingenommenheit: Sie ist auf die Herkunft des Benutzers zurückzuführen
