

Wie baut man ein KI-orientiertes Data-Governance-System auf?


In den letzten Jahren haben sich mit dem Aufkommen neuer Technologiemodelle, der Aufwertung des Werts von Anwendungsszenarien in verschiedenen Branchen und der Verbesserung der Produkteffekte aufgrund der Ansammlung massiver Daten die Anwendungen der künstlichen Intelligenz vom Konsum ausgeweitet , das Internet und andere Bereiche bis hin zur Fertigung, Energie und Elektrizität und anderen traditionellen Industrien. Der Reifegrad der Technologie und Anwendung künstlicher Intelligenz in Unternehmen verschiedener Branchen in den Hauptbereichen wirtschaftlicher Produktionsaktivitäten wie Design, Beschaffung, Produktion, Management und Vertrieb verbessert sich ständig und beschleunigt die Implementierung und Abdeckung künstlicher Intelligenz in allen Bereichen schrittweise Integration in das Hauptgeschäft, um den Industriestatus zu verbessern oder die Betriebseffizienz zu optimieren und die eigenen Vorteile weiter auszubauen.
Die groß angelegte Implementierung innovativer Anwendungen der Technologie der künstlichen Intelligenz hat die starke Entwicklung des Big-Data-Intelligence-Marktes gefördert und auch den zugrunde liegenden Data-Governance-Diensten Marktvitalität verliehen.
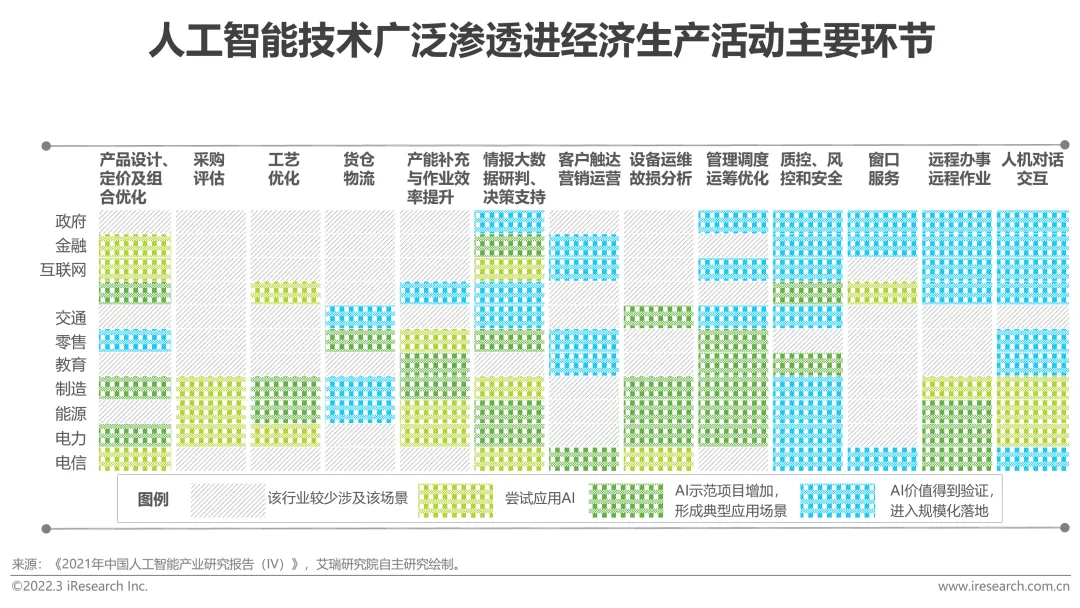
Mit der Entwicklung von Big Data, Cloud Computing und Algorithmen hat die Begeisterung für künstliche Intelligenz vor einigen Jahren bis heute angehalten und ist in vielen Branchen und Bereichen weit verbreitet und hat sich zu einem entwickelt aktuelle fortlaufende Technologie Eine führende Technologie der Revolution. Und wie kann künstliche Intelligenz im boomenden Bereich der Datenverwaltung fehlen? Datenverwaltung und künstliche Intelligenz sind zwei scheinbar unzusammenhängende Wörter. Welche Geschichte wird sich ergeben, wenn man sie zusammennimmt?
1. Data Governance legt den Grundstein für künstliche Intelligenz
Big Data ist die kontinuierliche Ansammlung, Bereinigung, Konvertierung, Klassifizierung usw. von Daten, während Data Governance ein standardisierteres Verwaltungsmodell für die Darstellung großer Datenmengen bietet Daten . Da die meisten aktuellen Formen der künstlichen Intelligenz eine große Menge an Datenberechnungen erfordern, sind sie untrennbar mit der Unterstützung von Big Data und Data Governance verbunden. Künstliche Intelligenz muss sich auf Big-Data-Plattformen und -Technologien stützen, um die Entwicklung des Deep Learning zu vollenden.

1. Data Governance liefert hochwertige Daten für künstliche Intelligenz
Der Großteil der künstlichen Intelligenz ist in zwei Bereiche unterteilt: Training und Vorhersage. Die Wirkung maschineller Trainingsalgorithmen hängt von der Qualität der Eingabedaten ab. Wenn die Eingabedaten verzerrt sind, ist auch der Ausgabealgorithmus verzerrt, was direkt zur Unbrauchbarkeit der erhaltenen Ergebnisse führen kann. Data Governance spielt eine wichtige Rolle bei der Verbesserung der Datenqualität. Durch die Klärung der Anforderungen an die Datenqualität, die Festlegung von Regeln zur Datenqualitätsprüfung, die Formulierung von Plänen zur Verbesserung der Datenqualität, die Entwicklung und Implementierung von Tools für das Datenqualitätsmanagement sowie die Überwachung der Betriebsabläufe und Leistung des Datenqualitätsmanagements können Unternehmen saubere und klar strukturierte Daten erhalten und vertrauenswürdige Daten bereitstellen Input für Technologien der künstlichen Intelligenz wie Deep Learning. 2. Data Governance sorgt für Datenschutz bei künstlicher Intelligenz Persönliche Daten müssen geschützt werden. Der Missbrauch dieser Daten kann zu enormen Sachschäden oder sogar zu Personenschäden führen. Der sogenannte Datenschutz ist eigentlich der Schutz privater Daten. Letztendlich handelt es sich um den Schutz der Privatsphäre der Datennutzer. Data-Governance-Tools entwerfen viele Aspekte des Schutzes privater Daten auf technischer Ebene und bieten Datenfuzzifizierung, Datendesensibilisierung und Datenverschlüsselung, die den Grundstein für den Schutz personenbezogener Unternehmensdaten legen und so die Datenkonformität für Anwendungen der künstlichen Intelligenz erreichen können. 2. Künstliche Intelligenz verbessert den Intelligenzgrad der Datenverwaltung Die Datenerfassung erfolgt in der Regel durch die Erstellung eines Suchindex für unstrukturierte Daten. Künstliche Intelligenztechnologien wie Spracherkennung, Bilderkennung und Textanalyse können dabei helfen, den Aufbau des anfänglichen Geschäftsvokabulars von Metadaten zu realisieren und zu einem Ressourcenpool für die Extraktion verschiedener wertvoller unstrukturierter Metadaten zu werden.
2. Datenstandardmanagement

In der frühen Phase der Implementierung von Datenstandards ist es notwendig, eine gründliche Untersuchung der Datenbankfelder des bestehenden Systems durchzuführen und gemeinsame und wiederverwendete Geschäftsfelder zu identifizieren die Grundlage für die Festlegung von Datenstandards. Wenn alles manuell erledigt wird, ist die Koordination einer großen Anzahl von Mitarbeitern aus verschiedenen Unternehmensabteilungen erforderlich, was einen enormen Arbeitsaufwand mit sich bringt und fehleranfällig ist. Mit Hilfe von maschinellem Lernen und Technologie zur Verarbeitung natürlicher Sprache können hochfrequente Wurzeln schnell anhand von Branchennamen aussortiert werden, und Arbeiten, die möglicherweise Monate dauern, können in wenigen Tagen abgeschlossen werden.
Ein weiterer wichtiger Aspekt des Datenstandardmanagements ist die Abbildung von Standards und Metadaten. In vielen Geschäftssystemen ist die Zuordnung von Datenstandards zu den Metadaten von Geschäftssystemen oft ein Albtraum für Implementierungsingenieure, und wenn man nicht vorsichtig ist, kann es leicht zu Fehlern kommen. Mit der Technologie der künstlichen Intelligenz können wir eine natürliche Sprachverarbeitung für Geschäftsfeldnamen durchführen, Wörter genau segmentieren und Datenstandards und Metadaten basierend auf der Stammähnlichkeit automatisch zuordnen.
3. Datenqualitätsmanagement
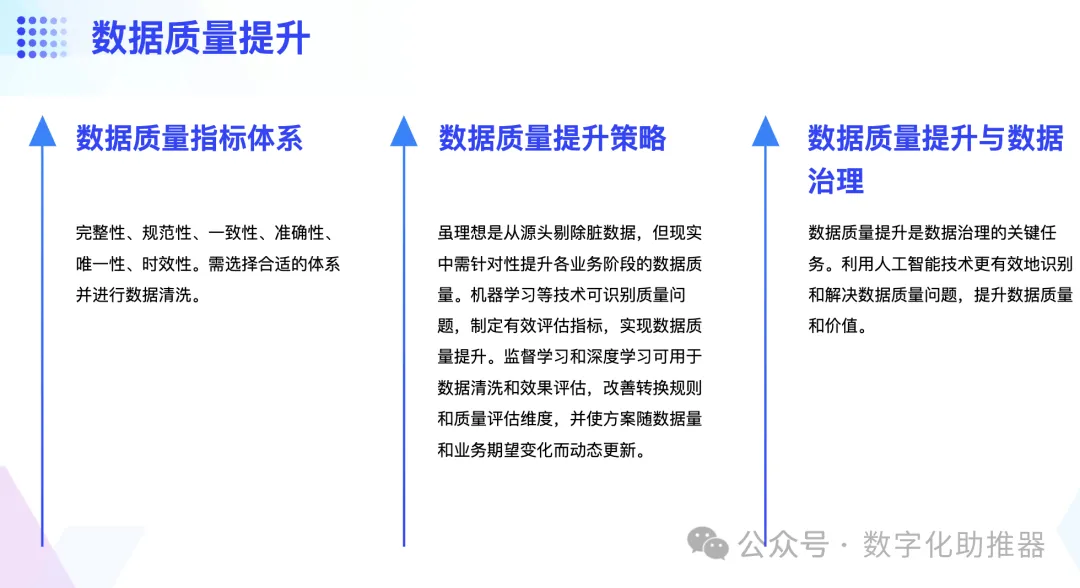
Datenqualität ist die Grundlage für die effiziente Nutzung von Daten. Das Indexsystem zur Messung der Datenqualität umfasst Vollständigkeit, Standardisierung, Konsistenz, Genauigkeit, Einzigartigkeit und Aktualität. Vor der Umsetzung des Plans zur Verbesserung der Datenqualität muss ein geeignetes Datenqualitätsindikatorsystem basierend auf unterschiedlichen Geschäftsregeln und Geschäftserwartungen ausgewählt und die Daten bereinigt werden.
Im Allgemeinen besteht das ideale Modell zur Verbesserung der Datenqualität darin, schmutzige Daten aus der Datenquelle zu entfernen, aber das ist in der Realität nicht machbar. Daher sollte entsprechend den Geschäftserwartungen die Datenqualität in jeder Geschäftsphase gezielt verbessert werden. Maschinelles Lernen (z. B. Klassifizierungslernen, Clustering, Regression usw.) kann vorhandene Qualitätsprobleme extrahieren und identifizieren, wodurch wirksame Indikatoren zur Datenqualitätsbewertung formuliert und die Verbesserung der Datenqualität unter diesem Indikator maximiert werden. Gleichzeitig ermöglichen überwachtes Lernen und Deep Learning auch die Bewertung von Datenbereinigungs- und Datenqualitätseffekten, wodurch Konvertierungsregeln und Datenqualitätsbewertungsdimensionen verbessert und Pläne zur Datenqualitätsverbesserung dynamisch aktualisiert werden, wenn sich Datenvolumen und Geschäftserwartungen allmählich ändern.
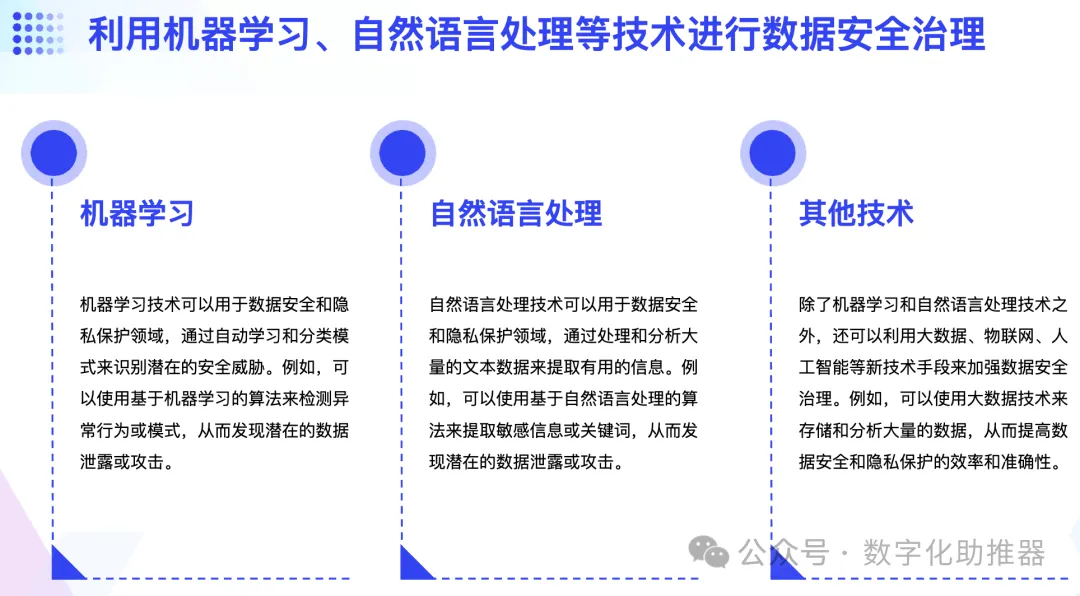
4. Datensicherheit

Datensicherheit bezieht sich auf den Prozess oder Zustand des Schutzes von Informationen oder Informationssystemen vor unbefugtem Zugriff, unbefugter Nutzung, Beschädigung, Änderung und Zerstörung. Künstliche Intelligenz-Technologie kann sensible Daten klassifizieren und klassifizieren. Durch die Anwendung von maschinellem Lernen, Verarbeitung natürlicher Sprache und Klassifizierungstechnologie für Textcluster können Daten basierend auf dem Inhalt in Echtzeit genau klassifiziert und klassifiziert werden. Datenklassifizierung und -klassifizierung sind das zentrale Glied der Datensicherheitsverwaltung. Beispielsweise hat der Einsatz von Datenklassifizierungs-Engines die Sicherheit in Bereichen wie E-Mail-Inhaltsfilterung, Verwaltung vertraulicher Dateien, Geheimdienstanalyse, Betrugsbekämpfung und Verhinderung von Datenlecks erheblich verbessert.
5. Stammdatenmanagement

Stammdaten beziehen sich auf die Daten der Kerngeschäftseinheiten des Unternehmens, auch Golden Data genannt, die über die gesamte Wertschöpfungskette hinweg wiederholt, geteilt und angewendet werden Bei mehreren Geschäftsprozessen bilden die zwischen jeder Geschäftsabteilung und jedem System gemeinsam genutzten Basisdaten die Grundlage für die Informationsinteraktion zwischen jeder Geschäftsanwendung und jedem System. Im Prozess der Stammdatenverwaltung können Unternehmen jedoch mit Problemen konfrontiert werden, beispielsweise mit der Frage, wie Stammdaten aus einer großen Anzahl von Datenelementen identifiziert werden können und wie einheitliche Stammdatenstandards festgelegt werden können.
Die Ermittlung der Stammdaten hängt vom Verständnis des Unternehmens für die Geschäftsanforderungen und der Definition entsprechender „goldener Daten“ ab. Im Allgemeinen verfügt jeder Stammdaten-Fachbereich über ein eigenes Aufzeichnungssystem und ist auf verschiedene Geschäftssysteme verteilt. Technologien im Zusammenhang mit künstlicher Intelligenz können uns dabei helfen, häufig auftretende oder fließende Daten aus allen Daten herauszufiltern, gleichzeitig schnell die zuverlässigen und vertrauenswürdigen Datenquellen von Stammdaten zu ermitteln und eine vollständige Stammdatenansicht zu erstellen.
6. Künstliche Intelligenz hilft beim Duplizieren von Daten, um Daten automatisch abzugleichen und zusammenzuführen

Eine der Herausforderungen beim digitalen Drama-Management besteht darin, dieselben Datenelemente oder doppelte Datenelemente in zahlreichen Systemen des Unternehmens abzugleichen und zusammenzuführen. Eine Möglichkeit, diese Herausforderung zu lösen, besteht darin, Datenabgleichsregeln zu erstellen, einschließlich der Abgleichsakzeptanz bei unterschiedlicher Konfidenz Ebenen. Einige Übereinstimmungen erfordern ein sehr hohes Maß an Vertrauen und können auf einem genauen Datenabgleich über mehrere Felder hinweg basieren. Einige Übereinstimmungen können einfach aufgrund widersprüchlicher Datenwerte mit einem geringeren Maß an Vertrauen erzielt werden. Maschinelles Lernen und die Verarbeitung natürlicher Sprache können dabei helfen, Abgleichsregeln für die Identifizierung doppelter Daten festzulegen. Nach der Identifizierung von Stammdaten mit doppelten Feldern wird keine automatische Zusammenführung durchgeführt, und Datensätze, die sich auf die Stammdaten beziehen, können ermittelt und Querverweisbeziehungen hergestellt werden. 3. Intelligentisierung der Datenverwaltungsplattform Unter vollständiger Berücksichtigung der hohen Komplexität der Datenverwaltung integriert die Datenverwaltungsplattform weiterhin neue KI-Technologien und strebt danach, den Implementierungsprozess der Datenverwaltung durch intelligentes Management zu vereinfachen, technisches Personal erheblich zu entlasten und Unternehmen dabei zu helfen, eine effizientere Datenverwaltung zu erreichen und fernzuhalten vom „Datenschwarzen Loch“.
1. Intelligenter Metadatendienst. 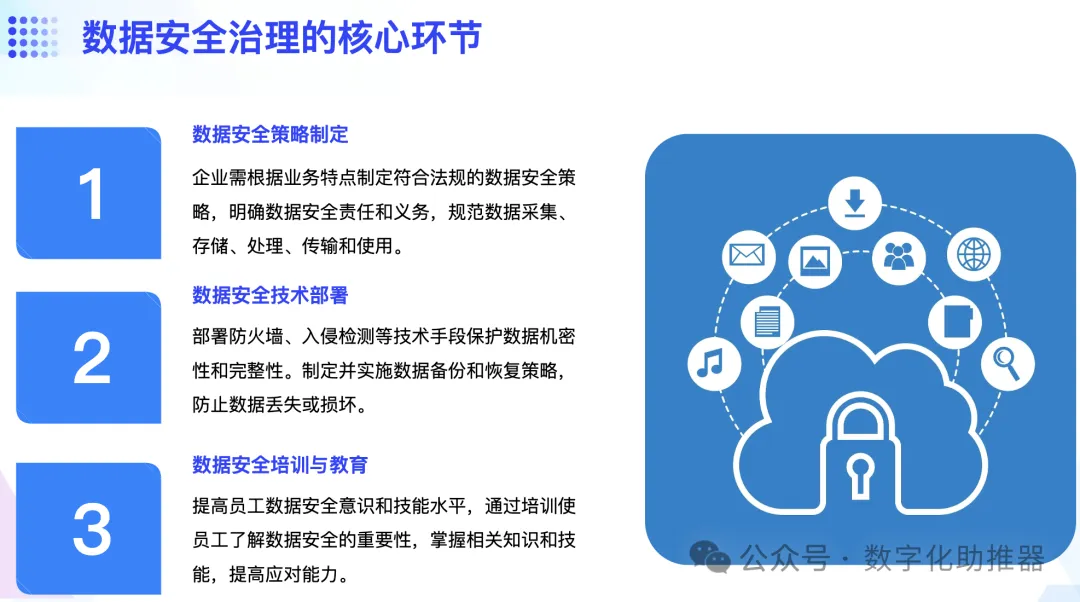 Die Ruizhi-Plattform unterstützt die vollautomatische Metadatenerfassung und -zuordnung, realisiert die intelligente Anwendung von Metamodellen und bietet grafische Metadatenanalyseansichten.
Die Ruizhi-Plattform unterstützt die vollautomatische Metadatenerfassung und -zuordnung, realisiert die intelligente Anwendung von Metamodellen und bietet grafische Metadatenanalyseansichten.
2. Intelligente Erkundung der Datenqualität.
 Die Ruizhi-Plattform verfügt über integrierte mathematisch-statistische Algorithmen und gebundene Algorithmen für maschinelles Lernen, um die Datenqualität automatisch zu erkennen und intelligente Reparaturen zu unterstützen.
Die Ruizhi-Plattform verfügt über integrierte mathematisch-statistische Algorithmen und gebundene Algorithmen für maschinelles Lernen, um die Datenqualität automatisch zu erkennen und intelligente Reparaturen zu unterstützen.
3. Intelligente Konstruktion von Datenstandards. Die Ruizhi-Plattform unterstützt die intelligente Kartierung und Markierung, die Bildung von Datenstandards und die wechselseitige Auswertung von Geschäftsdaten.
4. Intelligente Identifizierung von Stammdaten. Die Ruizhi-Plattform identifiziert Stammdaten automatisch, hilft beim automatischen Abgleich und Zusammenführen doppelter Daten und erstellt eine vollständige Stammdatenansicht.
Mit der rasanten Entwicklung der beiden Bereiche Data Governance und künstliche Intelligenz wird die Integration der beiden mehr Szenarien und Geschäftsmodelle mit sich bringen. 4. Branchenintegration von Daten-Governance + KI Die Vorteile der Optimierung von Datenressourcen bestimmen maßgeblich den Implementierungseffekt von KI-Anwendungen. Um die qualitativ hochwertige Implementierung von KI-Anwendungen voranzutreiben, ist daher die Durchführung gezielter Data-Governance-Arbeiten der erste und notwendige Schritt. Das traditionelle Daten-Governance-System, das das Unternehmen selbst aufgebaut hat, konzentriert sich derzeit auf die Optimierung der Governance strukturierter Daten. Es ist immer noch schwierig, die Anforderungen von KI-Anwendungen an Daten in den Dimensionen Datenqualität, Datenfeldreichtum und Daten zu erfüllen Verteilung und Daten in Echtzeit. Hohe Qualitätsanforderungen. Um die qualitativ hochwertige Implementierung von KI-Anwendungen sicherzustellen, Unternehmen müssen weiterhin eine sekundäre Datenverwaltung für Anwendungen der künstlichen Intelligenz durchführen.
Data Governance für künstliche Intelligenz ist ein „Upgrade“ des traditionellen Data Governance-Systems, das durch die Implementierung von KI-Anwendungen gesteuert wird.
Aus Sicht des Datenmanagements wird sich das Datenverwaltungssystem für künstliche Intelligenz weiterhin an die Einrichtung von Metadatenverwaltung, Datenbeständeverwaltung und Stammdatenverwaltung anpassen, die auf dem strukturierten Datenfluss, den Anforderungen der Datenbeständeverwaltung und der Datensicherheit basieren Anforderungen usw., Datenlebenszyklusmanagement und Datensicherheits-Privatsphärenmanagement sowie andere Komponentenmodule. Im Data-Governance-Prozess wird mehr Wert auf die unterste Ebene gelegt, um eine Datenfusion aus mehreren Quellen, die Häufigkeit der Datenerfassung, die Festlegung von Datenstandards und das Datenqualitätsmanagement zu erreichen, um den von der KI geforderten Umfang, die Qualität und die Aktualität der Daten zu erfüllen Modelle und erfüllen die Datenanforderungen von KI-Anwendungen. Optimieren Sie als Kern den Systemaufbau entsprechender Module.
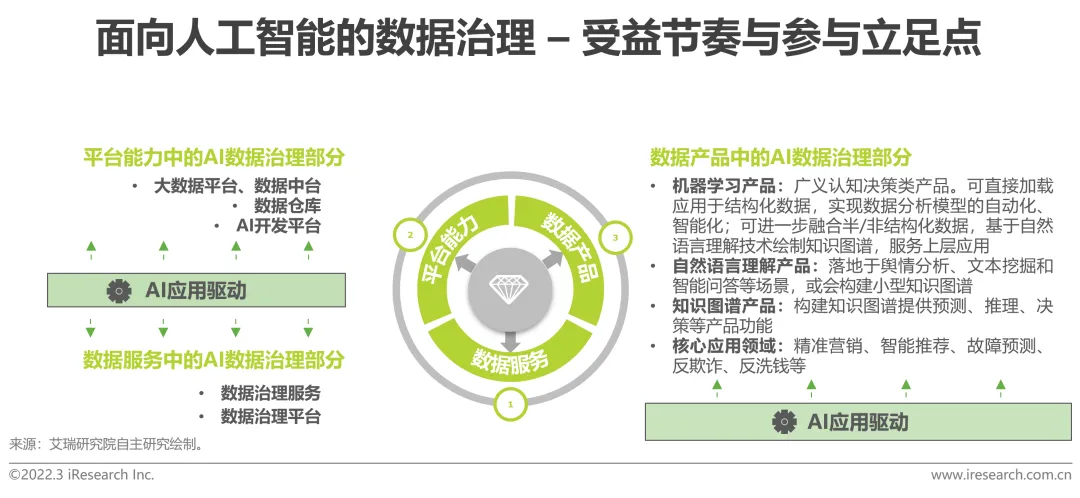
Der KI-Anwendungstreiber ist zum zentralen Standbein von auf künstlicher Intelligenz orientierten Data-Governance-Diensten geworden.
Auf künstlicher Intelligenz orientierte Data-Governance-Dienste sind häufig in drei Arten von Beschaffungsformen enthalten: Datendienste, Plattformfunktionen und Datenprodukte. Die erste Kategorie, Datendienste, erscheint in Form separater Daten-Governance-Produkte; die zweite Kategorie, Datenplattform, umfasst hauptsächlich Big-Data-Plattform, Data-Middle-Plattform, Data-Warehouse und KI-Fähigkeitsplattform und die dritte Kategorie, Datenprodukte; Umfang Datenprodukte, die auf die Anwendung von KI-Algorithmen beschränkt sind, können in drei Arten von KI-Produkten unterteilt werden: Produkte für maschinelles Lernen, Produkte zum Verständnis natürlicher Sprache und Wissensgraphen.
Heutzutage ist die Nachfrage nach KI-Produkten groß, und die KI-Entwicklungsplattform hat sukzessive die groß angelegte Implementierung von KI-Produkten vorangetrieben, und die Wirkung der KI-Datenverwaltung ist eng damit verbunden Liefereffekt des endgültigen Plattformprodukts.
Im Allgemeinen kann die Anwendung modernster Technologie die Datenverwaltung effizienter, automatisierter und intelligenter machen und gleichzeitig Daten skalierbarer, nachvollziehbarer, nachvollziehbarer und vertrauenswürdiger machen, was zur Zukunft des Datenmanagements geworden ist einzige Möglichkeit, sich zu entwickeln.
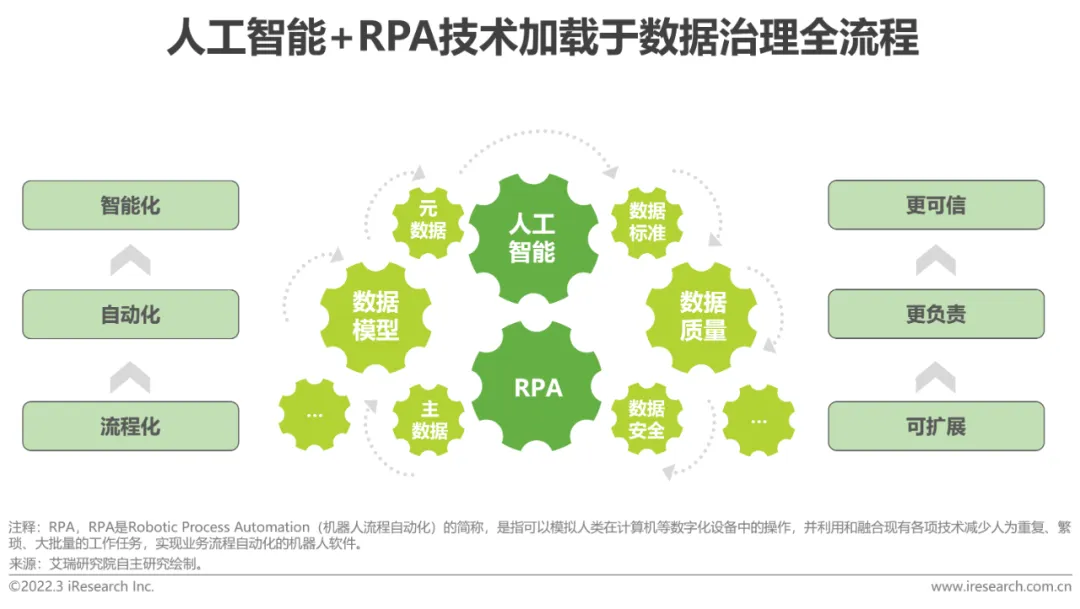
Schaffen Sie einen positiven Kreislauf des Systems „Governance + KI“
Zusammenhängend und voneinander abhängig, fördern Sie gemeinsam die interne und externe Entwicklung von Anwendungen für künstliche Intelligenz Intelligenz Der Einsatz maschineller Lerntechnologie zur Automatisierung und Intelligenz des Datenverwaltungsprozesses kann die Effizienz der Datenverwaltung erheblich verbessern. Gleichzeitig kann der Anwendungswert der damit verbundenen unstrukturierten Daten auf der Grundlage natürlicher Sprachverständnisse und Wissensdiagramme ermittelt und traditionelle Probleme gelöst werden Datenqualitätsmanagement und eine effizientere Governance. Die resultierenden Daten entsprechen besser den Anforderungen von KI-Anwendungen und fördern die Implementierung von KI-Modellen sowohl hinsichtlich der Effizienz als auch der Qualität.
Gleichzeitig wird die deutliche Optimierung des Implementierungseffekts von KI-Anwendungen auch mehr Vertrauen in die intelligente Transformation von Unternehmen schaffen und es ihnen ermöglichen, die Budgetinvestitionen in entsprechende KI-Projekte zu erhöhen und den Aufbau relevanter Governance weiter voranzutreiben Systeme und schaffen einen „tugendhaften Kreislauf aus „Governance + KI“

Das obige ist der detaillierte Inhalt vonWie baut man ein KI-orientiertes Data-Governance-System auf?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
 Iyo One: Teils Kopfhörer, teils Audiocomputer
Aug 08, 2024 am 01:03 AM
Iyo One: Teils Kopfhörer, teils Audiocomputer
Aug 08, 2024 am 01:03 AM
Konzentration ist zu jeder Zeit eine Tugend. Autor |. Herausgeber Tang Yitao |. Jing Yu Das Wiederaufleben der künstlichen Intelligenz hat zu einer neuen Welle von Hardware-Innovationen geführt. Der beliebteste AIPin hat beispiellose negative Bewertungen erhalten. Marques Brownlee (MKBHD) bezeichnete es als das schlechteste Produkt, das er jemals rezensiert habe; David Pierce, Herausgeber von The Verge, sagte, er würde niemandem empfehlen, dieses Gerät zu kaufen. Sein Konkurrent, der RabbitR1, ist nicht viel besser. Der größte Zweifel an diesem KI-Gerät besteht darin, dass es sich offensichtlich nur um eine App handelt, Rabbit jedoch eine 200-Dollar-Hardware gebaut hat. Viele Menschen sehen KI-Hardware-Innovationen als Chance, das Smartphone-Zeitalter zu untergraben und sich ihm zu widmen.
 „Vater des maschinellen Lernens' Mitchell schreibt: Wie KI die wissenschaftliche Entwicklung beschleunigt und wie die Vereinigten Staaten Chancen nutzen
Jul 29, 2024 pm 08:23 PM
„Vater des maschinellen Lernens' Mitchell schreibt: Wie KI die wissenschaftliche Entwicklung beschleunigt und wie die Vereinigten Staaten Chancen nutzen
Jul 29, 2024 pm 08:23 PM
Herausgeber |. ScienceAI Kürzlich hat Tom M. Mitchell, Professor an der Carnegie Mellon University und bekannt als „Vater des maschinellen Lernens“, ein neues Whitepaper zu KI für die Wissenschaft geschrieben, das sich mit der Frage „Wie beschleunigt künstliche Intelligenz die wissenschaftliche Entwicklung?“ befasst Helft die US-Regierung, dieses Ziel zu erreichen? ScienceAI hat den vollständigen Text des Original-Whitepapers zusammengestellt, ohne seine ursprüngliche Bedeutung zu ändern. Der Inhalt ist wie folgt. Der Bereich der künstlichen Intelligenz hat in jüngster Zeit erhebliche Fortschritte gemacht, einschließlich groß angelegter Sprachmodelle wie GPT, Claude und Gemini, was die Möglichkeit erhöht, dass sich die sehr positiven Auswirkungen der künstlichen Intelligenz möglicherweise erheblich beschleunigen
 Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Mit einer einzigen Anwendung ist es unmöglich, XML -zu -PDF -Konvertierung direkt auf Ihrem Telefon zu vervollständigen. Es ist erforderlich, Cloud -Dienste zu verwenden, die in zwei Schritten erreicht werden können: 1. XML in PDF in der Cloud, 2. Zugriff auf die konvertierte PDF -Datei auf dem Mobiltelefon konvertieren oder herunterladen.
