

Tokenisierung in einem Artikel verstehen!

Sprachmodelle basieren auf Text, der normalerweise in Form von Zeichenfolgen vorliegt. Die Eingabe in das Modell kann jedoch nur aus Zahlen bestehen, sodass der Text in eine numerische Form umgewandelt werden muss.
Die Tokenisierung ist eine grundlegende Aufgabe der Verarbeitung natürlicher Sprache. Sie kann eine fortlaufende Textsequenz (z. B. Sätze, Absätze usw.) nach bestimmten Kriterien in eine Zeichenfolge (z. B. Wörter, Phrasen, Zeichen, Satzzeichen usw.) unterteilen Unter ihnen wird die Einheit als Token oder Wort bezeichnet.
Gemäß dem in der Abbildung unten gezeigten spezifischen Prozess teilen Sie zunächst die Textsätze in Einheiten auf, digitalisieren Sie dann die einzelnen Elemente (bilden Sie sie in Vektoren ab), geben Sie diese Vektoren dann zur Codierung in das Modell ein und geben Sie sie schließlich an nachgelagerte Aufgaben aus um ein weiteres Endergebnis zu erzielen.
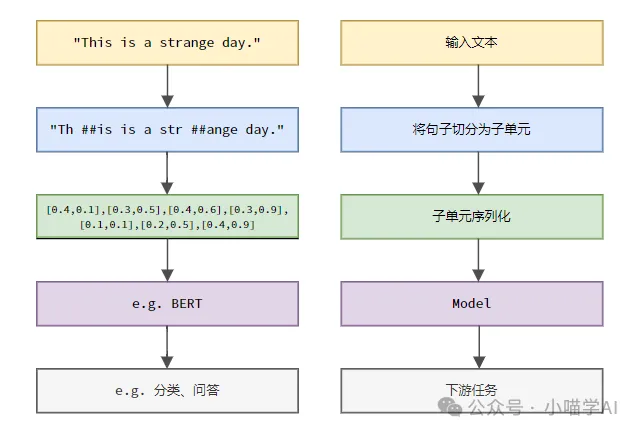
Textsegmentierung
Entsprechend der Granularität der Textsegmentierung kann die Tokenisierung in drei Kategorien unterteilt werden: granulare Tokenisierung für Wörter, granulare Tokenisierung für Zeichen und granulare Tokenisierung für Unterwörter.
1. Wortgranularitäts-Tokenisierung
Wortgranularitäts-Tokenisierung ist die intuitivste Wortsegmentierungsmethode, bei der der Text nach Vokabeln segmentiert wird. Beispiel:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
In diesem Beispiel wird der Text in unabhängige Wörter unterteilt, jedes Wort wird als Token verwendet und das Satzzeichen „.“ wird auch als unabhängiges Token betrachtet.
Chinesischer Text wird normalerweise entsprechend der im Wörterbuch enthaltenen Standardvokabelsammlung oder den Phrasen, Redewendungen, Eigennamen usw. segmentiert, die durch den Wortsegmentierungsalgorithmus erkannt werden.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
Dieser chinesische Text ist in fünf Wörter unterteilt: „Ich“, „Gefällt mir“, „Essen“, „Apfel“ und Punkt „.“; jedes Wort dient als Zeichen.
2. Granulare Zeichen-Tokenisierung
Die granulare Zeichen-Tokenisierung unterteilt Text in kleinste Zeicheneinheiten, d. h. jedes Zeichen wird als separates Token behandelt. Zum Beispiel:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Zeichengranularitäts-Tokenisierung im Chinesischen besteht darin, den Text nach jedem unabhängigen chinesischen Zeichen zu segmentieren.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.Subword-Granular-Tokenisierung
Subword-Granular-Tokenisierung liegt zwischen Wortgranularität und Zeichengranularität. Sie unterteilt den Text in Unterwörter (Unterwörter) zwischen Wörtern und Zeichen als Token. Zu den gängigen Unterwort-Tokenisierungsmethoden gehören Byte Pair Encoding (BPE), WordPiece usw. Diese Methoden generieren automatisch ein Wortsegmentierungswörterbuch durch Zählen der Teilzeichenfolgehäufigkeiten in Textdaten, das das Problem von Out-of-Service-Wörtern (OOV) effektiv lösen und gleichzeitig eine gewisse semantische Integrität aufrechterhalten kann. " hel“, „low“, „orld“, das sind alles hochfrequente Teilzeichenfolgenkombinationen, die in Wörterbüchern vorkommen. Diese Segmentierungsmethode kann nicht nur unbekannte Wörter verarbeiten (z. B. ist „helloworld“ kein englisches Standardwort), sondern auch bestimmte semantische Informationen beibehalten (durch die Kombination von Unterwörtern kann das ursprüngliche Wort wiederhergestellt werden).
helloworld
h, e, l, o, w, r, d, hel, low, wor, orld
['hel', 'low', 'orld']
In diesem Beispiel: „Ich esse gerne.“ Äpfel“ Es ist in vier Unterwörter „Ich“, „Gefällt mir“, „Essen“ und „Apfel“ unterteilt, und diese Unterwörter erscheinen alle im Wörterbuch. Obwohl chinesische Schriftzeichen nicht weiter wie englische Unterwörter kombiniert werden, hat die Unterwort-Tokenisierungsmethode bei der Erstellung des Wörterbuchs hochfrequente Wortkombinationen wie „Ich mag“ und „Äpfel essen“ berücksichtigt. Diese Segmentierungsmethode behält semantische Informationen auf Wortebene bei, während unbekannte Wörter verarbeitet werden.
Gehen Sie davon aus, dass ein Korpus oder Vokabular wie folgt erstellt wurde.
我喜欢吃苹果
kann den Index jedes Tokens in der Reihenfolge im Vokabular finden.
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Ausgabe: [0, 1, 2, 3, 4].
Das obige ist der detaillierte Inhalt vonTokenisierung in einem Artikel verstehen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
PhpMyAdmin erstellt Datentabelle
Apr 10, 2025 pm 11:00 PM
Um eine Datentabelle mithilfe von PHPMYADMIN zu erstellen, sind die folgenden Schritte unerlässlich: Stellen Sie eine Verbindung zur Datenbank her und klicken Sie auf die neue Registerkarte. Nennen Sie die Tabelle und wählen Sie die Speichermotor (innoDB empfohlen). Fügen Sie Spaltendetails hinzu, indem Sie auf die Taste der Spalte hinzufügen, einschließlich Spaltenname, Datentyp, ob Nullwerte und andere Eigenschaften zuzulassen. Wählen Sie eine oder mehrere Spalten als Primärschlüssel aus. Klicken Sie auf die Schaltfläche Speichern, um Tabellen und Spalten zu erstellen.
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Feldbetriebshandbuch in MySQL: Felder hinzufügen, ändern und löschen. Feld hinzufügen: Alter table table_name hinzufügen column_name data_type [nicht null] [Standard default_value] [Primärschlüssel] [auto_increment] Feld ändern: Alter table table_name Ändern Sie Column_Name Data_type [nicht null] [diffault default_value] [Primärschlüssel] [Primärschlüssel]
 Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Verschachtelte Anfragen sind eine Möglichkeit, eine andere Frage in eine Abfrage aufzunehmen. Sie werden hauptsächlich zum Abrufen von Daten verwendet, die komplexe Bedingungen erfüllen, mehrere Tabellen assoziieren und zusammenfassende Werte oder statistische Informationen berechnen. Beispiele hierfür sind zu findenen Mitarbeitern über den überdurchschnittlichen Löhnen, das Finden von Bestellungen für eine bestimmte Kategorie und die Berechnung des Gesamtbestellvolumens für jedes Produkt. Beim Schreiben verschachtelter Abfragen müssen Sie folgen: Unterabfragen schreiben, ihre Ergebnisse in äußere Abfragen schreiben (auf Alias oder als Klauseln bezogen) und optimieren Sie die Abfrageleistung (unter Verwendung von Indizes).
 Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Die Integritätsbeschränkungen von Oracle -Datenbanken können die Datengenauigkeit sicherstellen, einschließlich: nicht Null: Nullwerte sind verboten; Einzigartig: Einzigartigkeit garantieren und einen einzelnen Nullwert ermöglichen; Primärschlüssel: Primärschlüsselbeschränkung, Stärkung der einzigartigen und verboten Nullwerte; Fremdschlüssel: Verwalten Sie die Beziehungen zwischen Tabellen, Fremdschlüssel beziehen sich auf Primärtabellen -Primärschlüssel. Überprüfen Sie: Spaltenwerte nach Bedingungen begrenzen.
 Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Oracle ist das weltweit größte Softwareunternehmen für Datenbankverwaltungssystem (DBMS). Zu den Hauptprodukten gehören die folgenden Funktionen: Entwicklungstools für relationale Datenbankverwaltungssysteme (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud -Dienst (Oracle Cloud Infrastructure) Analyse und Business Intelligence (Oracle Analytic
