
 Technologie-Peripheriegeräte
KI
Durch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge
Technologie-Peripheriegeräte
KI
Durch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge
Durch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge

Ich weiß nicht, ob Gemini 1.5 Pro diese Technologie verwendet.
Google hat einen weiteren großen Schritt gemacht und das Transformer-Modell der nächsten Generation Infini-Transformer herausgebracht.
Führt einen praktischen und leistungsstarken Aufmerksamkeitsmechanismus Infini-Aufmerksamkeit ein – mit komprimiertem Langzeitgedächtnis und lokaler kausaler Aufmerksamkeit, der effektiv genutzt werden kann modellieren Sie langfristige und kurzfristige Kontextabhängigkeiten; Infini-Attention nimmt minimale Änderungen an der standardmäßig skalierten Punktproduktaufmerksamkeit vor und ist so konzipiert, dass es ein kontinuierliches Plug-and-Play-Vortraining und Selbstlernen über lange Kontexte unterstützt. Anpassung; Diese Methode ermöglicht es Transformer LLM, extrem lange Eingaben über Streams zu verarbeiten und auf unendlich lange Kontexte mit begrenzten Speicher- und Rechenressourcen zu skalieren. H-Paper-Link: https://arxiv.org/pdf/2404.07143.pdf

- Diese subtile, aber entscheidende Änderung der Transformer-Aufmerksamkeitsschicht kann das Kontextfenster bestehender LLMs durch kontinuierliches Vortraining und Feinabstimmung auf unendliche Längen erweitern.
-
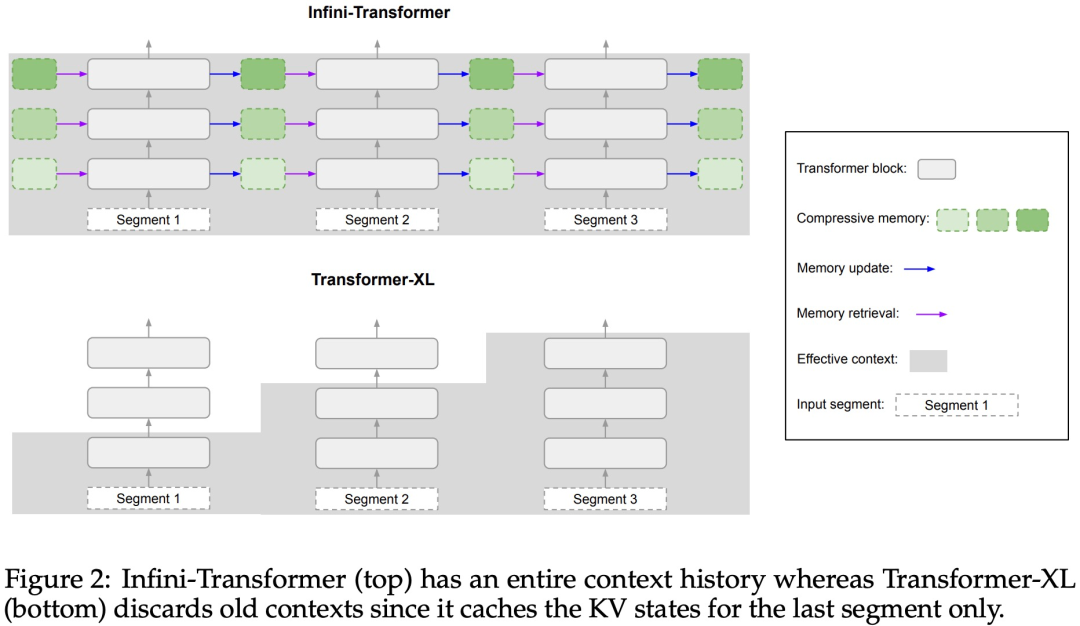
Infini-Attention übernimmt alle Schlüssel-, Wert- und Abfragezustände der Standard-Aufmerksamkeitsberechnungen für die Konsolidierung und den Abruf des Langzeitgedächtnisses und speichert den alten KV-Aufmerksamkeitszustand im komprimierten Speicher, anstatt sie wie der Standard-Aufmerksamkeitsmechanismus zu verwerfen.Bei der Verarbeitung nachfolgender Sequenzen verwendet Infini-attention den Aufmerksamkeitsabfragestatus, um Werte aus dem Speicher abzurufen. Um die endgültige Kontextausgabe zu berechnen, aggregiert Infini-attention die Abrufwerte des Langzeitgedächtnisses und den lokalen Aufmerksamkeitskontext. Wie in Abbildung 2 unten dargestellt, verglich das Forschungsteam Infini-Transformer und Transformer-XL basierend auf der Infini-Aufmerksamkeit. Ähnlich wie Transformer-XL arbeitet Infini-Transformer mit einer Folge von Segmenten und berechnet den standardmäßigen kausalen Punktprodukt-Aufmerksamkeitskontext in jedem Segment. Daher ist die Berechnung der Skalarproduktaufmerksamkeit in gewissem Sinne lokal. 
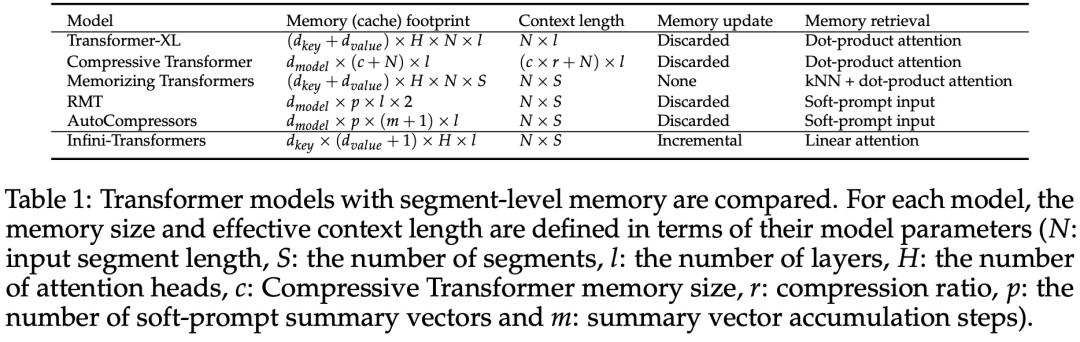
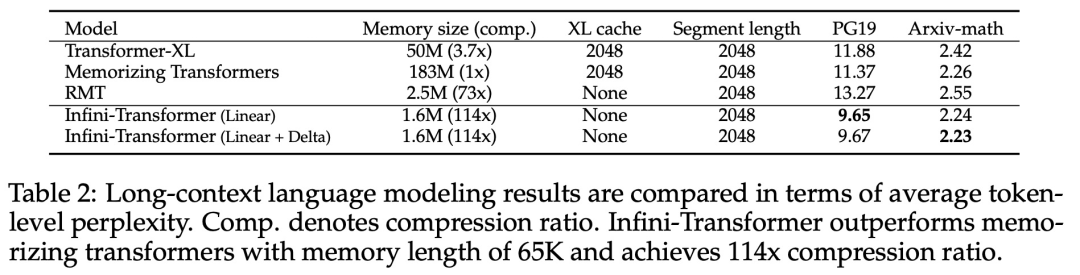
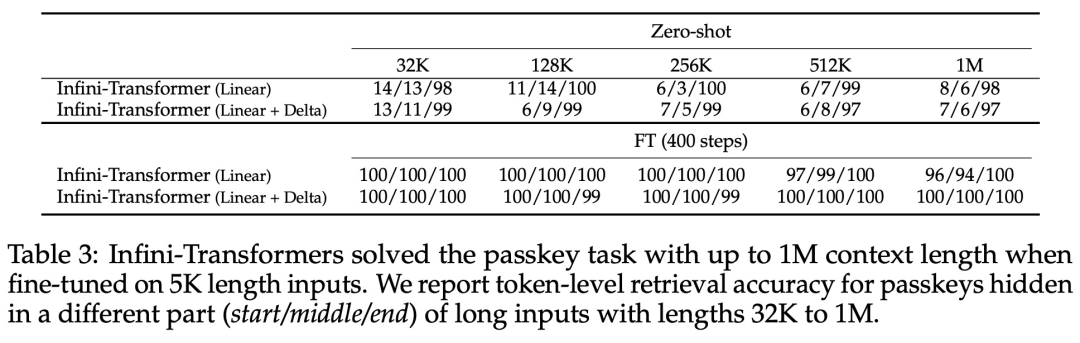
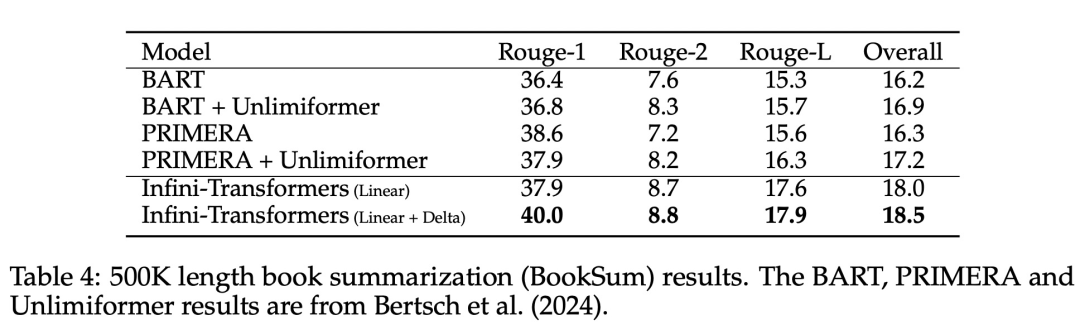
Allerdings verwirft die lokale Aufmerksamkeit den Aufmerksamkeitszustand des vorherigen Segments, wenn sie das nächste Segment verarbeitet, aber Infini-Transformer verwendet den alten KV-Aufmerksamkeitszustand wieder, um den gesamten Kontextverlauf durch komprimierte Speicherung aufrechtzuerhalten. Daher verfügt jede Aufmerksamkeitsschicht von Infini-Transformer über einen globalen komprimierten Zustand und einen lokalen feinkörnigen Zustand. Ähnlich wie bei der Multi-Head-Aufmerksamkeit (MHA) verwaltet Infini-Attention zusätzlich zur Punktproduktaufmerksamkeit auch H parallel komprimierte Erinnerungen für jede Aufmerksamkeitsschicht (H ist die Anzahl der Aufmerksamkeitsköpfe). Tabelle 1 unten listet den Kontextspeicherbedarf und die effektive Kontextlänge auf, die von mehreren Modellen basierend auf Modellparametern und Eingabesegmentlänge definiert werden. Infini-Transformer unterstützt unendliche Kontextfenster mit begrenztem Speicherbedarf. Experimente Die Studie evaluierte das Infini-Transformer-Modell zur Sprachmodellierung mit langen Kontexten, zum Abrufen von Schlüsselkontextblöcken mit einer Länge von 1 Mio. und zu Buchzusammenfassungsaufgaben mit einer Länge von 500.000, die eine extrem lange Eingabesequenz aufweisen. Für die Sprachmodellierung entschieden sich die Forscher dafür, das Modell von Grund auf zu trainieren, während die Forscher für die Schlüssel- und Buchzusammenfassungsaufgaben ein kontinuierliches Vortraining von LLM verwendeten, um die Plug-and-Play-Anpassbarkeit von Infini-attention für lange Kontexte zu beweisen. Sprachmodellierung mit langem Kontext. Die Ergebnisse in Tabelle 2 zeigen, dass Infini-Transformer die Baselines von Transformer-XL und Memorizing Transformers übertrifft und im Vergleich zum Memorizing Transformer-Modell 114-mal weniger Parameter speichert. Schlüsselmission. Tabelle 3 zeigt den Infini-Transformer, der auf eine Eingabe mit einer Länge von 5 KB fein abgestimmt ist und die Schlüsselaufgabe bis zu einer Kontextlänge von 1 MB löst. Die Eingabetoken im Experiment lagen zwischen 32.000 und 1 Mio. Für jede Testteilmenge kontrollierten die Forscher die Position des Schlüssels so, dass er sich nahe dem Anfang, der Mitte oder dem Ende der Eingabesequenz befand. Experimente berichten von Nullschussgenauigkeit und Feinabstimmungsgenauigkeit. Nach 400 Feinabstimmungsschritten an einer Eingabe mit 5K Länge löst Infini-Transformer Aufgaben mit einer Kontextlänge von bis zu 1M. Zusammenfassende Aufgaben. Tabelle 4 vergleicht Infini-Transformer mit einem Encoder-Decoder-Modell, das speziell für die Zusammenfassungsaufgabe entwickelt wurde. Die Ergebnisse zeigen, dass Infini-Transformer die bisherigen besten Ergebnisse übertrifft und durch die Verarbeitung des gesamten Buchtextes neue SOTA auf BookSum erreicht. Die Forscher haben auch den gesamten Rouge-Score der BookSum-Datenvalidierungsaufteilung in Abbildung 4 dargestellt. Der Polylinientrend zeigt, dass Infini-Transformer die zusammenfassenden Leistungsmetriken verbessern, wenn die Eingabelänge zunimmt.


Das obige ist der detaillierte Inhalt vonDurch die direkte Erweiterung auf unendliche Länge beendet Google Infini-Transformer die Debatte über die Kontextlänge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange -Webseite Registrierung Link Gate Trading App Registrierung Website Neueste
Feb 28, 2025 am 11:06 AM
In diesem Artikel wird der Registrierungsprozess der Webversion Sesam Open Exchange (GATE.IO) und die Gate Trading App im Detail vorgestellt. Unabhängig davon, ob es sich um eine Webregistrierung oder eine App -Registrierung handelt, müssen Sie die offizielle Website oder den offiziellen App Store besuchen, um die Genuine App herunterzuladen, und dann den Benutzernamen, das Kennwort, die E -Mail, die Mobiltelefonnummer und die anderen Informationen eingeben und eine E -Mail- oder Mobiltelefonüberprüfung abschließen.
 Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Top 10 für Crypto Digital Asset Trading App (2025 Global Ranking) empfohlen
Mar 18, 2025 pm 12:15 PM
Dieser Artikel empfiehlt die Top Ten Ten Cryptocurrency -Handelsplattformen, die es wert sind, auf Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI und Xbit -dezentrale Börsen geachtet zu werden. Diese Plattformen haben ihre eigenen Vorteile in Bezug auf Transaktionswährungsmenge, Transaktionstyp, Sicherheit, Konformität und Besonderheiten. Die Auswahl einer geeigneten Plattform erfordert eine umfassende Überlegung, die auf eigener Handelserfahrung, Risikotoleranz und Investitionspräferenzen basiert. Ich hoffe, dieser Artikel hilft Ihnen dabei, den besten Anzug für sich selbst zu finden
 Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Sesam Open Door Exchange Webseite Login Neueste Version Gateio Offizieller Website Eingang
Mar 04, 2025 pm 11:48 PM
Eine detaillierte Einführung in den Anmeldungsbetrieb der Sesame Open Exchange -Webversion, einschließlich Anmeldeschritte und Kennwortwiederherstellungsprozess.
 Warum wird Bittensor als 'Bitcoin' in der KI -Strecke gesagt?
Mar 04, 2025 pm 04:06 PM
Warum wird Bittensor als 'Bitcoin' in der KI -Strecke gesagt?
Mar 04, 2025 pm 04:06 PM
Original -Titel: Bittensor = Aibitcoin? Bittensor nimmt ein Subnetzmodell an, das die Entstehung verschiedener KI -Lösungen ermöglicht und Innovation durch Tao -Token inspiriert. Obwohl der KI -Markt ausgereift ist, steht Bittensor mit wettbewerbsfähigen Risiken aus und kann anderen Open Source unterliegen
 Registrieren Sie sich und laden Sie die neueste App auf der offiziellen Bitget -Website herunter und laden Sie sie herunter
Mar 05, 2025 am 07:54 AM
Registrieren Sie sich und laden Sie die neueste App auf der offiziellen Bitget -Website herunter und laden Sie sie herunter
Mar 05, 2025 am 07:54 AM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
 Ouyi okx offizielle Version Download App -Eingang
Mar 04, 2025 pm 11:24 PM
Ouyi okx offizielle Version Download App -Eingang
Mar 04, 2025 pm 11:24 PM
Dieser Artikel enthält die neuesten Download -Informationen zur offiziellen Version von Ouyi OKX. In diesem Artikel wird die Leser dazu geführt, wie man sicher und bequem auf die Android- und iOS -Apps der Exchange zugreifen kann. Dieser Artikel enthält Schritt-für-Schritt-Anweisungen und wichtige Tipps, mit denen die Leser die Ouyi OKX-App problemlos herunterladen und installieren können.
 Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
Tutorial zur Registrierung, Verwendung und Stornierung von Ouyi Okex -Konto
Mar 31, 2025 pm 04:21 PM
In diesem Artikel wird ausführlich die Registrierungs-, Nutzungs- und Stornierungsverfahren von Ouyi Okex -Konto eingeführt. Um sich zu registrieren, müssen Sie die App herunterladen, Ihre Handynummer oder E-Mail-Adresse eingeben, um sich zu registrieren, und die authentifizierte Authentifizierung abschließen. Die Verwendung deckt die Betriebsschritte wie Anmeldung, Aufladung und Rückzug, Transaktion und Sicherheitseinstellungen ab. Um ein Konto zu kündigen, müssen Sie den Kundendienst von Ouyi Okex kontaktieren, die erforderlichen Informationen bereitstellen und auf die Bearbeitung warten und schließlich die Bestätigung des Konto -Stornierens erhalten. In diesem Artikel können Benutzer das vollständige Lebenszyklusmanagement von Ouyi Okex -Konto problemlos beherrschen und digitale Asset -Transaktionen sicher und bequem durchführen.
 Bitget Exchange Portal: Offizieller App -Download -Handbuch
Mar 05, 2025 am 07:51 AM
Bitget Exchange Portal: Offizieller App -Download -Handbuch
Mar 05, 2025 am 07:51 AM
Dieser Leitfaden enthält detaillierte Download- und Installationsschritte für die offizielle Bitget Exchange -App, die für Android- und iOS -Systeme geeignet ist. Der Leitfaden integriert Informationen aus mehreren maßgeblichen Quellen, einschließlich der offiziellen Website, dem App Store und Google Play, und betont Überlegungen während des Downloads und des Kontoverwaltung. Benutzer können die App aus offiziellen Kanälen herunterladen, einschließlich App Store, offizieller Website APK Download und offizieller Website -Sprung sowie vollständige Registrierung, Identitätsüberprüfung und Sicherheitseinstellungen. Darüber hinaus deckt der Handbuch häufig gestellte Fragen und Überlegungen ab, wie z.
