
 Technologie-Peripheriegeräte
KI
Die neue Methode PiSSA der Peking-Universität ändert die Initialisierungsmethode von LoRA und verbessert den Feinabstimmungseffekt erheblich
Technologie-Peripheriegeräte
KI
Die neue Methode PiSSA der Peking-Universität ändert die Initialisierungsmethode von LoRA und verbessert den Feinabstimmungseffekt erheblich
Die neue Methode PiSSA der Peking-Universität ändert die Initialisierungsmethode von LoRA und verbessert den Feinabstimmungseffekt erheblich

Da die Anzahl der Parameter großer Modelle von Tag zu Tag zunimmt, werden die Kosten für die Feinabstimmung des gesamten Modells allmählich inakzeptabel.
Daher schlug das Forschungsteam der Universität Peking eine effiziente Parameter-Feinabstimmungsmethode namens PiSSA vor, die den Feinabstimmungseffekt des derzeit weit verbreiteten LoRA auf Mainstream-Datensätze übertrifft.

Papier: PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
Papier-Link: https://arxiv.org/pdf/2404.02948.pdf
Code-Link : https://github.com/GraphPKU/PiSSA
Abbildung 1 zeigt, dass PiSSA (Abbildung 1c) in der Modellarchitektur (Abbildung 1b) vollständig mit LoRA [1] übereinstimmt, die Art und Weise der Initialisierung des Adapters jedoch unterschiedlich ist . LoRA initialisiert A mit Gaußschem Rauschen und B mit 0. PiSSA verwendet Principal Singular Values und Singular Vectors, um den Adapter zu initialisieren, um A und B zu initialisieren.
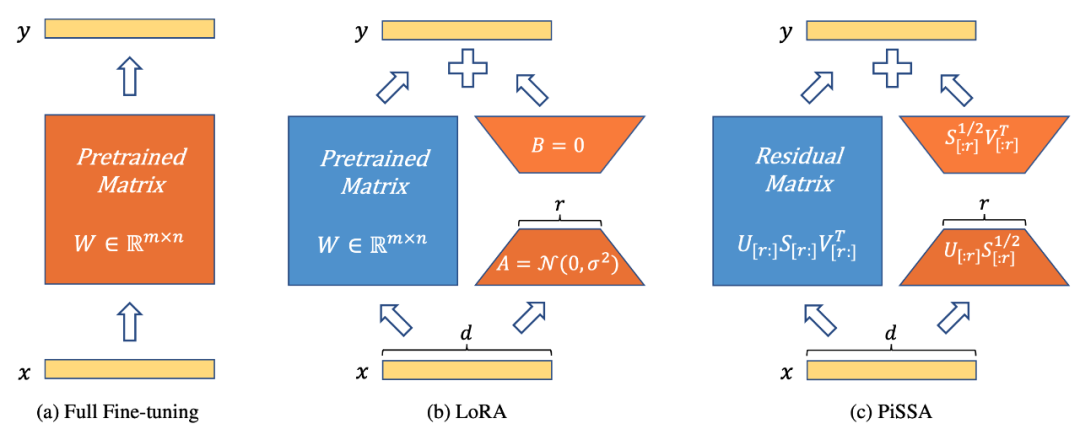
Abbildung 1 zeigt die vollständige Parameter-Feinabstimmung, LoRA und PiSSA von links nach rechts. Blau steht für eingefrorene Parameter, Orange für trainierbare Parameter und andere Initialisierungsmethoden. Im Vergleich zur vollständigen Parameter-Feinabstimmung reduzieren sowohl LoRA als auch PiSSA die Anzahl der trainierbaren Parameter erheblich. Bei gleicher Eingabe sind die Anfangsausgaben dieser drei Methoden genau gleich. PiSSA friert jedoch den sekundären Teil des Modells ein und passt den Hauptteil (die ersten r Singulärwerte und singulären Vektoren) direkt an, während LoRA als Einfrieren des Hauptteils des Modells und Feinabstimmung des Rauschens betrachtet werden kann Teil.
Vergleichen Sie die Feinabstimmungseffekte von PiSSA und LoRA auf verschiedene Aufgaben
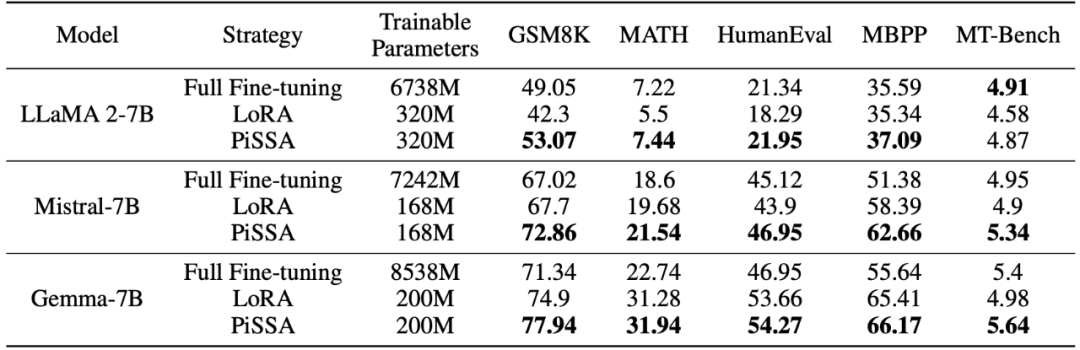
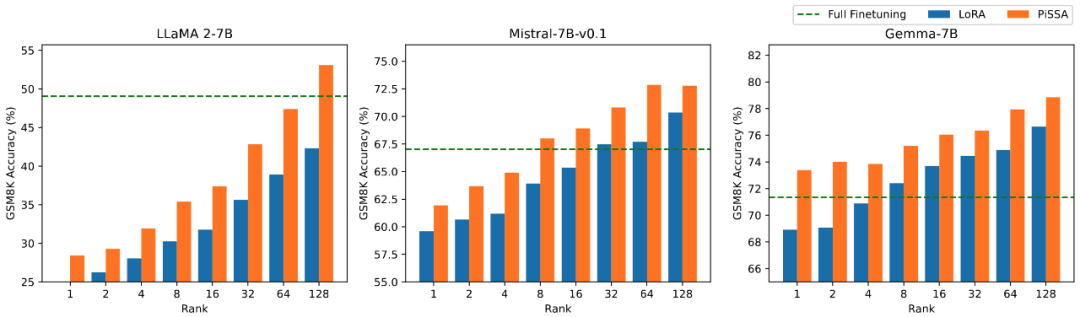
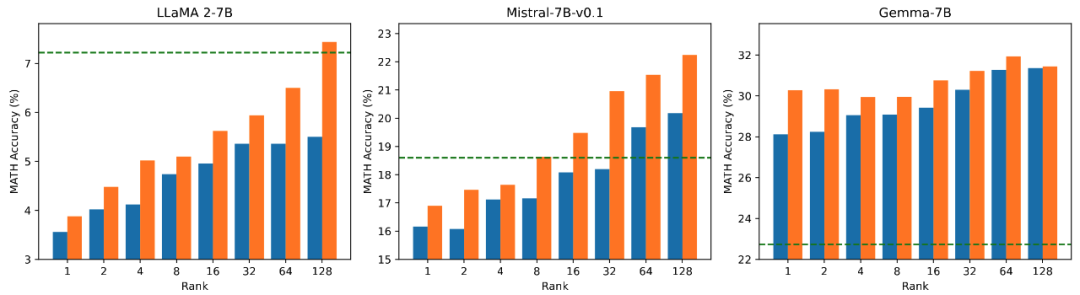
Das Forschungsteam verwendet Lama 2-7B, Mistral-7B und Gemma-7B als Grundmodelle, um ihre Mathematik-, Codierungs- und Dialogfähigkeiten zu verbessern Feinabstimmung . Dazu gehören: Schulung zu MetaMathQA, Überprüfung der mathematischen Fähigkeiten des Modells anhand der GSM8K- und MATH-Datensätze; Schulung zu CodeFeedBack, Überprüfung der Codefähigkeit des Modells anhand der HumanEval- und MBPP-Datensätze und Verwenden von MT – Überprüfen Sie die Konversationsfähigkeiten des Modells auf Bench. Wie aus den experimentellen Ergebnissen in der folgenden Tabelle ersichtlich ist, übertrifft der Feinabstimmungseffekt von PiSSA bei Verwendung derselben Skala trainierbarer Parameter den von LoRA deutlich und sogar den der Feinabstimmung mit vollständigen Parametern.
Vergleich der Auswirkungen der PiSSA- und LoRA-Feinabstimmung bei unterschiedlichen Mengen trainierbarer Parameter
Das Forschungsteam führte Ablationsexperimente zum Zusammenhang zwischen der Menge trainierbarer Parameter und der Wirkung des Modells auf mathematische Aufgaben durch. Aus Abbildung 2.1 geht hervor, dass der Trainingsverlust von PiSSA in der frühen Phase des Trainings sehr schnell abnimmt, während es bei LoRA ein Stadium gibt, in dem er nicht abnimmt oder sogar leicht zunimmt. Darüber hinaus ist der Trainingsverlust von PiSSA durchgehend geringer als der von LoRA, was darauf hindeutet, dass er besser zum Trainingssatz passt. Aus den Abbildungen 2.2, 2.3 und 2.4 können wir ersehen, dass der Verlust von PiSSA bei jeder Einstellung immer geringer ist als der von LoRA Immer höher als LoRA High, kann PiSSA den Effekt einer vollständigen Parameter-Feinabstimmung mit weniger trainierbaren Parametern erreichen.
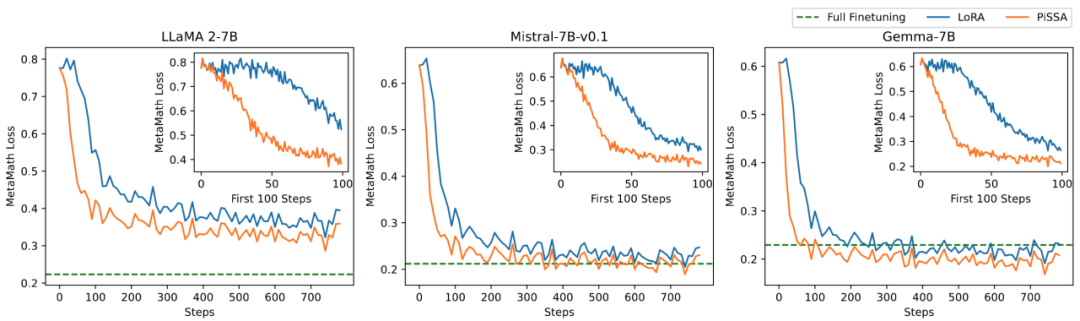
Abbildung 2.1) Wenn der Rang 1 ist, der Verlust von PiSSA und LoRA während des Trainingsprozesses. Die obere rechte Ecke jeder Abbildung ist die vergrößerte Kurve der ersten 100 Iterationen. Unter diesen wird PiSSA durch die orange Linie dargestellt, LoRA durch die blaue Linie und die Feinabstimmung der vollständigen Parameter verwendet die grüne Linie, um den endgültigen Verlust als Referenz anzuzeigen. Das Phänomen, wenn der Rang [2,4,8,16,32,64,128] ist, stimmt damit überein. Einzelheiten finden Sie im Anhang des Artikels.
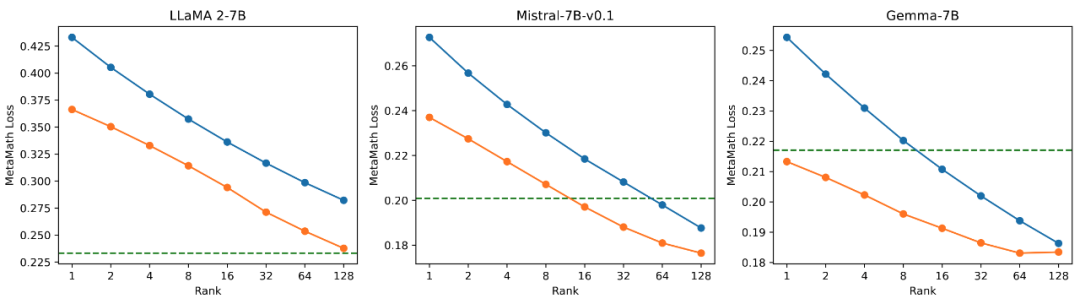
Abbildung 2.2) Der endgültige Trainingsverlust von PiSSA und LoRA anhand der Ränge [1,2,4,8,16,32,64,128].
Genauigkeit.
auf die Genauigkeitsrate.
Detaillierte Erklärung der PiSSA-Methode
Inspiriert von Intrinsic SAID [2] „Vorab trainierte große Modellparameter haben einen niedrigen Rang“, führt PiSSA eine Singulärwertzerlegung auf der Parametermatrix 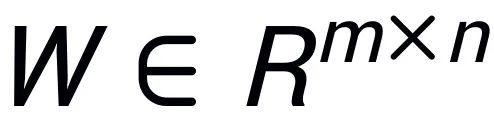 des vorab trainierten Modells durch, wobei die ersten r Singulärwerte und Singulärvektoren verwendet werden um den Adapter zu initialisieren) der beiden Matrizen
des vorab trainierten Modells durch, wobei die ersten r Singulärwerte und Singulärvektoren verwendet werden um den Adapter zu initialisieren) der beiden Matrizen  und
und  ,
,  ; die verbleibenden Singulärwerte und Singulärvektoren werden verwendet, um die Restmatrix
; die verbleibenden Singulärwerte und Singulärvektoren werden verwendet, um die Restmatrix  zu konstruieren, so dass
zu konstruieren, so dass 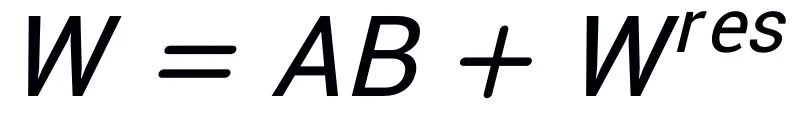 . Daher enthalten die Parameter im Adapter die Kernparameter des Modells, während die Parameter in der Restmatrix Korrekturparameter sind. Durch die Feinabstimmung der Kernadapter A und B mit kleineren Parametern und das Einfrieren der Restmatrix
. Daher enthalten die Parameter im Adapter die Kernparameter des Modells, während die Parameter in der Restmatrix Korrekturparameter sind. Durch die Feinabstimmung der Kernadapter A und B mit kleineren Parametern und das Einfrieren der Restmatrix  mit größeren Parametern wird der Effekt einer annähernd vollständigen Parameter-Feinabstimmung mit sehr wenigen Parametern erreicht.
mit größeren Parametern wird der Effekt einer annähernd vollständigen Parameter-Feinabstimmung mit sehr wenigen Parametern erreicht.
Obwohl die Prinzipien von PiSSA und LoRA gleichermaßen von Intrinsic SAID [1] inspiriert sind, sind sie völlig unterschiedlich.
LoRA geht davon aus, dass die Änderung der Matrix △W vor und nach der Feinabstimmung des großen Modells einen sehr niedrigen intrinsischen Rang r aufweist, sodass die Änderung des Modells △W durch die durch Multiplikation erhaltene Matrix mit niedrigem Rang simuliert wird  und
und  . In der Anfangsphase initialisiert LoRA A mit Gaußschem Rauschen und initialisiert B mit 0, um sicherzustellen, dass sich die anfängliche Fähigkeit des Modells nicht ändert, und optimiert A und B, um W zu aktualisieren. Im Gegensatz dazu kümmert sich PiSSA nicht um △W, sondern geht davon aus, dass W einen sehr niedrigen intrinsischen Rang r hat. Daher führen wir direkt eine Singulärwertzerlegung für W durch und zerlegen es in die Hauptkomponenten A, B und den Restterm
. In der Anfangsphase initialisiert LoRA A mit Gaußschem Rauschen und initialisiert B mit 0, um sicherzustellen, dass sich die anfängliche Fähigkeit des Modells nicht ändert, und optimiert A und B, um W zu aktualisieren. Im Gegensatz dazu kümmert sich PiSSA nicht um △W, sondern geht davon aus, dass W einen sehr niedrigen intrinsischen Rang r hat. Daher führen wir direkt eine Singulärwertzerlegung für W durch und zerlegen es in die Hauptkomponenten A, B und den Restterm  , sodass
, sodass  . Angenommen, die Singulärwertzerlegung von W ist
. Angenommen, die Singulärwertzerlegung von W ist 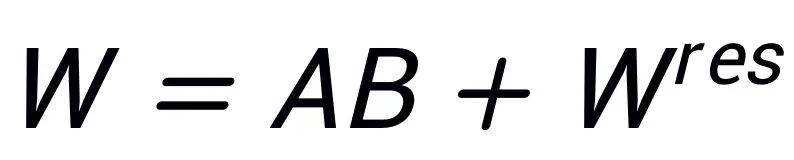 , A und B werden mit den r Singulärwerten und Singulärvektoren mit den größten Singulärwerten nach der SVD-Zerlegung initialisiert:
, A und B werden mit den r Singulärwerten und Singulärvektoren mit den größten Singulärwerten nach der SVD-Zerlegung initialisiert: 
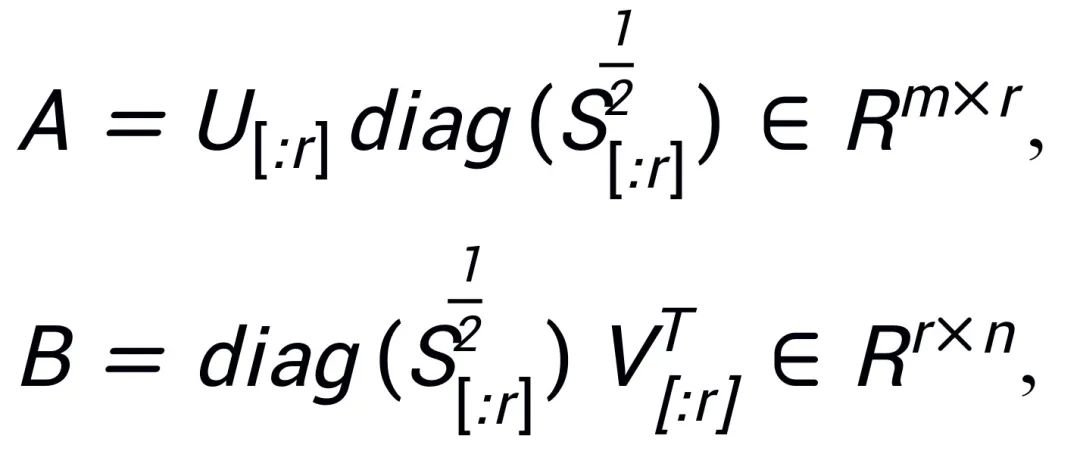
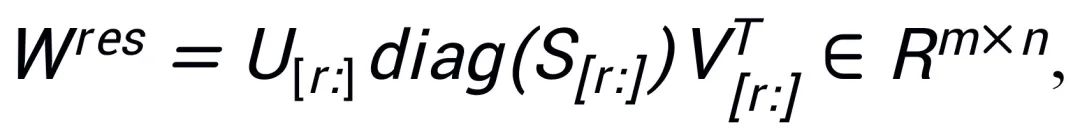
Da PiSSA genau die gleiche Architektur wie LoRA verwendet, kann es als optionale Initialisierungsmethode für LoRA verwendet und einfach geändert und im peft-Paket aufgerufen werden (wie im folgenden Code gezeigt). Die gleiche Architektur ermöglicht es PiSSA auch, die meisten Vorteile von LoRA zu übernehmen, wie zum Beispiel: Durch die Verwendung der 4-Bit-Quantisierung [3] für das Restmodell kann der Trainingsaufwand reduziert werden, nachdem die Feinabstimmung abgeschlossen ist Modell, ohne die Modellarchitektur des Inferenzprozesses zu ändern. Es ist nicht erforderlich, vollständige Modellparameter gemeinsam zu nutzen. Benutzer können die Einzelwertzerlegung und -zuweisung automatisch durchführen PiSSA-Modul; ein Modell kann mehrere PiSSA-Module gleichzeitig verwenden usw. Einige Verbesserungen der LoRA-Methode können auch mit PiSSA kombiniert werden: Anstatt beispielsweise den Rang jeder Ebene festzulegen, kann mithilfe von PiSSA-geführten Updates [5] der beste Rang ermittelt werden, um die Ranggrenze zu durchbrechen. usw.
# 在 peft 包中 LoRA 的初始化方式后面增加了一种 PiSSA 初始化选项:if use_lora:nn.init.normal_(self.lora_A.weight, std=1 /self.r)nn.init.zeros_(self.lora_B.weight) elif use_pissa:Ur, Sr, Vr = svd_lowrank (self.base_layer.weight, self.r, niter=4) # 注意:由于 self.base_layer.weight 的维度是 (out_channel,in_channel, 所以 AB 的顺序相比图示颠倒了一下)self.lora_A.weight = torch.diag (torch.sqrt (Sr)) @ Vh.t ()self.lora_B.weight = Ur @ torch.diag (torch.sqrt (Sr)) self.base_layer.weight = self.base_layer.weight - self.lora_B.weight @ self.lora_A.weight
Vergleichsexperiment der Feinabstimmungseffekte von hohen, mittleren und niedrigen Singulärwerten
Um die Auswirkungen der Verwendung unterschiedlicher Größen von Singulärwerten und Singularvektoren zur Initialisierung des Adapters auf das Modell zu überprüfen, Die Forscher verwendeten hohe, mittlere und niedrige Singulärwerte, um den LLaMA 2-7B-, Mistral-7B-v0.1- und Gemma-7B-Adapter zu initialisieren und dann den MetaMathQA-Datensatz zu optimieren, und die experimentellen Ergebnisse sind siehe Abbildung 3. Wie aus der Abbildung ersichtlich ist, weist die Methode mit primärer Singulärwertinitialisierung den geringsten Trainingsverlust auf und weist eine höhere Genauigkeit bei den GSM8K- und MATH-Validierungssätzen auf. Dieses Phänomen bestätigt die Wirksamkeit der Feinabstimmung der Hauptsingulärwerte und Singularvektoren.
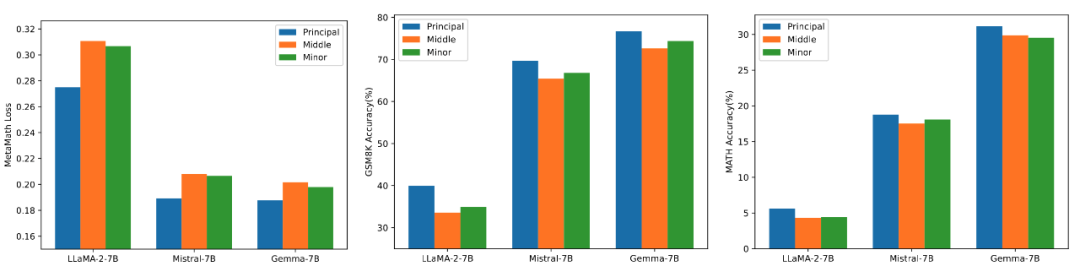
Abbildung 3) Von links nach rechts sind der Trainingsverlust, die Genauigkeit bei GSM8K und die Genauigkeit bei MATH. Blau stellt den maximalen Singulärwert dar, Orange stellt den mittleren Singulärwert dar und Grün stellt den minimalen Singulärwert dar.
Schnelle Singularwertzerlegung
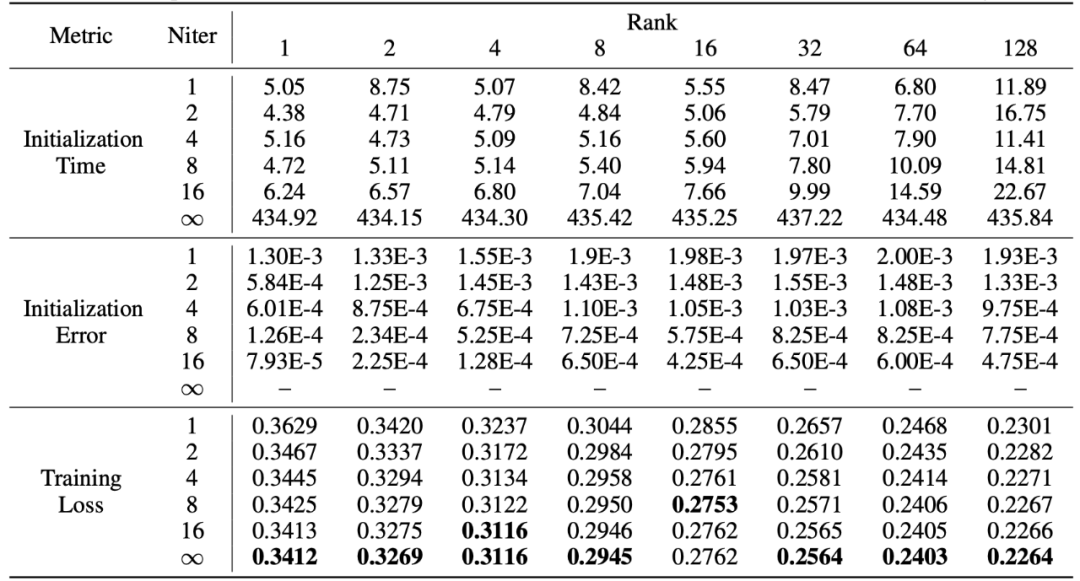
PiSSA übernimmt die Vorteile von LoRA, ist einfach zu verwenden und hat bessere Effekte als LoRA. Der Preis besteht darin, dass das Modell während der Initialisierungsphase in Einzelwerte zerlegt werden muss. Obwohl es während der Initialisierung nur einmal zerlegt werden muss, kann es dennoch mehrere Minuten oder sogar mehrere zehn Minuten Overhead erfordern. Daher verwendeten die Forscher eine schnelle Singulärwertzerlegungsmethode [6], um die Standard-SVD-Zerlegung zu ersetzen. Wie aus den Experimenten in der folgenden Tabelle ersichtlich ist, dauert es nur wenige Sekunden, um den Trainingssatzanpassungseffekt der Standard-SVD anzunähern Zersetzung. . Niter stellt die Anzahl der Iterationen dar. Je größer der Niter, desto länger die Zeit, aber desto kleiner der Fehler. Niter = ∞ repräsentiert die Standard-SVD. Der durchschnittliche Fehler in der Tabelle stellt den durchschnittlichen L_1-Abstand zwischen A und B dar, der durch schnelle Singulärwertzerlegung und Standard-SVD ermittelt wird.
Zusammenfassung und Ausblick
Diese Arbeit führt eine Singulärwertzerlegung der Gewichte des vorab trainierten Modells durch. Durch die Verwendung der wichtigsten Parameter zur Initialisierung eines Adapters namens PiSSA kommt die Feinabstimmung dieses Adapters einer Feinabstimmung gleich das komplette Modell. Experimente zeigen, dass PiSSA schneller konvergiert als LoRA und bessere Endergebnisse liefert. Der einzige Kostenfaktor ist der SVD-Initialisierungsprozess, der mehrere Sekunden dauert.
Sind Sie also bereit, für bessere Trainingsergebnisse noch ein paar Sekunden zu investieren und die Initialisierung von LoRA mit einem Klick auf PiSSA zu ändern?
Referenzen
[1] LoRA: Low-Rank-Anpassung großer Sprachmodelle
[2] Intrinsische Dimensionalität erklärt die Wirksamkeit der Feinabstimmung von Sprachmodellen
[3] QLoRA: Effiziente Feinabstimmung quantisierter LLMs Parameter mit dem Delta von Low-Rank-Matrizen
[6] Struktur mit Zufälligkeit finden: Wahrscheinlichkeitsalgorithmen zur Konstruktion ungefährer Matrixzerlegungen
Das obige ist der detaillierte Inhalt vonDie neue Methode PiSSA der Peking-Universität ändert die Initialisierungsmethode von LoRA und verbessert den Feinabstimmungseffekt erheblich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Frage Beschreibung: Wie erhalten Sie die Daten der Versandregion der Überseeversion? Gibt es bereitgestellte Ressourcen? Werden Sie im grenzüberschreitenden E-Commerce oder im globalisierten Geschäft genau ...
 Python Hourglass Graph Drawing: Wie vermeiden Sie variable undefinierte Fehler?
Apr 01, 2025 pm 06:27 PM
Python Hourglass Graph Drawing: Wie vermeiden Sie variable undefinierte Fehler?
Apr 01, 2025 pm 06:27 PM
Erste Schritte mit Python: Hourglas -Grafikzeichnung und Eingabeüberprüfung In diesem Artikel wird das Problem der Variablendefinition gelöst, das von einem Python -Anfänger im Hourglass -Grafikzeichnungsprogramm auftritt. Code...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 TYPECHO ROOTE VERFÜGBARKLOUTE: Warum ist mein/test/tag/his/10086 passungstesttagindex anstelle von testTagpage?
Apr 01, 2025 am 09:03 AM
TYPECHO ROOTE VERFÜGBARKLOUTE: Warum ist mein/test/tag/his/10086 passungstesttagindex anstelle von testTagpage?
Apr 01, 2025 am 09:03 AM
Analyse und Problemuntersuchung von typten-Routing-Matching-Regeln und Problemuntersuchungen analysiert und beantworten Fragen zu den inkonsistenten Ergebnissen der Registrierung von Typecho-Plug-in-Routing-Registrierung und den tatsächlichen Übereinstimmungsgebnissen ...
