
 Technologie-Peripheriegeräte
KI
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Technologie-Peripheriegeräte
KI
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!

Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama 2, Mistral und Gemma problemlos lokal ausführen können. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, können Sie diesen Artikel lesen.
In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft.
Starten Sie den nomic-embed-text-Dienst.
Nachdem Sie Ollama erfolgreich installiert haben, verwenden Sie den folgenden Befehl, um das nomic-embed-text-Modell abzurufen:
ollama pull nomic-embed-text
Nachdem Sie das Modell erfolgreich abgerufen haben, geben Sie den folgenden Befehl ein Terminal, starten Sie den Ollama-Dienst:
ollama serve
Danach können wir mit Curl überprüfen, ob der Einbettungsdienst normal läuft:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Verwenden Sie den nomic-embed-text-Dienst
Als nächstes stellen wir vor, wie um langchainjs und den nomic -embed-text-Dienst zu verwenden, der Einbettungsvorgänge für lokale TXT-Dokumente implementiert. Der entsprechende Vorgang ist in der folgenden Abbildung dargestellt:
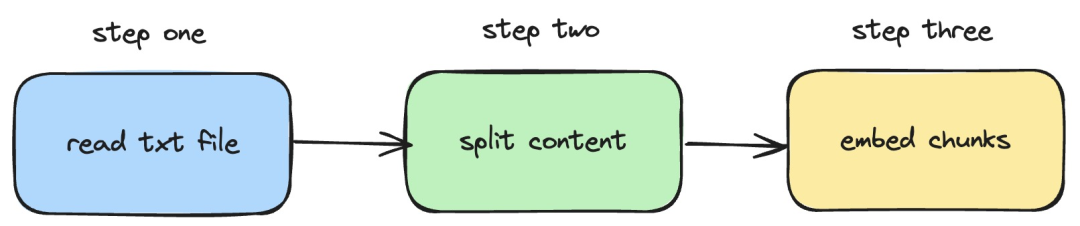 Bilder
Bilder
1. Lesen Sie die lokale TXT-Datei
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Im obigen Code haben wir eine Ladefunktion definiert, die intern den von langchainjs bereitgestellten TextLoader verwendet Lesen Sie „Lokales TXT-Dokument abrufen“.
2. Teilen Sie den TXT-Inhalt in Textblöcke auf
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Im obigen Code verwenden wir RecursiveCharacterTextSplitter, um den gelesenen TXT-Text zu schneiden und die Größe jedes Textblocks auf 500 festzulegen.
3. Führen Sie eine Einbettungsoperation für Textblöcke durch
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Im obigen Code definieren wir eine Einbettungsfunktion, in der die zuvor definierten Lade- und Teilungsfunktionen aufgerufen werden. Durchlaufen Sie dann den generierten Textblock und rufen Sie den lokal gestarteten Einbettungsdienst nomic-embed-text auf. Die sendRequest-Funktion wird zum Senden von Einbettungsanforderungen verwendet. Ihr Implementierungscode ist sehr einfach, nämlich die Verwendung der Abruf-API zum Aufrufen der vorhandenen REST-API.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Als nächstes definieren wir weiterhin eine EmbedTxtFile-Funktion, rufen die vorhandene Einbettungsfunktion direkt innerhalb der Funktion auf und fügen die entsprechende Ausnahmebehandlung hinzu.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Schließlich verwenden wir den Befehl npx esno src/index.ts, um die lokale ts-Datei schnell auszuführen. Wenn der Code in index.ts erfolgreich ausgeführt wird, werden die folgenden Ergebnisse im Terminal ausgegeben:
 Bilder
Bilder
Tatsächlich können wir zusätzlich zur Verwendung der oben genannten Methode auch direkt [OllamaEmbeddings im @ verwenden langchain/community module ](https://js.langchain.com/docs/integrations/text_embedding/ollama „OllamaEmbeddings“)-Objekt, das intern die Logik des Aufrufs des Ollama-Einbettungsdienstes kapselt:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Der in eingeführte Inhalt Dieser Artikel befasst sich mit der Entwicklung des RAG-Systems und dem Prozess der Erstellung eines Wissensdatenbank-Inhaltsindex. Wenn Sie das RAG-System nicht kennen, können Sie verwandte Artikel lesen.
Referenzen
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/library/nomic-embed-text
Das obige ist der detaillierte Inhalt vonDie lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks: REST-API-Anforderungsverarbeitung: Vert.x ist am besten, mit einer Anforderungsrate von 2-mal SpringBoot und 3-mal Dropwizard. Datenbankabfrage: HibernateORM von SpringBoot ist besser als ORM von Vert.x und Dropwizard. Caching-Vorgänge: Der Hazelcast-Client von Vert.x ist den Caching-Mechanismen von SpringBoot und Dropwizard überlegen. Geeignetes Framework: Wählen Sie entsprechend den Anwendungsanforderungen. Vert.x eignet sich für leistungsstarke Webdienste, SpringBoot eignet sich für datenintensive Anwendungen und Dropwizard eignet sich für Microservice-Architekturen.
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Benchmark-Zielerkennungssysteme der YOLO-Serie haben erneut ein großes Upgrade erhalten. Seit der Veröffentlichung von YOLOv9 im Februar dieses Jahres wurde der Staffelstab der YOLO-Reihe (YouOnlyLookOnce) in die Hände von Forschern der Tsinghua-Universität übergeben. Letztes Wochenende erregte die Nachricht vom Start von YOLOv10 die Aufmerksamkeit der KI-Community. Es gilt als bahnbrechendes Framework im Bereich Computer Vision und ist für seine End-to-End-Objekterkennungsfunktionen in Echtzeit bekannt. Es führt das Erbe der YOLO-Serie fort und bietet eine leistungsstarke Lösung, die Effizienz und Genauigkeit vereint. Papieradresse: https://arxiv.org/pdf/2405.14458 Projektadresse: https://github.com/THU-MIG/yo
 Technischer Bericht von Google Gemini 1.5: Einfache Prüfung von Mathematik-Olympiade-Fragen, die Flash-Version ist fünfmal schneller als GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Technischer Bericht von Google Gemini 1.5: Einfache Prüfung von Mathematik-Olympiade-Fragen, die Flash-Version ist fünfmal schneller als GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Im Februar dieses Jahres brachte Google das multimodale Großmodell Gemini 1.5 auf den Markt, das durch technische und Infrastrukturoptimierung, MoE-Architektur und andere Strategien die Leistung und Geschwindigkeit erheblich verbesserte. Mit längerem Kontext, stärkeren Argumentationsfähigkeiten und besserem Umgang mit modalübergreifenden Inhalten. Diesen Freitag hat Google DeepMind offiziell den technischen Bericht zu Gemini 1.5 veröffentlicht, der die Flash-Version und andere aktuelle Upgrades behandelt. Das Dokument ist 153 Seiten lang. Link zum technischen Bericht: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf In diesem Bericht stellt Google Gemini1 vor
 Wie kann die Leistung von Multithread-Programmen in C++ optimiert werden?
Jun 05, 2024 pm 02:04 PM
Wie kann die Leistung von Multithread-Programmen in C++ optimiert werden?
Jun 05, 2024 pm 02:04 PM
Zu den wirksamen Techniken zur Optimierung der C++-Multithread-Leistung gehört die Begrenzung der Anzahl der Threads, um Ressourcenkonflikte zu vermeiden. Verwenden Sie leichte Mutex-Sperren, um Konflikte zu reduzieren. Optimieren Sie den Umfang der Sperre und minimieren Sie die Wartezeit. Verwenden Sie sperrenfreie Datenstrukturen, um die Parallelität zu verbessern. Vermeiden Sie geschäftiges Warten und benachrichtigen Sie Threads über Ereignisse über die Ressourcenverfügbarkeit.
 ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
ChatGPT ist jetzt mit der Veröffentlichung einer speziellen App für macOS verfügbar
Jun 27, 2024 am 10:05 AM
Die ChatGPT-Mac-Anwendung von Open AI ist jetzt für alle verfügbar, während sie in den letzten Monaten nur denjenigen mit einem ChatGPT Plus-Abonnement vorbehalten war. Die App lässt sich wie jede andere native Mac-App installieren, sofern Sie über ein aktuelles Apple S verfügen
