
 Technologie-Peripheriegeräte
KI
Al Agent – Eine wichtige Implementierungsrichtung im Zeitalter großer Modelle
Technologie-Peripheriegeräte
KI
Al Agent – Eine wichtige Implementierungsrichtung im Zeitalter großer Modelle
Al Agent – Eine wichtige Implementierungsrichtung im Zeitalter großer Modelle

1. Die Gesamtarchitektur des LLM-basierten Agenten
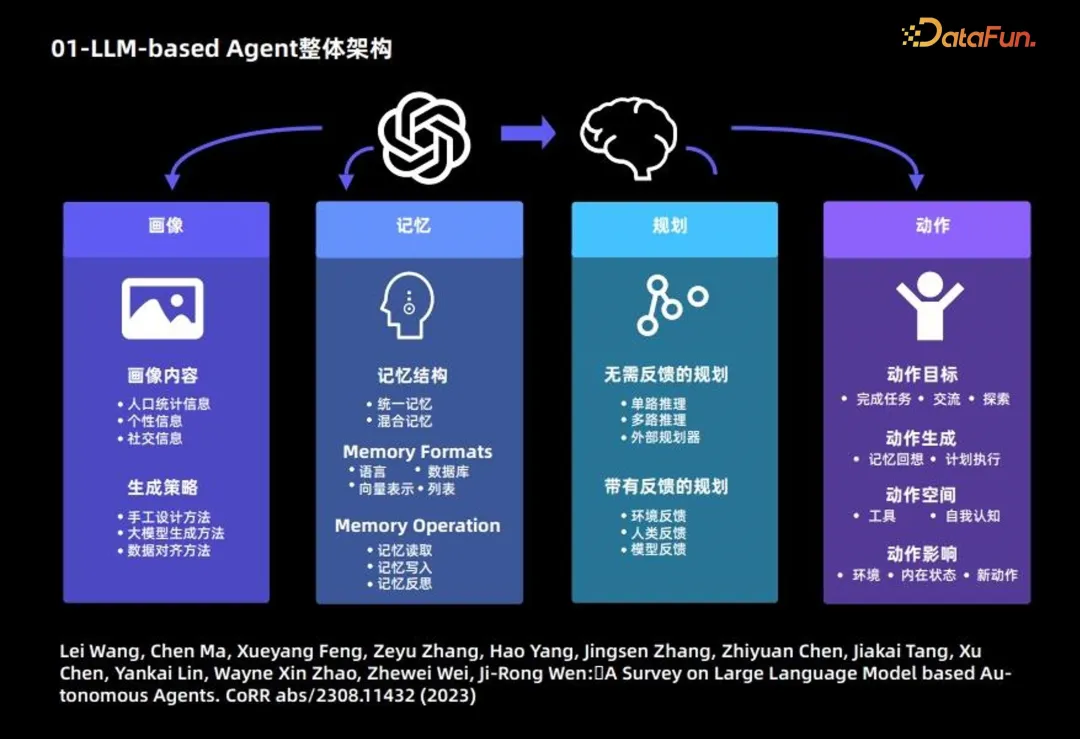
Die Zusammensetzung des großen Sprachmodells Agent ist hauptsächlich in die folgenden 4 Module unterteilt:
1. Porträtmodul: beschreibt hauptsächlich den Hintergrund Informationen des Agenten
Im Folgenden werden der Hauptinhalt und die Generierungsstrategie des Porträtmoduls vorgestellt.
Porträtinhalte basieren hauptsächlich auf drei Arten von Informationen: demografische Informationen, Persönlichkeitsinformationen und soziale Informationen.
Generierungsstrategie: 3 Strategien werden hauptsächlich zum Generieren von Porträtinhalten verwendet:
- Manuelle Entwurfsmethode: Schreiben Sie den Inhalt des Benutzerporträts auf eine bestimmte Weise in die Eingabeaufforderung des großen Modells; anwendbar auf die Nummer von Agenten Relativ wenige Situationen;
- Methode zur Generierung großer Modelle: Geben Sie zunächst eine kleine Anzahl von Porträts an und verwenden Sie diese als Beispiele. Verwenden Sie dann ein großes Sprachmodell, um weitere Porträts zu generieren Agenten;
- Datenausrichtungsmethode: Es ist notwendig, die Hintergrundinformationen der Zeichen im vorab festgelegten Datensatz als Eingabeaufforderung des großen Sprachmodells zu verwenden und dann entsprechende Vorhersagen zu treffen.
2. Speichermodul: Der Hauptzweck besteht darin, das Verhalten des Agenten aufzuzeichnen und Unterstützung für zukünftige Entscheidungen des Agenten bereitzustellen. kein Langzeitgedächtnis.
Hybrides Gedächtnis: Langzeitgedächtnis und Kurzzeitgedächtnis kombiniert.
- Speicherform: Basiert hauptsächlich auf den folgenden 4 Formen.
- Sprache
Datenbank
- Vektordarstellung
- Liste
- Speicherinhalt: Die folgenden 3 gängigen Operationen sind:
- Gedächtnislesen
Gedächtnisschreiben
- Gedächtnisreflexion
- 3. Planungsmodul
- Planung ohne Feedback: großes Sprachmodell im Prozess der Schlussfolgerung Keine Rückmeldung von Die äußere Umgebung ist erforderlich. Diese Art der Planung wird weiter in drei Typen unterteilt: einkanalbasiertes Denken, bei dem ein großes Sprachmodell nur einmal verwendet wird, um die Schritte des mehrkanaligen Denkens vollständig auszugeben, basierend auf der Idee des Crowdsourcing; Ermöglichen Sie dem großen Sprachmodell, mehrere Gründe für den Pfad zu generieren und den besten Pfad zu bestimmen.
Planung mit Feedback: Diese Planungsmethode erfordert Feedback von der externen Umgebung, und das große Sprachmodell erfordert Feedback von der Umgebung für den nächsten Schritt und die anschließende Planung. Anbieter dieser Art von Planungsfeedback kommen aus drei Quellen: Umgebungsfeedback, menschliches Feedback und Modellfeedback.
- 4. Aktionsmodul
- Aktionsziele: Einige Agentenziele bestehen darin, eine Aufgabe zu erledigen, andere darin, zu kommunizieren und andere darin, sie zu erkunden.
Aktionsgenerierung: Einige Agenten verlassen sich auf den Speicherabruf, um Aktionen zu generieren, und andere führen bestimmte Aktionen gemäß dem ursprünglichen Plan aus.
- Aktionsraum: Einige Aktionsräume sind eine Sammlung von Werkzeugen, andere basieren auf dem eigenen Wissen des großen Sprachmodells und betrachten den gesamten Aktionsraum aus der Perspektive des Selbstbewusstseins.
- Aktionsauswirkungen: einschließlich der Auswirkungen auf die Umwelt, der Auswirkungen auf den inneren Zustand und der Auswirkungen auf neue Aktionen in der Zukunft.
- Das Obige ist der Gesamtrahmen von Agent. Weitere Informationen finden Sie in den folgenden Artikeln:
- Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen , Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen: Eine Umfrage zu auf großen Sprachmodellen basierenden autonomen Agenten
2. Wichtige und schwierige Probleme des LLM-basierten Agenten

Zu den wichtigsten und schwierigen Problemen des aktuellen großen Sprachmodells gehören:
1 Wie man die Rollenspielfähigkeiten des Agenten verbessert
Agent Die wichtigste Funktion besteht darin, bestimmte Aufgaben zu erledigen oder verschiedene Simulationen abzuschließen, indem er eine bestimmte Rolle spielt. Daher ist die Rollenspielfähigkeit des Agenten von entscheidender Bedeutung.
(1) Definition der Agent-Rollenspielfähigkeit
Die Agent-Rollenspielfähigkeit ist in zwei Dimensionen unterteilt:
- Charakter- und Agent-Verhaltensbeziehung
- Charakterentwicklungsmechanismus im Umgebung
(2) Bewertung der Rollenspielfähigkeit des Agenten
Nach der Definition der Rollenspielfähigkeit besteht der nächste Schritt darin, die Rollenspielfähigkeit des Agenten anhand der folgenden zwei Aspekte zu bewerten:
- Indikatoren zur Rollenspielbewertung
- Szenario zur Rollenspielbewertung
(3) Verbesserung der Rollenspielfähigkeit des Agenten
Auf der Grundlage der Bewertung die Rollenspielfähigkeit des Agenten Es gibt zwei Arten: Methode:
- Verbesserung der Rollenspielfähigkeiten durch Eingabeaufforderungen: Der Kern dieser Methode besteht darin, die Fähigkeiten des ursprünglichen großen Sprachmodells durch die Gestaltung von Eingabeaufforderungen zu stimulieren Verbesserung der Rollenspielfähigkeiten durch Feinabstimmung: Diese Methode basiert normalerweise auf der Verwendung externer Daten, um das große Sprachmodell erneut zu verfeinern, um die Rollenspielfähigkeiten zu verbessern.
- 2. Wie man den Agent-Speichermechanismus entwirft
Der größte Unterschied zwischen Agent und großem Sprachmodell besteht darin, dass sich der Agent in der Umgebung kontinuierlich weiterentwickeln und selbst lernen kann sehr wichtiger Rollencharakter von. Analysieren Sie den Speichermechanismus des Agenten aus drei Dimensionen:
(1) Design des Agentenspeichermechanismus
Es gibt zwei gängige Speichermechanismen:
- Speichermechanismus basierend auf Vektorabruf
- Speichermechanismus basierend auf der LLM-Zusammenfassung
- Bewertungsszenario
(3) Entwicklung des Agentenspeichermechanismus
Abschließend muss die Entwicklung des Agentenspeichermechanismus analysiert werden, einschließlich:
- „Entwicklung des Speichermechanismus“
- Definition und Zerlegung von Unteraufgaben
- Optimale Reihenfolge der Aufgabenausführung
(2) Integration von Agentenbegründung und externem Feedback
Entwerfen Sie den Integrationsmechanismus von externem Feedback in Der Argumentationsprozess: Lassen Sie den Agenten und die Umgebung ein interaktives Ganzes bilden Andererseits muss der Agent in der Lage sein, Fragen zu stellen und nach Lösungen für die externe Umgebung zu suchen. 4. So entwerfen Sie einen effizienten Mechanismus für die Zusammenarbeit mit mehreren Agenten
- (2) Multi-Agenten-Debattiermechanismus
- Agenten debattieren über Mechanismusdesign
Agenten debattieren über die Bestimmung der Konvergenzbedingung
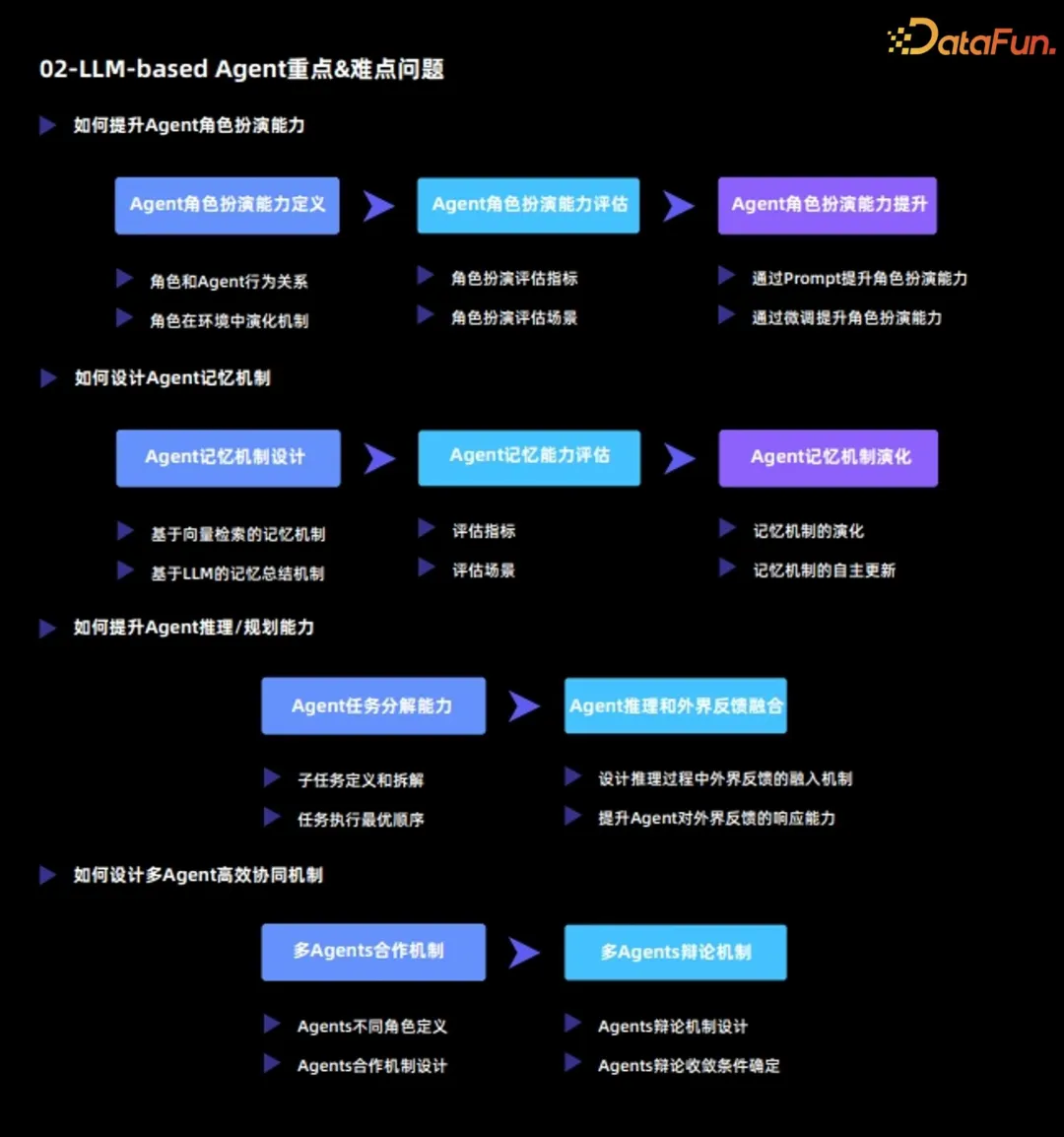
- 3 Basierend auf großen Sprachmodellen Verhaltenssimulationsagent
Hier sind einige tatsächliche Fälle von Agent. Der erste ist ein Agent zur Simulation des Benutzerverhaltens, der auf einem großen Sprachmodell basiert. Dieser Agent ist auch eine frühe Arbeit bei der Kombination großer Sprachmodellagenten mit der Analyse des Benutzerverhaltens. In dieser Arbeit ist jeder Agent in drei Module unterteilt:
- 1. Das Porträtmodul
- spezifiziert verschiedene Attribute für verschiedene Agenten, wie z. B. ID, Name, Beruf, Alter, Interessen, Eigenschaften usw. 2. Gedächtnismodul beobachtet Rohbeobachtungen Nach der Verarbeitung werden Beobachtungen mit höherem Informationsgehalt generiert und im Kurzzeitgedächtnis gespeichert.
- Die Speicherzeit des Kurzzeitgedächtnisinhalts ist relativ kurz. (3) Langfristig Gedächtnis
Nach wiederholter Auslösung und Aktivierung werden die Inhalte des Kurzzeitgedächtnisses automatisch in das Langzeitgedächtnis übertragen. Die Speicherzeit von Langzeitgedächtnisinhalten ist relativ lang Raffinesse.
- 3. Aktionsmodul
- Jeder Agent kann drei Aktionen ausführen:
Das Verhalten des Agenten im Empfehlungssystem, einschließlich Ansehen von Filmen, Finden der nächsten Seite und Verlassen des Empfehlungssystems usw ;
Konversationsverhalten zwischen Agenten
Posting-Verhalten des Agenten in sozialen Medien.Während des gesamten Simulationsprozesses kann ein Agent in jeder Aktionsrunde ohne äußere Einmischung drei Aktionen frei wählen. Wir können sehen, dass verschiedene Agenten miteinander sprechen und auch verschiedene Verhaltensweisen in sozialen Medien autonom generieren oder Empfehlungssysteme; nach mehreren Simulationsrunden lassen sich einige interessante soziale Phänomene sowie die Regeln des Nutzerverhaltens im Internet beobachten.
Weitere Informationen finden Sie in den folgenden Dokumenten:
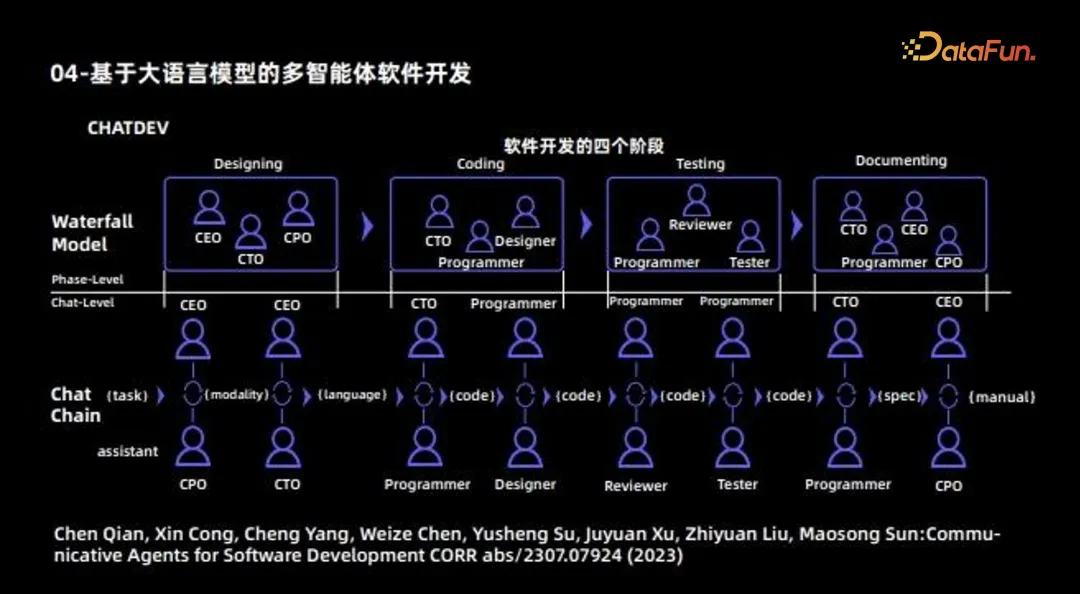
Lei Wang, Jingsen Zhang, Hao Yang, Zhiyuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Ruihua Song, Wayne Xin Zhao, Jun Xu, Zhicheng Dou, Jun Wang, Ji-Rong Wen: Wenn große Sprache Modellbasierter Agent trifft auf Benutzerverhaltensanalyse: Ein neuartiges Benutzersimulationsparadigma Mehrere Agenten führen die Softwareentwicklung durch. Diese Arbeit ist auch eine frühe Arbeit der Zusammenarbeit mit mehreren Agenten und ihr Hauptzweck besteht darin, verschiedene Agenten zu verwenden, um eine vollständige Software zu entwickeln. Daher kann es als Softwareunternehmen betrachtet werden, und verschiedene Agenten spielen unterschiedliche Rollen: Einige Agenten sind für das Design verantwortlich, darunter CEO, CTO, CPO und andere Rollen, und einige Agenten sind hauptsächlich für die Codierung verantwortlich Darüber hinaus wird es einige Agenten geben, die für das Verfassen von Dokumenten verantwortlich sind. Auf diese Weise sind verschiedene Agenten für unterschiedliche Aufgaben verantwortlich. Schließlich wird der Kooperationsmechanismus zwischen Agenten durch Kommunikation koordiniert und aktualisiert, und schließlich wird ein vollständiger Softwareentwicklungsprozess abgeschlossen. 5. Zukünftige Richtungen von LLM-basierten Agenten MetaGPT, ChatDev, Ghost, DESP usw.
Diese Art von Agent sollte letztendlich ein „Superman“ sein, der auf die richtigen menschlichen Werte ausgerichtet ist, mit zwei „Qualifizierern“:
Ausgerichtet auf die richtigen menschlichen WerteÜber gewöhnliche menschliche Fähigkeiten hinaus.
Simulieren Sie die reale Welt, z. B. Generative Agent, Social Simulation, RecAgent usw.
Die für diesen Agententyp erforderlichen Fähigkeiten sind völlig entgegengesetzt zum ersten Typ.
Erlauben Sie Agenten, unterschiedliche Werte zu vertreten.Ich hoffe, dass Agenten ihr Bestes geben sollten, um sich an gewöhnliche Menschen anzupassen, anstatt über gewöhnliche Menschen hinauszugehen.
Darüber hinaus weist das aktuelle große Sprachmodell Agent die folgenden zwei Schwachstellen auf:
-
IllusionsproblemDa der Agent kontinuierlich mit der Umgebung interagieren muss, wird die Illusion jedes Schritts angesammelt Das heißt, es wird einen kumulativen Effekt geben, der das Problem noch ernster macht. Daher muss hier der Illusion großer Modelle mehr Aufmerksamkeit geschenkt werden. Die Lösungen umfassen:
Entwerfen eines effizienten Mensch-Maschine-Kollaborationsrahmens;
Entwerfen - eines effizienten menschlichen Interventionsmechanismus.
EffizienzproblemeWährend des Simulationsprozesses ist die Effizienz ein sehr wichtiges Thema. Die folgende Tabelle fasst den Zeitaufwand verschiedener Agenten mit unterschiedlichen API-Nummern zusammen.
Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Vielen Dank an alle.

Das obige ist der detaillierte Inhalt vonAl Agent – Eine wichtige Implementierungsrichtung im Zeitalter großer Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
In diesem Artikel werden die Ergebnisse von „Local Deployment of Large Language Models in OpenHarmony“ auf der 2. OpenHarmony-Technologiekonferenz demonstriert. Open-Source-Adresse: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Die Implementierungsideen und -schritte bestehen darin, das leichtgewichtige LLM-Modellinferenz-Framework InferLLM auf das OpenHarmony-Standardsystem zu übertragen und ein Binärprodukt zu kompilieren, das auf OpenHarmony ausgeführt werden kann. InferLLM ist ein einfaches und effizientes L
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
