

ReFT (Representation Finetuning) ist eine bahnbrechende Methode, die verspricht, die Art und Weise, wie wir große Sprachmodelle verfeinern, neu zu definieren.
Forscher der Stanford University haben kürzlich (April) einen Artikel über arxiv veröffentlicht. ReFT unterscheidet sich stark von herkömmlichen gewichtsbasierten Feinabstimmungsmethoden und bietet eine effizientere und effektivere Methode zur Anpassung an diese groß angelegten Modelle Passen Sie sich neuen Aufgaben und Domänen an!

Bevor wir dieses Papier vorstellen, werfen wir einen Blick auf PeFT.
Parameter Efficient Fine-Tuning (PEFT) ist eine effiziente Feinabstimmungsmethode zur Feinabstimmung einer kleinen Anzahl oder zusätzlicher Modellparameter. Im Vergleich zu herkömmlichen Feinabstimmungsmethoden für Vorhersagenetzwerke kann die Feinabstimmung mithilfe von PEFT die Rechen- und Speicherkosten erheblich senken und gleichzeitig eine mit der vollständigen Feinabstimmung vergleichbare Leistung gewährleisten. Diese Technologie hat ein breites Anwendungsspektrum und kann eine mit Volltrimmen vergleichbare Leistung erzielen.
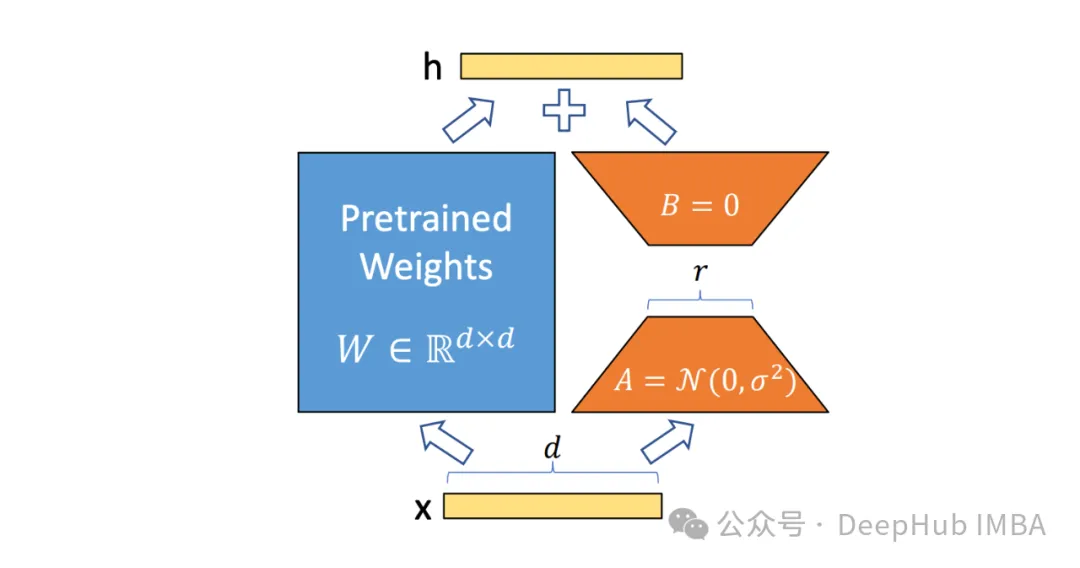
Basierend auf der Idee von PeFT wurde die uns sehr vertraute LoRA entwickelt, und es gibt verschiedene Varianten von LoRA. Zu den häufig verwendeten PeFT-Methoden gehören:
Präfix-Tuning: Durch virtuelles Token wird eine kontinuierliche implizite Eingabeaufforderung erstellt, eine Methode, die 2021 von Stanford veröffentlicht wurde.
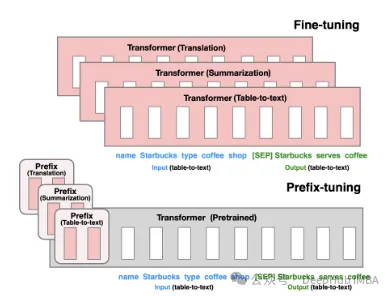
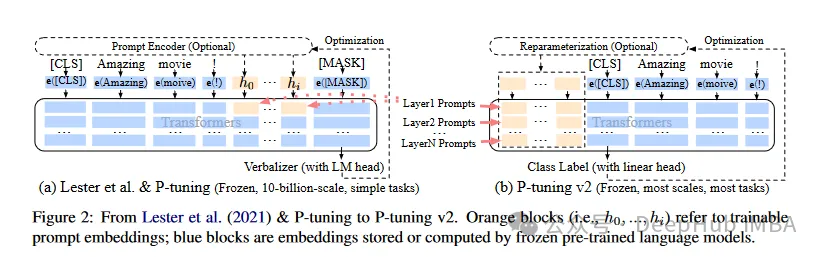
P-Tuning V1/V2 ist eine von der Tsinghua-Universität im Jahr 2021 vorgeschlagene Technologie mit dem Ziel, diskrete Modelle natürlicher Sprache in trainierbare implizite Eingabeaufforderungen (kontinuierliche Parameteroptimierungsprobleme) umzuwandeln. Die V2-Version verbessert die Leistung der V1-Version weiter, indem jeder Ebene vor der Eingabe fein abstimmbare Parameter hinzugefügt werden. Diese Methode erweitert effektiv den Anwendungsbereich und die Flexibilität des Modells.
Dann gibt es noch LoRA, das uns am längsten bekannt ist und das ich hier nicht im Detail vorstellen werde. Wir können es im engeren Sinne verstehen, dass LoRA derzeit die beste PeFT-Methode ist. was für den unten vorgestellten ReFT-Kontrast besser sein kann.
ReFT (Representation Finetuning) ist eine Gruppe von Methoden, die sich darauf konzentrieren, in das verborgene Repräsentationslernen des Sprachmodells während des Inferenzprozesses einzugreifen, anstatt seine Gewichte direkt zu modifizieren.
Im Gegensatz zu herkömmlichen Feinabstimmungsmethoden, die den gesamten Parametersatz eines Modells aktualisieren, funktioniert ReFT durch die strategische Manipulation kleiner Teile der Darstellung eines Modells und steuert so sein Verhalten, um nachgelagerte Aufgaben effizienter zu lösen.
Die Kernidee von ReFT ist von neueren Forschungen zur Interpretierbarkeit von Sprachmodellen inspiriert: In den von diesen Modellen erlernten Darstellungen sind umfangreiche semantische Informationen kodiert. Durch den Eingriff in diese Darstellungen zielt ReFT darauf ab, dieses codierte Wissen freizuschalten und zu nutzen und so eine effizientere und effektivere Modellanpassung zu ermöglichen.
Ein wesentlicher Vorteil von ReFT ist seine Parametereffizienz: Traditionelle Feinabstimmungsmethoden erfordern die Aktualisierung eines großen Teils der Modellparameter, was rechenintensiv und ressourcenintensiv sein kann, insbesondere bei großen Sprachmodellen mit Milliarden von Parametern. ReFT-Methoden erfordern typischerweise für das Training um Größenordnungen weniger Parameter, was zu schnelleren Trainingszeiten und weniger Speicherbedarf führt.
Der Schwerpunkt liegt auf der Änderung der Gewichte des Modells oder der Einführung zusätzlicher Gewichtsmatrizen. ReFT-Methoden verändern die Gewichte des Modells nicht direkt; sie beeinträchtigen die vom Modell während des Vorwärtsdurchlaufs berechnete verborgene Darstellung.
PEFT-Methoden wie LoRA und DoRA lernen Gewichtsaktualisierungen oder Low-Rank-Approximationen der Modellgewichtsmatrix. Diese Gewichtsaktualisierungen werden dann während der Inferenz in die Gewichte des Basismodells integriert, was zu keinem zusätzlichen Rechenaufwand führt. ReFT-Methoden lernen, während der Inferenz einzugreifen und die Darstellung des Modells auf bestimmten Ebenen und an bestimmten Orten zu manipulieren. Dieser Eingriffsprozess erfordert einen gewissen Rechenaufwand, ermöglicht jedoch eine effizientere Anpassung.
Die Hauptmotivation der PEFT-Methode ist die Notwendigkeit einer effektiven Anpassung von Parametern, die den Rechenaufwand und den Speicherbedarf beim Optimieren großer Sprachmodelle reduziert. ReFT-Methoden hingegen sind von neueren Forschungen zur Interpretierbarkeit von Sprachmodellen inspiriert, die zeigen, dass in den von diesen Modellen erlernten Darstellungen umfangreiche semantische Informationen kodiert sind. Das Ziel von ReFT besteht darin, dieses codierte Wissen zu nutzen und zu nutzen, um das Modell effizienter anzupassen.
Sowohl PEFT- als auch ReFT-Methoden sind auf Parametereffizienz ausgelegt, aber die ReFT-Methode hat sich in der Praxis als höhere Parametereffizienz erwiesen. Beispielsweise erfordern LoReFT-Methoden (Low-Rank Linear Subspace ReFT) in der Regel 10–50 Mal weniger Parameter zum Trainieren als die hochmoderne PEFT-Methode (LoRA) und erzielen gleichzeitig eine wettbewerbsfähige oder bessere Leistung bei verschiedenen NLP-Benchmarks.
Während die PEFT-Methode hauptsächlich auf eine effiziente Anpassung setzt, bietet die ReFT-Methode zusätzliche Vorteile hinsichtlich der Interpretierbarkeit. Durch den Eingriff in Darstellungen, von denen bekannt ist, dass sie bestimmte semantische Informationen kodieren, können ReFT-Methoden Erkenntnisse darüber liefern, wie Sprachmodelle Sprache verarbeiten und verstehen, was möglicherweise zu transparenteren und vertrauenswürdigeren Systemen der künstlichen Intelligenz führt.
Die ReFT-Modellarchitektur definiert das allgemeine Konzept der Intervention, was im Wesentlichen eine Änderung der verborgenen Darstellung während des Vorwärtsdurchlaufs des Modells bedeutet. Wir betrachten zunächst ein transformatorbasiertes Sprachmodell, das kontextualisierte Darstellungen von Token-Sequenzen generiert.
Gegeben eine Folge von n Eingabe-Tokens x = (x₁,…,xn), bettet das Modell sie zunächst in eine Liste von Darstellungen ein, und zwar in Form von h₁,…,hn. Dann berechnet die m-Schicht kontinuierlich die j-te verborgene Darstellung. Jede verborgene Darstellung ist ein Vektor h∈λ, wobei d die Dimension der Darstellung ist.
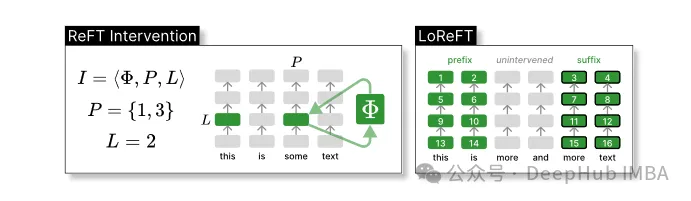
ReFT definiert das Konzept eines Eingriffs, der die verborgene Darstellung während des Vorwärtsdurchlaufs des Modells verändert.
Intervention I ist ein Tupel ⟨Φ, P, L , das die Interventionsaktion einer einzelnen Inferenzzeit kapselt, die durch die transformatorbasierte LM-Berechnung dargestellt wird. Diese Funktion enthält drei Parameter:
Interventionsfunktion Φ: dargestellt durch den gelernten Parameter Φ (Φ).
Der Satz von Eingabepositionen P≤{1,…,n}, auf die der Eingriff angewendet wird.
Auf Schicht L∈{1,…,m} eingreifen.
Dann ist die Aktion des Eingriffs wie folgt:
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}Dieser Eingriff wird unmittelbar nach Abschluss der Vorwärtsausbreitungsberechnung durchgeführt, sodass er sich auf die in nachfolgenden Schichten berechnete Darstellung auswirkt.
Um die Effizienz der Berechnung zu verbessern, können die Interventionsgewichte auch in niedrigrangige zerlegt werden, um einen linearen Unterraum-ReFT (LoReFT) mit niedrigem Rang zu erhalten.
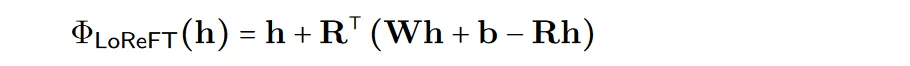
Verwenden Sie die erlernte Projektionsquelle Rs = Wh +b in der obigen Formel. LoReFT bearbeitet die Darstellung im R-dimensionalen Unterraum von R-Spalten, um die aus unserer linearen Projektion Wh + b erhaltenen Werte zu übernehmen.
Für Generierungsaufgaben nutzt das ReFT-Papier das Trainingsziel der Sprachmodellierung und konzentriert sich auf die Minimierung des Kreuzentropieverlusts über alle Ausgabepositionen hinweg. Codebeispiel für die Pyreft-Bibliothek
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))Abschließend werfen wir einen Blick auf die hervorragende Leistung in verschiedenen NLP-Benchmarks. Im Folgenden finden Sie die von Forschern der Stanford University gezeigten Daten.
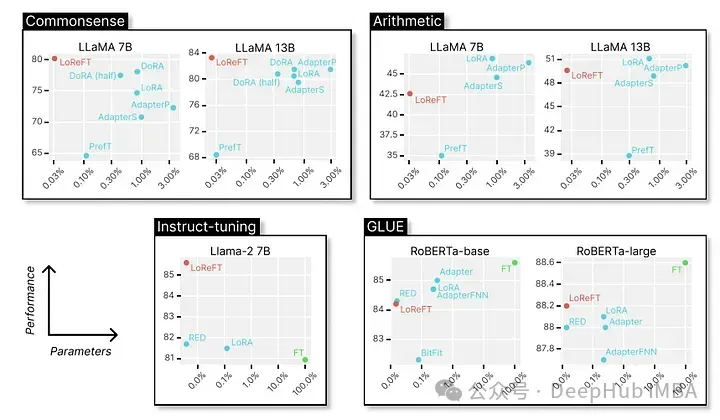
LoReFT erreicht modernste Leistung bei 8 anspruchsvollen Datensätzen, darunter BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c und OBQA. Obwohl LoReFT deutlich weniger Parameter als bestehende PEFT-Methoden verwendet (10-50x weniger), übertrifft es alle anderen Methoden deutlich und demonstriert seine Wirksamkeit bei der Erfassung und Nutzung des in großen Sprachmodellen kodierten gesunden Menschenverstandes.
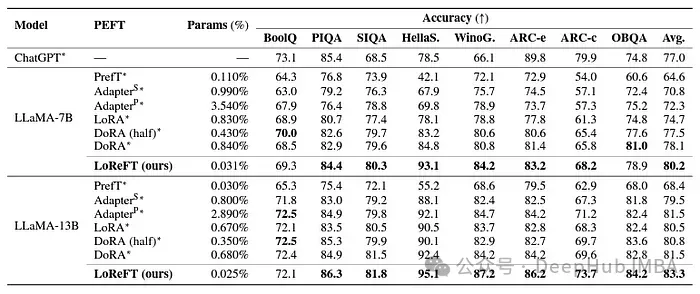
Obwohl LoReFT bestehende PEFT-Methoden bei mathematischen Denkaufgaben nicht übertrifft, zeigt es eine wettbewerbsfähige Leistung bei Datensätzen wie AQuA, GSM8K, MAWPS und SVAMP. Die Forscher stellten fest, dass sich die Leistung von LoReFT mit der Modellgröße verbessert, was darauf hindeutet, dass seine Fähigkeiten mit dem weiteren Wachstum der Sprachmodelle zunehmen.
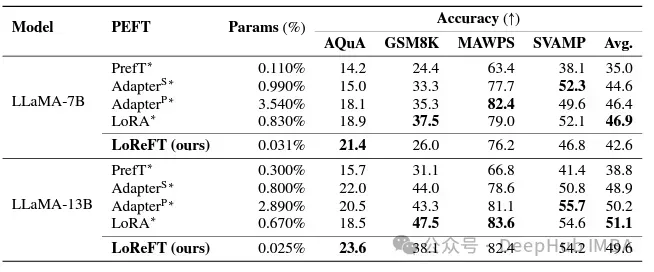
Im Bereich der Befehlskonformität hat LoReFT bemerkenswerte Ergebnisse erzielt und alle Feinabstimmungsmethoden des Alpaca-Eval v1.0-Benchmarks übertroffen, einschließlich der vollständigen Feinabstimmung (beachten Sie dies). Beim Training mit dem Lama-27b-Modell ist LoReFT 1 % besser als das GPT-3.5-Turbo-Modell und verwendet weitaus weniger Parameter als andere PEFT-Methoden.
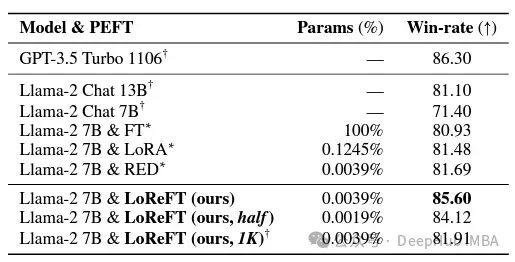
LoReFT demonstriert auch seine Fähigkeiten bei Aufgaben zum Verstehen natürlicher Sprache und erreicht beim GLUE-Benchmark eine vergleichbare Leistung wie bestehende PEFT-Methoden, wenn es auf RoBERTa-Basis- und RoBERTa-große Modelle angewendet wird.
Beim Vergleich der zuvor effektivsten PEFT-Methode in Bezug auf die Anzahl der Parameter erzielte LoReFT ähnliche Ergebnisse bei einer Vielzahl von Aufgaben, einschließlich Stimmungsanalyse und Argumentation in natürlicher Sprache.
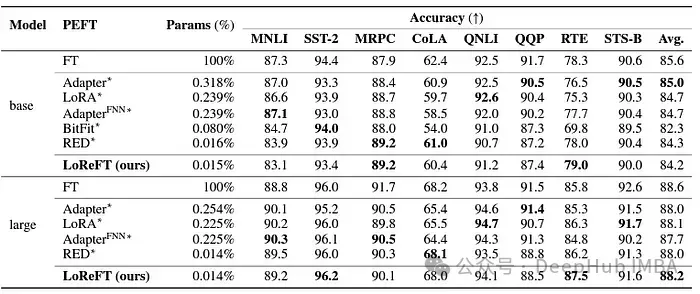
Der Erfolg von ReFT, insbesondere LoReFT, ist von großer Bedeutung für die Zukunft der Verarbeitung natürlicher Sprache und die praktische Anwendung großer Sprachmodelle. Die Parametereffizienz von ReFT macht es zu einer effektiven Lösung für die Anpassung großer Sprachmodelle an bestimmte Aufgaben oder Domänen bei gleichzeitiger Minimierung von Rechenressourcen und Trainingszeit.
Und ReFT bietet auch eine einzigartige Perspektive, um die Interpretierbarkeit großer Sprachmodelle zu verbessern. Der Erfolg bei Aufgaben wie dem gesunden Menschenverstand, dem arithmetischen Denken und dem Befolgen von Anweisungen zeigt die Wirksamkeit dieses Ansatzes. Derzeit wird erwartet, dass ReFT neue Möglichkeiten eröffnet und die Einschränkungen traditioneller Tuning-Methoden überwindet.
Das obige ist der detaillierte Inhalt vonReFT (Representation Fine-tuning): eine neue Technologie zur Feinabstimmung großer Sprachmodelle, die besser als PeFT ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



