
 Technologie-Peripheriegeräte
KI
Inspiriert durch den Optimierungsalgorithmus erster Ordnung schlug das Team von Lin Zhouchen von der Peking-Universität eine Entwurfsmethode für die Architektur neuronaler Netzwerke mit universellen Approximationseigenschaften vor.
Technologie-Peripheriegeräte
KI
Inspiriert durch den Optimierungsalgorithmus erster Ordnung schlug das Team von Lin Zhouchen von der Peking-Universität eine Entwurfsmethode für die Architektur neuronaler Netzwerke mit universellen Approximationseigenschaften vor.
Inspiriert durch den Optimierungsalgorithmus erster Ordnung schlug das Team von Lin Zhouchen von der Peking-Universität eine Entwurfsmethode für die Architektur neuronaler Netzwerke mit universellen Approximationseigenschaften vor.

Als Grundlage der Deep-Learning-Technologie haben neuronale Netze in vielen Anwendungsbereichen effektive Ergebnisse erzielt. In der Praxis kann die Netzwerkarchitektur die Lerneffizienz erheblich beeinflussen. Eine gute neuronale Netzwerkarchitektur kann Vorkenntnisse über das Problem einbeziehen, Netzwerktraining etablieren und die Recheneffizienz verbessern. Zu den klassischen Entwurfsmethoden für Netzwerkarchitekturen gehören derzeit der manuelle Entwurf, die Suche nach neuronalen Netzwerkarchitekturen (NAS) [1] und optimierungsbasierte Netzwerkentwurfsmethoden [2]. Künstlich entworfene Netzwerkarchitekturen wie ResNet usw.; die Suche nach der besten Netzwerkstruktur im Suchraum ist ein gängiges Paradigma bei optimierungsbasierten Entwurfsmethoden. Diese Methode entwirft normalerweise das Netzwerk Struktur aus der Sicht eines Optimierungsalgorithmus mit einer expliziten Zielfunktion. Diese Methoden entwerfen die Netzwerkstruktur aus der Perspektive des Optimierungsalgorithmus, während sie die Netzwerkstruktur aus der Perspektive des Optimierungsalgorithmus entwerfen.
Heutzutage ignorieren die meisten klassischen Architekturdesigns neuronaler Netzwerke die universelle Näherung des Netzwerks – dies ist einer der Schlüsselfaktoren für die leistungsstarke Leistung neuronaler Netzwerke. Daher verlieren diese Entwurfsmethoden bis zu einem gewissen Grad die A-priori-Leistungsgarantie des Netzwerks. Obwohl das zweischichtige neuronale Netzwerk universelle Approximationseigenschaften aufweist, wenn die Breite gegen Unendlich geht [3], können wir in der Praxis normalerweise nur Netzwerkstrukturen mit begrenzter Breite berücksichtigen, und die Ergebnisse der Leistungsanalyse in diesem Bereich sind sehr begrenzt. Tatsächlich ist es schwierig, die universelle Approximationseigenschaft beim Netzwerkdesign zu berücksichtigen, unabhängig davon, ob es sich um ein heuristisches künstliches Design oder eine Black-Box-Suche nach neuronalen Netzwerkarchitekturen handelt. Obwohl der optimierungsbasierte Entwurf neuronaler Netzwerke relativ besser interpretierbar ist, erfordert er normalerweise eine offensichtliche Zielfunktion, was zu einer begrenzten Vielfalt entworfener Netzwerkstrukturen führt und seinen Anwendungsbereich einschränkt. Wie man neuronale Netzwerkarchitekturen mit universellen Approximationseigenschaften systematisch entwerfen kann, bleibt eine wichtige Frage.
Das Team von Professor Lin Zhouchen von der Peking-Universität schlug eine neuronale Netzwerkarchitektur vor, die auf Entwurfstools für Optimierungsalgorithmen basiert. Diese Methode verbessert die Trainingsgeschwindigkeit durch die Kombination des Gradienten-basierten Optimierungsalgorithmus erster Ordnung mit dem Hash-basierten Optimierungsalgorithmus zweiter Ordnung Optimierungsalgorithmus und Konvergenzleistung und verbessert die Robustheitsgarantie des neuronalen Netzwerks. Dieses neuronale Netzwerkmodul kann auch mit bestehenden modularitätsbasierten Netzwerkentwurfsmethoden verwendet werden und verbessert die Modellleistung weiter. Kürzlich analysierten sie die Approximationseigenschaften neuronaler Netzwerkdifferentialgleichungen (NODE) und bewiesen, dass schichtübergreifend verbundene neuronale Netzwerke universelle Approximationseigenschaften haben. Sie verwendeten das vorgeschlagene Framework auch zum Entwerfen von Variantennetzwerken wie ConvNext und ViT und erzielten Ergebnisse das übertraf die Grundlinie. Das Papier wurde von TPAMI, der führenden Fachzeitschrift für künstliche Intelligenz, angenommen.

- Aufsatz: Designing Universally Approximating Deep Neural Networks: A First Order Optimization Approach
- Aufsatzadresse: https://ieeexplore.ieee.org/document/10477580
Methode Einführung
Traditionelle optimierungsbasierte Entwurfsmethoden für neuronale Netze gehen oft von einer Zielfunktion mit einem expliziten Ausdruck aus, verwenden einen bestimmten Optimierungsalgorithmus zur Lösung und ordnen die Optimierungsergebnisse dann einer neuronalen Netzstruktur wie der berühmten LISTA zu - NN ist ein expliziter Ausdruck, der durch die Verwendung des LISTA-Algorithmus zur Lösung des LASSO-Problems erhalten wird und die Optimierungsergebnisse in eine neuronale Netzwerkstruktur umwandelt [4]. Diese Methode ist stark vom expliziten Ausdruck der Zielfunktion abhängig, sodass die resultierende Netzwerkstruktur nur für den expliziten Ausdruck der Zielfunktion optimiert werden kann und das Risiko besteht, Annahmen zu entwerfen, die nicht der tatsächlichen Situation entsprechen. Einige Forscher versuchen, die Netzwerkstruktur zu entwerfen, indem sie die Zielfunktion anpassen und dann Methoden wie die Algorithmuserweiterung verwenden. Sie erfordern jedoch auch Annahmen wie die Neubindung der Gewichtung, die in tatsächlichen Situationen möglicherweise nicht unbedingt den Annahmen entsprechen. Daher haben einige Forscher vorgeschlagen, evolutionäre Algorithmen auf Basis neuronaler Netze zu verwenden, um nach Netzwerkarchitekturen zu suchen und eine vernünftigere Netzwerkstruktur zu erhalten.
Das aktualisierte Format des Netzwerkarchitektur-Entwurfsplans sollte der Idee vom Optimierungsalgorithmus erster Ordnung zum Algorithmus für nähere Punkte folgen und eine schrittweise Optimierung durchführen. Beispielsweise kann der Euler-Winkelalgorithmus in den Quaternion-Algorithmus geändert werden oder ein effizienterer iterativer Algorithmus zur Approximation der Lösung verwendet werden. Das aktualisierte Format sollte eine Erhöhung der Berechnungsgenauigkeit und eine Verbesserung der Betriebseffizienz berücksichtigen.
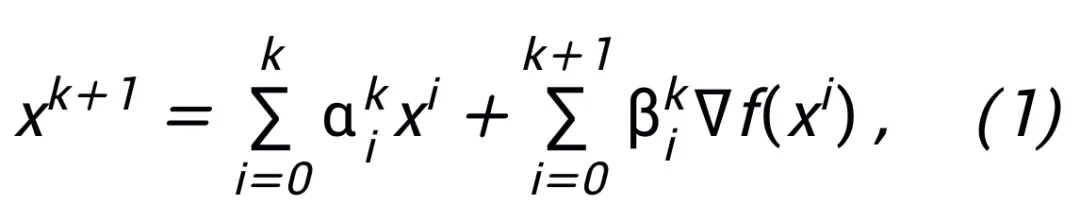
wobei 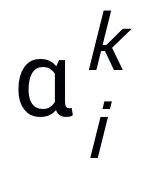 und
und 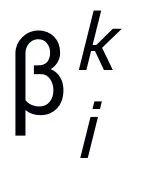 den (Schrittgrößen-)Koeffizienten bei der Aktualisierung des k-ten Schritts darstellen und dann den Gradiententerm durch das lernbare Modul T im neuronalen Netzwerk ersetzen, um das Skelett des neuronalen Netzwerks der L-Schicht zu erhalten:
den (Schrittgrößen-)Koeffizienten bei der Aktualisierung des k-ten Schritts darstellen und dann den Gradiententerm durch das lernbare Modul T im neuronalen Netzwerk ersetzen, um das Skelett des neuronalen Netzwerks der L-Schicht zu erhalten:
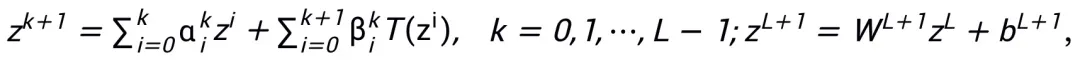
Das gesamte Methodengerüst ist in Abbildung 1 dargestellt.
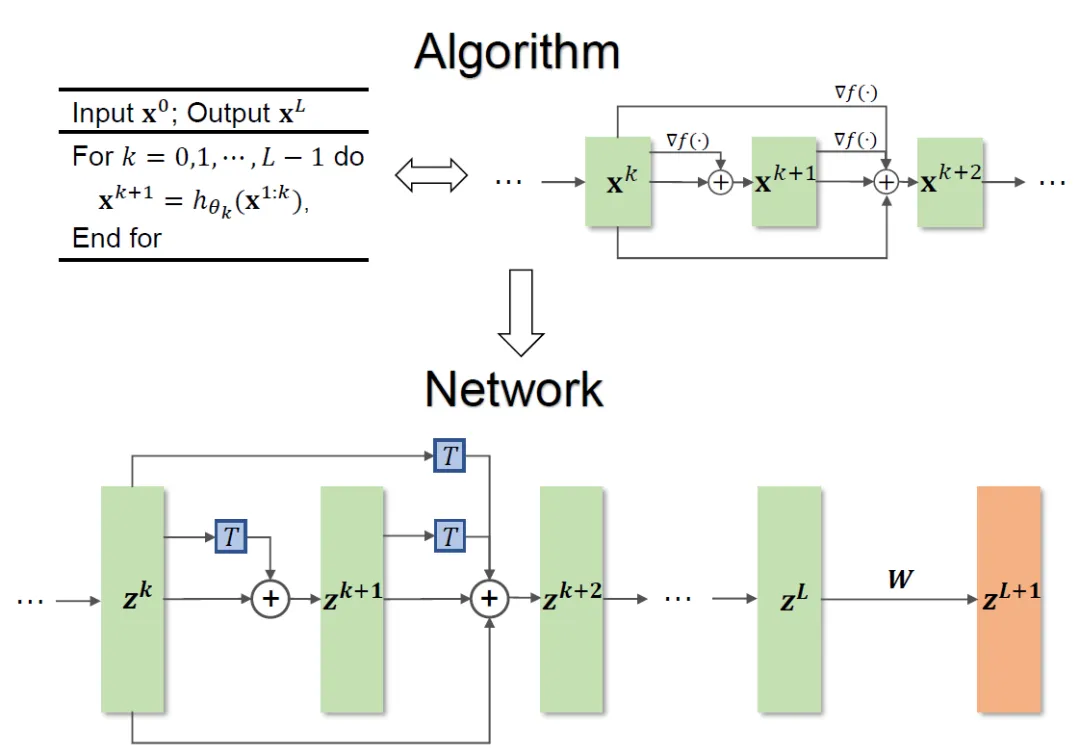
Abbildung 1 Illustration des Netzwerkdesigns
Die im Artikel vorgeschlagene Methode kann das Design klassischer Netzwerke wie ResNet und DenseNet inspirieren und löst das Problem, das herkömmliche Methoden auf der Optimierung des Netzwerkarchitekturdesigns basieren sind auf bestimmte Zielfunktionen beschränkt.
Modulauswahl und Architekturdetails
Das mit dieser Methode entworfene Netzwerkmodul T erfordert lediglich eine zweischichtige Netzwerkstruktur, d hat eine universelle Näherungseigenschaft, bei der die Breite der ausgedrückten Schicht begrenzt ist 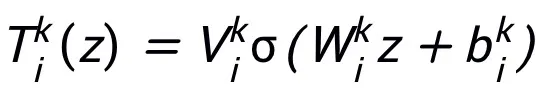 (das heißt, sie wächst nicht mit der Verbesserung der Näherungsgenauigkeit), und die universelle Näherungseigenschaft des gesamten Netzwerks wird nicht durch Verbreiterung erhalten Schichten. Modul T kann der in ResNet weit verbreitete Voraktivierungsblock oder die Aufmerksamkeits- und Feedforward-Schichtstruktur in Transformer sein. Die Aktivierungsfunktion in T kann eine allgemeine Aktivierungsfunktion wie ReLU, GeLU, Sigmoid usw. sein. Je nach Aufgabenstellung können auch entsprechende Normalisierungsschichten eingefügt werden. Wenn
(das heißt, sie wächst nicht mit der Verbesserung der Näherungsgenauigkeit), und die universelle Näherungseigenschaft des gesamten Netzwerks wird nicht durch Verbreiterung erhalten Schichten. Modul T kann der in ResNet weit verbreitete Voraktivierungsblock oder die Aufmerksamkeits- und Feedforward-Schichtstruktur in Transformer sein. Die Aktivierungsfunktion in T kann eine allgemeine Aktivierungsfunktion wie ReLU, GeLU, Sigmoid usw. sein. Je nach Aufgabenstellung können auch entsprechende Normalisierungsschichten eingefügt werden. Wenn 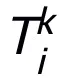 ist, ist das entworfene Netzwerk außerdem ein implizites Netzwerk [5], und die Festkomma-Iterationsmethode kann verwendet werden, um das implizite Format anzunähern, oder die implizite Differenzierungsmethode kann verwendet werden, um den Gradienten für die Aktualisierung zu lösen.
ist, ist das entworfene Netzwerk außerdem ein implizites Netzwerk [5], und die Festkomma-Iterationsmethode kann verwendet werden, um das implizite Format anzunähern, oder die implizite Differenzierungsmethode kann verwendet werden, um den Gradienten für die Aktualisierung zu lösen. 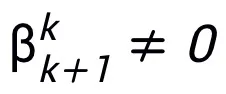
Diese Methode erfordert nicht, dass derselbe Algorithmus nur einer Struktur entsprechen kann. Im Gegenteil, diese Methode kann die äquivalente Darstellung von Optimierungsproblemen verwenden, um mehr Netzwerke zu entwerfen Architekturen, was seine Flexibilität widerspiegelt. Beispielsweise wird die Methode des linearisierten Wechselrichtungsmultiplikators häufig verwendet, um eingeschränkte Optimierungsprobleme zu lösen: inspiriert Siehe Abbildung 2.
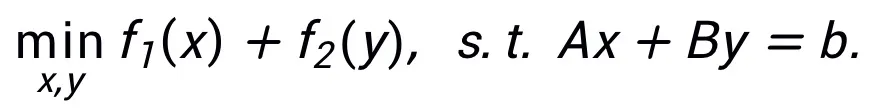 Abbildung 2 Netzwerkstruktur, inspiriert durch die linearisierte Wechselrichtungsmultiplikatormethode
Abbildung 2 Netzwerkstruktur, inspiriert durch die linearisierte Wechselrichtungsmultiplikatormethode 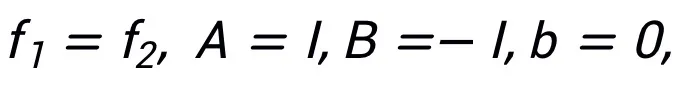
Das inspirierte Netzwerk hat universelle Approximationseigenschaften
L'architecture de réseau conçue par cette méthode peut prouver que, sous la condition que le module remplisse les conditions précédentes et que l'algorithme d'optimisation (en général) soit stable et convergent, le réseau de neurones inspiré de tout algorithme d'optimisation de premier ordre a les éléments suivants caractéristiques dans l'espace fonctionnel continu de grande dimension Toutes les propriétés d'approximation sont données et la vitesse d'approximation est donnée. Pour la première fois, l'article prouve les propriétés d'approximation universelle des réseaux de neurones avec des connexions inter-couches générales dans le cadre de largeur limitée (les recherches précédentes se sont essentiellement concentrées sur FCNN et ResNet, voir le tableau 1). être brièvement décrit comme suit :
Théorème principal (version courte) : Soit  A un algorithme d'optimisation de gradient du premier ordre. Si l'algorithme A a le format de mise à jour de la formule (1) et satisfait à la condition de convergence (les sélections de pas communes pour les algorithmes d'optimisation satisfont toutes à la condition de convergence. S'ils peuvent tous être appris dans le réseau heuristique, cette condition n'est pas requise), le neurone réseau inspiré de l'algorithme :
A un algorithme d'optimisation de gradient du premier ordre. Si l'algorithme A a le format de mise à jour de la formule (1) et satisfait à la condition de convergence (les sélections de pas communes pour les algorithmes d'optimisation satisfont toutes à la condition de convergence. S'ils peuvent tous être appris dans le réseau heuristique, cette condition n'est pas requise), le neurone réseau inspiré de l'algorithme :
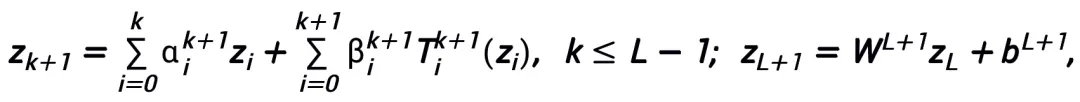
a des propriétés d'approximation universelles sous l'espace fonctionnel continu (à valeur vectorielle) 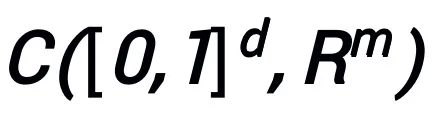 et la norme
et la norme 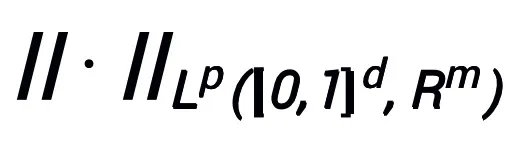 , où le module apprenable T n'a besoin que de contenir deux structures A avec une forme de couche comme
, où le module apprenable T n'a besoin que de contenir deux structures A avec une forme de couche comme  (σ peut être une fonction d'activation couramment utilisée) peut être utilisée comme sous-structure.
(σ peut être une fonction d'activation couramment utilisée) peut être utilisée comme sous-structure.
Les structures T couramment utilisées sont :
1) Dans le réseau convolutif, bloc de pré-activation : BN-ReLU-Conv-BN-ReLU-Conv (z),
2) Dans Transformer : Attn (z) + MLP (z+Attn (z)). La preuve du théorème principal utilise la propriété d'approximation universelle de NODE et la propriété de convergence de la méthode linéaire multi-étapes. la conception de l'algorithme d'optimisation. La structure correspond à la discrétisation de NODE continu par une méthode linéaire convergente multi-étapes, ainsi le réseau inspiré "hérite" de la capacité d'approximation de NODE. Dans la preuve, l'article donne également la vitesse d'approximation de NODE pour approximer une fonction continue dans un espace à d dimensions, ce qui résout un problème restant de l'article précédent [6].
Tableau 1 Recherches antérieures sur les propriétés d'approximation universelle essentiellement axées sur FCNN et ResNet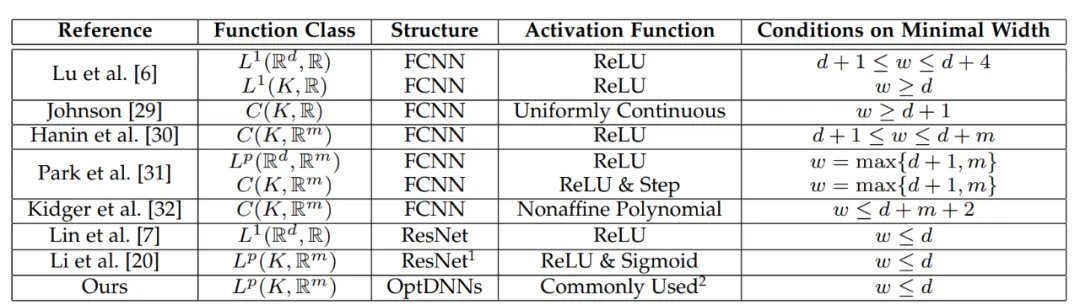
Résultats expérimentaux
L'article utilise le cadre de conception d'architecture de réseau proposé pour concevoir 8 réseaux explicites et 3 réseaux implicites (appelé OptDNN), les informations sur le réseau sont présentées dans le tableau 2 et des expériences ont été menées sur des questions telles que la séparation des anneaux imbriqués, l'approximation des fonctions et la classification des images. L'article utilise également ResNet, DenseNet, ConvNext et ViT comme références, utilise la méthode proposée pour concevoir un OptDNN amélioré et mène des expériences sur le problème de la classification des images, en considérant les deux indicateurs de précision et de FLOP.
Tableau 2 Informations pertinentes du réseau conçu 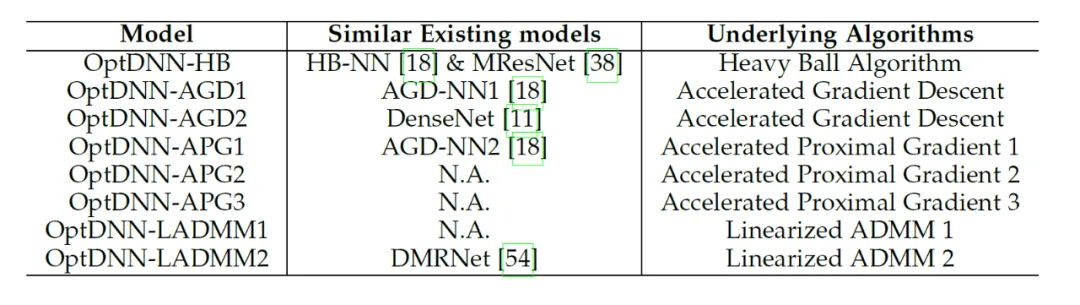
Tout d'abord, OptDNN mène des expériences sur deux problèmes : la séparation des anneaux imbriqués et l'approximation des fonctions pour vérifier ses propriétés d'approximation universelle. Dans le problème d'approximation de fonctions, la fonction de parité d'approximation et la fonction de Talgarsky sont considérées respectivement. La première peut être exprimée comme un problème de classification binaire et la seconde est un problème de régression. Les deux problèmes sont difficiles à approximer par des réseaux peu profonds. Les résultats expérimentaux d'OptDNN dans la séparation des anneaux imbriqués sont présentés dans la figure 3, et les résultats expérimentaux dans l'approximation des fonctions sont présentés dans la figure 3. OptDNN a non seulement obtenu de bons résultats de séparation/approximation, mais a également obtenu de meilleurs résultats que ResNet comme référence. un intervalle de classification et une erreur de régression plus petite suffisent pour vérifier les propriétés d'approximation universelle d'OptDNN.
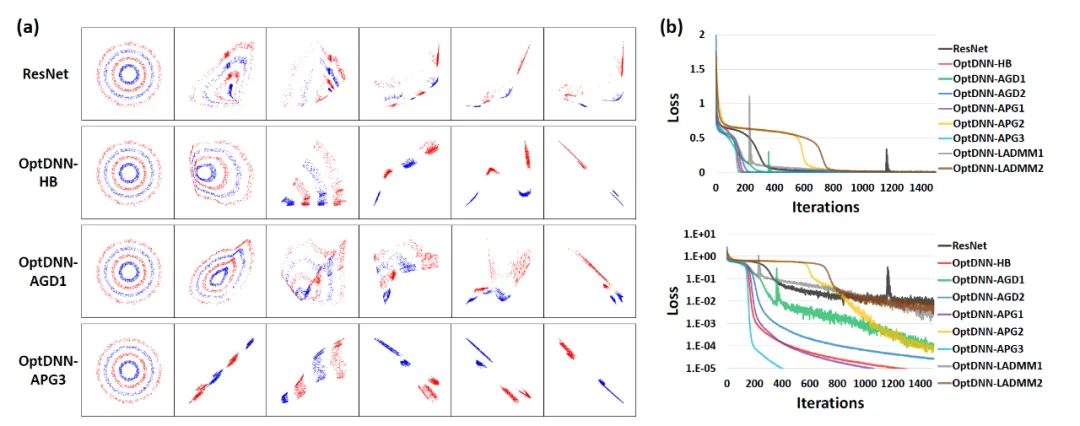
Figure 3 OptNN approchant la fonction de parité
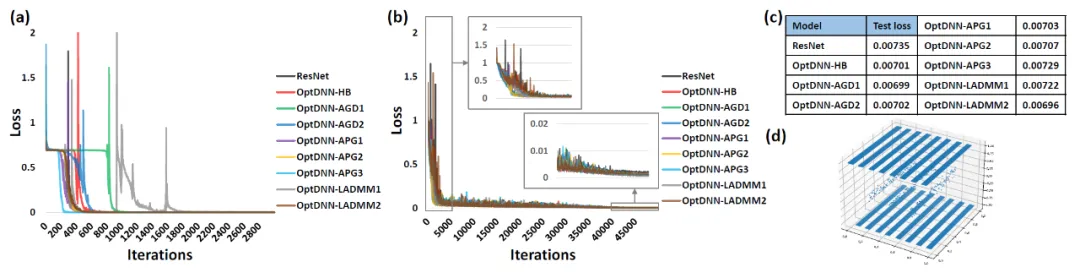
Figure 4 OptNN approchant la fonction de Talgarsky
Ensuite, OptDNN fonctionne en CIF sous la fonction large-peu profonde et étroite -paramètres profonds respectivement .AR Une expérience sur la tâche de classification d'images a été menée sur l'ensemble de données et les résultats sont présentés dans les tableaux 3 et 4. Les expériences ont toutes été menées dans des paramètres d'augmentation de données forts. On peut voir que certains OptDNN ont atteint des taux d'erreur plus faibles que ResNet avec une surcharge de FLOP identique ou même inférieure. L'article a également mené des expériences dans les paramètres ResNet et DenseNet et a obtenu des résultats expérimentaux similaires.
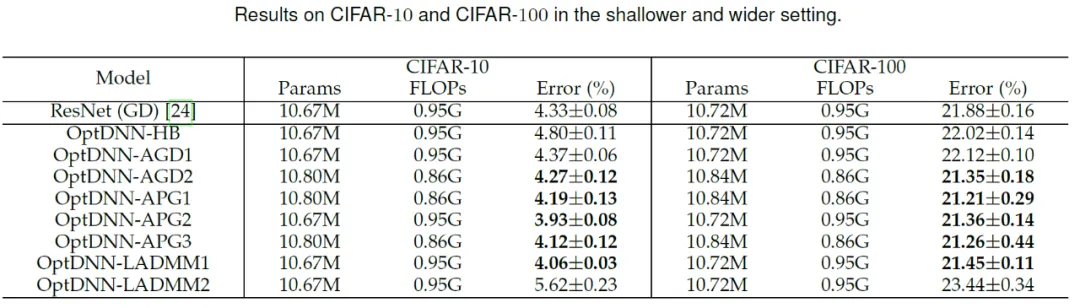
Tableau 3 Résultats expérimentaux de l'OPTDNN dans des paramètres à large évent Le réseau APG2 a été testé davantage sur l'ensemble de données ImageNet sous les paramètres de ConvNext et ViT. La structure du réseau OptDNN-APG2 est présentée à la figure 5 et les résultats expérimentaux figurent dans les tableaux 5 et 6. OptDNN-APG2 a atteint une précision qui dépassait ConvNext et ViT de largeur égale, vérifiant ainsi la fiabilité de cette méthode de conception d'architecture.
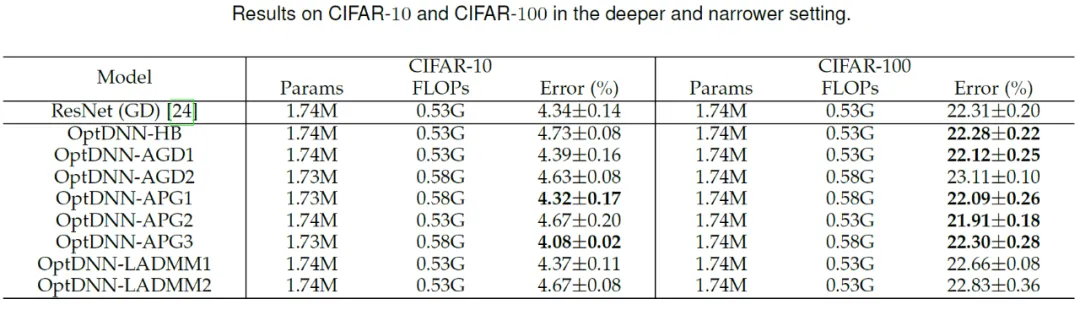
Figure 5 Structure du réseau d'OptDNN-APG2
Tableau 5 Comparaison des performances d'OptDNN-APG2 sur ImageNet 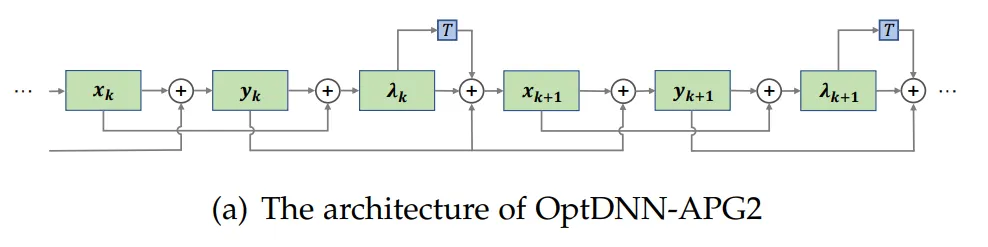
Tableau 6 DNN-AP G2 et isotrope) Comparaison des performances de ConvNeXt et ViT 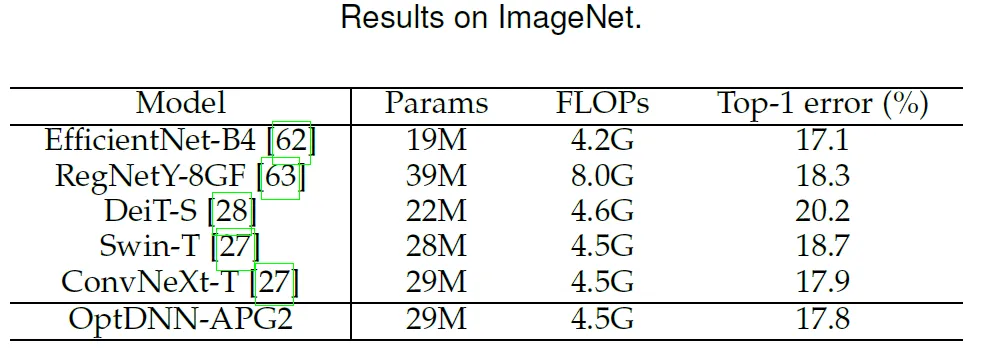
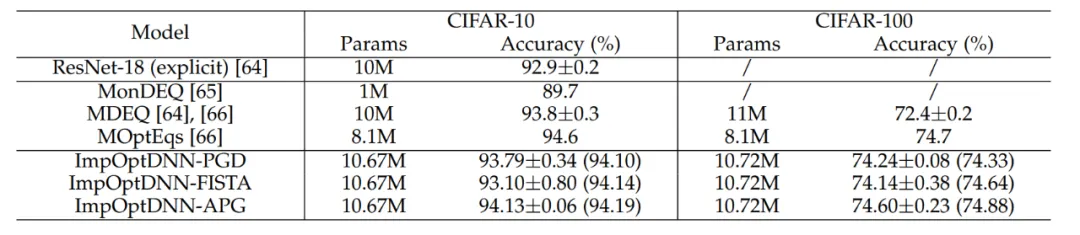
Enfin, l'article a conçu 3 réseaux implicites basés sur des algorithmes tels que Proximal Gradient Descent et FISTA, et a réalisé des expériences sur l'ensemble de données CIFAR avec ResNet explicite et certains réseaux implicites couramment utilisés. À titre de comparaison, les résultats expérimentaux sont présentés dans le tableau 7. Les trois réseaux implicites ont obtenu des résultats expérimentaux comparables aux réseaux implicites avancés, ce qui illustre également la flexibilité de la méthode.
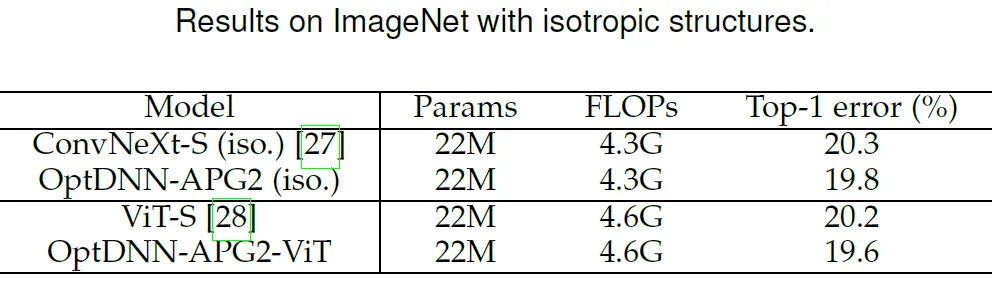
Tableau 7 Comparaison des performances des réseaux implicites
Résumé
 La conception de l'architecture des réseaux neuronaux est l'un des problèmes fondamentaux de l'apprentissage profond. L'article propose un cadre unifié pour l'utilisation d'algorithmes d'optimisation de premier ordre pour concevoir des architectures de réseaux neuronaux avec des propriétés d'approximation universelles, et étend la méthode basée sur le paradigme d'architecture de réseau de conception d'optimisation. Cette méthode peut être combinée avec la plupart des méthodes de conception d'architecture existantes axées sur les modules de réseau, et un modèle efficace peut être conçu sans pratiquement aucune augmentation de l'effort de calcul. En termes de théorie, l'article prouve que l'architecture de réseau induite par les algorithmes d'optimisation convergents possède des propriétés d'approximation universelles dans des conditions douces et relie les capacités de représentation de NODE et des réseaux de connexion multicouches généraux. Cette méthode devrait également être combinée avec la conception d'architecture NAS, SNN et d'autres domaines pour concevoir une architecture réseau plus efficace.
La conception de l'architecture des réseaux neuronaux est l'un des problèmes fondamentaux de l'apprentissage profond. L'article propose un cadre unifié pour l'utilisation d'algorithmes d'optimisation de premier ordre pour concevoir des architectures de réseaux neuronaux avec des propriétés d'approximation universelles, et étend la méthode basée sur le paradigme d'architecture de réseau de conception d'optimisation. Cette méthode peut être combinée avec la plupart des méthodes de conception d'architecture existantes axées sur les modules de réseau, et un modèle efficace peut être conçu sans pratiquement aucune augmentation de l'effort de calcul. En termes de théorie, l'article prouve que l'architecture de réseau induite par les algorithmes d'optimisation convergents possède des propriétés d'approximation universelles dans des conditions douces et relie les capacités de représentation de NODE et des réseaux de connexion multicouches généraux. Cette méthode devrait également être combinée avec la conception d'architecture NAS, SNN et d'autres domaines pour concevoir une architecture réseau plus efficace.
Das obige ist der detaillierte Inhalt vonInspiriert durch den Optimierungsalgorithmus erster Ordnung schlug das Team von Lin Zhouchen von der Peking-Universität eine Entwurfsmethode für die Architektur neuronaler Netzwerke mit universellen Approximationseigenschaften vor.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
