
 Technologie-Peripheriegeräte
KI
DeepMind rüstet Transformer auf, Vorwärtspass-FLOPs können um bis zur Hälfte reduziert werden
Technologie-Peripheriegeräte
KI
DeepMind rüstet Transformer auf, Vorwärtspass-FLOPs können um bis zur Hälfte reduziert werden
DeepMind rüstet Transformer auf, Vorwärtspass-FLOPs können um bis zur Hälfte reduziert werden

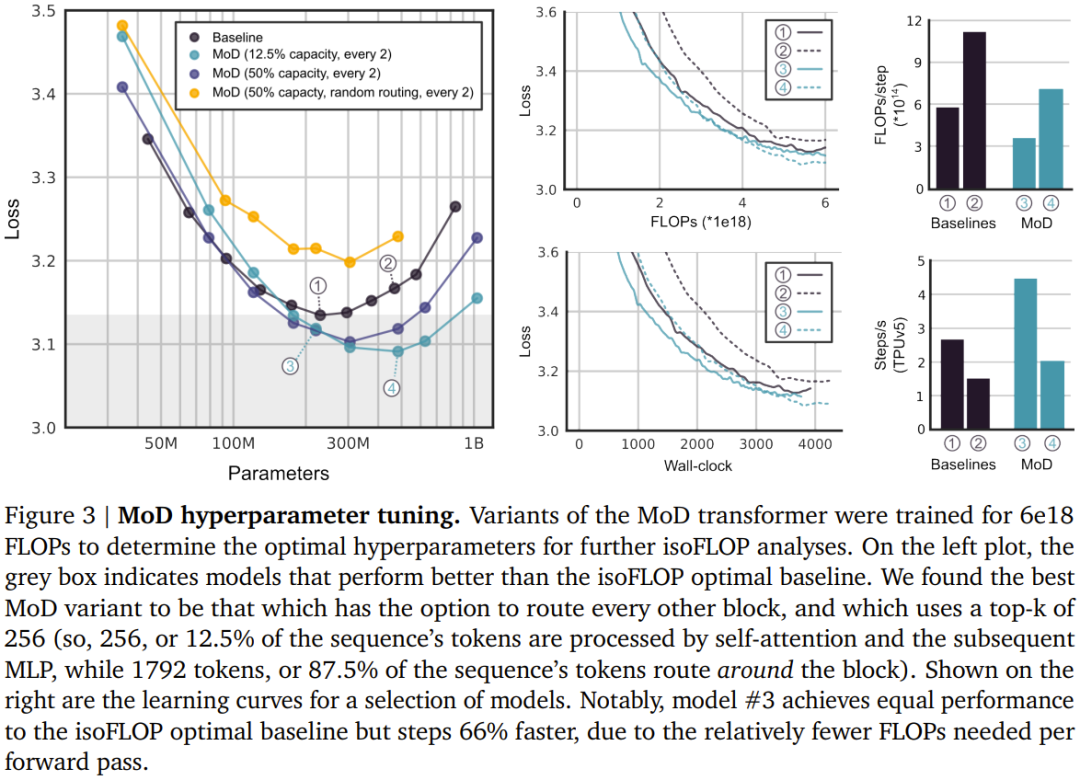
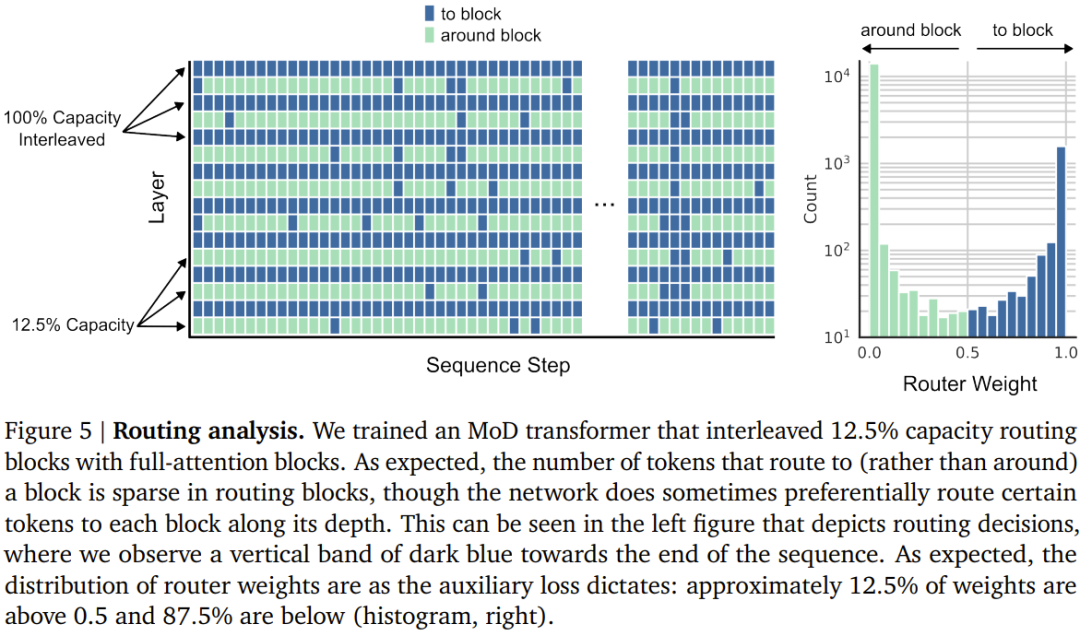
Durch die Einführung der Hybridtiefe kann das neue Design von DeepMind die Transformer-Effizienz erheblich verbessern.



- Adresse des Papiers: https://arxiv.org/pdf/2404.02258.pdf
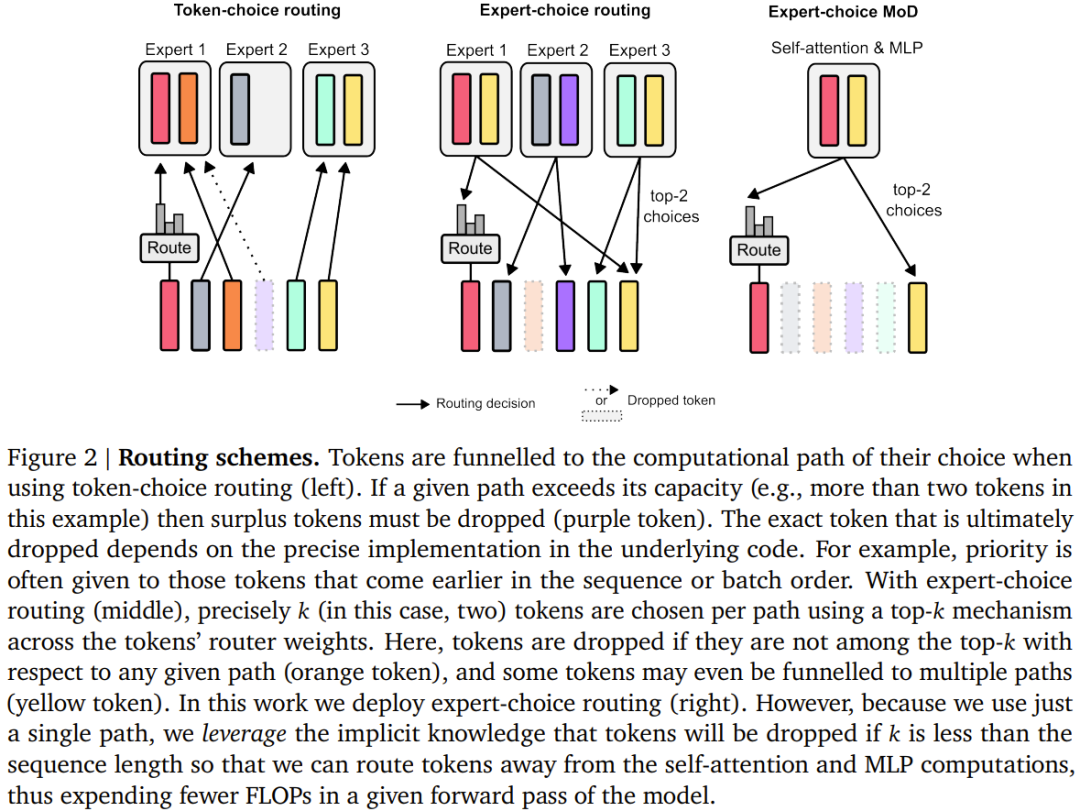
Legen Sie ein statisches Rechenbudget fest, das niedriger ist als der entsprechende herkömmliche Betrag Die von Transformer benötigte Berechnung besteht darin, die Anzahl der Token in der Sequenz zu begrenzen, die an Modulberechnungen teilnehmen können (z. B. Selbstaufmerksamkeitsmodul und nachfolgendes MLP). Beispielsweise kann ein regulärer Transformer zulassen, dass alle Token in der Sequenz an Selbstaufmerksamkeitsberechnungen teilnehmen, der MoD-Transformer kann jedoch die Verwendung von nur 50 % der Token in der Sequenz beschränken. Für jeden Token gibt es in jedem Modul einen Routing-Algorithmus, der eine skalare Gewichtung angibt; diese Gewichtung stellt die Routing-Präferenz für jeden Token dar – ob er an der Berechnung des Moduls teilnimmt oder diese umgeht. Finden Sie in jedem Modul die obersten k größten Skalargewichte, und ihre entsprechenden Token nehmen an der Berechnung des Moduls teil. Da nur k Token an der Berechnung dieses Moduls teilnehmen müssen, sind sein Berechnungsdiagramm und seine Tensorgröße während des Trainingsprozesses statisch. Diese Token sind dynamische und kontextbezogene Token, die vom Routing-Algorithmus erkannt werden.
 Autoregressive Bewertung
Autoregressive Bewertung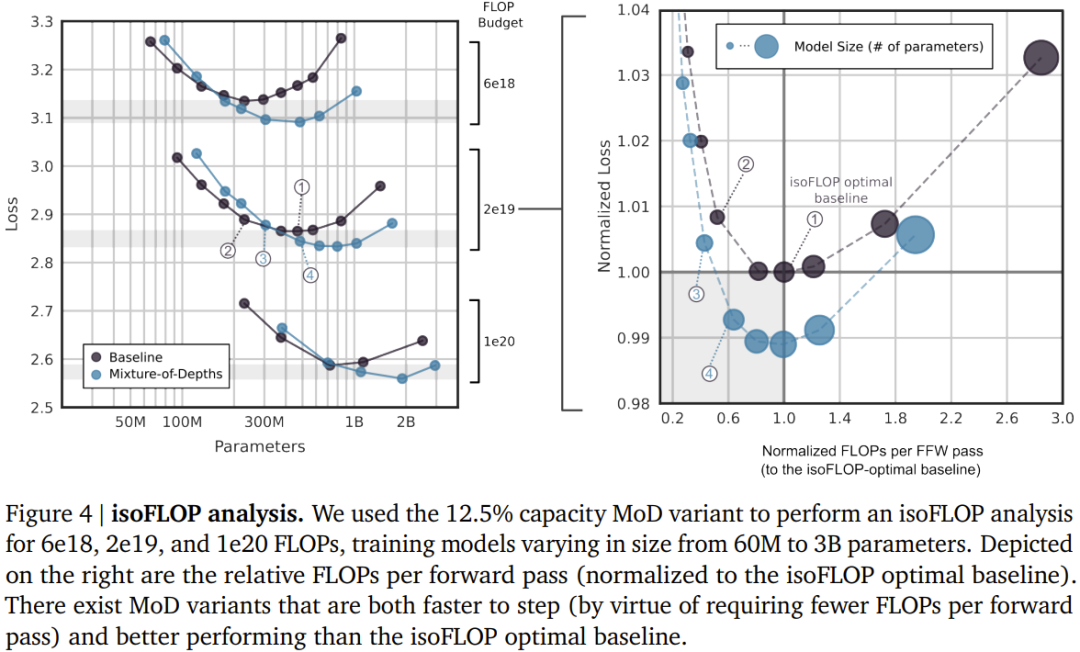
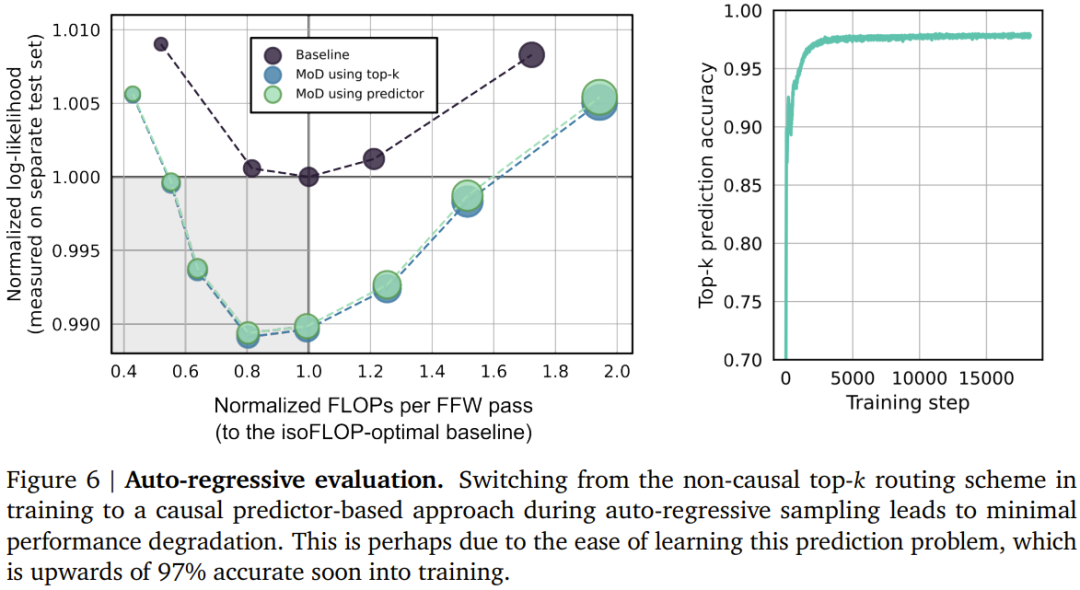
Das obige ist der detaillierte Inhalt vonDeepMind rüstet Transformer auf, Vorwärtspass-FLOPs können um bis zur Hälfte reduziert werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
Um Projekte lokal über Git herunterzuladen, befolgen Sie die folgenden Schritte: Installieren Sie Git. Navigieren Sie zum Projektverzeichnis. Klonen des Remote-Repositorys mit dem folgenden Befehl: Git Clone https://github.com/username/repository-name.git.git
 So aktualisieren Sie den Code in Git
Apr 17, 2025 pm 04:45 PM
So aktualisieren Sie den Code in Git
Apr 17, 2025 pm 04:45 PM
Schritte zur Aktualisierung von Git -Code: CODEHOUSSCHAFTEN:
 Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Git Commit ist ein Befehl, mit dem Dateien Änderungen an einem Git -Repository aufgezeichnet werden, um einen Momentaufnahme des aktuellen Status des Projekts zu speichern. So verwenden Sie dies wie folgt: Fügen Sie Änderungen in den temporären Speicherbereich hinzu, schreiben Sie eine prägnante und informative Einreichungsnachricht, um die Einreichungsnachricht zu speichern und zu beenden, um die Einreichung optional abzuschließen: Fügen Sie eine Signatur für die Einreichungs -Git -Protokoll zum Anzeigen des Einreichungsinhalts hinzu.
 Wie man Code in Git zusammenfasst
Apr 17, 2025 pm 04:39 PM
Wie man Code in Git zusammenfasst
Apr 17, 2025 pm 04:39 PM
Git -Code -Merge -Prozess: Ziehen Sie die neuesten Änderungen an, um Konflikte zu vermeiden. Wechseln Sie in die Filiale, die Sie zusammenführen möchten. Initiieren Sie eine Zusammenführung und geben Sie den Zweig an, um zusammenzuarbeiten. Merge -Konflikte auflösen (falls vorhanden). Inszenierung und Bekämpfung verschmelzen, liefern die Botschaft.
 Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Auflösung: Wenn die Git -Download -Geschwindigkeit langsam ist, können Sie die folgenden Schritte ausführen: Überprüfen Sie die Netzwerkverbindung und versuchen Sie, die Verbindungsmethode zu wechseln. Optimieren Sie die GIT-Konfiguration: Erhöhen Sie die Post-Puffer-Größe (GIT-Konfiguration --global http.postbuffer 524288000) und verringern Sie die Niedriggeschwindigkeitsbegrenzung (GIT-Konfiguration --global http.lowSpeedLimit 1000). Verwenden Sie einen GIT-Proxy (wie Git-Proxy oder Git-LFS-Proxy). Versuchen Sie, einen anderen Git -Client (z. B. Sourcetree oder Github Desktop) zu verwenden. Überprüfen Sie den Brandschutz
 So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
Befolgen Sie die folgenden Schritte, um ein Git -Repository zu löschen: Bestätigen Sie das Repository, das Sie löschen möchten. Lokale Löschen des Repositorys: Verwenden Sie den Befehl rm -RF, um seinen Ordner zu löschen. Löschen Sie ein Lager aus der Ferne: Navigieren Sie zu den Lagereinstellungen, suchen Sie die Option "Lager löschen" und bestätigen Sie den Betrieb.
 So aktualisieren Sie den lokalen Code in Git
Apr 17, 2025 pm 04:48 PM
So aktualisieren Sie den lokalen Code in Git
Apr 17, 2025 pm 04:48 PM
Wie aktualisiere ich den lokalen Git -Code? Verwenden Sie Git Fetch, um die neuesten Änderungen aus dem Remote -Repository zu ziehen. Merge Remote -Änderungen in die lokale Niederlassung mit Git Merge Origin/& lt; Remote -Zweigname & gt;. Lösung von Konflikten, die sich aus Fusionen ergeben. Verwenden Sie Git Commit -m "Merge Branch & lt; Remote Branch Name & gt;" Um Änderungen zu verschmelzen und Aktualisierungen anzuwenden.
 Wie löste ich das effiziente Suchproblem in PHP -Projekten? Typense hilft Ihnen, es zu erreichen!
Apr 17, 2025 pm 08:15 PM
Wie löste ich das effiziente Suchproblem in PHP -Projekten? Typense hilft Ihnen, es zu erreichen!
Apr 17, 2025 pm 08:15 PM
Bei der Entwicklung einer E-Commerce-Website habe ich auf ein schwieriges Problem gestoßen: Wie kann ich effiziente Suchfunktionen in großen Mengen an Produktdaten erzielen? Herkömmliche Datenbanksuche sind ineffizient und haben eine schlechte Benutzererfahrung. Nach einigen Nachforschungen entdeckte ich den Suchmaschinen-Artensense und löste dieses Problem durch seine offizielle PHP-Client-Artense-/Artense-Php, die die Suchleistung erheblich verbesserte.
