
 Technologie-Peripheriegeräte
KI
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Technologie-Peripheriegeräte
KI
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!

Vorwort & Ausgangspunkt
Das End-to-End-Paradigma nutzt ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Darüber hinaus werden Bewegungsvorhersage und -planung überarbeitet und ein sinnvollerer Rahmen für die Bewegungsplanung entworfen. Auf dem anspruchsvollen nuScenes-Datensatz erreicht SparseAD in einem End-to-End-Ansatz eine hochmoderne Full-Task-Leistung und verringert die Leistungslücke zwischen dem End-to-End-Paradigma und Einzeltask-Ansätzen.
Hintergrund aus der Praxis
Autonome Fahrsysteme müssen in komplexen Fahrszenarien die richtigen Entscheidungen treffen, um Fahrsicherheit und Komfort zu gewährleisten. Typischerweise integrieren autonome Fahrsysteme mehrere Aufgaben wie Erkennung, Verfolgung, Online-Kartierung, Bewegungsvorhersage und Planung. Wie in Abbildung 1a dargestellt, teilt das traditionelle modulare Paradigma komplexe Systeme in mehrere einzelne Aufgaben auf, die jeweils unabhängig voneinander optimiert werden. In diesem Paradigma ist eine manuelle Nachbearbeitung zwischen unabhängigen Einzelaufgabenmodulen erforderlich, was den gesamten Prozess umständlicher macht. Andererseits häufen sich aufgrund des Verlusts der Szeneninformationskomprimierung zwischen gestapelten Aufgaben Fehler im gesamten System an, was zu potenziellen Sicherheitsproblemen führen kann.
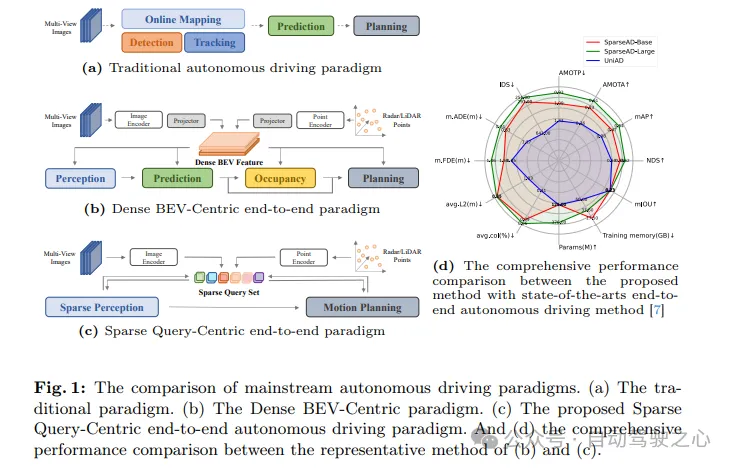
In Bezug auf die oben genannten Probleme verwendet das End-to-End-System für autonomes Fahren Perzeptron-Rohdaten als Eingabe und gibt die Planungsergebnisse auf prägnantere Weise zurück. Frühe Arbeiten schlugen vor, Zwischenaufgaben zu überspringen und Planungsergebnisse direkt aus Perzeptron-Rohdaten vorherzusagen. Obwohl dieser Ansatz einfacher ist, ist er im Hinblick auf Modelloptimierung, Interpretierbarkeit und Planungsleistung nicht zufriedenstellend. Ein weiteres vielschichtiges Paradigma mit besserer Interpretierbarkeit besteht darin, mehrere Teile des autonomen Fahrens in ein modulares End-to-End-Modell zu integrieren, das eine mehrdimensionale Überwachung einführt, um das Verständnis komplexer Fahrszenarien zu verbessern, und die Fähigkeit zum Multitasking bietet.
Wie in Abbildung 1b dargestellt, ist das gesamte Fahrszenario bei den meisten fortschrittlichen modularen End-to-End-Methoden durch eine dichte Sammlung von BEV-Funktionen (Vogelperspektive) gekennzeichnet, die Multisensor- und Zeitinformationen umfassen und als dienen Full-Stack-Eingaben, die Aufgaben steuern, einschließlich Wahrnehmung, Vorhersage und Planung. Obwohl dicht aggregierte BEV-Merkmale eine Schlüsselrolle beim Erreichen von Multimodalität und Multitasking über Raum und Zeit hinweg spielen, werden frühere End-to-End-Methoden mit BEV-Darstellung als dichtes BEV-zentriertes Paradigma zusammengefasst. Trotz der Einfachheit und Interpretierbarkeit dieser Methoden bleibt ihre Leistung bei jeder Teilaufgabe des autonomen Fahrens immer noch weit hinter den entsprechenden Einzelaufgabenmethoden zurück. Darüber hinaus werden im Rahmen des Dense BEV-Centric-Paradigmas die langfristige zeitliche Fusion und die multimodale Fusion hauptsächlich durch mehrere BEV-Feature-Maps erreicht, was zu einem erheblichen Anstieg der Rechenkosten und der Speichernutzung führt und die tatsächliche Belastung erhöht Einsatz.
Hier wird ein neuartiges, auf Sparse Search basierendes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen. In diesem Paradigma werden die räumlichen und zeitlichen Elemente in der gesamten Fahrszene durch spärliche Nachschlagetabellen dargestellt, wodurch die traditionelle Funktion der Vogelperspektive (BEV) mit dichtem Ensemble aufgegeben wird, wie in Abbildung 1c dargestellt. Diese spärliche Darstellung ermöglicht es End-to-End-Modellen, längere historische Informationen effizienter zu nutzen und auf mehr Modi und Aufgaben zu skalieren, während gleichzeitig die Rechenkosten und der Speicherbedarf deutlich reduziert werden.
Die modulare End-to-End-Architektur wurde neu gestaltet und zu einer prägnanten Struktur vereinfacht, die aus spärlicher Wahrnehmung und Bewegungsplaner besteht. Im Sparse-Perception-Modul wird ein universeller zeitlicher Decoder verwendet, um Wahrnehmungsaufgaben einschließlich Erkennung, Verfolgung und Online-Mapping zu vereinheitlichen. In diesem Prozess werden Multisensor-Merkmale und historische Aufzeichnungen als Token behandelt, während Objektabfragen und Kartenabfragen Hindernisse bzw. Straßenelemente in der Fahrszene darstellen. Im Bewegungsplaner werden spärliche Wahrnehmungsabfragen als Umgebungsdarstellung verwendet und multimodale Bewegungsvorhersagen werden gleichzeitig für das Fahrzeug und umgebende Agenten durchgeführt, um mehrere anfängliche Planungslösungen für das eigene Fahrzeug zu erhalten. Anschließend werden mehrdimensionale Fahreinschränkungen vollständig berücksichtigt, um die endgültigen Planungsergebnisse zu generieren.
Hauptbeiträge:
- Schlagen Sie ein neuartiges, spärlich besetztes, abfragezentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vor, das die traditionelle Darstellungsmethode der dichten Vogelperspektive (BEV) aufgibt und daher ein enormes Potenzial für eine effiziente Skalierung auf mehr Modalitäten und Aufgaben hat.
- Vereinfachen Sie die modulare End-to-End-Architektur in zwei Teile: spärliche Sensorik und Bewegungsplanung. Im spärlichen Wahrnehmungsteil werden Wahrnehmungsaufgaben wie Erkennung, Verfolgung und Online-Kartierung auf völlig spärliche Weise vereinheitlicht, während im Bewegungsplanungsteil Bewegungsvorhersage und -planung in einem vernünftigeren Rahmen durchgeführt werden.
- Auf dem anspruchsvollen nuScenes-Datensatz erreicht SparseAD eine hochmoderne Leistung unter End-to-End-Methoden und verringert die Leistungslücke zwischen dem End-to-End-Paradigma und Einzelaufgabenmethoden erheblich. Dies zeigt voll und ganz das enorme Potenzial des vorgeschlagenen Sparse-End-to-End-Paradigmas. SparseAD verbessert nicht nur die Leistung und Effizienz autonomer Fahrsysteme, sondern bietet auch neue Richtungen und Möglichkeiten für zukünftige Forschung und Anwendungen.
SparseAD-Netzwerkstruktur
Wie in Abbildung 1c gezeigt, repräsentieren im vorgeschlagenen, auf Sparse-Abfragen zentrierten Paradigma verschiedene Sparse-Abfragen vollständig die gesamte Fahrszene und sind nicht nur für die Informationsübertragung und Interaktion zwischen Modulen verantwortlich, sondern auch für Rückwärtsgradienten werden zur Optimierung auch durchgängig über mehrere Aufgaben verteilt. Im Gegensatz zu früheren BEV-zentrierten Methoden (Dense Set Bird's Eye View) werden in SparseAD keine Ansichtsprojektion und dichte BEV-Funktionen verwendet, wodurch hohe Rechen- und Speicherbelastungen vermieden werden. Die detaillierte Architektur von SparseAD ist in Abbildung 2 dargestellt.
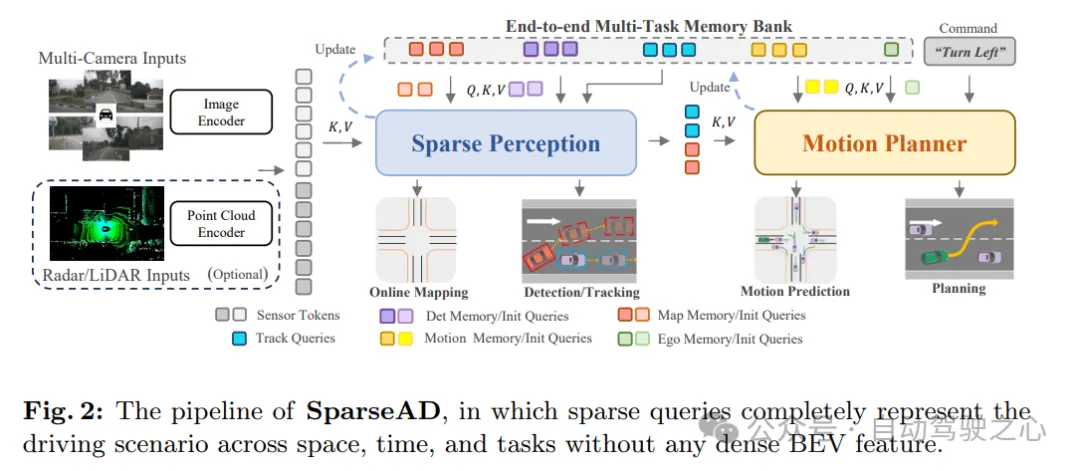
Aus dem Architekturdiagramm besteht SparseAD hauptsächlich aus drei Teilen, einschließlich Sensor-Encoder, Sparse Perception und Bewegungsplaner. Konkret nimmt der Sensor-Encoder als Eingabe Multiview-Kamerabilder, Radar- oder Lidar-Punkte und kodiert sie in hochdimensionale Merkmale. Diese Merkmale werden dann als Sensor-Token zusammen mit Positionseinbettungen (PE) in das Sparse-Sensing-Modul eingegeben. Im Sparse-Sensing-Modul werden die Rohdaten von Sensoren zu einer Vielzahl von Sparse-Sensing-Abfragen aggregiert, wie z. B. Erkennungsabfragen, Tracking-Abfragen und Kartenabfragen, die jeweils unterschiedliche Elemente in der Fahrszene darstellen und weiter an nachgelagerte Bereiche weitergegeben werden Aufgaben. Im Bewegungsplaner wird die Wahrnehmungsabfrage als spärliche Darstellung der Fahrszene behandelt und für alle umgebenden Agenten und das eigene Fahrzeug vollständig ausgenutzt. Gleichzeitig werden mehrere Fahreinschränkungen berücksichtigt, um einen endgültigen Plan zu erstellen, der sowohl sicher als auch dynamisch konform ist.
Darüber hinaus wird in der Architektur eine End-to-End-Multitasking-Speicherbibliothek eingeführt, um die Zeitinformationen der gesamten Fahrszene einheitlich zu speichern, sodass das System von der Aggregation langfristiger historischer Informationen profitieren kann, um es zu vervollständigen Full-Stack-Fahraufgaben.
Wie in Abbildung 3 dargestellt, vereint das Sparse-Perception-Modul von SparseAD mehrere Wahrnehmungsaufgaben auf spärliche Weise, einschließlich Erkennung, Verfolgung und Online-Mapping. Konkret handelt es sich um zwei strukturell identische zeitliche Decoder, die langfristige historische Informationen aus der Speicherbank nutzen. Einer der Decoder dient zur Hinderniserkennung und der andere zur Online-Kartierung.
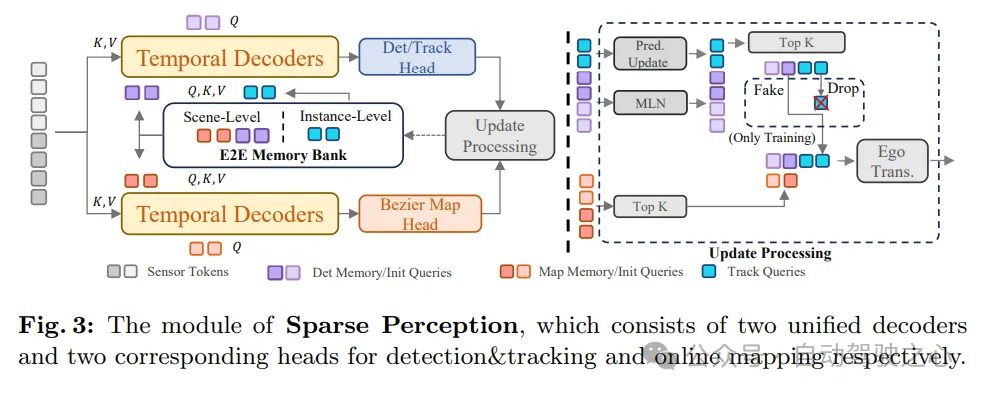
Nach der Informationsaggregation durch Wahrnehmungsabfragen, die verschiedenen Aufgaben entsprechen, werden die Erkennungs- und Verfolgungsköpfe und der Kartenteil verwendet, um Hindernisse bzw. Kartenelemente zu dekodieren und auszugeben. Danach wird ein Aktualisierungsprozess durchgeführt, der die hochsichere Erkennungsabfrage des aktuellen Frames filtert und speichert und die Speicherbank entsprechend aktualisiert, was dem Erkennungsprozess des nächsten Frames zugute kommt.
Auf diese Weise erreicht das SparseAD-Modul „Sparse Perception“ eine effiziente und genaue Wahrnehmung der Fahrszene und stellt eine wichtige Informationsgrundlage für die nachfolgende Bewegungsplanung bereit. Gleichzeitig kann das Modul durch die Nutzung historischer Informationen in der Speicherbank die Genauigkeit und Stabilität der Wahrnehmung weiter verbessern und den zuverlässigen Betrieb des autonomen Fahrsystems sicherstellen.
Sparse Perception
In Bezug auf die Hinderniswahrnehmung werden die gemeinsame Erkennung und Verfolgung innerhalb eines einheitlichen Decoders ohne zusätzliche manuelle Nachbearbeitung übernommen. Es besteht ein erhebliches Ungleichgewicht zwischen Erkennungs- und Tracking-Abfragen, was zu einer erheblichen Verschlechterung der Erkennungsleistung führen kann. Um die oben genannten Probleme zu lindern, wurde die Leistung der Hinderniserkennung aus mehreren Blickwinkeln verbessert. Zunächst wird ein zweistufiger Speichermechanismus eingeführt, um zeitliche Informationen über Frames hinweg zu verbreiten. Unter diesen behält der Speicher auf Szenenebene Abfrageinformationen ohne Cross-Frame-Korrelation bei, während der Speicher auf Instanzebene die Korrespondenz zwischen benachbarten Frames der Verfolgung von Hindernissen aufrechterhält. Zweitens werden angesichts der unterschiedlichen Ursprünge und Aufgaben der beiden unterschiedliche Aktualisierungsstrategien für Speicher auf Szenenebene und Instanzebene angewendet. Insbesondere wird der Speicher auf Szenenebene über MLN aktualisiert, während der Speicher auf Instanzebene mit zukünftigen Vorhersagen für jedes Hindernis aktualisiert wird. Darüber hinaus wird während des Trainings eine Verbesserungsstrategie für Tracking-Abfragen übernommen, um die Überwachung zwischen den beiden Speicherebenen auszugleichen und dadurch die Erkennungs- und Tracking-Leistung zu verbessern. Anschließend kann durch Erkennen und Verfolgen des Kopfes ein 3D-Begrenzungsrahmen mit Attributen und einer eindeutigen ID aus der Erkennungs- oder Verfolgungsabfrage dekodiert und dann in nachgelagerten Aufgaben weiterverwendet werden.
Online-Kartenerstellung ist eine komplexe und wichtige Aufgabe. Nach aktuellem Kenntnisstand basieren bestehende Online-Kartenerstellungsmethoden hauptsächlich auf BEV-Funktionen (Dense Bird's Eye View), um die Fahrumgebung darzustellen. Bei diesem Ansatz ist es schwierig, den Erfassungsbereich zu erweitern oder historische Informationen zu nutzen, da große Mengen an Speicher und Rechenressourcen erforderlich sind. Wir sind der festen Überzeugung, dass alle Kartenelemente spärlich dargestellt werden können. Deshalb versuchen wir, die Online-Kartenerstellung nach dem Sparse-Paradigma abzuschließen. Insbesondere wird die gleiche zeitliche Decoderstruktur wie bei der Hinderniswahrnehmungsaufgabe übernommen. Zunächst werden Kartenabfragen mit vorherigen Kategorien initialisiert, um sie gleichmäßig auf der Fahrebene zu verteilen. Im zeitlichen Decoder interagieren Kartenabfragen mit Sensormarkierungen und historischen Speichermarkierungen. Diese historischen Speichermarkierungen bestehen tatsächlich aus äußerst zuverlässigen Kartenabfragen aus früheren Frames. Die aktualisierte Kartenabfrage enthält dann gültige Informationen über die Kartenelemente des aktuellen Frames und kann zur Verwendung in zukünftigen Frames oder nachgelagerten Aufgaben an die Speicherbank übertragen werden.
Offensichtlich ist der Prozess der Online-Kartenerstellung in etwa derselbe wie die Wahrnehmung von Hindernissen. Das heißt, Erfassungsaufgaben, einschließlich Erkennung, Verfolgung und Online-Kartenerstellung, werden in einem gemeinsamen, spärlichen Ansatz vereinheitlicht, der bei der Skalierung auf größere Bereiche (z. B. 100 m × 100 m) oder bei der Langzeitfusion effizienter ist und keine komplexen Vorgänge erfordert (wie verformbare Aufmerksamkeit oder Mehrpunktaufmerksamkeit). Nach unserem besten Wissen ist dies das erste, das die Online-Kartenerstellung in einer einheitlichen Sensorarchitektur auf spärliche Weise implementiert. Anschließend wird die stückweise Bezier-Karte Head verwendet, um die stückweisen Bezier-Kontrollpunkte jedes spärlichen Kartenelements zurückzugeben, und diese Kontrollpunkte können leicht transformiert werden, um den Anforderungen nachgelagerter Aufgaben gerecht zu werden.
Bewegungsplaner
Wir haben das Problem der Bewegungsvorhersage und -planung in autonomen Fahrsystemen erneut untersucht und festgestellt, dass viele bisherige Methoden die Dynamik des Ego-Fahrzeugs bei der Vorhersage der Bewegung umgebender Fahrzeuge ignorierten. Während dies in den meisten Situationen möglicherweise nicht offensichtlich ist, kann es in Szenarien wie Kreuzungen, an denen es zu einer engen Interaktion zwischen Fahrzeugen in der Nähe und dem Host-Fahrzeug kommt, ein potenzielles Risiko darstellen. Davon inspiriert wurde ein vernünftigerer Rahmen für die Bewegungsplanung entworfen. In diesem Rahmen sagt der Bewegungsprädiktor gleichzeitig die Bewegung umgebender Fahrzeuge und des eigenen Fahrzeugs voraus. Anschließend werden die Vorhersageergebnisse des eigenen Fahrzeugs als Bewegungspriors in nachfolgenden Planungsoptimierern verwendet. Während des Planungsprozesses berücksichtigen wir verschiedene Aspekte von Randbedingungen, um ein endgültiges Planungsergebnis zu erzielen, das sowohl den Sicherheits- als auch den Dynamikanforderungen gerecht wird.
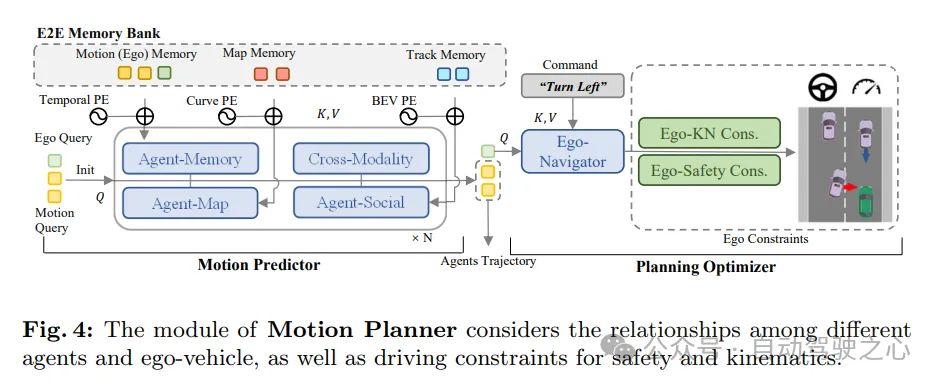
Wie in Abbildung 4 dargestellt, behandelt der Bewegungsplaner in SparseAD Wahrnehmungsabfragen (einschließlich Trajektorienabfragen und Kartenabfragen) als spärliche Darstellung der aktuellen Fahrszene. Multimodale Bewegungsabfragen werden als Medium verwendet, um das Verständnis von Fahrszenarien, die Wahrnehmung von Interaktionen zwischen allen Fahrzeugen (einschließlich des eigenen Fahrzeugs) und das Durchspielen verschiedener zukünftiger Möglichkeiten zu ermöglichen. Die multimodale Bewegungsabfrage des Fahrzeugs wird dann in einen Planungsoptimierer eingespeist, der Fahreinschränkungen einschließlich hochrangiger Anweisungen, Sicherheit und Dynamik berücksichtigt.
Bewegungsvorhersage. In Anlehnung an frühere Methoden werden die Wahrnehmung und Integration zwischen Bewegungsabfragen und aktuellen Fahrszenendarstellungen (einschließlich Trajektorienabfragen und Kartenabfragen) durch Standardtransformatorebenen erreicht. Darüber hinaus werden Selbstfahrzeug-Agenten und modalübergreifende Interaktionen angewendet, um die Interaktion zwischen umgebenden Agenten und dem Eigenfahrzeug in zukünftigen räumlich-zeitlichen Szenen gemeinsam zu modellieren. Durch Modulsynergien innerhalb und zwischen mehrschichtigen Stapelstrukturen sind Bewegungsabfragen in der Lage, umfangreiche semantische Informationen sowohl aus statischen als auch dynamischen Umgebungen zu aggregieren.
Zusätzlich zu den oben genannten werden zwei Strategien eingeführt, um die Leistung des Bewegungsvorhersagers weiter zu verbessern. Zunächst wird eine einfache und unkomplizierte Vorhersage getroffen, indem der zeitliche Speicher der Trajektorienabfrage auf Instanzebene als Teil der Initialisierung der Bewegungsabfrage des umgebenden Agenten verwendet wird. Auf diese Weise kann der Bewegungsprädiktor von Vorkenntnissen profitieren, die er aus vorgelagerten Aufgaben gewonnen hat. Zweitens können dank der End-to-End-Speicherbibliothek nützliche Informationen aus den gespeicherten historischen Bewegungsabfragen per Streaming über den Agent-Speicheraggregator zu nahezu vernachlässigbaren Kosten assimiliert werden.
Es ist zu beachten, dass gleichzeitig die multimodale Bewegungsabfrage dieses Autos aktualisiert wird. Auf diese Weise kann die Bewegungspriorität des eigenen Fahrzeugs ermittelt werden, was den Planungslernprozess weiter erleichtern kann.
Planungsoptimierer. Mit der vom Bewegungsprädiktor bereitgestellten Bewegungspriorität wird eine bessere Initialisierung erreicht, was zu weniger Umwegen während des Trainings führt. Als Schlüsselkomponente des Bewegungsplaners ist die Gestaltung der Kostenfunktion von entscheidender Bedeutung, da sie die Qualität der endgültigen Leistung stark beeinflusst oder sogar bestimmt. Im vorgeschlagenen SparseAD-Bewegungsplaner werden hauptsächlich zwei Haupteinschränkungen, Sicherheit und Dynamik, berücksichtigt, um zufriedenstellende Planungsergebnisse zu erzielen. Zusätzlich zu den in VAD ermittelten Einschränkungen konzentriert es sich insbesondere auch auf die dynamische Sicherheitsbeziehung zwischen dem Fahrzeug und in der Nähe befindlichen Agenten und berücksichtigt deren relative Positionen in zukünftigen Momenten. Wenn Agent i beispielsweise weiterhin im vorderen linken Bereich relativ zum Fahrzeug bleibt und dadurch verhindert, dass das Fahrzeug die Spur nach links wechselt, erhält Agent i eine linke Markierung, die angibt, dass Agent i dem Fahrzeug eine Einschränkung nach links auferlegt . Einschränkungen werden daher in Längsrichtung als vorne, hinten oder keine und in Querrichtung als links, rechts oder keine klassifiziert. Im Planer entschlüsseln wir aus der entsprechenden Abfrage die Beziehung zwischen anderen Agenten und dem Fahrzeug in horizontaler und vertikaler Richtung. Bei diesem Prozess werden die Wahrscheinlichkeiten aller Einschränkungen zwischen anderen Agenten und dem eigenen Fahrzeug in diesen Richtungen ermittelt. Dann verwenden wir den Fokusverlust als Kostenfunktion der Ego-Agent-Beziehung (EAR), um die potenziellen Risiken, die durch nahegelegene Agenten entstehen, effektiv zu erfassen:
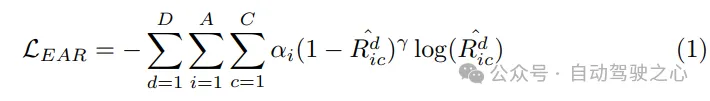
Da die geplante Flugbahn den dynamischen Gesetzen der Ausführung des Kontrollsystems folgen muss, Bei der Bewegungsplanung sind Hilfsaufgaben in die Maschine eingebettet, um das Erlernen des dynamischen Zustands des Fahrzeugs zu fördern. Dekodieren Sie Zustände wie Geschwindigkeit, Beschleunigung und Gierwinkel aus der Qego-Abfrage des eigenen Fahrzeugs und überwachen Sie diese Zustände mithilfe von Dynamikverlusten: Überlegenheit der Methode. Um fair zu sein, wird die Leistung jeder vollständigen Aufgabe bewertet und mit früheren Methoden verglichen. Die Experimente in diesem Abschnitt verwenden drei verschiedene Konfigurationen von SparseAD, nämlich SparseAD-B und SparseAD-L, die nur Bildeingaben verwenden, und SparseAD-BR, das Radarpunktwolken und multimodale Bildeingaben verwendet. Sowohl SparseAD-B als auch SparseAD-BR verwenden V2-99 als Bild-Backbone-Netzwerk und die Auflösung des Eingabebildes beträgt 1600 × 640. SparseAD-L verwendet außerdem ViTLarge als Bild-Backbone-Netzwerk und die Eingabebildauflösung beträgt 1600 x 800.
Die Ergebnisse der 3D-Erkennung und der 3D-Mehrzielverfolgung im nuScenes-Validierungsdatensatz sind wie folgt. „Nur Tracking-Methoden“ bezieht sich auf Methoden, die durch Nachbearbeitungskorrelation verfolgt werden. „End-to-End-Methode des autonomen Fahrens“ bezieht sich auf eine Methode, die vollständige autonome Fahraufgaben ausführen kann. Alle Methoden in der Tabelle werden mit Bildeingabe in voller Auflösung ausgewertet. †: Die Ergebnisse werden durch offiziellen Open-Source-Code reproduziert. -R: Zeigt an, dass die Radarpunktwolkeneingabe verwendet wird. Der Leistungsvergleich von 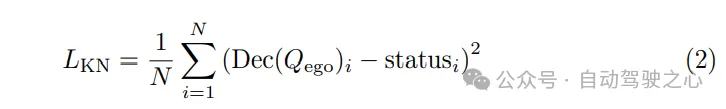
mit der Online-Mapping-Methode ist wie folgt: Die Ergebnisse werden am Schwellenwert von [1,0 m, 1,5 m, 2,0 m] bewertet. ‡: Ergebnis durch offiziellen Open-Source-Code reproduziert. †: Basierend auf den Anforderungen des Planungsmoduls in SparseAD haben wir die Grenze weiter in Straßensegmente und Fahrspuren unterteilt und diese separat ausgewertet. ∗: Kosten des Backbone-Netzwerks und des spärlich besetzten Sensormoduls. -R: Zeigt an, dass die Radarpunktwolkeneingabe verwendet wird.
Multi-Task-Ergebnisse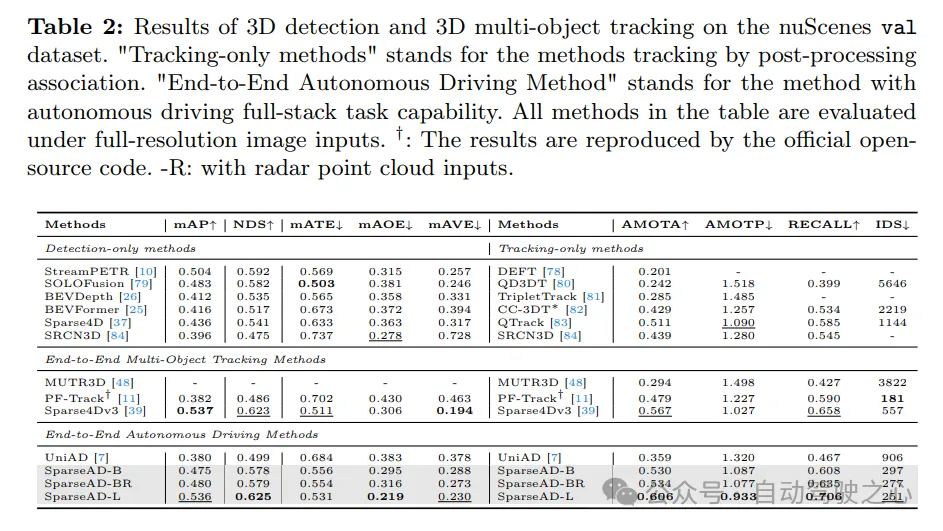
. Die Erkennungs- und Verfolgungsleistung von SparseAD wird mit anderen Methoden im nuScenes-Validierungssatz in Tab. 2 verglichen. Offensichtlich schneidet SparseAD-B bei den gängigsten Nur-Erkennungs-, Nur-Tracking- und End-to-End-Multi-Objekt-Tracking-Methoden gut ab, während es bei den entsprechenden Aufgaben eine vergleichbare Leistung mit SOTA-Methoden wie StreamPETR und QTrack erbringt. Durch die Skalierung mit einem fortschrittlicheren Backbone-Netzwerk erreicht SparseAD-Large eine insgesamt bessere Leistung mit mAP von 53,6 %, NDS von 62,5 % und AMOTA von 60,6 %, was insgesamt besser ist als die bisher beste Methode Sparse4Dv3. 
Online-Mapping. Tab. 3 zeigt die Vergleichsergebnisse der Online-Mapping-Leistung zwischen SparseAD und anderen früheren Methoden im nuScenes-Validierungssatz. Es ist zu beachten, dass wir die Grenze entsprechend den Planungsanforderungen in Straßenabschnitte und Fahrspuren unterteilt und diese separat bewertet haben, während wir den Bereich von den üblichen 60 m × 30 m auf 102,4 m × 102,4 m erweitert haben, um der Hinderniswahrnehmung zu entsprechen. Ohne an Fairness zu verlieren, erreicht SparseAD 34,2 % mAP auf spärliche End-to-End-Methode ohne dichte BEV-Darstellung, was in Bezug auf die Leistung besser ist als die meisten zuvor gängigen Methoden wie HDMapNet, VectorMapNet und MapTR. Es hat offensichtliche Vorteile Bedingungen für Schulungskosten und -kosten. Obwohl die Leistung etwas schlechter ist als bei StreamMapNet, beweist unsere Methode, dass Online-Mapping auf einheitliche, spärliche Weise ohne dichte BEV-Darstellung durchgeführt werden kann, was Auswirkungen auf die praktische Einführung von durchgängigem autonomem Fahren zu deutlich geringeren Kosten hat. Zugegebenermaßen ist die effektive Nutzung nützlicher Informationen aus anderen Modalitäten (z. B. Radar) immer noch eine Aufgabe, die es wert ist, weiter erforscht zu werden. Wir glauben, dass es noch viel Spielraum für Erkundungen in spärlicher Form gibt.
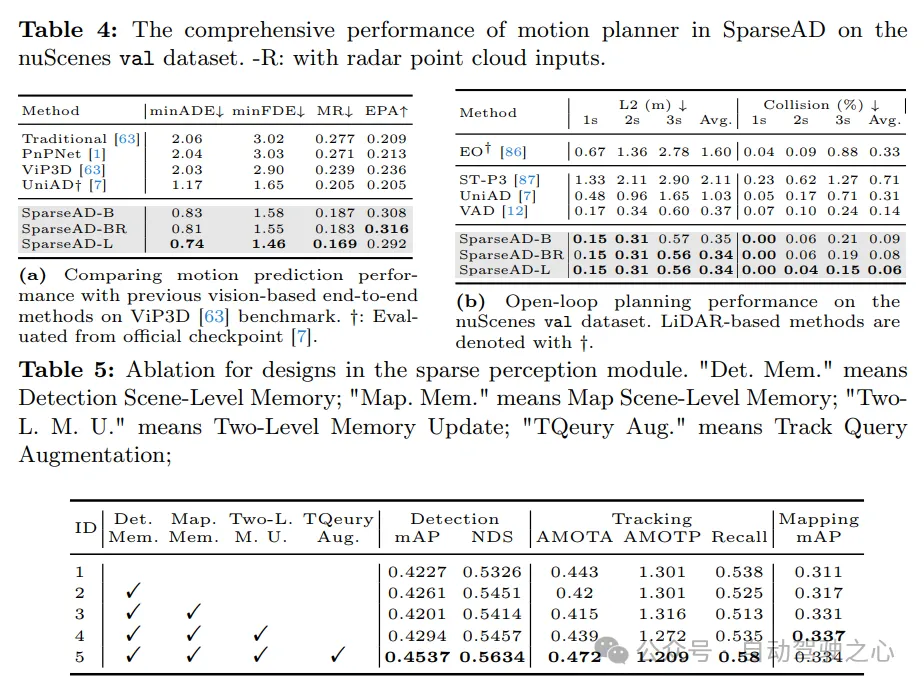
Sportvorhersage. Die Vergleichsergebnisse der Bewegungsvorhersage sind in Tab. 4a dargestellt, wobei die Indikatoren mit VIP3D übereinstimmen. SparseAD erreicht die beste Leistung unter allen End-to-End-Methoden, mit der niedrigsten 0,83 Mio. minADE, 1,58 Mio. minFDE, 18,7 % Fehlerquote und der höchsten 0,308 EPA, was ein großer Vorteil ist. Darüber hinaus kann SparseAD dank der Effizienz und Skalierbarkeit des Sparse-Query-Center-Paradigmas effektiv auf mehr Modalitäten expandieren und vom fortschrittlichen Backbone-Netzwerk profitieren, um die Vorhersageleistung weiter deutlich zu verbessern.
Planung. Die Ergebnisse der Planung sind in Tab. 4b dargestellt. Dank des überlegenen Designs des vorgeschalteten Wahrnehmungsmoduls und Bewegungsplaners erreichen alle Versionen von SparseAD eine Leistung auf dem neuesten Stand der Technik im nuScenes-Validierungsdatensatz. Insbesondere erreicht SparseAD-B im Vergleich zu allen anderen Methoden, einschließlich UniAD und VAD, die niedrigste durchschnittliche L2-Fehler- und Kollisionsrate, was die Überlegenheit unseres Ansatzes und unserer Architektur demonstriert. Ähnlich wie bei vorgelagerten Aufgaben, einschließlich der Wahrnehmung von Hindernissen und der Bewegungsvorhersage, verbessert SparseAD die Leistung mit Radar oder einem leistungsfähigeren Backbone-Netzwerk weiter.

Das obige ist der detaillierte Inhalt vonnuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
Detaillierte Schritte zum Bereinigen des Speichers in Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Öffnen Sie Xiaohongshu, klicken Sie unten rechts auf „Ich“. 2. Klicken Sie auf das Einstellungssymbol und dann auf „Allgemein“. 3. Klicken Sie auf „Cache leeren“.
 Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Was tun, wenn Ihr Huawei-Telefon nicht über genügend Speicher verfügt (Praktische Methoden zur Lösung des Problems des unzureichenden Speichers)
Apr 29, 2024 pm 06:34 PM
Unzureichender Speicher auf Huawei-Mobiltelefonen ist mit der Zunahme mobiler Anwendungen und Mediendateien zu einem häufigen Problem geworden, mit dem viele Benutzer konfrontiert sind. Um Benutzern zu helfen, den Speicherplatz ihres Mobiltelefons voll auszunutzen, werden in diesem Artikel einige praktische Methoden vorgestellt, um das Problem des unzureichenden Speichers auf Huawei-Mobiltelefonen zu lösen. 1. Cache bereinigen: Verlaufsdatensätze und ungültige Daten, um Speicherplatz freizugeben und von Anwendungen generierte temporäre Dateien zu löschen. Suchen Sie in den Huawei-Telefoneinstellungen nach „Speicher“, klicken Sie auf die Schaltfläche „Cache löschen“ und löschen Sie dann die Cache-Dateien der Anwendung. 2. Deinstallieren Sie selten verwendete Anwendungen: Um Speicherplatz freizugeben, löschen Sie einige selten verwendete Anwendungen. Ziehen Sie es an den oberen Rand des Telefonbildschirms, drücken Sie lange auf das Symbol „Deinstallieren“ der Anwendung, die Sie löschen möchten, und klicken Sie dann auf die Bestätigungsschaltfläche, um die Deinstallation abzuschließen. 3.Mobile Anwendung auf
 Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Wie man Deepseek vor Ort fein abgestimmt
Feb 19, 2025 pm 05:21 PM
Die lokale Feinabstimmung von Deepseek-Klasse-Modellen steht vor der Herausforderung unzureichender Rechenressourcen und Fachkenntnisse. Um diese Herausforderungen zu bewältigen, können die folgenden Strategien angewendet werden: Modellquantisierung: Umwandlung von Modellparametern in Ganzzahlen mit niedriger Präzision und Reduzierung des Speicherboots. Verwenden Sie kleinere Modelle: Wählen Sie ein vorgezogenes Modell mit kleineren Parametern für eine einfachere lokale Feinabstimmung aus. Datenauswahl und Vorverarbeitung: Wählen Sie hochwertige Daten aus und führen Sie eine geeignete Vorverarbeitung durch, um eine schlechte Datenqualität zu vermeiden, die die Modelleffizienz beeinflusst. Batch -Training: Laden Sie für große Datensätze Daten in Stapel für das Training, um den Speicherüberlauf zu vermeiden. Beschleunigung mit GPU: Verwenden Sie unabhängige Grafikkarten, um den Schulungsprozess zu beschleunigen und die Trainingszeit zu verkürzen.
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
 Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
Was tun, wenn der Edge-Browser zu viel Speicher beansprucht? Was tun, wenn der Edge-Browser zu viel Speicher beansprucht?
May 09, 2024 am 11:10 AM
1. Rufen Sie zunächst den Edge-Browser auf und klicken Sie auf die drei Punkte in der oberen rechten Ecke. 2. Wählen Sie dann in der Taskleiste [Erweiterungen] aus. 3. Schließen oder deinstallieren Sie als Nächstes die Plug-Ins, die Sie nicht benötigen.
 Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Für nur 250 US-Dollar zeigt Ihnen der technische Leiter von Hugging Face Schritt für Schritt, wie Sie Llama 3 verfeinern
May 06, 2024 pm 03:52 PM
Die bekannten großen Open-Source-Sprachmodelle wie Llama3 von Meta, Mistral- und Mixtral-Modelle von MistralAI und Jamba von AI21 Lab sind zu Konkurrenten von OpenAI geworden. In den meisten Fällen müssen Benutzer diese Open-Source-Modelle anhand ihrer eigenen Daten verfeinern, um das Potenzial des Modells voll auszuschöpfen. Es ist nicht schwer, ein großes Sprachmodell (wie Mistral) im Vergleich zu einem kleinen mithilfe von Q-Learning auf einer einzelnen GPU zu optimieren, aber die effiziente Feinabstimmung eines großen Modells wie Llama370b oder Mixtral blieb bisher eine Herausforderung . Deshalb Philipp Sch, technischer Leiter von HuggingFace
