
 Technologie-Peripheriegeräte
KI
EEG-Synthese natürlicher Sprache! LeCun leitet neue Ergebnisse des Nature-Unterjournals weiter, und der Code ist Open Source
Technologie-Peripheriegeräte
KI
EEG-Synthese natürlicher Sprache! LeCun leitet neue Ergebnisse des Nature-Unterjournals weiter, und der Code ist Open Source
EEG-Synthese natürlicher Sprache! LeCun leitet neue Ergebnisse des Nature-Unterjournals weiter, und der Code ist Open Source

Der neueste Fortschritt bei Gehirn-Computer-Schnittstellen wurde im Nature-Subjournal veröffentlicht und LeCun, einer der drei Giganten des Deep Learning, kam, um ihn voranzutreiben.
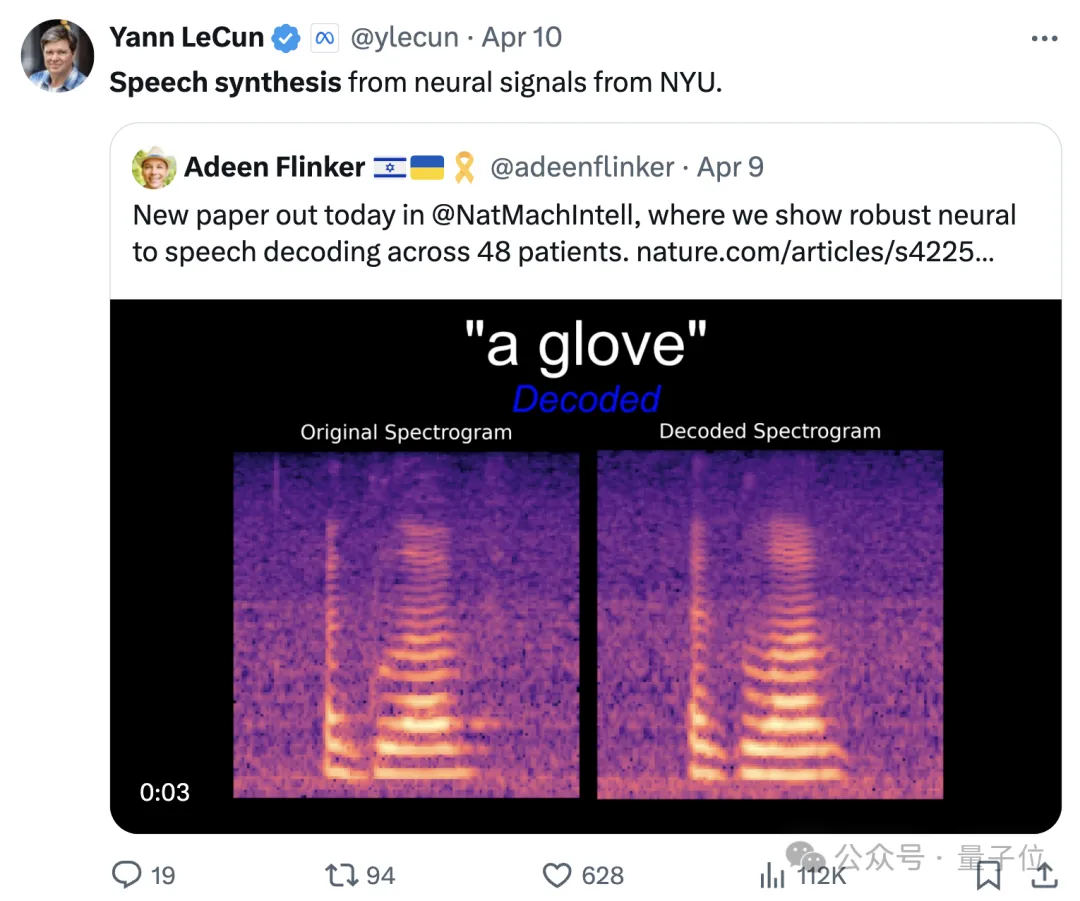
Dieses Mal werden neuronale Signale für die Sprachsynthese genutzt, um Menschen mit Aphasie aufgrund neurologischer Defekte dabei zu helfen, ihre Kommunikationsfähigkeit wiederzuerlangen.
Es wird berichtet, dass ein Forschungsteam der New York University einen neuen Typ eines differenzierbaren Sprachsynthesizers entwickelt hat, der ein leichtes Faltungs-Neuronales Netzwerk verwenden kann, um Sprache in eine Reihe interpretierbarer Sprachparameter (wie Tonhöhe, Lautstärke, Formantenfrequenz, usw.) und resynthetisieren die Sprache durch einen differenzierbaren Sprachsynthesizer.
Durch die Zuordnung neuronaler Signale zu diesen Sprachparametern haben die Forscher ein neuronales Sprachdekodierungssystem entwickelt, das gut interpretierbar und auf Situationen mit geringem Datenvolumen anwendbar ist und natürlich klingende Sprache erzeugen kann.
Insgesamt 48 Forscher sammelten Daten von Probanden und führten Experimente durch, um die Sprachdekodierung zu verifizieren und zukünftige hochpräzise Gehirn-Computer-Schnittstellen zu evaluieren.
Die Ergebnisse zeigen, dass das Framework hohe und niedrige räumliche Abtastdichten verarbeiten und EEG-Signale aus der linken und rechten Hemisphäre verarbeiten kann, was starke Fähigkeiten zur Sprachdekodierung zeigt.

Sprachdekodierung neuronaler Signale ist schwierig!
Zuvor hat Musks Firma Neuralink erfolgreich Elektroden in das Gehirn eines Probanden implantiert, die einfache Cursoroperationen ausführen können, um Funktionen wie Tippen auszuführen.
Allerdings gilt die Dekodierung neuronaler Sprache allgemein als komplexer.
Die meisten Versuche, Neuro-Sprachdecoder und andere hochpräzise Gehirn-Computer-Schnittstellenmodelle zu entwickeln, stützen sich auf eine besondere Art von Daten: Elektrokortikographie (ECoG) aufgezeichnete Probandendaten, normalerweise von Epilepsiepatienten, die sich in Behandlung befinden.
Verwenden Sie bei Patienten mit Epilepsie implantierte Elektroden, um beim Sprechen Daten aus der Großhirnrinde zu sammeln. Diese Daten haben eine hohe räumliche und zeitliche Auflösung und haben Forschern dabei geholfen, eine Reihe bemerkenswerter Ergebnisse auf dem Gebiet der Sprachdekodierung zu erzielen.
Allerdings steht die Sprachdekodierung neuronaler Signale noch vor zwei großen Herausforderungen.
- Die Daten, die zum Trainieren personalisierter neuronaler Sprachdekodierungsmodelle verwendet werden, sind zeitlich sehr begrenzt, normalerweise nur etwa zehn Minuten, während Deep-Learning-Modelle oft eine große Menge an Trainingsdaten benötigen, um zu fahren.
- Die menschliche Aussprache ist sehr unterschiedlich. Selbst wenn dieselbe Person wiederholt dasselbe Wort spricht, ändern sich die Sprechgeschwindigkeit, die Intonation und die Tonhöhe, was den vom Modell erstellten Darstellungsraum komplexer macht.
Frühe Versuche, neuronale Signale in Sprache zu dekodieren, stützten sich hauptsächlich auf lineare Modelle. Die Modelle erforderten normalerweise keine großen Trainingsdatensätze und waren gut interpretierbar, aber die Genauigkeit war sehr gering.
Auf der Grundlage tiefer neuronaler Netze, insbesondere der Verwendung von Faltungs- und wiederkehrenden neuronalen Netzarchitekturen, wurden kürzlich viele Versuche in den beiden Schlüsseldimensionen der Simulation der latenten Zwischendarstellung von Sprache und der Qualität synthetisierter Sprache unternommen. Beispielsweise gibt es Studien, die die Aktivität der Großhirnrinde in Mundbewegungsräume dekodieren und diese dann in Sprache umwandeln. Obwohl die Dekodierungsleistung leistungsstark ist, klingt die rekonstruierte Stimme unnatürlich.
Andererseits rekonstruieren einige Methoden erfolgreich natürlich klingende Sprache mithilfe von Wavenet-Vocoder, generativem gegnerischen Netzwerk (GAN) usw., aber die Genauigkeit ist begrenzt.
Eine kürzlich in Nature veröffentlichte Studie erreichte sowohl Genauigkeit als auch Genauigkeit, indem sie quantisierte HuBERT-Merkmale als Zwischendarstellungsraum und einen vortrainierten Sprachsynthesizer verwendete, um diese Merkmale bei einem Patienten mit einem implantierten Gerät in Sprache umzuwandeln.
Allerdings können die HuBERT-Funktionen keine sprecherspezifischen akustischen Informationen darstellen und nur feste und einheitliche Sprechertöne erzeugen. Daher sind zusätzliche Modelle erforderlich, um diesen universellen Klang in die Stimme eines bestimmten Patienten umzuwandeln. Darüber hinaus wurde in dieser Studie und den meisten früheren Versuchen eine nicht-kausale Architektur verwendet, was ihre Verwendung in praktischen Gehirn-Computer-Schnittstellenanwendungen, die zeitliche kausale Operationen erfordern, möglicherweise einschränkt. Aufbau eines differenzierbaren SprachsynthesizersDas Forschungsteam des NYU Video Lab und des Flinker Lab führte ein neues Decodierungsrahmenwerk für das Signal-zu-Sprache-Signal des Elektroenzephalogramms
(ECoG) ein und konstruierte eine niedrigdimensionale Zwischendarstellung(latente Darstellung mit niedriger Dimension)
, der von einem Sprachcodec-Modell generiert wird, das nur Sprachsignale verwendet.△Neural Speech Decoding Framework
Konkret besteht das Framework aus zwei Teilen: 
Ein Teil ist der ECoG-Decoder, der das ECoG-Signal in akustische Sprachparameter umwandelt, die wir verstehen können (z. B. Tonhöhe, ob Ton). Produktion, Lautstärke und Formantfrequenz usw.);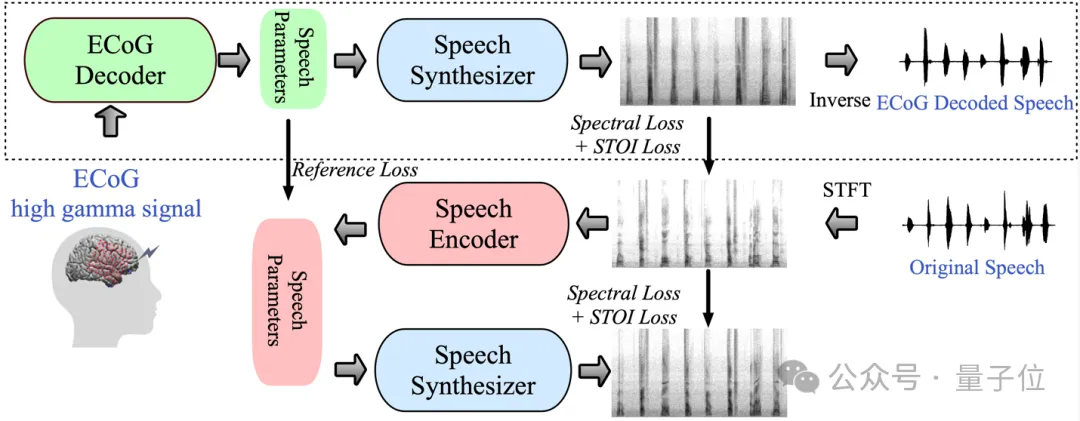
Der andere Teil ist der Sprachsynthesizer, der diese Sprachparameter in ein Spektrogramm umwandelt.
Die Forscher haben einen differenzierbaren Sprachsynthesizer entwickelt, der es dem Sprachsynthesizer ermöglicht, während des Trainings des ECoG-Decoders auch am Training teilzunehmen und gemeinsam zu optimieren, um den Fehler bei der Spektrogrammrekonstruktion zu reduzieren.
Dieser niedrigdimensionale latente Raum ist hochgradig interpretierbar, gepaart mit dem leichten vorab trainierten Sprachkodierer, um Referenz-Sprachparameter zu generieren, was Forschern hilft, ein effizientes neuronales Sprachdekodierungs-Framework aufzubauen und das Problem der sehr knappen Daten in der Sprache zu überwinden Bereich der Sprachdekodierung.
Dieses Framework kann natürliche Sprache erzeugen, die der eigenen Stimme des Sprechers sehr nahe kommt, und der ECoG-Decoder-Teil kann in verschiedene Deep-Learning-Modellarchitekturen eingebunden werden und unterstützt auch kausale Operationen.
Forscher sammelten und verarbeiteten ECoG-Daten von 48 neurochirurgischen Patienten und verwendeten dabei mehrere Deep-Learning-Architekturen (einschließlich Faltung, rekurrentes neuronales Netzwerk und Transformer) als ECoG-Decoder.
Das Framework hat bei verschiedenen Modellen eine hohe Genauigkeit bewiesen, wobei die beste Leistung mit der Faltungsarchitektur (ResNet) erzielt wurde. Das von den Forschern in diesem Artikel vorgeschlagene Framework kann nur durch kausale Operationen und eine relativ niedrige Abtastrate (niedrige Dichte, 10 mm Abstand) eine hohe Genauigkeit erreichen. Sie demonstrierten außerdem die Fähigkeit, eine effiziente Sprachdekodierung sowohl aus der linken als auch aus der rechten Gehirnhälfte durchzuführen, wodurch die Anwendung der neuronalen Sprachdekodierung auf die rechte Hemisphäre ausgeweitet wurde.
△ Differenzierbare Sprachsynthesizer-Architektur
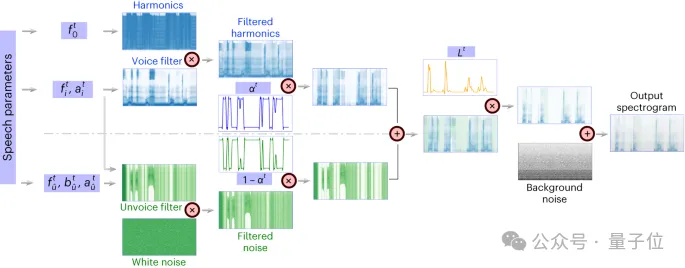 △ Differenzierbare Sprachsynthesizer-Architektur
△ Differenzierbare Sprachsynthesizer-Architektur Differenzierbarer Sprachsynthesizer
(Sprachsynthesizer)macht die Aufgabe der Sprachneusynthese sehr effizient und kann eine sehr kleine Sprachsynthese verwenden, um den Originalton mit High-Fidelity-Audio abzugleichen. Das Prinzip des differenzierbaren Sprachsynthesizers basiert auf dem Prinzip des menschlichen Erzeugungssystems und unterteilt die Sprache in zwei Teile: Stimme
(zur Modellierung von Vokalen)und Unvoice (zur Modellierung von Konsonanten) . Der Sprachteil kann zunächst das Grundfrequenzsignal zur Erzeugung von Harmonischen verwenden und es mit einem Filter filtern, der aus den Formantenspitzen von F1–F6 besteht, um die spektralen Eigenschaften des Vokalteils zu erhalten.
Für den Unvoice-Teil haben die Forscher das weiße Rauschen mit entsprechenden Filtern gefiltert, um das entsprechende Spektrum zu erhalten. Ein lernbarer Parameter kann das Mischungsverhältnis der beiden Teile zu jedem Zeitpunkt steuern. Anschließend wird das Lautstärkesignal verstärkt und Hintergrundgeräusche hinzugefügt um das endgültige Sprachspektrum zu erhalten.
△ Sprachkodierer und ECoG-Dekodierer
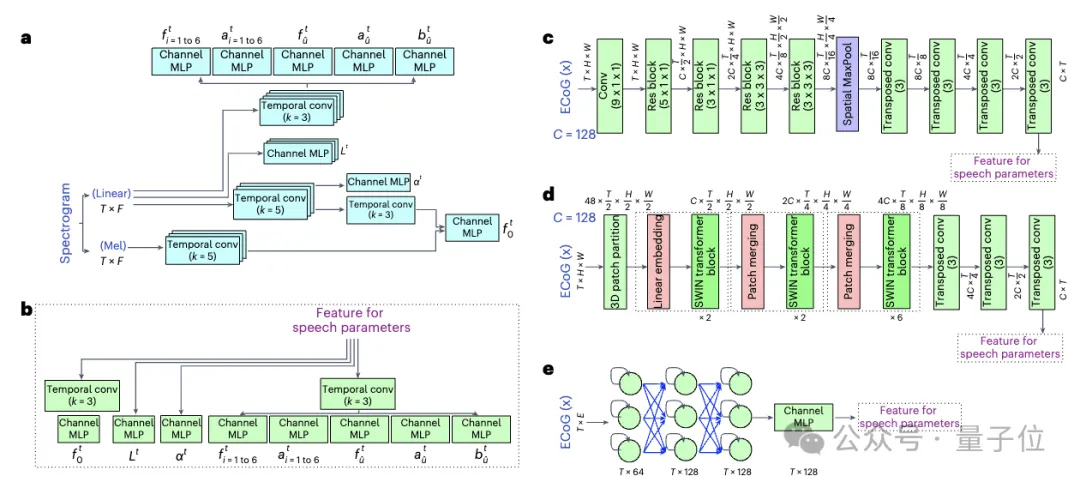 △ Sprachkodierer und ECoG-Dekodierer
△ Sprachkodierer und ECoG-Dekodierer Forschungsergebnisse
1. Sprachdekodierungsergebnisse mit zeitlicher Kausalität
Zunächst verglichen die Forscher direkt verschiedene Modellarchitekturen Faltung
(ResNet)und Schleife Der Unterschied in der Sprachdekodierung Leistung zwischen (LSTM) und Transformer (3D Swin) . Es ist erwähnenswert, dass diese Modelle zeitlich nicht kausale
(nicht kausale)oder kausale Operationen durchführen können. Die Kausalität der Dekodierung von Modellen hat große Auswirkungen auf Anwendungen von Brain-Computer Interfaces
(BCI): Kausalmodelle verwenden nur vergangene und aktuelle neuronale Signale, um Sprache zu erzeugen, während akausale Modelle auch zukünftige neuronale Signale verwenden, was in Echtzeit nicht möglich ist in der Anwendung. Daher konzentrierten sie sich auf den Vergleich der Leistung desselben Modells bei der Durchführung akausaler und kausaler Operationen.
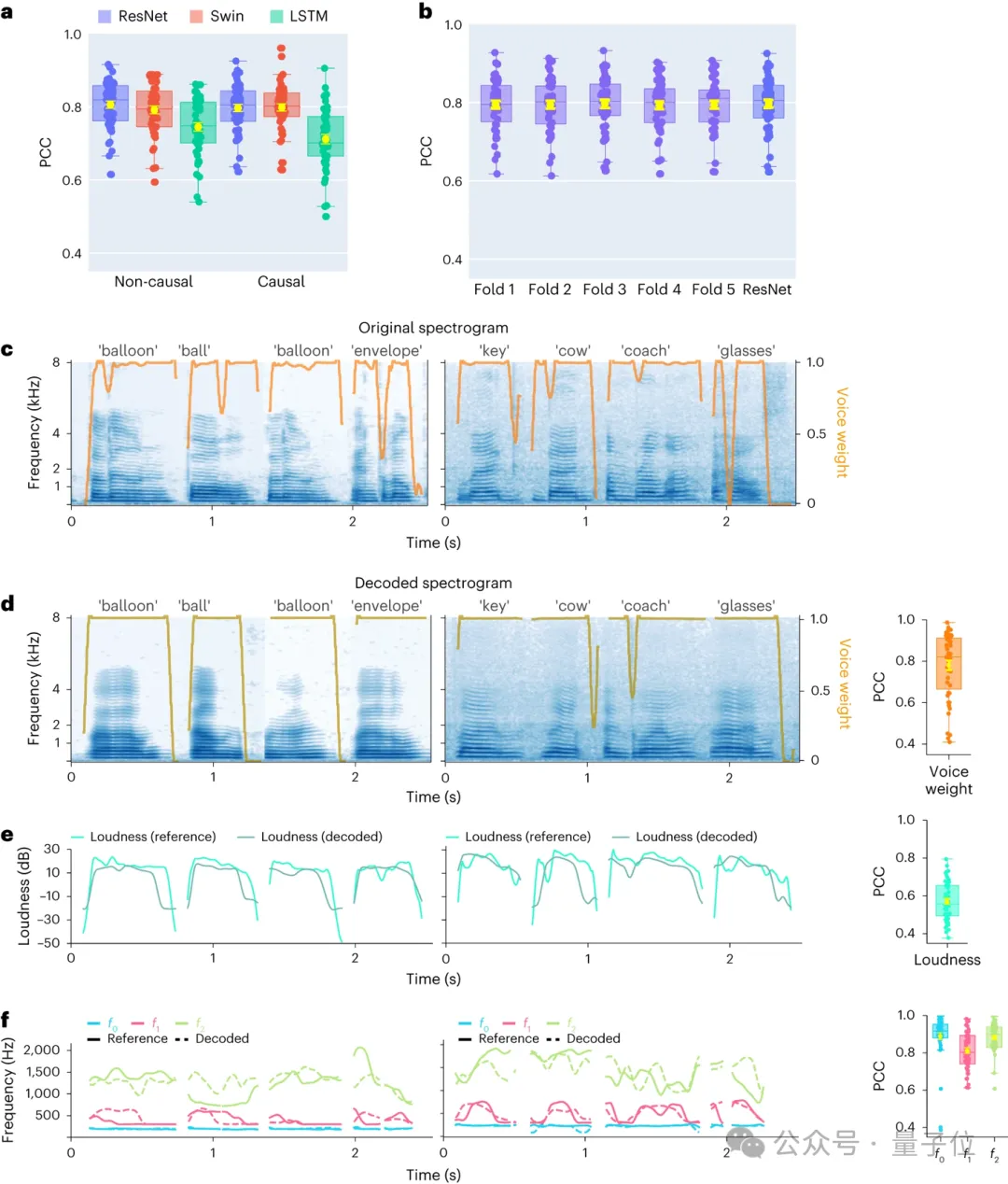 Es wurde festgestellt, dass sogar die kausale Version des ResNet-Modells mit der nicht-kausalen Version vergleichbar ist, ohne dass es einen signifikanten Unterschied zwischen den beiden gibt. Ebenso ist die Leistung der kausalen und nicht-kausalen Version des Swin-Modells ähnlich, aber die Leistung der kausalen Version des LSTM-Modells ist deutlich geringer als die der nicht-kausalen Version.
Es wurde festgestellt, dass sogar die kausale Version des ResNet-Modells mit der nicht-kausalen Version vergleichbar ist, ohne dass es einen signifikanten Unterschied zwischen den beiden gibt. Ebenso ist die Leistung der kausalen und nicht-kausalen Version des Swin-Modells ähnlich, aber die Leistung der kausalen Version des LSTM-Modells ist deutlich geringer als die der nicht-kausalen Version.
Forscher demonstrieren eine durchschnittliche Dekodierungsgenauigkeit (N=48) für mehrere wichtige Sprachparameter, darunter Klanggewicht (zur Unterscheidung von Vokalen von Konsonanten), Lautstärke, Tonhöhe f0, erster Formant f1 und zweiter Formant Peak f2. Eine genaue Rekonstruktion dieser Sprachparameter, insbesondere Tonhöhe, Klanggewicht und die ersten beiden Formanten, ist entscheidend für eine genaue Sprachdekodierung und -rekonstruktion, die die Stimme des Teilnehmers auf natürliche Weise nachahmt.
Die Ergebnisse zeigen, dass sowohl nicht-kausale als auch kausale Modelle vernünftige Dekodierungsergebnisse erzielen können, was eine positive Orientierung für zukünftige Forschung und Anwendungen bietet.
2. Forschung zur Sprachdekodierung und räumlichen Abtastrate neuronaler Signale der linken und rechten Gehirnhälfte.
Die Forscher verglichen außerdem die Ergebnisse der Sprachdekodierung der linken und rechten Gehirnhälfte. Die meisten Studien haben sich auf die linke Hemisphäre konzentriert, die die Sprech- und Sprachfunktionen dominiert, während der Dekodierung von Sprachinformationen aus der rechten Hemisphäre weniger Aufmerksamkeit geschenkt wurde.
Vor diesem Hintergrund verglichen sie die Dekodierungsleistung der linken und rechten Gehirnhälfte der Teilnehmer, um die Möglichkeit zu überprüfen, die rechte Gehirnhälfte zur Sprachwiederherstellung zu nutzen.
Von den 48 in der Studie erfassten Probanden wurden die ECoG-Signale von 16 Probanden aus der rechten Gehirnhälfte erfasst.
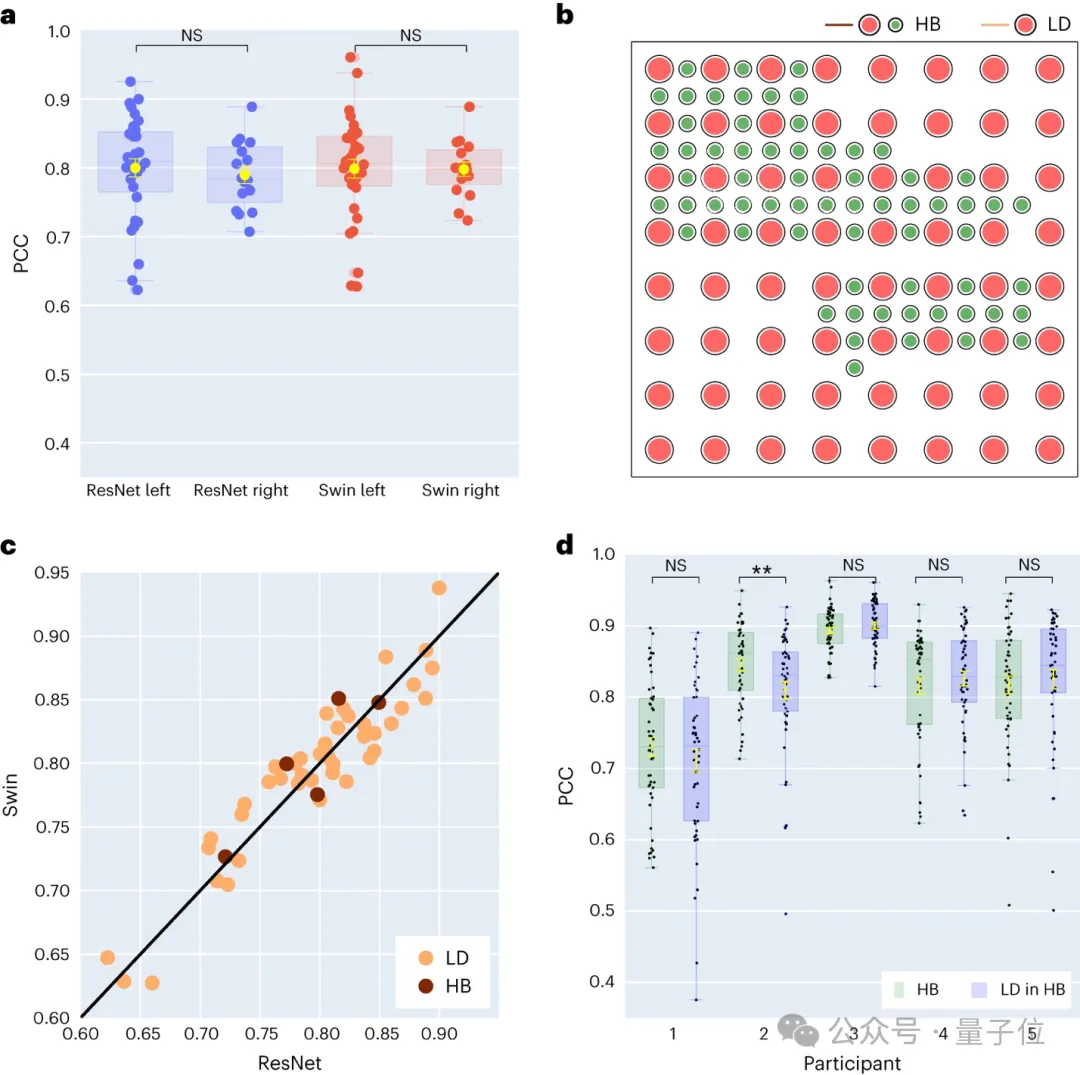
Durch den Vergleich der Leistung von ResNet- und Swin-Dekodierern haben wir festgestellt, dass die rechte Gehirnhälfte auch eine stabile Sprachdekodierung durchführen kann und der Dekodierungseffekt geringer ist als der der linken Gehirnhälfte.
Das bedeutet, dass für Patienten mit einer Schädigung der linken Hemisphäre und einem Verlust der Sprachfähigkeit die Nutzung neuronaler Signale der rechten Hemisphäre zur Wiederherstellung der Sprache eine praktikable Lösung sein kann.
Dann untersuchten sie auch den Einfluss der Elektroden-Abtastdichte auf den Sprachdekodierungseffekt.
Frühere Studien verwendeten meist Elektrodengitter mit höherer Dichte (0,4 mm) , während die Dichte der in der klinischen Praxis üblicherweise verwendeten Elektrodengitter geringer ist (LD 1 cm) . Fünf Teilnehmer verwendeten Hybrid-Elektrodengitter vom Typ (HB), bei denen es sich in erster Linie um Probenentnahme mit geringer Dichte handelt, die jedoch zusätzliche Elektroden enthalten. Die restlichen 43 Teilnehmer wurden in geringer Dichte beprobt. Die Dekodierungsleistung dieser Hybridproben (HB) ist ähnlich wie bei herkömmlichen Proben mit niedriger Dichte (LD) .
Dies zeigt, dass das Modell Sprachinformationen von der Großhirnrinde mit unterschiedlichen räumlichen Abtastdichten lernen kann, was auch impliziert, dass die in der klinischen Praxis üblicherweise verwendete Abtastdichte für zukünftige Gehirn-Computer-Schnittstellenanwendungen ausreichend sein könnte.3. Forschung zum Beitrag verschiedener Gehirnbereiche der linken und rechten Gehirnhälfte zur Sprachdekodierung
Die Forscher untersuchten auch den Beitrag sprachbezogener Bereiche des Gehirns beim Sprachdekodierungsprozess, was für die Zukunft hilfreich sein wird Sprachimplantationen in der linken und rechten Gehirnhälfte bieten eine wichtige Referenz. Verwendet Okklusionstechnologie(Okklusionsanalyse), um den Beitrag verschiedener Gehirnbereiche zur Sprachdekodierung zu bewerten.
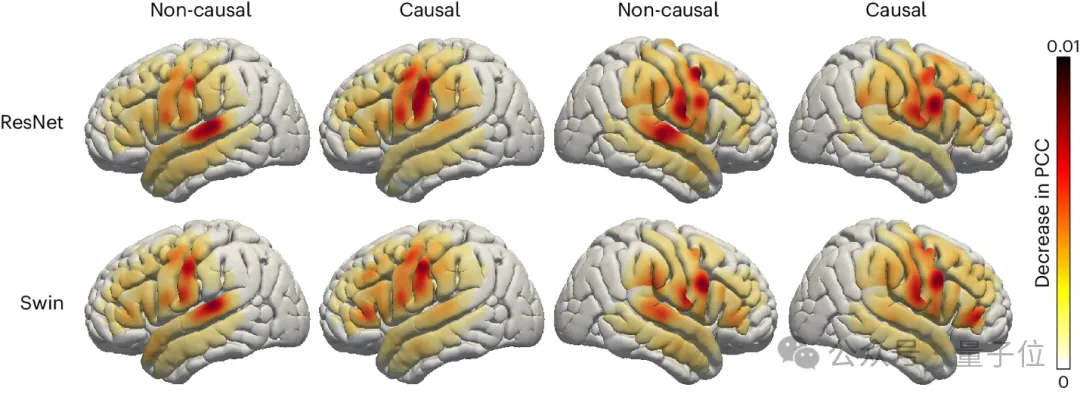
Auf dem Gebiet der Gehirn-Computer-Schnittstelle befindet sich die aktuelle Forschung noch in einem sehr frühen Stadium. Mit der Iteration der Hardware-Technologie und dem schnellen Fortschritt der Deep-Learning-Technologie werden die Ideen für Gehirn-Computer-Schnittstellen in Science-Fiction-Filmen auftauchen der Realität näher kommen.
Papierlink: https://www.nature.com/articles/s42256-024-00824-8. GitHub-Link: https://github.com/flinkerlab/neural_speech_decoding.
Weitere generierte Sprachbeispiele: https://xc1490.github.io/nsd/.
Das obige ist der detaillierte Inhalt vonEEG-Synthese natürlicher Sprache! LeCun leitet neue Ergebnisse des Nature-Unterjournals weiter, und der Code ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Frage Beschreibung: Wie erhalten Sie die Daten der Versandregion der Überseeversion? Gibt es bereitgestellte Ressourcen? Werden Sie im grenzüberschreitenden E-Commerce oder im globalisierten Geschäft genau ...
