
 Technologie-Peripheriegeräte
KI
OWASP veröffentlicht Checkliste für Netzwerksicherheit und Governance für umfangreiche Sprachmodelle
Technologie-Peripheriegeräte
KI
OWASP veröffentlicht Checkliste für Netzwerksicherheit und Governance für umfangreiche Sprachmodelle
OWASP veröffentlicht Checkliste für Netzwerksicherheit und Governance für umfangreiche Sprachmodelle

Das größte Risiko, dem die Technologie der künstlichen Intelligenz derzeit ausgesetzt ist, besteht darin, dass die Entwicklungs- und Anwendungsgeschwindigkeit großer Sprachmodelle (LLM) und generativer Technologie der künstlichen Intelligenz die Geschwindigkeit von Sicherheit und Governance bei weitem übertroffen hat.

Die Nutzung generativer KI und großer Sprachmodellprodukte von Unternehmen wie OpenAI, Anthropic, Google und Microsoft nimmt exponentiell zu. Gleichzeitig nehmen auch Open-Source-Lösungen für große Sprachmodelle schnell zu. Open-Source-Communitys für künstliche Intelligenz wie HuggingFace bieten eine große Anzahl von Open-Source-Modellen, Datensätzen und KI-Anwendungen.
Um die Entwicklung künstlicher Intelligenz voranzutreiben, entwickeln und stellen Branchenorganisationen wie OWASP, OpenSSF und CISA aktiv wichtige Ressourcen für die Sicherheit und Governance künstlicher Intelligenz bereit, wie z. B. OWASP AI Exchange, AI Security and Privacy Guide und das Top-Ten-Risikoliste großer Sprachmodelle (LLMTop10).
Kürzlich hat OWASP eine umfassende Checkliste für Cybersicherheit und Governance für Sprachmodelle veröffentlicht, die die Lücke in der Sicherheitsgovernance für generative künstliche Intelligenz schließt. Der spezifische Inhalt lautet wie folgt:
OWASPs Definition von KI-Typen und Bedrohungen
OWASPs Sprachmodell für Cybersicherheit und Governance Die Checkliste definiert die Unterschiede zwischen künstlicher Intelligenz, maschinellem Lernen, generativer KI und großen Sprachmodellen.
Zum Beispiel lautet OWASPs Definition von generativer KI: eine Art maschinelles Lernen, die sich auf die Erstellung neuer Daten konzentriert, während große Sprachmodelle ein KI-Modell sind, das zur Verarbeitung und Generierung menschenähnlicher „natürlicher Inhalte“ verwendet wird – – Sie treffen Vorhersagen auf der Grundlage dieser die Eingabe, die ihnen bereitgestellt wird, und die Ausgabe ist menschenähnlicher „natürlicher Inhalt“.
In Bezug auf die zuvor veröffentlichte „Big Language Model Top Ten Threat List“ ist OWASP davon überzeugt, dass sie Cybersicherheitsexperten dabei helfen kann, mit der sich schnell entwickelnden KI-Technologie Schritt zu halten, wichtige Bedrohungen zu identifizieren und sicherzustellen, dass Unternehmen über grundlegende Sicherheitskontrollen zum Schutz und zur Unterstützung der Nutzung verfügen Geschäft mit generativer künstlicher Intelligenz und großen Sprachmodellen. OWASP ist jedoch der Ansicht, dass diese Liste nicht vollständig ist und auf der Grundlage der Entwicklung generativer künstlicher Intelligenz kontinuierlich verbessert werden muss.
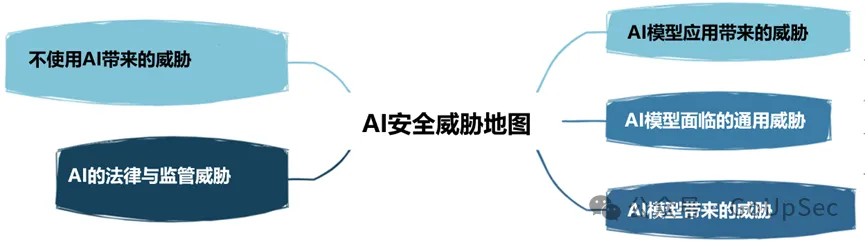
OWASP unterteilt KI-Sicherheitsbedrohungen in die folgenden fünf Typen:
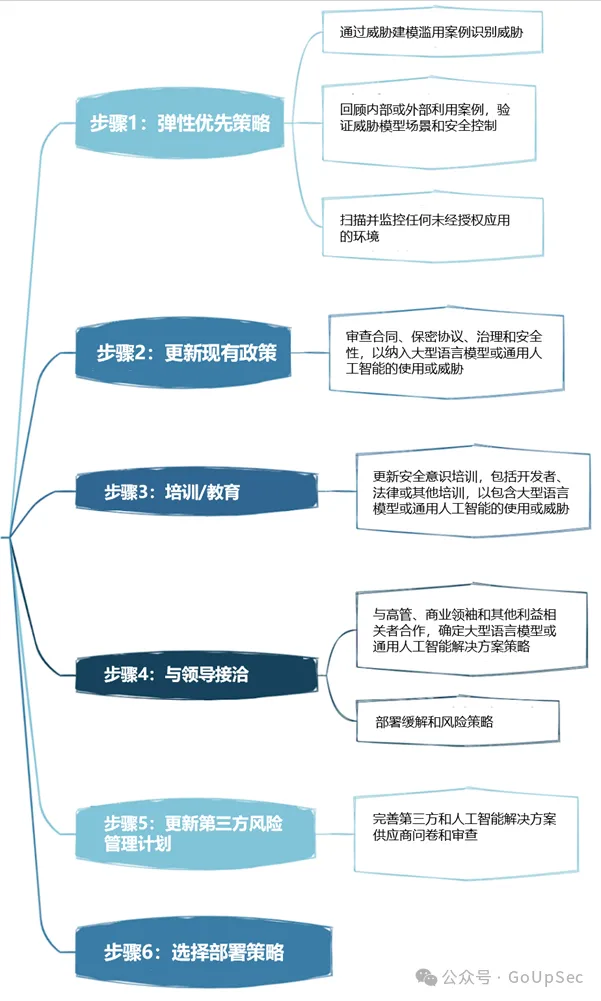
Die Bereitstellung der Sicherheits-Governance-Strategie für das große Sprachmodell von OWASP ist in sechs Schritte unterteilt:
Das Folgende ist die OWASP-Liste für Netzwerksicherheit und -governance für das große Sprachmodell :
1. Das Gegnerrisiko großer Sprachmodelle betrifft nicht nur Konkurrenten, sondern auch Angreifer. Der Schwerpunkt liegt nicht nur auf der Angriffshaltung, sondern auch auf der Geschäftshaltung. Dazu gehört das Verständnis, wie Wettbewerber KI nutzen, um Geschäftsergebnisse voranzutreiben, sowie die Aktualisierung interner Prozesse und Richtlinien, wie etwa Incident-Response-Pläne (IRPs), um auf generative KI-Angriffe und -Vorfälle zu reagieren.
2. Bedrohungsmodellierung
Bedrohungsmodellierung ist eine immer beliebter werdende Sicherheitstechnologie, die mit der Förderung des Konzepts sicherer Designsysteme immer mehr Aufmerksamkeit erregt und von der US-amerikanischen Cybersecurity and Infrastructure Security Agency (CISA) genehmigt wurde andere maßgebliche Organisationen. Bei der Bedrohungsmodellierung muss darüber nachgedacht werden, wie Angreifer große Sprachmodelle und generative KI nutzen, um die Ausnutzung von Schwachstellen zu beschleunigen, über die Fähigkeit des Unternehmens, bösartige große Sprachmodelle zu erkennen, und darüber, ob Unternehmen große Sprachmodelle und generative KI-Plattformen vor internen Systemen und Umgebungen schützen können.
3. Checkliste für künstliche Intelligenz-Assets
Das Sprichwort „Man kann ein unbekanntes Asset nicht schützen“ gilt auch für die Bereiche generative KI und große Sprachmodelle. Dieser Teil des OWASP-Inventars umfasst die Inventarisierung von KI-Assets für intern entwickelte KI-Lösungen sowie externe Tools und Plattformen.
OWASP betont, dass Unternehmen nicht nur verstehen müssen, welche Tools und Dienste intern verwendet werden, sondern auch deren Eigentümer, d. h. wer für die Nutzung dieser Tools und Dienste verantwortlich ist. Die Checkliste empfiehlt außerdem, KI-Komponenten in eine Software-Stückliste (SBOM) aufzunehmen und KI-Datenquellen und ihre jeweiligen Empfindlichkeiten zu dokumentieren.
Zusätzlich zur Inventarisierung vorhandener KI-Tools sollten Unternehmen auch einen sicheren Prozess für die Aufnahme zukünftiger KI-Tools und -Dienste in die Bestandsaufnahme etablieren.
4. Schulung zur Sensibilisierung für künstliche Intelligenz und Datenschutz
Es wird oft gesagt, dass „Menschen die größte Sicherheitslücke darstellen“. Modelle können menschliche Risiken erheblich mindern.
Dazu gehört es, den Mitarbeitern dabei zu helfen, bestehende Initiativen zur generativen KI/großen Sprachmodelle, Technologien und deren Fähigkeiten sowie wichtige Sicherheitsaspekte wie Datenschutzverletzungen zu verstehen. Darüber hinaus ist der Aufbau einer Sicherheitskultur des Vertrauens und der Transparenz von entscheidender Bedeutung.
Eine Kultur des Vertrauens und der Transparenz innerhalb des Unternehmens kann auch dazu beitragen, Bedrohungen durch Schatten-KI zu vermeiden, da Mitarbeiter andernfalls „heimlich“ Schatten-KI einsetzen, ohne es den IT- und Sicherheitsteams mitzuteilen.
5. Business Case für Projekte zur künstlichen Intelligenz . Lassen Sie sich vom Hype mitreißen. Ohne ein solides Geschäftsszenario führen KI-Anwendungen in Unternehmen wahrscheinlich zu schlechten Ergebnissen und erhöhen die Risiken.
6. Governance
Ohne Governance können Unternehmen keine Rechenschaftsmechanismen und klare Ziele für künstliche Intelligenz etablieren. In der OWASP-Checkliste wird empfohlen, dass Unternehmen ein RACI-Diagramm (Responsibility Allocation Matrix) für Anwendungen der künstlichen Intelligenz entwickeln, Risikoverantwortungen und Governance-Aufgaben erfassen und zuweisen sowie unternehmensweite Richtlinien und Verfahren für künstliche Intelligenz festlegen.
7. Rechtliches
Angesichts der rasanten Entwicklung der Technologie der künstlichen Intelligenz sind ihre rechtlichen Auswirkungen nicht zu unterschätzen und können erhebliche finanzielle Risiken und Reputationsrisiken für Unternehmen mit sich bringen.
Rechtsangelegenheiten im Bereich der künstlichen Intelligenz umfassen eine Reihe von Aktivitäten, wie z. B. die Produktgarantie für künstliche Intelligenz, die Endbenutzer-Lizenzvereinbarung (EULA) für künstliche Intelligenz, das Eigentum an Code, der mit Tools der künstlichen Intelligenz entwickelt wurde, Risiken in Bezug auf geistiges Eigentum und vertragliche Vergütungsklauseln usw. Kurz gesagt: Stellen Sie sicher, dass Ihr Rechtsteam oder Ihre Experten die verschiedenen unterstützenden rechtlichen Aktivitäten verstehen, die Ihr Unternehmen beim Einsatz generativer KI und großer Sprachmodelle durchführen sollte.
8. Regulierung
Auch die Regulierungsvorschriften für künstliche Intelligenz entwickeln sich rasant, wie zum Beispiel das EU-Gesetz zur künstlichen Intelligenz, und in anderen Ländern und Regionen werden bald Vorschriften eingeführt. Unternehmen sollten die KI-Compliance-Anforderungen ihres Landes kennen, beispielsweise die Mitarbeiterüberwachung, und ein klares Verständnis davon haben, wie ihre KI-Anbieter Daten speichern und löschen und deren Verwendung regeln.
9. Verwenden oder implementieren Sie große Sprachmodelllösungen.
Die Verwendung großer Sprachmodelllösungen erfordert die Berücksichtigung spezifischer Risiken und Kontrollen. Die OWASP-Checkliste listet Elemente wie Zugriffskontrolle, Schulung der Pipeline-Sicherheit, Zuordnung von Daten-Workflows und Verständnis bestehender oder potenzieller Schwachstellen in großen Sprachmodellmodellen und Lieferketten auf. Darüber hinaus sind sowohl anfänglich als auch fortlaufend Audits durch Dritte, Penetrationstests und sogar Codeüberprüfungen von Anbietern erforderlich.
10. Test, Bewertung, Verifizierung und Validierung (TEVV)
Der TEVV-Prozess ist ein Prozess, der speziell vom NIST in seinem Rahmen für künstliche Intelligenz empfohlen wird. Dazu gehört die Einrichtung kontinuierlicher Tests, Bewertungen, Validierungen und Validierungen während des gesamten Lebenszyklus des KI-Modells sowie die Bereitstellung von Ausführungsmetriken zur Funktionalität, Sicherheit und Zuverlässigkeit des KI-Modells.
11. Modellkarten und Risikokarten
Um große Sprachmodelle ethisch einzusetzen, verlangt die OWASP-Checkliste, dass Unternehmen Modell- und Risikokarten verwenden, die es Benutzern ermöglichen, KI-Systeme zu verstehen und ihnen zu vertrauen und Voreingenommenheit und Datenschutz offen anzusprechen. usw. mögliche negative Folgen.
Diese Karten können Elemente wie Modelldetails, Architektur, Trainingsdatenmethoden und Leistungsmetriken enthalten. Überlegungen zu verantwortungsvoller KI und Bedenken hinsichtlich Fairness und Transparenz werden ebenfalls hervorgehoben.
12RAG: Optimierung großer Sprachmodelle
Retrieval Augmented Generation (RAG) ist eine Methode zur Optimierung der Fähigkeit großer Sprachmodelle, relevante Daten aus bestimmten Quellen abzurufen. Dies ist eine der Möglichkeiten, vorab trainierte Modelle zu optimieren oder bestehende Modelle auf der Grundlage neuer Daten neu zu trainieren, um die Leistung zu verbessern. OWASP empfiehlt Unternehmen, RAG zu implementieren, um den Wert und die Effektivität großer Sprachmodelle zu maximieren.
13. AI Red Team
Abschließend unterstreicht die OWASP-Checkliste die Bedeutung von AI Red Teaming, das gegnerische Angriffe auf KI-Systeme simuliert, um Schwachstellen zu identifizieren und bestehende Kontrollen und Abwehrmaßnahmen zu validieren. OWASP betont, dass Red Teams ein integraler Bestandteil einer umfassenden Sicherheitslösung mit generativer KI und großen Sprachmodellen sein sollten.
Es ist erwähnenswert, dass Unternehmen auch ein klares Verständnis der Red-Team-Dienste sowie der Systemanforderungen und -fähigkeiten externer generativer KI und großer Anbieter von Sprachmodellen haben müssen, um Richtlinienverstöße oder sogar rechtliche Probleme zu vermeiden.
Das obige ist der detaillierte Inhalt vonOWASP veröffentlicht Checkliste für Netzwerksicherheit und Governance für umfangreiche Sprachmodelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Schritt-für-Schritt-Anleitung zur lokalen Verwendung von Groq Llama 3 70B
Jun 10, 2024 am 09:16 AM
Übersetzer |. Bugatti Review |. Chonglou Dieser Artikel beschreibt, wie man die GroqLPU-Inferenz-Engine verwendet, um ultraschnelle Antworten in JanAI und VSCode zu generieren. Alle arbeiten daran, bessere große Sprachmodelle (LLMs) zu entwickeln, beispielsweise Groq, der sich auf die Infrastrukturseite der KI konzentriert. Die schnelle Reaktion dieser großen Modelle ist der Schlüssel, um sicherzustellen, dass diese großen Modelle schneller reagieren. In diesem Tutorial wird die GroqLPU-Parsing-Engine vorgestellt und erläutert, wie Sie mithilfe der API und JanAI lokal auf Ihrem Laptop darauf zugreifen können. In diesem Artikel wird es auch in VSCode integriert, um uns dabei zu helfen, Code zu generieren, Code umzugestalten, Dokumentation einzugeben und Testeinheiten zu generieren. In diesem Artikel erstellen wir kostenlos unseren eigenen Programmierassistenten für künstliche Intelligenz. Einführung in die GroqLPU-Inferenz-Engine Groq
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Sieben coole technische Interviewfragen für GenAI und LLM
Jun 07, 2024 am 10:06 AM
Um mehr über AIGC zu erfahren, besuchen Sie bitte: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou unterscheidet sich von der traditionellen Fragendatenbank, die überall im Internet zu sehen ist erfordert einen Blick über den Tellerrand hinaus. Large Language Models (LLMs) gewinnen in den Bereichen Datenwissenschaft, generative künstliche Intelligenz (GenAI) und künstliche Intelligenz zunehmend an Bedeutung. Diese komplexen Algorithmen verbessern die menschlichen Fähigkeiten, treiben Effizienz und Innovation in vielen Branchen voran und werden zum Schlüssel für Unternehmen, um wettbewerbsfähig zu bleiben. LLM hat ein breites Anwendungsspektrum und kann in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung, der Spracherkennung und Empfehlungssystemen eingesetzt werden. Durch das Lernen aus großen Datenmengen ist LLM in der Lage, Text zu generieren
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
Stellen Sie große Sprachmodelle lokal in OpenHarmony bereit
Jun 07, 2024 am 10:02 AM
In diesem Artikel werden die Ergebnisse von „Local Deployment of Large Language Models in OpenHarmony“ auf der 2. OpenHarmony-Technologiekonferenz demonstriert. Open-Source-Adresse: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Die Implementierungsideen und -schritte bestehen darin, das leichtgewichtige LLM-Modellinferenz-Framework InferLLM auf das OpenHarmony-Standardsystem zu übertragen und ein Binärprodukt zu kompilieren, das auf OpenHarmony ausgeführt werden kann. InferLLM ist ein einfaches und effizientes L
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
