
 Technologie-Peripheriegeräte
KI
Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle
Technologie-Peripheriegeräte
KI
Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle
Ant Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle

Kürzlich wurde OneKE, ein großes Modell-Wissensextraktions-Framework, das gemeinsam von der Ant Group und der Zhejiang-Universität entwickelt wurde, als Open Source angekündigt und an die OpenKG-Community für offene Wissensgraphen gespendet.
Knowledge Graph ist eine der Schlüsseltechnologien, um Vertrauenswürdigkeit und Kontrollierbarkeit großer Modelle zu erreichen. Die Wissensextraktion kann beim Aufbau von Domänenwissensgraphen helfen. OneKE setzt sich dafür ein, Forschern und Entwicklern dabei zu helfen, Probleme wie Informationsextraktion, Textdatenstrukturierung und Wissensgraphenerstellung besser zu bewältigen.
Das Extrahieren von Risikoereignissen, Personenentitäten, institutionellen Entitäten usw. über OneKE kann den Ereigniskontext, Ereignisentwicklungstrends und Beziehungen zwischen Entitäten klar darstellen. Das erstellte Diagramm kann großen Modellen dabei helfen, komplexe Überlegungen über Entitäten und Dokumente hinweg zu realisieren. OneKE ist zweisprachig in Chinesisch und Englisch, unterstützt die Open-Source-Frameworks OpenSPG und DeepKE und kann sofort verwendet werden.
Große Sprachmodelle haben die Fähigkeit künstlicher Intelligenzsysteme, Weltwissen zu verarbeiten, erheblich verbessert. Allerdings sind reale Informationen stark fragmentiert und unstrukturiert. Wenn also große Sprachmodelle Informationsextraktionsaufgaben übernehmen, erzielen sie aufgrund des großen Unterschieds zwischen den extrahierten Inhalten und Ausdrücken in natürlicher Sprache immer noch schlechte Ergebnisse Es gibt viele Mehrdeutigkeiten, Polysemie, Metaphern usw., die die Aufgabe der Wissensextraktion vor größere Herausforderungen stellen. Dies führt auch dazu, dass die durch große Sprachmodelle dargestellte generative künstliche Intelligenz immer noch Probleme wie unzureichende Argumentationsfähigkeit, mangelndes Sachwissen und instabile Generierungsergebnisse aufweist, was die Industrialisierung großer Sprachmodelle erheblich behindert.
Das einheitliche Framework zur Wissensextraktion kann die Kosten für die Erstellung von Domänenwissensdiagrammen erheblich senken und verfügt über ein breites Spektrum an Anwendungsszenarien. Dies bedeutet, dass durch die Extraktion strukturierten Wissens aus massiven Daten, die Erstellung hochwertiger Wissensgraphen und die Herstellung logischer Verbindungen zwischen Wissenselementen erklärbare Argumentationsentscheidungen getroffen werden können, und es kann auch zur Verbesserung großer Modelle verwendet werden, um Illusionen zu lindern und die Stabilität zu verbessern. Beschleunigung der Anwendung großer Modelle in vertikalen Feldern.
Im medizinischen Bereich wird das Wissensmanagement der Erfahrung von Ärzten durch Wissensextraktion erreicht und kontrollierbare Hilfsdiagnosen und -behandlungen sowie medizinische Fragen und Antworten erstellt. Im Finanzbereich wird die Wissensextraktionsabteilung für Finanzindikatoren, Risikoereignisse, kausale Zusammenhänge, Industrieketten usw. verwendet, um eine automatische Erstellung von Finanzforschungsberichten, Risikovorhersagen, Industriekettenanalysen usw. zu erreichen. In Szenarien für Regierungsangelegenheiten kann die Kenntnis der Vorschriften für Regierungsangelegenheiten genutzt werden, um die Effizienz und genaue Entscheidungsfindung der Dienste für Regierungsangelegenheiten zu verbessern.
Um die industrielle Implementierung produktionsbasierter künstlicher Intelligenz zu beschleunigen, haben Ant Group und die Zhejiang-Universität ein gemeinsames Wissensgraphenlabor eingerichtet, das sich auf Themen wie die Konstruktion von Wissensgraphen mit großem Modell, wissensgestützte vertrauenswürdige und kontrollierbare Generierungsfunktionen usw. konzentriert Führen Sie eine umfassende Zusammenarbeit durch, um durch gemeinsame technische Forschung ein kontrollierbares Generierungs-Funktionsparadigma mit wechselseitiger Verbesserung großer Sprachmodelle und Wissensgraphen zu etablieren.
Ant Group und die Zhejiang-Universität haben gemeinsam die Fähigkeiten des Ant Bailing-Großmodells im Bereich der Wissensextraktion etabliert und verbessert und OneKE veröffentlicht, ein zweisprachiges Wissensextraktions-Framework für große Modelle in Chinesisch-Englisch, und eine Open-Source-Version basierend auf LLaMA2 Full veröffentlicht -Parameter-Feinabstimmung. Testindikatoren zeigen, dass OneKE bei mehreren vollständig überwachten Entitäts-/Beziehungs-/Ereignisextraktionsaufgaben ohne Stichprobe relativ gute Ergebnisse erzielt hat.
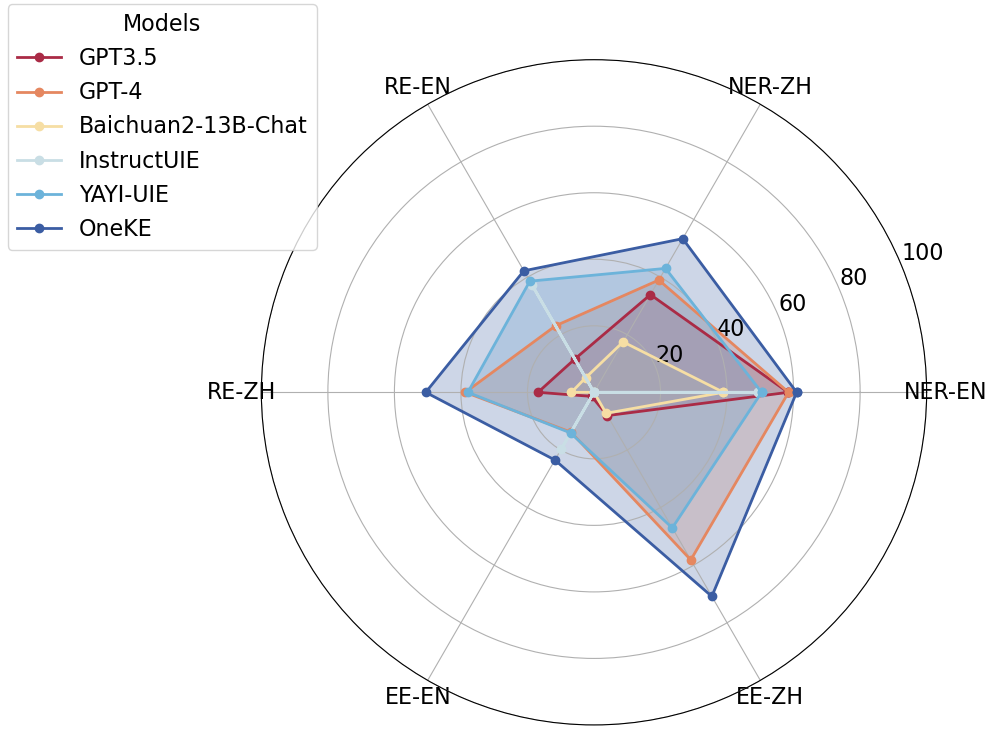
OneKE ist ein hervorragendes zweisprachiges verallgemeinerbares Wissensextraktionstool für Chinesisch. Es hat bei chinesischen NER-Aufgaben zur Erkennung benannter Entitäten, RE-Beziehungsextraktionsaufgaben und EE-Ereignisextraktionsaufgaben relativ gute Ergebnisse erzielt.
Liang Lei, Leiter des Wissensgraphen bei der Ant Group, sagte, dass Ant die Leistung der Wissensextraktion weiterhin optimieren wird, um den kontrollierbaren und vertrauenswürdigen Anforderungen großer Modelle in verschiedenen Szenarien gerecht zu werden. In Zukunft werden wir mit Industriepartnern zusammenarbeiten, um relevante technische Systeme auf verschiedene vertikale Bereiche wie Finanzen, medizinische Versorgung und Regierungsangelegenheiten anzuwenden und die industrielle Umsetzung steuerbarer Erzeugungstechnologie zu fördern, die auf Wissensgraphen und großen Sprachmodellen basiert.
Offizielle OneKE-Homepage: http://oneke.openkg.cn/
OpenSPG GitHub: https://github.com/OpenSPG/openspg
Das obige ist der detaillierte Inhalt vonAnt Group und die Zhejiang-Universität veröffentlichen gemeinsam OneKE, ein Open-Source-Framework zur Wissensextraktion großer Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 TYPECHO ROOTE VERFÜGBARKLOUTE: Warum ist mein/test/tag/his/10086 passungstesttagindex anstelle von testTagpage?
Apr 01, 2025 am 09:03 AM
TYPECHO ROOTE VERFÜGBARKLOUTE: Warum ist mein/test/tag/his/10086 passungstesttagindex anstelle von testTagpage?
Apr 01, 2025 am 09:03 AM
Analyse und Problemuntersuchung von typten-Routing-Matching-Regeln und Problemuntersuchungen analysiert und beantworten Fragen zu den inkonsistenten Ergebnissen der Registrierung von Typecho-Plug-in-Routing-Registrierung und den tatsächlichen Übereinstimmungsgebnissen ...
