
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Bei alltäglichen Aktivitäten führen die Bewegungen von Menschen oft zu sekundären Bewegungen der Kleidung und damit zu unterschiedlichen Falten der Kleidung, was ein Verständnis der Geometrie und Bewegung des menschlichen Körpers und der Kleidung (menschliche Körperhaltung und Geschwindigkeitsdynamik usw.) erfordert .) und Aussehen werden gleichzeitig dynamisch modelliert. Da dieser Prozess komplexe, nicht starre physische Interaktionen zwischen Menschen und Kleidung beinhaltet, ist die traditionelle dreidimensionale Darstellung oft schwierig zu handhaben. Das Erlernen dynamischer digitaler menschlicher Darstellung aus Videosequenzen hat in den letzten Jahren große Fortschritte gemacht. Bestehende Methoden betrachten die Darstellung häufig als eine neuronale Abbildung der menschlichen Körperhaltung auf ein Bild unter Verwendung des Decoder-Paradigmas „Bewegungsencoder-Bewegungsmerkmale-Erscheinungsbild“. Dieses Paradigma basiert auf Bildverlust für die Überwachung. Es konzentriert sich zu sehr auf die Rekonstruktion jedes einzelnen Bildes und lässt die Modellierung der Bewegungskontinuität vermissen. Daher ist es schwierig, komplexe Bewegungen wie „menschliche Körperbewegungen“ und „kleidungsbezogene Bewegungen“ effektiv zu modellieren ". Um dieses Problem zu lösen, schlug das S-Lab-Team der Nanyang Technological University in Singapur „ein neues Paradigma der dynamischen Rekonstruktion des menschlichen Körpers mit gemeinsamem Lernen von Bewegung und Aussehen“ vor und schlug eine darauf basierende Bewegungsdarstellung in drei Ebenen vor Die Oberfläche des menschlichen Körpers (oberflächenbasierter Dreidecker), der die Modellierung der Bewegungsphysik und des Erscheinungsbilds in einem Framework vereint und neue Ideen zur Verbesserung der Qualität der dynamischen Darstellung des menschlichen Körpers eröffnet. Dieses neue Paradigma modelliert effektiv an der Kleidung befestigte Bewegungen und kann verwendet werden, um die dynamische Rekonstruktion des menschlichen Körpers aus sich schnell bewegenden Videos (z. B. Tanzen) zu erlernen und bewegungsbezogene Schatten darzustellen. Die Rendering-Effizienz ist 9-mal schneller als bei der 3D-Voxel-Rendering-Methode und die LPIPS-Bildqualität wird um etwa 19 Prozentpunkte verbessert.
Papiertitel: SurMo: Surface-based 4D Motion Modeling for Dynamic Human RenderingPapieradresse: https://arxiv.org/pdf/2404.01225.pdfProjekthomepage: https ://taohuumd.github.io/projects/SurMoGithub-Link: https://github.com/TaoHuUMD/SurMo
Angesichts der Mängel des bestehenden Paradigmas „Motion Encoder-Motion Features-Appearance Decoder“, das sich nur auf die Rekonstruktion des Erscheinungsbildes konzentriert und die Bewegungskontinuitätsmodellierung ignoriert, wird ein neues Paradigma SurMo vorgeschlagen: „①Motion Encoder-Motion Features-②Motion Decoder, ③ Aussehen Decoder". Wie in der Abbildung oben gezeigt, ist das Paradigma in drei Phasen unterteilt:
- Im Gegensatz zu bestehenden Methoden, die Bewegung im spärlichen dreidimensionalen Raum modellieren, schlägt SurMo basierend auf dem Mannigfaltigkeitsfeld der menschlichen Oberfläche (oder kompakt) vor (zweidimensionaler strukturierter UV-Raum) vierdimensionale (XYZ-T) Bewegungsmodellierung und stellt die Bewegung durch eine dreiebene (oberflächenbasierte Dreiebene) dar, die auf der menschlichen Körperoberfläche definiert ist.
- Schlagen Sie einen Bewegungsphysik-Decoder vor, der den Bewegungszustand des nächsten Frames basierend auf den aktuellen Bewegungseigenschaften (wie dreidimensionale Haltung, Geschwindigkeit, Bewegungsbahn usw.) vorhersagt, wie z. B. der räumlichen Ablenkung der Bewegungsoberfläche Normalenvektor und zeitliche Ablenkung – Geschwindigkeit, um Dies modelliert die Kontinuität von Bewegungsmerkmalen.
- Vierdimensionale Erscheinungsbilddekodierung, zeitliche Dekodierung von Bewegungsmerkmalen zum Rendern dreidimensionaler Free-View-Point-Videos, hauptsächlich implementiert durch hybrides neuronales Voxel-Textur-Rendering (Hybrid Volumetric-Textural Rendering, HVTR [Hu et al. 2022]) .
SurMo kann dynamisches menschliches Rendering aus Videos lernen, die auf dem End-to-End-Training für Rekonstruktionsverluste und gegnerische Verluste basieren. Experimentelle ErgebnisseDiese Studie führte experimentelle Auswertungen an 3 Datensätzen mit insgesamt 9 dynamischen menschlichen Videosequenzen durch: ZJU-MoCap [Peng et al. 2021], AIST++ [Li, Yang et al . 2021] MPII-RRDC [Habermann et al. 2021]. Der Effekt einer Zeitsequenz (zeitlich variierende Erscheinungen), insbesondere zweier Sequenzen, wird untersucht, wie in der Abbildung unten dargestellt. Jede Sequenz enthält ähnliche Gesten, erscheint jedoch in unterschiedlichen Bewegungsbahnen, wie z. B. ①②, ③④, ⑤⑥. SurMo kann Bewegungsbahnen modellieren und somit dynamische Effekte erzeugen, die sich im Laufe der Zeit ändern, während verwandte Methoden Ergebnisse liefern, die nur von der Körperhaltung abhängen, wobei die Falten der Kleidung bei verschiedenen Bahnen nahezu gleich sind. Wiedergabe von bewegungsbezogenen Schatten und mit Kleidung verbundenen Bewegungen
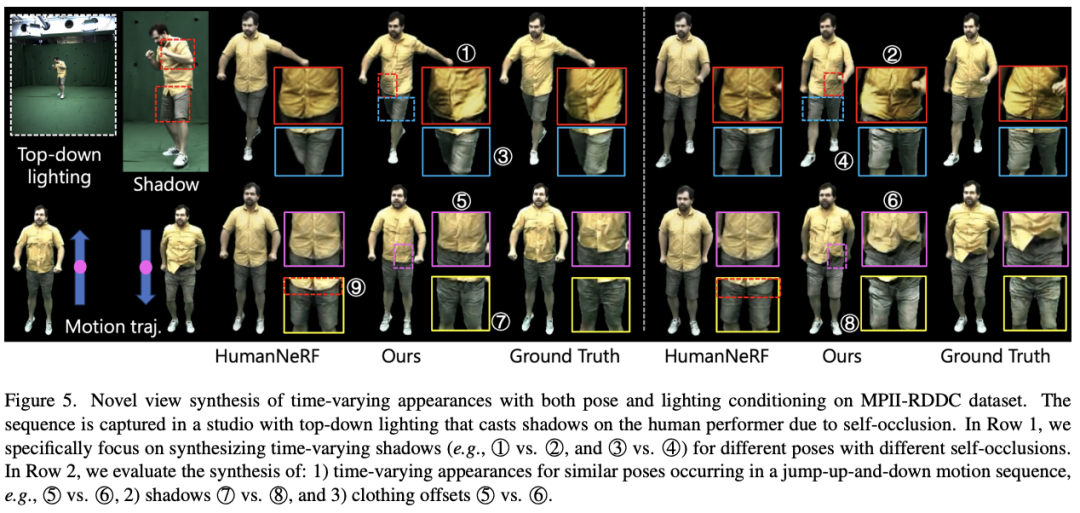
SurMo untersuchte bewegungsbezogene Schatten und mit Kleidung verbundene Bewegungen im MPII-RRDC-Datensatz, wie in der Abbildung unten dargestellt. Die Sequenz wurde auf einer Indoor-Klangbühne gedreht und die Lichtverhältnisse erzeugten aufgrund von Selbstverdeckungsproblemen bewegungsbedingte Schatten auf den Darstellern. SurMo kann diese Schatten wie ①②, ③④, ⑦⑧ unter einem neuen Blickwinkel-Rendering wiederherstellen. Die Kontrastierungsmethode HumanNeRF [Weng et al.] ist nicht in der Lage, bewegungsbedingte Schatten wiederherzustellen. Darüber hinaus kann SurMo die Bewegung von Kleidungsaccessoires rekonstruieren, die sich mit der Bewegungsbahn ändert, wie z. B. unterschiedliche Falten bei Sprungbewegungen ⑤⑥, während HumanNeRF diesen dynamischen Effekt nicht rekonstruieren kann.
Rendern sich schnell bewegender menschlicher Körper
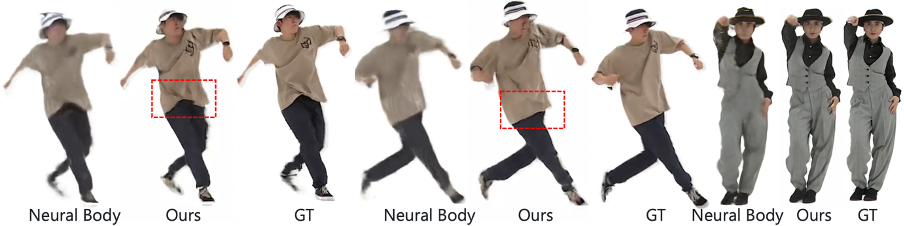
SurMo rendert auch menschliche Körper aus sich schnell bewegenden Videos und stellt bewegungsbezogene Kleidungsfaltendetails wieder her, die mit Kontrastmethoden nicht wiedergegeben werden können.
(1) Bewegungsmodellierung der menschlichen Oberfläche
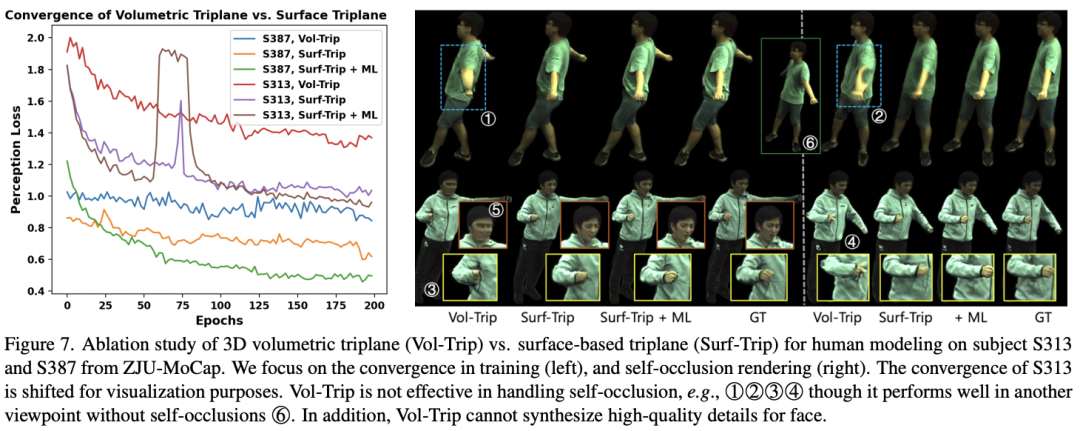
Diese Studie verglich zwei verschiedene Bewegungsmodellierungsmethoden: die derzeit häufig im Voxelraum (Volumenraum) verwendete Bewegungsmodellierung , sowie die von SurMo vorgeschlagene Bewegungsmodellierung des menschlichen Oberflächenmannigfaltigkeitsfeldes (Oberflächenmannigfaltigkeit), insbesondere der Vergleich des volumetrischen Dreideckers und des oberflächenbasierten Dreideckers, wie in der folgenden Abbildung dargestellt. Es lässt sich feststellen, dass die volumetrische Triplane ein spärlicher Ausdruck ist, bei dem nur etwa 21–35 % der Features zum Rendern verwendet werden, während die Feature-Auslastung der oberflächenbasierten Triplane 85 % erreichen kann, sodass sie mehr Vorteile bei der Handhabung von Selbstokklusion bietet, wie z wie (d) gezeigt. Gleichzeitig kann das oberflächenbasierte Triplane ein schnelleres Rendering erzielen, indem es beim Voxel-Rendering weit von der Oberfläche entfernte Punkte filtert, wie in Abbildung (c) dargestellt.
Gleichzeitig zeigt diese Studie, dass der oberflächenbasierte Dreidecker während des Trainingsprozesses schneller konvergieren kann als der volumetrische Dreidecker und offensichtliche Vorteile in Bezug auf Kleidungsfaltdetails und Selbstokklusion aufweist, wie in der Abbildung oben gezeigt. SurMo untersuchte die Wirkung der Bewegungsmodellierung durch Ablationsexperimente, wie in der Abbildung unten dargestellt. Die Ergebnisse zeigen, dass SurMo die statischen Bewegungseigenschaften (z. B. feste Haltung in einem bestimmten Frame) und dynamischen Eigenschaften (z. B. Geschwindigkeit) entkoppeln kann. Wenn beispielsweise die Geschwindigkeit geändert wird, bleiben die Falten eng anliegender Kleidung unverändert (z. B. ①), während die Falten lockerer Kleidung (z. B. ②) stark von der Geschwindigkeit beeinflusst werden, was mit täglichen Beobachtungen übereinstimmt.
Das obige ist der detaillierte Inhalt vonCVPR 2024 | KI kann den fliegenden Rock auch beim Tanzen stark wiederherstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





 SurMo kann diese Schatten wie ①②, ③④, ⑦⑧ unter einem neuen Blickwinkel-Rendering wiederherstellen. Die Kontrastierungsmethode HumanNeRF [Weng et al.] ist nicht in der Lage, bewegungsbedingte Schatten wiederherzustellen. Darüber hinaus kann SurMo die Bewegung von Kleidungsaccessoires rekonstruieren, die sich mit der Bewegungsbahn ändert, wie z. B. unterschiedliche Falten bei Sprungbewegungen ⑤⑥, während HumanNeRF diesen dynamischen Effekt nicht rekonstruieren kann.
SurMo kann diese Schatten wie ①②, ③④, ⑦⑧ unter einem neuen Blickwinkel-Rendering wiederherstellen. Die Kontrastierungsmethode HumanNeRF [Weng et al.] ist nicht in der Lage, bewegungsbedingte Schatten wiederherzustellen. Darüber hinaus kann SurMo die Bewegung von Kleidungsaccessoires rekonstruieren, die sich mit der Bewegungsbahn ändert, wie z. B. unterschiedliche Falten bei Sprungbewegungen ⑤⑥, während HumanNeRF diesen dynamischen Effekt nicht rekonstruieren kann. 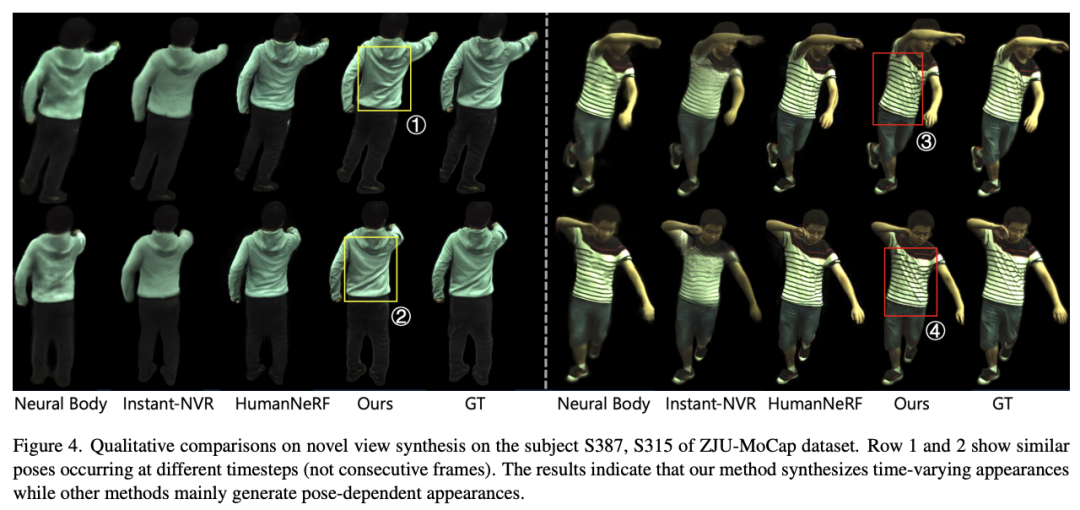

 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Yiou-Handelssoftware herunterladen
Yiou-Handelssoftware herunterladen
 In Win11 gibt es keine WLAN-Option
In Win11 gibt es keine WLAN-Option
 Was soll ich tun, wenn das übereinstimmende Ergebnis der Vlookup-Funktion N/A lautet?
Was soll ich tun, wenn das übereinstimmende Ergebnis der Vlookup-Funktion N/A lautet?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



