
 Technologie-Peripheriegeräte
KI
Jenseits von BEVFusion! DifFUSER: Das Diffusionsmodell tritt in die autonome Fahr-Multitask ein (BEV-Segmentierung + Erkennung Dual-SOTA)
Technologie-Peripheriegeräte
KI
Jenseits von BEVFusion! DifFUSER: Das Diffusionsmodell tritt in die autonome Fahr-Multitask ein (BEV-Segmentierung + Erkennung Dual-SOTA)
Jenseits von BEVFusion! DifFUSER: Das Diffusionsmodell tritt in die autonome Fahr-Multitask ein (BEV-Segmentierung + Erkennung Dual-SOTA)

Geschrieben im Voraus und nach persönlichem Verständnis des Autors
Da die autonome Fahrtechnologie ausgereifter wird und die Nachfrage nach Wahrnehmungsaufgaben für autonomes Fahren steigt, hoffen Industrie und Wissenschaft derzeit sehr auf ein ideales Wahrnehmungsalgorithmusmodell, das gleichzeitig abgeschlossen werden kann dreidimensionale Zielerkennung und semantische Segmentierungsaufgaben basierend auf dem BEV-Raum. Ein autonom fahrendes Fahrzeug ist in der Regel mit Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellen-Radarsensoren ausgestattet, um Daten in verschiedenen Modalitäten zu sammeln. Auf diese Weise können die komplementären Vorteile zwischen verschiedenen Modalitäten vollständig genutzt werden, sodass die komplementären Vorteile von Daten zwischen verschiedenen Modalitäten erzielt werden können. Beispielsweise können 3D-Punktwolkendaten Informationen für 3D-Zielerkennungsaufgaben liefern, während Farbbilddaten kann mehr Informationen für semantische Segmentierungsaufgaben liefern. Angesichts der komplementären Vorteile zwischen verschiedenen Modaldaten wird durch die Konvertierung der effektiven Informationen verschiedener Modaldaten in dasselbe Koordinatensystem die anschließende gemeinsame Verarbeitung und Entscheidungsfindung erleichtert. Beispielsweise können 3D-Punktwolkendaten in Punktwolkendaten basierend auf dem BEV-Raum umgewandelt werden, und Bilddaten von Rundumsichtkameras können durch die Kalibrierung interner und externer Parameter der Kamera in den 3D-Raum projiziert werden, wodurch eine einheitliche Verarbeitung erreicht wird verschiedene modale Daten. Durch die Nutzung unterschiedlicher Modaldaten können genauere Wahrnehmungsergebnisse erzielt werden als bei einzelnen Modaldaten. Jetzt können wir das multimodale Wahrnehmungsalgorithmusmodell bereits im Auto einsetzen, um robustere und genauere räumliche Wahrnehmungsergebnisse zu erzielen. Durch genaue räumliche Wahrnehmungsergebnisse können wir eine zuverlässigere und sicherere Garantie für die Realisierung autonomer Fahrfunktionen bieten.
Obwohl in Wissenschaft und Industrie kürzlich viele 3D-Wahrnehmungsalgorithmen für die multisensorische und multimodale Datenfusion basierend auf dem Transformer-Netzwerk-Framework vorgeschlagen wurden, nutzen sie alle den Kreuzaufmerksamkeitsmechanismus in Transformer, um eine multimodale Datenintegration zu erreichen. Fusion zwischen ihnen, um ideale 3D-Zielerkennungsergebnisse zu erzielen. Diese Art der multimodalen Merkmalsfusionsmethode ist jedoch nicht vollständig für semantische Segmentierungsaufgaben basierend auf dem BEV-Raum geeignet. Darüber hinaus verwenden viele Algorithmen nicht nur den Kreuzaufmerksamkeitsmechanismus, um die Informationsfusion zwischen verschiedenen Modalitäten abzuschließen, sondern verwenden auch die Vorwärtsvektorkonvertierung in LSA, um fusionierte Merkmale zu konstruieren. Es gibt jedoch auch einige Probleme wie folgt: (Begrenzte Wortanzahl, detaillierte Beschreibung folgt ).
- Aufgrund des derzeit vorgeschlagenen 3D-Erfassungsalgorithmus im Zusammenhang mit der multimodalen Fusion ist die Fusionsmethode verschiedener modaler Datenmerkmale nicht ausreichend konzipiert, was dazu führt, dass das Wahrnehmungsalgorithmusmodell die komplexen Verbindungsbeziehungen zwischen Sensordaten nicht genau erfassen kann. und wirkt sich somit auf die letztendlich wahrgenommene Leistung des Modells aus.
- Beim Sammeln von Daten von verschiedenen Sensoren werden unweigerlich irrelevante Rauschinformationen eingeführt. Dieses inhärente Rauschen zwischen verschiedenen Modalitäten führt auch dazu, dass Rauschen in den Prozess der Fusion verschiedener modaler Merkmale eingemischt wird, was zu einer multimodalen Merkmalsfusion führt . Die Ungenauigkeit wirkt sich auf nachfolgende Wahrnehmungsaufgaben aus.
Angesichts der vielen oben genannten Probleme im multimodalen Fusionsprozess, die sich auf die Wahrnehmungsfähigkeit des endgültigen Modells auswirken können, und angesichts der leistungsstarken Leistung, die das generative Modell kürzlich gezeigt hat, haben wir das generative Modell anhand seiner Verwendung untersucht um multimodale Fusions- und Rauschunterdrückungsaufgaben zwischen mehreren Sensoren zu erreichen. Darauf aufbauend schlagen wir einen generativen Modellwahrnehmungsalgorithmus DifFUSER vor, der auf bedingter Diffusion basiert, um multimodale Wahrnehmungsaufgaben zu implementieren. Wie aus der folgenden Abbildung ersichtlich ist, kann der von uns vorgeschlagene multimodale Datenfusionsalgorithmus DifFUSER einen effektiveren multimodalen Fusionsprozess erreichen.  Der multimodale Datenfusionsalgorithmus von DifFUSER kann einen effektiveren multimodalen Fusionsprozess erreichen. Die Methode umfasst hauptsächlich zwei Stufen. Zunächst verwenden wir generative Modelle, um die Eingabedaten zu entrauschen und zu verbessern und so saubere und reichhaltige multimodale Daten zu generieren. Anschließend werden die vom generativen Modell generierten Daten für die multimodale Fusion verwendet, um bessere Wahrnehmungseffekte zu erzielen. Die experimentellen Ergebnisse des DifFUSER-Algorithmus zeigen, dass der von uns vorgeschlagene multimodale Datenfusionsalgorithmus einen effektiveren multimodalen Fusionsprozess erreichen kann. Bei der Implementierung multimodaler Wahrnehmungsaufgaben kann dieser Algorithmus einen effektiveren multimodalen Fusionsprozess erreichen und die Wahrnehmungsfähigkeiten des Modells verbessern. Darüber hinaus kann der multimodale Datenfusionsalgorithmus des Algorithmus einen effizienteren multimodalen Fusionsprozess erreichen. Alles in allem
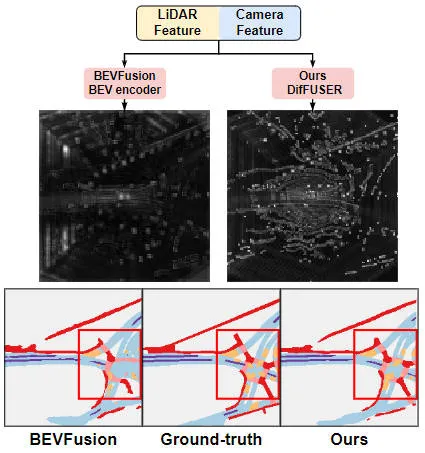
Visuelle Vergleichstabelle der Ergebnisse des vorgeschlagenen Algorithmusmodells und anderer Algorithmusmodelle
Papierlink: https://arxiv.org/pdf/2404.04629.pdf
Gesamtarchitektur und Details des Netzwerkmodell
„Moduldetails des DifFUSER-Algorithmus, Multitask-Wahrnehmungsalgorithmus basierend auf dem bedingten Diffusionsmodell“ ist ein Algorithmus zur Lösung von Aufgabenwahrnehmungsproblemen. Die folgende Abbildung zeigt die gesamte Netzwerkstruktur unseres vorgeschlagenen DifFUSER-Algorithmus. In diesem Modul schlagen wir einen Multitasking-Wahrnehmungsalgorithmus vor, der auf dem bedingten Diffusionsmodell basiert, um das Problem der Aufgabenwahrnehmung zu lösen. Das Ziel dieses Algorithmus besteht darin, die Leistung des Multitask-Lernens durch die Verbreitung und Aggregation aufgabenspezifischer Informationen im Netzwerk zu verbessern. Integration des DifFUSER-Algorithmus
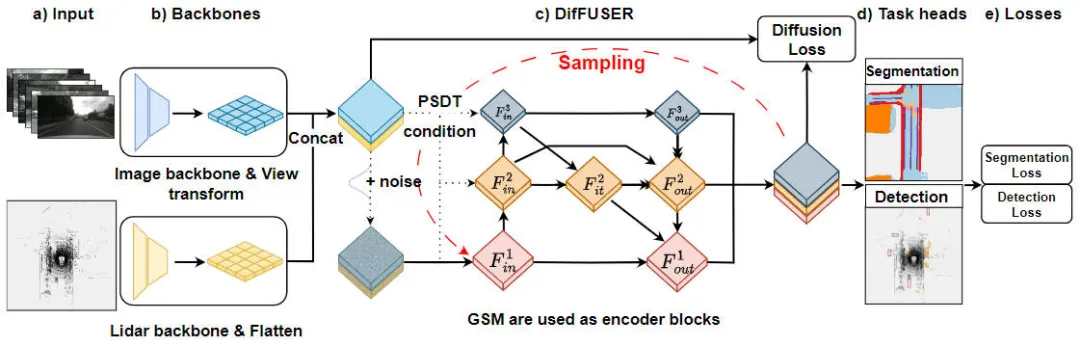 Vorgeschlagenes Netzwerkstrukturdiagramm des DifFUSER-Wahrnehmungsalgorithmusmodells
Vorgeschlagenes Netzwerkstrukturdiagramm des DifFUSER-Wahrnehmungsalgorithmusmodells
Wie aus der obigen Abbildung ersichtlich ist, umfasst die von uns vorgeschlagene DifFUSER-Netzwerkstruktur hauptsächlich drei Teilnetzwerke, nämlich den Backbone-Netzwerkteil, den multimodalen Datenfusionsteil von DifFUSER und der letzte BEV-Kopfteil der semantischen Segmentierungsaufgabe. Kopfteil der Wahrnehmungsaufgabe zur 3D-Objekterkennung. Im Backbone-Netzwerkteil nutzen wir vorhandene Deep-Learning-Netzwerkarchitekturen wie ResNet oder VGG, um High-Level-Merkmale der Eingabedaten zu extrahieren. Der multimodale Datenfusionsteil von DifFUSER verwendet mehrere parallele Zweige, wobei jeder Zweig zur Verarbeitung verschiedener Sensordatentypen (wie Bilder, Lidar und Radar usw.) verwendet wird. Jeder Zweig verfügt über einen eigenen Backbone-Netzwerkteil
- : Dieser Teil führt hauptsächlich die Merkmalsextraktion der vom Netzwerkmodell eingegebenen 2D-Bilddaten und der 3D-Lidar-Punktwolkendaten durch, um die entsprechenden semantischen BEV-Merkmale auszugeben. Für das Backbone-Netzwerk, das Bildmerkmale extrahiert, umfasst es hauptsächlich ein 2D-Bild-Backbone-Netzwerk und ein Perspektivenkonvertierungsmodul. Das Backbone-Netzwerk, das 3D-Lidar-Punktwolkenfunktionen extrahiert, umfasst hauptsächlich das 3D-Punktwolken-Backbone-Netzwerk und das Feature-Flatten-Modul.
- Multimodaler Datenfusionsteil von DifFUSER: Die von uns vorgeschlagenen DifFUSER-Module sind in Form eines hierarchischen bidirektionalen Feature-Pyramidennetzwerks miteinander verbunden. Wir nennen diese Struktur cMini-BiFPN. Diese Struktur bietet eine alternative Struktur für die potenzielle Diffusion und kann die mehrskaligen und detaillierten Breiten-Höhen-Merkmalsinformationen aus verschiedenen Sensordaten besser verarbeiten.
- BEV-Semantiksegmentierung, 3D-Zielerkennungs-Wahrnehmungsaufgabenkopfteil: Da unser Algorithmusmodell gleichzeitig 3D-Zielerkennungsergebnisse und semantische Segmentierungsergebnisse im BEV-Raum ausgeben kann, umfasst der 3D-Wahrnehmungsaufgabenkopf einen 3D-Erkennungskopf und einen semantischen Segmentierungskopf . Darüber hinaus umfassen die mit dem von uns vorgeschlagenen Algorithmusmodell verbundenen Verluste Diffusionsverluste, Erkennungsverluste und semantische Segmentierungsverluste. Durch die Summierung aller Verluste werden die Parameter des Netzwerkmodells durch Backpropagation aktualisiert.
Als nächstes werden wir die Implementierungsdetails jedes Hauptunterteils des Modells sorgfältig vorstellen.
Fusion-Architektur-Design (Conditional-Mini-BiFPN, cMini-BiFPN)
Für die Wahrnehmungsaufgaben im autonomen Fahrsystem ist es entscheidend, dass das Algorithmusmodell die aktuelle äußere Umgebung in Echtzeit wahrnehmen kann, also ist es so sehr wichtig, um die Leistung und Effizienz des Diffusionsmoduls sicherzustellen. Daher lassen wir uns vom bidirektionalen Feature-Pyramiden-Netzwerk inspirieren und führen eine BiFPN-Diffusionsarchitektur mit ähnlichen Bedingungen ein, die wir Conditional-Mini-BiFPN nennen. Die spezifische Netzwerkstruktur ist in der obigen Abbildung dargestellt.


Progressive Sensor Dropout Training (PSDT)
Für ein autonomes Fahrzeug ist die Leistung des autonomen Fahrerfassungssensors von entscheidender Bedeutung. Während der täglichen Fahrt des autonomen Fahrzeugs ist es sehr wahrscheinlich, dass die Der Kamerasensor oder Lidar-Sensor wird blockiert oder weist eine Fehlfunktion auf, was sich auf die Sicherheit und Betriebseffizienz des endgültigen autonomen Fahrsystems auswirkt. Basierend auf dieser Überlegung haben wir ein progressives Sensor-Dropout-Trainingsparadigma vorgeschlagen, um die Robustheit und Anpassungsfähigkeit des vorgeschlagenen Algorithmusmodells in Situationen zu verbessern, in denen der Sensor möglicherweise blockiert ist.
Durch unser vorgeschlagenes progressives Sensor-Dropout-Trainingsparadigma kann das Algorithmusmodell fehlende Merkmale rekonstruieren, indem es die Verteilung zweier modaler Daten nutzt, die von Kamerasensoren und Lidar-Sensoren erfasst werden, und so eine hervorragende Anpassung an Leistung und Robustheit unter rauen Bedingungen erreichen. Insbesondere nutzen wir Merkmale aus Bilddaten und Lidar-Punktwolkendaten auf drei verschiedene Arten: als Trainingsziele, als Rauscheingabe in das Diffusionsmodul und zur Simulation von Bedingungen, unter denen ein Sensor verloren geht oder eine Fehlfunktion aufweist. Während des Trainings erhöhen wir schrittweise die Verlustrate des Kamerasensor- oder Lidar-Sensoreingangs von 0 auf einen vordefinierten Maximalwert a = 25. Der gesamte Prozess kann durch die folgende Formel ausgedrückt werden:
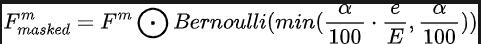
Stellt unter anderem die Anzahl der Trainingsrunden dar, in denen sich das aktuelle Modell befindet, und definiert die Ausfallwahrscheinlichkeit, um die Wahrscheinlichkeit darzustellen, dass jedes Feature gelöscht wird. Durch diesen progressiven Trainingsprozess wird das Modell nicht nur darauf trainiert, das Rauschen effektiv zu entstören und ausdrucksstärkere Merkmale zu erzeugen, sondern minimiert auch seine Abhängigkeit von einem einzelnen Sensor und verbessert so die Handhabung unvollständiger Sensoren mit größerer Belastbarkeit.
Gated Self-Conditioned Modulation Diffusion Module (GSM Diffusion Module)

Im Einzelnen ist die Netzwerkstruktur des Gated Self-Conditioned Modulation Diffusion Module in der folgenden Abbildung dargestellt
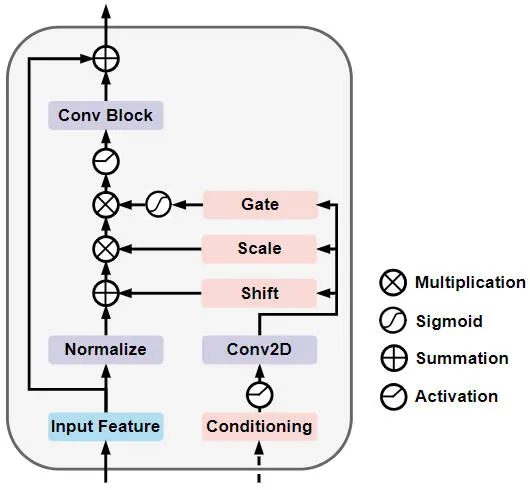
Gated Self-Conditioned Modulationsdiffusion Schematische Darstellung der Modulnetzwerkstruktur

Experimentelle Ergebnisse und Bewertungsindikatoren
Quantitativer Analyseteil
Um die Wahrnehmungsergebnisse unseres vorgeschlagenen Algorithmusmodells DifFUSER für mehrere Aufgaben zu überprüfen, haben wir hauptsächlich durchgeführt Basierend auf dem nuScenes-Datensatz werden 3D-Zielerkennungs- und semantische Segmentierungsexperimente basierend auf dem BEV-Raum durchgeführt.
Zuerst haben wir die Leistung des vorgeschlagenen Algorithmusmodells DifFUSER mit anderen multimodalen Fusionsalgorithmen für semantische Segmentierungsaufgaben verglichen. Die spezifischen experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt:
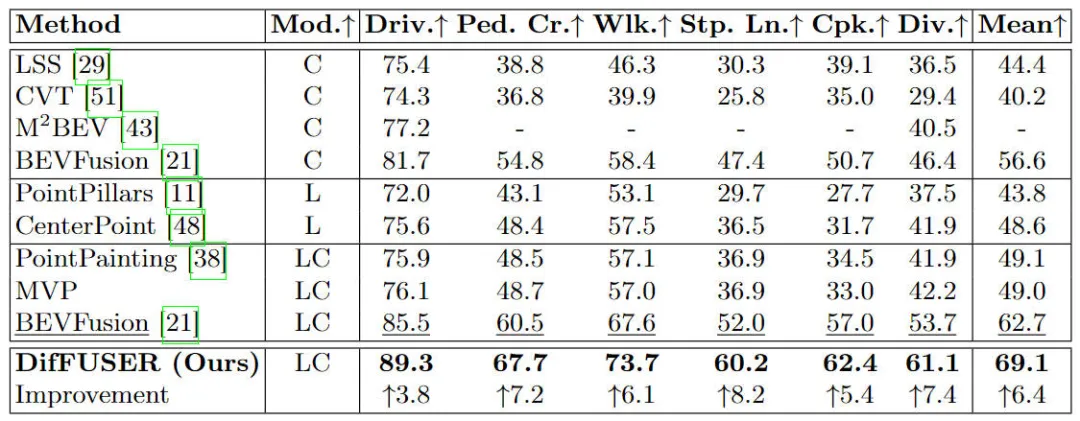 Vergleich verschiedener Algorithmusmodelle im nuScenes-Datensatz Experimentelle Ergebnisse semantischer Segmentierungsaufgaben basierend auf dem BEV-Raum
Vergleich verschiedener Algorithmusmodelle im nuScenes-Datensatz Experimentelle Ergebnisse semantischer Segmentierungsaufgaben basierend auf dem BEV-Raum
Aus den experimentellen Ergebnissen ist ersichtlich, dass das von uns vorgeschlagene Algorithmusmodell im Vergleich zum Basismodell eine deutlich verbesserte Leistung aufweist. Insbesondere beträgt der mIoU-Wert des BEVFusion-Modells nur 62,7 %, während das von uns vorgeschlagene Algorithmusmodell 69,1 % erreicht hat, was einer Verbesserung von 6,4 % entspricht, was zeigt, dass der von uns vorgeschlagene Algorithmus in verschiedenen Kategorien mehr Vorteile bietet. Darüber hinaus veranschaulicht die folgende Abbildung auch intuitiver die Vorteile des von uns vorgeschlagenen Algorithmusmodells. Insbesondere liefert der BEVFusion-Algorithmus schlechte Segmentierungsergebnisse, insbesondere in Szenarien über große Entfernungen, in denen eine Fehlausrichtung des Sensors offensichtlicher ist. Im Vergleich dazu liefert unser Algorithmusmodell genauere Segmentierungsergebnisse mit offensichtlicheren Details und weniger Rauschen.
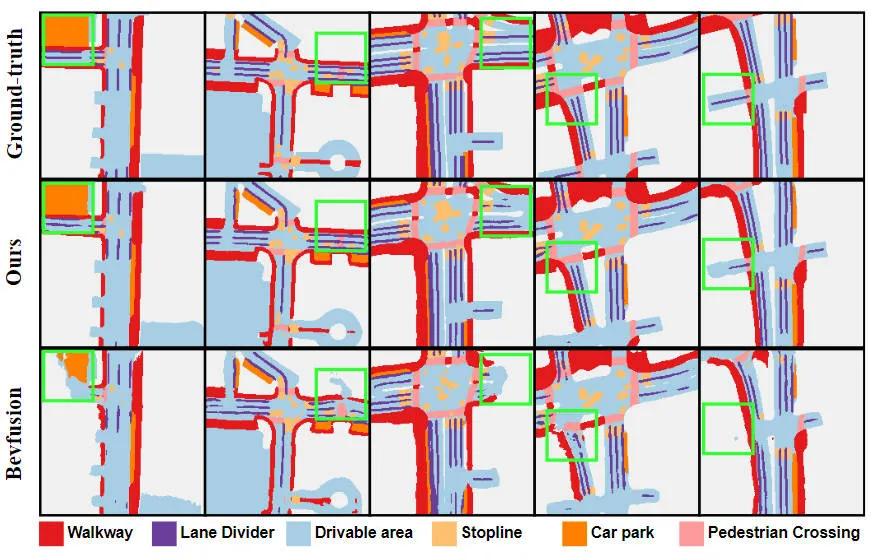
Vergleich der Segmentierungsvisualisierungsergebnisse des vorgeschlagenen Algorithmusmodells und des Basismodells
Darüber hinaus haben wir das vorgeschlagene Algorithmusmodell auch mit anderen 3D-Zielerkennungsalgorithmusmodellen verglichen. Die spezifischen experimentellen Ergebnisse sind in der folgenden Tabelle aufgeführt
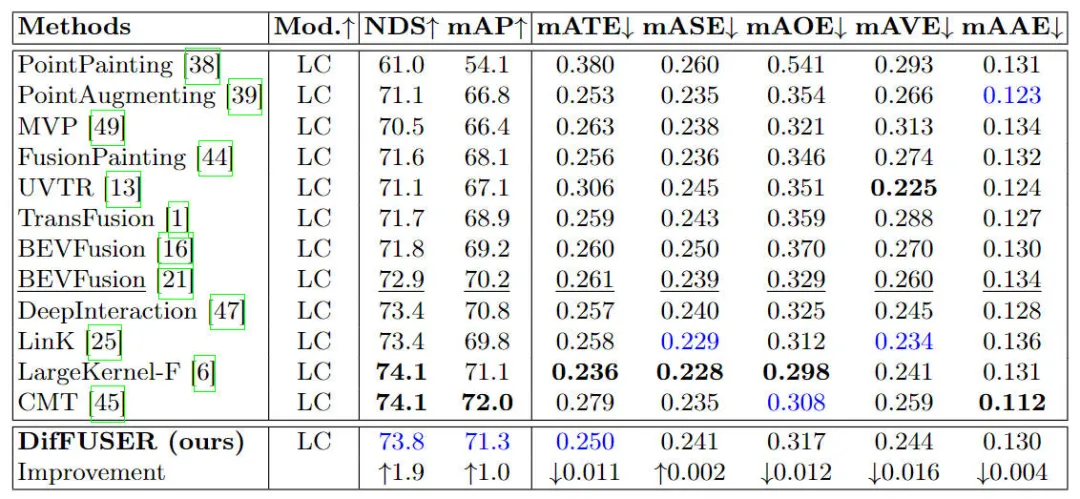
Vergleich der experimentellen Ergebnisse verschiedener Algorithmusmodelle zur 3D-Zielerkennungsaufgabe im nuScenes-Datensatz
Wie aus den in der Tabelle aufgeführten Ergebnissen ersichtlich ist, weist unser vorgeschlagenes Algorithmusmodell DifFUSER sowohl in NDS als auch in mAP eine bessere Leistung auf Im Vergleich zu den 72,9 % NDS und 70,2 % mAP des Basismodells BEVFusion ist unser Algorithmusmodell um 1,8 % bzw. 1,0 % höher. Die Verbesserung relevanter Indikatoren zeigt, dass das von uns vorgeschlagene multimodale Diffusionsfusionsmodul bei der Merkmalsreduzierung und Merkmalsverfeinerung wirksam ist.
Um die Wahrnehmungsrobustheit unseres vorgeschlagenen Algorithmusmodells im Falle eines Sensorausfalls oder einer Sensorokklusion zu zeigen, haben wir außerdem die Ergebnisse verwandter Segmentierungsaufgaben verglichen, wie in der folgenden Abbildung dargestellt.
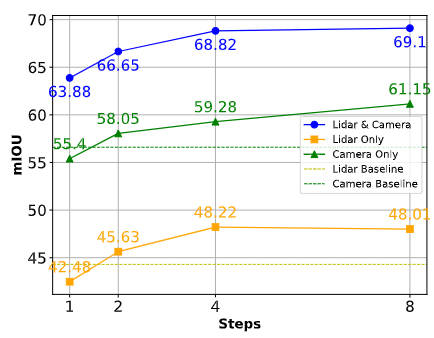
Vergleich der Algorithmusleistung in verschiedenen Situationen
Wie aus der obigen Abbildung ersichtlich ist, kann das von uns vorgeschlagene Algorithmusmodell bei ausreichender Abtastung fehlende Merkmale effektiv kompensieren und als Grundlage für die Sammlung fehlender Sensoren verwendet werden Informationen. Alternative Inhalte. Die Fähigkeit unseres vorgeschlagenen DifFUSER-Algorithmusmodells, synthetische Merkmale zu generieren und zu nutzen, verringert effektiv die Abhängigkeit von einer einzelnen Sensormodalität und stellt sicher, dass das Modell in verschiedenen und anspruchsvollen Umgebungen reibungslos funktionieren kann.
Teil der qualitativen Analyse
Die folgende Abbildung zeigt die Visualisierung der 3D-Zielerkennungs- und semantischen Segmentierungsergebnisse des BEV-Raums unseres vorgeschlagenen DifFUSER-Algorithmusmodells. Aus den Visualisierungsergebnissen ist ersichtlich, dass das von uns vorgeschlagene Algorithmusmodell gut ist Erkennung und Split-Effekt.

Fazit
In diesem Artikel wird ein multimodales Wahrnehmungsalgorithmusmodell DifFUSER vorgeschlagen, das auf dem Diffusionsmodell basiert und die Fusionsarchitektur des Netzwerkmodells verbessert und die Rauschunterdrückungseigenschaften nutzt des Diffusionsmodells. Die experimentellen Ergebnisse des Nuscenes-Datensatzes zeigen, dass das von uns vorgeschlagene Algorithmusmodell eine SOTA-Segmentierungsleistung in der semantischen Segmentierungsaufgabe des BEV-Raums erreicht und eine ähnliche Erkennungsleistung wie das aktuelle SOTA-Algorithmusmodell in der 3D-Zielerkennungsaufgabe erreichen kann.
Das obige ist der detaillierte Inhalt vonJenseits von BEVFusion! DifFUSER: Das Diffusionsmodell tritt in die autonome Fahr-Multitask ein (BEV-Segmentierung + Erkennung Dual-SOTA). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Ein Diffusionsmodell-Tutorial, das Ihre Zeit wert ist, von der Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion kann nicht nur besser imitieren, sondern auch „erschaffen“. Das Diffusionsmodell (DiffusionModel) ist ein Bilderzeugungsmodell. Im Vergleich zu bekannten Algorithmen wie GAN und VAE im Bereich der KI verfolgt das Diffusionsmodell einen anderen Ansatz. Seine Hauptidee besteht darin, dem Bild zunächst Rauschen hinzuzufügen und es dann schrittweise zu entrauschen. Das Entrauschen und Wiederherstellen des Originalbilds ist der Kernbestandteil des Algorithmus. Der endgültige Algorithmus ist in der Lage, aus einem zufälligen verrauschten Bild ein Bild zu erzeugen. In den letzten Jahren hat das phänomenale Wachstum der generativen KI viele spannende Anwendungen in der Text-zu-Bild-Generierung, Videogenerierung und mehr ermöglicht. Das Grundprinzip dieser generativen Werkzeuge ist das Konzept der Diffusion, ein spezieller Sampling-Mechanismus, der die Einschränkungen bisheriger Methoden überwindet.
 Ein Artikel, der die Anwendung des Diffusionsmodells in Zeitreihen zusammenfasst
Mar 07, 2024 am 10:30 AM
Ein Artikel, der die Anwendung des Diffusionsmodells in Zeitreihen zusammenfasst
Mar 07, 2024 am 10:30 AM
Das Diffusionsmodell ist derzeit das Kernmodul der generativen KI und wird häufig in großen generativen KI-Modellen wie Sora, DALL-E und Imagen verwendet. Gleichzeitig werden Diffusionsmodelle zunehmend auf Zeitreihen angewendet. Dieser Artikel führt Sie in die Grundideen des Diffusionsmodells sowie in mehrere typische Arbeiten des in Zeitreihen verwendeten Diffusionsmodells ein, um Ihnen das Verständnis der Anwendungsprinzipien des Diffusionsmodells in Zeitreihen zu erleichtern. 1. Idee der Diffusionsmodellmodellierung Der Kern des generativen Modells besteht darin, einen Punkt aus einer zufälligen einfachen Verteilung abzutasten und diesen Punkt durch eine Reihe von Transformationen einem Bild oder einer Probe im Zielraum zuzuordnen. Die Methode des Diffusionsmodells besteht darin, das Rauschen an den abgetasteten Abtastpunkten kontinuierlich zu entfernen und nach mehreren Rauschentfernungsschritten die endgültigen Daten zu generieren.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 So beschleunigen Sie BitGenie_So beschleunigen Sie die Download-Geschwindigkeit von BitGenie
Apr 29, 2024 pm 02:58 PM
So beschleunigen Sie BitGenie_So beschleunigen Sie die Download-Geschwindigkeit von BitGenie
Apr 29, 2024 pm 02:58 PM
1. Stellen Sie zunächst sicher, dass Ihre BT-Seeds gesund sind, über genügend Seeds verfügen und beliebt genug sind, damit sie die Voraussetzungen für das BT-Downloaden erfüllen und die Geschwindigkeit hoch ist. Öffnen Sie die Spalte „Auswählen“ Ihres eigenen BitComet, klicken Sie in der ersten Spalte auf „Netzwerkverbindung“ und passen Sie die globale maximale Download-Geschwindigkeit unbegrenzt auf 1000 an (1000 für Benutzer unter 2 Millionen ist eine unerreichbare Zahl, es ist jedoch in Ordnung, sie nicht anzupassen das, wer möchte es nicht herunterladen) Sehr schnell). Die maximale Upload-Geschwindigkeit kann unbegrenzt auf 40 eingestellt werden (entsprechend den persönlichen Umständen wählen, wenn die Geschwindigkeit zu hoch ist, friert der Computer ein). 3. Klicken Sie auf Aufgabeneinstellungen. Sie können das Standard-Download-Verzeichnis darin anpassen. 4. Klicken Sie auf Schnittstellendarstellung. Ändern Sie die maximale Anzahl der angezeigten Peers auf 1000, um die Details der mit Ihnen verbundenen Benutzer anzuzeigen, damit Sie beruhigt sein können. 5. Klicken Sie
 So verwenden Sie den Netsh-Befehl in Win7
Apr 09, 2024 am 10:03 AM
So verwenden Sie den Netsh-Befehl in Win7
Apr 09, 2024 am 10:03 AM
Der Befehl netsh wird zum Verwalten von Netzwerken in Windows 7 verwendet und kann Folgendes tun: Netzwerkinformationen anzeigen, TCP/IP-Einstellungen konfigurieren, drahtlose Netzwerke verwalten, Netzwerk-Proxys einrichten
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
