
 Technologie-Peripheriegeräte
KI
CVPR 2024 |. Ein allgemeines Bildfusionsmodell basierend auf MoE, das 2,8 % Parameter hinzufügt, um mehrere Aufgaben zu erledigen
Technologie-Peripheriegeräte
KI
CVPR 2024 |. Ein allgemeines Bildfusionsmodell basierend auf MoE, das 2,8 % Parameter hinzufügt, um mehrere Aufgaben zu erledigen
CVPR 2024 |. Ein allgemeines Bildfusionsmodell basierend auf MoE, das 2,8 % Parameter hinzufügt, um mehrere Aufgaben zu erledigen


Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

Papier-Link: https://arxiv.org/abs/2403.12494 Code-Link: https://github.com/YangSun22/TC-MoA Papier-Titel: Aufgabenspezifische Mischung von Adaptern für General Image Fusion

Wir schlagen ein einheitliches allgemeines Bildfusionsmodell vor, das einen neuen aufgabenspezifischen Hybridadapter (TC-MoA) für die adaptive Bildfusion aus mehreren Quellen bereitstellt (nutzt die dynamische Aggregation). gültiger Informationen aus den jeweiligen Schemata).
 komplementäre Informationen aus verschiedenen Quellen, um ein zusammengeführtes Bild
komplementäre Informationen aus verschiedenen Quellen, um ein zusammengeführtes Bild 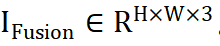 zu erhalten. Wir geben das Quellbild in das ViT-Netzwerk ein und erhalten das Token des Quellbilds über die Patch-Codierungsschicht. ViT besteht aus einem Encoder zur Merkmalsextraktion und einem Decoder zur Bildrekonstruktion, die beide aus Transformer-Blöcken bestehen.
zu erhalten. Wir geben das Quellbild in das ViT-Netzwerk ein und erhalten das Token des Quellbilds über die Patch-Codierungsschicht. ViT besteht aus einem Encoder zur Merkmalsextraktion und einem Decoder zur Bildrekonstruktion, die beide aus Transformer-Blöcken bestehen.  Transformatorblock einen TC-MoA in den Encoder und Decoder ein. Das Netzwerk moduliert schrittweise das Ergebnis der Fusion durch diese TC-MoAs. Jedes TC-MoA besteht aus einer aufgabenspezifischen Router-Bank
Transformatorblock einen TC-MoA in den Encoder und Decoder ein. Das Netzwerk moduliert schrittweise das Ergebnis der Fusion durch diese TC-MoAs. Jedes TC-MoA besteht aus einer aufgabenspezifischen Router-Bank  , einer Task-Sharing-Adapterbank
, einer Task-Sharing-Adapterbank  und einer Hinweisfusionsschicht F. TC-MoA besteht aus zwei Hauptphasen: Cue-Generierung und Cue-gesteuerte Fusion. Zur Vereinfachung des Ausdrucks nehmen wir VIF als Beispiel, gehen davon aus, dass die Eingabe aus dem VIF-Datensatz stammt, und verwenden G zur Darstellung von
und einer Hinweisfusionsschicht F. TC-MoA besteht aus zwei Hauptphasen: Cue-Generierung und Cue-gesteuerte Fusion. Zur Vereinfachung des Ausdrucks nehmen wir VIF als Beispiel, gehen davon aus, dass die Eingabe aus dem VIF-Datensatz stammt, und verwenden G zur Darstellung von  . O Abbildung 2 Die Gesamtarchitektur von TC-MOA
. O Abbildung 2 Die Gesamtarchitektur von TC-MOA 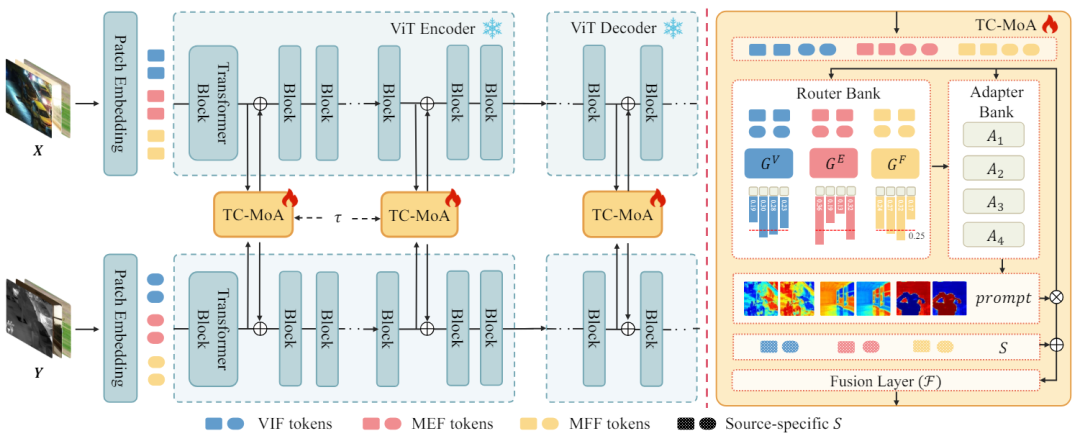
definiert. Wir verketten als Feature-Darstellungen von Token-Paaren aus mehreren Quellen. Dadurch können Token aus unterschiedlichen Quellen innerhalb des nachfolgenden Netzwerks Informationen austauschen. Die direkte Berechnung hochdimensionaler verketteter Features bringt jedoch eine große Anzahl unnötiger Parameter mit sich. Daher verwenden wir


 Dann wählen wir entsprechend der Aufgabe, zu der Φ gehört, einen aufgabenspezifischen Router aus der Router-Bank aus um das Routing-Schema anzupassen, d. h., welcher Adapter in der Adapterbank für jedes Quell-Token-Paar eingegeben werden soll.
Dann wählen wir entsprechend der Aufgabe, zu der Φ gehört, einen aufgabenspezifischen Router aus der Router-Bank aus um das Routing-Schema anzupassen, d. h., welcher Adapter in der Adapterbank für jedes Quell-Token-Paar eingegeben werden soll. 

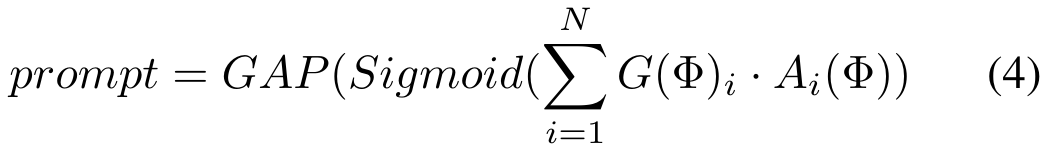
 und erhalten dann die Fusionsfeatures über die Fusionsschicht F. Der Prozess ist wie folgt:
und erhalten dann die Fusionsfeatures über die Fusionsschicht F. Der Prozess ist wie folgt: 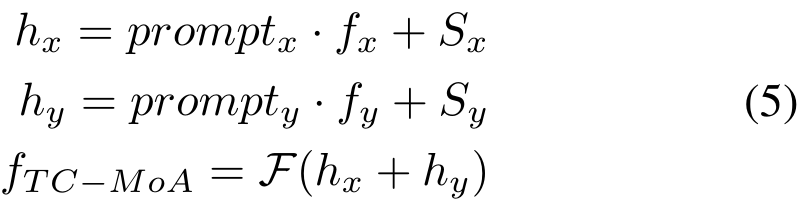
 ist ein Hyperparameter):
ist ein Hyperparameter): 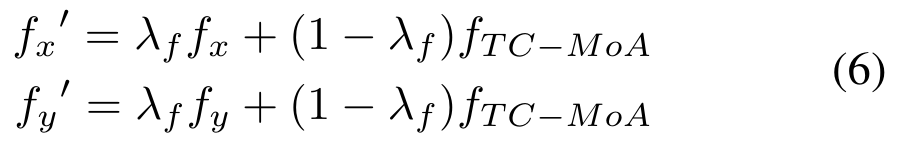



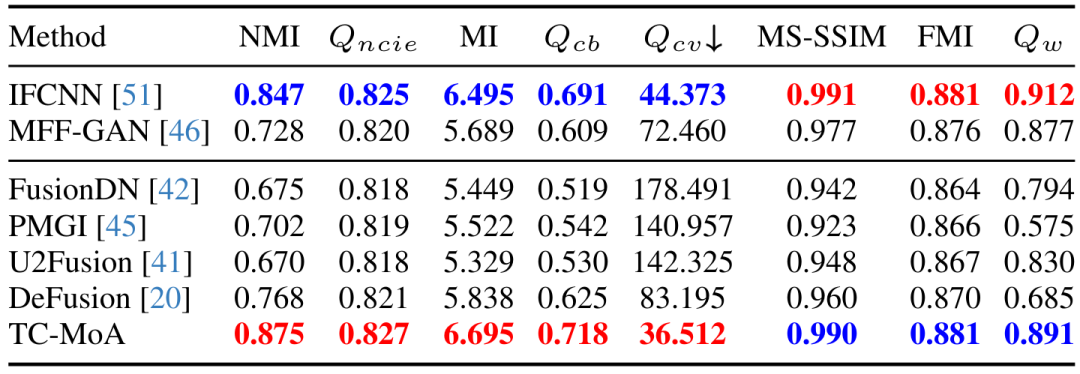
Das obige ist der detaillierte Inhalt vonCVPR 2024 |. Ein allgemeines Bildfusionsmodell basierend auf MoE, das 2,8 % Parameter hinzufügt, um mehrere Aufgaben zu erledigen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Frage Beschreibung: Wie erhalten Sie die Daten der Versandregion der Überseeversion? Gibt es bereitgestellte Ressourcen? Werden Sie im grenzüberschreitenden E-Commerce oder im globalisierten Geschäft genau ...
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
